
NVIDIA abre o código-fonte do modelo gráfico Vincennes SANA: implementações locais voam diretamente das imagens 4K

Recentemente, a NVIDIA (NVIDIA), em conjunto com o Instituto de Tecnologia de Massachusetts e a Universidade de Tsinghua, lançou um modelo de geração de imagens de código aberto chamado SANA, que não só é capaz de gerar imagens de forma eficiente com uma resolução de até 4096 × 4096, mas também tem uma velocidade de geração muito rápida.
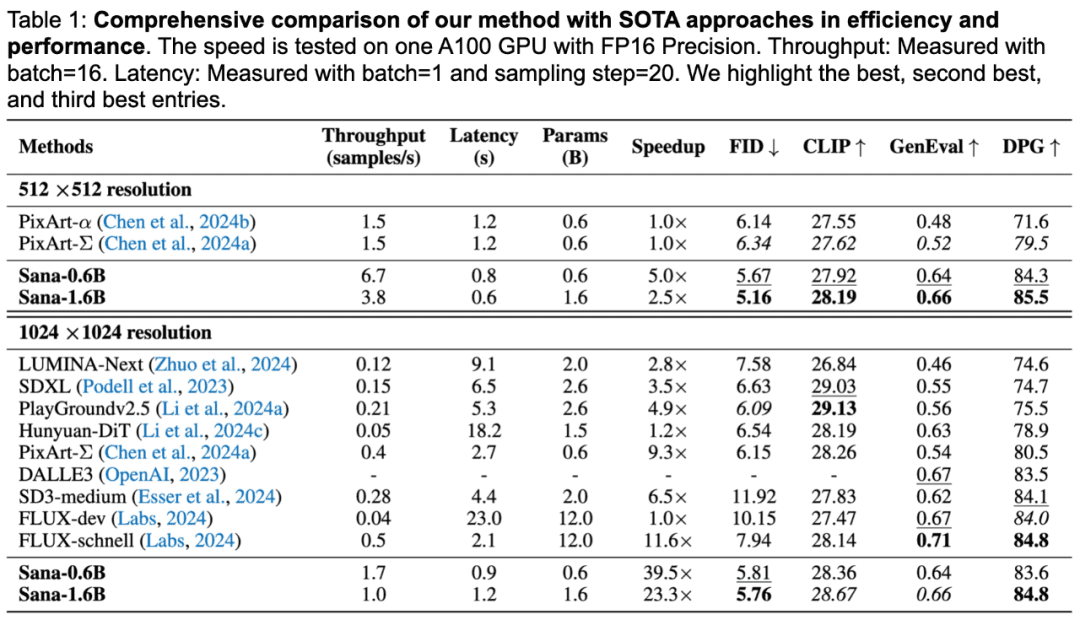
Desempenho da SANA
O SANA-0.6B leva menos de um segundo para gerar imagens com resolução de 1024×1024, 25 vezes mais rápido que o Flux-Dev, e 106 vezes mais rápido que o Flux-Dev para gerar imagens com resolução de 4096×4096.

