
Um artigo de 10.000 palavras para organizar o processo de desenvolvimento do Text-to-SQL baseado em LLM
OlaChat AI Digital Intelligence Assistant Análise aprofundada de 10.000 palavras, que leva você a entender o passado e o presente da tecnologia Text-to-SQL.
Tese: Interfaces de banco de dados de última geração: uma pesquisa de texto para SQL baseada em LLM
A geração de SQL preciso a partir de problemas de linguagem natural (texto para SQL) é um desafio de longa data devido à complexidade da compreensão do problema do usuário, da compreensão do esquema do banco de dados e da geração de SQL. Os sistemas tradicionais de texto para SQL, incluindoEngenharia Artificial e Redes Neurais ProfundasEm um ano, houve um progresso substancial. Posteriormente.Modelos de linguagem pré-treinados (PLMs) foram desenvolvidos e usados para tarefas de conversão de texto em SQL, obtendo um desempenho promissor. À medida que os bancos de dados modernos se tornam mais complexos, os problemas correspondentes do usuário se tornam mais desafiadores, resultando em PLMs com restrições de parâmetros (modelos pré-treinados) que geram SQL incorreto, o que exige métodos de otimização personalizados mais sofisticados, o que, por sua vez, limita a aplicação de sistemas baseados em PLM.
Recentemente, os modelos de linguagem grande (LLMs) demonstraram recursos significativos na compreensão de linguagem natural devido ao crescimento do tamanho do modelo. Portanto, a integração de implementações baseadas em LLMpode trazer oportunidades, melhorias e soluções exclusivas para a pesquisa de texto para SQL. Especificamente, os autores apresentam uma breve visão geral dos desafios técnicos e do processo evolutivo da conversão de texto em SQL. Em seguida, os autores fornecem uma descrição detalhada dos conjuntos de dados e das métricas de avaliação criadas para avaliar os sistemas de texto para SQL. Em seguida, o artigo analisa sistematicamente os avanços recentes em texto para SQL baseado em LLM. Por fim, são discutidos os desafios remanescentes no campo e são apresentadas as expectativas para futuras direções de pesquisa.
Os artigos especificamente mencionados por "[xx]" no texto podem ser consultados na seção de referências do artigo original.
introdutório
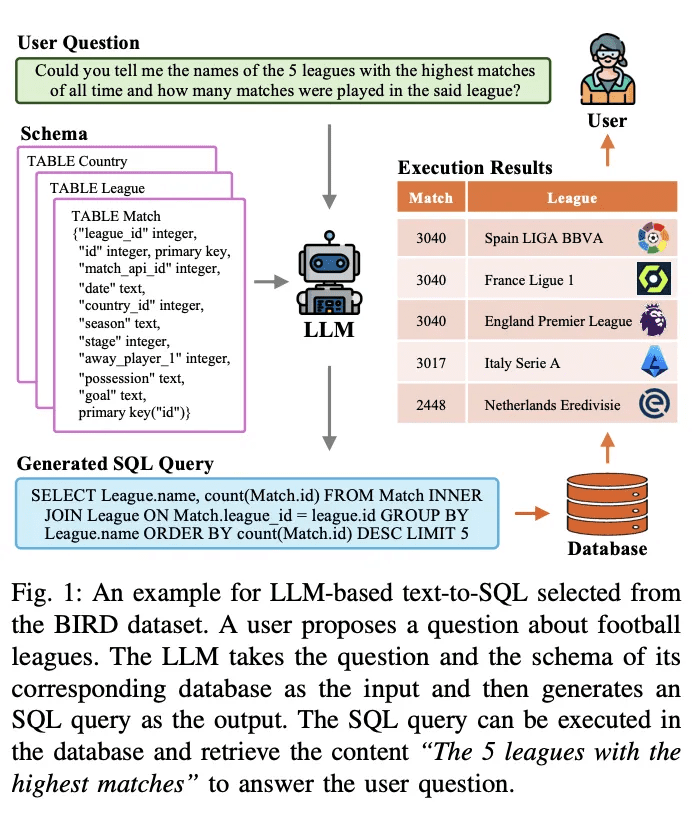
Text-To-SQL é uma tarefa de longa data na pesquisa de processamento de linguagem natural. Seu objetivo é converter (traduzir) problemas de linguagem natural em consultas SQL executáveis em banco de dados. A Figura 1 apresenta um exemplo de um sistema de texto para SQL baseado em um modelo de linguagem de grande escala (baseado em LLM). Dada uma pergunta do usuário, por exemplo, "Você pode me dizer os nomes das 5 ligas mais disputadas da história e quantos jogos foram disputados nessa liga?", o LLM traduz a pergunta e sua consulta correspondente em uma consulta SQL executável. O LLM recebe a pergunta e seu esquema de banco de dados correspondente como entrada e os analisa. Em seguida, ele gera uma consulta SQL como saída. Essa consulta SQL pode ser executada no banco de dados para recuperar o conteúdo relevante para responder à pergunta do usuário. O sistema acima usa o LLM para criar uma interface de linguagem natural para o banco de dados (NLIDB).
