
Comparação da profundidade do banco de dados vetorial: Weaviate, Milvus e Qdrant
No campo da inteligência artificial e do aprendizado de máquina, especialmente na criação de aplicativos como os sistemas RAG (Retrieval Augmented Generation) e a pesquisa semântica, o processamento e a recuperação eficientes de grandes quantidades de dados não estruturados tornam-se cruciais. Os bancos de dados vetoriais surgiram como uma tecnologia essencial para enfrentar esse desafio. Eles não são apenas bancos de dados especializados para armazenar dados vetoriais de alta dimensão, mas também uma infraestrutura essencial para impulsionar a próxima geração de aplicativos de IA.
Neste artigo, discutiremos os conceitos, os princípios e os cenários de aplicação de bancos de dados vetoriais e compararemos e analisaremos os principais bancos de dados vetoriais de código aberto atuais, Weaviate, Milvus e Qdrant, com o objetivo de fornecer aos leitores um guia abrangente e detalhado sobre bancos de dados vetoriais, que o ajudará a entender o valor dos bancos de dados vetoriais e a fazer escolhas técnicas informadas em projetos reais.
O que é um banco de dados vetorial? Dos bancos de dados tradicionais à recuperação de vetores
Para entender o que torna os bancos de dados vetoriais únicos, primeiro precisamos entender o que são vetores e por que os bancos de dados tradicionais ficam sobrecarregados ao lidar com dados vetoriais.
Vetores: representação matemática de dados
Em termos simples, um vetor é uma ferramenta matemática usada para representar um recurso ou atributo de dados, que pode ser visto como um ponto em um espaço multidimensional. No contexto de bancos de dados vetoriais, geralmente discutimos ovetor de alta dimensãoo que significa que esses vetores têm um grande número de dimensões, variando de dezenas a milhares de dimensões, dependendo da complexidade dos dados e da granularidade da representação necessária.
Incorporação de vetores: representação estruturada de dados não estruturados
Então, como esses vetores de alta dimensão são gerados? A resposta é por meio dofunção incorporadaque converte dados brutos não estruturados (por exemplo, texto, imagens, áudio, vídeo etc.) em vetores. Esse processo de conversão, chamadoIncorporação de vetoresusando métodos como modelos de aprendizado de máquina, técnicas de incorporação de palavras ou algoritmos de extração de recursos para compactar as informações semânticas ou os recursos dos dados em um espaço vetorial compacto.
Por exemplo, para dados textuais, podemos usar uma ferramenta como Word2Vec, GloVe, FastText ou Transformador Modelos (por exemplo, BERT, Sentence-BERT) e outras técnicas convertem cada palavra, frase ou até mesmo o texto inteiro em um vetor. No espaço vetorial, os textos que são semanticamente semelhantes terão seus vetores mais próximos.

O ponto forte dos bancos de dados vetoriais: pesquisa de similaridade
Os bancos de dados tradicionais, como os bancos de dados relacionais (por exemplo, PostgreSQL, MySQL) e os bancos de dados NoSQL (por exemplo, MongoDB, Redis), são projetados principalmente para armazenar e consultar dados estruturados ou semiestruturados e são excelentes na recuperação de dados com base em correspondências exatas ou critérios predefinidos. No entanto, quando se trata de recuperação de dados com base emsimilaridade semânticatalvezSignificado contextualA localização de dados torna os bancos de dados tradicionais ineficientes.
Os bancos de dados vetoriais surgiram para preencher essa lacuna. Sua principal força é a capacidade deRealizar com eficiência a pesquisa e a recuperação de similaridade com base na distância vetorial ou na similaridade. Isso significa que podemos encontrar dados com base em sua semelhança semântica ou de recursos sem precisar fazer a correspondência exata de palavras-chave.
Principais diferenças entre os bancos de dados vetoriais e os bancos de dados tradicionais
Para entender melhor a singularidade dos bancos de dados vetoriais, resumimos a seguir as principais diferenças entre eles e os bancos de dados tradicionais:
| caracterização | banco de dados de vetores | Banco de dados tradicional (relacional/NoSQL) |
|---|---|---|
| tipo de dados | Incorporação de vetores (vetores de alta dimensão) | Dados estruturados (Dados tabulares, documentos JSON, etc.) |
| operação principal | Pesquisa de similaridade (cálculo de similaridade de vetores) | Consulta de correspondência exata, consulta de intervalo, análise de agregação, etc. |
| Tipo de índice | Índices vetoriais (índices ANN, etc.) | Índices de árvore B, índices de hash, índices invertidos, etc. |
| Método de consulta | Com base em distâncias vetoriais (distância cosseno, distância euclidiana, etc.) | Consulta baseada em SQL, consulta de valor-chave, pesquisa de texto completo, etc. |
| cenário do aplicativo | Pesquisa semântica, sistemas de recomendação, sistemas de recomendação RAG, recuperação de imagem/áudio/vídeo | Processamento de transações, análise de dados, gerenciamento de conteúdo, armazenamento em cache |
| modelo de dados | modelo de espaço vetorial | Modelo relacional, modelo de documento, modelo de valor-chave, modelo de gráfico etc. |
O valor dos bancos de dados vetoriais: uma pedra angular para aplicativos de IA
Os bancos de dados vetoriais estão desempenhando uma função cada vez mais importante no campo da inteligência artificial e do aprendizado de máquina, especialmente nas seguintes áreas:
- Mecanismos de pesquisa de última geração: Implemente a pesquisa semântica para entender a intenção da consulta do usuário e retornar resultados de pesquisa mais relevantes e contextuais, não apenas a correspondência de palavras-chave.
- Sistemas de recomendação inteligentes: Recomendações personalizadas com base no comportamento histórico do usuário e nas características do item para melhorar a precisão da recomendação e a experiência do usuário.
- Aplicativos de modelagem de linguagem grande (LLM): Fornece ao LLM memória de longo prazo e recursos eficientes de recuperação contextual, apoiando a construção de chatbots, sistemas de perguntas e respostas e aplicativos de geração de conteúdo mais avançados.
- Recuperação de dados multimodais: Possibilitar a pesquisa de similaridade entre modalidades, por exemplo, pesquisar imagens ou vídeos relacionados por meio de descrições textuais.
Em resumo, os bancos de dados vetoriais são a principal infraestrutura para o processamento e a recuperação de dados não estruturados na era da IA e capacitam as máquinas a entender a semântica e a raciocinar sobre semelhanças, impulsionando assim vários aplicativos inovadores de IA.
Bancos de dados vetoriais e RAG: criação de um sistema avançado de geração de aprimoramento de pesquisa
A ideia central do RAG é recuperar informações relevantes de uma base de conhecimento externa antes de gerar o texto e, em seguida, usar as informações recuperadas como um contexto para orientar o modelo de linguagem a fim de gerar respostas mais precisas e confiáveis.
A função central dos bancos de dados de vetores no sistema RAG
No sistema RAG, o banco de dados de vetores desempenha a função derepositórioO sistema RAG é responsável pelo armazenamento e pela recuperação eficiente de representações vetoriais de documentos de conhecimento em massa:
- Criação de base de conhecimento:
- Incorporação vetorial de documentos de conhecimento (por exemplo, texto, páginas da Web, PDFs etc.) em representações vetoriais.
- Armazene esses vetores e seus metadados de documentos correspondentes em um banco de dados de vetores.
- Recuperação de consultas:
- Receber a consulta do usuário e o vetor incorporar a consulta também para obter o vetor de consulta.
- Uma pesquisa de similaridade é realizada em um banco de dados vetorial usando o vetor de consulta para recuperar o vetor de documento mais semelhante ao vetor de consulta.
- Obtenha o documento original ou o fragmento de documento correspondente ao vetor de documentos recuperado.
- Geração de texto:
- Os fragmentos de documentos recuperados são inseridos no Large Language Model (LLM) como contexto, juntamente com a consulta do usuário.
- O LLM gera a resposta ou o texto final com base em informações contextuais.

Pesquisa semântica de imagens com o Milvus
Por que os bancos de dados vetoriais são ideais para os sistemas RAG?
- Recursos eficientes de recuperação semântica: Os bancos de dados vetoriais são capazes de recuperar documentos com base na similaridade semântica, o que é uma combinação perfeita para os sistemas RAG que precisam encontrar informações contextuais da base de conhecimento que sejam relevantes para a consulta do usuário.
- Lidar com arquivos de conhecimento em massa: Os sistemas RAG geralmente precisam lidar com um grande número de documentos de conhecimento, e os bancos de dados vetoriais podem armazenar e recuperar com eficiência dados vetoriais maciços para atender aos requisitos de escalabilidade dos sistemas RAG.
- Resposta rápida às consultas dos usuários: A pesquisa de similaridade do banco de dados de vetores é muito rápida e garante que o sistema RAG responda rapidamente às consultas dos usuários.
Seleção de banco de dados vetorial: decisões importantes para sistemas RAG
A escolha do banco de dados vetorial correto é fundamental para o desempenho e a eficácia de um sistema RAG. Os diferentes bancos de dados vetoriais diferem em termos de desempenho, funcionalidade e facilidade de uso. Nos próximos capítulos, discutiremos os fatores de seleção dos bancos de dados vetoriais e compararemos e analisaremos três excelentes bancos de dados vetoriais de código aberto, a saber, Weaviate, Milvus e Qdrant, para ajudá-lo a escolher a base mais adequada para o seu sistema RAG.
Seleção de banco de dados vetorial: concentre-se nestes fatores-chave, não apenas no desempenho
Antes de nos aprofundarmos na comparação de produtos específicos, vamos identificar as principais preocupações da seleção do banco de dados vetorial. Esses fatores afetarão diretamente o desempenho, a escalabilidade, a estabilidade e o custo do sistema RAG ou do aplicativo de IA que você criar.
1. código aberto vs. comercialização: autonomia vs. facilidade de uso
- Bancos de dados vetoriais de código aberto (por exemplo, Milvus, Weaviate, Qdrant, Vespa):
- Vantagens: Maior autonomia e flexibilidade para personalização livre e desenvolvimento secundário, melhor controle da segurança dos dados e da arquitetura do sistema. Apoiado por uma comunidade de código aberto ativa, com iteração rápida e resolução rápida de problemas. Geralmente de baixo custo ou até mesmo de uso gratuito.