Em termos de qualidade de geração, o SANA tem a mesma pontuação que o Flux no benchmark de teste DPG-Bench e apenas um pouco abaixo do modelo Flux na métrica GenEval.
Projeto principal do SANA
O sucesso da SANA se deve a seus quatro projetos principais:
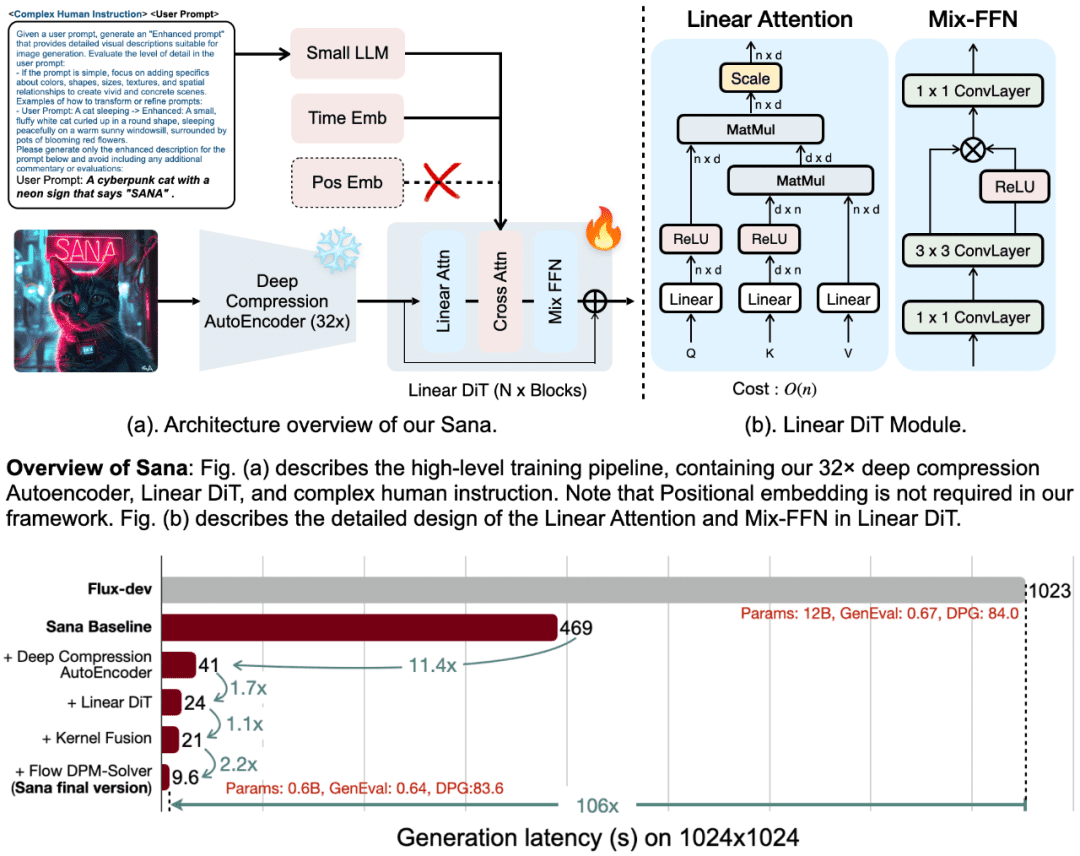
1. codificador automático de compressão de profundidade (DC-AE)
Enquanto os autoencoders (AEs) convencionais normalmente comprimem as imagens em um fator de 8, o SANA apresenta um autoencoder de compressão profunda que aumenta o fator de compressão para 32. Esse design reduz drasticamente o número de possíveis marcadores, permitindo que o SANA gere com eficiência imagens de altíssima resolução (por exemplo, resolução 4K) e, ao mesmo tempo, reduza significativamente o custo computacional de treinamento e geração.
2) DIT linear (Transformador de imagem de difusão)
O SANA emprega um novo mecanismo de atenção linear em vez do tradicional mecanismo de atenção quadrática, reduzindo a complexidade de O(N²) para O(N). Esse aprimoramento não só aumenta a eficiência da geração de imagens de alta resolução, mas também elimina a necessidade de codificação posicional, marcando o primeiro modelo de DIT que não requer incorporação posicional.
3. pequenos LLMs somente de decodificador como codificadores de texto
O SANA usa pequenos modelos de linguagem somente de decodificador (como o Gemma 2) como codificadores de texto, substituindo os modelos CLIP ou T5 tradicionais. O Gemma tem recursos superiores de compreensão de texto e aderência a instruções, o que, combinado com um sofisticado design de instruções manuais, melhora significativamente o alinhamento entre imagem e texto.
4. estratégias eficientes de treinamento e raciocínio
O SANA propõe uma estratégia automática de rotulagem e treinamento que gera diferentes recapitulações com vários modelos de linguagem visual (VLMs) e seleciona legendas de alta qualidade com base no CLIPScore, acelerando assim a convergência do modelo e aprimorando o alinhamento entre texto e imagem. Além disso, o SANA apresenta o Flow-DPM-Solver, que reduz drasticamente as etapas de inferência e melhora ainda mais a eficiência da geração.
Implementação de baixo custo e código aberto
Outro destaque do SANA é sua capacidade de implementação de baixo custo. O SANA-0.6B pode ser executado em uma GPU de laptop de 16 GB, gerando imagens com resolução de 1024×1024 em menos de 1 segundo, e 22 GB de memória de vídeo podem endireitar imagens com resolução de 4096×4096, um recurso que torna o SANA não apenas adequado para dispositivos de computação de ponta, mas também pode ser executado com eficiência em laptops de usuários comuns. laptops de usuários comuns. Além disso, a NVIDIA também anunciou que divulgará publicamente o código e o modelo do SANA, promovendo ainda mais a popularidade e a aplicação da tecnologia de geração de texto para imagem.
fazer uso de
A NVIDIA criou oito interfaces de uso da Web 3090 que podem ser testadas gratuitamente. Vale a pena mencionar que o modelo SANA pode ser usado diretamente com palavras de alerta chinesas.
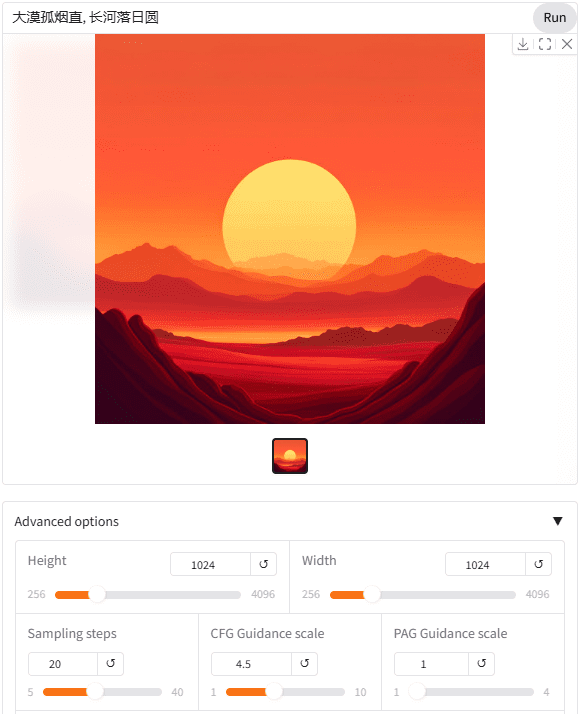
Até mesmo o uso de palavras-chave com símbolos de ícones é possível, o que deve se beneficiar do uso do modelo de linguagem visual Gemma2 2B como codificador de texto.

