Wettbewerb für KI-Forschungsassistenten: Eingehende Prüfung und Auswahlhilfe für fünf gängige Tools

Der Aufstieg der KI-Forschungsassistenten: Wer kann Ihnen wirklich bei Ihren Hausaufgaben helfen?
Forschung im Informationszeitalter bedeutet oft, sich durch riesige Datenmengen zu kämpfen. In der Vergangenheit mussten Forscher Informationen manuell suchen, sichten und ordnen, bevor sie wichtige Inhalte an Personen wie ChatGPT Solche großen Sprachmodelle werden analysiert. Doch mit der Einführung der Funktion "Deep Research" von OpenAI beginnen sich die Dinge zu ändern. Diese neuen KI-Tools versprechen, den gesamten Forschungsprozess zu automatisieren: Der Nutzer stellt einfach eine Frage, und die KI durchsucht selbstständig das Internet, analysiert die Daten und erstellt einen Bericht mit Zitaten. Dies wird häufig durch fortschrittliche Big-Language-Modelle wie o3 von OpenAI gesteuert, die nicht nur auf vortrainiertes Wissen zurückgreifen, sondern auch proaktiv aktuelle Informationen beschaffen und mehrstufige Schlussfolgerungen ziehen.
Die Versuche von OpenAI haben die Branche schnell auf den Plan gerufen.2023 Seit März haben mehrere Unternehmen ihre eigenen automatisierten Recherchetools oder KI-Agenten (Agents) auf den Markt gebracht, die oft als "KI-Suchassistenten" oder "Deep Research"-Tools bezeichnet werden. Das Kernkonzept dieser Tools ist ähnlich: Nutzung leistungsfähiger KI-Modellierungsfunktionen in Kombination mit der Websuche, um eigenständig Rechercheaufgaben durchzuführen und Ergebnisse zu liefern.

Dieser Artikel befasst sich mit einigen dieser hoch angesehenen Produkte auf dem Markt, mit dem Ziel, ihre Leistungsunterschiede, Leistungsgrenzen und die besten Szenarien für jedes Produkt durch einen Praxistest zu untersuchen. Zu den an diesem Vergleich beteiligten Tools gehören:
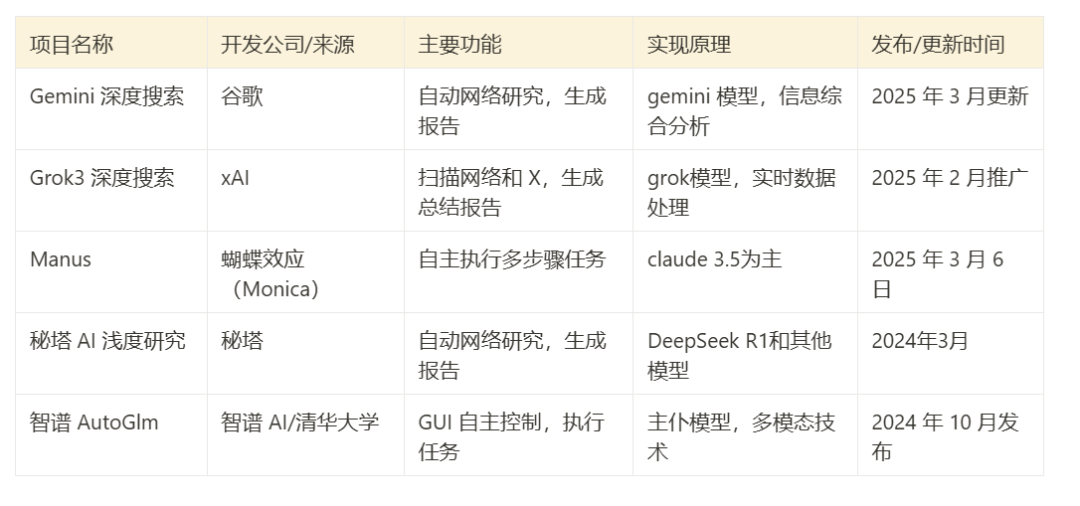
- Gemini Deep Search: basierend auf Google's Zwillinge Eine Reihe von Modellen, die die Fähigkeit zur Synthese und Analyse von Informationen hervorheben.
- Grok 3 Tiefensuche: Verwendung von xAIs Grok 3 Ein Modell, das so konzipiert ist, dass es Aufgaben selbständig ausführen kann, möglicherweise mit einer stärkeren Ausrichtung auf Echtzeitinformationen.
- Manusein System, das eine breite Palette von KI-Modellen unterstützt (z. B. Anthropisch (in Form eines Nominalausdrucks) Claude und Alis Qwen) Plattformen, die dafür bekannt sind, mehrstufige Aufgaben zu erfüllen.
