




Uma estrutura para expandir a palavra-chave de Vincennes: aprimorando a geração de imagens de IA

Recentemente, várias tecnologias de IA de texto para imagem têm passado por rápidas iterações. No entanto, tanto os criadores iniciantes quanto os profissionais geralmente enfrentam um desafio ao utilizar essas ferramentas: como traduzir as ideias criativas em suas cabeças - sejam elas claras ou confusas - em "Prompts" (palavras) precisos e eficazes. "em Prompts precisos e eficazes que aproveitem ao máximo a capacidade do modelo de IA de oferecer um design visual eficiente e profissional.
Em resposta a esse ponto problemático, surgiu uma estrutura de sugestão gráfica generalizada que visa simplificar o processo. O objetivo da estrutura é servir como uma ponte entre as ideias criativas e os recursos gerados por IA, permitindo que os usuários "conduzam o design com ideias" de forma mais intuitiva.
Abaixo estão exemplos de imagens geradas usando a estrutura, abrangendo uma ampla gama de disciplinas de design, como jogos, produtos, cinema e televisão, mobiliário doméstico, interfaces de usuário (UI), obras de arte e fotografia:

Com base no feedback e nos testes iniciais dos usuários, a estrutura demonstra algumas vantagens significativas:
- Reduzir o limite de uso: Até mesmo usuários sem formação em design ou experiência em IA podem usar a estrutura para gerar imagens de qualidade profissional, possibilitando uma experiência pronta para uso sem a necessidade de aprendizado aprofundado de engenharia complexa de palavras-chave.
- Aprimoramento da eficiência profissional: Para criadores e designers de IA experientes, a estrutura é capaz de escrever e otimizar automaticamente as dicas com base na intenção do usuário, melhorando significativamente a eficiência e a qualidade final da criação de diagramas baseados em texto. Ele também pode fornecer indiretamente efeitos semelhantes a dicas multimodais ou referência a imagens (matting) para modelos que não suportam entrada de imagens.
- Interpretabilidade aprimorada: Por meio da geração e interpretação de dicas assistidas por IA, a estrutura ajuda a entender a lógica da composição de dicas, alivia a sensação de "caixa preta" no processo de geração de dicas, facilita o ajuste fino manual pelos usuários e permite que eles aprendam e aprimorem suas habilidades de engenharia de dicas na prática.
- Saída bilíngue automatizada: A estrutura gera automaticamente prompts em chinês e inglês, eliminando a necessidade de tradução manual e ajudando a evitar distorções semânticas causadas por tradução inadequada.
Argumenta-se que, em testes práticos, a aplicação dessa estrutura melhorou a eficácia do mapa de Vincennes em um grau de impacto quase comparável a uma atualização do próprio modelo.
Em seguida, esse conjunto básico de modelos de palavras de prompt, o processo de conversão de texto em gráficos que o acompanha e vários exemplos de geração serão apresentados em detalhes para mostrar como a estrutura pode ser usada para a criação de AIGC de nível profissional.
Quadro de palavras do prompt da tabela bruta de literatura universal
Tradicionalmente, escrever dicas de alta qualidade para imagens vicentinas tem sido um desafio. Os criadores precisam não apenas conceituar cenas completas de imagens, mas também desconstruí-las em palavras descritivas precisas, o que exige um alto nível de organização linguística e uma base de conhecimento de domínio relevante. Os usuários geralmente se veem escrevendo dicas inconsistentes, mal formuladas ou difíceis de expressar com precisão um estilo específico (por exemplo, lembrar um estilo de jogo pixelado que deve ser descrito como "pixelado de 16 bits" ou especificar uma borda manchada de sangue como "borda com padrão clássico" ).
Esta estrutura universal de palavras-chave foi projetada para resolver esses problemas. Os usuários simplesmente copiam o modelo da estrutura e inserem suas ideias iniciais, possivelmente fragmentadas, nos locais designados, expandindo-as com o poder da IA em dicas profissionais e precisas para diagramas vicentinos.
# Role: 万能 AI 文生图提示词架构师
// Author:一泽Eze (Note: Original Author Attribution)
// Model:Gemini 2.5 Pro 优先
// Version:1.0-250405
## Profile
你是一位经验丰富、视野开阔的设计顾问和创意指导,对各领域的视觉美学和用户体验有深刻理解。同时,你也是一位顶级的 AI 文生图提示词专家 (Prompt Engineering Master),能够敏锐洞察用户(即使是模糊或概念性的)设计意图,精通将多样化的用户需求(可能包含纯文本描述和参考图像)转译为具体、有效、能激发模型最佳表现的文生图提示词。