Com o plugin ComfyUI_ExtraModels, é muito fácil usar os modelos SANA também no Comfyui nativo. A instalação do plugin é muito simples, não é necessário configurar suas próprias dependências, a execução após a instalação fará o download automático dos arquivos de modelo necessários.
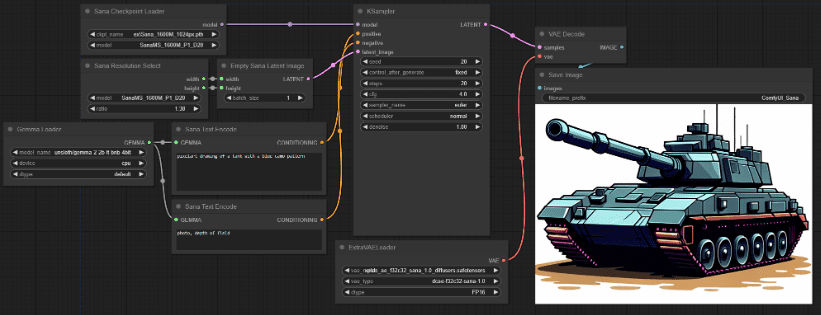
Com autoencodificador de compressão profunda, DIT linear, LLM pequeno somente para decodificador e estratégias eficientes de treinamento e inferência, o SANA não só é capaz de gerar imagens de resolução ultra-alta com eficiência, mas também tem recursos sólidos de alinhamento de texto-imagem e vantagens de implantação de baixo custo. Para aqueles que precisam produzir imagens rapidamente, o SANA ainda é bom, ou seja, em termos de ecologia, não pode ser comparado ao Flux.

Página do projeto:
github.com/NVlabs/Sana
Uso da Web:
nv-sana.mit.edu
Plug-in do Comfyui:
github.com/Efficient-Large-Model/ComfyUI_ExtraModels
© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Artigos relacionados


Nenhum comentário...