
Um artigo para levá-lo a entender o RAG (Retrieval Augmented Generation), o conceito de introdução teórica + prática de código
I. Os LLMs já têm recursos avançados, por que precisamos do RAG (Retrieval Augmentation Generation)?
Embora o LLM tenha demonstrado capacidades significativas, vários desafios continuam sendo motivo de preocupação:
- Problema de ilusão: o LLM usa uma abordagem probabilística baseada em estatística para gerar texto palavra por palavra, um mecanismo que inerentemente leva à possibilidade de resultados que parecem ser logicamente rigorosos, mas não são baseados em fatos, as chamadas "declarações fictícias solenes";
- (a) Problemas de pontualidade: à medida que o LLM cresce, o custo e o tempo de ciclo do treinamento aumentam. Como resultado, é difícil incorporar dados com informações atualizadas ao processo de treinamento do modelo, tornando o LLM menos capaz de lidar com questões sensíveis ao tempo, como "sugira o filme favorito atual";
- Problemas de segurança de dados: o LLM genérico não tem dados internos da empresa e dados do usuário; então as empresas querem usar o LLM sob a premissa de garantir a segurança, a melhor maneira é colocar todos os dados localmente, e todos os cálculos comerciais dos dados da empresa são feitos localmente. O big model on-line completa apenas uma função de resumo;
II - Apresentando o RAG?
RAG (Retrieval Augmented Generation) é uma estrutura tecnológica, cujo núcleo está no fato de que, quando o LLM se depara com a tarefa de responder a uma pergunta ou criar um texto, ele primeiro pesquisa a biblioteca de documentos em grande escala e filtra os materiais que estão intimamente relacionados à tarefa e, em seguida, orienta o processo subsequente de geração de respostas ou de construção de texto com base nesses materiais com precisão, com o objetivo de melhorar a precisão e a confiabilidade do resultado do modelo dessa forma. O objetivo é melhorar a precisão e a confiabilidade do resultado do modelo dessa forma.
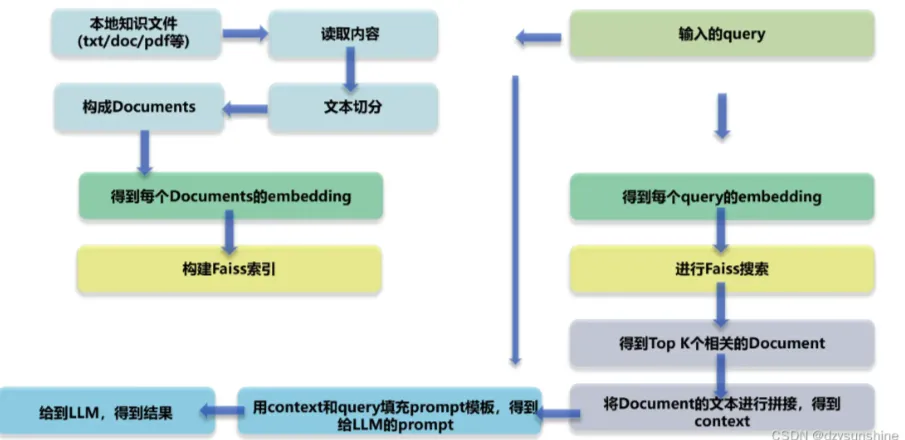
RAG Diagrama de arquitetura técnica
III Quais são os principais módulos do RAG?
- Módulo 1: Análise de layout
- Leitura de arquivos de conhecimento local (pdf, txt, html, doc, excel, png, jpg, voz, etc.)
- Recuperação de documentos de conhecimento
- Módulo II: Criando a base de conhecimento
- Segmentação de textos de conhecimento e construção de textos de documentos
- Incorporação de texto de documento
- Índice de construção de texto do documento
- Módulo 3: Ajuste fino do grande modelo
- Módulo IV: Teste de conhecimento baseado em RAG
- Incorporação da consulta do usuário
- consulta Recuperação
- classificação de consultas
- Os principais K documentos relevantes foram unidos para construir o contexto
- Criação de prompts com base na consulta e no contexto
- Envie o prompt para o modelo grande para gerar a resposta
Quais são as vantagens do RAG em relação ao uso de LLMs diretamente para questionários?
A abordagem RAG (Retrieval Augmented Generation) permite que os desenvolvedores melhorem significativamente a precisão de suas respostas sem precisar treinar novamente modelos grandes para cada tarefa específica, simplesmente conectando-se a uma base de conhecimento externa que pode ser injetada com recursos de informações adicionais. Essa abordagem é especialmente adequada para tarefas que dependem muito de conhecimento especializado. Veja a seguir os principais benefícios do modelo RAG:
- Escalabilidade: reduza o tamanho do modelo e as despesas gerais de treinamento, simplificando o processo de expansão e atualização da base de conhecimento.
- Precisão: ao citar as fontes, os usuários podem verificar a credibilidade das respostas, o que, por sua vez, aumenta sua confiança nos resultados do modelo.