Como o SQL ainda é uma das linguagens de programação mais usadas, com metade (51.52%) dos desenvolvedores profissionais usando SQL em seu trabalho e, notavelmente, apenas cerca de um terço (35.29%) dos desenvolvedores são treinados no sistema, o NLIDB permite que usuários não qualificados acessem bancos de dados estruturados como engenheiros de banco de dados profissionais [1, 2] e também acelera a interação humano-computador [3]. Além disso, entre os pontos críticos de pesquisa em LLM, a conversão de texto em SQL pode preencher a lacuna de conhecimento em LLM incorporando conteúdo real de bancos de dados, fornecendo possíveis soluções para o problema generalizado de ilusões [4, 5] [6]. O grande valor e o potencial do texto para SQL desencadearam uma série de estudos sobre sua integração e otimização com LLMs [7-10]; assim, o texto para SQL baseado em LLM continua sendo uma área de pesquisa muito discutida nas comunidades de NLP e de banco de dados.
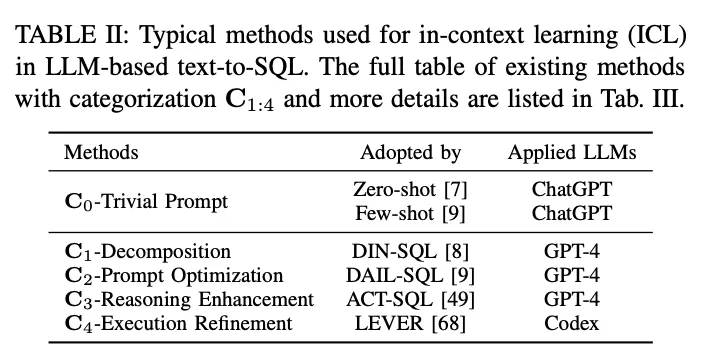
Pesquisas anteriores fizeram um progresso significativo na implementação de texto para SQL e passaram por um longo processo de evolução. A maioria das primeiras pesquisas baseava-se em regras e modelos bem projetados [11], que eram particularmente adequados para cenários simples de bancos de dados. Nos últimos anos, a criação de regras ou modelos para cada cenário tornou-se cada vez mais difícil e impraticável, devido aos altos custos de mão de obra associados às abordagens baseadas em regras [12] e à crescente complexidade dos ambientes de banco de dados [13 - 15]. Os avanços na conversão de texto em SQL foram impulsionados pelo desenvolvimento de redes neurais profundas [16, 17], que aprendem automaticamente os mapeamentos das perguntas dos usuários para o SQL correspondente [18, 19]. Posteriormente, os modelos de linguagem (PLMs) pré-treinados com recursos avançados de análise semântica tornaram-se o novo paradigma dos sistemas de texto para SQL [20], elevando seu desempenho a um novo patamar [21 - 23]. A pesquisa progressiva sobre otimizações baseadas em PLM (por exemplo, codificação de conteúdo de tabela [19, 24, 25] e pré-treinamento [20, 26]) fez o campo avançar ainda mais. Recentemente.A abordagem baseada em LLM implementa a transformação de texto para SQL por meio dos paradigmas de aprendizado de contexto (ICL) [8] e ajuste fino (FT) [10]A empresa obtém precisão de última geração com uma estrutura bem projetada e maior compreensão do que o PLM.
Os detalhes gerais de implementação do texto para SQL baseado em LLM podem ser divididos em três áreas:
1) Compreensão do problemaPerguntas NL: as perguntas NL são representações semânticas da intenção do usuário, e as consultas SQL geradas correspondentes devem ser consistentes com elas;
2) Compreensão de padrõesO esquema fornece a estrutura de tabelas e colunas do banco de dados, e o sistema de texto para SQL precisa identificar o componente de destino que corresponde ao problema do usuário;
3) Geração de SQLO objetivo da análise de texto para SQL é a análise de texto para SQL: isso envolve a combinação da análise acima e, em seguida, a previsão da sintaxe correta para gerar uma consulta SQL executável para recuperar a resposta desejada. Foi demonstrado que os LLMs podem implementar bem a funcionalidade texto-para-SQL [7, 27], graças a recursos de análise semântica mais poderosos possibilitados por corpora de treinamento mais ricos [28, 29]. Estão crescendo as pesquisas sobre o aprimoramento dos LLMs para compreensão de problemas [8, 9], compreensão de padrões [30, 31] e geração de SQL [32].
