Documento da Microsoft que vazou: apenas 8 bilhões para o GPT-4o-mini e 100 bilhões para o o1-mini?
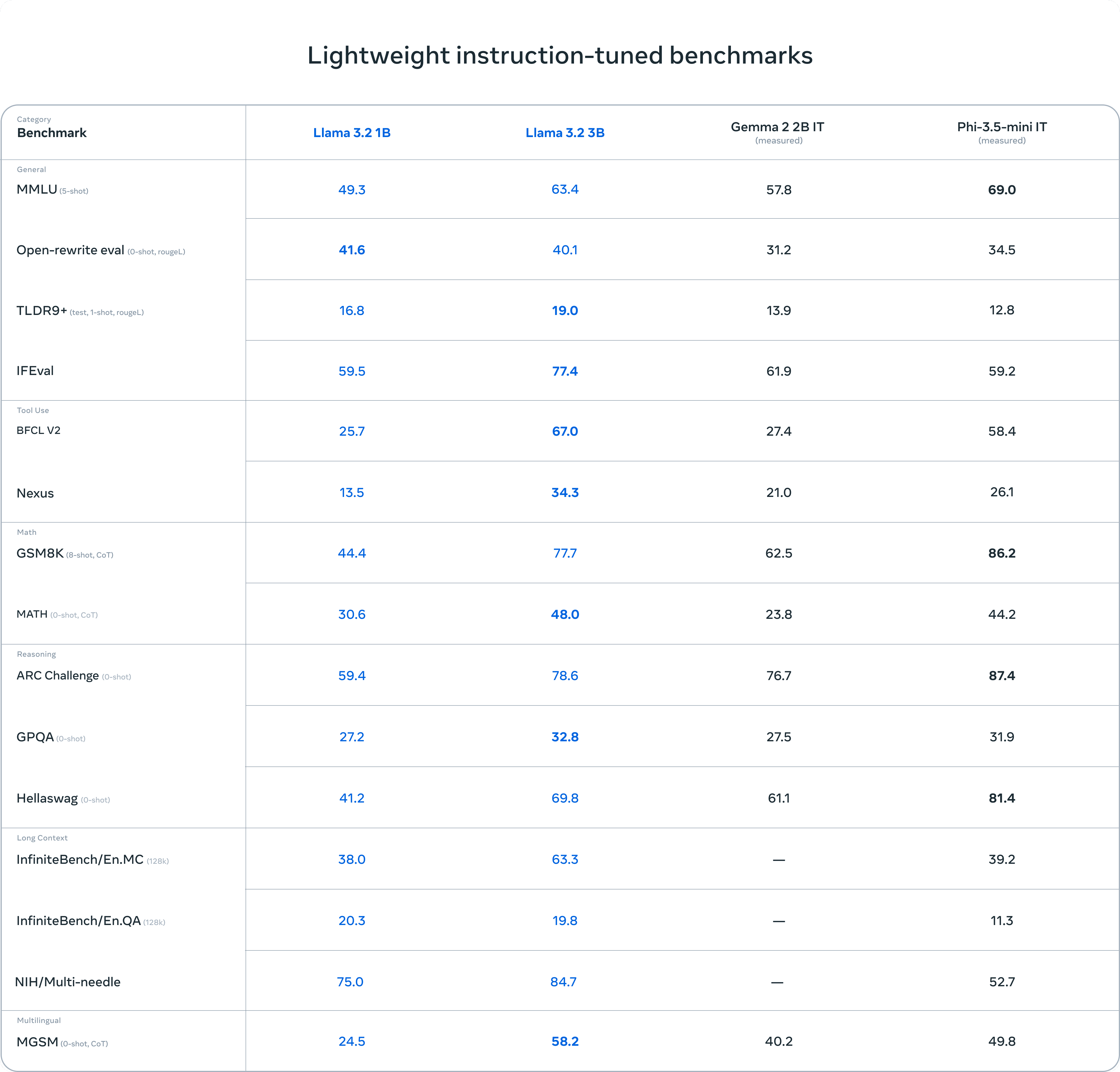
Tem havido uma discussão contínua sobre os tamanhos dos parâmetros dos principais LLMs de código fechado e, nos últimos dois dias de 2024, um artigo da Microsoft sobre oDetecção e correção de erros médicos em anotações clínicasconjecturaexperimentopadrão de referênciaO estudo MEDEC ignorou acidentalmente e diretamente a escala de seus parâmetros:o1-preview, GPT-4.GPT-4o eClaude 3.5 Soneto.
Endereço para correspondência: https://arxiv.org/pdf/2412.19260v1

A parte experimental do experimento também divide as grandes escalas de parâmetros do modelo em três blocos:7-8B, ~100-300B, ~1,7Tmas (não)GPT-4o-miniSer colocado na primeira posição com apenas 8B é um pouco inacreditável.
resumos

- Claude 3,5 Soneto (2024-10-22), ~175B
- ChatGPT, ~175B
- GPT-4, aproximadamente 1,76T
- GPT-4o, ~200B
- GPT-4o-mini (gpt-4o-2024-05-13) somente 8B
- Último o1-mini (o1-mini-2024-09-12) apenas 100B
- o1-preview (o1-preview-2024-09-12) ~ 300B
© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Artigos relacionados


Nenhum comentário...