
Intelligent Agentic Retrieval Enhanced Generation: uma visão geral da tecnologia Agentic RAG
resumos
Os modelos de linguagem ampla (LLMs), como o GPT-4 da OpenAI, o PaLM do Google e o LLaMA da Meta, mudaram radicalmente a inteligência artificial (IA) ao possibilitar a geração de textos semelhantes aos humanos e a compreensão da linguagem natural. No entanto, sua dependência de dados de treinamento estáticos limita sua capacidade de responder a consultas dinâmicas e em tempo real, resultando em resultados desatualizados ou imprecisos. O Retrieval Augmented Generation (RAG) surgiu como uma solução para aumentar os LLMs, integrando a recuperação de dados em tempo real para fornecer respostas contextualmente relevantes e oportunas. Apesar da promessa da RAG, os sistemas RAG tradicionais são limitados em termos de fluxos de trabalho estáticos e não têm a flexibilidade necessária para acomodar o raciocínio em várias etapas e o gerenciamento de tarefas complexas.
O Agentic Retrieval Augmented Generation (Agentic RAG) supera essas limitações ao incorporar agentes autônomos de IA ao processo RAG. Esses agentes utilizam padrões de design agêntico - reflexão, planejamento, uso de ferramentas e colaboração entre vários agentes - para gerenciar dinamicamente estratégias de recuperação, refinar iterativamente a compreensão contextual e adaptar fluxos de trabalho para atender aos requisitos de tarefas complexas. Essa integração permite que o sistema Agentic RAG ofereça flexibilidade, escalabilidade e conscientização do contexto incomparáveis em uma ampla variedade de aplicativos.
Esta análise explora de forma abrangente o Agentic RAG, começando com seus princípios subjacentes e a evolução do paradigma RAG. Ela detalha a categorização das arquiteturas Agentic RAG, destaca suas principais aplicações em setores como saúde, finanças e educação e explora estratégias práticas de implementação. Além disso, discute os desafios de dimensionar esses sistemas, garantindo a tomada de decisões éticas e otimizando o desempenho de aplicativos do mundo real, ao mesmo tempo em que fornece insights detalhados sobre estruturas e ferramentas para implementar o Agentic RAG.
Palavras-chave. Modelos de linguagem grandes (LLMs) - Inteligência artificial (IA) - Compreensão de linguagem natural - Geração aumentada de recuperação (RAG) - RAG autêntico - Agentes autônomos de IA - Reflexão - Planejamento - Uso de ferramentas - Colaboração de vários agentes - Padrões autênticos - Compreensão contextual - Adaptação dinâmica - Escalabilidade - Recuperação de dados em tempo real - Classificação RAG autêntica - Aplicativos de saúde - Aplicativos financeiros - Aplicativos educacionais -. Tomada de decisões éticas com IA - Otimização de desempenho - Raciocínio em várias etapas
1 Introdução
Os modelos de linguagem ampla (LLMs) [1, 2] [3], como o GPT-4 da OpenAI, o PaLM do Google e o LLaMA da Meta, mudaram radicalmente a Inteligência Artificial (IA) ao gerar textos semelhantes aos humanos e realizar tarefas complexas de processamento de linguagem natural. Esses modelos impulsionaram a inovação no campo do diálogo [4], incluindo agentes de conversação, criação automatizada de conteúdo e tradução em tempo real. Avanços recentes ampliaram seus recursos para tarefas multimodais, como a geração de texto para imagem e texto para vídeo [5], permitindo a criação e a edição de vídeos e imagens com base em prompts detalhados [6], o que amplia a gama de possíveis aplicações da IA generativa.
Apesar desses avanços, os LLMs ainda enfrentam limitações significativas devido à sua dependência de dados estáticos de pré-treinamento. Essa dependência geralmente leva a informações desatualizadas, respostas fantasmas [7] e à incapacidade de se adaptar a cenários dinâmicos do mundo real. Esses desafios enfatizam a necessidade de sistemas que possam integrar dados em tempo real e refinar dinamicamente as respostas para manter a relevância e a precisão do contexto.
A Geração Aumentada de Recuperação (RAG) [8, 9] surgiu como uma solução promissora para esses desafios. A RAG aumenta a relevância e a pontualidade das respostas combinando os recursos de geração dos LLMs com mecanismos externos de recuperação [10]. Esses sistemas recuperam informações em tempo real de fontes como bases de conhecimento [11], APIs ou da Web, preenchendo efetivamente a lacuna entre os dados de treinamento estáticos e os requisitos dinâmicos dos aplicativos. No entanto, os fluxos de trabalho RAG tradicionais ainda são restringidos por seu design linear e estático, o que limita sua capacidade de realizar raciocínios complexos em várias etapas, integrar uma compreensão contextual profunda e refinar as respostas de forma iterativa.
A evolução dos agentes [12] aprimorou ainda mais os recursos dos sistemas de IA. Os agentes modernos, inclusive os agentes móveis e baseados em LLM [13], são entidades inteligentes capazes de perceber, raciocinar e executar tarefas de forma autônoma. Esses agentes utilizam padrões de fluxo de trabalho baseados em agentes, como reflexão [14], planejamento [15], uso de ferramentas e colaboração entre vários agentes [16], o que lhes permite gerenciar fluxos de trabalho dinâmicos e resolver problemas complexos.
A convergência do RAG e da inteligência agêntica deu origem ao Agentic Retrieval Augmented Generation (Agentic RAG) [17], um paradigma que integra agentes ao processo de RAG. O Agentic RAG implementa estratégias de recuperação dinâmica, compreensão contextual e refinamento iterativo [18], permitindo o processamento adaptativo e eficiente de informações. Diferentemente do RAG tradicional, o Agentic RAG emprega agentes autônomos para orquestrar a recuperação, filtrar informações relevantes e refinar as respostas, e se destaca em cenários que exigem precisão e adaptabilidade.
Esta análise explora os princípios subjacentes, a classificação e os aplicativos do Agentic RAG. Ela oferece uma visão geral abrangente dos paradigmas RAG, como Simple RAG, Modular RAG e Graph RAG [19] e sua evolução para sistemas Agentic RAG. As principais contribuições incluem uma classificação detalhada das estruturas Agentic RAG, aplicações em domínios como saúde [20, 21], finanças e educação [22] e percepções sobre estratégias de implementação, benchmarking e considerações éticas.
O artigo está estruturado da seguinte forma: a seção 2 apresenta o RAG e sua evolução, enfatizando as limitações das abordagens tradicionais. A seção 3 detalha os princípios da inteligência agêntica e dos modelos agênticos. A Seção 4 apresenta uma classificação dos sistemas Agentic RAG, incluindo estruturas de agente único, multiagente e baseadas em gráficos. A Seção 5 examina as aplicações do Agentic RAG, enquanto a Seção 6 discute as ferramentas e estruturas de implementação. A Seção 7 concentra-se em benchmarks e conjuntos de dados, e a Seção 8 conclui com orientações futuras para os sistemas Agentic RAG.
2 Base para a geração de aprimoramentos de recuperação
2.1 Visão geral do Retrieval Augmented Generation (RAG)
A geração aumentada por recuperação (RAG) representa um grande avanço no campo da inteligência artificial, combinando o poder de geração dos modelos de linguagem ampla (LLMs) com a recuperação de dados em tempo real. Embora os LLMs tenham demonstrado recursos excepcionais no processamento de linguagem natural, sua dependência de dados estáticos de pré-treinamento geralmente resulta em respostas desatualizadas ou incompletas. O RAG aborda essa limitação recuperando dinamicamente informações relevantes de fontes externas e incorporando-as ao processo de geração, permitindo a geração de resultados contextualmente precisos e responsivos em tempo hábil.
2.2 Componentes principais do RAG
A arquitetura do sistema RAG integra três componentes principais (consulte a Figura 1):
- recuperar (dados)Recuperação de dados: responsável por consultar fontes de dados externas, como bases de conhecimento, APIs ou bancos de dados vetoriais. Os recuperadores avançados utilizam pesquisa vetorial densa e modelos baseados em transformadores para melhorar a precisão da recuperação e a relevância semântica.
- reforçarProcessamento: processa os dados recuperados para extrair e resumir as informações mais relevantes para o contexto da consulta.
- gerandoCombinar as informações recuperadas com o conhecimento pré-treinado do LLM para gerar respostas coerentes e contextualmente apropriadas.

Figura 1: Componentes principais do RAG
2.3 Evolução do paradigma RAG
O campo da Geração Aumentada de Recuperação (RAG) fez avanços significativos para lidar com a crescente complexidade dos aplicativos do mundo real, em que a precisão contextual, a escalabilidade e o raciocínio em várias etapas são essenciais. A partir da recuperação simples baseada em palavras-chave, ela se transformou em sistemas complexos, modulares e adaptáveis, capazes de integrar várias fontes de dados e processos autônomos de tomada de decisão. Essa evolução destaca a necessidade crescente de sistemas RAG para lidar com consultas complexas de forma eficiente e eficaz.
Esta seção examina a evolução do paradigma RAG, descrevendo os principais estágios de desenvolvimento - RAG simples, RAG avançado, RAG modular, RAG gráfico e RAG baseado em agente - bem como suas características definidoras, pontos fortes e limitações. Ao entender a evolução desses paradigmas, o leitor pode apreciar os avanços feitos nos recursos de recuperação e geração, bem como suas aplicações em vários domínios.
2.3.1 RAG simples
O RAG simples [23] representa a implementação básica da geração aprimorada por recuperação. A Figura 2 ilustra RAGs simples para fluxos de trabalho simples de leitura de recuperação, com foco em recuperação baseada em palavras-chave e conjuntos de dados estáticos. Esses sistemas dependem de técnicas simples de recuperação baseadas em palavras-chave, como TF-IDF e BM25, para recuperar documentos de conjuntos de dados estáticos. Os documentos recuperados são então usados para aprimorar a geração de modelos de linguagem.

Figura 2: Visão geral do Naive RAG.
O RAG simples é caracterizado por sua simplicidade e facilidade de implementação e é adequado para tarefas que envolvem consultas baseadas em fatos com complexidade contextual mínima. Entretanto, ele tem várias limitações:
- Falta de consciência contextualDocumentos recuperados geralmente não capturam as nuances semânticas de uma consulta porque dependem da correspondência lexical em vez da compreensão semântica.
- Fragmentação de saídaA falta de pré-processamento avançado ou de integração contextual geralmente leva a respostas incoerentes ou excessivamente genéricas.
- problema de escalabilidadeAs técnicas de recuperação baseadas em palavras-chave tendem a ter um desempenho ruim ao lidar com grandes conjuntos de dados e geralmente não conseguem identificar as informações mais relevantes.
Apesar dessas limitações, o sistema RAG simples fornece uma prova de conceito fundamental para combinar recuperação com geração, estabelecendo as bases para paradigmas mais complexos.
2.3.2 RAG avançado
Os sistemas RAG avançados [23] se baseiam nas limitações do RAG simples, integrando a compreensão semântica e técnicas de recuperação aprimoradas. A Figura 3 destaca o aprimoramento semântico e o processo iterativo e sensível ao contexto do RAG avançado na recuperação. Esses sistemas utilizam modelos de recuperação densos, como o Dense Paragraph Retrieval (DPR) e algoritmos de classificação neural para melhorar a precisão da recuperação.

Figura 3: Visão geral do RAG avançado
Os principais recursos do Advanced RAG incluem:
- Pesquisa de vetor densoConsulta: As consultas e os documentos são representados em um espaço vetorial de alto nível, resultando em um melhor alinhamento semântico entre as consultas do usuário e os documentos recuperados.
- reordenação de contextoO modelo neural reordena os documentos recuperados para priorizar as informações contextualmente mais relevantes.
- Pesquisa iterativaRAG Avançado: O RAG Avançado apresenta um mecanismo de recuperação multihop que permite o raciocínio sobre consultas complexas em vários documentos.
Esses avanços tornam o RAG avançado adequado para aplicativos que exigem alta precisão e compreensão diferenciada, como síntese de pesquisa e recomendações personalizadas. No entanto, os problemas de sobrecarga computacional e escalabilidade limitada permanecem, especialmente ao lidar com grandes conjuntos de dados ou consultas em várias etapas.
2.3.3 RAG modular
Os RAGs modulares [23] representam o desenvolvimento mais recente do paradigma RAG, com ênfase na flexibilidade e na personalização. Esses sistemas decompõem os processos de recuperação e geração em componentes separados e reutilizáveis para permitir a otimização específica do domínio e a adaptabilidade da tarefa. A Figura 4 ilustra a arquitetura modular, mostrando estratégias de recuperação híbridas, processos compostáveis e integração de ferramentas externas.
As principais inovações do RAG modular incluem:
- estratégia de pesquisa híbridaCombinação de métodos de recuperação esparsos (por exemplo, Sparse Encoder - BM25) e técnicas de recuperação densas (por exemplo, DPR - Dense Paragraph Retrieval) para maximizar a precisão de diferentes tipos de consulta.
- integração de ferramentasIntegração de APIs externas, bancos de dados ou ferramentas de computação para lidar com tarefas específicas, como análise de dados em tempo real ou cálculos específicos do domínio.
- Processos compostáveisRAG modular: o RAG modular permite que recuperadores, geradores e outros componentes sejam substituídos, aumentados ou reconfigurados, permitindo de forma independente um alto grau de adaptação a casos de uso específicos.
Por exemplo, um sistema RAG modular projetado para análise financeira pode recuperar preços de ações em tempo real por meio de uma API, analisar tendências históricas usando pesquisa intensiva e gerar percepções de investimento acionáveis por meio de um modelo de linguagem personalizado. Essa modularidade e personalização tornam o RAG modular adequado para tarefas complexas e de vários domínios, proporcionando escalabilidade e precisão.

Figura 4: Visão geral do RAG modular
2.3.4 Figura RAG
O Graph RAG [19] amplia os sistemas tradicionais de geração de aprimoramento de recuperação ao integrar estruturas de dados baseadas em gráficos, conforme mostrado na Figura 5. Esses sistemas utilizam relacionamentos e hierarquias em dados de gráficos para aprimorar o raciocínio multihop e o aprimoramento contextual. Ao integrar a recuperação baseada em gráficos, os RAGs de gráficos podem produzir resultados gerados mais ricos e mais precisos, especialmente para tarefas que exigem compreensão relacional.
A Figura RAG é caracterizada por sua capacidade de:
- conectividade de nósCaptura e raciocínio sobre relacionamentos entre entidades.
- Gerenciamento de conhecimento hierárquicoManipulação de dados estruturados e não estruturados por meio de hierarquias de gráficos.
- sensível ao contextoAdicionar compreensão relacional usando caminhos de gráficos.
No entanto, o gráfico RAG tem algumas limitações:
- Escalabilidade limitadaDependência da estrutura do gráfico pode limitar a escalabilidade, especialmente para uma ampla variedade de fontes de dados.
- Dependência de dadosDados gráficos de alta qualidade são essenciais para um resultado significativo, o que limita sua aplicação a conjuntos de dados não estruturados ou mal anotados.
- Complexidade da integraçãoDescrição: A integração de dados de gráficos com sistemas de recuperação não estruturados aumenta a complexidade do projeto e da implementação.
O Graph RAG é adequado para aplicações em áreas como diagnóstico médico e pesquisa jurídica, em que o raciocínio sobre relacionamentos estruturados é fundamental.