Apesar do progresso significativo na pesquisa de texto para SQL, ainda há desafios que impedem o desenvolvimento de sistemas de texto para SQL robustos e de uso geral [ 73 ]. Pesquisas relevantes nos últimos anos pesquisaram sistemas de texto para SQL em abordagens de aprendizagem profunda e forneceram insights sobre abordagens anteriores de aprendizagem profunda e pesquisas baseadas em PLM. O objetivo desta pesquisa é acompanhar os últimos avanços e fornecer uma análise abrangente dos modelos e abordagens atuais de última geração para conversão de texto em SQL com base em LLM. Em primeiro lugar, são apresentados os conceitos básicos e os desafios associados à conversão de texto em SQL, destacando a importância dessa tarefa em vários domínios. Em seguida, é apresentada uma análise aprofundada da evolução dos paradigmas de implementação dos sistemas de conversão de texto em SQL, discutindo os principais avanços e descobertas nesse campo. A visão geral é seguida por uma descrição e análise detalhadas dos avanços recentes em texto para SQL com integração LLM. Especificamente, este artigo de pesquisa aborda uma série de tópicos relacionados ao texto para SQL baseado em LLM, incluindo:
● Conjuntos de dados e benchmarksDescrição detalhada de conjuntos de dados e benchmarks comumente usados para avaliar sistemas de texto para SQL baseados em LLM. São discutidas suas características, complexidade e os desafios que representam para o desenvolvimento e a avaliação de texto para SQL.
● Avaliação de indicadoresDescrição: Serão apresentadas as métricas de avaliação usadas para avaliar o desempenho dos sistemas de texto para SQL baseados em LLM, incluindo exemplos baseados em correspondência de conteúdo e em execução. Em seguida, as características de cada métrica serão descritas resumidamente.
● Métodos e modelosEste artigo apresenta uma análise sistemática de diferentes abordagens e modelos usados para conversão de texto em SQL com base em LLM, incluindo exemplos baseados em aprendizado contextual e ajuste fino. Seus detalhes de implementação, vantagens e adaptações para tarefas de texto para SQL são discutidos a partir de diferentes perspectivas de implementação.
● Expectativas e direções futurasEste artigo discute os desafios e as limitações restantes do texto para SQL baseado em LLM, como robustez no mundo real, eficiência computacional, privacidade de dados e dimensionamento. Também são descritas as possíveis direções de pesquisas futuras e as oportunidades de aprimoramento e otimização.
delineado
Text-to-SQL é uma tarefa que visa transformar perguntas de linguagem natural em consultas SQL correspondentes que podem ser executadas em um banco de dados relacional. Formalmente, dada uma pergunta do usuário Q (também conhecida como consulta do usuário, pergunta em linguagem natural etc.) e um esquema de banco de dados S, o objetivo da tarefa é gerar uma consulta SQL Y que recupere o conteúdo necessário do banco de dados para responder à pergunta do usuário. O Text-to-SQL tem o potencial de democratizar o acesso aos dados, permitindo que os usuários interajam com o banco de dados usando linguagem natural sem a necessidade de conhecimento especializado em programação SQL [75]. Ao permitir que usuários não qualificados recuperem facilmente conteúdo direcionado de bancos de dados e facilitem uma análise de dados mais eficaz, isso pode beneficiar áreas tão diversas quanto inteligência de negócios, suporte ao cliente e pesquisa científica.
A. Desafios na conversão de texto em SQL
Os desafios técnicos da implementação de texto para SQL podem ser resumidos da seguinte forma:
1)Complexidade e ambiguidade linguísticaProblemas de linguagem natural geralmente contêm representações linguísticas complexas, como cláusulas aninhadas, co-referências e elipses, o que torna difícil mapeá-las com precisão para as partes correspondentes de uma consulta SQL [41]. Além disso, a linguagem natural é inerentemente ambígua, com várias representações possíveis para um determinado problema do usuário [76, 77]. A resolução dessas ambiguidades e a compreensão da intenção por trás do problema do usuário exigem uma compreensão profunda da linguagem natural e a capacidade de integrar o conhecimento contextual e de domínio [33].
2)Compreensão e representação de padrõesPara gerar consultas SQL precisas, os sistemas de texto para SQL exigem uma compreensão completa do esquema do banco de dados, incluindo nomes de tabelas, nomes de colunas e relacionamentos entre tabelas individuais. Entretanto, os esquemas de banco de dados podem ser complexos e variar muito entre os domínios [13]. Representar e codificar as informações do esquema de uma forma que possa ser efetivamente utilizada pelos modelos de texto para SQL é uma tarefa desafiadora.
3)Operações raras e complexas de SQLAlgumas consultas SQL envolvem operações e sintaxe raras ou complexas em cenários desafiadores, como subconsultas aninhadas, junções externas e funções de janela. Essas operações são menos comuns nos dados de treinamento e representam um desafio para a geração precisa de sistemas de texto para SQL. A criação de modelos que generalizem para uma variedade de operações SQL, incluindo cenários raros e complexos, é uma consideração importante.