- Mita AI Shallow ResearchKombination des R1-Modells mit einer Zerlegung des logischen Rahmens und Verwendung des eigenen Modells für die Websuche und Integration.
- Zhipu AutoGLMAuf der Grundlage des umfangreichen Sprachmodells von Zhipu AI steuert es selbstständig digitale Geräte zur Informationserfassung und -verarbeitung, indem es Benutzeraktionen über eine grafische Benutzeroberfläche (GUI) simuliert.
Um die tatsächliche Leistung dieser Werkzeuge zu verstehen, haben wir allen fünf Produkten dieselbe relativ komplexe Forschungsaufgabe gestellt.
Vergleichende Tests: Erstellung von AI-Modellstudien
Anforderungen der Mission:
Erstellen Sie eine ca. 5.000 Wörter umfassende Forschungsarbeit zum Thema KI-Modellierung auf der Grundlage der folgenden Gliederung:
- Überblick über aktuelle große Sprachmodelle (z. B. GPT-Familie, Claude, LLaMA, DeepSeek, usw.)
- Vergleich der Merkmale und Anwendungsszenarien der einzelnen Modelle
- Analyse der Grenzen und Beschränkungen der Modellfähigkeit
- Strategien zur Auswahl von Modellen mit offener oder geschlossener Quelle
- Modell-API-Grundlagen Tutorial
- Eine kurze Erläuterung der Grundsätze der Big Model-Technologie
Umsetzung:
- Gemini Deep Search: Dauert 8 Minuten, um über 300 Webseiten zu durchsuchen.
- Grok 3 Deep Search: Es dauerte 6 Minuten, um über 160 Webseiten zu durchsuchen.
- Manus: Dauerte 21 Minuten und meldete 8 durchgeführte Teilaufgaben.
- Mita AI Shallow Research: 7 Minuten für die Suche auf über 300 Webseiten.
- Zhipu AutoGLM: Es dauerte 16 Minuten, um 71 Webseiten zu durchsuchen.
Anmerkungen: Die Wartezeit und das Suchvolumen sind nur Referenzdaten für diesen Test, und die tatsächliche Leistung kann je nach Aufgabenkomplexität, Netzwerkbedingungen und Serverlast variieren.
Zusammenfassung der Antworten für jedes Instrument:

(Die Bilder zeigen einige der Screenshots oder Zusammenfassungen der von den einzelnen Tools erstellten Berichte)
Unabhängige Bewertung: scharfe Überprüfung durch Claude 3.7
Um eine relativ objektive Sichtweise Dritter zu erhalten, haben wir die fünf erstellten Berichte dem Modell Claude 3.7 von Anthropic zur Bewertung vorgelegt. Im Folgenden finden Sie eine Zusammenfassung der Bewertung der einzelnen Berichte durch Claude 3.7:
Zhipu AutoGLM
Der Bericht versucht, das Format einer akademischen Arbeit zu imitieren, indem er 71 Referenzen anführt, aber das ist ziemlich leer. Die Sprache ist übermäßig akademisch, als ob der Bericht mit Rhetorik den Mangel an Substanz überdecken wollte. Die Analyse der Stärken und Schwächen des Modells gleicht der Wiederholung einer Produktbeschreibung und lässt einen tiefen Einblick vermissen.
Manus
Der Bericht geht ins andere Extrem, indem er komplexe technische Sachverhalte im Namen der "politischen Entscheidungsträger" zu stark vereinfacht und eingehende Analysen in oberflächliche Marketingtexte verwandelt. Wie ein Kinderbuch über Quantenphysik ist er weder tiefgründig noch genau.
Gemini Deep Search
Der Bericht ist in einem akademischen Stil verfasst, aber die vielen Anführungszeichen stören den Lesefluss. Er ist langatmig und nimmt zu viel Platz in Anspruch, um einfache Konzepte zu erklären, ohne wesentliche Informationen hinzuzufügen. Der Bericht gibt zwar vor, sich an Nichtfachleute zu richten, ist aber dennoch voller unerklärlicher Fachausdrücke und verfehlt seine Ziele.
Grok 3 Tiefensuche
Die Tatsache, dass sowohl eine Kurz- als auch eine ausführliche Fassung zur Verfügung stehen, ist ein Vorteil, bringt aber auch Probleme hinsichtlich der inhaltlichen Konsistenz mit sich. Die Kurzfassung ist zu stark vereinfacht, und einige der Projektionen in der ausführlichen Fassung (z. B. für 2025) sind etwas spekulativ, da ihnen eine ausreichende Argumentationsgrundlage und die notwendigen Annahmen fehlen.
