CosyVoice: Open-Source-Projekt zum Klonen von 3-Sekunden-Stimmen von Ali mit Unterstützung für gefühlsgesteuerte Tags
Allgemeine Einführung
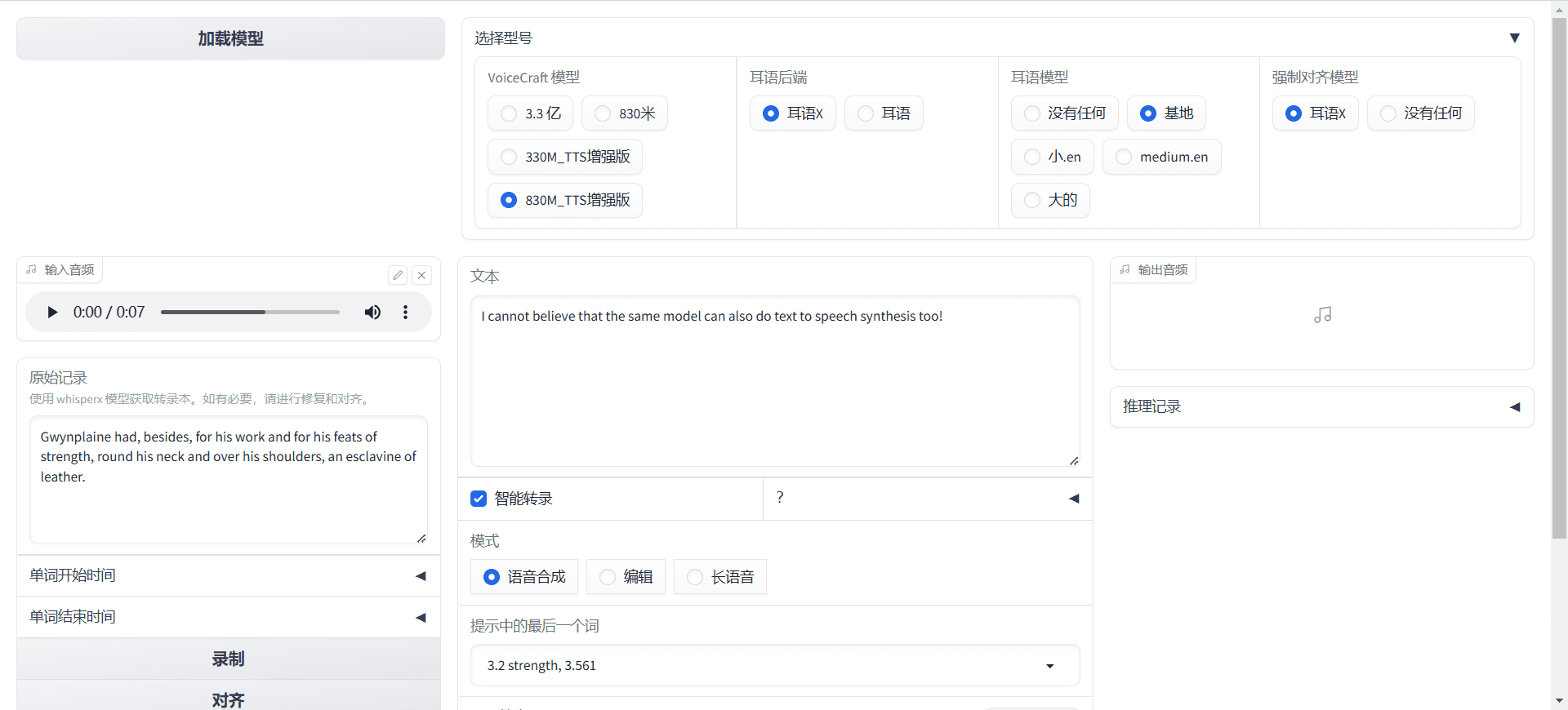
CosyVoice ist ein mehrsprachiges, groß angelegtes Spracherzeugungsmodell, das von der Inferenz über das Training bis hin zur Bereitstellung umfassende Funktionen bietet. CosyVoice wurde vom FunAudioLLM-Team entwickelt und zielt auf eine hochwertige Sprachsynthese durch fortschrittliche autoregressive Transformatoren und ODE-basierte Diffusionsmodelle ab. CosyVoice unterstützt nicht nur die mehrsprachige Spracherzeugung, sondern bietet auch Emotionskontrolle und Kantonesisch-Synthese auf einem Niveau, das mit der menschlichen Aussprache vergleichbar ist.
Kostenlose Online-Erfahrung (Text-to-Speech): https://modelscope.cn/studios/iic/CosyVoice-300M
Kostenlose Online-Erfahrung (Sprache zu Text): https://www.modelscope.cn/studios/iic/SenseVoice

Funktionsliste
- Mehrsprachige Spracherzeugung: unterstützt die Sprachsynthese in mehreren Sprachen.
- Sprachklonen: die Fähigkeit, die Sprachmerkmale eines bestimmten Sprechers zu klonen.
- Text-to-Speech: Wandeln Sie Textinhalte in natürliche und flüssige Sprache um.
