Baichuan Intelligence bringt Baichuan-Omni-1.5 Omnimodales Großmodell heraus, das das GPT-4o Mini in mehreren Messungen übertrifft
Gegen Ende des Jahres verbreitete die inländische Großmodellbranche wieder gute Nachrichten. BCinks Intelligence hat vor kurzem eine Reihe von Großmodellprodukten veröffentlicht, nachdem dieTiefes Inferenzmodell für eine ganze Szene Baichuan-M1-Vorschauim Gesang antwortenMedizinische Verbesserung Open Source Modell Baichuan-M1-14BEs folgte der Relaunch vonVollständiges modales Modell Baichuan-Omni-1.5.
Baichuan-Omni-1.5 ist als "Big Model Generalist" bekannt, was den bedeutenden Fortschritt des einheimischen Big Model in der multimodalen Fusionstechnologie markiert.Baichuan-Omni-1.5 ist mit ausgezeichneten omnimodalen Verständnis- und Erzeugungsfähigkeiten ausgestattet, die nicht nur in der Lage sind, gleichzeitigText, Bilder, Audio, Videound andere multimodale Informationen, sowie mehr Unterstützung fürText und AudioBimodale Inhaltserstellung.
Gleichzeitig hat der Nachrichtendienst Baichuan auch eine Open-Source-Lösung fürOpenMM-Medicalim Gesang antwortenOpenAudioBenchDie beiden hochwertigen Bewertungsdatensätze sollen die erfolgreiche Entwicklung des inländischen Ökosystems für multimodale Modelltechnologien fördern. Nach den umfassenden Bewertungsergebnissen, die veröffentlicht wurden, verfügt Baichuan-Omni-1.5 über eine Reihe von multimodalen FähigkeitenDie Gesamtleistung übertrifft die des GPT-4o MiniBesonders im medizinischen Bereich, wo BCinks Intelligence immer weiter vorgedrungen ist.Die Bewertungen medizinischer Bilder sind ein wichtiger HinweisDies beweist die Stärke und Entschlossenheit von BCinks Intelligence als führendes Unternehmen im Bereich der Großmodelle. Dies beweist die Stärke und Entschlossenheit von Baichuan Intelligence als führendes Unternehmen auf dem Gebiet der Großmodelle, seine Stärke und Entschlossenheit bei der technologischen Innovation und der Landung in der Industrie.
Adresse des Modellgewichts:
Baichuan-Omini-1.5: https://huggingface.co/baichuan-inc/Baichuan-Omni-1d5 https://modelers.cn/models/Baichuan/Baichuan-Omni-1d5
Baichuan-Omini-1.5-Basis: https://huggingface.co/baichuan-inc/Baichuan-Omni-1d5-Base https://modelers.cn/models/Baichuan/Baichuan- Omni-1d5-Basis
GitHub-Adresse: https://github.com/baichuan-inc/Baichuan-Omni-1.5
Technischer Bericht: https://github.com/baichuan-inc/Baichuan-Omni-1.5/blob/main/baichuan_omni_1_5.pdf
01 . Umfassender Durchbruch bei den multimodalen Fähigkeiten: hervorragende Leistung bei der Bewertung der Text-, Grafik-, Audio- und Videoverarbeitung
Die Leistungsmerkmale des Baichuan-Omni-1.5 lassen sich wie folgt zusammenfassen: "Umfassende Funktionen und hohe Leistung". Das bemerkenswerteste Merkmal des Modells ist seineUmfassendDie Fähigkeit, multimodale Inhalte zu verstehen und zu erzeugen, bedeutet, dass sie nicht nur multimodale Inhalte wie Text, Bild, Video und Audio versteht, sondern auch die bimodale Erzeugung von Text und Audio unterstützt.