Figura 5: Visão geral do gráfico RAG
2.3.5 Proxy RAG
O RAG baseado em agentes representa uma mudança de paradigma ao introduzir agentes autônomos capazes de tomar decisões dinâmicas e otimizar o fluxo de trabalho. Diferentemente dos sistemas estáticos, os RAGs baseados em agentes empregam refinamento iterativo e estratégias de recuperação adaptáveis para lidar com consultas complexas, em tempo real e em vários domínios. Esse paradigma explora a modularidade do processo de recuperação e geração e, ao mesmo tempo, introduz a autonomia baseada em agentes.
Os principais recursos do RAG baseado em agentes incluem:
- autodeterminaçãoAgentes: avaliam e gerenciam de forma independente as estratégias de recuperação com base na complexidade da consulta.
- Refinamento iterativoIntegração de loops de feedback para melhorar a precisão da recuperação e a relevância da resposta.
- Otimização do fluxo de trabalhoProgramação dinâmica de tarefas para tornar os aplicativos em tempo real mais eficientes.
Apesar desses avanços, os RAGs baseados em agentes enfrentam uma série de desafios:
- Complexidade da coordenaçãoGerenciar interações entre agentes requer mecanismos de coordenação complexos.
- sobrecarga computacionalUso de vários agentes aumenta os requisitos de recursos para fluxos de trabalho complexos.
- restrições de escalabilidadeEmbora seja dimensionável, a natureza dinâmica do sistema pode pressionar os altos volumes de consulta.
Os RAGs baseados em agentes têm se destacado em aplicações em áreas como suporte ao cliente, análise financeira e plataformas de aprendizagem adaptativa, em que a adaptabilidade dinâmica e a precisão contextual são essenciais.
2.4 Desafios e limitações dos sistemas RAG tradicionais
Os sistemas tradicionais de Geração Aumentada de Recuperação (RAG) ampliaram muito os recursos dos modelos de linguagem grandes (LLMs) ao integrar a recuperação de dados em tempo real. No entanto, esses sistemas ainda enfrentam vários desafios importantes que impedem sua eficácia em aplicativos complexos do mundo real. As limitações mais notáveis estão centradas na integração do contexto, no raciocínio em várias etapas e nos problemas de escalabilidade e latência.
2.4.1 Integração contextual
Mesmo quando os sistemas RAG recuperam com sucesso as informações relevantes, eles geralmente têm dificuldades para integrá-las perfeitamente à resposta gerada. A natureza estática do processo de recuperação e a consciência limitada do contexto levam a resultados fragmentados, inconsistentes ou excessivamente genéricos.
EXEMPLO: uma consulta como "Avanços recentes na pesquisa da doença de Alzheimer e suas implicações para o tratamento precoce" pode gerar artigos científicos e diretrizes médicas relevantes. No entanto, os sistemas RAG tradicionais geralmente não conseguem sintetizar essas descobertas em explicações coerentes que vinculam novos tratamentos a cenários específicos de pacientes. Da mesma forma, para uma consulta como "Quais são as melhores práticas sustentáveis para a agricultura de pequena escala em regiões áridas?", um sistema convencional pode recuperar artigos sobre métodos agrícolas gerais, mas omitir práticas sustentáveis de importância crítica para ambientes áridos.
Tabela 1. Análise comparativa dos paradigmas RAG
| Paradigma | Principais recursos | Pontos fortes |
|---|---|---|
| RAG ingênuo | - Baseado em palavras-chave recuperação (por exemplo, TF-IDF. BM25) | - Simples e fácil de implementar - Adequado para consultas baseadas em fatos |
| RAG avançado | - Modelos de recuperação densos (por exemplo, DPR) - Classificação e reclassificação neural - Recuperação em vários locais | - Recuperação de alta precisão - Contexto aprimorado relevância |
| RAG modular | - Recuperação híbrida (esparsa e densa) - Integração de ferramentas e APIs - Pipelines compostáveis e específicos do domínio | - Alta flexibilidade e personalização - Adequado para diversos aplicativos - Escalável |
| Gráfico RAG | - Integração de estruturas baseadas em gráficos - Raciocínio de múltiplos saltos - Enriquecimento contextual por meio de nós | - Recursos de raciocínio relacional - Reduz as alucinações - Ideal para tarefas de dados estruturados |
| RAG autêntico | - Agentes autônomos - Tomada de decisão dinâmica - Refinamento iterativo e fluxo de trabalho otimização | - Adaptável a mudanças em tempo real - Escalável para tarefas de vários domínios - Alta precisão |
2.4.2 Raciocínio em várias etapas
Muitas consultas do mundo real exigem raciocínio iterativo ou de vários saltos, recuperando e sintetizando informações de várias etapas. Os sistemas RAG tradicionais geralmente não estão preparados para refinar a recuperação com base em percepções intermediárias ou feedback do usuário, o que resulta em respostas incompletas ou desarticuladas.
Exemplo: uma consulta complexa, como "Quais lições das políticas europeias de energia renovável podem ser aplicadas aos países em desenvolvimento e quais são os possíveis impactos econômicos?" Várias informações precisam ser conciliadas, incluindo dados de políticas, contextualização para regiões em desenvolvimento e análise econômica. Os sistemas RAG tradicionais geralmente não conseguem conectar esses elementos díspares em uma resposta coerente.
2.4.3 Problemas de escalabilidade e latência
À medida que o número de fontes de dados externas aumenta, a consulta e a classificação de grandes conjuntos de dados se tornam cada vez mais intensivas em termos de computação. Isso leva a uma latência significativa, o que prejudica a capacidade do sistema de fornecer respostas oportunas em aplicativos em tempo real.
Exemplo: em ambientes sensíveis ao tempo, como análise financeira ou suporte ao cliente em tempo real, os atrasos decorrentes da consulta a vários bancos de dados ou do trabalho com grandes conjuntos de documentos podem diminuir a utilidade geral do sistema. Por exemplo, atrasos na recuperação de tendências de mercado em negociações de alta frequência podem resultar na perda de oportunidades.
2.5 RAG baseado em agentes: uma mudança de paradigma
Os sistemas RAG tradicionais, com seus fluxos de trabalho estáticos e adaptabilidade limitada, muitas vezes têm dificuldades para lidar com o raciocínio dinâmico de várias etapas e com tarefas complexas do mundo real. Essas limitações levaram à integração da inteligência de agentes, resultando em RAGs baseados em agentes. Ao integrar agentes autônomos capazes de tomar decisões dinâmicas, raciocínio iterativo e estratégias de recuperação adaptáveis, os RAGs baseados em agentes superam suas limitações inerentes e mantêm a modularidade dos paradigmas anteriores. Essa evolução permite a solução de tarefas mais complexas e de vários domínios com maior precisão e compreensão contextual, posicionando os RAGs baseados em agentes como a base para a próxima geração de aplicativos de IA. Em especial, os sistemas RAG baseados em agentes reduzem a latência por meio de fluxos de trabalho otimizados e refinam os resultados de forma incremental, enfrentando desafios que há muito tempo impedem a escalabilidade e a eficácia dos RAGs tradicionais.
3 Princípios básicos e contexto da inteligência de agentes
A inteligência do agente forma a base dos sistemas RAG (Retrieval Augmented Generation) baseados em agentes, permitindo que eles ultrapassem a natureza estática e reativa do RAG tradicional. Ao integrar agentes autônomos capazes de tomar decisões dinâmicas, raciocínio iterativo e fluxos de trabalho colaborativos, os sistemas RAG baseados em agentes apresentam maior adaptabilidade e precisão. Esta seção explora os princípios fundamentais que sustentam a inteligência do agente.
Componentes de um agente de IA. Essencialmente, um agente de IA consiste em (veja a Figura 6):
- LLM (com funções e tarefas definidas)Mecanismo de raciocínio: serve como o principal mecanismo de raciocínio e interface de diálogo para o agente. Ele interpreta as consultas do usuário, gera respostas e mantém a coerência.
- Memória (curto e longo prazo)Memória de curto prazo [25]: Captura de contexto e dados relevantes durante uma interação. A memória de curto prazo [25] rastreia o estado imediato do diálogo, enquanto a memória de longo prazo [25] armazena o conhecimento acumulado e a experiência do agente.
- Planejamento (reflexão e autocrítica)Orientando o processo de raciocínio iterativo do agente por meio de reflexão, roteamento de consultas ou autocrítica [26], garante-se que tarefas complexas sejam efetivamente decompostas [15].
- Ferramentas (pesquisa vetorial, pesquisa na Web, APIs, etc.)Capacidade dos agentes de ir além da geração de texto para acessar recursos externos, dados em tempo real ou computação especializada: amplie a capacidade dos agentes de ir além da geração de texto para acessar recursos externos, dados em tempo real ou computação especializada.

Figura 6: Visão geral dos agentes de IA
3.1 Modelo de proxy
Os padrões de agentes [27, 28] oferecem maneiras estruturadas de orientar o comportamento dos agentes em sistemas RAG (Retrieval Augmented Generation) baseados em agentes. Esses padrões permitem que os agentes se adaptem, planejem e colaborem de forma dinâmica, garantindo que o sistema possa lidar com precisão e em escala com tarefas complexas do mundo real. Quatro padrões principais formam a base do fluxo de trabalho do agente:
3.1.1 Reflexão
A reflexão é um padrão de design fundamental no fluxo de trabalho do agente que permite que o agente avalie e refine iterativamente sua saída. Ao integrar um mecanismo de autofeedback, o agente pode identificar e resolver erros, inconsistências e áreas de aprimoramento, melhorando assim o desempenho de tarefas como geração de código, geração de texto e perguntas e respostas (conforme mostrado na Figura 7). Na prática, a reflexão envolve solicitar ao agente que critique seu resultado em termos de correção, estilo e eficiência e, em seguida, incorporar esse feedback nas iterações subsequentes. Ferramentas externas, como testes unitários ou pesquisas na Web, podem aprimorar ainda mais esse processo, validando os resultados e destacando as lacunas.

Figura 7: Visão geral do Agentic Self- Reflexão
Em sistemas com vários agentes, a reflexão pode envolver diferentes funções, por exemplo, um agente gera o resultado enquanto outro agente o critica, facilitando assim o aprimoramento colaborativo. Por exemplo, na pesquisa jurídica, os agentes podem refinar iterativamente as respostas para garantir a precisão e a abrangência, reavaliando a jurisprudência recuperada. A reflexão demonstrou ganhos significativos de desempenho em estudos como Self-Refine [29], Reflexion [30] e CRITIC [26].
3.1.2 Planejamento
O planejamento [15] é um padrão de design fundamental em fluxos de trabalho de agentes que permite que os agentes decomponham de forma autônoma tarefas complexas em subtarefas menores e mais gerenciáveis. Esse recurso é essencial para o raciocínio multihop e a solução iterativa de problemas em cenários dinâmicos e incertos (conforme mostrado na Figura 8).

Figura 8: Visão geral do planejamento agêntico
Ao utilizar o planejamento, os agentes podem determinar dinamicamente a sequência de etapas necessárias para atingir metas maiores. Essa adaptabilidade permite que os agentes lidem com tarefas que não podem ser predefinidas, garantindo flexibilidade na tomada de decisões. Embora poderoso, o planejamento pode produzir resultados menos previsíveis do que os fluxos de trabalho determinísticos, como a reflexão. O planejamento é particularmente adequado para tarefas que exigem adaptação dinâmica, em que os fluxos de trabalho predefinidos não são suficientes. À medida que a tecnologia amadurece, seu potencial para impulsionar aplicativos inovadores em vários domínios continuará a crescer.
3.1.3 Uso de ferramentas
O uso de ferramentas permite que os agentes ampliem seus recursos por meio da interação com ferramentas externas, APIs ou recursos computacionais, conforme mostrado na Figura 9. Esse modelo permite que o agente colete informações, execute cálculos e manipule dados além de seu conhecimento pré-treinado. Ao integrar dinamicamente as ferramentas ao fluxo de trabalho, os agentes podem se adaptar a tarefas complexas e fornecer resultados mais precisos e contextualmente relevantes.

Figura 9: Visão geral do uso de ferramentas
Os fluxos de trabalho de agentes modernos integram o uso de ferramentas em uma variedade de aplicativos, incluindo recuperação de informações, raciocínio computacional e interface com sistemas externos. A implementação desse modelo evoluiu significativamente com o desenvolvimento dos recursos de invocação de recursos do GPT-4 e dos sistemas capazes de gerenciar o acesso a várias ferramentas. Esses desenvolvimentos facilitaram fluxos de trabalho de agentes complexos, nos quais os agentes podem selecionar e executar de forma autônoma as ferramentas mais relevantes para uma determinada tarefa.
Embora o uso de ferramentas tenha aprimorado muito os fluxos de trabalho dos agentes, ainda há desafios para otimizar a seleção de ferramentas, especialmente quando há um grande número de opções disponíveis. Técnicas inspiradas na geração aprimorada por recuperação (RAG), como a seleção baseada em heurística, foram propostas para resolver esse problema.
3.1.4 Multiagente
A colaboração entre vários agentes [16] é um padrão de design fundamental em fluxos de trabalho de agentes que permite a especialização de tarefas e o processamento paralelo. Os agentes se comunicam entre si e compartilham resultados intermediários, garantindo que o fluxo de trabalho geral permaneça eficiente e coerente. Ao atribuir subtarefas a agentes especializados, esse padrão melhora a escalabilidade e a adaptabilidade de fluxos de trabalho complexos. Os sistemas multiagentes permitem que os desenvolvedores dividam tarefas complexas em subtarefas menores e mais gerenciáveis, que são atribuídas a diferentes agentes. Essa abordagem não só melhora o desempenho da tarefa, mas também oferece uma estrutura avançada para o gerenciamento de interações complexas. Cada agente tem sua própria memória e fluxo de trabalho, que pode incluir o uso de ferramentas, reflexão ou planejamento, permitindo a solução dinâmica e colaborativa de problemas (consulte a Figura 10).