- Desafio: A implantação, a operação e a manutenção e a solução de problemas exigem algumas habilidades técnicas. O suporte comercial pode ser relativamente fraco, exigindo a dependência da comunidade ou a resolução de problemas por iniciativa própria.
- Cenários aplicáveis: Projetos que exigem um alto grau de autonomia e controle, contam com o apoio de uma equipe técnica, desejam reduzir custos e podem participar ativamente da coprodução da comunidade.
- Bancos de dados vetoriais comerciais (por exemplo, bancos de dados vetoriais hospedados de provedores de nuvem, como Pinecone, etc.):
- Vantagens: Normalmente, oferece serviços gerenciados e suporte técnico completos, simplifica a complexidade da implantação e da O&M e é fácil de começar a usar. O desempenho e a estabilidade são comprovados comercialmente e a qualidade do serviço é garantida.
- Desafio: Custos mais altos e podem incorrer em despesas significativas ao longo do tempo. Possível risco de aprisionamento ao fornecedor, personalização limitada e desenvolvimento secundário.
- Cenários aplicáveis: Projetos que buscam facilidade de uso e estabilidade, querem começar a trabalhar rapidamente, reduzir a carga de O&M, têm um bom orçamento e não são sensíveis aos riscos de dependência do fornecedor.
2. suporte a CRUD: dados dinâmicos vs. dados estáticos
- Suporte a CRUD (criar, ler, atualizar, excluir):
- Importância: Essencial para sistemas RAG e muitos aplicativos de dados dinâmicos. Se os dados precisarem ser atualizados, excluídos ou modificados com frequência, é importante escolher um banco de dados vetorial que ofereça suporte a operações CRUD completas.
- Impacto: Um banco de dados que suporta operações CRUD facilita o gerenciamento de dados que mudam dinamicamente e mantém a base de conhecimento precisa e em tempo real.
- Cenários de dados estáticos:
- Demanda: Se os dados forem estáticos, como uma base de conhecimento pré-construída, e forem atualizados com pouca frequência, uma biblioteca de vetores somente leitura ou um banco de dados que não ofereça suporte a CRUD completo também poderão ser adequados.
- Selecione: Nesse caso, algumas bibliotecas de vetores leves podem ser consideradas, ou alguns bancos de dados de vetores que se concentram na recuperação de alto desempenho com uma função de atualização de dados fraca.
3. arquitetura distribuída e escalabilidade: lidar com dados massivos e alta simultaneidade
- Arquitetura distribuída:
- Necessidade: Os sistemas RAG e muitos aplicativos de IA geralmente precisam lidar com grandes quantidades de dados e solicitações altamente simultâneas. As arquiteturas distribuídas são fundamentais para enfrentar esses desafios.
- Vantagens: Os bancos de dados vetoriais distribuídos podem armazenar dados dispersos em vários servidores e suportar consultas paralelas, melhorando assim o poder de processamento de dados e o desempenho das consultas.
- Escalabilidade:
- Expansão horizontal: Um bom banco de dados vetorial deve ser capaz de escalonar horizontalmente com facilidade, adicionando nós para lidar com o crescimento do volume de dados e das solicitações.
- Elástico elástico: É desejável oferecer suporte ao dimensionamento elástico para ajustar dinamicamente os recursos com base na carga real para otimizar o custo e o desempenho.
4. replicação de dados e alta disponibilidade: garantindo a segurança dos dados e a estabilidade do serviço
- Cópia de dados:
- Função: O mecanismo de cópia de dados é um meio importante de garantir a segurança dos dados e a alta disponibilidade do sistema.
- Realização: Ao armazenar cópias idênticas de dados em vários servidores, o sistema continua a operar normalmente sem perda de dados, mesmo que alguns dos nós falhem.
- Alta disponibilidade:
- Importância: A alta disponibilidade é essencial para sistemas RAG e aplicativos on-line que exigem alta estabilidade de serviço.
- Salvaguardas: Mecanismos como cópia de dados, transferência automática de falhas e monitoramento e alarme trabalham juntos para garantir a operação contínua e estável do sistema.
5 Desempenho: velocidade e precisão da pesquisa
- Latência:
- Indicadores: Latência da consulta, ou seja, o tempo entre o início de uma consulta e a obtenção dos resultados.
- Fatores de influência: algoritmos de indexação, recursos de hardware, tamanho dos dados, complexidade da consulta, etc.
- Demanda: Para aplicativos com altos requisitos de tempo real, é necessário escolher um banco de dados vetorial com velocidade de recuperação rápida.
- Recall, Precisão:
- Indicadores: Recall e Precision, que medem a precisão dos resultados da pesquisa de similaridade.
- Pesagem: Geralmente, há uma compensação entre a velocidade de recuperação e a precisão, e o equilíbrio certo precisa ser escolhido de acordo com o cenário do aplicativo. Por exemplo, para um sistema RAG, a recuperação pode ser mais importante para garantir que o maior número possível de documentos relevantes seja recuperado.
6. manutenção contínua e apoio da comunidade: uma garantia de operação estável a longo prazo
- Manutenção contínua:
- Importância: A tecnologia de banco de dados vetorial está evoluindo rapidamente e a manutenção e as atualizações contínuas são essenciais.
- Pontos de preocupação: Se o banco de dados é mantido e atualizado continuamente por uma equipe de desenvolvimento ativa, corrigindo bugs em tempo hábil e acompanhando as últimas tendências tecnológicas.
- Suporte à comunidade:
- Valor: Uma comunidade ativa fornece uma grande quantidade de documentação, tutoriais, exemplos de código e respostas a perguntas, reduzindo as barreiras ao aprendizado e ao uso.
- Avaliação: O suporte da comunidade pode ser avaliado por meio da análise de métricas como atividade em repositórios do GitHub, buzz em fóruns da comunidade, número de usuários e assim por diante.
7. considerações de custo: código aberto vs. comercialização, construção própria vs. hospedagem
- Código aberto vs. custos de comercialização:
- Código aberto: O software do banco de dados em si é gratuito, mas há custos de hardware, custos de O&M, custos de mão de obra, etc. a serem considerados.
- Comercialização: Há taxas de licença de software ou de serviço de nuvem a serem pagas, mas os custos de O&M podem ser menores e o suporte técnico pode ser melhor.
- Construção própria vs. custos de hospedagem:
- Construção própria: Você precisa ser responsável pela aquisição, implementação, operação e manutenção do hardware, monitoramento etc. O investimento inicial e os custos de operação e manutenção de longo prazo são altos.
- Hospedagem: O uso de um serviço de banco de dados vetorial hospedado de um provedor de nuvem não requer nenhuma preocupação com a infraestrutura subjacente, é pago conforme o uso e tem uma estrutura de custos mais flexível, mas pode ser mais caro para uso a longo prazo.
Síntese:
Na seleção do banco de dados de vetores, é necessário considerar os sete fatores principais acima e fazer escolhas e compensações com base em cenários, necessidades e orçamentos de aplicativos específicos. Não existe um banco de dados ideal absoluto, apenas o banco de dados mais adequado para um cenário específico.
Comparação de diferentes tipos de soluções de bancos de dados vetoriais: um panorama da seleção de tecnologias
Diante das muitas soluções de bancos de dados vetoriais existentes no mercado, entender seus tipos e recursos o ajudará a restringir suas escolhas e a encontrar a solução certa para você mais rapidamente. Em linhas gerais, classificamos as soluções de bancos de dados vetoriais nas cinco categorias a seguir:
1. bibliotecas de vetores (FAISS, HNSWLib, ANNOY): índices leves, ferramentas de aceleração de dados estáticos
Bibliotecas de vetores, como FAISS (Facebook AI Similarity Search), HNSWLib (Hierarchical Navigable Small World Graphs Library) e ANNOY (Approximate Nearest Neighbors Oh Yeah), que são essencialmenteBibliotecas de software para construção de índices vetoriais e realização de pesquisas de similaridade. Em geral, são executados como bibliotecas incorporadas ao aplicativo, e não como serviços de banco de dados autônomos.
de ponta::
- Alto desempenho: Concentra-se na indexação de vetores e nos algoritmos de pesquisa de similaridade otimizados para uma recuperação extremamente rápida.
- Leve: Baixo consumo de recursos, simples de implementar e fácil de integrar aos aplicativos existentes.
- Maduro e estável: Após um longo período de desenvolvimento e ampla aplicação, a tecnologia é madura e confiável, com bom suporte da comunidade.
limitações::
- Os dados estáticos são predominantes: Ela é usada principalmente para armazenar dados estáticos, e não é fácil atualizar os dados depois que o índice é construído. Com exceção da HNSWLib, a maioria das bibliotecas de vetores não oferece suporte a operações CRUD, o que dificulta a atualização e a exclusão de dados.
- Funcionalidade limitada: Normalmente, oferecem apenas a função básica de índice vetorial e pesquisa de similaridade, sem distribuição, cópia de dados, gerenciamento de direitos, monitoramento de operações e manutenção e outros recursos avançados de banco de dados.
- Altos custos de O&M: Você precisa criar seu próprio ecossistema de implementação, lidar com a replicação de dados e a tolerância a falhas, além de não ter ferramentas de O&M e interfaces de gerenciamento abrangentes.
Cenários aplicáveis::
- Pesquisa de similaridade para conjuntos de dados estáticos: Por exemplo, cenários em que os dados são atualizados com pouca frequência, como bases de conhecimento construídas off-line, bases de mercadorias, bases de faces e assim por diante.
- Cenários com requisitos de desempenho muito altos, mas com baixa frequência de atualizações de dados: Os exemplos incluem a construção de índices off-line para mecanismos de pesquisa e a indexação de recursos off-line para sistemas de recomendação em grande escala.
- como um componente de aceleração de índice vetorial para outros bancos de dados: Por exemplo, o uso de bibliotecas vetoriais em conjunto com bancos de dados como Redis, MySQL etc. acelera a pesquisa de similaridade.
Produtos representativos:
- FAISS (Facebook AI Similarity Search): Desenvolvido pelo Facebook AI Research, amplamente utilizado no meio acadêmico e no setor. Fornece uma variedade de algoritmos de indexação eficientes, como IVF, PQ, HNSW etc., e é particularmente bom para lidar com conjuntos de dados em grande escala.