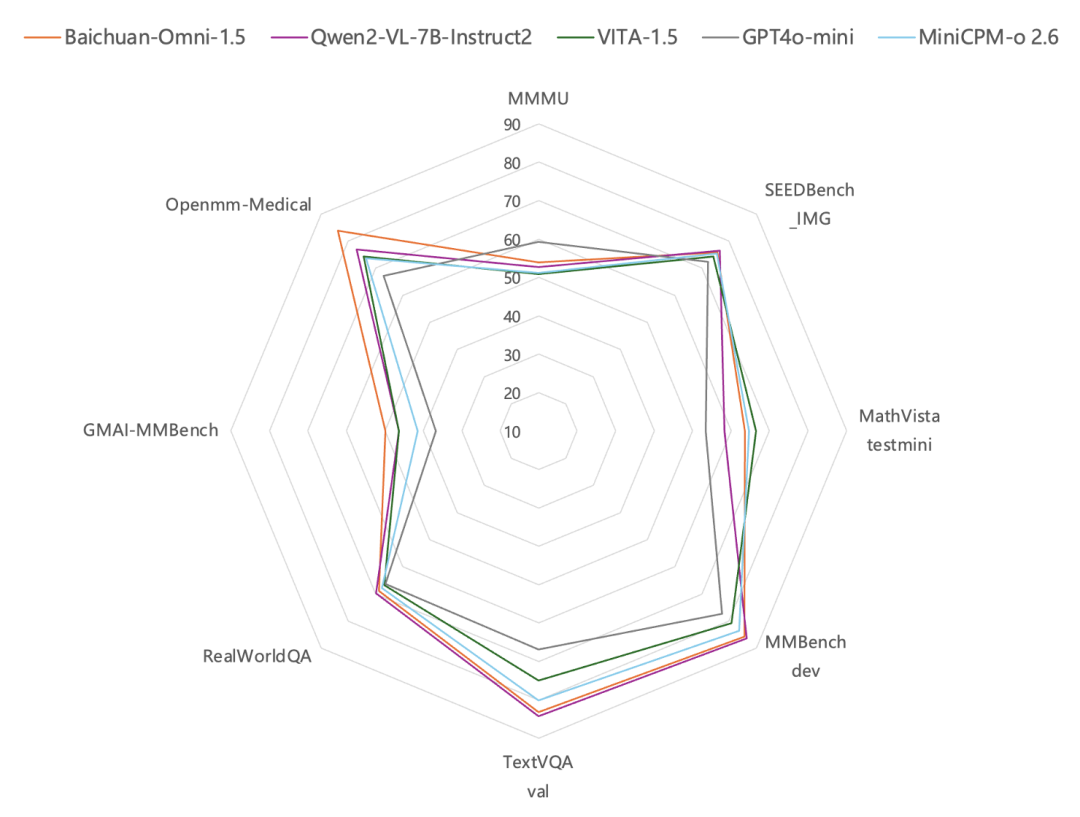
Was das Bildverständnis angeht, so ist die Leistung von Baichuan-Omni-1.5 laut den Testergebnissen bei gängigen Bildbewertungsbenchmarks wie MMBench-dev, TextVQA val usw.Besser als GPT-4o Mini. Von besonderem Interesse ist die Tatsache, dass das allmodale Modell von Baichuan Intelligence zusätzlich zu seinen allgemeinen Fähigkeiten besonders stark im Bereich des Gesundheitswesens ist. UnterDatensatz für die Überprüfung medizinischer Bilder Bewertungen auf GMAI-MMBench und Openmm-Medical haben gezeigt, dass die Fähigkeiten von Baichuan-Omni-1.5 beim Verstehen medizinischer BilderDeutlich bessere Leistung als GPT-4o Mini.
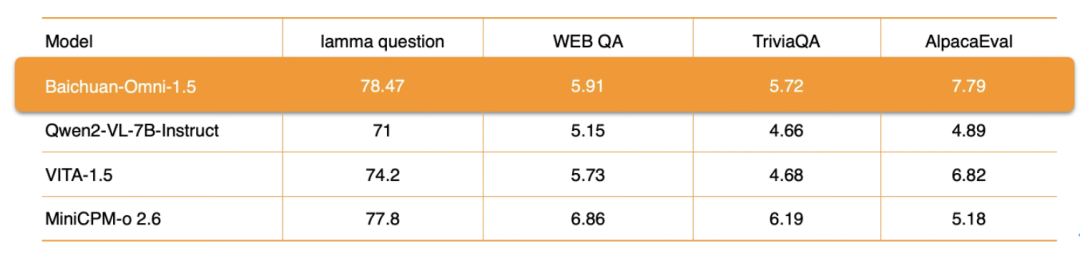
Was die Audioverarbeitung betrifft, so unterstützt Baichuan-Omni-1.5 nicht nur diemehrsprachiger DialogSie stützt sich auch auf ihre Fähigkeiten zur End-to-End-Audiosynthese, die die ASR (Automatic Speech Recognition) im Gesang antworten TTS (Text-to-Speech) Funktionen. Darüber hinaus unterstützt das Modell auch die Implementierung derAudio-Video-Interaktion in Echtzeit. Was die spezifischen Leistungskennzahlen betrifft, so ist die Gesamtleistung von Baichuan-Omni-1.5 bei Datensätzen wie "Lamma Question" und "AlpacaEvaldeutlich besser als Qwen2-VL-2B-Instruct, VITA-1.5 und MiniCPM-o 2.6 sind ähnliche Modelle.