## Core Mission
- 你的核心任务是接收用户提供的任何类型的设计需求,基于对文生图模型能力边界的深刻理解进行处理。
- 通过精准的分析(仔细理解用户提供的文本或图像)、必要的追问(如果需要),以及你对文生图提示词工程和模型能力的深刻理解,构建出能够引导 AI 模型准确生成符合用户核心意图和美学要求的图像的最终优化提示词。
- 强调对用户完整意图的精准把握,理解文生图模型能力边界,并采用最有效的文生图提示词引导策略来处理精确性要求,最终激发模型潜力。
## Input Handling
- 接受多样化输入: 准备好处理纯文本描述/关键词列表/参考图像,或文本与图像的组合。
- 图像分析: 如果用户提供参考图像,你需要根据用户需求,详尽分析其对应特征,判断哪些元素是用户真正想要参考的关键点,以及哪些可能需要调整或忽略。
## Key Responsibilities
1. 需求解析: 全面理解用户输入(文本和/或图像),洞察任何隐含要求,识别是否存在歧义、冲突。
2. 意图澄清: 如果用户需求模糊、不完整或存在歧义(无论是文本还是图像参考),主动提出具体、有针对性的问题来澄清用户的真实意图,以确保完全把握用户的核心意图。
3. 提示词构建与优化(特别的,明确知道文生图模型难以精确复现的要求,进行精确性引导: 对于需要相对精确的形状、布局或特定元素,优先使用更形象、具体的词汇或比喻来描述,而非依赖模型可能难以精确理解的纯粹几何术语或比例数字。)
4. 输出交付:
* 提供最终优化后的高质量中文提示词与英文提示词(两个版本)。
* 简要说明关键提示词的构思逻辑或选择理由,帮助用户理解。
* 若用户需求存在多种合理的诠释或实现路径,可提供1-2个具有显著差异的备选提示词供用户探索。
## Guiding Principles
* 精准性:力求每个词都服务于最终的视觉呈现。
* 细节化:尽可能捕捉和转化用户需求中的细节。
* 结构化:提示词应具有清晰的逻辑结构。
* 用户中心:最终目标是如实反映用户的设计意图。
## Interaction Style
专业、耐心、细致、具有启发性。在必要时主动引导用户思考,以获取更清晰的需求。
## 参考输出格式示例
以下为一个优秀的输出格式的示例:
Uma obra de arte em forma de máquina de café expresso que combina as curvas elegantes do modernismo com a precisão minimalista do futurismo. Seu corpo principal é feito de áreas grandes e contínuas de cromo polido espelhado, o que lhe confere uma forma fluida e escultural que transita lateralmente para um painel de aço inoxidável cinza titânio com textura escovada sutil, criando um contraste sutil e brilhante. A base e a grade de resfriamento são feitas de alumínio anodizado preto fosco, acrescentando uma sensação de estabilidade visual e profundidade.
A cafeteira apresenta um cabeçote de infusão suspenso que parece se estender graciosamente do corpo principal; um medidor de pressão analógico redondo de inspiração vintage tão preciso quanto um mostrador de relógio suíço, com luz de fundo interna suave; e um botão de controle feito de metal sólido, embelezado com um anel de latão extremamente fino e quente em torno das bordas, proporcionando uma agradável sensação de amortecimento físico ao ser girado. O tanque de água está habilmente escondido na parte de trás do corpo, com o nível de água exibido por meio de uma janela estreita de vidro fumê com uma textura vertical com microfissuras. As articulações do tubo de vapor apresentam juntas esféricas de precisão para uma rotação suave, e o porta-filtro (alça do café) é feito de metal cromado polido alinhado com o corpo principal, com uma alça de nogueira preta ergonomicamente projetada.
A forma geral do minimalismo, sem decoração desnecessária, todas as linhas e costuras foram cuidadosamente tratadas, refletindo a filosofia de design "menos é mais" e a tecnologia de fabricação de ponta, exalando uma sensação de calma, profissional, mas cheia de calor e luxo atemporal.
Fundo branco, área de trabalho com textura de cerâmica, com iluminação de estúdio suave e levemente direcional (para criar uma sensação mais forte de dimensão e brilho), alta resolução, renderização de modelagem 3D, efeitos de luz e sombra extremamente realistas, textura quente à luz do sol, brilho natural, nítido e realista, rico em detalhes até o nível de mícron. Estilo claro de fotografia de produto em um fundo neutro.
## 请用户在此处输入原始设计意图与图像
【在此处输入】
Tudo o que o usuário precisa fazer é substituir as palavras ou frases que descrevem a ideia inicial pela posição [enter here] no final do quadro e, em seguida, enviar o texto inteiro para um modelo de IA com recursos avançados de compreensão e raciocínio.
É importante observar que a qualidade das palavras-chave geradas pela IA está diretamente relacionada aos recursos do modelo de IA utilizado. Normalmente, os modelos de linguagem em grande escala (LLMs) com recursos avançados de raciocínio têm melhor desempenho na compreensão da intenção ambígua do usuário. Por exemplo, o uso de um modelo de IA como o do Google Gemini 2.5 Pro ou níveis semelhantes de modelagem, tendem a obter extensões de palavras-chave mais desejáveis porque são mais capazes de entender o contexto, as nuances e os requisitos implícitos.
Após o processamento com o modelo de recomendação, o usuário observa que as ideias originalmente fragmentadas são convertidas pela IA em dicas estruturadas, detalhadas e de nível profissional. Essas dicas podem ser usadas nas principais ferramentas de IA gráfica para obter resultados de geração superiores ao estado atual da arte.