- Controlabilidade: oferece suporte à atualização flexível e à configuração personalizada do conteúdo do conhecimento.
- Interpretabilidade: mostra as entradas de pesquisa das quais dependem as previsões do modelo, melhorando a compreensão e a transparência.
- Versatilidade: o RAG pode ser ajustado e personalizado para se adequar a uma ampla gama de cenários de aplicativos, abrangendo áreas como perguntas e respostas, resumo de textos e sistemas de diálogo.
- Pontualidade: o uso de técnicas de recuperação para capturar os últimos desenvolvimentos de informações garante que as respostas sejam imediatas e precisas, uma clara vantagem sobre os modelos de linguagem que dependem apenas de dados de treinamento intrínsecos.
- Personalização de domínio: ao mapear conjuntos de dados de texto para setores ou domínios específicos, o RAG pode oferecer suporte especializado direcionado.
- Segurança: ao implementar o particionamento de funções e o controle de segurança no nível do banco de dados, o RAG fortalece efetivamente o gerenciamento do uso de dados, demonstrando maior segurança do que a possível ambiguidade dos modelos de ajuste fino para o gerenciamento de direitos de dados.
V. Compare e contraste o RAG e o SFT e diga-nos quais são as diferenças?
De fato, a SFT é uma das soluções mais comuns e básicas para os problemas de LLM mencionados acima, além de ser uma etapa fundamental na realização de aplicativos de LLM. Em seguida, é necessário comparar as duas abordagens em várias dimensões:
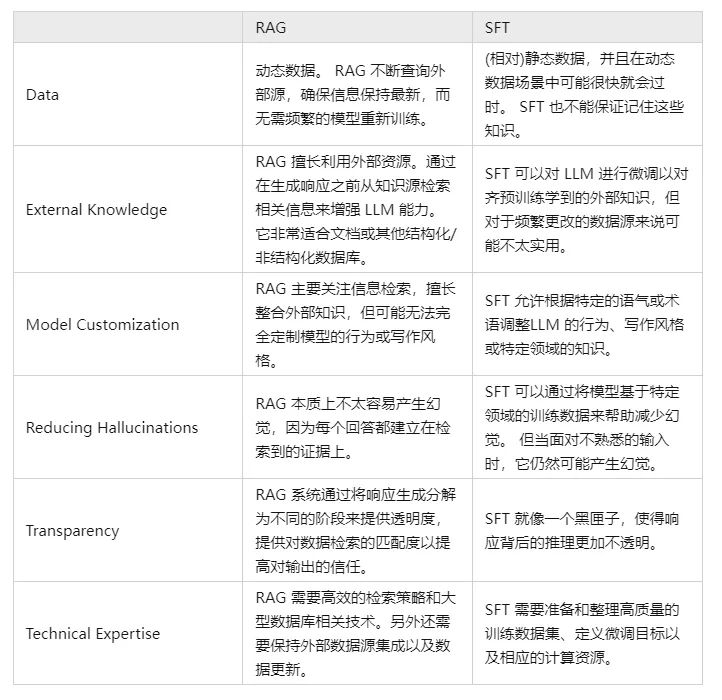
Obviamente, esses dois métodos não são uma coisa ou outra, e é razoável e necessário combinar as necessidades comerciais com as vantagens de ambos os métodos e usá-los de maneira razoável.
Módulo 1: Análise de layout
Por que preciso de uma análise de layout?
Embora o valor central da tecnologia RAG (Retrieval Augmented Generation) esteja em sua combinação de recuperação e geração para melhorar a precisão e a coerência do conteúdo textual, seus limites funcionais podem ser ampliados para incluir a análise de layout em domínios de aplicativos específicos, como análise de documentos, criação inteligente e construção de diálogos, especialmente quando confrontados com a necessidade de processar informações estruturadas ou semiestruturadas.
Isso se deve ao fato de que esse tipo de informação geralmente é incorporado a uma estrutura de layout específica que exige um profundo entendimento dos elementos da página e de suas inter-relações.
Além disso, quando o modelo RAG é confrontado com fontes de dados que contêm componentes multimídia ou multimodais ricos, como páginas da Web, arquivos PDF, registros de rich text, documentos do Word, dados de imagem, clipes de voz, dados tabulares e outros conteúdos complexos, torna-se fundamental ter um recurso básico de análise de layout para poder ingerir e utilizar com eficiência essas informações não textuais. Essa capacidade ajuda o modelo a analisar com precisão as várias unidades de informação e a integrá-las com sucesso em uma interpretação geral significativa.
etapa 1: aquisição de documentos de conhecimento local
P1: Como fazer a aquisição de documentos de conhecimento local?
O acesso a arquivos de conhecimento local envolve o processo de extração de informações de várias fontes de dados (por exemplo, .txt, .pdf, .html, .doc, .xlsx, .png, .jpg, arquivos de áudio etc.). Para diferentes tipos de arquivos, são necessárias estratégias específicas de acesso e análise para obter efetivamente o conhecimento contido neles. A seguir, apresentaremos os métodos de acesso e as dificuldades para diferentes fontes de dados.