Mita AI Shallow Research
Die umfangreiche Verwendung von Tabellen zur Strukturierung der Informationen verbessert die Effizienz der Informationsbeschaffung, aber der übermäßige Rückgriff auf Tabellen und Abgrenzungen führt zu einer mechanisierten Darstellung der Inhalte, der es an erzählerischer Kohärenz und Tiefe fehlt. Die technischen Erklärungen sind nicht ausreichend mit praktischen Anwendungsszenarien verknüpft, und den betriebswirtschaftlichen Kostenanalysen mangelt es an differenzierten Betrachtungen für Unternehmen unterschiedlicher Größe, so dass die Empfehlungen als "one-size-fits-all" erscheinen.
Allgemeine Bemerkungen zu Claude 3.7:
Diese fünf Berichte versuchen alle, die inhaltlichen Mängel durch eine andere "Verpackung" zu überdecken. Unabhängig davon, ob es sich um akademische, kommerzielle oder technische Berichte handelt, scheinen sie den Kern nicht zu berühren - ein tiefgreifendes Verständnis des Wesens der Technologie und tiefgreifende Überlegungen zu praktischen Anwendungen. So heißt es in dem Bericht zum Beispiel DeepSeek Die übermäßige Aufmerksamkeit mag das allgemeine Streben der Branche nach neuen Technologien widerspiegeln, während die Verharmlosung von Schlüsselthemen wie Datenschutz und Einhaltung ethischer Grundsätze die Grenzen der analytischen Perspektive offenbart. Ein guter Technologieforschungsbericht sollte Erkenntnisse und pragmatische Analysen liefern, keine Wortspiele. Nach diesem Maßstab sind alle fünf Berichte verbesserungswürdig.
Gesamtleistung und Punktevergabe
Auf der Grundlage der Auswertung von Klausel 3.7 und einer direkten Durchsicht des Berichtsinhalts ist es möglich, eine umfassende Bewertung der Leistung der Werkzeuge in diesem Test vorzunehmen:
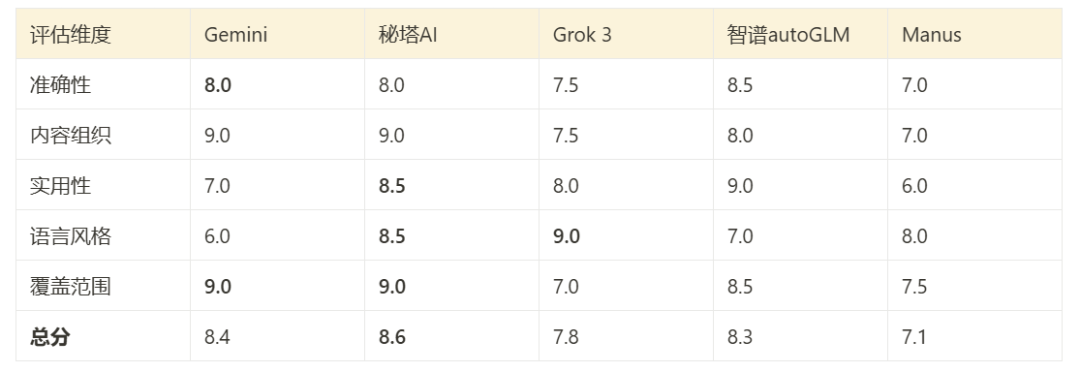
(Die Abbildung zeigt eine umfassende Punktetabelle auf der Grundlage der Testergebnisse)
- Gemini Deep SearchBessere Organisation des Inhalts, große Reichweite und mehrsprachige Unterstützung sind seine Stärken.
- Mita AI Shallow ResearchDie Leistung ist umfassend und ausgewogen, mit einer guten Kombination aus technischer Tiefe und Lesbarkeit.
- Grok 3 Tiefensuche: Flexibler Sprachstil (duale Version) und starke pragmatische Orientierung.
- Zhipu AutoGLMTechnischer Inhalt: Der technische Inhalt ist sehr genau, aber die Lesbarkeit ist für Nicht-Fachleute begrenzt.
- ManusDer Bericht ist prägnant und leicht verständlich, allerdings auf Kosten der Tiefe der Analyse.
Auswahl: Vorschläge für den Einsatz in verschiedenen Szenarien
Auf der Grundlage dieses Tests und der Merkmale der einzelnen Werkzeuge werden im Folgenden einige Vorschläge für die Auswahl gemacht:
Überblick über die Suchfunktionen:
- Gemini Deep SearchSuche: Die Suche ist breit gefächert und kann globale mehrsprachige Ressourcen integrieren, ist aber möglicherweise nicht so gut wie lokalisierte Produkte, wenn es darum geht, chinesische Inhalte in der Tiefe zu verstehen.
