Documentação inteligente: criação eficiente de documentos de licitação com o Dify Chatflow
Leitura e escrita de banco de dados interativo em linguagem natural
Perto do final do ano, a temporada de licitações está chegando novamente, e a preparação de documentos grandes, como os documentos de licitação, costuma ser uma dor de cabeça.
Não só precisamos garantir que o conteúdo seja preciso e profissional, mas também precisamos destacar os pontos fortes da empresa, testando tanto o conhecimento profissional quanto as habilidades de redação. Mesmo que ambos ainda precisem gastar muito tempo e energia para escrever palavra por palavra, a carga de trabalho é enorme e a dificuldade é bastante alta.

Portanto, este é baseado em Dify O fluxo de trabalho inteligente de preparação de documentos da estrutura tornou-se uma solução eficiente, cujo núcleo é usar o Dify-Chatflow para realizar operações de leitura/gravação no banco de dados orientadas por linguagem natural, que podem ler automaticamente o documento original, modificar ou gravar novo conteúdo de acordo com as necessidades do usuário e, ao mesmo tempo, gerar automaticamente uma visão geral do documento e destilar os pontos principais e, finalmente, concluir a preservação.

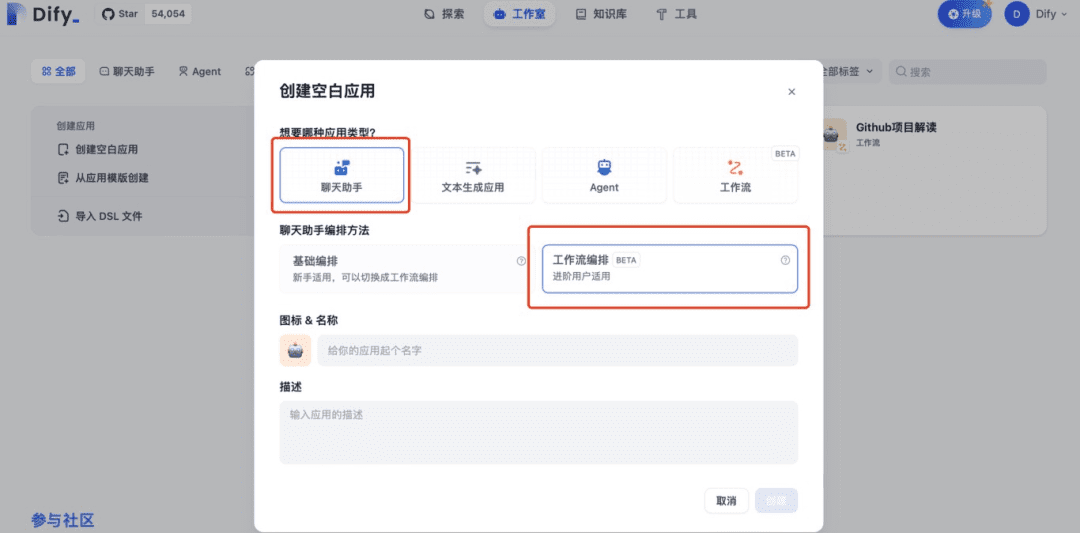
Esse fluxo de trabalho usa o padrão de orquestração de fluxo de trabalho do Chat Assistant da dify, também chamado de Chatflow.