4)generalização entre domíniosOs sistemas de texto para SQL geralmente são difíceis de generalizar em vários cenários e domínios de bancos de dados. Devido à diversidade de vocabulários, estruturas de esquema de banco de dados e padrões de problemas, os modelos treinados em um domínio específico podem não lidar bem com problemas apresentados em outros domínios. O desenvolvimento de sistemas que possam ser generalizados de forma eficaz para novos domínios usando o mínimo de dados de treinamento específicos do domínio ou adaptações ajustadas é um grande desafio [78].
B. Processos evolutivos
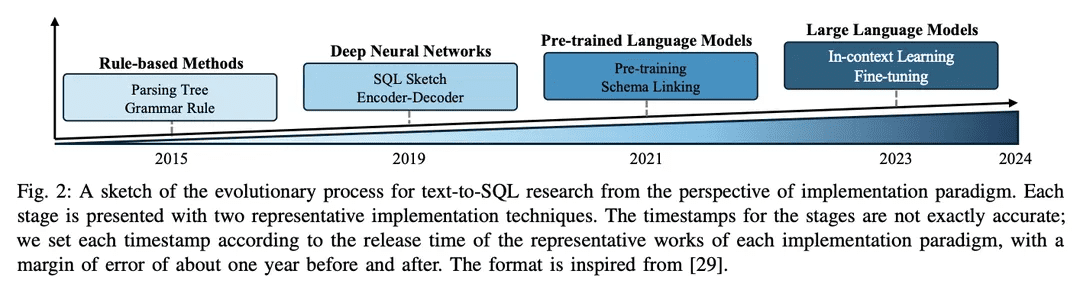
O campo de pesquisa de texto para SQL fez grandes avanços na comunidade de PLN ao longo dos anos, evoluindo de abordagens baseadas em regras para abordagens baseadas em aprendizagem profunda e, mais recentemente, para a integração de modelos de linguagem pré-treinados (PLMs) e modelos de linguagem em grande escala (LLMs), com um esboço do processo evolutivo mostrado na Figura 2.
1) Abordagem baseada em regrasOs primeiros sistemas de texto para SQL dependiam muito de abordagens baseadas em regras [11, 12, 26], ou seja, o uso de regras e heurísticas formuladas manualmente para mapear problemas de linguagem natural para consultas SQL. Em geral, essas abordagens envolvem engenharia de recursos significativa e conhecimento específico do domínio. Embora as abordagens baseadas em regras tenham sido bem-sucedidas em domínios simples específicos, elas não têm a flexibilidade e a generalização necessárias para lidar com uma grande variedade de problemas complexos.
2)Abordagem baseada em aprendizagem profundaCom o surgimento das redes neurais profundasModelagem de sequência a sequência e arquitetura de codificador-decodificador(por exemplo, LSTM [79] e conversores [17]) são usados para gerar consultas SQL a partir da entrada de linguagem natural [19 , 80]. Normalmente, o RYANSQL [19] introduz técnicas como representações intermediárias e preenchimento de espaços com base em esboços para lidar com problemas complexos e melhorar a generalidade entre domínios. Recentemente, os pesquisadores utilizaram técnicas dependentes de esquemaOs gráficos capturam as relações entre os elementos do banco de dadosA primeira etapa foi introduzir uma nova tarefa de texto para SQL, aRedes neurais de grafos (GNN)[18,81].
3) Implementação baseada em PLMOs primeiros aplicativos de PLMs em texto para SQL se concentraram no ajuste fino de PLMs prontos para uso em conjuntos de dados padrão de texto para SQL, como BERT [24] e RoBERTa [82] [13, 14]. Esses PLMs são pré-treinados em um grande corpus de treinamento, capturando representações semânticas ricas e recursos de compreensão de linguagem. Ao fazer o ajuste fino em tarefas de texto para SQL, os pesquisadores pretendem aproveitar os recursos de compreensão semântica e linguística dos PLMs para gerar consultas SQL precisas [ 20, 80, 83]. Outra direção de pesquisa é incorporar informações de esquema aos PLMs para melhorar a maneira como esses sistemas podem ajudar os usuários a entender as estruturas do banco de dados e gerar consultas SQL mais executáveis. Os PLMs com reconhecimento de esquema são projetados para capturar as relações e restrições presentes na estrutura do banco de dados [21].
4) Implementação baseada em LLMModelos de linguagem grandes (LLMs), como a família GPT [ 84 -86 ], receberam muita atenção nos últimos anos por sua capacidade de gerar textos coerentes e fluentes. Os pesquisadores começaram a explorar o potencial do texto para SQL explorando a ampla base de conhecimento e os recursos geradores superiores dos LLMs [7, 9]. Essas abordagens geralmente envolvem o direcionamento da engenharia de dicas de LLMs proprietários durante a geração de SQL [47] ou o ajuste fino de LLMs de código aberto em conjuntos de dados de texto para SQL [9].