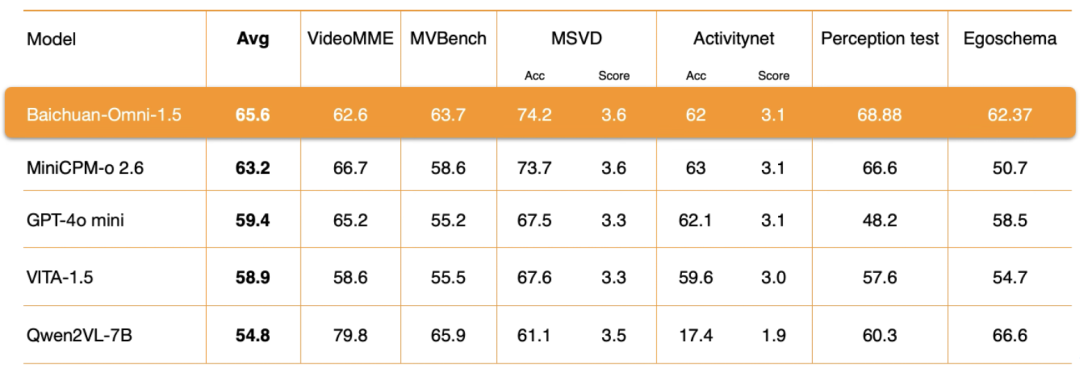
Video-VerständnisAuf der Ebene von Baichuan-Omni-1.5 hat Baichuan Intelligence mehrere Schlüsselaspekte wie die Encoder-Architektur, die Qualität der Trainingsdaten und die Strategie der Trainingsmethode eingehend optimiert. Die Bewertungsergebnisse zeigen, dass das VideoverständnisAuch die Gesamtleistung liegt deutlich über der des GPT-4o-mini..
Zusammenfassend lässt sich sagen, dass Baichuan-Omni-1.5 nicht nur GPT4o-mini in Bezug auf die Allzweckfähigkeit insgesamt übertrifft, sondern vor allem auch dieEinheit von vollständigem modalem Verständnis und Erzeugungdie die Grundlage für den Aufbau allgemeinerer KI-Systeme bildet.
Um die Forschung im Bereich der multimodalen Modellierung weiter voranzutreiben, hat Baichuan Intelligence zwei professionelle Bewertungsdatensätze zur Verfügung gestellt:OpenMM-Medical und OpenAudioBench. Unter ihnen OpenMM-Medical DatensatzEntwickelt zur Bewertung der Modellleistung bei medizinischen multimodalen AufgabenEs integriert Daten aus 42 öffentlich zugänglichen medizinischen Bilddatensätzen, wie ACRIMA (Fundusbilder), BioMediTech (Mikroskopbilder) und CoronaHack (Röntgenbilder), mit insgesamt 88.996 Bildern.
Adresse herunterladen:
https://huggingface.co/datasets/baichuan-inc/OpenMM_Medical
OpenAudioBench dann ist es einEine umfassende Bewertungsplattform zur effizienten Beurteilung von Modell-AudiokenntnissenEs enthält 5 Sub-Assessment-Sets für das Audio-End-to-End-Verständnis, von denen 4 aus öffentlichen Assessment-Datensätzen abgeleitet sind (Llama Question, WEB QA, TriviaQA, AlpacaEval), und das andere ist ein von Baichuan Intelligence selbst konstruiertes Assessment-Set für logisches Denken, das 2.701 Daten enthält.
Adresse herunterladen:
https://huggingface.co/datasets/baichuan-inc/OpenAudioBench
BCinks Intelligence beteiligt sich aktiv am Aufbau und der Entwicklung des nationalen Open-Source-Ökosystems und fördert dieses. Der Open-Source-Evaluierungsdatensatz bietet Forschern und Entwicklern ein einheitliches und standardisiertes Evaluierungstool, das eine objektive und faire vergleichende Analyse der Leistung verschiedener multimodaler Modelle ermöglicht und so die innovative Entwicklung von Sprachverstehensalgorithmen und Modellarchitekturen der neuen Generation fördert.