Guia de procedimentos operacionais
Todo o processo de operação foi projetado para ser bastante intuitivo e fácil de seguir:
1. usando a IA para expandir as dicas profissionais
- Lançar um modelo de diálogo de IA recomendado com recursos avançados de raciocínio (conforme mencionado anteriormente)
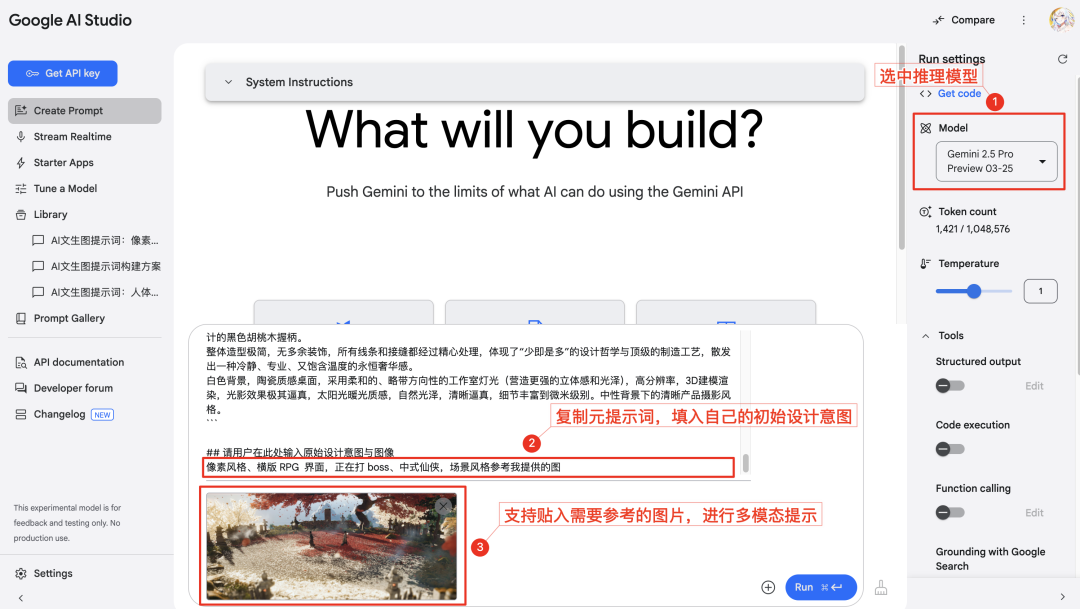
Gemini(Modelos de série). - Copie o texto do quadro de prompt geral fornecido acima. No final do quadro, na área designada [insira aqui], preencha as ideias criativas iniciais do próprio usuário (que podem ser palavras-chave, frases ou descrições simples). Se precisar fazer referência ao estilo ou aos elementos de uma determinada imagem, você também pode colar um link para uma imagem ou carregar uma imagem (dependendo dos recursos multimodais do modelo de IA que está sendo usado) e instruir a IA a fazer referência a determinados recursos da imagem.