A integração do LLM em texto para SQL ainda é uma área de pesquisa emergente com grande potencial para exploração e aprimoramento. Os pesquisadores estão investigando como utilizar melhor os recursos de conhecimento e raciocínio do LLM, incorporar conhecimento específico do domínio [31, 33] e desenvolver estratégias de ajuste fino mais eficientes [10]. À medida que o campo continua a evoluir, espera-se que sejam desenvolvidas implementações mais avançadas e superiores baseadas em LLM que levarão o desempenho e a generalização de texto para SQL a novos patamares.
Padrões de referência e avaliações
Nesta seção, o documento apresenta benchmarks de texto para SQL, incluindo conjuntos de dados conhecidos e métricas de avaliação.
A. Conjuntos de dados
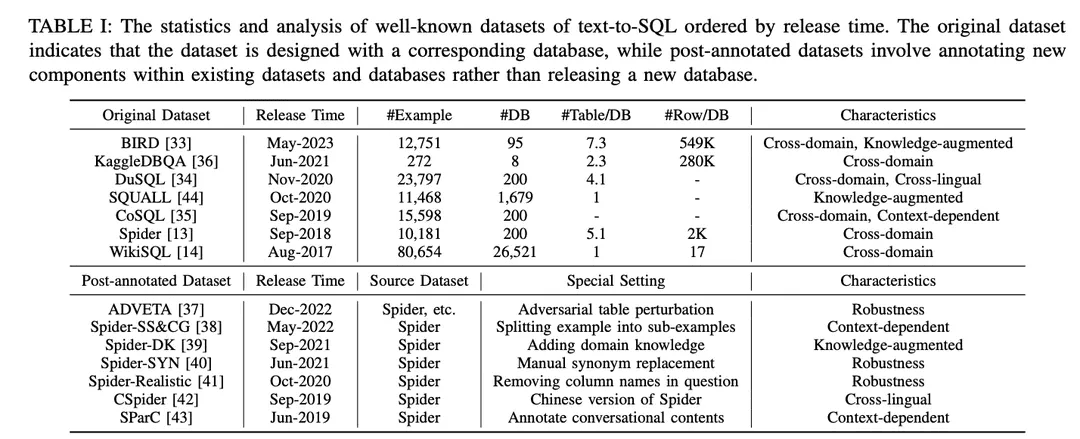
Conforme mostrado na Tabela I, os conjuntos de dados são categorizados em "conjuntos de dados originais" e "conjuntos de dados pós-anotação". Os conjuntos de dados são classificados em "Conjuntos de dados originais" e "Conjuntos de dados pós-anotação", de acordo com o fato de os conjuntos de dados serem publicados com os conjuntos de dados e bancos de dados originais ou criados por meio de configurações especiais nos conjuntos de dados e bancos de dados existentes. Para o conjunto de dados original, é fornecida uma análise detalhada, incluindo o número de exemplos, o número de bancos de dados, o número de tabelas por banco de dados e o número de linhas por banco de dados. Para os conjuntos de dados anotados, seus conjuntos de dados de origem são identificados e as configurações específicas aplicadas a eles são descritas. Para ilustrar as oportunidades potenciais de cada conjunto de dados, ele foi anotado de acordo com suas características. As anotações estão listadas no lado direito da Tabela I. Elas são discutidas em mais detalhes a seguir.
1) Conjuntos de dados entre domíniosO termo "banco de dados" refere-se a conjuntos de dados em que as informações de fundo para diferentes bancos de dados vêm de diferentes domínios. Como os aplicativos de texto para SQL do mundo real geralmente envolvem bancos de dados de vários domínios, a maioria dos conjuntos de dados originais de texto para SQL [13,14,33 - 36] e os conjuntos de dados pós-anotação [37 -43] estão em uma configuração entre domínios, o que é uma boa opção para aplicativos entre domínios.
2) Conjuntos de dados aprimorados pelo conhecimentoBIRD [ 33 ] utiliza especialistas em bancos de dados humanos para anotar cada amostra de texto para SQL com conhecimento externo categorizado como conhecimento de raciocínio numérico, conhecimento de domínio, conhecimento de sinônimos e declarações de valor. Da mesma forma, o Spider-DK [ 39] editou manualmente uma versão do conjunto de dados Spider [13] para editores humanos: a coluna SELECT foi omitida, foi exigido raciocínio simples, substituições de sinônimos em palavras com valor de célula, uma palavra sem valor de célula gera uma condição e é propensa a conflitos com outros domínios. Ambos os estudos constataram que o conhecimento anotado manualmente melhorou significativamente o desempenho da geração de SQL para amostras que exigiam conhecimento de domínio externo. Além disso, o SQUALL [44] anota manualmente o alinhamento entre palavras em problemas de NL e entidades em SQL, fornecendo uma supervisão mais refinada do que em outros conjuntos de dados.