02 . Umfassende technologische Optimierung: Synergie von Daten, Architektur und Prozessen, um den Engpass der multimodalen Modelle zu überwinden
Von der frühen Entwicklung unimodaler Modelle über die multimodale Fusion bis hin zu den heutigen allmodalen Modellen hat diese technologische Entwicklung den Raum für die Anwendung der KI-Technologie in verschiedenen Branchen erweitert. Mit der tiefgreifenden Entwicklung der KI-Technologie wird jedoch auch dieDie Frage, wie die Einheit von Verstehen und Erzeugen in multimodalen Modellen effektiv erreicht werden kann, ist zu einem zentralen Thema und einer technischen Schwierigkeit in der aktuellen Forschung im Bereich der Multimodalität geworden.
Einerseits ist die Einheit von Verstehen und Generieren der Schlüssel zur Simulation natürlicher menschlicher Interaktion und zur Erreichung einer natürlicheren und effizienteren Mensch-Computer-Kommunikation sowie ein wichtiges Bindeglied zu allgemeiner künstlicher Intelligenz (AGI); andererseits gibt es erhebliche Unterschiede zwischen verschiedenen modalen Daten in Bezug auf Merkmalsrepräsentationen, Datenstrukturen und semantische Konnotationen usw., so dass die Frage, wie multimodale Merkmale effektiv extrahiert werden können und wie eine effektive Interaktion und Fusion von cross-modalen Informationen erreicht werden kann, als eine der eine der größten Herausforderungen für das Training multimodaler Modelle.
Die Veröffentlichung von Baichuan-Omni-1.5 zeigt, dass Baichuan Intelligence erhebliche Fortschritte bei der Lösung der oben genannten technischen Probleme gemacht und einen effektiven technischen Weg erkundet hat. Um das allgemeine Problem des "intellektuellen Abbaus" beim Training omnimodaler Modelle zu überwinden, hat das Forschungsteam von Baichuan den gesamten Prozess vom Entwurf der Modellstruktur über die Optimierung der Trainingsstrategie bis hin zur Erstellung von Trainingsdaten eingehend optimiert und schließlich eine effektive Vereinheitlichung von Verständnis und Erzeugung erreicht.
zuerst inModellierungDie Eingabeschicht von Baichuan-Omni-1.5 unterstützt verschiedene modale Daten, die zur Verarbeitung durch den entsprechenden Encoder/Tokeniser in das groß angelegte Sprachmodell eingespeist werden; in der Ausgabeschicht verwendet das Modell ein Text-Audio-Interleaved-Output-Design, das durch den Text-Tokenizer und den Audio-Decoder gleichzeitig sowohl Text- als auch Audioinhalte erzeugen kann. In der Ausgabeschicht verwendet das Modell ein Text-Audio-Interleaved-Output-Design, bei dem durch den Text-Tokenizer und den Audio-Decoder gleichzeitig sowohl Text- als auch Audio-Modalitäten erzeugt werden können. Der Audio Tokenizer basiert auf dem OpenAI Open Source Spracherkennungs- und Übersetzungsmodell. Flüstern Inkrementelles Training wird durchgeführt, um eine fortschrittliche semantische Extraktion und eine originalgetreue Audiorekonstruktion zu ermöglichen. Um das Modell in die Lage zu versetzen, Bilder mit unterschiedlichen Auflösungen zu verarbeiten, führt Baichuan-Omni-1.5 das NaViT-Modell ein, das Bildeingaben mit einer Auflösung von bis zu 4K und Multibild-Inferenz unterstützt und so sicherstellt, dass das Modell die Bildinformationen vollständig erfassen und den Bildinhalt genau verstehen kann.