- HNSWLib (Biblioteca de gráficos hierárquicos navegáveis do mundo pequeno): Baseada no algoritmo HNSW (Hierarchical Navigable Small World), conhecido por seu alto desempenho e eficiência. A HNSWLib, comparada a outras bibliotecas vetoriais, é mais flexível, oferece suporte a operações CRUD e leitura e gravação simultâneas.
- ANNOY (Approximate Nearest Neighbors Oh Yeah): Desenvolvido pelo Spotify para se concentrar na busca rápida e aproximada do vizinho mais próximo. Conhecido por seu design limpo e eficiente, ele é adequado para cenários de aplicativos sensíveis à latência.
2. bancos de dados de pesquisa de texto completo (ElasticSearch, OpenSearch): complementar às pesquisas vetoriais, recurso não essencial
Os bancos de dados de pesquisa de texto completo, como o ElasticSearch e o OpenSearch, foram projetados principalmente para serem usados paraPesquisa de texto completo e pesquisa de palavras-chaveEles se baseiam na tecnologia de indexação invertida e são poderosos na recuperação de texto e na análise avançada. Nos últimos anos, eles também começaram a adicionar recursos de pesquisa vetorial, mas a pesquisa vetorial não é seu principal ponto forte.
de ponta::
- Recursos avançados de pesquisa de texto completo: Suporte para consultas de texto complexas, divisão de palavras, sinônimos, correção ortográfica, classificação de relevância (por exemplo, o que significa que o texto é mais importante do que a palavra). BM25) e outras funções.
- Análise avançada: Fornece agregação, estatísticas, relatórios e visualização de dados para análise de dados e insights de negócios.
- Ecossistemas maduros: Com uma grande base de usuários e um ecossistema bem estabelecido, é fácil de integrar e usar, com uma abundância de ferramentas periféricas e plug-ins.
limitações::
- O desempenho da recuperação de vetores é fraco: Em comparação com os bancos de dados de vetores dedicados, o desempenho da pesquisa de similaridade de vetores é baixo, especialmente em dados de alta dimensão e conjuntos de dados de grande escala, em que a latência da consulta é alta e a precisão pode ser insuficiente.
- Alto consumo de recursos: Para dar suporte a funções como pesquisa e análise de texto completo, o consumo de recursos é alto, e os custos de implantação, operação e manutenção são elevados.
- Não é bom em pesquisa semântica: Ele se baseia principalmente na correspondência de palavras-chave e na indexação invertida, com compreensão semântica limitada, o que dificulta o atendimento às necessidades complexas de pesquisa semântica.
Cenários aplicáveis::
- A pesquisa de palavras-chave é o principal aplicativo, complementado pela recuperação de vetores: Por exemplo, a pesquisa de produtos em sites de comércio eletrônico e a pesquisa de artigos em sites de notícias usam principalmente a pesquisa por palavra-chave, e a pesquisa vetorial é usada como uma função auxiliar para aumentar a relevância semântica da pesquisa.
- Cenários de pesquisa híbrida que exigem uma combinação de pesquisa de texto completo e pesquisa vetorial: Por exemplo, o sistema inteligente de atendimento ao cliente, que suporta pesquisas por palavra-chave e semântica, atende às diversas necessidades de consulta dos usuários.
- Análise de registros, monitoramento de alarmes e outros cenários que exigem funções de análise avançadas: Use o poderoso recurso de análise do banco de dados de pesquisa de texto completo para análise de registros, monitoramento e alertas, auditoria de segurança, etc.
produto representativo::
- ElasticSearch: Criado com base no Lucene, é um dos mais populares mecanismos de pesquisa de texto completo de código aberto, amplamente utilizado em pesquisa, análise de registros, visualização de dados e outros campos.
- OpenSearch: Com base no ElasticSearch e no Kibana, ele mantém a compatibilidade com o ElasticSearch e adiciona novos recursos e melhorias ao ElasticSearch.
Conclusão: Embora o ElasticSearch e o OpenSearch ofereçam recursos de recuperação de vetores, seu desempenho e funcionalidade ainda estão aquém dos bancos de dados vetoriais dedicados. Para sistemas RAG ou aplicativos de IA que se concentram na recuperação de vetores, os bancos de dados de vetores dedicados são a melhor opção. Os bancos de dados de pesquisa de texto completo são mais adequados como complemento à recuperação de vetores do que como alternativa.
3. bancos de dados SQL habilitados para vetores (pgvector, Supabase, StarRocks): extensões vetoriais para bancos de dados tradicionais, para aplicativos leves.
Os bancos de dados SQL, como o PostgreSQL, suportam tipos de dados vetoriais e recursos de pesquisa de similaridade por meio de extensões (por exemplo, pgvector). Isso permite que os usuários armazenem e consultem dados vetoriais em bancos de dados relacionais existentes sem a necessidade de introduzir um novo sistema de banco de dados.
de ponta::
- Fácil integração: A integração perfeita com os bancos de dados SQL existentes reduz a complexidade da pilha de tecnologia e reduz os custos de aprendizado e migração.
- Maduro e estável: A tecnologia de banco de dados SQL é madura e estável, com recursos avançados de gerenciamento de dados e processamento de transações, além de garantir a consistência e a confiabilidade dos dados.
- Baixo custo de aprendizado: Para os desenvolvedores que estão familiarizados com SQL, o custo de aprendizado é baixo e você pode começar a trabalhar com a funcionalidade de recuperação de vetores rapidamente.
limitações::
- O desempenho da recuperação de vetores é limitado: Os bancos de dados relacionais, cuja arquitetura não foi projetada para a recuperação de vetores, não apresentam o mesmo desempenho que os bancos de dados vetoriais dedicados, especialmente ao lidar com dados vetoriais de grande escala e alta dimensão, em que a latência da consulta é alta.
- A escalabilidade é limitada: Os bancos de dados relacionais têm uma escalabilidade relativamente fraca, o que dificulta lidar com dados vetoriais maciços e consultas altamente simultâneas, além de uma escalabilidade horizontal limitada.
- Restrições de dimensão vetorial: Por exemplo, o limite superior da dimensão do vetor suportado pelo pgvector é de 2.000 dimensões, o que é inferior aos bancos de dados de vetores dedicados e pode não atender às necessidades de dados vetoriais de alta dimensão.
Cenários aplicáveis::
- Aplicativos com pequenos volumes de dados vetoriais (abaixo do nível 100.000): Por exemplo, pequenos sistemas de recomendação, pesquisas simples de imagens, bases de conhecimento pessoal etc. têm pequenas quantidades de dados vetoriais e baixos requisitos de desempenho.
- Aplicação de dados vetoriais como uma função auxiliar: Por exemplo, ao adicionar um campo de vetor de produto ao banco de dados de produtos de um site de comércio eletrônico para recomendação de produto ou pesquisa de produto semelhante, a recuperação de vetor é apenas uma função auxiliar do banco de dados.
- Aplicativos que já possuem bancos de dados SQL maduros e desejam adicionar rapidamente recursos de recuperação de vetores: Em projetos que já usam bancos de dados SQL, como o PostgreSQL, e desejam introduzir rapidamente a funcionalidade de recuperação de vetores, considere o uso de extensões como o pgvector.
produto representativo::
- pgvector: Extensão do PostgreSQL, desenvolvida pela Crunchy Data, que fornece tipos de dados vetoriais (vetor) e índices (IVF, HNSW), bem como recursos de pesquisa de similaridade de vetores.
- Supabase: Plataforma PaaS de código aberto baseada no PostgreSQL, pgvector integrado, fácil para os usuários criarem rapidamente aplicativos que suportam a recuperação de vetores.
- StarRocks: Um banco de dados MPP orientado para OLAP que também adiciona a funcionalidade de recuperação de vetores, mas a recuperação de vetores não é seu nicho principal e é usada principalmente em cenários de análise OLAP.
Conclusão: Os bancos de dados SQL que oferecem suporte a vetores, como o pgvector, são mais adequados para cenários de aplicativos leves em que a quantidade de dados vetoriais é pequena, os requisitos de desempenho não são altos e os dados vetoriais são usados apenas como um recurso complementar do aplicativo. Se os dados vetoriais forem o núcleo do aplicativo ou se houver uma alta demanda por escalabilidade, um banco de dados vetorial dedicado seria uma opção melhor.
4. bancos de dados NoSQL habilitados para vetores (Redis, MongoDB): um esforço emergente com potencial e desafios
Os bancos de dados NoSQL, como o Redis e o MongoDB, também estão começando a experimentar a adição de suporte a vetores, como o Redis Vector Similarity Search (VSS) e o MongoDB Atlas Vector Search, que oferecem aos bancos de dados NoSQL a capacidade de lidar também com dados vetoriais.
de ponta::
- Vantagens inerentes dos bancos de dados NoSQL: Por exemplo, o Redis, por seu cache de alto desempenho, baixa latência e alta taxa de transferência; e o MongoDB, por seu modelo de documento flexível, facilidade de dimensionamento e recursos avançados de manipulação de documentos.
- Novidade técnica: Ele representa a tendência de desenvolvimento da tecnologia de banco de dados, incorporando o recurso de recuperação de vetores em bancos de dados NoSQL maduros, com certo potencial de inovação e desenvolvimento.
limitações::
- A funcionalidade ainda não está madura: A funcionalidade do suporte a vetores ainda está em seus estágios iniciais, com recursos e desempenho a serem refinados e validados, e o ecossistema é relativamente imaturo.
- Ecossistemas pobres: Há uma relativa escassez de ferramentas, bibliotecas e ecossistemas relevantes, cujo uso e manutenção podem ser caros, e o apoio da comunidade é relativamente fraco.
- Desempenho a ser considerado: Embora o Redis VSS afirme ter um excelente desempenho, os resultados reais precisam ser verificados em mais cenários e podem não ter o mesmo desempenho que os bancos de dados vetoriais dedicados em dados de alta dimensão e conjuntos de dados de grande escala.
Cenários aplicáveis::
- Cenários com requisitos de alto desempenho e pequenas quantidades de dados vetoriais: Por exemplo, os sistemas de recomendação em tempo real baseados em Redis, a recuperação de anúncios on-line etc. exigem recuperação de vetores de baixa latência e alta taxa de transferência.