Figura 10: Visão geral do MultiAgent
Embora a colaboração entre vários agentes ofereça um grande potencial, é um paradigma de design muito menos previsível do que os fluxos de trabalho mais maduros, como a reflexão e o uso de ferramentas. Dito isso, estruturas emergentes como AutoGen, Crew AI e LangGraph estão oferecendo novas maneiras de implementar soluções eficazes com vários agentes.
Esses padrões são a base do sucesso dos sistemas RAG baseados em agentes, permitindo que eles adaptem dinamicamente os fluxos de trabalho de recuperação e geração para atender às demandas de ambientes diversos e dinâmicos. Ao utilizar esses padrões, os agentes podem lidar com tarefas iterativas e sensíveis ao contexto além dos recursos dos sistemas RAG tradicionais.
4 Classificação dos sistemas RAG baseados em agentes
Os sistemas RAG (Retrieval Augmented Generation) baseados em agentes podem ser classificados em diferentes estruturas arquitetônicas com base em sua complexidade e princípios de projeto. Essas estruturas incluem arquiteturas de agente único, sistemas de vários agentes e arquiteturas de agentes hierárquicos. Cada estrutura visa a enfrentar desafios específicos e otimizar o desempenho em diferentes aplicativos. Esta seção apresenta uma categorização detalhada dessas arquiteturas, destacando seus recursos, benefícios e limitações.
4.1 Proxy de agente único RAG: Roteador
Os RAGs baseados em agentes únicos [31] atuam como um sistema centralizado de tomada de decisões em que um agente gerencia a recuperação, o roteamento e a integração de informações (conforme mostrado na Figura 11). Essa arquitetura simplifica o sistema ao combinar essas tarefas em um único agente unificado, o que a torna particularmente adequada para ambientes com um número limitado de ferramentas ou fontes de dados.
fluxo de trabalho
- Envio e avaliação de consultasO processo começa quando o usuário envia uma consulta. Um agente de coordenação (ou agente mestre de recuperação) recebe a consulta e a analisa para determinar a fonte de informações mais adequada.
- Seleção de fontes de conhecimentoDependendo do tipo de consulta, o agente de coordenação escolhe entre várias opções de pesquisa:
- Banco de dados estruturadoPara consultas que exigem acesso a dados tabulares, o sistema pode usar um mecanismo Text-to-SQL que interage com bancos de dados como o PostgreSQL ou o MySQL.
- pesquisa semânticaQuando se trata de informações não estruturadas, ele usa a recuperação baseada em vetores para recuperar documentos relevantes (por exemplo, PDFs, livros, registros organizacionais).
- Pesquisa na InternetPara obter informações contextuais amplas ou em tempo real, o sistema usa ferramentas de pesquisa na Web para acessar os dados on-line mais recentes.
- sistema de recomendaçãoPara consultas personalizadas ou contextuais, o sistema usa um mecanismo de recomendação para fornecer sugestões personalizadas.
- Integração de dados e síntese de LLMDados relevantes recuperados de uma fonte selecionada: Depois de recuperados de uma fonte selecionada, os dados relevantes são passados para o Modelo de Linguagem Ampla (LLM), que reúne as informações coletadas, integrando insights de várias fontes em uma resposta coerente e contextualmente relevante.
- Geração de saídaPor fim, o sistema gera uma resposta abrangente e orientada ao usuário para a consulta original. A resposta é apresentada em um formato prático e conciso e, opcionalmente, inclui referências ou citações das fontes utilizadas.
Principais recursos e vantagens
- Simplicidade centralizadaUm único agente lida com todas as tarefas de recuperação e roteamento, o que torna a arquitetura fácil de projetar, implementar e manter.
- Eficiência e otimização de recursosCom menos agentes e uma coordenação mais simples, o sistema requer menos recursos computacionais e pode processar as consultas mais rapidamente.
- roteamento dinâmicoO agente avalia cada consulta em tempo real e seleciona a fonte de conhecimento mais adequada (por exemplo, bancos de dados estruturados, pesquisa semântica, pesquisa na Web).
- Versatilidade entre ferramentasSuporte a várias fontes de dados e APIs externas, permitindo o suporte a fluxos de trabalho estruturados e não estruturados.
- Adequado para sistemas simplesPara aplicativos com tarefas bem definidas ou requisitos de integração limitados (por exemplo, recuperação de arquivos, fluxos de trabalho baseados em SQL).

Figura 11: Visão geral dos RAGs de agente único
Casos de uso: Suporte ao cliente
chamar a atenção para algo: Vocês podem me informar o status de entrega do meu pedido?
Processos do sistema (fluxo de trabalho de agente único)::
- Envio e avaliação de consultas::
- O usuário envia uma consulta, que é recebida pelo agente de coordenação.
- Coordenar com os agentes para analisar as consultas e identificar as fontes de informação mais adequadas.
- Seleção de fontes de conhecimento::
- Recuperar detalhes de rastreamento do banco de dados de gerenciamento de pedidos.
- Receba atualizações em tempo real da API da transportadora.
- Opcionalmente, uma pesquisa na Web pode ser realizada para identificar as condições locais que afetam a entrega, como clima ou atrasos logísticos.
- Integração de dados e síntese de LLM::
- Passar os dados relevantes para o LLM, que consolida as informações em uma resposta coerente.
- Geração de saída::
- O sistema gera uma resposta acionável e concisa que fornece rastreamento em tempo real de atualizações e possíveis alternativas.
responsivo::
Resposta integradaSeu pacote está em trânsito e deve chegar amanhã à noite. O rastreamento em tempo real da UPS mostra que ele está localizado em um centro de distribuição regional.
4.2 Sistema RAG multiagente
O RAG multiagente [31] representa uma evolução modular e escalonável da arquitetura de agente único, com o objetivo de lidar com processos complexos e diversos tipos de consulta, aproveitando vários agentes especializados (conforme mostrado na Figura 12). Em vez de depender de um único agente para gerenciar todas as tarefas (raciocínio, recuperação e geração de respostas), o sistema atribui responsabilidades a vários agentes, cada um deles otimizado para uma função ou fonte de dados específica.
fluxo de trabalho
- Envio de consultasProcesso de recuperação: O processo começa com uma consulta do usuário, que é recebida por um agente coordenador ou um agente de recuperação mestre. Esse agente atua como um coordenador central e delega a consulta a um agente de recuperação especializado de acordo com os requisitos da consulta.

Figura 12: Visão geral dos sistemas RAG com vários agentes
- Agentes de pesquisa especializadosAgente de recuperação: as consultas são atribuídas a vários agentes de recuperação, cada um concentrado em um tipo específico de fonte de dados ou tarefa. Exemplo:
- Agente 1Manipulação de consultas estruturadas, por exemplo, interagindo com bancos de dados baseados em SQL, como PostgreSQL ou MySQL.
- Agente 2Gerencie pesquisas semânticas para recuperar dados não estruturados de fontes como PDFs, livros ou registros internos.
- Agente 3Foco na recuperação de informações públicas em tempo real a partir de pesquisas na Web ou APIs.
- Agente 4Especialista em sistemas de recomendação que fornecem sugestões contextualmente relevantes com base no comportamento ou no perfil do usuário.
- Acesso a ferramentas e recuperação de dadosCada agente encaminha a consulta para a ferramenta ou fonte de dados apropriada em seu domínio, por exemplo:
- pesquisa vetorial: para relevância semântica.
- Texto para SQLPara dados estruturados.
- Pesquisa na InternetPara informações públicas em tempo real.
- APIPara acessar serviços externos ou sistemas proprietários.
O processo de recuperação é executado em paralelo, permitindo assim o processamento eficiente de diferentes tipos de consulta.
- Integração de dados e síntese de LLMO modelo de linguagem grande (LLM) consolida as informações recuperadas em uma resposta coerente e contextualmente relevante que integra perfeitamente os insights de várias fontes.
- Geração de saídaO sistema gera uma resposta abrangente que é devolvida ao usuário em um formato prático e conciso.
Principais recursos e vantagens
- modularizaçãoCada agente opera de forma independente, permitindo que os agentes sejam adicionados ou removidos sem problemas com base nos requisitos do sistema.
- escalabilidadeProcessamento paralelo de vários agentes: o processamento paralelo de vários agentes permite que o sistema manipule com eficiência grandes volumes de consulta.
- Especialização de tarefasCada agente é otimizado para um tipo específico de consulta ou fonte de dados, melhorando a precisão e a relevância da recuperação.
- eficiênciaAtribuição de tarefas a agentes dedicados: Ao atribuir tarefas a agentes dedicados, o sistema minimiza os gargalos e melhora o desempenho de fluxos de trabalho complexos.
- versatilidadePara aplicações em vários domínios, incluindo pesquisa, análise, tomada de decisões e suporte ao cliente.
desafio
- Complexidade da coordenaçãoO gerenciamento da comunicação entre agentes e a delegação de tarefas exigem mecanismos de coordenação complexos.
- sobrecarga computacionalProcessamento paralelo de vários agentes pode aumentar o uso de recursos.
- integração de dadosIntegração de resultados de diferentes fontes em uma resposta coerente não é fácil e requer recursos avançados de LLM.
Caso de uso: assistente de pesquisa multidisciplinar
chamar a atenção para algo: Quais são os impactos econômicos e ambientais da adoção de energia renovável na Europa?
Processos do sistema (fluxo de trabalho multiagente)::
- Agente 1Use consultas SQL para recuperar dados estatísticos de bancos de dados econômicos.
- Agente 2Pesquisa de artigos acadêmicos relevantes usando ferramentas de pesquisa semântica.
- Agente 3Pesquisa na Web para obter as últimas notícias e atualizações de políticas sobre energia renovável.
- Agente 4Consulta ao sistema de recomendação para sugerir conteúdo relevante, como relatórios ou comentários de especialistas.
responsivo::
Resposta integrada:: "A adoção de energia renovável na Europa levou a uma redução nas emissões de gases de efeito estufa de 20% na última década, de acordo com o relatório de política da UE. No aspecto econômico, os investimentos em energia renovável criaram cerca de 1,2 milhão de empregos, com crescimento significativo nos setores solar e eólico. Pesquisas acadêmicas recentes também destacaram possíveis compensações em termos de estabilidade da rede e custos de armazenamento de energia."
4.3 Sistema RAG hierárquico baseado em agentes
O sistema RAG [17] baseado em agentes hierárquicos usa uma abordagem estruturada e multinível para a recuperação e o processamento de informações, o que melhora a eficiência e a tomada de decisões estratégicas (conforme mostrado na Figura 13). Os agentes são organizados em uma estrutura hierárquica, com agentes de nível superior supervisionando e orientando os agentes de nível inferior. Essa estrutura permite a tomada de decisões em vários níveis e garante que as consultas sejam tratadas pelos recursos mais adequados.

Figura 13: Ilustração de um RAG hierárquico agêntico
fluxo de trabalho
- Recibo de consultaAgente de nível superior: O usuário envia uma consulta que é recebida pelo agente de nível superior, que é responsável pela avaliação inicial e pelo comissionamento.
- tomada de decisões estratégicasAgente de nível superior: O agente de nível superior avalia a complexidade da consulta e decide quais agentes subordinados ou fontes de dados devem ser priorizados. Dependendo do domínio da consulta, determinados bancos de dados, APIs ou ferramentas de pesquisa podem ser considerados mais confiáveis ou relevantes.
- Delegação a um subordinadoAgentes de nível superior atribuem tarefas a agentes de nível inferior especializados em métodos de recuperação específicos (por exemplo, bancos de dados SQL, pesquisas na Web ou sistemas proprietários). Esses agentes executam suas tarefas atribuídas de forma independente.
- Polimerização e sínteseAgentes de alto nível coletam e integram resultados de agentes subordinados, consolidando informações em respostas coerentes.
- Entrega de respostasResposta final sintetizada: A resposta final sintetizada é retornada ao usuário, garantindo que a resposta seja abrangente e contextualmente relevante.
Principais recursos e vantagens
- Priorização estratégicaAgentes de nível superior podem priorizar fontes de dados ou tarefas com base na complexidade, confiabilidade ou contexto da consulta.
- escalabilidadeAtribuição de tarefas a vários níveis de agentes pode lidar com consultas altamente complexas ou multifacetadas.
- Capacidade aprimorada de tomada de decisões: agentes de alto nível aplicam supervisão estratégica para melhorar a precisão geral e a consistência da resposta.
desafio
- Complexidade da coordenaçãoA manutenção de uma comunicação robusta entre agentes em vários níveis pode aumentar a sobrecarga de coordenação.
- Alocação de recursosDistribuição de tarefas: Não é fácil distribuir tarefas de forma eficiente entre os níveis e, ao mesmo tempo, evitar gargalos.
Caso de uso: sistema de análise financeira
chamar a atenção para algo: Quais são as opções de investimento em energia renovável com base nas tendências atuais do mercado?
Processos do sistema (fluxo de trabalho do agente hierárquico)::
- agente no topo da hierarquiaAvalie a complexidade das consultas e priorize bancos de dados financeiros e indicadores econômicos confiáveis em relação a fontes de dados menos validadas.
- Agentes de nível médioRecupere dados de mercado em tempo real (por exemplo, preços de ações, desempenho do setor) de APIs proprietárias e bancos de dados SQL estruturados.
- Agentes de baixo nívelPesquisa na Web sobre anúncios e políticas recentes e consulta a sistemas de referência para rastrear opiniões de especialistas e análises de notícias.
- Polimerização e síntese: resultados de agregação de proxy de nível superior que integram dados quantitativos com percepções de políticas.
responsivo::
Resposta integrada: "Com base nos dados atuais do mercado, as ações de energia renovável cresceram 15% no último trimestre, impulsionadas principalmente pelas políticas governamentais de apoio e pelo alto interesse dos investidores. Os analistas acreditam que os setores eólico e solar provavelmente continuarão a ganhar impulso, enquanto as tecnologias emergentes, como o hidrogênio verde, têm risco moderado, mas podem oferecer altos retornos."
4.4 RAG corretivo de proxy
O Corrective RAG [32] [33] introduz a capacidade de autocorrigir os resultados da recuperação, aprimorando a utilização de documentos e melhorando a qualidade da geração de respostas (conforme mostrado na Figura 14). Ao incorporar agentes inteligentes no fluxo de trabalho, o Corrective RAG [32] [33] garante o refinamento iterativo dos documentos contextuais e das respostas para minimizar os erros e maximizar a relevância.