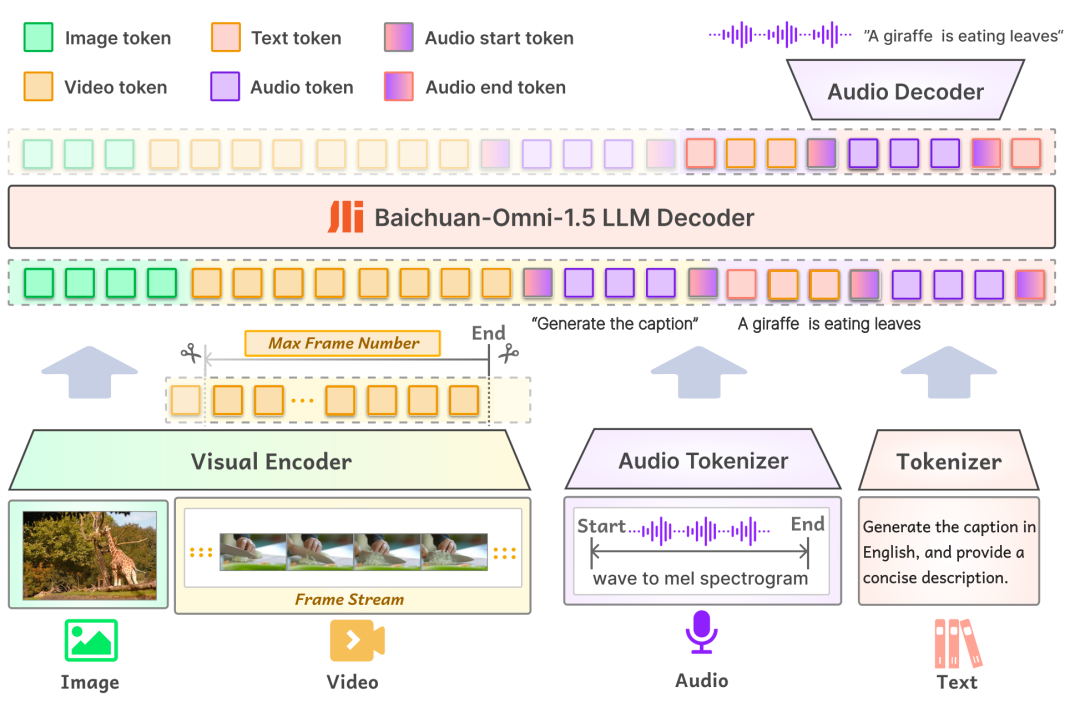
Zweitens, inEbene der DatenBCI hat eine umfangreiche Datenbank mit 340 Millionen hochwertigen Bild-/Video-Text-Daten und fast 1 Million Stunden Audiodaten aufgebaut, aus der 17 Millionen vollmodale Daten für die SFT-Phase (supervised fine-tuning) des Modells ausgewählt wurden. Im Gegensatz zur Datenzusammensetzung herkömmlicher Modelle erfordert das Training vollmodaler Modelle nicht nur eine große Datenmenge, sondern auch eine Vielfalt von Datentypen und eine intermodale Verschachtelung. In der realen Welt werden Informationen in der Regel als eine Verschmelzung mehrerer Modalitäten dargestellt, und Daten verschiedener Modalitäten enthalten komplementäre Informationen, und die effektive Verschmelzung multimodaler Daten hilft dem Modell, allgemeinere Muster und Gesetze zu erlernen, wodurch die Generalisierungsfähigkeit des Modells verbessert wird. Dies ist eines der Schlüsselelemente bei der Entwicklung leistungsstarker multimodaler Modelle.
Um die Fähigkeit des Modells zum cross-modalen Verständnis zu verbessern, erstellte Baichuan Intelligence hochwertige, verschachtelte Bild-Audio-Text-Daten und trainierte das Modell mit Alignment unter Verwendung von 16 Millionen Grafikdaten, 300.000 reinen Textdaten, 400.000 Audiodaten sowie den oben erwähnten cross-modalen Daten. Um das Modell in die Lage zu versetzen, verschiedene Audioaufgaben wie ASR, TTS, Timbre-Switching und Audio-End-to-End-Q&A gleichzeitig auszuführen, konstruierte das Forschungsteam außerdem Datenmuster, die sich speziell auf diese Aufgaben in den abgeglichenen Daten beziehen.
Der dritte technologische Schlüsselpunkt istAusbildungsprozessDie optimale Gestaltung des Modells ist das zentrale Bindeglied, um sicherzustellen, dass hochwertige Daten die Leistung des Modells effektiv verbessern können. BCinks Intelligence verwendet ein mehrstufiges Trainingsverfahren sowohl in der Pre-Training- als auch in der SFT-Phase, um die Wirkung des Modells umfassend zu verbessern. Der Trainingsprozess ist in vier Phasen unterteilt: Die erste Phase basiert auf dem Training von Grafikdaten, in der zweiten Phase werden Audiodaten für das Pre-Training hinzugefügt, in der dritten Phase werden Videodaten für das Training eingeführt und die letzte Phase ist die multimodale Ausrichtungsphase, die es dem Modell schließlich ermöglicht, ein umfassendes Verständnis für alle modalen Inhalte zu erlangen.