- Cenários em que você deseja experimentar novas tecnologias e está disposto a assumir alguns riscos: Para os iniciantes em tecnologia, tente usar os recursos de suporte a vetores dos bancos de dados NoSQL para explorar seu potencial.
- Já estou usando um banco de dados NoSQL e gostaria de adicionar recursos de recuperação de vetores a ele: Em projetos que já estejam usando o Redis ou o MongoDB e queiram introduzir rapidamente a funcionalidade de recuperação de vetores sobre ele, considere o uso do módulo de extensão de vetores.
produto representativo::
- Pesquisa de Similaridade Vetorial (VSS) do Redis: Um módulo para o Redis que fornece indexação vetorial (HNSW) e funcionalidade de pesquisa por similaridade com ênfase em alto desempenho e baixa latência para cenários exigentes em tempo real.
- Pesquisa vetorial do MongoDB Atlas: Um novo recurso do Atlas, o serviço de nuvem do MongoDB, foi projetado para integrar a pesquisa vetorial ao banco de dados de documentos do MongoDB, fornecendo recursos de processamento de dados mais abrangentes.
Conclusão: Os recursos de suporte a vetores recém-adicionados aos bancos de dados NoSQL ainda estão nos estágios iniciais de desenvolvimento, e sua maturidade e estabilidade precisam ser mais bem verificadas. Embora tenham algum potencial, eles ainda podem ser menos maduros e poderosos do que os bancos de dados vetoriais dedicados em termos de funcionalidade e desempenho. A escolha precisa ser avaliada com cuidado e suas limitações devem ser totalmente consideradas.
5. bancos de dados vetoriais dedicados (Pinecone, Milvus, Weaviate, Qdrant, Vespa, Vald, Chroma, Vearch): criados para vetores, primeira opção para sistemas RAG e aplicativos de IA
Bancos de dados vetoriais dedicados, como Pinecone, Milvus, Weaviate, Qdrant, Vespa, Vald, Chroma, Vearch, etc., são projetados desde o início para se concentrarem noArmazenamento, indexação e recuperação de dados vetoriaisOs dados vetoriais de alta dimensão são inerentemente bem equipados para lidar com dados vetoriais de alta dimensão. Eles são a solução preferida para a criação de aplicativos de IA, como sistemas RAG, pesquisa semântica, sistemas de recomendação e muito mais.
de ponta::
- Excelente desempenho de recuperação de vetores: Ele é profundamente otimizado para a pesquisa de similaridade vetorial, com velocidade de recuperação rápida e alta precisão, e pode lidar eficientemente com dados vetoriais de alta dimensão em grande escala.
- Escalabilidade poderosa: Geralmente adota uma arquitetura distribuída, fácil de escalar horizontalmente, pode lidar com dados maciços e consultas de alta simultaneidade, para atender às necessidades de aplicativos de grande escala.
- Recursos avançados de funcionalidade: Em geral, ele oferece gerenciamento perfeito de dados vetoriais, construção de índices, otimização de consultas, monitoramento e funções de operação e manutenção, além de algoritmos avançados de pesquisa de similaridade e métricas de distância.
- Opções flexíveis de indexação: Oferece suporte a vários algoritmos de indexação vetorial (por exemplo, IVF, HNSW, PQ, indexação em árvore etc.), o que permite que você escolha a estratégia de indexação ideal de acordo com diferentes cenários de aplicativos e características de dados.
- Ecossistema maduro (alguns produtos): Alguns dos produtos têm comunidades ativas e ecossistemas bem estabelecidos, fornecendo documentação rica, ferramentas e soluções de integração que são fáceis de usar e integrar.
limitações::
- Custos de aprendizado mais altos: Em comparação com os bancos de dados tradicionais, os bancos de dados vetoriais dedicados podem ter uma curva de aprendizado mais acentuada e exigir um conhecimento de indexação vetorial, pesquisa de similaridade e outros conceitos relacionados.
- A seleção de tecnologia é complexa: Há muitos produtos com diferentes funções e recursos, e a seleção requer uma avaliação cuidadosa para comparar as vantagens e desvantagens dos diferentes produtos.
- Comercialização parcial de produtos: Alguns dos melhores bancos de dados de vetores dedicados são produtos comerciais (por exemplo, Pinecone), que são mais caros de usar e podem correr o risco de ficarem presos ao fornecedor.
Cenários aplicáveis::
- Aplicativos centrados na recuperação de vetores: Por exemplo, sistemas RAG, pesquisa semântica, pesquisa de imagens, pesquisa de áudio, pesquisa de vídeo, sistemas de recomendação, análise de bioinformática etc., a recuperação de vetores é uma função essencial do aplicativo.
- Aplicativos que precisam lidar com grandes quantidades de dados vetoriais de alta dimensão: Por exemplo, gráficos de conhecimento em grande escala, bibliotecas de produtos em massa e análise de dados de comportamento do usuário exigem o processamento de dados vetoriais de alta dimensão em grande escala.
- Aplicativos com altos requisitos de desempenho e precisão de recuperação: Por exemplo, o controle de riscos financeiros, o monitoramento de segurança e a recomendação precisa têm requisitos rigorosos de velocidade e precisão de recuperação.
- Aplicativos que exigem escalabilidade flexível e alta disponibilidade: Por exemplo, os serviços on-line em grande escala e as plataformas de nuvem precisam suportar o dimensionamento horizontal e a alta disponibilidade para garantir a estabilidade e a confiabilidade dos serviços.
produto representativo::
- Pinha: O banco de dados vetorial baseado em nuvem disponível comercialmente, mantido por uma equipe de profissionais, oferece serviços de recuperação de vetores fáceis de usar e altamente escaláveis. Conhecido por sua facilidade de uso e alto desempenho, ele é um representante dos bancos de dados vetoriais baseados em nuvem. No entanto, há limitações na natureza de código aberto e na personalização, e a versão gratuita tem funcionalidade limitada.
- Milvus: O banco de dados vetorial distribuído de código aberto, liderado pela empresa Zilliz, com desempenho poderoso, rico em recursos e comunidade ativa, é a referência do banco de dados vetorial de código aberto. Suporta uma variedade de tipos de índices, métricas de distância e métodos de consulta, podendo ser flexível para lidar com uma variedade de cenários de aplicativos.
- Weaviate: O banco de dados vetorial gráfico de código aberto, desenvolvido pela empresa alemã SeMI Technologies, combina a pesquisa vetorial com a tecnologia de banco de dados gráfico para oferecer recursos exclusivos de modelagem e consulta de dados. Oferece suporte à linguagem de consulta GraphQL para facilitar a consulta e a análise de dados complexos.
- Qdrant: Banco de dados vetorial de código aberto, desenvolvido por uma equipe russa, escrito em linguagem Rust, com foco em desempenho e facilidade de uso, arquitetura leve e baixo consumo de recursos. Popular por seu alto desempenho, baixa latência e facilidade de implementação.
- Vespa: Desenvolvido pelo Yahoo e por um mecanismo de pesquisa e banco de dados vetorial de código aberto, poderoso e de excelente desempenho, mas a arquitetura é mais complexa, com curva de aprendizado acentuada. Adequado para cenários com requisitos muito altos de desempenho e funcionalidade.
- Vald: Banco de dados vetorial distribuído de código aberto, desenvolvido por uma equipe japonesa, com foco na recuperação de vetores de alta precisão e alta confiabilidade. Ênfase em alta precisão e baixa latência, adequado para cenas com requisitos muito altos de precisão. No entanto, há deficiências na integração com o Langchain, e o tamanho da comunidade é pequeno.
- Pesquisa: O banco de dados vetorial distribuído de código aberto, desenvolvido por uma equipe chinesa, oferece serviços de recuperação vetorial de alto desempenho e alta disponibilidade. Concentra-se na facilidade de uso e na escalabilidade, e é adequado para projetos que precisam criar rapidamente aplicativos de recuperação de vetores. Há deficiências na integração com o Langchain e a comunidade é pequena.
- Croma: O Chroma é um banco de dados vetorial incorporado de código aberto que se concentra na leveza e na facilidade de uso, usando o SQLite como armazenamento de documentos. Adequado para o desenvolvimento local, prototipagem ou pequenos aplicativos, com escalabilidade e eficiência relativamente limitadas, o Chroma foi projetado especificamente para dados de áudio, mas não foi otimizado para lidar com dados de texto, e há uma escassez de informações abrangentes sobre benchmarking de desempenho.
Conclusão: Para os sistemas RAG e a maioria dos aplicativos de IA, os bancos de dados vetoriais dedicados são a melhor opção. Eles são melhores em termos de desempenho, funcionalidade e escalabilidade para atender melhor às necessidades desses aplicativos. Entre os vários bancos de dados vetoriais dedicados, Weaviate, Milvus, Qdrant e Vespa são alguns dos mais populares e amplamente usados atualmente.
Para comparar mais visualmente três excelentes bancos de dados vetoriais de código aberto, Weaviate, Milvus e Qdrant, resumimos a tabela abaixo:
| banco de dados abrangente | Qdrant | Weaviate | Milvus |
|---|---|---|---|
| Código aberto e auto-hospedado | ser | ser | ser |
| protocolo de código aberto | Apache-2.0 | BSD | Apache-2.0 |
| desenvolvimento da linguagem | Ferrugem | Ir | Go, C++ |
| Estrelas do Github (a partir de 2024) | 17k+ | 9.2k+ | 26.2k+ |
| Primeira data de lançamento | 2021 | 2019 | 2019 |
| SDK | Python, JS, Go, Java, .Net, Rust | Python, JS, Java, Go | Python, Java, JS, Go |
| Serviços de nuvem hospedada | ser | ser | ser |
| Incorporação de texto incorporado | FastEmbed | ser | ser |
| Pesquisa híbrida | ser | RRF*+RSF* | Mistura multivetorial na mesa |
| Filtragem de meta-informações | ser | ser | ser |
| Suporte BM25 | ser | ser | ser |
| Pesquisa de texto | ser | ser | ser |
| multivetor de ponto único (matemática) | ser | ser | ser |
| Pesquisa de Tensor | ser | ser | ser |
| Integração Langchain | ser | ser | ser |
| Integração do Índice Llama | ser | ser | ser |
| Geo Pesquisa de informações geográficas | ser | ser | ser |
| Suporte a vários locatários | via coleções/metadados | ser | ser |

Resumo:
- Qdrant: Arquitetura leve, baixa sobrecarga de recursos, excelente desempenho, fácil de implementar e usar, desenvolvimento em linguagem Rust, foco em desempenho e eficiência.