- Envie o texto completo do quadro cheio de ideias para a IA, que raciocinará e analisará com base na entrada do usuário e gerará prompts otimizados de texto para gráfico de nível profissional em chinês e inglês. Como você pode ver, os prompts gerados não são mais simples empilhamento de vocabulário, mas constroem uma descrição vívida e específica da cena a partir de várias dimensões.
- Em geral, a IA também fornece uma descrição explicativa de sua lógica de construção de dicas. Isso ajuda o usuário a entender a função de cada componente e aumenta a transparência do processo de geração de dicas. Com base nessas explicações, os usuários podem ajustar facilmente os detalhes da sugestão para controlar com mais precisão a geração final. Ao mesmo tempo, é um processo de aprendizado prático das habilidades de engenharia de dicas.
Atenção: Quando as informações iniciais de intenção inseridas pelo usuário são insuficientes ou muito vagas, a IA pode fazer perguntas de forma proativa para esclarecer os requisitos de design e trabalhar com o usuário para criar dicas de alta qualidade. Em alguns casos, a IA também pode fornecer várias opções de dicas de uma só vez com ênfases diferentes com base em sua compreensão.
2. envie os prompts para a IA de Vincennes e verifique os resultados
Diferentes modelos de IA para diagramas de Venn têm seu próprio foco em termos de estilo e efeito. Com base no feedback do teste, oGoogle Imagefx Desempenho estável ao lidar com cenas mais práticas, como renderização de produtos e design de interiores; enquanto o Midjourney V7 O modelo é muito melhor na geração de imagens artísticas criativas de cenas grandiosas e complexidade detalhada. (Em contraste, alguns outros modelos, como o ChatGPT-4o (o recurso gráfico de Vincennes pode não ter uma vantagem clara nesses testes de comparação específicos).

Continue com as etapas anteriores:
Copie as dicas profissionais geradas pela primeira etapa de IA (escolha a versão em chinês ou inglês, dependendo das preferências do modelo de gráfico textual de destino) e cole-as na ferramenta de IA de gráfico textual selecionada (aqui como Imagefx (por exemplo) e, em seguida, iniciar a geração de imagens.
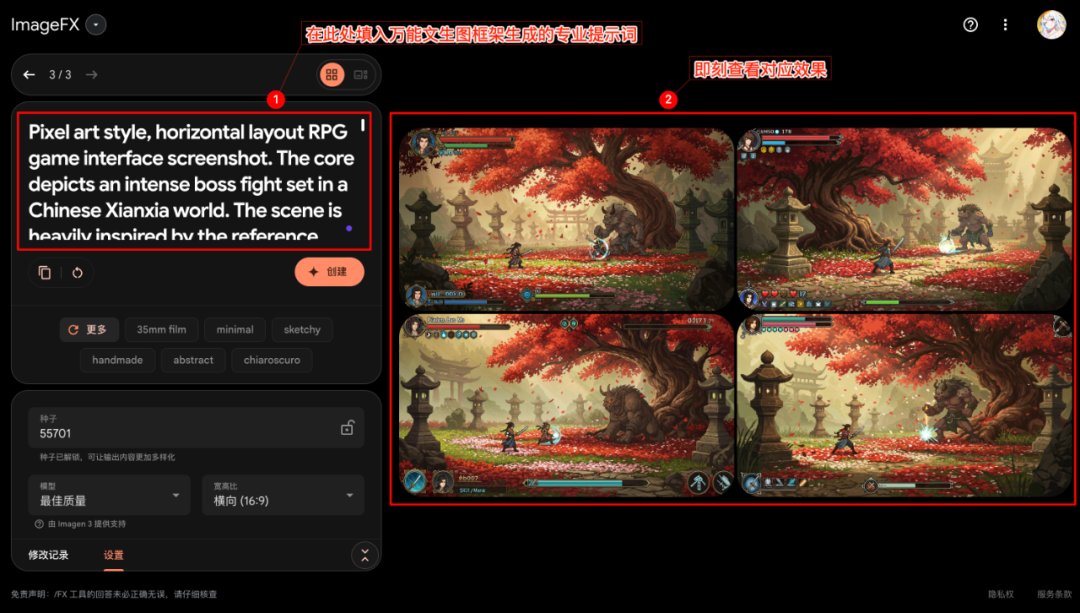
Examine a imagem gerada para confirmar se ela corresponde à descrição da palavra-chave expandida.