Figura 14: Visão geral do RAG corretivo autêntico
Correção da ideia central do RAGO princípio central do RAG Corretivo está em sua capacidade de avaliar dinamicamente os documentos recuperados, executar ações corretivas e refinar a consulta para melhorar a qualidade da resposta gerada. O RAG corretivo ajusta sua metodologia da seguinte forma:
- Avaliação da relevância do documentoDocumentos recuperados são avaliados por um agente de avaliação de relevância. Os documentos abaixo do limite de relevância acionam uma etapa de correção.
- Aprimoramento e refinamento da pesquisaConsulta: As consultas são refinadas por um agente de refinamento de consultas que usa a compreensão semântica para otimizar a recuperação para obter melhores resultados.
- Recuperação dinâmica de fontes externasQuando o contexto é insuficiente, o agente externo de recuperação de conhecimento realiza uma pesquisa na Web ou acessa fontes de dados alternativas para complementar os documentos recuperados.
- síntese de respostaTodas as informações validadas e refinadas são passadas para o agente de síntese de resposta para a geração da resposta final.
fluxo de trabalhoO sistema RAG corretivo é baseado em cinco agentes principais:
- agente de pesquisa contextualResponsável por recuperar o documento de contexto inicial do banco de dados de vetores.
- Agente de avaliação de relevânciaAvaliação da relevância dos documentos recuperados e sinalização de quaisquer documentos irrelevantes ou ambíguos para ação corretiva.
- Agente de refinamento de consultasReescrever consultas para melhorar a eficiência da recuperação e usar a compreensão semântica para otimizar os resultados.
- Agente de recuperação de conhecimento externoPesquisa na Web ou acesso a fontes de dados alternativas quando a documentação contextual for insuficiente.
- Agente de síntese de respostaIntegração de todas as informações validadas em uma resposta coerente e precisa.
Principais recursos e vantagens:
- Correção iterativaGaranta alta precisão de resposta identificando e corrigindo dinamicamente resultados de pesquisa irrelevantes ou ambíguos.
- Adaptação dinâmicaIntegração de pesquisa na Web em tempo real e refinamento de consultas para melhorar a precisão da recuperação.
- Proxy ModularCada agente executa tarefas especializadas para garantir operações eficientes e dimensionáveis.
- Garantias factuaisCorreção do RAG: A correção do RAG minimiza o risco de alucinações ou informações incorretas, validando todo o conteúdo recuperado e gerado.
Caso de uso: assistente de pesquisa acadêmica
chamar a atenção para algo: Quais são as descobertas mais recentes da pesquisa de IA generativa?
Processos do sistema (correção de fluxos de trabalho RAG)::
- Envio de consultasOs usuários enviam consultas ao sistema.
- pesquisa contextual::
- agente de pesquisa contextualRecuperar documentos iniciais do banco de dados de artigos publicados sobre IA generativa.
- Os documentos recuperados são passados para a próxima etapa de avaliação.
- Avaliação da relevância:
- Agente de avaliação de relevânciaAvaliar a correspondência entre o documento e a consulta.
- Categorizar documentos como relevantes, ambíguos ou irrelevantes. Os documentos irrelevantes são marcados para ação corretiva.
- Ação corretiva (se necessário):
- Agente de refinamento de consultasReescrever consultas para melhorar a especificidade.
- Agente de recuperação de conhecimento externoRealizar pesquisas na Web para obter documentos e relatórios adicionais de fontes externas.
- Síntese de respostas.
- Agente de síntese de respostaIntegrar documentos validados em resumos abrangentes e detalhados.
Resposta.
Resposta integrada: "Os resultados recentes da pesquisa de IA generativa incluem modelos de difusão, aprendizado por reforço em tarefas de texto para vídeo e avanços em técnicas de otimização para treinamento de modelos em larga escala. Veja a pesquisa apresentada no NeurIPS 2024 e no AAAI 2025 para obter mais detalhes."
4.5 RAG baseado em agente adaptável
A Geração Aumentada de Recuperação Adaptativa (Adaptive Retrieval Augmented Generation, RAG) [34] aumenta a flexibilidade e a eficiência dos Modelos de Linguagem Grande (LLMs) adaptando dinamicamente a estratégia de processamento de consultas com base na complexidade da consulta recebida. Ao contrário dos fluxos de trabalho de recuperação estática, o Adaptive RAG [35] emprega classificadores para analisar a complexidade da consulta e determinar a abordagem mais adequada, variando de recuperação em uma única etapa a raciocínio em várias etapas, ou até mesmo ignorando a recuperação para consultas simples, conforme mostrado na Figura 15.

Figura 15: Visão geral do RAG adaptativo e agêntico
A ideia central do RAG adaptativo O princípio central do RAG adaptativo está em sua capacidade de ajustar dinamicamente a estratégia de recuperação de acordo com a complexidade da consulta. O RAG adaptativo ajusta seu método da seguinte forma:
- consulta simplesPara perguntas factuais que exigem recuperação adicional (por exemplo, "Qual é o ponto de ebulição da água?") :: Para perguntas factuais que exigem recuperação adicional (por exemplo, "What is the boiling point of water?"), o sistema gera respostas diretamente usando o conhecimento pré-existente.
- consulta simplesPara tarefas moderadamente complexas que exigem um contexto mínimo (por exemplo, "Qual é o status da minha última conta de luz?") o sistema executa uma pesquisa em uma única etapa para obter os detalhes relevantes.
- consulta complexaPara consultas em vários níveis que exigem raciocínio iterativo (por exemplo, "Como a população da cidade X mudou na última década e quais foram os fatores que contribuíram para isso?") o sistema usa a pesquisa em várias etapas, refinando progressivamente os resultados intermediários para fornecer respostas abrangentes.
fluxo de trabalhoO sistema Adaptive RAG é baseado em três componentes principais:
- Função de classificador.
- Um modelo de linguagem menor analisa as consultas para prever sua complexidade.
- O classificador é treinado usando conjuntos de dados rotulados automaticamente, derivados de resultados de modelos anteriores e padrões de consulta.
- Seleção dinâmica de estratégias.
- Para consultas simples, o sistema evita pesquisas desnecessárias e gera respostas diretamente usando o LLM.
- Para consultas simples, ele usa um processo de pesquisa em uma única etapa para obter o contexto relevante.
- Para consultas complexas, ele ativa a recuperação em várias etapas para garantir o refinamento iterativo e o raciocínio aprimorado.
- Integração do LLM.
- O LLM integra as informações recuperadas em uma resposta coerente.
- A interação iterativa entre o LLM e o classificador permite o refinamento de consultas complexas.
Principais recursos e benefícios.
- Adaptação dinâmicaAdaptação das estratégias de recuperação à complexidade da consulta para otimizar a eficiência computacional e a precisão da resposta.
- Eficiência de recursos: minimiza a sobrecarga desnecessária para consultas simples e garante o processamento completo de consultas complexas.
- Precisão aprimorada:: O refinamento iterativo garante que as consultas complexas sejam resolvidas com alta precisão.
- destrezaPode ser estendido para integrar caminhos adicionais, como ferramentas específicas de domínio ou APIs externas.
Casos de uso. Assistente de suporte ao cliente
Dica. Por que minha encomenda está atrasada e quais são minhas opções?
Processos do sistema (fluxo de trabalho adaptativo do RAG).
- Categoria de consulta.
- O classificador analisa a consulta e determina que ela é uma consulta complexa que exige raciocínio em várias etapas.
- Seleção dinâmica de estratégias.
- O sistema ativa um processo de recuperação em várias etapas com base na classificação de complexidade.
- Pesquisa em várias etapas.
- Recuperar detalhes de rastreamento do banco de dados de pedidos.
- Obtenha atualizações de status em tempo real da API do Courier.
- Faça uma pesquisa na Web para procurar fatores externos, como condições climáticas ou interrupções locais.
- Síntese de respostas.
- O LLM integra todas as informações recuperadas em uma resposta abrangente e acionável.
Resposta.
Resposta integrada: "Sua encomenda sofreu um atraso devido às condições climáticas adversas em sua região. No momento, ela está localizada no centro de distribuição local e a previsão é de que chegue dentro de 2 dias. Como alternativa, você pode optar por retirá-lo nas instalações."
4.6 RAGs baseados em agentes gráficos
4.6.1 Agent-G: uma estrutura baseada em agentes para RAGs de gráficos
O Agent-G [8] apresenta uma arquitetura inovadora baseada em agentes que combina bases de conhecimento de gráficos com recuperação de documentos não estruturados. Ao combinar fontes de dados estruturados e não estruturados, essa estrutura aprimora o raciocínio e a precisão da recuperação dos sistemas RAG (Retrieval Augmented Generation). Ele emprega bibliotecas modulares de recuperadores, interações dinâmicas de agentes e loops de feedback para garantir resultados de alta qualidade, conforme mostrado na Figura 16.

Figura 16: Visão geral do Agent-G: estrutura agêntica para o Graph RAG
A ideia central do Agent-G O princípio central do Agent-G está em sua capacidade de atribuir dinamicamente tarefas de recuperação a agentes especializados, utilizando bases de conhecimento de gráficos e arquivos de texto:
- base de conhecimento gráficaUso de dados estruturados para extrair relacionamentos, hierarquias e conexões (por exemplo, mapeamento de doença para sintoma no domínio médico).
- documento não estruturado:: Os sistemas tradicionais de recuperação de texto fornecem informações contextuais para complementar os dados do gráfico.
- Módulo de críticaAvaliação da relevância e da qualidade das informações recuperadas para garantir o alinhamento com a consulta.
- loop de feedback:: Refinamento da recuperação e da síntese por meio de validação iterativa e novas consultas.
fluxo de trabalhoO sistema Agent-G é baseado em quatro componentes principais:
- Biblioteca Retriever.
- Um conjunto de agentes modulares é especializado na recuperação de dados baseados em gráficos ou não estruturados.
- O agente seleciona dinamicamente as fontes relevantes com base nos requisitos da consulta.
- Módulo de crítica.
- Validar a relevância e a qualidade dos dados recuperados.
- Sinalizar resultados de baixa confiança para recuperação ou refinamento.
- Interação dinâmica de agentes.
- Agentes específicos de tarefas colaboram para integrar diferentes tipos de dados.
- Garantir a recuperação e a síntese coordenadas entre as fontes de figuras e textos.
- Integração do LLM.
- Sintetize os dados validados em uma resposta coerente.
- O feedback iterativo do módulo de crítica garante o alinhamento com a intenção da consulta.
Principais recursos e benefícios.
- raciocínio aprimoradoCombinação de relações estruturadas em um diagrama com informações contextuais de documentos não estruturados.
- Adaptação dinâmica:: Adaptação dinâmica das estratégias de pesquisa aos requisitos da consulta.
- Precisão aprimoradaO módulo Critique reduz o risco de dados irrelevantes ou de baixa qualidade na resposta.
- Modularidade escalávelSuporte para adicionar novos agentes para executar tarefas especializadas para maior escalabilidade.
Casos de uso: Diagnóstico médico
Dica. Quais são os sintomas comuns do diabetes tipo 2 e como eles estão relacionados às doenças cardíacas?
Processos do sistema (fluxo de trabalho do agente G).
- Recebimento e distribuição de consultasResposta: O sistema recebe consultas e identifica a necessidade de usar dados estruturados e não estruturados em gráficos para responder totalmente à pergunta.
- Localizador de gráficos.
- Extraindo a relação entre diabetes tipo 2 e doenças cardíacas do Medical Knowledge Graph.
- Identificar fatores de risco comuns, como obesidade e hipertensão, explorando hierarquias e relações gráficas.
- Document Retriever.
- Obtenha descrições dos sintomas do diabetes tipo 2 (por exemplo, aumento da sede, micção frequente, fadiga) na literatura médica.
- Adicione informações contextuais para complementar os insights baseados em gráficos.
- Módulo de crítica.
- Avaliar a relevância e a qualidade dos dados de gráficos e dados de documentos recuperados.
- Sinalizar resultados de baixa confiança para refinamento ou nova consulta.
- síntese de resposta: o LLM integra os dados de validação do recuperador de gráficos e do recuperador de documentos em uma resposta coerente, garantindo o alinhamento com a intenção da consulta.
Resposta.
Resposta integrada: "Os sintomas do diabetes tipo 2 incluem aumento da sede, micção frequente e fadiga. Estudos demonstraram uma correlação entre diabetes e doenças cardíacas, principalmente por meio de fatores de risco compartilhados, como obesidade e pressão alta."
4.6.2 GeAR: agente de aumento de gráfico para geração de aumento de recuperação
O GeAR [36] apresenta uma estrutura baseada em agentes que aprimora os sistemas tradicionais de geração aumentada de recuperação (RAG) integrando mecanismos de recuperação baseados em gráficos. Ao utilizar técnicas de extensão de gráficos e arquitetura baseada em agentes, o GeAR aborda os desafios em cenários de recuperação com vários saltos e melhora a capacidade do sistema de lidar com consultas complexas, conforme mostrado na Figura 17.