- Grok 3 TiefensucheHochgradig echtzeitorientiert, insbesondere bei Wirtschaftsinformationen und Nachrichten, aber mit relativ geringer Tiefe der technischen Inhalte.
- Zhipu AutoGLMZitierte Referenzen sind von hoher Qualität, mit tiefem Verständnis der technischen Konzepte, aber die Suche ist relativ fokussiert.
- Mita AI Shallow ResearchStarke Integration von Informationen in Englisch und Chinesisch, umfassendere Abdeckung von Fachgebieten und genaue Extraktion von strukturierten Informationen.
- Manus(Dieser Test konzentrierte sich auf die Erstellung von Berichten und die Suchfunktionen wurden nicht in vollem Umfang demonstriert, aber die Plattform ist so konzipiert, dass sie die Integration von Informationen aus verschiedenen Quellen und komplexen Arbeitsabläufen unterstützt).
Vorläufige Einstufung der Such- und Recherchefähigkeiten (basierend auf diesem Test):
- Mita AI Shallow ResearchHerausragende Leistungen bei der Tiefensuche in Spezialgebieten, zweisprachige Verarbeitung in Englisch und Chinesisch.
- Gemini Deep SearchDie vielseitigste und umfangreichste Abdeckung der globalen Ressourcen.
- Zhipu AutoGLMVorteile im Umgang mit chinesischer Fachliteratur und tiefes Verständnis.
- Grok 3 TiefensucheFührend beim Zugang zu Geschäftsinformationen und Nachrichten in Echtzeit.
- ManusDie Stärken liegen eher in der Flexibilität der Aufgabenausführung und den Aufrufen mehrerer Modelle als in der reinen Suchreihenfolge.
Szenariobasierte Empfehlungen:
- akademische ForschungPriorität wurde Zhipu AutoGLM (hohe Qualität der Referenzen) eingeräumt, gefolgt von Mita AI (Abdeckung spezieller Bereiche).
- UnternehmensanalysePriorität hatte Grok 3 (Echtzeit-Geschäftsinformationen), gefolgt von Gemini (globale Vision).
- TechnologieentwicklungPriorität hat Mita AI (Dokumentverständnis, strukturierte Extraktion), gefolgt von Zhipu AutoGLM (technische Tiefe).
- Täglicher Informationszugang/allgemeine RecherchePriorität hat Gemini (breite Abdeckung), gefolgt von Grok 3 (Aktualität).
- Eingehende Recherche zu chinesischen InhaltenPriorität haben Zhipu AutoGLM oder Mita AI, die ein besseres Verständnis der Muttersprache und des Kontextes haben.
Wichtiger Hinweis:
- KreuzvalidierungFür kritische Informationen oder wichtige Entscheidungen wird eine vergleichende Validierung mit mindestens zwei verschiedenen Instrumenten dringend empfohlen, um die Genauigkeit und Vollständigkeit der Informationen zu gewährleisten.
- AufgabenübereinstimmungEs gibt kein Patentrezept für alle. Welches Produkt zu wählen ist, hängt in hohem Maße von der spezifischen Rechercheaufgabe, der Art der benötigten Informationen (Echtzeit vs. detailliert, technisch vs. kommerziell) und den Anforderungen an das Format und die Tiefe des Berichts ab.
- Einschränkungen des TestsDieser Vergleich bezieht sich nur auf eine einzige Aufgabe. Wie Manus Die Vorteile eines solchen Werkzeugs, bei dem der Schwerpunkt auf dem Aufgabenfluss und der Fähigkeit zur Bereitstellung mehrerer Formate liegt, werden möglicherweise erst dann voll erkannt, wenn andere Arten von Aufgaben durchgeführt werden. Darüber hinaus sind auch die Benutzeroberfläche, die Kosten und die API-Integrationsfähigkeiten Faktoren, die bei der tatsächlichen Auswahl zu berücksichtigen sind.
Diese KI-Forschungsassistenten stellen zweifellos zukünftige Trends in der Art und Weise dar, wie auf Informationen zugegriffen und diese analysiert werden. Auch wenn jedes von ihnen derzeit seine eigenen Stärken und Schwächen hat, entwickeln sie sich in rasantem Tempo weiter und verdienen weitere Aufmerksamkeit. Die Wahl der richtigen Tools und das Erlernen ihrer effektiven Nutzung wird die Forschung und Entscheidungsfindung erheblich verbessern.
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel




Keine Kommentare...