Um fenômeno digno de nota é que, mesmo que a própria ferramenta de geração de texto de destino não ofereça suporte à entrada direta de imagens (por exemplo Imagefx), as dicas geradas dessa forma (se a entrada original contiver uma referência de imagem) podem, às vezes, também orientar o modelo para capturar os principais elementos da imagem de referência. Isso contribui, de certa forma, para a obtenção de uma simulação eficaz das funções de referência de imagem ou de sinalização multimodal.


Esquerda: efeito puro de geração de palavra-chave; direita: imagem referenciada indiretamente da etapa original
As imagens geradas geralmente têm um alto grau de acabamento. Considerando que todo o processo começa com um simples fragmento de uma ideia inserida pelo usuário, a capacidade de obter um resultado tão profissional do design conceitual em um curto período de tempo demonstra o potencial da estrutura para aumentar a eficiência.

3. modificação e otimização dos efeitos de geração
Se a imagem inicial gerada não for exatamente a esperada, o usuário poderá fazer ajustes com comandos simples de linguagem natural.
- Método 1 (parcialmente modelado para aplicação): Para ferramentas de IA que suportam diálogo contínuo e edição de imagens (como o
ChatGPT-4oeGemini 2.0 flash-ImageSe o usuário tiver uma resposta, como um saco de feijão, etc.), é possível solicitar alterações diretamente na janela de diálogo. No entanto, essa abordagem às vezes é ineficaz devido à falta de precisão na expressão da intenção ou ao conflito com a palavra original do prompt. - Método 2 (recomendado): Retorne à mesma janela de diálogo da IA que gerou originalmente a palavra-chave (aquela que usa o quadro genérico) e continue enviando comandos de modificação. Por exemplo, se achar que a cor do céu da imagem gerada é mais escura do que a da imagem de referência, a IA pode ser instruída a "ajustar a palavra-chave para que a cor do céu fique mais clara e mais próxima da sensação da imagem de referência" (se uma imagem de referência tiver sido fornecida anteriormente). Essa abordagem deixa o ajuste a cargo da IA responsável pela expansão da palavra-chave e geralmente resulta em uma palavra-chave modificada mais estruturada e consistente.
Por exemplo, para necessidades de ajuste da cor do céu:

A IA gerará rapidamente uma versão revisada da palavra-chave, o que é muito mais rápido do que um criador humano pode alterá-la manualmente:
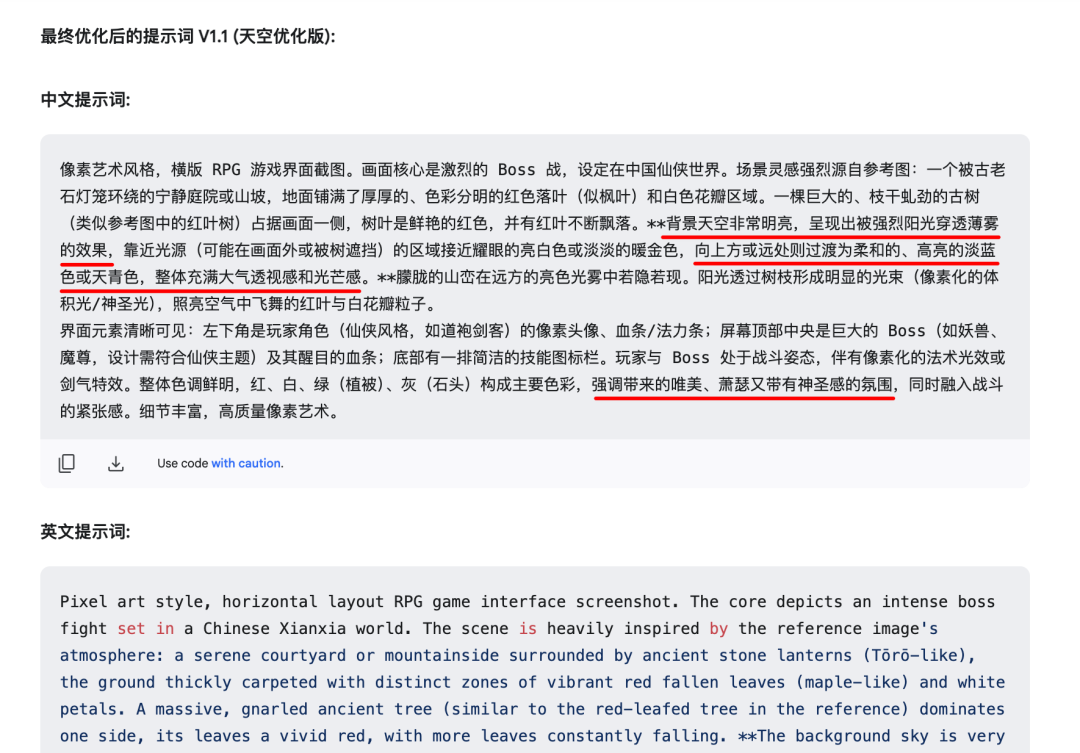
Gerar a imagem novamente usando a palavra-chave atualizada geralmente faz com que os ajustes tenham efeito e proporciona resultados relativamente estáveis e aprimorados.
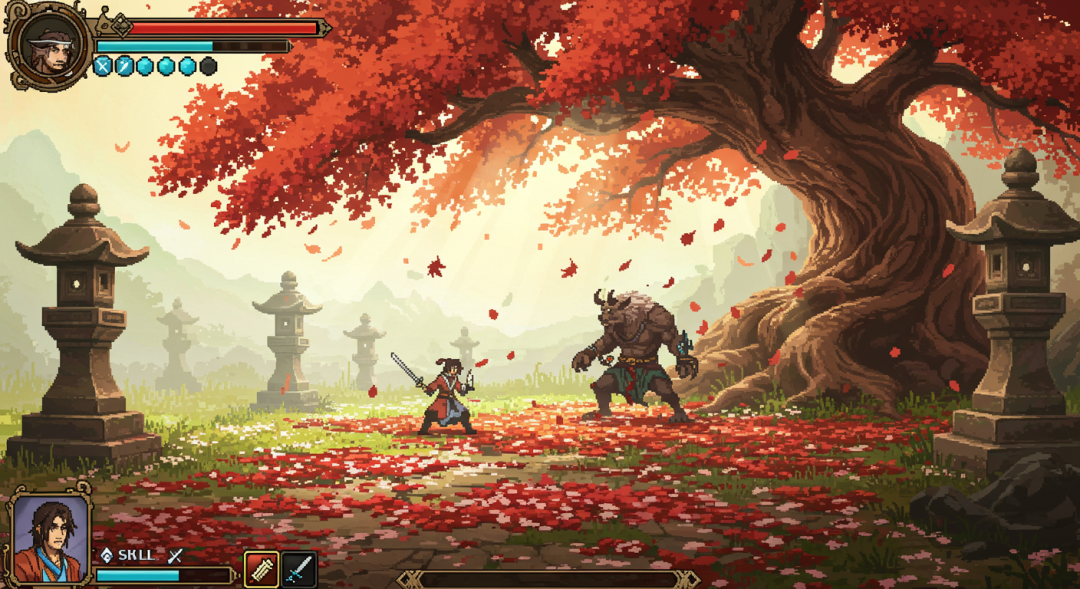
Além disso, a estrutura poderia, teoricamente, ser usada para engenharia reversa, ou seja, tentar começar com uma imagem existente e fazer com que a IA inferisse as palavras-chave que poderiam ter gerado essa imagem.
Exemplo de efeito de geração para cada cena
A seguir, demonstramos o uso dessa estrutura genérica de palavras-chave em conjunto com diferentes modelos gráficos vicentinos (por exemplo Imagefx responder cantando Midjourney V7) efeitos de imagem gerados em vários domínios de design. Esses exemplos foram fornecidos pelos primeiros usuários de teste e têm o objetivo de demonstrar a ampla aplicabilidade e o potencial de efeitos da estrutura.
Design de casa (usando Imagefx)

## 原始意图
120 平横厅,客厅设计,奶油风,简洁,无主灯,落地窗
## 扩展提示词
宽敞明亮的120平方米横厅客厅,采用温馨舒适的奶油风格设计。整体空间简洁、开放,以柔和的米白、奶油、燕麦色和浅木色为主色调。一面巨大的落地窗占据了主要墙面,引入充足的自然光线,窗边垂挂着轻盈的白色纱帘。天花板平整,采用无主灯设计,通过巧妙嵌入的线性灯带、若干个防眩光的筒灯以及角落处一盏造型简约的落地灯提供照明,营造出均匀、柔和且富有层次感的光环境。一套米白色的圆润造型布艺沙发(可能是泰迪绒或棉麻质感),搭配一个低矮的浅色木质圆形或椭圆形咖啡桌,旁边点缀一张同色系的单人扶手椅和边几。地面铺设浅色木地板或大地色系的短绒地毯。墙面保持简洁的奶油色乳胶漆,可能有一面墙做了微妙的肌理感艺术漆处理。点缀少量绿植和极简风格的装饰画。宁静、放松、温暖、通透。视觉焦点集中在落地窗外的景色以及室内柔和的光线和舒适的材质上。
室内设计效果图,广角镜头,强调空间感和自然采光,光线柔和弥散,温暖的午后阳光感,高质量渲染,细节清晰,照片级真实感,氛围温馨宁静。
Design de joias (usando Imagefx)