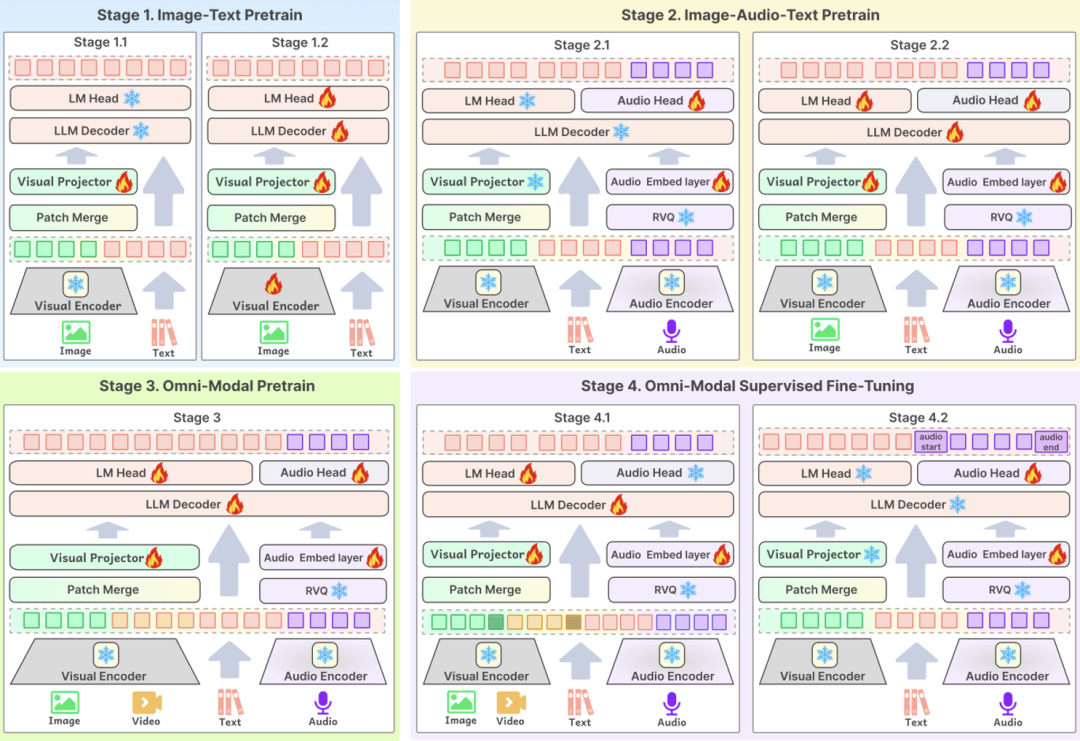
Die Veröffentlichung von Baichuan-Omni-1.5 ist nicht nur ein weiterer wichtiger Meilenstein in der technologischen Forschung und Entwicklung von Baichuan Intelligence, sondern bedeutet auch, dass sich der Schwerpunkt der KI-Entwicklung von der Verbesserung der grundlegenden Fähigkeiten des Modells bis hin zur praktischen Anwendung beschleunigt.
Bisher konzentrierte sich die Verbesserung der Fähigkeiten des großen Modells vor allem auf grundlegende Fähigkeiten wie Sprachverständnis und Bilderkennung, während die leistungsstarke multimodale Fusionsfähigkeit von Baichuan-Omni-1.5 dazu beitragen wird, die Technologie stärker in reale Anwendungsszenarien zu integrieren. Durch die Verbesserung der umfassenden Fähigkeiten des Modells in der multimodalen Informationsverarbeitung, wie Sprache, Bild, Ton usw., kann Baichuan-Omni-1.5 effektiv auf komplexere und vielfältigere praktische Anwendungsaufgaben reagieren. In der Medizinbranche beispielsweise können die leistungsstarken Verstehens- und Generierungsfähigkeiten des omnimodalen Modells dazu genutzt werden, Ärzte bei der Krankheitsdiagnose zu unterstützen und die Genauigkeit und Effizienz der Diagnose zu verbessern, was für die Förderung der eingehenden Anwendung von KI-Technologie im medizinischen Bereich von großem Wert ist. Mit Blick auf die Zukunft könnte die Veröffentlichung von Baichuan-Omni-1.5 der Beginn der Anwendung von KI-Technologie in der Medizin und im Gesundheitswesen in der AGI-Ära sein, und wir haben Grund zu der Annahme, dass KI in naher Zukunft eine größere Rolle in der Medizin und anderen Bereichen spielen und unser Leben tiefgreifend verändern wird.
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel




Keine Kommentare...