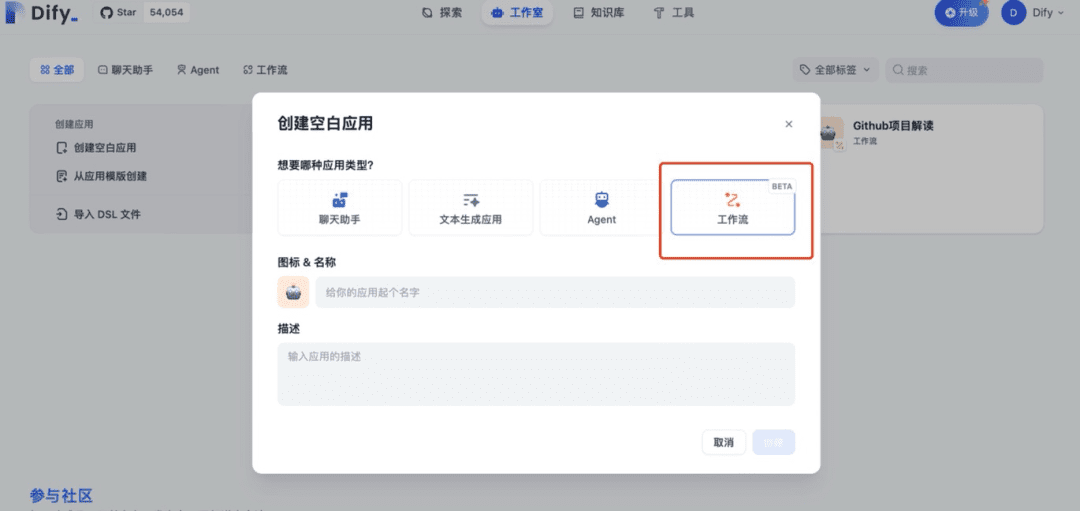
Fluxo de bate-papo VS Fluxo de trabalho
Cenários de aplicativos do Chatflow:
Orientado para cenários do tipo diálogo, incluindo atendimento ao cliente, pesquisa semântica e outros aplicativos de conversação que exigem lógica de várias etapas na construção de respostas. Esse tipo de aplicativo se distingue por seu suporte a várias rodadas de interações de diálogo para ajustar os resultados gerados.
Caminhos comuns de interação: dar instruções → gerar conteúdo → várias discussões sobre o conteúdo → gerar novamente o resultado → fim
Cenários de aplicativos de fluxo de trabalho:
Orientado para cenários de automação e processamento em lote, adequado para aplicativos como tradução de alta qualidade, análise de dados, geração de conteúdo, automação de e-mail etc. Esse tipo de aplicativo não permite várias rodadas de interação de diálogo com os resultados gerados.
Caminhos comuns de interação: dar comando → gerar conteúdo → finalizar
Lógica de implementação do Chatflow de documentação inteligente
Etapa 1
Dividimos documentos grandes em vários blocos de texto. Por exemplo, os conteúdos comuns de um documento de licitação: perfil da empresa, medidas de garantia de qualidade, recursos de desenvolvimento técnico, garantia de serviço pós-venda, etc., são divididos em blocos de texto separados.
Etapa 2
Armazene esses blocos de texto em um banco de dados. O principal motivo para escolher o armazenamento em banco de dados em vez de arquivos locais é que os bancos de dados são fáceis de compartilhar e a estruturação do conteúdo do documento facilita o pós-processamento e a resposta a diversos cenários de demanda. Nossa tabela de dados inclui campos como ID, título, categoria, visão geral, pontos-chave, conteúdo e tempo de gravação, sendo que a visão geral e os pontos-chave são gerados automaticamente pelo big model com base no conteúdo modificado. A visão geral fornece um resumo de alto nível do conteúdo, enquanto os pontos-chave são resumos detalhados, que podem ser facilmente usados para a produção subsequente de PPTs e assim por diante.
Etapa 3
Com o aplicativo de criação Chatflow da Dify, os usuários podem concluir duas tarefas por meio da interação de linguagem natural: uma é modificar e melhorar os blocos de documentos existentes e a outra é escrever um conteúdo totalmente novo. Após a conclusão da tarefa, o conteúdo modificado e o novo são automaticamente enviados ao banco de dados por meio de linguagem natural para atualização e salvamento.