3) Conjuntos de dados contextualmente relevantesSParC [43] e CoSQL [35] exploram a geração de SQL sensível ao contexto criando um sistema de consulta para bancos de dados de sessão. Diferentemente dos conjuntos de dados tradicionais de texto para SQL que têm um único par de perguntas SQL com apenas um exemplo, o SParC decompõe os exemplos de perguntas SQL no conjunto de dados Spider em vários pares de subperguntas SQL para criar interações simuladas e significativas, incluindo subperguntas inter-relacionadas que contribuem para a geração de SQL e subperguntas não relacionadas que aumentam a diversidade de dados. Em contrapartida, o CoSQL envolve interações de diálogo em linguagem natural que simulam cenários do mundo real para aumentar a complexidade e a variedade. Além disso, o Spider-SS&CG [38] divide o problema de NL no conjunto de dados Spider [13] em vários subproblemas e sub-SQLs, demonstrando que o treinamento nesses subexemplos melhora a distribuição de amostras dos recursos de generalização do sistema de texto para SQL.
4) Conjuntos de dados de robustezSpider-Realistic [ 41] remove termos explicitamente relacionados a esquemas das perguntas NL, enquanto Spider-SYN [ 40] os substitui por sinônimos selecionados manualmente.ADVETA [ 37] introduziu a perturbação adversária da tabela (ATP), que perturba a tabela substituindo os nomes originais das colunas por substituições enganosas e inserindo novas colunas com alta relevância semântica, mas baixa equivalência semântica. Essas perturbações podem levar a uma queda significativa na precisão, pois os sistemas de texto para SQL menos robustos podem ser enganados por correspondências errôneas entre tokens e entidades de banco de dados em problemas de NL.
5) Conjuntos de dados entre idiomasCSpider [42] traduz o conjunto de dados Spider para o chinês e descobre novos desafios na segmentação de palavras e na correspondência entre idiomas entre perguntas chinesas e conteúdo de banco de dados em inglês. perguntas em chinês e conteúdo de banco de dados em inglês e chinês.
B. Indicadores de avaliação
As quatro métricas de avaliação amplamente usadas a seguir são apresentadas para tarefas de texto para SQL: "Correspondência de componentes" e "Correspondência exata" com base na correspondência de conteúdo SQL e "Precisão de execução" com base nos resultados da execução "e "Pontuação de eficiência efetiva".
1) Métricas baseadas na correspondência de conteúdoA métrica de correspondência de conteúdo SQL baseia-se principalmente na similaridade estrutural e sintática da consulta SQL prevista com a consulta SQL real subjacente.
Correspondência de componentes (CM)[13] O desempenho de um sistema de conversão de texto em SQL é avaliado medindo-se as correspondências exatas entre os componentes SQL previstos (SELECT, WHERE, GROUP BY, ORDER BY e KEYWORDS) e os componentes SQL reais (GROUP BY, ORDER BY e KEYWORDS) usando as pontuações F1. Cada componente é decomposto em conjuntos de subcomponentes e comparado para correspondências exatas, levando em conta os componentes SQL sem restrições de ordem.
Correspondência exata (EM))[ 13] mede a porcentagem de exemplos em que a consulta SQL prevista é exatamente igual à consulta SQL verdadeira. Uma consulta SQL prevista é considerada correta somente se todos os seus componentes (conforme descrito em CM) corresponderem exatamente aos componentes da consulta de verdade terrestre.
2) Indicadores baseados em implementaçãoResultados da execução: A métrica Resultados da execução avalia a correção da consulta SQL gerada comparando os resultados obtidos pela execução da consulta no banco de dados de destino com os resultados esperados.
Precisão da execução (EX)[13] A correção de uma consulta SQL prevista é medida executando a consulta no banco de dados correspondente e comparando os resultados com os obtidos com a consulta verdadeira de base.
Índice de eficiência efetiva (VES)A definição de [33] é medir a eficiência de uma consulta SQL eficaz. Uma consulta SQL eficaz é uma consulta SQL prevista cujo resultado da execução é idêntico ao resultado verdadeiro subjacente. Especificamente, o VES avalia simultaneamentePrevisão da eficiência e da precisão das consultas SQL. Para um conjunto de dados de texto contendo N exemplos, o VES é calculado como:

R(Y_n, Y_n) denota a eficiência de execução relativa da consulta SQL prevista em comparação com a consulta real.