P2: Como obter o conteúdo do rich text txt?
- Introdução: o rich text é armazenado principalmente no arquivo txt, porque o layout é relativamente simples, portanto, a maneira de obtê-lo é relativamente simples
- Habilidades práticas:
- [Análise de layout - leitura de texto rico em txt].
P3: Como obter o conteúdo do documento PDF?
- Introdução: os dados dos documentos PDF são mais complexos, incluindo texto, imagens, tabelas e outros estilos diferentes de dados, portanto, o processo de análise será mais complexo!
- Habilidades práticas:
- Análise de layout - PDF parser pdfplumber
- Análise de layout--PDF Parser PyMuPDF
P4: Como obter o conteúdo de um documento HTML?
- Introdução: os dados dos documentos PDF são mais complexos, incluindo texto, imagens, tabelas e outros estilos diferentes de dados, portanto, o processo de análise será mais complexo!
- Habilidades práticas:
- Análise de layout - Análise de HTML BeautifulSoup
P5: Como obter o conteúdo do documento Doc?
- Introdução: Os dados do documento do documento são mais complexos, incluindo texto, imagens, tabelas e outros estilos diferentes de dados, portanto, o processo de análise será mais complexo!
- Habilidades práticas:
- Análise de layout--Artifício de análise de Docx python-docx]
P6: Como usar o OCR para obter o conteúdo de uma imagem?
- Introdução: reconhecimento óptico de caracteres (óptico) Caráter Reconhecimento, OCR) é o processo de análise e reconhecimento de arquivos de imagem de informações textuais para obter informações textuais e de layout. Isso também significa que o texto na imagem é reconhecido e retornado na forma de texto.
- Pensamentos:
- Reconhecimento de texto: reconhecimento de áreas de texto bem localizadas, o principal problema é resolver o problema do que é cada texto, a área de texto na imagem na conversão de informações de caracteres.
- Detecção de texto: o problema resolvido é onde há texto e qual o alcance do texto;
- Projeto atual de OCR de código aberto
- Tesseract
- PaddleOCR
- EasyOCR
- chineseocr
- Chinêsocr_lite
- TrWebOCR
- cnocr
- hn_ocr
- Estudos teóricos:
- Análise de layout - Ferramenta de análise de imagens OCR]
- Habilidades práticas:
- [Análise de layout - tesseract OCR].
- [Análise de layout - OCR Magic PaddleOCR].
- [Análise de layout - artefatos de OCR hn_ocr].
P7: Como usar a ASR para obter o conteúdo da fala?
- Apelido: Reconhecimento automático de fala Reconhecimento automático de fala (ASR)
- Introdução: a conversão de um sinal de fala em uma mensagem de texto correspondente é como um "sistema auditivo da máquina", que permite que a máquina transforme o sinal de fala em um texto ou comando correspondente por meio de reconhecimento e compreensão.
- Objetivo: converter o conteúdo lexical da fala humana em entrada legível por computador (por exemplo, pressionamentos de teclas, códigos binários ou sequências de caracteres).
- Pensamentos:
- Pré-processamento do sinal acústico: para extrair recursos de forma mais eficaz, muitas vezes também é necessário capturar a filtragem do sinal sonoro, o enquadramento e outros trabalhos de pré-processamento, o sinal a ser analisado a partir da extração do sinal original;
- Extração de recursos: converter o sinal sonoro do domínio do tempo para o domínio da frequência para fornecer vetores de recursos adequados para o modelo acústico.
- Modelagem acústica: cálculo de uma pontuação para cada vetor de característica em características acústicas com base em propriedades acústicas; o
- Modelagem de linguagem: cálculo da probabilidade de que o sinal sonoro corresponda a uma sequência de frases possíveis, com base em teorias linguisticamente relevantes.
- Dicionário e decodificação: com base no dicionário existente, a sequência de frases é decodificada para obter a representação final possível do texto
- Tutorial de teoria:
- Reconhecimento de fala para análise de layout
- Habilidades práticas:
- [Análise de layout de fala para texto].
- Análise de layout do WeTextProcessing
- [Análise de layout - ferramenta ASR Wenet].
- Análise de layout Treinamento em ASR
etapa 2: recuperação de documentos de conhecimento
P1: Por que a recuperação de documentos de conhecimento é necessária?
A aquisição de documentos de conhecimento local contém após a leitura de dados de várias fontes (txt, pdf, html, doc, excel, png, jpg, voz etc.), é fácil dividir um parágrafo de várias linhas em vários parágrafos, o que faz com que os encontros de parágrafos sejam divididos, portanto, é necessário reorganizar os parágrafos de acordo com a lógica do conteúdo.
P2: Como posso recuperar documentos de conhecimento?
- Metodologia I: recuperação baseada em regras de documentos de conhecimento
- Método 2: Splicing de contexto com base no Bert NSP
Etapa 3: Análise de layout - Estratégias de otimização
- Estudos teóricos:
- [Análise de layout - Estratégias de otimização].