- Weaviate: Recursos abrangentes, integração de pesquisa vetorial, armazenamento de objetos e índice invertido, suporte para consultas GraphQL, recursos de modelagem de dados, desenvolvimento da linguagem Go, comunidade ativa.
- Milvus: Desempenho sólido, funcionalidade avançada, comunidade ativa, suporte para vários tipos de índices e métodos de consulta, pode lidar de forma flexível com vários cenários complexos, desenvolvimento em linguagem Go e C++, perfeição ecológica.
Você pode escolher o banco de dados vetorial que melhor atenda às suas necessidades, preferências de pilha de tecnologia e recursos da equipe.
Explicação dos métodos de pesquisa de banco de dados de vetores: desvendando as muitas posições da recuperação de vetores
A principal função dos bancos de dados vetoriais é a pesquisa de similaridade, e diferentes bancos de dados vetoriais oferecem uma variedade de métodos de pesquisa para atender a diferentes requisitos de aplicativos. Compreender esses métodos de pesquisa o ajudará a fazer um uso mais eficaz dos bancos de dados vetoriais para criar aplicativos de IA mais avançados.

6. comparação de métodos de pesquisa em bancos de dados de vetores
Vamos nos concentrar nos principais métodos de pesquisa de três bancos de dados, Milvus, Weaviate e Qdrant:
6.1 Milvus: estratégias de pesquisa flexíveis e variadas para diferentes cenários
O Milvus oferece uma estratégia de pesquisa rica e flexível. Você pode escolher o método de pesquisa apropriado de acordo com diferentes estruturas de dados e requisitos de consulta.
- Pesquisa de vetor único: Essa é a maneira mais básica de pesquisar, usando o
search()que compara um vetor de consulta com os vetores existentes na coleção, retornando os IDs de entidade mais semelhantes e suas distâncias. Você pode escolher os valores do vetor e os metadados dos resultados retornados. Ideal para cenários simples de pesquisa de similaridade, por exemplo, encontrar o produto mais semelhante a um determinado item, encontrar a imagem mais semelhante a uma determinada imagem etc. - Pesquisa multivetorial: para coleções que contêm vários campos vetoriais, por
hybrid_search()método. O método executa várias solicitações de pesquisa ANN (Approximate Nearest Neighbour) simultaneamente e funde e reorganiza os resultados para retornar as correspondências mais relevantes. A versão 2.4.x mais recente do Milvus suporta pesquisas usando até 10 vetores. A pesquisa multivetorial é particularmente adequada para cenários complexos em que é necessária alta precisão, por exemplo:- Os mesmos dados são processados usando diferentes modelos de incorporação: Por exemplo, a mesma frase pode ser gerada com diferentes representações vetoriais usando diferentes modelos, como BERT, Sentence-BERT, GPT-3 etc. A pesquisa multivetorial pode fundir as representações vetoriais desses diferentes modelos para melhorar a precisão da pesquisa.
- Fusão de dados multimodais: Por exemplo, várias informações modais, como imagens, impressões digitais e impressões de voz de indivíduos, são convertidas em diferentes formatos de vetores para uma pesquisa abrangente. A pesquisa multivetorial pode fundir as informações vetoriais dessas diferentes modalidades para obter uma pesquisa de similaridade mais abrangente.
- Aumentar as taxas de recall: Ao atribuir pesos a diferentes vetores e utilizar as informações de vários vetores em uma estratégia de "recall múltiplo", a capacidade de recall e a eficácia dos resultados da pesquisa podem ser significativamente aprimoradas para evitar a perda de resultados relevantes.
- Operações básicas de pesquisa: Além das pesquisas unidirecionais e multivetoriais, o Milvus oferece um conjunto avançado de operações básicas de pesquisa, incluindo:
- Pesquisa de vetores em lote: O envio de vários vetores de consulta de uma só vez melhora a eficiência da pesquisa e é adequado para cenários que exigem processamento em lote de consultas.
- Pesquisa de partição: Pesquise na partição especificada, restringindo o escopo da pesquisa e melhorando a velocidade da pesquisa. Adequado para cenários de grande volume de dados, você pode armazenar os dados por partição para aumentar a eficiência da consulta.
- Especifique os campos de saída a serem pesquisados: Retorna apenas os campos especificados, reduz a quantidade de transferência de dados, melhora a eficiência da pesquisa e é adequado para cenários em que apenas parte das informações do campo é necessária.
- Busca por filtro: Filtrar condições com base em campos escalares para refinar os resultados da pesquisa, por exemplo, filtrar com base em condições como preço do produto, idade do usuário, categoria do produto etc., filtrando ainda mais os resultados com base na pesquisa de similaridade para melhorar a precisão da pesquisa.
- Pesquisa de alcance: Encontre vetores cuja distância do vetor de consulta esteja dentro de um intervalo específico, por exemplo, encontre produtos com uma semelhança de 0,8 ou mais com o produto-alvo, o que é adequado para cenários em que o intervalo de semelhança precisa ser limitado.
- Pesquisa agrupada: O agrupamento de resultados de pesquisa com base em campos específicos garante a diversidade de resultados e evita a concentração excessiva de resultados, o que é adequado para cenários que exigem diversidade de resultados, por exemplo, sistemas de recomendação que desejam recomendar diferentes categorias de produtos.
6.2 Weaviate: um poderoso recurso de pesquisa híbrida que incorpora várias técnicas de pesquisa
A Weaviate oferece um poderoso recurso de pesquisa híbrida, que pode combinar com flexibilidade a pesquisa de similaridade vetorial, a pesquisa de palavras-chave, a pesquisa generativa e outros métodos de pesquisa para atender a requisitos complexos de consulta e fornecer uma solução de recuperação mais abrangente.
- Pesquisa de similaridade vetorial: O fornecimento de vários métodos de pesquisa de proximidade para encontrar o objeto mais semelhante ao vetor de consulta é o principal recurso de pesquisa da Weaviate.
- Pesquisa de imagens: Suporta o uso de imagens como entrada para pesquisa de similaridade para realizar a função de pesquisa de imagens, que é adequada para cenários de recuperação de imagens.
- Pesquisa de palavras-chave: Os resultados são classificados usando o algoritmo BM25F, que oferece suporte à recuperação eficiente de palavras-chave para cenários tradicionais de pesquisa de palavras-chave.
- Pesquisa de híbridos: A combinação da pesquisa de palavras-chave BM25 e da pesquisa de similaridade de vetores para a classificação de fusão de resultados, levando em conta a relevância semântica e a correspondência de palavras-chave, é adequada para cenários de pesquisa híbrida em que as informações semânticas e de palavras-chave precisam ser consideradas.
- Pesquisa generativa: Usar os resultados da pesquisa como dicas para o LLM para gerar respostas que correspondam melhor à intenção do usuário, combinando a pesquisa com a tecnologia de IA generativa para proporcionar uma experiência de pesquisa mais inteligente.
- Re-ranking: A qualidade dos resultados de pesquisa é otimizada ainda mais com o uso do módulo de reclassificação (Re-rank) para reclassificar os resultados de pesquisa recuperados para melhorar sua precisão e relevância.
- Agregação: Agregar dados da coleta de resultados, realizar análises estatísticas, fornecer recursos de análise de dados e auxiliar os usuários na mineração e análise de dados.
- Filtros: Aplique a filtragem condicional às pesquisas, por exemplo, com base em campos de metadados, para melhorar a precisão das pesquisas e oferecer suporte a condições de filtragem complexas.
6.3 Qdrant: foco na pesquisa vetorial, levando em conta a filtragem de texto completo, leve e eficiente
A Qdrant se concentra em fornecer serviços de pesquisa vetorial de alto desempenho com um equilíbrio de filtragem de texto completo e é conhecida por sua leveza, alto desempenho e facilidade de uso.
Operações básicas de pesquisa suportadas pelo Qdrant::
- Filtragem por pontuação: A filtragem baseada em pontuações de similaridade de vetores retorna apenas resultados com maior similaridade, melhorando a qualidade dos resultados da pesquisa.
- Uma única solicitação carrega várias operações de pesquisa (Multi-Search Requests): O envio de várias solicitações de pesquisa de uma só vez melhora a eficiência da pesquisa e é adequado para cenários que exigem processamento em lote de consultas.
- Recomendar API: Fornecer APIs de recomendação especiais para a criação de sistemas de recomendação e simplificar o processo de desenvolvimento de sistemas de recomendação.
- Agrupamento de operações: O agrupamento de resultados de pesquisa melhora a diversidade de resultados para cenários que exigem diversidade de resultados.
Outros métodos de pesquisa suportados pelo Qdrant::
O posicionamento central do Qdrant é um mecanismo de pesquisa vetorial, que oferece suporte limitado à pesquisa de texto completo para atender às necessidades básicas de filtragem de texto completo sem afetar o desempenho da pesquisa vetorial.
- Use a filtragem de texto completo: Os dados vetoriais podem ser filtrados usando filtros de texto completo, por exemplo, para encontrar dados vetoriais que contenham palavras-chave específicas, permitindo uma funcionalidade simples de pesquisa de texto completo.
- Filtro de texto completo com pesquisa vetorial: Realiza pesquisas vetoriais em registros com palavras-chave específicas para obter pesquisas mais precisas, combinando filtragem de texto completo e pesquisas vetoriais para melhorar a precisão das pesquisas.
- Prefix Search e Semantic Instant Search: Suporte à pesquisa de prefixo e à pesquisa semântica instantânea para proporcionar uma experiência mais amigável ao usuário, pesquisa difusa e pesquisa em tempo real.
Recursos planejados para o futuro da Qdrant::
- Há suporte para vetores esparsos: Por exemplo, os vetores esparsos usados no SPLADE ou em modelos semelhantes aumentam a capacidade de lidar com dados esparsos e melhoram a eficiência e a precisão da recuperação de vetores.
Recursos que não se destinam a ser suportados pelo Qdrant::
- BM25 ou outras funções de classificação ou recuperação não baseadas em vetores (recuperação não baseada em vetores): O Qdrant insiste na pesquisa vetorial como seu núcleo e não pretende oferecer suporte aos métodos tradicionais de recuperação baseados em palavras-chave, mantendo a arquitetura simples e eficiente.