Figura 17: Visão geral do GeAR: agente aprimorado por gráfico para geração aumentada de recuperação[36]
- extensão gráficaRecuperadores de linha de base tradicionais (por exemplo, BM25): aprimora os recuperadores de linha de base tradicionais (por exemplo, BM25) estendendo o processo de recuperação para incluir dados estruturados em gráficos, permitindo que o sistema capture relações e dependências complexas entre entidades.
- estrutura de proxyArquitetura baseada em agentes: integra uma arquitetura baseada em agentes que utiliza extensões de gráficos para gerenciar tarefas de recuperação de forma mais eficiente, permitindo a tomada de decisões dinâmicas e autônomas durante o processo de recuperação.
fluxo de trabalhoO sistema GeAR opera por meio dos seguintes componentes:
- Figura Módulo de extensão.
- A integração de dados baseados em gráficos no processo de recuperação permite que o sistema considere as relações entre as entidades durante o processo de recuperação.
- Aprimorar a capacidade do pesquisador de linha de base para lidar com consultas de vários saltos, estendendo o espaço de pesquisa para incluir entidades conectadas.
- Recuperação baseada em agentes.
- Uma estrutura de agente é usada para gerenciar o processo de recuperação, permitindo que os agentes selecionem e combinem dinamicamente estratégias de recuperação com base na complexidade da consulta.
- Os agentes podem decidir de forma autônoma sobre um caminho de pesquisa usando extensões de gráficos para melhorar a relevância e a precisão das informações recuperadas.
- Integração do LLM.
- Combinando as informações recuperadas com os benefícios das extensões de gráficos com os recursos da Modelagem de Linguagem Ampla (LLM) para gerar respostas coerentes e contextualmente relevantes.
- Essa integração garante que o processo de geração seja inspirado tanto em documentos não estruturados quanto em dados de gráficos estruturados.
Principais recursos e benefícios.
- Pesquisa aprimorada de múltiplos saltos:: As extensões de gráficos do GeAR permitem que o sistema lide com consultas complexas que exigem raciocínio sobre várias informações inter-relacionadas.
- Tomada de decisão por procuraçãoA estrutura de proxy permite a seleção dinâmica e autônoma de estratégias de recuperação, melhorando a eficiência e a relevância.
- Precisão aprimoradaConclusão: ao integrar dados gráficos estruturados, o GeAR melhora a precisão das informações recuperadas para gerar respostas mais precisas e contextualmente adequadas.
- escalabilidadeA natureza modular da estrutura do agente permite a integração de estratégias de pesquisa e fontes de dados adicionais, conforme necessário.
Caso de uso: Quiz Multi-hop
Dica. Quem influenciou o mentor de J.K. Rowling?
Processos do sistema (fluxo de trabalho GeAR).
- agente no topo da hierarquiaAvalie a natureza de vários saltos da consulta e determine a necessidade de combinar a expansão de gráficos e a recuperação de documentos para responder à pergunta.
- Figura Módulo de extensão.
- Identifique o mentor de J.K. Rowling como a entidade-chave na consulta.
- Rastreamento das influências literárias dos mentores por meio da exploração de dados da estrutura do Mapa de Relacionamento Literário.
- Recuperação baseada em agentes.
- Um agente seleciona de forma autônoma um caminho de pesquisa expandido no gráfico para reunir informações relevantes sobre o impacto do mentor.
- Integrar contexto adicional para detalhes não estruturados de mentores e suas influências, consultando fontes de dados textuais.
- síntese de respostaUse o LLM para combinar percepções do processo de recuperação de gráficos e documentos para gerar uma resposta que reflita com precisão as relações complexas da consulta.
Resposta.
Resposta integrada"O mentor de J.K. Rowling, [nome do mentor], foi fortemente influenciado por [nome do autor], que é conhecido por sua [obra ou gênero famoso]. Essa conexão destaca as relações em cascata na história literária, em que ideias influentes são frequentemente transmitidas por várias gerações de escritores."
4.7 Fluxos de trabalho de documentos baseados em agentes em RAGs baseados em agentes
Fluxos de trabalho de documentos autênticos (ADW)[37] amplia o paradigma tradicional do Retrieval Augmented Generation (RAG) automatizando o trabalho de conhecimento de ponta a ponta. Esses fluxos de trabalho orquestram processos complexos centrados em documentos que integram análise, recuperação, raciocínio e saída estruturada de documentos com agentes inteligentes (veja a Figura 18). Os sistemas ADW abordam as limitações do Processamento Inteligente de Documentos (IDP) e do RAG mantendo o estado, orquestrando fluxos de trabalho de várias etapas e aplicando lógica específica do domínio aos documentos.
fluxo de trabalho
- Análise de documentos e estruturação de informações::
- Use ferramentas de nível empresarial (por exemplo, LlamaParse) para analisar documentos e extrair campos de dados relevantes, como números de faturas, datas, informações do fornecedor, entradas e condições de pagamento.
- Organizar dados estruturados para processamento posterior.
- Manutenção de estado entre processos::
- O sistema mantém o estado do contexto do documento em questão, garantindo consistência e relevância em fluxos de trabalho de várias etapas.
- Acompanhe o andamento dos documentos nos vários estágios de processamento.
- recuperação de conhecimento::
- Recuperar referências relevantes de bases de conhecimento externas (por exemplo, LlamaCloud) ou índices vetoriais.
- Recupere orientações em tempo real e específicas do domínio para aprimorar a tomada de decisões.
- Programação baseada em agentes::
- Os agentes inteligentes aplicam regras de negócios, realizam raciocínio multihop e geram recomendações acionáveis.
- Orquestrar componentes como analisadores, recuperadores e APIs externas para uma integração perfeita.
- Geração de resultados acionáveis::
- O resultado é apresentado em um formato estruturado, adaptado a casos de uso específicos.
- Sintetize as recomendações e os insights extraídos em relatórios concisos e acionáveis.