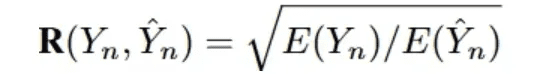
A pesquisa mais recente sobre texto para SQL baseada em LLM concentrou-se nesses quatro conjuntos de dados, Spider [13], Spider-Realistic [41], Spider-SYN [40] e BIRD [33]; e nos três métodos de avaliação, EM, EX e VES, que serão o foco da análise a seguir.
metodologias
As implementações atuais de aplicativos baseados em LLM dependem muito dos paradigmas ICL (In-Context Learning) (Just-in-Time Engineering) [87-89] e FT (Fine-Tuning) [90,91], já que modelos poderosos de código aberto proprietários e bem arquitetados estão sendo lançados em grande número [45,86,92-95]. Os sistemas de texto para SQL baseados em LLM seguem esses paradigmas para implementação. Nesta pesquisa, eles serão discutidos de acordo.
A. aprendizado contextual
Por meio de pesquisas extensas e bem reconhecidas, foi demonstrado que a engenharia de dicas desempenha um papel decisivo no desempenho dos LLMs [28 , 96 ], além de influenciar a geração de SQL em diferentes estilos de dicas [9 , 46]. Portanto, o desenvolvimento de métodos de texto para SQL no paradigma de aprendizado contextual (ICL) é valioso para obter melhorias promissoras. Uma implementação de um processo de texto para SQL baseado em LLM que gera uma consulta SQL executável Y pode ser formulada da seguinte forma:

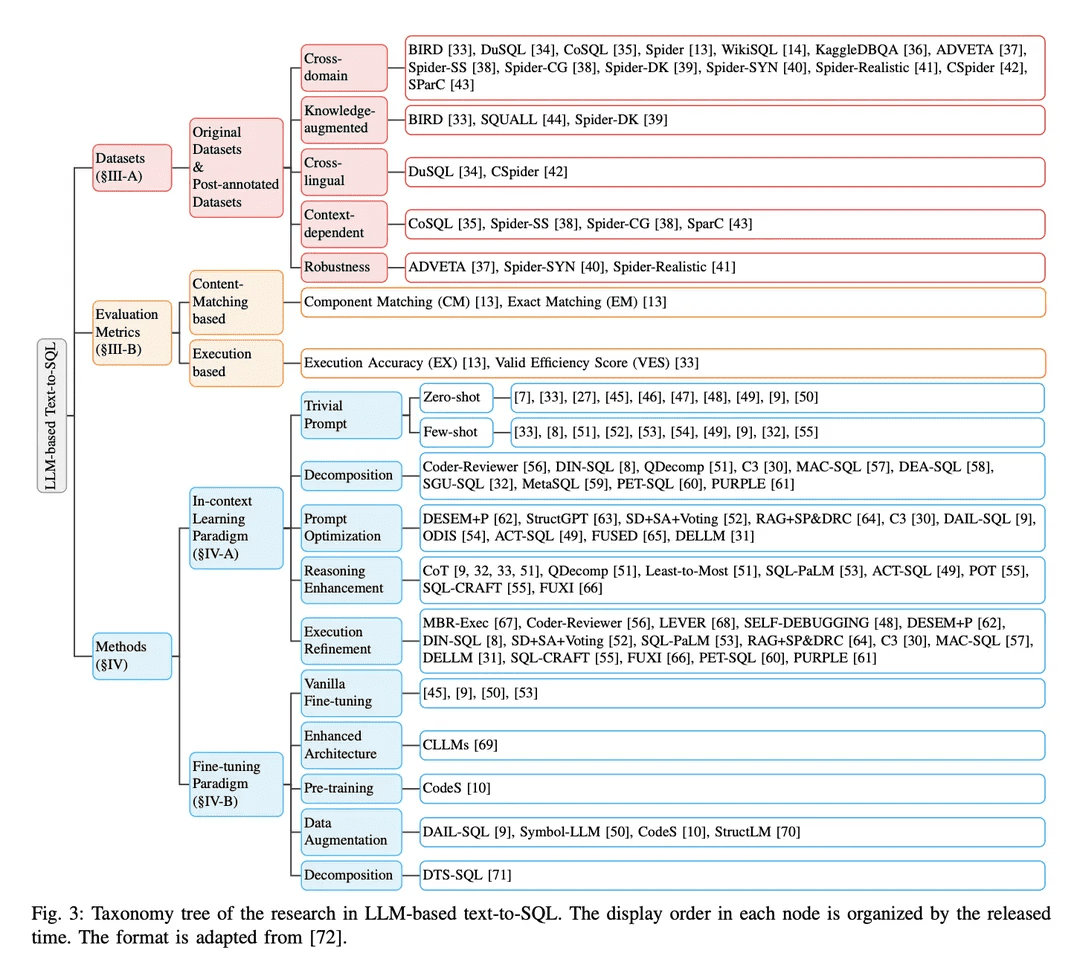
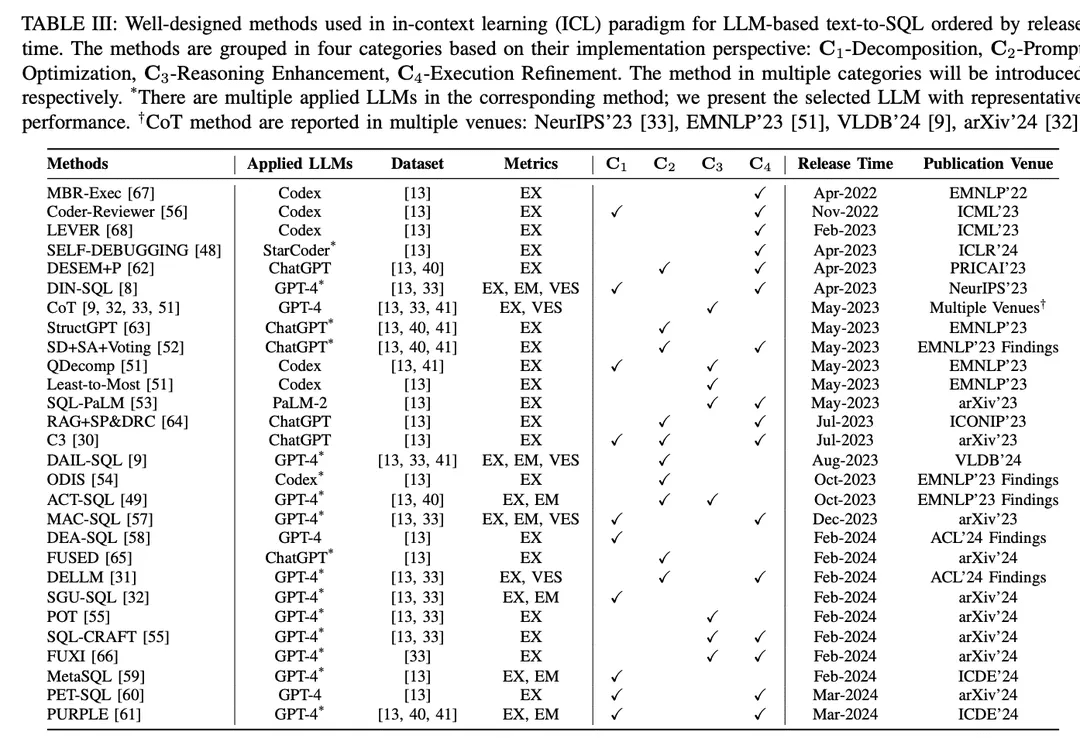
No paradigma de aprendizado contextual (ICL), um modelo de texto para SQL pronto para uso (ou seja, o parâmetro θ do modelo está congelado) é usado para gerar consultas SQL previstas. As tarefas de texto para SQL baseadas em LLM empregam uma variedade de métodos bem projetados no paradigma ICL. Eles são classificados em cinco categorias C0:4, incluindo C0-Simple Hinting, C1-Decomposition, C2-Hint Optimisation, C3-Inference Enhancement e C4-Execution Refinement. A Tabela II lista os representantes de cada categoria.