- Ontologia integrada ou gráfico de conhecimento, analisador de consultas e outras ferramentas de PNL (ontologia integrada ou gráfico de conhecimento): A Qdrant se concentra na infraestrutura subjacente da pesquisa vetorial, deixando os aplicativos da camada superior e a funcionalidade de PNL fora da equação, mantendo o foco na funcionalidade principal e otimizando o desempenho.
Qual é a diferença entre o BM25 e uma simples pesquisa de palavras-chave? Uma análise detalhada da pontuação de relevância
No campo da pesquisa de palavras-chave, o algoritmo BM25 (Best Matching 25) é um método de pontuação de relevância mais avançado e eficaz do que a simples correspondência de palavras-chave. Entender a diferença entre eles o ajudará a escolher melhor a estratégia de pesquisa correta, especialmente em cenários em que a pesquisa por palavra-chave ou a pesquisa mista é necessária.
1. mecanismo de pontuação de relevância:
- Pesquisa simples de palavras-chave: A pontuação geralmente se baseia na frequência de termos (TF - Term Frequency), ou seja, quanto mais vezes uma palavra-chave aparecer em um documento, mais relevante ele será. Esse método é simples e direto, mas tende a ignorar o tamanho do documento e a importância das palavras-chave, o que pode levar à pontuação excessiva de documentos longos, bem como à interferência nos resultados de palavras comumente usadas e desativadas.
- BM25 (Best Matching 25): Usando um algoritmo mais complexo que leva em conta a frequência de palavras (TF), a frequência inversa de documentos (IDF - Inverse Document Frequency) e o tamanho do documento para pontuar a relevância dos documentos, o BM25 pode medir com mais precisão a relevância de um documento para uma consulta e abordar com eficácia as limitações das pesquisas simples por palavras-chave.
2. processamento do comprimento do documento:
- Pesquisa simples de palavras-chave: O comprimento do documento pode não ser levado em conta, resultando em documentos longos com maior probabilidade de serem considerados relevantes, pois documentos longos têm maior probabilidade de conter palavras-chave, resultando em uma tendência de documentos longos.
- BM25: Com a introdução do fator de normalização do comprimento do documento, o problema do viés do documento longo é resolvido para garantir a imparcialidade da pontuação de relevância entre documentos longos e curtos e para evitar que os documentos longos obtenham pontuações muito altas devido à vantagem do comprimento.
3. importância dos termos de consulta:
- Pesquisa simples de palavras-chave: É comum tratar todas as palavras-chave como igualmente importantes, ignorando a raridade das palavras-chave na coleção de documentos e fazendo com que palavras comuns e desativadas interfiram nos resultados.
- BM25: A importância das palavras-chave é medida usando a frequência inversa do documento (IDF). As palavras-chave com valores mais altos de IDF (ou seja, palavras-chave mais raras na coleção de documentos) contribuem mais para a pontuação de relevância do documento, diferenciando efetivamente a importância das palavras-chave e melhorando a qualidade dos resultados da pesquisa.
4. ajuste de parâmetros:
- Pesquisa simples de palavras-chave: Em geral, há menos parâmetros, o que dificulta o ajuste fino e o torna menos flexível.
- BM25: Parâmetros ajustáveis (por exemplo, k1 e b) são fornecidos para permitir que os usuários ajustem os algoritmos de acordo com cenários de aplicação e características de dados específicos, otimizem os resultados da pesquisa e melhorem a flexibilidade e a personalização da pesquisa.
Resumo:
Em comparação com a pesquisa simples por palavra-chave, o algoritmo BM25 é superior em termos de pontuação de relevância, processamento do comprimento do documento, medição da importância do termo de consulta e ajuste de parâmetros, e pode fornecer resultados de pesquisa mais precisos e esperados pelo usuário. Portanto, o algoritmo BM25 é uma escolha melhor em cenários com altos requisitos de qualidade de pesquisa, especialmente em cenários em que a pesquisa por palavra-chave ou a pesquisa híbrida é necessária, o algoritmo BM25 é uma tecnologia fundamental para melhorar os resultados da pesquisa.
7. benchmarking de desempenho e métricas em detalhes: avaliação quantitativa dos pontos fortes e fracos dos bancos de dados de vetores
O desempenho é uma consideração importante na seleção de um banco de dados vetorial. O benchmarking é um meio eficaz de avaliar o desempenho dos bancos de dados vetoriais. No entanto, deve-se observar que os resultados do benchmarking são afetados por uma variedade de fatores; portanto, ao se referir aos resultados do benchmarking, é necessário combiná-los com cenários e requisitos de aplicativos específicos para uma análise abrangente.
7. Apêndice
7.1 ANN Benchmarks: a plataforma autorizada de avaliação de desempenho
Benchmarks ANN O Approximate Nearest Neighbors Benchmarks (ANN-Benchmarks) é uma plataforma de avaliação de desempenho confiável para algoritmos de vizinho mais próximo, criada e mantida por Erik Bernhardsson. Ele fornece uma estrutura de benchmarking unificada e um conjunto de dados para avaliar o desempenho de vários algoritmos de pesquisa de vizinho mais próximo e bancos de dados vetoriais. O ANN-Benchmarks fornece uma referência importante para a avaliação de desempenho de bancos de dados vetoriais e é uma ferramenta importante para compreender as diferenças de desempenho entre diferentes bancos de dados vetoriais.
Fatores de influência para o benchmarking:
- Tipo de pesquisa: Pesquisa filtrada vs. Pesquisa regular, diferentes tipos de pesquisa têm impacto diferente no desempenho.
- Definições de configuração: Os parâmetros de configuração do banco de dados, como tipos de índice, parâmetros de índice, configurações de cache, etc., podem afetar significativamente o desempenho.
- Algoritmos de indexação: Diferentes algoritmos de indexação (por exemplo, IVF, HNSW, PQ) têm diferentes características de desempenho e são adequados para diferentes cenários de distribuição de dados e consultas.
- Incorporação de dados: A qualidade e a dimensionalidade da incorporação de dados afetam o desempenho e a precisão do banco de dados vetorial.
- Ambiente de hardware: A CPU, a memória, o disco, a rede e outros recursos de hardware afetam diretamente o desempenho do banco de dados.
Principais fatores a serem observados ao selecionar um modelo, além do benchmarking:
- Capacidades distribuídas: Se ele oferece suporte à implementação distribuída e pode ser dimensionado horizontalmente para lidar com dados massivos e alta simultaneidade.
- Cópias de dados e armazenamento em cache: Se deve oferecer suporte à cópia de dados e ao mecanismo de cache para garantir a segurança dos dados e melhorar o desempenho do sistema.
- Algoritmos de indexação: Que tipo de algoritmo de indexação é usado, as características de desempenho e os cenários aplicáveis do algoritmo e se há suporte para vários algoritmos de indexação.
- Recurso de pesquisa de similaridade de vetores: Suporte a pesquisa híbrida, filtragem, várias métricas de similaridade e outras funções avançadas de pesquisa para atender às necessidades de consultas complexas.
- Mecanismo de segmentação: Se deve oferecer suporte ao fatiamento de dados, como realizar o fatiamento e o gerenciamento de dados e melhorar a eficiência do gerenciamento e da consulta de dados.
- Abordagem de cluster: Como criar clusters, o dimensionamento e a estabilidade dos clusters, garantindo a alta disponibilidade e o dimensionamento do sistema.
- Potencial de escalabilidade: O limite superior da escalabilidade do sistema, se ele pode atender às necessidades de crescimento futuro dos negócios e prever a capacidade de expansão do sistema.
- Consistência de dados: Como garantir a consistência e a confiabilidade dos dados, especialmente em um ambiente distribuído.
- Disponibilidade geral do sistema: Estabilidade e confiabilidade do sistema, se ele pode garantir uma operação estável de 7x24 horas e atender aos requisitos de continuidade dos negócios.
Métricas angulares versus métricas euclidianas: principais métricas para recuperação de texto
No campo da recuperação de texto, os bancos de dados vetoriais emDistância angular O desempenho é geralmente melhor do queDistância Euclidiana mais importante. Isso ocorre porque as métricas angulares são mais sensíveis à similaridade semântica dos documentos de texto, enquanto as métricas euclidianas se concentram mais no comprimento e no tamanho dos documentos.
- Medida angular (por exemplo, distância cosseno): Foco na direção do vetor, não sensível ao comprimento do vetor, mais adequado para medir a similaridade semântica do texto, adequado para recuperação de texto, classificação de documentos e outros cenários.
- Métrica euclidiana (por exemplo, distância euclidiana): Ele também considera o tamanho e a direção dos vetores, é sensível ao comprimento dos vetores e é mais adequado para medir a distância absoluta dos vetores, o que é adequado para cenários como reconhecimento de imagem e reconhecimento de fala.
Portanto, ao selecionar o sistema RAG, devemos nos concentrar no banco de dados de vetores em diferentes dimensões doConjunto de dados de ângulosdesempenho, por exemplo, nos conjuntos de dados glove-100-angular e nytimes-256-angular.

Análise de desempenho (conjunto de dados glove-100-angular):
- Consultas por segundo (QPS): O Milvus apresenta a maior taxa de transferência quando a recuperação é inferior a 0,95, o que significa que o Milvus consegue lidar com uma maior simultaneidade de consultas com melhor desempenho, garantindo uma determinada recuperação. Quando a taxa de recall ultrapassa 0,95, a diferença de taxa de transferência entre os bancos de dados diminui, e a diferença de desempenho não é óbvia quando o recall é alto.
- Tempo de construção do índice: O Vespa tem o tempo de criação de índice mais longo, o Weaviate e o Milvus têm tempos de criação semelhantes, mas o Milvus é um pouco mais longo. O tempo de construção do índice afeta diretamente a velocidade de inicialização do banco de dados e a eficiência da atualização de dados; quanto menor o tempo de construção, mais rápida será a inicialização do banco de dados e a atualização de dados.
- Tamanho do índice: O Weaviate tem o menor índice e o Milvus tem o maior. O tamanho do índice afeta o custo de armazenamento e o uso da memória; quanto menor o índice, menor o custo de armazenamento e o uso da memória. Embora o índice do Milvus seja grande, para um conjunto de dados contendo 1,2 milhão de vetores de 100 dimensões, o tamanho do índice é inferior a 1,5 GB, o que ainda é aceitável, e o impacto do tamanho do índice deve ser avaliado de acordo com o tamanho dos dados em aplicações práticas.