Etapa 4: Dever de casa
- Descrição da tarefa: use a metodologia acima para analisar o layout do [ChatGLM Evaluation Challenge - Finance Track dataset] do [SMP 2023 ChatGLM Finance Big Model Challenge].
- Eficácia da tarefa: analisar a eficácia e o desempenho dos vários métodos
Módulo II: Criando a base de conhecimento
Por que você precisa criar uma base de conhecimento?
A criação de uma base de conhecimento em RAG (Retrieval-Augmented Generation) é fundamental por vários motivos, incluindo, entre outros, os seguintes:
- Ampliação dos recursos do modelo: embora os modelos de linguagem em grande escala, como a família GPT, tenham recursos avançados de geração e compreensão de linguagem, eles são limitados pela cobertura do conjunto de dados de treinamento e podem não ser capazes de responder com precisão a algumas perguntas com base em fatos específicos ou informações detalhadas sobre o histórico. Ao criar uma base de conhecimento, o RAG pode complementar as limitações de conhecimento do próprio modelo, permitindo que ele recupere as informações mais atualizadas e precisas para gerar respostas.
- Atualização de informações em tempo real: a base de conhecimento pode ser atualizada e expandida em tempo real para garantir que o modelo tenha acesso ao conteúdo de conhecimento mais recente, o que é especialmente importante para lidar com informações sensíveis ao tempo, como notícias, avanços científicos e tecnológicos e assim por diante.
- Maior precisão: o RAG combina os processos de recuperação e geração para melhorar a precisão ao responder perguntas, recuperando documentos relevantes antes de gerar respostas. Dessa forma, as respostas geradas pelo modelo baseiam-se não apenas em seu conhecimento interno parametrizado, mas também em uma base de conhecimento externa de fontes confiáveis.
- Reduzir o excesso de ajuste e a alucinação: os modelos grandes podem, às vezes, sofrer de excesso de confiança em padrões intrínsecos e sofrer de alucinação, ou seja, gerar respostas que parecem ser razoáveis, mas não são. O RAG pode reduzir a probabilidade de tais erros citando evidências definitivas da base de conhecimento.
- Interpretabilidade aprimorada: o RAG não apenas fornece a resposta, mas também aponta a fonte da resposta, aumentando a transparência e a credibilidade dos resultados gerados pelo modelo.
- Suporte às necessidades de personalização e privatização: para empresas ou usuários individuais, eles podem atender às necessidades de domínios específicos ou personalização privada criando uma base de conhecimento exclusiva, que permite que o big model atenda melhor a cenários e negócios específicos.
Em resumo, a construção de uma base de conhecimento é um dos principais mecanismos dos modelos RAG para obter recuperação e geração de respostas eficientes e precisas, o que melhora muito o desempenho e a confiabilidade do modelo em aplicações práticas.
Etapa 1: divisão do texto do conhecimento
- Por que preciso dividir o texto em partes?
- Risco de informações ausentes: a tentativa de extrair os vetores de incorporação de todo o documento de uma só vez, embora capture o contexto geral, também pode perder muitas informações importantes específicas do tópico, o que pode resultar na geração de informações menos precisas ou ausentes.
- Limitação do tamanho do bloco: o tamanho do bloco é um fator limitante importante ao usar modelos como o OpenAI. Por exemplo, o modelo GPT-4 tem um limite de tamanho de janela de 32K. Embora esse limite não seja um problema na maioria dos casos, é importante considerar o tamanho do bloco desde o início.
- Há dois fatores principais a serem considerados:
- Caso de restrição de tokens para modelos de incorporação;
- O efeito da integridade semântica na eficácia geral da recuperação;
- Habilidades práticas:
- [Construção de base de conhecimento - fragmentação de texto de conhecimento]
- [Construção da base de conhecimento - Estratégias de otimização de corte e divisão de documentos]
Etapa 2: Vetorização de documentos (embdeeing)
P1: O que é a vetorização do Docs (embdeeing)?
A incorporação também é uma representação com uso intensivo de informações do significado semântico de um texto, em que cada incorporação é um vetor de números de ponto flutuante, de modo que a distância entre duas incorporações no espaço vetorial está correlacionada com a semelhança semântica entre as duas entradas no formato original. Por exemplo, se dois textos forem semelhantes, suas representações vetoriais também deverão ser semelhantes, e esse conjunto de representações de matriz no espaço vetorial descreve as diferenças sutis de recursos entre os textos. Em termos simples, a incorporação ajuda os computadores a entender o "significado" das informações humanas. A incorporação pode ser usada para obter a "relevância" de recursos em textos, imagens, vídeos ou outras informações, o que é comumente usado no nível do aplicativo em pesquisa, recomendação, classificação e outros aplicativos. Esse tipo de correlação é comumente usado em pesquisa, recomendação, classificação e agrupamento.
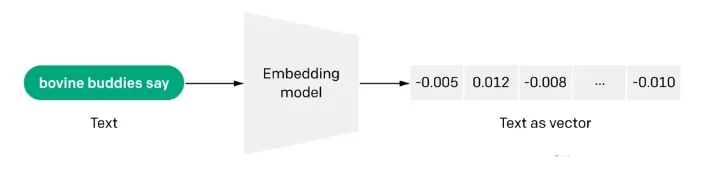
P2: Como funciona a incorporação?