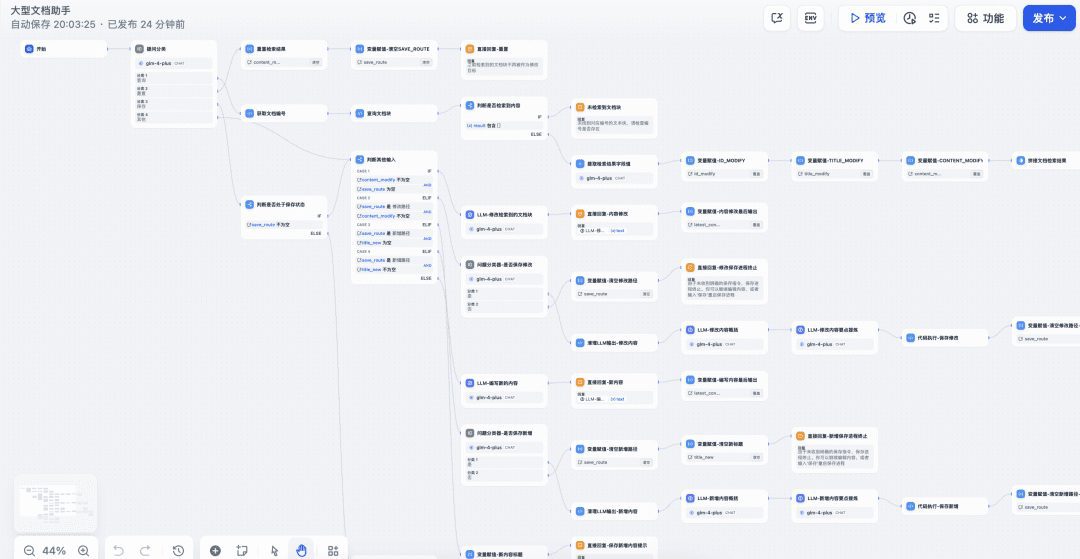
Como todo o nó do Chatflow é complexo e numeroso, darei uma breve visão geral do todo.
Tarefa 1: Modificar e aprimorar os blocos de documentação existentes
- Ramificação de consulta de documentos:
- O usuário inicia a solicitação de consulta inserindo uma ID de bloco de texto (por exemplo, número do poço + número).
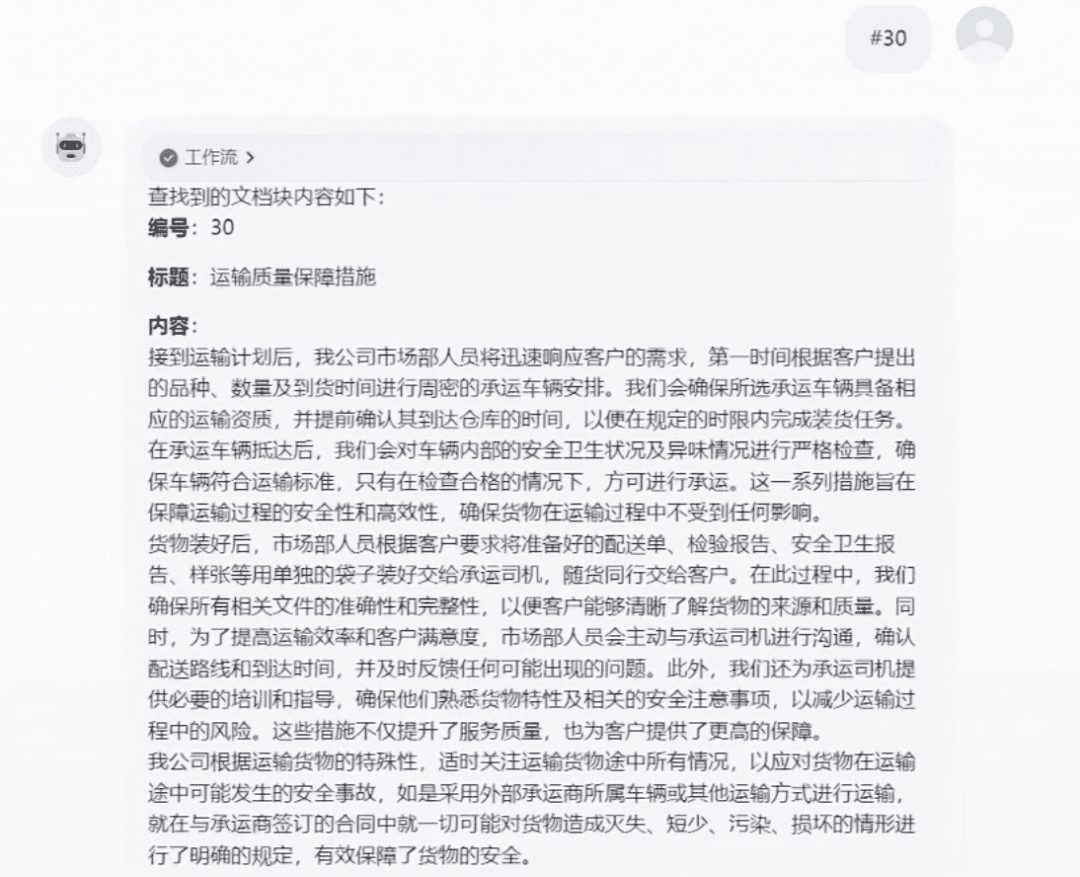
- A ramificação de consulta recupera o bloco de documentos correspondente do banco de dados, extrai e exibe o ID, o título e o conteúdo.