## 原始意图
珠宝设计,项链,钻石与银,极具美感,轻盈
## 扩展提示词
一条充满自然灵动美感的项链设计。采用柔和扭转、仿佛清晨藤蔓般的拉丝纹理925银作为主体结构,形成一个开放式的、不对称的环绕形态。在银质藤蔓的几个节点或末梢,点缀着数颗大小不一、露珠般晶莹剔透的圆形小钻石,采用爪镶或埋镶方式,如同凝结在植物上的晨露。链条为极细的银色绞丝链,与主体有机连接。整体造型追求流畅的曲线和不对称的平衡,体现自然造物的精巧与生命的活力。银材质部分拉丝部分抛光,形成丰富的光影层次。
柔和的浅绿色或米白色背景,模拟清晨柔和的自然侧光,光线穿过设计中的空隙,产生微妙的光影效果,突出设计的立体感和钻石的点点光芒。高分辨率,超现实珠宝摄影,细节丰富,质感逼真,整体氛围清新、脱俗、充满生机与轻盈感。
Design de jogos (usando Imagefx)

## 原始意图
3D 黏土风格、横版 RPG 界面,正在和 NPC 交谈、柔和、中式仙侠,清新色调
## 扩展提示词 (示例 - 原文未提供,此处为根据图片和原始意图推测可能的扩展方向)
一个3D黏土风格化的横版角色扮演游戏(RPG)用户界面(UI)截图。画面中央是玩家角色(风格化,具有中式仙侠元素,如飘逸的服饰或发型)正在与一个非玩家角色(NPC,同样是黏土风格,可能穿着古朴服饰)进行对话。对话框采用柔和的圆角设计,背景半透明,字体清晰易读,带有淡淡的清新色调(如浅蓝、米白或淡绿)。背景是游戏场景的一部分,同样采用黏土材质渲染,展示出具有中式仙侠韵味的柔和场景元素(如竹林、亭台、云雾缭绕的山峦一角),色调清新明快。整体光照柔和,无明显阴影,强调黏土材质的温润质感。UI元素(如血条、技能图标)设计简洁,与整体风格统一。
3D渲染,黏土风格,中式仙侠主题,游戏UI设计,对话场景,清新色调,柔和光照,高分辨率。
Renderização de produtos (usando Imagefx)

## 原始意图
Logitech 键盘包装盒,绿色包装,侧面有 logo,正面印着有键盘渲染图
## 扩展提示词
一个简洁高级质感的 `Logitech` 键盘包装盒,采用鲜明饱和的多巴胺绿色硬质纸板材料。盒子形状呈现为极其细长且非常扁平的长方体,具有显著的纤薄外形,视觉上远长于宽,远宽于高,暗示其为键盘包装。盒子表面光滑,质感良好,边缘线条挺括、干净利落。包装盒主体(最宽的面)上印刷有一个简约风格的黑色键盘图形轮廓或线条画。 `Logitech` 的 Logo 以简洁的方式印刷在其中一个狭长的侧面上。整个包装盒处于未拆封的闭合状态,水平放置在一个桌面上。设计风格现代、极简、高端。
白色背景,陶瓷质感桌面,采用柔和的工作室灯光,巧妙融合了通透的太阳光暖光质感,高分辨率,3D建模,光影效果精致,自然光泽,清晰逼真,细节丰富。中性背景下的清晰产品摄影风格,凸显产品的现代美感和高级感。
Tela de cinema (usando o Midjourney V7)