Figura 18: Visão geral dos fluxos de trabalho de documentos autênticos (ADW) [37]
Caso de uso: Fluxo de trabalho de pagamento de faturas
chamar a atenção para algoGerar um relatório de aviso de pagamento com base nas faturas enviadas e nos termos do contrato do fornecedor relevante.
Processos do sistema (fluxo de trabalho do ADW)::
- Analisar faturas para extrair detalhes importantes, como número da fatura, data, informações do fornecedor, entradas e condições de pagamento.
- Recupere os contratos de fornecedores apropriados para validar os termos de pagamento e identificar quaisquer descontos aplicáveis ou requisitos de conformidade.
- Gere um relatório de recomendação de pagamento que inclua o valor original devido, possíveis descontos para pagamento antecipado, análise de impacto orçamentário e ações estratégicas de pagamento.
responsivoResposta consolidada: "A fatura INV-2025-045 no valor de $15.000,00 foi processada. Se o pagamento for feito até 2025-04-10, um desconto de pagamento antecipado de 21 TP3T estará disponível, reduzindo o valor devido para $14.700,00. Como o subtotal excede $10.000,00, um desconto de pedido em massa de 5% foi aplicado. Recomenda-se que o pagamento antecipado seja aprovado para economizar 21 TP3T e garantir a alocação oportuna de fundos para as próximas fases do projeto."
Principais recursos e vantagens
- Manutenção de condiçõesControle o contexto do documento e os estágios do fluxo de trabalho para garantir a consistência entre os processos.
- programação em várias etapasGerencie fluxos de trabalho complexos que envolvam vários componentes e ferramentas externas.
- Inteligência de domínio específicoAplique regras e diretrizes comerciais personalizadas para obter orientações precisas.
- escalabilidadeSuporte ao processamento de documentos em larga escala com integração modular e dinâmica de agentes.
- Aumento da produtividadeAutomatize tarefas repetitivas e, ao mesmo tempo, aprimore o conhecimento humano na tomada de decisões.
4.8 Análise comparativa das estruturas RAG baseadas em agentes
A Tabela 2 apresenta uma análise comparativa abrangente de três estruturas arquitetônicas: RAG tradicional, RAG baseado em agente e fluxo de trabalho de documentos baseado em agente (ADW). A análise destaca seus respectivos pontos fortes, pontos fracos e cenários mais adequados, fornecendo informações valiosas para aplicação em diferentes casos de uso.
Tabela 2: Análise comparativa: RAG tradicional vs. RAG baseado em agente vs. fluxo de trabalho de documentos baseado em agente (ADW)
| caracterização | RAG tradicional | RAG de proxy | Fluxo de trabalho de documentos baseado em agente (ADW) |
|---|---|---|---|
| recontagem (por exemplo, resultados da eleição) | Tarefas isoladas de recuperação e geração | Colaboração e raciocínio de vários agentes | Fluxos de trabalho de ponta a ponta centrados em documentos |
| Manutenção do contexto | restrições | Realização por meio de módulos de memória | Manutenção do status em um fluxo de trabalho de várias etapas |
| Adaptação dinâmica | mínimo | your (honorífico) | Adaptado ao fluxo de trabalho do documento |
| Organização do fluxo de trabalho | hiato | Orquestrar tarefas de vários agentes | Processamento integrado de documentos em várias etapas |
| Uso de ferramentas/APIs externas | Integração básica (por exemplo, ferramentas de pesquisa) | Extensão por meio de ferramentas (por exemplo, APIs e bases de conhecimento) | Integração profunda com regras de negócios e ferramentas específicas do domínio |
| escalabilidade | Limitado a pequenos conjuntos de dados ou consultas | Sistema multiagente dimensionável | Fluxos de trabalho corporativos multidisciplinares e dimensionáveis |
| inferência complexa | Básico (por exemplo, questionário simples) | Raciocínio em várias etapas usando agentes | Raciocínio estruturado entre documentos |
| Aplicação principal | Sistema de perguntas e respostas, recuperação de conhecimento | Conhecimento e raciocínio multidisciplinares | Revisão de contratos, processamento de faturas, análise de reclamações |
| de ponta | Configuração simples e rápida | Alta precisão, raciocínio colaborativo | Automação de ponta a ponta, inteligência específica do domínio |
| desafio | Má compreensão do contexto | Complexidade da coordenação | Sobrecarga de recursos, padronização de campo |
A análise comparativa destaca a trajetória evolutiva do RAG tradicional para o RAG baseado em agentes e para o fluxo de trabalho de documentos baseado em agentes (ADW). Embora o RAG tradicional ofereça os benefícios da simplicidade e da facilidade de implantação para tarefas básicas, o RAG baseado em agentes introduz recursos aprimorados de raciocínio e escalabilidade por meio da colaboração de vários agentes. O ADW se baseia nesses avanços, fornecendo fluxos de trabalho robustos e centrados em documentos que facilitam a automação de ponta a ponta e a integração com processos específicos do domínio. Compreender os pontos fortes e as limitações de cada estrutura é fundamental para selecionar a arquitetura que melhor se adapta às necessidades específicas dos aplicativos e aos requisitos operacionais.
5 Aplicação do RAG de proxy
Os sistemas RAG (Retrieval Augmented Generation) baseados em agentes demonstram potencial transformador em diversos domínios. Combinando recuperação de dados em tempo real, recursos de geração e tomada de decisão autônoma, esses sistemas abordam desafios complexos, dinâmicos e multimodais. Esta seção explora as principais aplicações do RAG baseado em agentes, detalhando como esses sistemas estão moldando domínios como suporte ao cliente, saúde, finanças, educação, fluxos de trabalho jurídicos e setores criativos.
5.1 Suporte ao cliente e assistentes virtuais
Os sistemas RAG baseados em agentes estão revolucionando o suporte ao cliente ao permitir a resolução de consultas em tempo real e com reconhecimento de contexto. Os chatbots e assistentes virtuais tradicionais geralmente dependem de bases de conhecimento estáticas, o que resulta em respostas genéricas ou desatualizadas. Em contrapartida, os sistemas RAG baseados em agentes recuperam dinamicamente as informações mais relevantes, adaptam-se ao contexto do usuário e geram respostas personalizadas.
Caso de uso: aprimoramento das vendas de anúncios da Twitch [38]
Por exemplo, a Twitch utiliza um fluxo de trabalho no estilo de agência com o RAG no Amazon Bedrock para otimizar as vendas de anúncios. O sistema recupera dinamicamente os dados do anunciante, o desempenho histórico da campanha e as estatísticas do público para gerar propostas detalhadas de anúncios, melhorando significativamente a eficiência operacional.
Principais benefícios:
- Melhorar a qualidade da respostaRespostas personalizadas e contextualmente relevantes aumentam o envolvimento do usuário.
- Eficiência operacionalReduz a carga de trabalho dos agentes de suporte manual, automatizando consultas complexas.
- Adaptabilidade em tempo realIntegração dinâmica de dados em evolução, como interrupções de serviço em tempo real ou atualizações de preços.
5.2 Tratamento médico e medicina personalizada
No setor de saúde, a combinação de dados específicos do paciente com as pesquisas médicas mais recentes é fundamental para a tomada de decisões informadas. Os sistemas RAG baseados em agentes permitem isso recuperando diretrizes clínicas em tempo real, literatura médica e históricos de pacientes para ajudar os médicos no diagnóstico e no planejamento do tratamento.
Casos de uso: resumo dos casos de pacientes [39]
Os sistemas RAG baseados em agentes foram aplicados para gerar resumos de casos de pacientes. Por exemplo, ao integrar registros eletrônicos de saúde (EHRs) e literatura médica atualizada, o sistema gera resumos abrangentes para que os médicos possam tomar decisões mais rápidas e bem informadas.
Principais benefícios:
- Atendimento personalizadoAdaptar as recomendações às necessidades de cada paciente.
- eficiência de tempoSimplifique a recuperação de estudos relevantes e economize o valioso tempo dos profissionais de saúde.
- precisãoRecomendações: garantir que as recomendações sejam baseadas nas evidências mais recentes e nos parâmetros específicos do paciente.
5.3 Análise legal e contratual
Os sistemas RAG baseados em agentes estão redefinindo a forma como os fluxos de trabalho jurídicos são executados, fornecendo ferramentas para análise rápida de documentos e tomada de decisões.
Casos de uso: revisão de contratos [40]
Um sistema RAG no estilo de agente jurídico analisa contratos, extrai cláusulas-chave e identifica riscos potenciais. Ao combinar recursos de pesquisa semântica e mapeamento de conhecimento jurídico, ele automatiza o complicado processo de revisão de contratos, garantindo a conformidade e reduzindo os riscos.
Principais benefícios:
- identificação de riscosCláusulas padrão: sinaliza automaticamente as cláusulas que se desviam das cláusulas padrão.
- eficiênciaRedução do tempo gasto no processo de revisão de contratos.
- escalabilidadeGerenciamento de um grande número de contratos ao mesmo tempo.
5.4 Análise financeira e de risco
Os sistemas RAG baseados em agentes estão transformando o setor financeiro, fornecendo percepções em tempo real para decisões de investimento, análise de mercado e gerenciamento de riscos. Esses sistemas integram fluxos de dados em tempo real, tendências históricas e modelagem preditiva para produzir resultados acionáveis.
Casos de uso: processamento de reclamações de seguro de automóveis [41]
No seguro de automóveis, o RAG baseado em agentes automatiza o processamento de sinistros. Por exemplo, ao recuperar os detalhes da apólice e combiná-los com os dados de acidentes, ele gera recomendações de sinistros e, ao mesmo tempo, garante a conformidade com os requisitos regulamentares.
Principais benefícios:
- análise em tempo realInformações sobre o mercado: fornece insights com base em dados de mercado em tempo real.
- Mitigação de riscosIdentificação de riscos potenciais usando análise preditiva e raciocínio em várias etapas.
- Capacidade aprimorada de tomada de decisõesCombinação de dados históricos e em tempo real para desenvolver uma estratégia abrangente.
5.5 Educação
A educação é outra área em que os sistemas RAG baseados em agentes tiveram um progresso significativo. Esses sistemas permitem a aprendizagem adaptativa gerando explicações, materiais de aprendizagem e feedback que se adaptam ao progresso e às preferências do aluno.
Casos de uso: geração de artigos de pesquisa [42]
No ensino superior, o RAG baseado em agentes tem sido usado para ajudar os pesquisadores a sintetizar as principais descobertas de várias fontes. Por exemplo, os pesquisadores que perguntam "Quais são os últimos avanços na computação quântica?" receberão um resumo conciso com referências, melhorando assim a qualidade e a eficiência de seu trabalho.
Principais benefícios:
- Caminhos de aprendizagem personalizadosAdaptar o conteúdo às necessidades e aos níveis de desempenho de cada aluno.
- Interações envolventesForneça explicações interativas e feedback personalizado.
- escalabilidadeSuporte à implementação em larga escala para uma variedade de ambientes educacionais.
5.6 Aplicativos de aprimoramento de gráficos em fluxos de trabalho multimodais
O Graph Enhanced Agent-based RAG (GEAR) combina estruturas gráficas e mecanismos de recuperação e é particularmente eficaz em fluxos de trabalho multimodais em que as fontes de dados interconectadas são essenciais.
Caso de uso: geração de pesquisa de mercado
A GEAR é capaz de sintetizar textos, imagens e vídeos para uso em campanhas de marketing. Por exemplo, a consulta "Quais são as tendências emergentes em produtos ecologicamente corretos?" gera um relatório detalhado com as preferências do cliente, análise da concorrência e conteúdo multimídia.
Principais benefícios:
- capacidade multimodalIntegração de dados de texto, imagem e vídeo para uma saída abrangente.
- Criatividade aprimoradaGeração de ideias e soluções inovadoras para marketing e entretenimento.
- Adaptação dinâmicaAdaptar-se às mudanças nas tendências do mercado e às necessidades dos clientes.
Os sistemas RAG baseados em agentes são usados em uma ampla variedade de aplicações, demonstrando sua versatilidade e potencial de transformação. Desde o suporte personalizado ao cliente até a educação adaptativa e os fluxos de trabalho multimodais aprimorados por gráficos, esses sistemas abordam desafios complexos, dinâmicos e que exigem muito conhecimento. Ao integrar recuperação, inteligência generativa e de agentes, os sistemas RAG baseados em agentes estão abrindo caminho para a próxima geração de aplicativos de IA.
6 Ferramentas e estruturas para RAG com base em agentes
Os sistemas de geração aprimorada de recuperação (RAG) baseados em agentes representam uma evolução significativa na combinação de recuperação, geração e inteligência de agentes. Esses sistemas ampliam os recursos do RAG tradicional ao integrar a tomada de decisões, a reconstrução de consultas e os fluxos de trabalho adaptáveis. As ferramentas e estruturas a seguir oferecem suporte avançado para o desenvolvimento de sistemas RAG baseados em agentes que atendem aos requisitos complexos de aplicativos do mundo real.
Principais ferramentas e estruturas:
- LangChain e LangGraphLangChain [43] fornece componentes modulares para a criação de pipelines RAG, integrando perfeitamente recuperadores, geradores e ferramentas externas. O LangGraph complementa isso introduzindo processos baseados em gráficos que suportam loops, persistência de estado e interações homem-computador, possibilitando mecanismos sofisticados de orquestração e autocorreção em sistemas de agentes.
- LlamaIndexLlamaIndex's [44] Agent-based Document Workflow (ADW) permite a automação de ponta a ponta do processamento, recuperação e raciocínio estruturado de documentos. Ele apresenta uma arquitetura de meta-agente em que subagentes gerenciam conjuntos menores de documentos e tarefas como análise de conformidade e compreensão contextual são coordenadas por agentes de nível superior.
- Transformadores de rosto abraçado e QdrantHugging Face [45] fornece modelos pré-treinados para tarefas de incorporação e geração, enquanto Qdrant [46] aprimora o fluxo de trabalho de recuperação com recursos de pesquisa vetorial adaptativa, permitindo que os agentes otimizem o desempenho alternando dinamicamente entre métodos de vetores esparsos e densos.
- CrewAI e AutoGencrewAI [47] oferece suporte a processos hierárquicos e sequenciais, sistemas de memória avançados e integração de ferramentas. ag2 [48] (anteriormente conhecido como AutoGen [49, 50]) é excelente em colaboração multiagente com geração avançada de código, execução de ferramentas e suporte a decisões.
- Estrutura do OpenAI Swarm(EN): uma estrutura educacional projetada para permitir a orquestração ergonômica e leve de vários agentes [51], com ênfase na autonomia do agente e na colaboração estruturada.
- RAG baseado em agente com Vertex AIVertex AI [52], desenvolvido pelo Google, integra-se perfeitamente com o Retrieval Augmentation Generation (RAG) baseado em agentes para fornecer uma plataforma para criar, implantar e dimensionar modelos de aprendizado de máquina e, ao mesmo tempo, aproveitar os recursos avançados de IA para fluxos de trabalho avançados de recuperação e tomada de decisões com reconhecimento de contexto.
- Amazon Bedrock para RAGs baseados em agentesAmazon Bedrock [38] fornece uma plataforma avançada para a implementação de fluxos de trabalho RAG (Retrieval Augmentation Generation) baseados em agentes.
- IBM Watson e RAGs baseados em agenteswatsonx.ai [53] da IBM oferece suporte à construção de sistemas RAG baseados em agentes, por exemplo, usando o modelo Granite-3-8B-Instruct para responder a consultas complexas e melhorar a precisão da resposta integrando informações externas.
- Neo4j e bancos de dados vetoriaisNeo4j: O Neo4j, um conhecido banco de dados de gráficos de código aberto, é excelente no tratamento de consultas relacionais e semânticas complexas. Além do Neo4j, bancos de dados vetoriais como Weaviate, Pinecone, Milvus e Qdrant oferecem recursos eficientes de pesquisa e recuperação de similaridade e formam a espinha dorsal de um fluxo de trabalho de geração de aumento de recuperação (RAG) baseado em agente de alto desempenho.
7 Benchmarks e conjuntos de dados
Os benchmarks e conjuntos de dados atuais fornecem informações valiosas para avaliar os sistemas de Geração Aumentada de Recuperação (RAG), inclusive aqueles com aumento de gráficos e baseados em agentes. Embora alguns tenham sido projetados especificamente para RAG, outros foram adaptados para testar os recursos de recuperação, inferência e geração em uma variedade de cenários. Os conjuntos de dados são essenciais para testar os componentes de recuperação, inferência e geração do sistema RAG. A Tabela 3 discute alguns conjuntos de dados importantes para a avaliação do RAG com base em tarefas downstream.
Os benchmarks desempenham um papel fundamental na padronização da avaliação dos sistemas RAG, fornecendo tarefas e indicadores estruturados. Os seguintes benchmarks são particularmente relevantes:
- BEIR (Benchmarking for Information Retrieval)um benchmark versátil projetado para avaliar o desempenho de modelos incorporados em uma variedade de tarefas de recuperação de informações, abrangendo 17 conjuntos de dados que abrangem os domínios de bioinformática, finanças e perguntas e respostas [54].
- MS MARCO (Microsoft Machine Reading Comprehension)Esse parâmetro de comparação é amplamente usado para tarefas de recuperação intensiva em sistemas RAG [55].
- TREC (Conferência de Recuperação de Texto, trilha de aprendizagem profunda)Fornecimento de conjuntos de dados para recuperação de parágrafos e documentos, enfatizando a qualidade dos modelos de classificação no pipeline de recuperação [56].
- MuSiQue (questionamento sequencial de múltiplos saltos)um benchmark para raciocínio multihop em vários documentos, enfatizando a importância de recuperar e sintetizar informações de contextos discretos [57].
- 2WikiMultihopQAUm conjunto de dados projetado para uma tarefa de controle de qualidade de vários saltos em dois artigos da Wikipédia, com foco na capacidade de conectar o conhecimento de várias fontes [58].
- AgentG (RAG baseado em agente para fusão de conhecimento)Benchmarks especificamente adaptados para tarefas RAG baseadas em agentes que avaliam a síntese dinâmica de informações em várias bases de conhecimento [8].
- HotpotQAum benchmark de controle de qualidade multihop que exige recuperação e raciocínio em contextos inter-relacionados, adequado para avaliar fluxos de trabalho RAG complexos [59].
- RAGBenchUm benchmark em larga escala e interpretável contendo 100.000 exemplos em todos os setores da indústria com a estrutura de avaliação TRACe para métricas RAG acionáveis [60].
- BERGEN (benchmarking de geração de aprimoramento de recuperação)RAG: uma biblioteca para avaliar sistematicamente os sistemas RAG com experimentos padronizados [61].
- Kit de ferramentas FlashRAGO RAG é uma ferramenta de avaliação de dados que implementa 12 métodos RAG e inclui 32 conjuntos de dados de referência para apoiar a avaliação RAG eficiente e padronizada [62].
- GNN-RAGEsse benchmark avalia o desempenho dos sistemas RAG baseados em gráficos em tarefas de previsão em nível de nó e de borda, concentrando-se na qualidade da recuperação e no desempenho da inferência no Knowledge Graph Quizzing (KGQA) [63].
Tabela 3: Tarefas downstream e conjuntos de dados avaliados pelo RAG (adaptado de [23])
| formulário | Tipo de missão | Conjuntos de dados e referências |
|---|---|---|
| Perguntas e respostas (QA) | Controle de qualidade de salto único | Natural Questions (NQ) [64], TriviaQA [65], SQuAD [66], Web Questions (WebQ) [67], PopQA [68], MS MARCO [55] |
| QA de múltiplos saltos | HotpotQA[59], 2WikiMultiHopQA[58], MuSiQue[57] | |
| Perguntas e respostas longas | ELI5 [69], NarrativeQA (NQA) [70], ASQA [71], QMSum [72] | |
| Controle de qualidade específico do domínio | Qasper [73], COVID-QA [74], CMB/MMCU Medical [75] | |
| Controle de qualidade de múltipla escolha | QUALITY [76], ARC (sem referência), CommonSenseQA [77] | |
| Figura QA | GraphQA [78] | |
| Perguntas e respostas baseadas em gráficos | Meta-extração da teoria de eventos | WikiEvent[79], RAMS[80] |
| Diálogo de domínio aberto | Wizards of Wikipedia (WoW)[81] | |
| diálogos | Diálogo personalizado | KBP [82], DuleMon [83] |
| Diálogo orientado para tarefas | CamRest[84] | |
| Conteúdo personalizado | Conjunto de dados da Amazon (brinquedos, esportes, beleza) [85] | |
| Raciocínio recomendado | HellaSwag [86], CommonSenseQA [77]. | |
| raciocínio de senso comum | Raciocínio de CoT | Raciocínio CoT [87], CSQA [88] |
| O resto | inferência complexa | MMLU (sem referência), WikiText-103[64] |
| compreensão do idioma | ||
| Verificação/validação de fatos | FEBRE [89], PubHealth [90] | |
| resumos | Resumo do texto de controle de qualidade da estratégia | StrategyQA [91] |
| resumo do texto | WikiASP [92], XSum [93] | |
| Geração de texto | resumo longo | NarrativeQA (NQA) [70], QMSum [72] |
| categorização de texto | história | Conjunto de dados biográficos (sem referência), SST-2 [94] |
| Classificação geral da análise de sentimentos | ||
| Pesquisa de código | Pesquisa de programação | VioLens [95], TREC [56], CodeSearchNet [96] |
| robustez | robustez da recuperação | NoMIRACL [97] |
| Robustez da modelagem de idiomas | WikiText-103 [98] | |
| matemática | raciocínio matemático | GSM8K [99] |
| tradução automática | tarefa de tradução | JRC-Acquis [100] |
8 Conclusão
O Retrieval Augmented Generation (RAG) baseado em agentes representa um avanço transformador na inteligência artificial que supera as limitações dos sistemas RAG tradicionais por meio da integração de agentes autônomos. Ao aproveitar a inteligência do agente, esses sistemas introduzem a capacidade de tomada de decisão dinâmica, raciocínio iterativo e fluxos de trabalho colaborativos, permitindo que eles resolvam tarefas complexas do mundo real com maior precisão e adaptabilidade.
Esta análise explora a evolução dos sistemas RAG desde as implementações iniciais até paradigmas avançados, como o RAG modular, destacando as contribuições e limitações de cada paradigma. A integração de agentes nos processos de RAG tornou-se um desenvolvimento importante, levando ao surgimento de sistemas de RAG baseados em agentes que superam os fluxos de trabalho estáticos e a adaptabilidade contextual limitada. Aplicativos nos setores de saúde, finanças, educação e criação demonstram o potencial transformador desses sistemas, evidenciando sua capacidade de oferecer soluções personalizadas, em tempo real e sensíveis ao contexto.
Apesar de sua promessa, os sistemas RAG baseados em agentes enfrentam desafios que exigem mais pesquisa e inovação. A complexidade da coordenação, a escalabilidade e os problemas de latência em arquiteturas de vários agentes, bem como as considerações éticas, devem ser abordados para garantir uma implantação robusta e responsável. Além disso, a falta de benchmarks e conjuntos de dados projetados especificamente para avaliar os recursos dos agentes representa uma barreira significativa. O desenvolvimento de métodos de avaliação para capturar aspectos exclusivos da RAG baseada em agentes, como a colaboração entre vários agentes e a adaptabilidade dinâmica, é fundamental para o avanço do campo.