Como exemplo, aqui estão três frases:
- "O gato persegue o rato."
- "O gatinho caça roedores".
- "I like ham sandwiches." Eu gosto de sanduíches de presunto.
Se os seres humanos classificassem essas três frases, a frase 1 e a frase 2 teriam quase o mesmo significado, enquanto a frase 3 seria completamente diferente. Mas vemos que, nas frases originais em inglês, apenas "The" é a mesma na frase 1 e na frase 2, e nenhuma outra palavra é a mesma. Como um computador pode entender a relevância das duas primeiras frases? A incorporação comprime informações discretas (palavras e símbolos) em dados distribuídos de valor contínuo (vetores). Se traçássemos a frase anterior em um gráfico, ele teria a seguinte aparência:
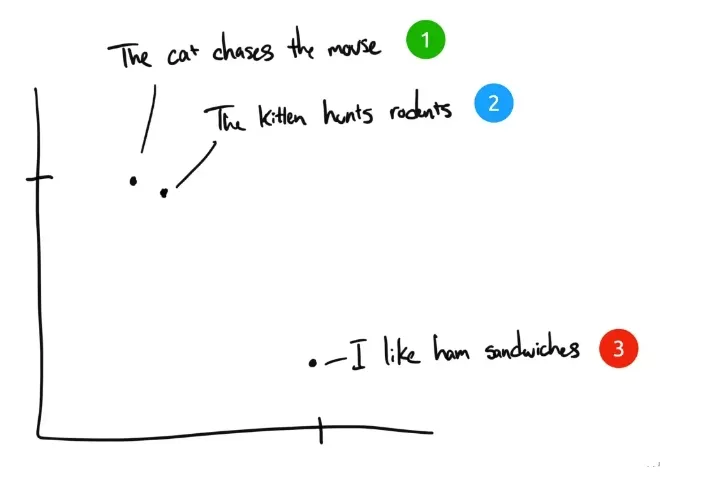
Após o texto ter sido compactado por incorporação em um espaço vetorial multidimensional compreensível por computador, as frases 1 e 2 são plotadas próximas uma da outra porque têm significados semelhantes. A frase 3 está mais distante porque não está relacionada a elas. Se tivéssemos uma quarta frase, "Sally comeu queijo suíço", ela provavelmente estaria em algum lugar entre a frase 3 (queijo é usado em sanduíches) e a frase 1 (ratos gostam de queijo suíço).
P3: Vantagens da abordagem de recuperação semântica da Embedding em relação à recuperação por palavra-chave?
- Compreensão semântica: os métodos de recuperação baseados em incorporação representam o texto por vetores de palavras, o que permite que o modelo capture associações semânticas entre as palavras, em contraste com a recuperação baseada em palavras-chave, que tende a se concentrar na correspondência literal e pode ignorar as conexões semânticas entre as palavras.
- Tolerância a erros: como os métodos baseados em incorporação são capazes de entender a relação entre as palavras, eles são mais vantajosos para lidar com casos como erros de ortografia, sinônimos e quase-sinônimos. Já os métodos de recuperação baseados em palavras-chave são relativamente fracos para lidar com esses casos.
- Suporte a vários idiomas: muitos métodos de incorporação podem suportar vários idiomas, o que ajuda a obter recuperação de texto em vários idiomas. Por exemplo, você pode usar a entrada em chinês para consultar o conteúdo de texto em inglês, enquanto os métodos de recuperação baseados em palavras-chave são difíceis de fazer isso.
- Compreensão contextual: os métodos baseados em incorporação são mais vantajosos para lidar com o caso de vários significados de uma palavra, pois são capazes de atribuir diferentes representações vetoriais às palavras com base no contexto. Já os métodos de recuperação baseados em palavras-chave podem não ser capazes de distinguir bem o significado da mesma palavra em diferentes contextos.
P4: Quais são as limitações da pesquisa de incorporação?
- Restrições de contagem de palavras de entrada: mesmo que os fragmentos de texto que melhor correspondam à consulta sejam selecionados com a ajuda da tecnologia de incorporação para a referência do modelo de grande escala, a restrição de contagem de vocabulário ainda existe. Quando a recuperação abrange uma ampla gama de textos, para controlar a quantidade de vocabulário contextual injetado no modelo, geralmente é definido um limite K de TopK para os resultados da recuperação, mas isso inevitavelmente desencadeia o problema de omissão de informações.
- Somente dados de texto: o GPT-3.5 e muitos modelos de linguagem em larga escala neste estágio ainda não têm recursos de reconhecimento de imagem; no entanto, no processo de recuperação de conhecimento, muitas informações importantes geralmente dependem da combinação de gráficos e texto para serem totalmente compreendidas. Por exemplo, é difícil compreender com precisão o significado de diagramas esquemáticos em trabalhos acadêmicos e gráficos de dados em relatórios financeiros com base apenas no texto.