- Os resultados da consulta são processados pelo nó de execução de código e determinam se existe um bloco de documentos válido.

- Ramo de modificação do documento:
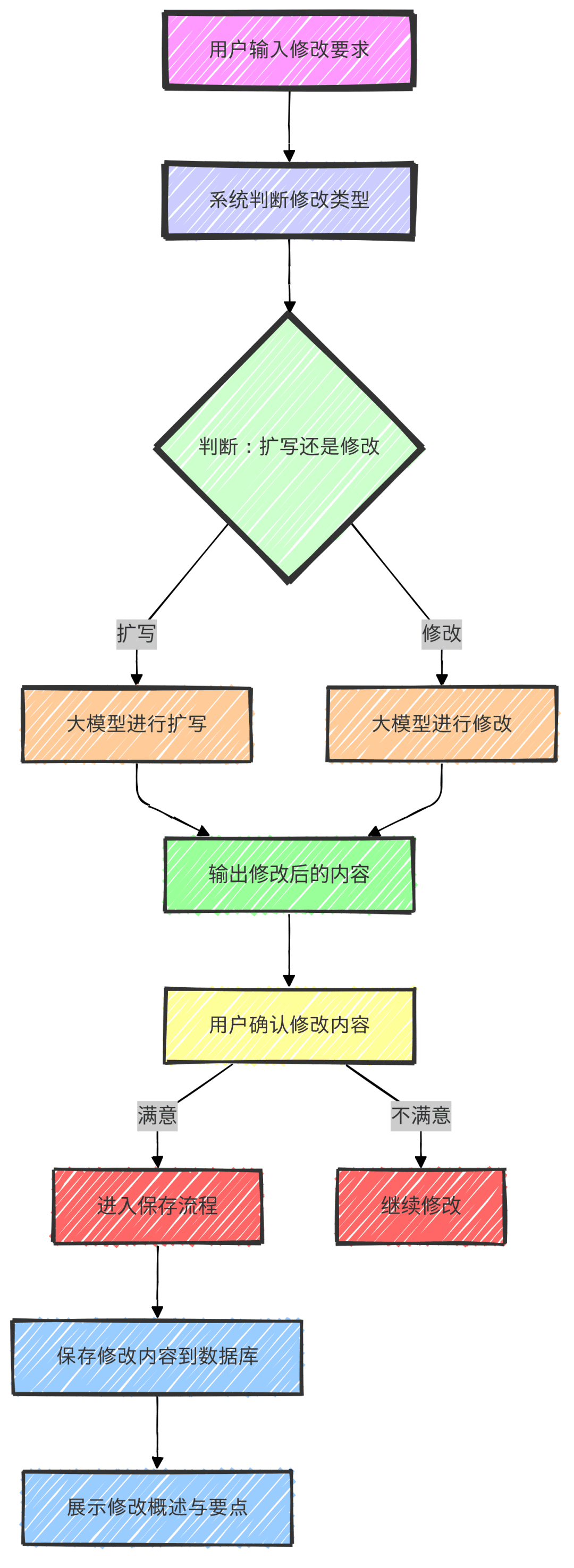
- Depois que o usuário insere uma solicitação de modificação, o sistema determina se deve expandir ou modificar o bloco de documentos com base no conteúdo.
- Na ramificação modify (modificar), o big model modificará o documento consultado de acordo com os requisitos do usuário, e o conteúdo modificado será gerado em formato de bloco de código para facilitar a cópia.
- O usuário confirma o conteúdo modificado e, se estiver satisfeito, pode entrar no processo de salvamento; se não estiver satisfeito, continua a modificar.
- Depois que o usuário confirmar o salvamento das modificações, o sistema salvará o texto modificado no banco de dados e exibirá uma visão geral e os pontos principais das modificações.