- Emotionskontrolle: Einstellbarer Gefühlsausdruck bei der Sprachsynthese.
- Kantonesische Synthese: Unterstützt die Spracherzeugung in Kantonesisch.
- Hochwertige Audioausgabe: Synthese von High-Fidelity-Audio über HiFTNet-Vocoder.
Hilfe verwenden
Einbauverfahren
Kürzlich hat Ali Tongyi Labs das CosyVoice-Sprachmodell veröffentlicht, das natürliche Spracherzeugung, Mehrsprachigkeit, Klangfarben- und Emotionskontrolle unterstützt und sich durch mehrsprachige Spracherzeugung, Null-Sample-Spracherzeugung, sprachübergreifende Klangsynthese und Befehlsausführungsfähigkeiten auszeichnet.
CosyVoice nutzt insgesamt mehr als 150.000 Stunden Datentraining, um die Synthese von fünf Sprachen - Chinesisch, Englisch, Japanisch, Kantonesisch und Koreanisch - zu unterstützen, und der Syntheseeffekt ist deutlich besser als bei herkömmlichen Sprachsynthesemodellen.
CosyVoice unterstützt das Klonen von Tönen in einem Durchgang: Es werden nur 3 bis 10 Sekunden an Rohdaten benötigt, um analoge Töne zu erzeugen, die sogar Details wie Rhythmus und Emotionen enthalten. Auch bei der sprachenübergreifenden Sprachsynthese zeigt es gute Leistungen.
Da die offizielle Version vorerst keine Windows- und Mac-Plattformen unterstützt, haben wir CosyVoice dieses Mal lokal auf diesen beiden Plattformen eingesetzt.
Windows-Plattform
Wechseln Sie zunächst zur Windows-Plattform und klonen Sie das Projekt:
git clone https://github.com/v3ucn/CosyVoice_For_Windows
Zugang zu Projekten.
cd CosyVoice_For_Windows
Eingebaute Module generieren:
git submodule update --init --recursive
Installieren Sie anschließend die Abhängigkeiten:
conda create -n cosyvoice python=3.11
conda activate cosyvoice
pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/ --trusted-host=mirrors.aliyun.com
Die offiziell empfohlene Version von Python ist 3.8. Tatsächlich läuft 3.11, und theoretisch hat 3.11 eine bessere Leistung.
Laden Sie dann die Windows-Version des deepspeed-Installationsprogramms herunter, um es zu installieren:
https://github.com/S95Sedan/Deepspeed-Windows/releases/tag/v14.0%2Bpy311
Installieren Sie schließlich die GPU-Version der Fackel: die
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
Hier ist die Version von cuda als 12 ausgewählt, oder Sie können 11 installieren.
Das Modell wurde dann heruntergeladen:
# git模型下载,请确保已安装git lfs
mkdir -p pretrained_models
git clone https://www.modelscope.cn/iic/CosyVoice-300M.git pretrained_models/CosyVoice-300M
git clone https://www.modelscope.cn/iic/CosyVoice-300M-SFT.git pretrained_models/CosyVoice-300M-SFT
git clone https://www.modelscope.cn/iic/CosyVoice-300M-Instruct.git pretrained_models/CosyVoice-300M-Instruct
git clone https://www.modelscope.cn/speech_tts/speech_kantts_ttsfrd.git pretrained_models/speech_kantts_ttsfrd
Es ist sehr schnell, weil es das Magic Hitch Lager in China nutzt.
Fügen Sie schließlich die Umgebungsvariablen hinzu:
set PYTHONPATH=third_party/AcademiCodec;third_party/Matcha-TTS
Grundlegende Verwendung:
from cosyvoice.cli.cosyvoice import CosyVoice
from cosyvoice.utils.file_utils import load_wav
import torchaudio
cosyvoice = CosyVoice('speech_tts/CosyVoice-300M-SFT')
# sft usage
print(cosyvoice.list_avaliable_spks())
output = cosyvoice.inference_sft('你好,我是通义生成式语音大模型,请问有什么可以帮您的吗?', '中文女')
torchaudio.save('sft.wav', output['tts_speech'], 22050)
cosyvoice = CosyVoice('speech_tts/CosyVoice-300M')
# zero_shot usage
prompt_speech_16k = load_wav('zero_shot_prompt.wav', 16000)
output = cosyvoice.inference_zero_shot('收到好友从远方寄来的生日礼物,那份意外的惊喜与深深的祝福让我心中充满了甜蜜的快乐,笑容如花儿般绽放。', '希望你以后能够做的比我还好呦。', prompt_speech_16k)
torchaudio.save('zero_shot.wav', output['tts_speech'], 22050)
# cross_lingual usage
prompt_speech_16k = load_wav('cross_lingual_prompt.wav', 16000)
output = cosyvoice.inference_cross_lingual('<|en|>And then later on, fully acquiring that company. So keeping management in line, interest in line with the asset that\'s coming into the family is a reason why sometimes we don\'t buy the whole thing.', prompt_speech_16k)
torchaudio.save('cross_lingual.wav', output['tts_speech'], 22050)
cosyvoice = CosyVoice('speech_tts/CosyVoice-300M-Instruct')
# instruct usage
output = cosyvoice.inference_instruct('在面对挑战时,他展现了非凡的<strong>勇气</strong>与<strong>智慧</strong>。', '中文男', 'Theo \'Crimson\', is a fiery, passionate rebel leader. Fights with fervor for justice, but struggles with impulsiveness.')