Olhando para o futuro, a convergência da geração aprimorada por recuperação e da inteligência de agentes tem o potencial de redefinir o papel da IA em ambientes dinâmicos e complexos. Ao enfrentar esses desafios e explorar direções futuras, os pesquisadores e profissionais podem liberar todo o potencial dos sistemas RAG baseados em agentes, abrindo caminho para aplicações transformadoras em todos os setores e domínios. À medida que os sistemas de IA continuam a evoluir, o RAG baseado em agentes serve como pedra angular para a criação de soluções adaptáveis, conscientes do contexto e impactantes que atendam às necessidades de um mundo em rápida mudança.
bibliografia
[1] Shervin Minaee, Tomas Mikolov, Narjes Nikzad, Meysam Chenaghlu, Richard Socher, Xavier Amatriain eJianfeng Gao. Modelos de linguagem grandes: uma pesquisa, 2024.
[2] Aditi Singh. Explorando modelos de linguagem: uma pesquisa e análise abrangentes. in 2023 Conferência Internacional sobre Metodologias de Pesquisa em Gestão do Conhecimento, Inteligência Artificial e Telecomunicações.
Engineering (RMKMATE), páginas 1-4, 2023.
[3] Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang.
Junjie Zhang, Zican Dong, Yifan Du, Chen Yang, Yushuo Chen, Zhipeng Chen, Jinhao Jiang, Ruiyang Ren.
Yifan Li, Xinyu Tang, Zikang Liu, Peiyu Liu, Jian-Yun Nie e Ji-Rong Wen. Uma pesquisa de grandes linguagens
modelos, 2024.
[4] Sumit Kumar Dam, Choong Seon Hong, Yu Qiao e Chaoning Zhang. Uma pesquisa completa sobre IA baseada em llm
chatbots, 2024.
[5] Aditi Singh. A survey of ai text-to-image and ai text-to-video generators (Uma pesquisa de geradores de texto para imagem e texto para vídeo com IA). in 2023 4th International Conference
sobre Inteligência Artificial, Robótica e Controle (AIRC), páginas 32-36, 2023.
[6] Aditi Singh, Abul Ehtesham, Gaurav Kumar Gupta, Nikhil Kumar Chatta, Saket Kumar e Tala Talaei Khoei.
Explorando a engenharia imediata: uma revisão sistemática com análise swot, 2024.
[7] Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qianglong Chen, Weihua
Peng, Xiaocheng Feng, Bing Qin e Ting Liu. Uma pesquisa sobre alucinação em grandes modelos de linguagem: Princípios,
ACM Transactions on Information Systems, novembro de 2024.
[8] Meng-Chieh Lee, Qi Zhu, Costas Mavromatis, Zhen Han, Soji Adeshina, Vassilis N. Ioannidis, Huzefa Rangwala.
e Christos Faloutsos. agent-g: An agentic framework for graph retrieval augmented generation, 2024.
[9] Penghao Zhao, Hailin Zhang, Qinhan Yu, Zhengren Wang, Yunteng Geng, Fangcheng Fu, Ling Yang, Wentao
Zhang, Jie Jiang e Bin Cui. Retrieval-augmented generation for ai-generated content: a survey, 2024.
[10] Zhengbao Jiang, Frank F. Xu, Luyu Gao, Zhiqing Sun, Qian Liu, Jane Dwivedi-Yu, Yiming Yang, Jamie Callan.
e Graham Neubig. active retrieval augmented generation, 2023.
[11] Yikun Han, Chunjiang Liu e Pengfei Wang. Uma pesquisa abrangente sobre banco de dados vetorial: armazenamento e recuperação
técnica, desafio, 2023.
[12] Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang.
Xu Chen, Yankai Lin, Wayne Xin Zhao, Zhewei Wei e Jirong Wen. Uma pesquisa sobre modelos de linguagem grandes baseados em
Fronteiras de Computador Science, 18(6), março de 2024.
[13] Aditi Singh, Saket Kumar, Abul Ehtesham, Tala Talaei Khoei e Deepshikha Bhati. large language modeldriven immersive agent. em 2024 IEEE World AI IoT Congress (AIIoT), páginas 0619-0624, 2024.
[14] Matthew Renze e Erhan Guven, Self-reflection in llm agents: effects on problem-solving performance, 2024.
[15] Xu Huang, Weiwen Liu, Xiaolong Chen, Xingmei Wang, Hao Wang, Defu Lian, Yasheng Wang, Ruiming Tang.
Entendendo o planejamento dos agentes de MLM: uma pesquisa, 2024.
[16] Taicheng Guo, Xiuying Chen, Yaqi Wang, Ruidi Chang, Shichao Pei, Nitesh V. Chawla, Olaf Wiest e
Xiangliang Zhang, Large language model based multi-agents: a survey of progress and challenges, 2024.
[17] Chidaksh Ravuru, Sagar Srinivas Sakhinana e Venkataramana Runkana.
geração para análise de séries temporais, 2024.
[18] Jie Huang e Kevin Chen-Chuan Chang, Towards reasoning in large language models: a survey, 2023.
[19] Boci Peng, Yun Zhu, Yongchao Liu, Xiaohe Bo, Haizhou Shi, Chuntao Hong, Yan Zhang e Siliang Tang.
Geração aumentada por recuperação de gráficos: uma pesquisa, 2024.
[20] Aditi Singh, Abul Ehtesham, Saifuddin Mahmud e Jong-Hoon Kim Revolutionising mental health care (Revolucionando os cuidados com a saúde mental)
através da langchain: uma jornada com um grande modelo de linguagem. Em 2024, IEEE 14th Annual Computing and
Workshop e Conferência de Comunicação (CCWC), páginas 0073-0078, 2024.
[21] Gaurav Kumar Gupta, Aditi Singh, Sijo Valayakkad Manikandan e Abul Ehtesham. digital diagnostics: the
potencial de grandes modelos de linguagem no reconhecimento de sintomas de doenças comuns, 2024.
[22] Aditi Singh, Abul Ehtesham, Saket Kumar, Gaurav Kumar Gupta e Tala Talaei Khoei.
Uso de IA generativa na educação: uma abordagem de aprendizagem baseada em recompensas. Em Tim Schlippe, Eric C. K. Cheng e
Tianchong Wang, editores, Artificial Intelligence in Education Technologies: New Development and Innovative
Practices, páginas 404-413, Cingapura, 2025, Springer Nature Singapore.
[23] Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, Meng Wang e
Haofen Wang. Retrieval-augmented generation for large language models: a survey, 2024.
[24] Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen e Wen ˘
tau Yih. Recuperação de passagens densas para respostas a perguntas de domínio aberto, 2020.
[25] Zeyu Zhang, Xiaohe Bo, Chen Ma, Rui Li, Xu Chen, Quanyu Dai, Jieming Zhu, Zhenhua Dong e Ji-Rong
Wen. Uma pesquisa sobre o mecanismo de memória de grandes agentes baseados em modelos de linguagem, 2024.
[26] Zhibin Gou, Zhihong Shao, Yeyun Gong, Yelong Shen, Yujiu Yang, Nan Duan e Weizhu Chen. Crítica: Grande
Os modelos de linguagem podem se autocorrigir com a crítica interativa da ferramenta, 2024.
[27] Aditi Singh, Abul Ehtesham, Saket Kumar e Tala Talaei Khoei. Aprimorando os sistemas de IA com fluxos de trabalho agênticos
Em 2024, IEEE World AI IoT Congress (AIIoT), páginas 527-532, 2024.
[28] DeepLearning.AI. How agents can improve llm performance (Como os agentes podem melhorar o desempenho do LLM). https://www.deeplearning.ai/the-batch/
how-agents-can-improve-llm-performance/?ref=dl-staging-website.ghost.io, 2024. acessado em: 2025-01-13.
[29] Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha
Dziri, Shrimai Prabhumoye, Yiming Yang, Shashank Gupta, Bodhisattwa Prasad Majumder, Katherine Hermann.
Sean Welleck, Amir Yazdanbakhsh e Peter Clark. self-refine: Iterative refinement with self-feedback, 2023.
[30] Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan e Shunyu Yao.
Reflexion: agentes de linguagem com aprendizado por reforço verbal, 2023.
[31] Weaviate Blog. O que é agentic rag? https://weaviate.io/blog/what-is-agentic-rag#:~:text=is%
20Agentic%20RAG%3F-,%E2%80%8B,of%20the%20non%2Dagentic%20pipeline. Accessed: 2025-01-14.
[32] Shi-Qi Yan, Jia-Chen Gu, Yun Zhu e Zhen-Hua Ling. Corrective retrieval augmented generation, 2024.
[33] LangGraph Tutorial CRAG. langgraph crag: Contextualised retrieval-augmented generation tutorial. https.
//langchain-ai.github.io/langgraph/tutorials/rag/langgraph_crag/. Acessado em: 2025-01-14.
[34] Soyeong Jeong, Jinheon Baek, Sukmin Cho, Sung Ju Hwang e Jong C. Park. Adaptive-rag: aprendendo a se adaptar
modelos de linguagem de grande porte com reforço de recuperação por meio da complexidade das perguntas, 2024.
[35] LangGraph Adaptive RAG Tutorial. langgraph adaptive rag: Adaptive retrieval-augmented generation tutorial. https://langchain-ai.github.io /langgraph/tutorials/rag/langgraph_adaptive_rag/.
Acessado em: 2025-01-14.
[36] Zhili Shen, Chenxin Diao, Pavlos Vougiouklis, Pascual Merita, Shriram Piramanayagam, Damien Graux, Dandan
Tu, Zeren Jiang, Ruofei Lai, Yang Ren e Jeff Z. Pan. Gear: agente aprimorado por gráfico para recuperação aumentada
geração, 2024.
[37] LlamaIndex. Introduzindo fluxos de trabalho de documentos autênticos. https://www.llamaindex.ai/blog/
introducing-agentic-document-workflows, 2025. acessado em: 2025-01-13.
[38] Blog de aprendizado de máquina da AWS. como a twitch usou o fluxo de trabalho agêntico com o rag na amazon
bedrock para turbinar as vendas de anúncios. https://aws.amazon.com/blogs/machine-learning/
how-twitch-used-agentic-workflow-with-rags-on-amazon-bedrock-to-supercharge-ad-sales/,
2025 Acesso em: 2025-01-13.
[39] LlamaCloud Demo Repository. fluxo de trabalho de resumo do caso do paciente usando o LlamaCloud. https.
//github.com/run-llama/llamacloud-demo/blob/main/examples/document_workflows/
patient_case_summary/patient_case_summary.ipynb, 2025. acessado em: 2025-01-13.
[40] LlamaCloud Demo Repository. fluxo de trabalho de revisão de contrato usando llamacloud. https://github.com/
run-llama/llamacloud-demo/blob/main/examples/document_workflows/contract_review/
contract_review.ipynb, 2025. acessado em: 2025-01-13.
[41] LlamaCloud Demo Repository. fluxo de trabalho de reclamações de seguro de automóveis usando llamacloud. https.
//github.com/run-llama/llamacloud-demo/blob/main/examples/document_workflows/auto_
insurance_claims/auto_insurance_claims.ipynb, 2025. acessado em: 2025-01-13.
[42] LlamaCloud Demo Repository. fluxo de trabalho de geração de relatórios de artigos de pesquisa usando o LlamaCloud.
https://github.com/run-llama/llamacloud-demo/blob/main/examples/report_generation/
research_paper_report_generation.ipynb, 2025. acessado em: 2025-01-13.
[43] LangGraph Agentic RAG Tutorial. langgraph agentic rag: Nodes and edges tutorial. https://langchain-ai.
github.io/langgraph/tutorials/rag/langgraph_agentic_rag/#nodes-and-edges. acessado.
2025-01-14.
[44] Blog do LlamaIndex. trapo autêntico com llamaindex. https://www.llamaindex.ai/blog/
agentic-rag-with-llamaindex-2721b8a49ff6. Accessed: 2025-01-14.
[45] Hugging Face Cookbook. agentic rag: Turbine sua geração aumentada de recuperação com reformulação de consulta e autoconsulta. https:// Huggingface.co/learn/cookbook/en/agent_rag. Acessado em: 2025-01-14.
[46] Qdrant Blog. agentic rag: combinando rag com agentes para recuperação aprimorada de informações. https://qdrant.
tech/articles/agentic-rag/. Acessado em: 2025-01-14.
[47] tripulaçãoAI Inc. crewai: um repositório do github para projetos de IA. https://github.com/crewAIInc/crewAI, 2025.
Acessado em: 2025-01-15.
[48] Contribuidores da AG2AI. Ag2: Um repositório do github para pesquisa avançada de IA generativa. https://github.com/
ag2ai/ag2, 2025. acessado em: 2025-01-15.
[49] Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun
Zhang, Jiale Liu, Ahmed Hassan Awadallah, Ryen W White, Doug Burger e Chi Wang. AutógenoHabilitação
aplicativos llm de próxima geração por meio de uma estrutura de conversação multiagente. 2023.
[50] Shaokun Zhang, Jieyu Zhang, Jiale Liu, Linxin Song, Chi Wang, Ranjay Krishna e Qingyun Wu. Treinamento
agentes de modelos de linguagem sem modificar modelos de linguagem. ICML'24, 2024.
[51] OpenAI. EnxameEstrutura leve de orquestração de vários agentes. https://github.com/openai/swarm.
Acessado em: 2025-01-14.
[52] Documentação do LlamaIndex. trapo autêntico usando o vértice ai. https://docs.llamaindex.ai/en/stable/
examples/agent/agentic_rag_using_vertex_ai/. Acessado em: 2025-01-14.
[53] IBM Granite Community. Agentic rag: Agentes de IA com modelos ibm granite. https://github.com/
ibm-granite-community/granite-snack-cookbook/blob/main/recipes/AI-Agents/Agentic_
RAG.ipynb. Acessado em: 2025-01-14.
[54] Nandan Thakur, Nils Reimers, Andreas Rücklé, Abhishek Srivastava e Iryna Gurevych. Beir: um sistema heterogêneo
benchmark para a avaliação de zero-shot de modelos de recuperação de informações, 2021.
[55] Payal Bajaj, Daniel Campos, Nick Craswell, Li Deng, Jianfeng Gao, Xiaodong Liu, Rangan Majumder, Andrew
McNamara, Bhaskar Mitra, Tri Nguyen, Mir Rosenberg, Xia Song, Alina Stoica, Saurabh Tiwary e Tong
Wang. ms marco: um conjunto de dados de compreensão de leitura de máquina gerada por humanos, 2018.
[56] Nick Craswell, Bhaskar Mitra, Emine Yilmaz, Daniel Campos, Jimmy Lin, Ellen M. Voorhees e Ian Soboroff.
Visão geral da trilha de aprendizagem profunda da trec 2022. na Text REtrieval Conference (TREC). NIST, TREC, março de 2023.
[57] Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot e Ashish Sabharwal. musique: multihop questions
por meio da composição de perguntas de um único salto, 2022.
[58] Xanh Ho, Anh-Khoa Duong Nguyen, Saku Sugawara e Akiko Aizawa. Construção de um conjunto de dados de qa multihop
para uma avaliação abrangente das etapas de raciocínio, 2020.
[59] Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William W. Cohen, Ruslan Salakhutdinov e Christopher D. Manning. hotpotqa: um conjunto de dados para resposta diversificada e explicável a perguntas de múltiplos saltos, 2018.
[60] Robert Friel, Masha Belyi e Atindriyo Sanyal. Ragbench: referência explicável para recuperação aumentada
Sistemas de geração, 2024.
[61] David Rau, Hervé Déjean, Nadezhda Chirkova, Thibault Formal, Shuai Wang, Vassilina Nikoulina e Stéphane
Clinchant. Bergen: uma biblioteca de benchmarking para geração aumentada por recuperação, 2024.
[62] Jiajie Jin, Yutao Zhu, Xinyu Yang, Chenghao Zhang e Zhicheng Dou. Flashrag: um kit de ferramentas modular para a
pesquisa de geração aumentada por recuperação, 2024.
[63] Costas Mavromatis e George Karypis Gnn-rag: Graph neural retrieval for large language model reasoning.
2024.
[64] Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle
Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, Kristina Toutanova, Llion Jones, Matthew Kelcey, Ming-Wei
Chang, Andrew M. Dai, Jakob Uszkoreit, Quoc Le e Slav Petrov. Natural questions: a benchmark for question
Transactions of the Association for Computational Linguistics, 7:452-466, 2019.
[65] Mandar Joshi, Eunsol Choi, Daniel S. Weld e Luke Zettlemoyer. triviaqa: a large scale distantly supervised
conjunto de dados de desafio para compreensão de leitura, 2017.
[66] Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev e Percy Liang. Squad: 100.000+ questions for machine
compreensão de texto, 2016.
[67] Jonathan Berant, Andrew K. Chou, Roy Frostig e Percy Liang. Semantic parsing on freebase from questionanswer pairs. in Conference on Empirical Empirical Methods in Natural Language Processing, 2013.
[68] Alex Mallen, Akari Asai, Victor Zhong, Rajarshi Das, Daniel Khashabi e Hannaneh Hajishirzi. when not to
trust language models: investigating effectiveness of parametric and non-parametric memories. em Anna Rogers,
Jordan Boyd-Graber e Naoaki Okazaki, editores, Proceedings of the 61st Annual Meeting of the Association for
Computational Linguistics (Volume 1: Long Papers), páginas 9802-9822, Toronto, Canadá, julho de 2023.
para a Linguística Computacional.
[69] Angela Fan, Yacine Jernite, Ethan Perez, David Grangier, Jason Weston e Michael Auli. Eli5: forma longa
Resposta a perguntas, 2019.
[70] Tomáš Kociský, Jonathan Schwarz, Phil Blunsom, Chris Dyer, Karl Moritz Hermann, Gábor Melis e Edward ˇ
Grefenstette. o desafio de compreensão de leitura da narrativeqa. 2017.
[71] Ivan Stelmakh, Yi Luan, Bhuwan Dhingra e Ming-Wei Chang. Asqa: Factoid questions meet long-form
respostas, 2023.
[72] Ming Zhong, Da Yin, Tao Yu, Ahmad Zaidi, Mutethia Mutuma, Rahul Jha, Ahmed Hassan Awadallah, Asli
Celikyilmaz, Yang Liu, Xipeng Qiu e Dragomir Radev. QMSum: Um novo benchmark para consultas baseadas em
Multi-domain meeting summarization. páginas 5905-5921, junho de 2021.
[73] Pradeep Dasigi, Kyle Lo, Iz Beltagy, Arman Cohan, Noah A. Smith e Matt Gardner. um conjunto de dados de perguntas e respostas de busca de informações ancoradas em artigos de pesquisa. em Kristina Toutanova, Anna Rumshisky, Luke
Zettlemoyer, Dilek Hakkani-Tur, Iz Beltagy, Steven Bethard, Ryan Cotterell, Tanmoy Chakraborty e Yichao
Zhou, editores, Proceedings of the 2021 Conference of the North American Chapter of the Association for
Computational Linguistics: Human Language Technologies, páginas 4599-4610, Online, junho de 2021.
para a Linguística Computacional.
[74] Timo Möller, Anthony Reina, Raghavan Jayakumar e Malte Pietsch. COVID-QA: A question answering
conjunto de dados para COVID-19. no Workshop ACL 2020 sobre processamento de linguagem natural para COVID-19 (NLP-COVID),.
2020.
[75] Xidong Wang, Guiming Hardy Chen, Dingjie Song, Zhiyi Zhang, Zhihong Chen, Qingying Xiao, Feng Jiang.
Jianquan Li, Xiang Wan, Benyou Wang e Haizhou Li. Cmb: uma referência médica abrangente em chinês.
2024.
[76] Richard Yuanzhe Pang, Alicia Parrish, Nitish Joshi, Nikita Nangia, Jason Phang, Angelica Chen, Vishakh
Padmakumar, Johnny Ma, Jana Thompson, He He e Samuel R. Bowman. quality: question answering with
textos de entrada longos, sim!, 2022.
[77] Alon Talmor, Jonathan Herzig, Nicholas Lourie e Jonathan Berant. commonsenseQA: A question answering
challenge targeting commonsense knowledge. em Jill Burstein, Christy Doran e Thamar Solorio, editores.
Anais da Conferência de 2019 do Capítulo Norte-Americano da Association for Computational
Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), páginas 4149-4158, Minneapolis, Estados Unidos.
Minnesota, junho de 2019. association for Computational Linguistics.
[78] Xiaoxin He, Yijun Tian, Yifei Sun, Nitesh V. Chawla, Thomas Laurent, Yann LeCun, Xavier Bresson e Bryan
Hooi. g-retriever: geração aumentada por recuperação para compreensão de gráficos textuais e resposta a perguntas.
2024.
[79] Sha Li, Heng Ji e Jiawei Han. Extração de argumentos de eventos em nível de documento por geração condicional, 2021.
[80] Seth Ebner, Patrick Xia, Ryan Culkin, Kyle Rawlins e Benjamin Van Durme. Argumento de várias sentenças
vinculação, 2020.
[81] Emily Dinan, Stephen Roller, Kurt Shuster, Angela Fan, Michael Auli e Jason Weston. wizard of wikipedia.
Agentes de conversação com base no conhecimento, 2019.
[82] Hongru Wang, Minda Hu, Yang Deng, Rui Wang, Fei Mi, Weichao Wang, Yasheng Wang, Wai-Chung Kwan.
Irwin King e Kam-Fai Wong. Modelos de linguagem grandes como planejador de fontes para conhecimento personalizado baseado em
diálogo, 2023.
[83] Xinchao Xu, Zhibin Gou, Wenquan Wu, Zheng-Yu Niu, Hua Wu, Haifeng Wang e Shihang Wang.
conversa de domínio aberto com memória pessoal de longo prazo, 2022.
[84] Tsung-Hsien Wen, Milica Gašic, Nikola Mrkši' c, Lina M. Rojas-Barahona, Pei-Hao Su, Stefan Ultes, David '
Vandyke e Steve Young. Geração condicional e aprendizado de instantâneos em sistemas de diálogo neural.
Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, pages 2153-2162, em Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing.
Austin, Texas, novembro de 2016. association for Computational Linguistics.
[85] Ruining He e Julian McAuley, "Ups and downs: modelling the visual evolution of fashion trends with one-class
em Proceedings of the 25th International Conference on World Wide Web, WWW '16, page
507-517, República e Cantão de Genebra, CHE, 2016. Conferências internacionais sobre a World Wide Web Direção
Comitê.
[86] Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi e Yejin Choi. HellaSwag: uma máquina pode realmente
Em Anna Korhonen, David Traum e Lluís Màrquez, editores, Proceedings of the 57th session of the Commission on Human Rights.
Reunião anual da Association for Computational Linguistics, páginas 4791-4800, Florença, Itália, julho de 2019.
Associação de Linguística Computacional.
[87] Seungone Kim, Se June Joo, Doyoung Kim, Joel Jang, Seonghyeon Ye, Jamin Shin e Minjoon Seo.
coleção cot: aprimoramento do aprendizado de modelos de linguagem com zero e poucos disparos por meio do ajuste fino da cadeia de raciocínio,
2023.
[88] Amrita Saha, Vardaan Pahuja, Mitesh M. Khapra, Karthik Sankaranarayanan e Sarath Chandar, Complex.
Resposta sequencial a perguntas: para aprender a conversar sobre pares de respostas a perguntas vinculadas com um conhecimento
graph. 2018.
[89] James Thorne, Andreas Vlachos, Christos Christodoulopoulos e Arpit Mittal. FEVER: um conjunto de dados em grande escala para
extração de fatos e VERificação. em Marilyn Walker, Heng Ji e Amanda Stent, editores, Proceedings of the 2018
Conferência do Capítulo Norte-Americano da Associação para Linguística Computacional: Linguagem Humana
Technologies, Volume 1 (Long Papers), páginas 809-819, Nova Orleans, Louisiana, junho de 2018. association for
Linguística computacional.
[90] Neema Kotonya e Francesca Toni, Explainable automated fact-checking for public health claims, 2020.
[91] Mor Geva, Daniel Khashabi, Elad Segal, Tushar Khot, Dan Roth e Jonathan Berant. did aristotle use a laptop?
uma referência de resposta a perguntas com estratégias de raciocínio implícito, 2021.
[92] Hiroaki Hayashi, Prashant Budania, Peng Wang, Chris Ackerson, Raj Neervannan e Graham Neubig. Wikiasp.
Um conjunto de dados para resumo baseado em aspectos de vários domínios, 2020.
[93] Shashi Narayan, Shay B. Cohen e Mirella Lapata. Não me dê os detalhes, apenas o resumo!
redes neurais convolucionais para resumo extremo, 2018.
[94] Richard Socher, Alex Perelygin, Jean Wu, Jason Chuang, Christopher D. Manning, Andrew Ng e Christopher
Potts. Recursive deep models for semantic compositionality over a sentiment treebank. em David Yarowsky,
Timothy Baldwin, Anna Korhonen, Karen Livescu e Steven Bethard, editores, Proceedings of the 2013
Conference on Empirical Methods in Natural Language Processing, páginas 1631-1642, Seattle, Washington.
EUA, outubro de 2013, Associação de Linguística Computacional.
[95] Sourav Saha, Jahedul Alam Junaed, Maryam Saleki, Arnab Sen Sharma, Mohammad Rashidujjaman Rifat.
Mohamed Rahouti, Syed Ishtiaque Ahmed, Nabeel Mohammed e Mohammad Ruhul Amin. Vio-lens: a novel
Conjunto de dados de postagens anotadas em redes sociais que levam a diferentes formas de violência comunitária e sua avaliação.
Firoj Alam, Sudipta Kar, Shammur Absar Chowdhury, Farig Sadeque e Ruhul Amin, editores, Proceedings
do First Workshop on Bangla Language Processing (BLP-2023), páginas 72-84, Cingapura, dezembro de 2023.
Associação de Linguística Computacional.
[96] Hamel Husain, Ho-Hsiang Wu, Tiferet Gazit, Miltiadis Allamanis e Marc Brockschmidt. Codesearchnet
desafio: Avaliando o estado da pesquisa de código semântico, 2020.
[97] Nandan Thakur, Luiz Bonifacio, Xinyu Zhang, Odunayo Ogundepo, Ehsan Kamalloo, David Alfonso-Hermelo.
Xiaoguang Li, Qun Liu, Boxing Chen, Mehdi Rezagholizadeh e Jimmy Lin. "knowing when you don't know" (sabendo quando você não sabe).
Um conjunto de dados de avaliação de relevância multilíngue para geração robusta de recuperação aumentada, 2024.
[98] Stephen Merity, Caiming Xiong, James Bradbury e Richard Socher. pointer sentinel mixture models, 2016.
[99] Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert.
Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse e John Schulman. treinamento de verificadores para
resolver problemas de matemática, 2021.
[100] Ralf Steinberger, Bruno Pouliquen, Anna Widiger, Camelia Ignat, Tomaž Erjavec, Dan Tufi¸s e Dániel Varga.
O JRC-Acquis: um corpus paralelo alinhado multilíngue com mais de 20 idiomas. Em Nicoletta Calzolari, Khalid
Choukri, Aldo Gangemi, Bente Maegaard, Joseph Mariani, Jan Odijk e Daniel Tapias, editores, Proceedings of
a Quinta Conferência Internacional sobre Recursos e Avaliação de Idiomas (LREC'06), Gênova, Itália, maio de 2006.
Associação Europeia de Recursos Linguísticos (ELRA).
© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Artigos relacionados