Tarefa II: Preparação de conteúdo totalmente novo
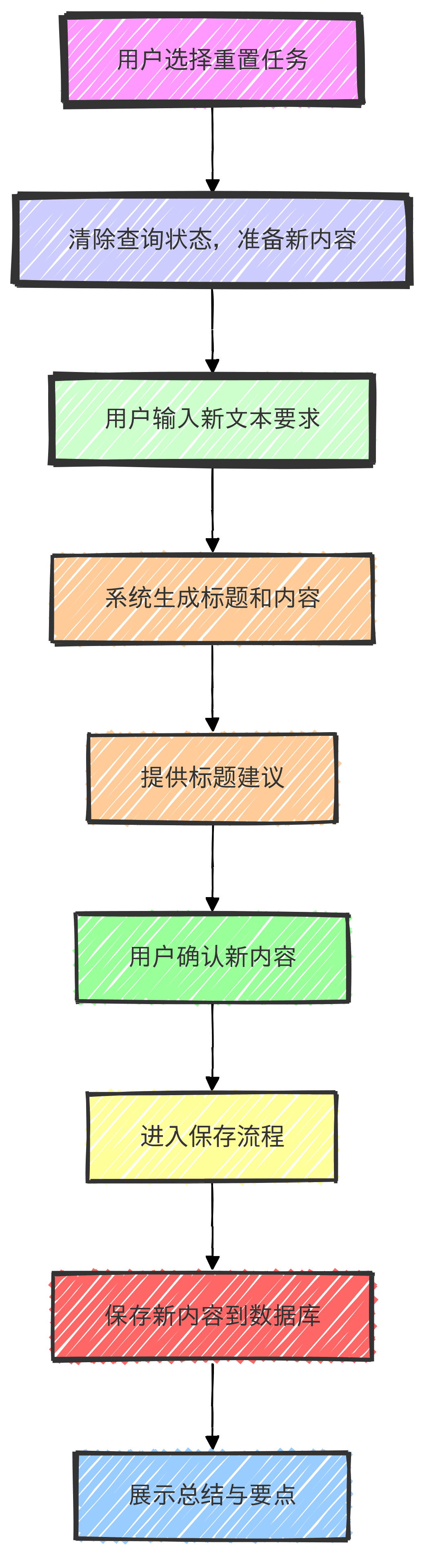
- Reiniciar ramificação da tarefa: se o usuário optar por reiniciar, o sistema limpará o status dos documentos consultados anteriormente em preparação para a gravação de novo conteúdo.
- Compor um novo ramo de conteúdo: o usuário insere um novo bloco de solicitação de texto e o sistema compõe de acordo com a nova tarefa, gerando títulos e conteúdo.
- Nova ramificação de dicas de títulos de conteúdo: fornece aos usuários novas sugestões de títulos para ajudá-los a organizar e editar melhor seu conteúdo.
- Confirmação da ramificação de salvamento: o usuário confirma o novo conteúdo escrito e, por fim, entra no processo de salvamento.
- Enviar salvar ramificação: o novo conteúdo é salvo no banco de dados e um resumo e os pontos principais são exibidos.
Descrição das principais funções e nós
- Nó classificador: classifica as entradas do usuário e identifica a necessidade de consulta, modificação e salvamento.
- Nós de ramificação condicional: determinam a direção do fluxo de trabalho com base em diferentes situações (por exemplo, se o conteúdo está vazio ou não).
- Nó de execução de código: realiza consultas a bancos de dados, processamento de texto e outras operações.
- Nó de modelo grande: responsável pela geração ou modificação de texto para fornecer saída de acordo com os requisitos do usuário.
- Nó de resposta direta: mostra o resultado ou solicita ao usuário uma ação.
- Nó de atribuição de variáveis: gerencia as variáveis na sessão para garantir que a lógica do processo seja tranquila.
 Acima estão o processo geral e os principais nós funcionais da Tarefa 1 e da Tarefa 2. Por meio de um projeto claro, o sistema pode responder com flexibilidade às necessidades do usuário e garantir a consulta, a modificação e a criação de documentos sem problemas.
Acima estão o processo geral e os principais nós funcionais da Tarefa 1 e da Tarefa 2. Por meio de um projeto claro, o sistema pode responder com flexibilidade às necessidades do usuário e garantir a consulta, a modificação e a criação de documentos sem problemas.
© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Artigos relacionados



Nenhum comentário...