torchaudio.save('instruct.wav', output['tts_speech'], 22050)
Webui wird hier für mehr Intuition und Komfort empfohlen:
python3 webui.py --port 9886 --model_dir ./pretrained_models/CosyVoice-300M
Besuchen Sie http://localhost:9886

Beachten Sie, dass die offizielle Fackel sox für das Backend verwendet, hier ist es in soundfile geändert:
torchaudio.set_audio_backend('soundfile')
Es kann noch einige Fehler geben, also bleiben Sie dran, wenn es in Zukunft offizielle Projekt-Updates gibt.
MacOS-Plattform
Für die MacOs-Plattform ist es besser, das Projekt zunächst zu klonen:
git clone https://github.com/v3ucn/CosyVoice_for_MacOs.git
Installieren Sie die Abhängigkeit:
cd CosyVoice_for_MacOs
conda create -n cosyvoice python=3.8
conda activate cosyvoice
pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/ --trusted-host=mirrors.aliyun.com
Anschließend müssen Sie sox über Homebrew installieren:
brew install sox
Es ist also konfiguriert, aber vergessen Sie nicht, Umgebungsvariablen hinzuzufügen:
export PYTHONPATH=third_party/AcademiCodec:third_party/Matcha-TTS
Die Verwendung bleibt dieselbe wie bei der Windows-Version.
Hier wird nach wie vor das Webui empfohlen: die
python3 webui.py --port 50000 --model_dir speech_tts/CosyVoice-300M
Besuchen Sie http://localhost:50000

Schlussbemerkungen
In aller Fairness, CosyVoice verdient eine große Fabrik zu sein, ist die Qualität des Modells nicht zu sagen, was das höchste Niveau der inländischen AI, Tongyi Labs Name ist nicht falsch, natürlich, wenn Sie auch Open-Source-Code nach dem Engineering, wäre es besser, ich glaube, dass nach der Optimierung der libtorch, wird dieses Modell die Open-Source der TTS ist keine gute Wahl.
Verwendungsprozess
- Spracherzeugung::
- Bereiten Sie die Eingabetextdatei (z. B. input.txt) mit einem Satz pro Zeile vor.
- Führen Sie den folgenden Befehl zur Spracherzeugung aus:
python generate.py --input input.txt --output output/ - Die erzeugten Sprachdateien werden im Verzeichnis
output/Katalog.
- Sprachklonen::
- Bereiten Sie eine Sprachmusterdatei (z. B. sample.wav) des Zielsprechers vor.
- Führen Sie den folgenden Befehl zum Klonen der Stimme aus:
python clone.py --sample sample.wav --text input.txt --output output/ - Die geklonten Sprachdateien werden im Verzeichnis
output/Katalog.
- emotionale Kontrolle::
- Emotionen können bei der Spracherzeugung mit Kommandozeilenparametern eingestellt werden:
python generate.py --input input.txt --output output/ --emotion happy - Zu den unterstützenden Emotionen gehören: glücklich, traurig, wütend, neutral.
- Emotionen können bei der Spracherzeugung mit Kommandozeilenparametern eingestellt werden:
- Kantonesisch-Synthese::
- Bereiten Sie eine kantonesische Textdatei vor (z. B. cantonese_input.txt).
- Führen Sie den folgenden Befehl zur Erzeugung kantonesischer Sprache aus:
python generate.py --input cantonese_input.txt --output output/ --language cantonese - Die erzeugten kantonesischen Sprachdateien werden im Verzeichnis
output/Katalog.
Detaillierte Vorgehensweise
- Textvorbereitung::
- Vergewissern Sie sich, dass die Eingabedatei korrekt formatiert ist (ein Satz pro Zeile).
- Der Text sollte so knapp und klar wie möglich gehalten sein und keine komplexen Sätze enthalten.
- Vorbereitung von Stimmproben::
- Bei den Sprachproben sollte es sich um klare Ein-Personen-Sprache mit möglichst wenig Hintergrundgeräuschen handeln.
- Es wird empfohlen, dass die Probenlänge weniger als 1 Minute beträgt, um eine optimale Klonierung zu gewährleisten.
- Parametrisierung::
- Passen Sie die Parameter der generierten Sprache, wie z. B. Emotionen, Sprache usw., nach Bedarf an.
- Die Personalisierung kann durch die Änderung von Konfigurationsdateien oder Befehlszeilenparametern erreicht werden.
- Validierung der Ergebnisse::
- Die erzeugten Sprachdateien können mit einem Audioplayer vorgehört werden.
- Wenn die Ergebnisse nicht zufriedenstellend sind, können die eingegebenen Text- oder Sprachproben angepasst und neu generiert werden.
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel

Keine Kommentare...