- (b) Improvisação de um modelo grande: quando a literatura relevante recuperada é insuficiente para dar suporte a um modelo grande para responder a uma pergunta com precisão, o modelo pode estar sujeito a um certo grau de "improvisação", ou seja, especulação e acréscimos com base em informações limitadas, a fim de completar a resposta da melhor forma possível.
- Estudos teóricos:
- [Construção da base de conhecimento - Vetorização de documentos]
- Habilidades práticas:
- [Vetorização de documentos - Vetor de palavras da Tencent].
- [Docs vectorisation - sbt]
- [Vetorização de documentos - SimCSE]
- [Vetorização de documentos - text2vec]
- [Vetorização de documentos - SGPT]
- [Docs vectorisation -- BGE -- Smart Source open source o modelo de vetor semântico mais forte].
- [Vetorização de documentos - M3E: uma incorporação híbrida em grande escala]
Etapa 3: Índice de criação de documentos
- apresentar (alguém para um emprego etc.)
- Habilidades práticas:
- [Índice de compilação de documentos - Faiss]
- [Índice de compilação de documentos - milvus]
- [Docs Building Indexes - Elasticsearch].
Módulo 3: Ajuste fino do grande modelo
Por que precisamos ajustar os grandes modelos?
Normalmente, há vários motivos para fazer o ajuste fino de um modelo grande:
- O primeiro motivo é que, como o número de parâmetros em um modelo grande é muito grande, o custo de treinamento é muito alto, e cada empresa sai e treina um modelo grande do zero, o que é muito econômico;
- O segundo motivo é que a abordagem de engenharia de prompts é uma maneira relativamente fácil de começar a usar modelos grandes, mas também tem desvantagens óbvias. Como geralmente os princípios de implementação de modelos grandes têm restrições quanto ao comprimento da sequência de entrada, a abordagem Prompt Engineering pode tornar o Prompt muito longo.
Quanto mais longo for o Prompt, maior será o custo de inferência do modelo grande, porque o custo de inferência está positivamente correlacionado com o quadrado do comprimento do Prompt. Além disso, o Prompt muito longo será truncado porque excede o limite, o que, por sua vez, faz com que a qualidade da saída do modelo grande seja descontada. Para usuários individuais, se eles estiverem resolvendo alguns problemas em sua vida diária e no trabalho, geralmente não é um grande problema usar o Prompt Engineering diretamente. No entanto, para as empresas que prestam serviços ao mundo externo, para acessar a capacidade dos modelos grandes em seus próprios serviços, o custo de raciocínio é um fator que deve ser considerado, e o ajuste fino é uma solução relativamente melhor.
- O terceiro motivo é que o efeito do Prompt Engineering não está à altura dos requisitos, e a empresa tem dados próprios melhores, que podem ser usados para aprimorar a capacidade do big model no domínio específico. É nesse momento que o ajuste fino é muito aplicável.
- O quarto motivo é usar o poder dos modelos grandes em serviços personalizados, quando o treinamento de um modelo leve e ajustado para os dados de cada usuário é uma boa solução.
- O quinto motivo é a segurança dos dados. Se os dados não forem transmitidos a um serviço de modelo grande de terceiros, é muito necessário criar seu próprio modelo grande. Normalmente, esses modelos grandes de código aberto precisam ser ajustados com seus próprios dados para atender às necessidades da empresa.
Como você faz o ajuste fino de um modelo grande?
P1: A questão do ajuste fino das rotas técnicas para modelos grandes
O ajuste fino de modelos grandes a partir de uma perspectiva de escala de parâmetros é dividido em duas rotas técnicas:
- Caminho técnico 1: Para a quantidade total de parâmetros, a quantidade total de treinamento, esse caminho é chamado de FFT (Full Fine Tuning) de ajuste fino completo.
- Rota técnica II: apenas alguns dos parâmetros são treinados, esse caminho é chamado de PEFT (Parameter-Efficient Fine Tuning).
P2: Quais são os problemas com a técnica FFT de ajuste fino de volume total para modelos grandes?
A FFT também traz alguns problemas, os mais impactantes, sendo os dois principais os seguintes:
- Problema 1: O custo do treinamento será maior porque o número de parâmetros para o ajuste fino é o mesmo que para o pré-treinamento;
- Problema 2: esquecimento catastrófico (Catastrophic Forgetting), em que o ajuste fino com dados de treinamento específicos pode melhorar o desempenho nesse domínio, mas também pode piorar a capacidade em outros domínios que estavam com bom desempenho.
P3: Quais problemas são resolvidos pelo PEFT (Parameter-Efficient Fine Tuning) para modelos grandes?