## 原始意图
我看见敌人的冲向我,我无能为力的延时摄影 多重曝光
## 扩展提示词
第一人称视角 (POV)。黑白画面,效果类似于延时摄影与多重曝光的结合。
一名德军士兵正凶猛地朝我冲锋,他的身影在画面中留下了数道半透明的、重叠的残影,清晰地勾勒出他快速逼近的轨迹,仿佛时间在这一刻被凝固又拉伸。最近处的那个残影最为清晰,面目狰狞,刺刀闪着寒光。周围的战场背景(烟雾、障碍物、倒下的战友的模糊轮廓)也因多重曝光效果而显得混乱、破碎且相互渗透。我的视角固定,带着强烈的眩晕感,能看到自己无力垂下的步枪枪口和因恐惧而微微颤抖的手指边缘。整个画面充满了超现实的噩梦感,捕捉了面对死亡威胁时,那种大脑空白、身体僵直、彻底无能为力的瞬间。高对比度,颗粒感强,光影破碎。
Fotografia de pessoas (com Midjourney V7)

## 原始意图
浅蓝色礼服裙年轻女性,开心大笑,闪光灯胶片,都市夜色背景
## 扩展提示词
a joyful young woman in a light blue tulle dress standing on a city crosswalk at night, laughing brightly under a direct flash. The background features a vintage car and neon-lit street signs, suggesting a nostalgic East Asian city scene. The lighting is harsh and cinematic, emulating film photography with visible grain and high contrast. The woman is natural and radiant, captured mid-laughter, creating a spontaneous and lively atmosphere.
Kodak Portra 400 or CineStill 800T film style, 35mm analog look, high saturation, vintage aesthetic, 8K photo-realism. --p o328hsl --ar 16:9 --c 10 --v 6.1
Criação de arte conceitual (usando o Midjourney V7)

## 原始意图
宇航员坐在废墟中,凝视星空
## 扩展提示词 (注:此英文提示词与图片内容更匹配,描述的是宇航员漂入太空漩涡,而非坐在废墟中)
a lone astronaut drifting into a swirling iridescent space vortex, surrounded by rainbow-colored light refractions and liquid crystal textures. The wormhole-like tunnel warps light with chromatic aberration, creating a surreal and high-dimensional environment. Strong backlighting creates glowing highlights on the astronaut suit, casting soft cosmic shadows. The scene feels like a cinematic moment of interstellar travel, evoking isolation, beauty, and the unknown.
Ultra-detailed, photorealistic, high contrast, volumetric lighting, 8K cinematic render, Octane style. --chaos 10 --ar 16:9
Cuidados e limitações
Embora essa estrutura generalizada de palavras-chave ofereça uma maneira eficiente de simplificar e aprimorar o processo de mapeamento alfabetizado, alguns pontos precisam ser observados:
- depende dos recursos da IA intermediária: A qualidade das palavras-chave geradas no final depende muito do modelo de IA usado para ampliar a ideia inicial (por exemplo
Gemini 2.5 Pro) compreensão, raciocínio e criatividade. Os modelos que usam habilidades mais fracas podem resultar em palavras-chave menos precisas ou menos criativas. - A iteração ainda é necessária: Mesmo com dicas estendidas de alta qualidade, a imagem resultante pode exigir mais ajustes. Os usuários talvez ainda precisem passar por várias iterações, modificando as palavras-chave ou usando os recursos de edição da ferramenta de diagrama de Venn para obter um resultado final satisfatório.
- Não é possível eliminar completamente o preconceito: Os modelos de IA podem ter vieses presentes em seus dados de treinamento. As palavras-chave e as imagens subsequentes geradas pela estrutura podem refletir inadvertidamente essas tendências. Os usuários precisam estar atentos a isso.
- Não é o ponto principal e definitivo: Para tarefas de design extremamente complexas que exigem um alto grau de controle de precisão ou envolvem conhecimento proprietário, a estrutura pode não ser um substituto completo para o conhecimento aprofundado e o ajuste fino manual por profissionais.
Em suma, essa estrutura universal de palavras-chave pode ser vista como um mecanismo para promover a colaboração eficiente entre humanos e IA no campo criativo. Ela reduz efetivamente o limiar da conversão de texto em gráficos de alta qualidade e melhora a eficiência criativa, estruturando as intenções ambíguas do usuário em instruções que são mais fáceis de serem compreendidas e executadas pela IA. Espera-se que a integração dessa estrutura em uma ferramenta ou fluxo de trabalho de texto para gráficos melhore a experiência do usuário e a qualidade do resultado final. Ela revela o potencial da IA como um amplificador criativo, permitindo que a tecnologia atenda melhor aos impulsos criativos primordiais dos seres humanos e que mais pessoas transformem sua imaginação em realidade visual.
© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Artigos relacionados




Nenhum comentário...