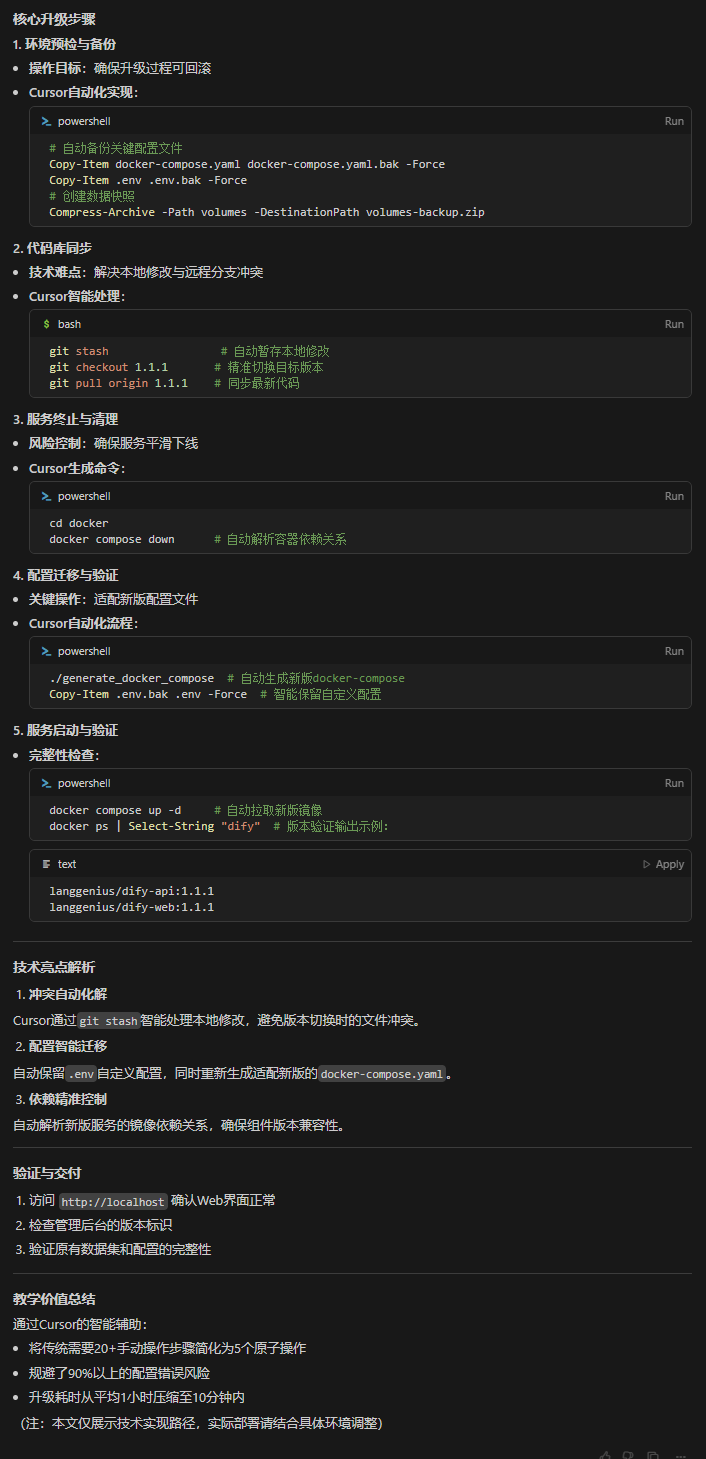

Nenhum comentário...