O principal problema que a PEFT quer resolver são os dois problemas acima da FFT, e a PEFT também é o programa de ajuste fino mais comum no momento. Do ponto de vista da fonte de dados de treinamento, bem como do método de treinamento, há várias rotas técnicas para o ajuste fino de modelos grandes, como segue:
- Rota técnica 1: Supervised Fine Tuning SFT (Supervised Fine Tuning), esse esquema se concentra no ajuste fino de modelos grandes com dados rotulados manualmente usando a abordagem tradicional de aprendizado supervisionado no aprendizado de máquina;
- Rota técnica II: Aprendizado por reforço com feedback humano (RLHF), a principal característica desse esquema é introduzir o feedback humano, por meio do aprendizado por reforço, no ajuste fino do modelo grande, de modo que os resultados gerados pelo modelo grande possam estar mais alinhados com algumas das expectativas humanas;
- Rota tecnológica III: Aprendizado por reforço com feedback de IA (RLAIF), o princípio é mais ou menos semelhante ao do RLHF, mas a fonte de feedback é a IA. Aqui, tenta-se resolver o problema de eficiência do sistema de feedback, pois a coleta de feedback humano, em termos relativos, terá um custo maior e será menos eficiente.
As diferentes perspectivas de classificação são simplesmente ênfases diferentes, e o ajuste fino do mesmo modelo grande não se limita a um cenário específico, mas pode abranger vários cenários juntos. O objetivo final do ajuste fino é poder aprimorar os recursos do modelo grande em um domínio específico, tanto quanto possível, a um custo gerenciável.
O que os LLMs de modelos grandes estão aprendendo quando realizam operações de SFT?
- Pré-treinamento -> pré-treinamento em grandes quantidades de dados não supervisionados para obter um modelo básico -> use o modelo pré-treinado como ponto de partida para SFT e RLHF.
- SFT --> Executar o treinamento SFT em conjuntos de dados supervisionados e otimizar ainda mais o modelo usando sinais supervisionados, como informações contextuais --> Usar o modelo treinado SFT como ponto de partida para RLHF.
- RLHF --> Aprendizado por reforço usando feedback humano para otimizar o modelo e adequá-lo melhor às intenções e preferências humanas --> Avaliação e validação do modelo treinado por RLHF e realização dos ajustes necessários.
etapa 1: construção de dados de treinamento de ajuste fino de modelos grandes
- Introdução: Como criar dados de treinamento?
- Habilidades práticas:
- [Modelos de grande escala (LLMs) Metodologia LLM para gerar dados SFT].
Etapa 2: Ajuste fino das instruções do modelo grande
- Introdução: Como criar dados de treinamento?
- Habilidades práticas:
- [Pré-treinamento contínuo de modelos grandes (LLMs)].
- [Ajuste fino das instruções dos LLMs].
- [Treinamento do modelo de recompensa dos LLMs].
- Aprendizado por reforço para modelos grandes (LLMs) - Capítulo de treinamento do PPO]
- Aprendizado por reforço para modelos grandes (LLMs) - Capítulo de treinamento da DPO
Module 4: Recuperação de documentos
Por que você precisa do Document Retrieval?
Recuperação de documentos Como o trabalho principal do RAG, sua eficácia é crucial para o trabalho posterior. Embora seja possível melhorar a qualidade da resposta do modelo recuperando fragmentos de documentos relacionados às perguntas do usuário no repositório de documentos por meio da recuperação de vetores e inserindo-os no LLM ao mesmo tempo. Uma maneira comum de fazer a recuperação de documentos é usar diretamente a pergunta do usuário. No entanto, muitas vezes, a pergunta do usuário é muito coloquial e vagamente descrita, o que afeta a qualidade da recuperação do vetor e, portanto, a resposta do modelo. Este capítulo apresenta principalmente alguns problemas e soluções correspondentes no processo de recuperação de documentos.
etapa 1: recuperação de documentos mineração de amostras negativas
- INTRODUÇÃO: em todos os tipos de tarefas de recuperação, para treinar um modelo de recuperação de boa qualidade, geralmente é necessário coletar exemplos negativos de alta qualidade de um grande conjunto de amostras candidatas, juntamente com exemplos positivos.
- Habilidades práticas:
- [Document Retrieval - Negative Sample Sample Mining Chapter].
etapa 2: estratégia de otimização da recuperação de documentos
- Introdução: estratégias de otimização da recuperação de documentos
- Habilidades práticas:
- Recuperação de documentos - Estratégias de otimização para recuperação de documentos
Módulo V: Reranker
Por que você precisa do Reranker?
O aplicativo RAG básico consiste em quatro componentes técnicos principais:
- Modelos de incorporação: usados para transformar documentos externos e consultas de usuários em vetores de incorporação
- banco de dados de vetoresEmbedding vectors: Usado para armazenar vetores de incorporação e realizar pesquisas de similaridade de vetores (recuperar as informações Top-K mais relevantes).
- Engenharia de prompts: entradas para combinar perguntas de usuários e contextos recuperados em modelos maiores
- Modelagem de linguagem ampla (LLM): para gerar respostas
A arquitetura básica do RAG descrita acima aborda com eficácia o problema de os LLMs criarem "ilusões" e gerarem conteúdo não confiável. No entanto, alguns usuários corporativos exigem arquiteturas mais sofisticadas para obter relevância contextual e precisão de perguntas e respostas. Uma abordagem comprovada e popular é integrar o Reranker aos aplicativos RAG.