7.1.2 Desempenho do conjunto de dados nytimes-256-angular

Análise de desempenho (conjunto de dados nytimes-256-angular):
O desempenho nesse conjunto de dados é semelhante ao do conjunto de dados glove-100-angular, com a tendência geral sendo consistente.
- Tempo de construção do índice: O Weaviate tem o tempo de construção de índice mais longo, o Milvus e o Qdrant são relativamente curtos, e a ordem do tempo de construção é consistente com o conjunto de dados glove-100-angular.
- Tamanho do índice: O índice da Weaviate é o menor, o da Milvus é o maior, mas tem apenas 440 MB (um conjunto de dados com 290.000 vetores de 256 dimensões), e a ordenação do tamanho do índice é consistente com o conjunto de dados glove-100-angular.
Resumo:
Os benchmarks ANN fornecem dados de referência de desempenho valiosos para nos ajudar a entender as características de desempenho de diferentes bancos de dados vetoriais. O Milvus se destaca em termos de taxa de transferência e é adequado para cenários de consulta altamente simultâneos; o Weaviate tem uma vantagem no tamanho do índice e economiza espaço de armazenamento; e o Vespa tem um tempo de construção relativamente mais longo e precisa ser considerado para a eficiência da construção do índice.
Ao selecionar um modelo, é necessário combinar cenários de aplicativos específicos, características de dados e requisitos de desempenho para uma avaliação abrangente, e não se pode confiar apenas nos resultados de testes de benchmark.
7.2 Métricas de similaridade de vetores: escolhendo as métricas certas para melhorar os resultados da recuperação
As métricas de similaridade de vetores são usadas para medir o grau de similaridade entre dois vetores, e diferentes métricas de similaridade são adequadas para diferentes tipos de dados e cenários de aplicativos. A escolha da métrica de similaridade correta afeta diretamente a precisão e o efeito da recuperação de vetores. Diferentes bancos de dados de vetores oferecem suporte a diferentes métricas de similaridade, portanto, é necessário escolher o banco de dados e as métricas de similaridade corretos de acordo com as necessidades reais.
| norma | descrições | de ponta | inferior | Cenários aplicáveis | Bancos de dados suportados |
|---|---|---|---|---|---|
| Distância do cosseno | Medir o cosseno do ângulo entre dois vetores | Foco na direção do vetor, não sensível ao comprimento do vetor; adequado para dados esparsos de alta dimensão | Insensível às informações de comprimento do vetor; não aplicável a conjuntos de dados não convexos | Computação de similaridade de texto, classificação de documentos, sistemas de recomendação | pgvector, Pinecone, Weaviate, Qdrant, Milvus, Vespa |
| Distância Euclidiana (L2) | Calcule a distância em linha reta entre dois vetores em um espaço multidimensional | Intuitivo e fácil de entender; considera tanto a magnitude quanto a direção do vetor | Degradação do desempenho em espaços de alta dimensão devido à "catástrofe dimensional"; sensibilidade a outliers | Reconhecimento de imagens, reconhecimento de fala, análise de escrita à mão | pgvector, Pinecone, Qdrant, Milvus, Vespa |
| Produto de ponto | Calcule a soma dos produtos dos componentes correspondentes do vetor | Computação rápida; reflete tanto a magnitude quanto a direção do vetor | Sensível à escala do vetor; pode exigir a normalização dos dados | Sistemas de recomendação, filtragem colaborativa, decomposição de matriz | pgvector, Pinecone, Weaviate, Qdrant, Milvus |
| Distância euclidiana quadrada L2 | Distância de Euclides ao quadrado | Penaliza grandes diferenças entre elementos vetoriais; mais eficaz em alguns casos | A operação de quadratura pode distorcer as distâncias; mais sensível a valores discrepantes | Processamento de imagens, detecção de anomalias | Weaviate |
| Distância de Hamming | Medição do número de valores diferentes correspondentes à posição de um vetor binário | Adequado para dados binários ou categóricos; cálculos rápidos | Não aplicável a dados numéricos contínuos | Detecção e correção de erros, correspondência de sequência de DNA | Weaviate, Milvus, Vespa |
| Distância de Manhattan (L1) | Medir a soma das distâncias entre dois vetores na direção dos eixos de coordenadas | Mais robusto em relação a outliers do que a distância euclidiana | O significado geométrico é menos intuitivo do que a distância euclidiana. | Cálculo da distância da placa, cálculo da distância da quadra da cidade | Weaviate |
7.2.1 Distância cosseno: a primeira opção para o cálculo de similaridade de texto
A distância de cosseno mede a similaridade dos vetores calculando o cosseno do ângulo entre dois vetores. Quanto mais próximo o valor do cosseno estiver de 1, mais semelhantes são os vetores; quanto mais próximo o valor do cosseno estiver de -1, menos semelhantes são os vetores; e com um valor de cosseno de 0, os vetores são ortogonais, indicando que não estão relacionados.
- vantagem::
- Concentre-se na direção do vetor e ignore o comprimento do vetor: A distância cosseno se concentra na direção do vetor e não é sensível ao comprimento do vetor. Isso a torna adequada para o processamento de dados textuais, pois o comprimento de um documento geralmente não é o fator principal nos cálculos de similaridade textual, enquanto o assunto e a direção semântica do documento são importantes.
- Para dados esparsos de alta dimensão: Em cenários de dados esparsos de alta dimensão, a distância cosseno ainda pode manter um bom desempenho e é adequada para o cálculo de similaridade de dados esparsos de alta dimensão, como texto e comportamento do usuário.
- desvantagens::
- Insensível às informações de comprimento do vetor: Em alguns cenários, as informações de comprimento dos vetores também podem ser importantes, por exemplo, em um sistema de recomendação, o nível de atividade do usuário (comprimento do vetor) pode ser um recurso importante. A distância cosseno ignora essas informações e pode levar à perda de informações.
- Não aplicável a conjuntos de dados não convexos: Se a distribuição de dados não for um conjunto convexo, a distância cosseno pode não fornecer uma medida de similaridade precisa, e uma métrica de similaridade adequada precisa ser selecionada com base na distribuição de dados.
- Cenários aplicáveis::
- Cálculo de similaridade de texto: Por exemplo, calcular a semelhança semântica de dois artigos, duas frases ou dois parágrafos é uma métrica comum para o cálculo da semelhança de texto.
- Categorização de documentos: Os documentos são classificados em diferentes categorias com base na similaridade dos vetores de documentos.
- Sistemas recomendados: As recomendações são baseadas no comportamento do usuário ou nas características do item, e a semelhança entre os vetores do usuário e os vetores do item é calculada para recomendações personalizadas.
- Cenários de dados esparsos de alta dimensão: Por exemplo, o cálculo da similaridade de dados esparsos de alta dimensão, como dados de comportamento do usuário e dados de recursos do produto.
7.2.2 Distância Euclidiana (L2): intuitiva e fácil de entender, mas o desempenho é limitado em espaços de dimensões maiores.
A distância euclidiana, também conhecida como norma L2, calcula a distância em linha reta entre dois vetores em um espaço multidimensional. Quanto menor a distância, mais semelhantes são os vetores; quanto maior a distância, menos semelhantes são os vetores.
- vantagem::
- Intuitivo e fácil de entender: O conceito de distância euclidiana é simples e intuitivo, fácil de entender e usar, e é uma das medidas de distância mais comuns usadas pelas pessoas.
- Considere a magnitude e a direção do vetor: A distância euclidiana leva em conta tanto a magnitude quanto a direção dos vetores, o que fornece uma imagem mais completa das diferenças entre os vetores e é adequada para cenários em que tanto a magnitude quanto a direção dos vetores precisam ser levadas em conta.
- desvantagens::
- O desempenho do espaço dimensional mais alto é degradado pela "catástrofe dimensional": Em espaços de alta dimensão, as distâncias euclidianas entre todos os pontos tendem a ser iguais, o que leva a uma diminuição da diferenciação, afetando a precisão da pesquisa de similaridade e limitando o desempenho em cenários de dados de alta dimensão.
- Sensível a valores discrepantes: A distância euclidiana é sensível a outliers, que afetam significativamente os resultados do cálculo da distância e são menos robustos.
- Cenários aplicáveis::
- Reconhecimento de imagens: Por exemplo, reconhecimento facial, reconhecimento de objetos etc., comparação de similaridade com base na distância euclidiana dos vetores de recursos de imagem.
- Reconhecimento de fala: A correspondência de recursos de fala, por exemplo, realiza comparações de similaridade com base na distância euclidiana dos vetores de recursos de fala.
- Análise de caligrafia: Por exemplo, reconhecimento de caracteres manuscritos, comparação de similaridade com base na distância euclidiana de vetores de recursos de caracteres manuscritos.
- Cenários de dados de baixa dimensão: Em cenários de dados de baixa dimensão, a distância euclidiana ainda é uma métrica de similaridade eficaz para a pesquisa de similaridade em dados de baixa dimensão.
7.2.3 Produto de pontos: cálculo eficiente, adequado para sistemas de recomendação
O produto interno, também conhecido como produto escalar, calcula a soma dos produtos dos componentes correspondentes de dois vetores. Quanto maior o produto interno, mais semelhantes são os vetores; quanto menor o produto interno, menos semelhantes são os vetores.
- vantagem::
- Os cálculos são rápidos: O produto interno é muito rápido, especialmente quando a dimensão do vetor é alta, a vantagem de desempenho é mais óbvia, adequada para dados em grande escala e cenários de alta simultaneidade.
- Reflete a magnitude e a direção do vetor: O produto interno leva em conta a magnitude e a direção dos vetores, o que reflete a similaridade geral dos vetores, e é adequado para cenários em que a magnitude e a direção dos vetores precisam ser levadas em conta.
- desvantagens::
- Sensível a escalas vetoriais: O valor do produto interno é afetado pela escala dos vetores e, se os vetores tiverem uma grande diferença de escala, a medida de similaridade do produto interno poderá ser distorcida e sensível à escala dos vetores.