O que é o Reranker?
O Reranker é uma parte importante do ecossistema de Recuperação de Informações (RI) para avaliar os resultados da pesquisa e reordená-los para melhorar a relevância da consulta. Nos aplicativos RAG, o Reranker é usado principalmente após a obtenção dos resultados de uma consulta vetorial (ANN), o que permite uma determinação mais eficaz da relevância semântica entre documentos e consultas, uma reordenação mais refinada dos resultados e, por fim, melhora a qualidade da pesquisa.
Etapa 1: Parte Reranker
- Estudos teóricos:
- Pesquisa de documentação RAG - Seção Reranker
- Habilidades práticas:
- [Reranker - capítulo do bge-reranker].
Module 6: Superfícies de avaliação RAG
Por que preciso revisar o RAG?
Ao explorar e otimizar os RAGs (Retrieval Augmentation Generators, geradores de aumento de recuperação), a questão de como avaliar efetivamente seu desempenho tornou-se fundamental.
Etapa 1: Revisão RAG
- Estudos teóricos:
- [RAG Review].
Módulo 7: Projeto de código aberto RAG Aprendizado recomendado
Por que eu preciso do RAG Open Source Project Recommended Learning?
Depois de conduzi-lo pelos vários processos do RAG, aqui estão alguns projetos de código aberto do RAG recomendados para ajudar os grandes a digerir e aprender.
Recomendações do projeto de código aberto RAG - Artigo do RAGFlow
- Introdução: o RAGFlow é um mecanismo de geração aumentada de recuperação (RAG) de código aberto criado com base na compreensão profunda de documentos. O RAGFlow oferece um conjunto simplificado de fluxos de trabalho RAG para empresas e indivíduos de todos os portes, combinado com um modelo de linguagem grande (LLM) para fornecer O RAGFlow oferece um fluxo de trabalho RAG simplificado para organizações e indivíduos de todos os portes, combinado com um Modelo de Linguagem Grande (LLM) para fornecer perguntas, respostas e citações justificadas confiáveis para uma ampla gama de formatos de dados complexos.
- Aprendizagem de projetos:
- Recomendações do projeto RAG - RagFlow Parte I - Implantação do RagFlow no Docker
- Recomendação do Projeto RAG - RagFlow Parte (2) - Construção da Base de Conhecimento RagFlow].
- Recomendação do projeto RAG - RagFlow Parte III - Seleção do fornecedor do modelo RagFlow
- Recomendação do Projeto RAG - RagFlow Parte (4) - Diálogo RagFlow]
- Recomendação do projeto RAG - RagFlow Parte (V) - Acesso à API do RAGFlow (para) ollama (por exemplo)]
- Recomendação do projeto RAG - RagFlow Parte (VI) - Aprendizado do código-fonte do RAGFlow
Recomendações do projeto de código aberto RAG - QAnything
- Introdução: o QAnything (Question and Answer based on Anything) é um sistema local de perguntas e respostas de base de conhecimento projetado para suportar uma ampla variedade de formatos de arquivos e bancos de dados, permitindo a instalação e o uso off-line. Com o QAnything, você pode simplesmente excluir arquivos armazenados localmente em qualquer formato e obter respostas precisas, rápidas e confiáveis. Atualmente, o QAnything é compatível com os seguintes formatos de arquivo de base de conhecimento: PDF (pdf) , Word (docx) , PPT (pptx) , XLS (xlsx) , Markdown (md) , Email (eml) , TXT (txt), Imagem (jpg, jpeg, png), CSV (csv), links da Web (html) e assim por diante.
- Aprendizagem de projetos:
- [Recomendações do projeto de código aberto RAG -- QQualquer coisa [Texto].
Recomendações do projeto de código aberto RAG -- Artigo do ElasticSearch-Langchain
- INTRODUÇÃO: Inspirado no projeto langchain-ChatGLM, uma vez que o Elasticsearch pode realizar consultas mistas de forma textual e vetorial e é mais amplamente usado em cenários comerciais, este projeto substitui o Faiss pelo Elasticsearch como repositório de conhecimento e usa Langchain+Chatglm2 para implementar um questionário inteligente baseado na base de conhecimento do Faiss. Perguntas e respostas inteligentes baseadas em sua própria base de conhecimento usando Langchain+Chatglm2.
- Aprendizagem de projetos:
- [Introdução aos LLMs] Eficiente 🤖ElasticSearch-Langchain-Chatglm2 baseado na base de conhecimento local]
Recomendações do projeto de código aberto RAG - Artigo de Langchain-Chatchat
- Introdução: Aplicativo de controle de qualidade Langchain-Chatchat (anteriormente Langchain-ChatGLM) com LLM baseado em conhecimento local (como o ChatGLM) conhecimento local baseado em LLM (como o ChatGLM) Aplicativo de controle de qualidade com langchain
- Aprendizagem de projetos:
- [Introdução aos LLMs] Eficiente 🤖Langchain-Chatchat baseado na base de conhecimento local]
© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Artigos relacionados



Nenhum comentário...