- Pode ser necessária a normalização dos dados: Para eliminar o efeito das diferenças de escala do vetor, muitas vezes é necessário normalizar os dados, por exemplo, normalizando os vetores para o comprimento da unidade, a fim de garantir a precisão da medida de similaridade do produto interno.
- Cenários aplicáveis::
- Sistemas recomendados: Por exemplo, para calcular a similaridade entre vetores de usuários e vetores de itens para recomendações personalizadas, o produto interno é uma métrica de similaridade comumente usada em sistemas de recomendação.
- Filtragem colaborativa: As recomendações são feitas com base na similaridade de usuários ou itens, usando o produto interno para calcular a similaridade entre usuários ou itens.
- Decomposição de matrizes: usado para redução de dimensionalidade e extração de recursos, e o produto interno pode ser usado para medir a similaridade entre vetores e ajudar na implementação de algoritmos de decomposição de matrizes.
- Cenários que exigem computação de alto desempenho: Por exemplo, sistemas de recomendação on-line em grande escala, sistemas de recuperação em tempo real e outros cenários que exigem o cálculo rápido da similaridade de vetores.
7.2.4 L2 Squared Euclidean Distance: amplifica as diferenças, eficaz para cenas específicas
L2 A distância quadrada é o quadrado da distância euclidiana e é calculada como o valor quadrado da distância euclidiana.
- vantagem::
- Grandes diferenças entre os elementos do vetor de penalidade: A operação de quadratura amplia as diferenças entre os elementos do vetor, tornando os valores de distância mais sensíveis às diferenças. Em alguns casos, essa propriedade pode ser mais benéfica para distinguir semelhanças e destacar diferenças.
- Evitar cálculos de raiz quadrada melhora a eficiência computacional: Em alguns cenários de cálculo, os cálculos de raiz quadrada podem ser evitados para aumentar a eficiência e simplificar o processo de cálculo.
- desvantagens::
- As operações de quadratura podem distorcer as distâncias: A operação de quadratura altera a escala da distância, o que pode resultar em um significado menos interpretativo da distância, que é menos intuitivo do que a distância euclidiana.
- Mais sensível a valores discrepantes: A operação de quadratura amplifica ainda mais o efeito dos outliers, tornando a distância ao quadrado L2 mais sensível aos outliers e menos robusta.
- Cenários aplicáveis::
- Processamento de imagens: Por exemplo, para comparar duas imagens no nível do pixel, a distância L2 ao quadrado amplia as diferenças de pixel e compara as nuances das imagens de forma mais eficaz.
- Detecção de anomalias: Amplificar o impacto dos outliers facilita a detecção de dados anômalos e é adequado para cenários de detecção de anomalias sensíveis a outliers.
- Cenários específicos em que as diferenças precisam ser ampliadas: A distância quadrada L2 pode ser mais eficaz do que a distância euclidiana em determinados cenários específicos em que a diferenciação precisa ser destacada.
7.2.5 Distância de Hamming: uma métrica exclusiva para dados binários
A distância de Hamming mede o número de valores diferentes nas posições correspondentes de dois vetores binários de comprimento igual e é usada para medir o grau de diferença entre vetores binários.
- vantagem::
- Para dados binários ou categóricos: A distância de Hamming é usada especificamente para medir diferenças em dados binários ou categóricos e é adequada para cálculos de similaridade de vetores binários.
- Os cálculos são rápidos: O cálculo da distância de Hamming é muito simples e eficiente, e requer apenas a comparação das posições correspondentes dos vetores binários e a contagem do número de valores diferentes.
- desvantagens::
- Não aplicável a dados numéricos contínuos: A distância de Hamming só pode ser usada para dados binários ou categóricos e não pode lidar com dados numéricos contínuos, o que tem um escopo de aplicação limitado.
- Cenários aplicáveis::
- Detecção e correção de erros: Por exemplo, na codificação de comunicação, a distância de Hamming é usada para medir a diferença entre palavras-código para detecção e correção de erros e é um conceito importante na teoria da codificação.
- Comparação da sequência de DNA: As sequências de DNA foram convertidas em representação binária e a comparação de sequências foi realizada usando a distância de Hamming para análise de bioinformática.
- Cálculo de similaridade de dados do subtipo: É adequado para o cálculo de similaridade de dados subtipados, por exemplo, cálculo de similaridade de dados categorizados, como rótulos de usuários e atributos de produtos.
7.2.6 Distância Manhattan (L1): métrica de distância mais robusta, resistente a outliers
A distância de Manhattan, também conhecida como norma L1 ou distância de quarteirão, é calculada como a soma das diferenças absolutas entre dois vetores em todas as dimensões.
- vantagem::
- Mais robusto em relação a outliers do que a distância euclidiana: A distância de Manhattan é menos sensível a outliers do que a distância euclidiana porque calcula apenas a diferença absoluta, não a diferença quadrada, e é mais robusta e resistente à interferência de outliers.
- Os cálculos são relativamente rápidos: A distância de Manhattan é um pouco mais rápida do que a distância euclidiana e é adequada para cenários em que a distância precisa ser calculada rapidamente.
- desvantagens::
- A significância geométrica é menos intuitiva do que a distância euclidiana: O significado geométrico da distância de Manhattan é menos intuitivo do que a distância euclidiana, menos fácil de entender e menos interpretável geometricamente.
- Cenários aplicáveis::
- Cálculo da distância da placa: Por exemplo, para calcular a distância entre dois quadrados em um tabuleiro de xadrez, a distância de Manhattan é comumente usada para calcular a distância do tabuleiro.
- Cálculos de distância de bairros urbanos: Por exemplo, para calcular a distância entre dois locais em uma cidade, ignorando as distâncias na direção diagonal, a distância de Manhattan também é conhecida como distância de quarteirão.
- O problema do caminho mais curto no planejamento logístico: A distância de Manhattan pode ser usada para avaliar os comprimentos de caminho no planejamento de logística e auxiliar na implementação de algoritmos de caminho mais curto.
- Cenários que são menos sensíveis a discrepâncias: Em cenários em que o efeito dos outliers precisa ser reduzido, a distância de Manhattan é mais aplicável e robusta do que a distância euclidiana.
8 Referências
- https://github.com/milvus-io/milvus
- Potencializando o Al com bancos de dados vetoriais: uma referência - Parte I - Dados - Blog - F-Tech
- Fundamentos - Qdrant
- Documentação de Milvus
- Home | Weaviate - Banco de dados vetorial
- Documentação da Qdrant - Qdrant
- Casos de uso de banco de dados vetorial - Qdrant
- Bancos de dados vetoriais: introdução, casos de uso, os 5 principais bancos de dados vetoriais
- Benchmarks ANN
- Métricas de distância na pesquisa vetorial - Weaviate
- BM25 - Enciclopédia Baidu
© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Artigos relacionados

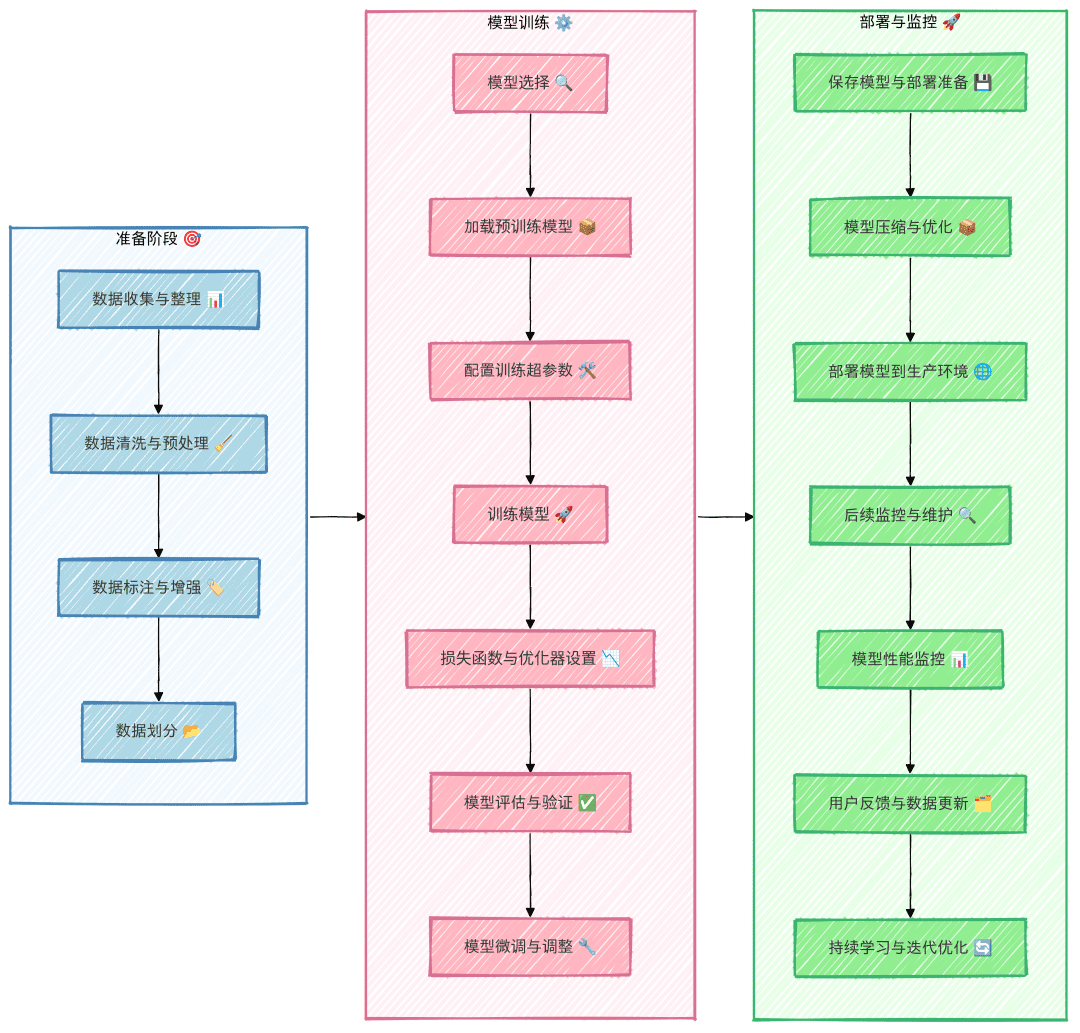


Nenhum comentário...