C0 - Prompt trivialO LLM é um método de treinamento de dados de grande porte, com forte proficiência geral em diferentes tarefas de downstream com amostra zero e pequeno número de dicas [90, 97, 98], o que é amplamente reconhecido e aplicado em aplicações práticas. Na pesquisa, os métodos de solicitação mencionados anteriormente sem enquadramento elaborado foram categorizados como solicitações triviais (engenharia de solicitação falsa). Conforme mencionado acima, a Eq. 3 descreve o processo de conversão de texto em SQL baseado em LLM, que também pode denotar a solicitação de amostra zero. A entrada geral P0 é obtida pela concatenação de I, S e Q. A entrada P0 é a mesma que a entrada geral P0:
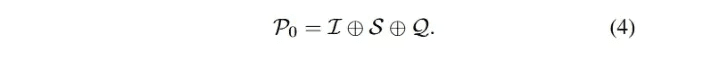
Para padronizar o processo de solicitação, o OpenAI demo2 foi configurado como uma solicitação padrão (simples) para texto para SQL [30].
amostra zeroPesquisa: Muitos trabalhos de pesquisa [7,27,46] utilizam dicas de amostra zero, concentrando-se no impacto dos estilos de construção de dicas e de vários LLMs no desempenho de amostra zero de texto para SQL. Como uma avaliação empírica, [7] avaliou o desempenho de diferentes LLMs desenvolvidos anteriormente [85, 99, 100] para a funcionalidade de texto para SQL de linha de base, bem como para diferentes estilos de dicas. Os resultados mostram que o design on-the-fly é fundamental para o desempenho e, por meio da análise de erros, [7] sugere que mais conteúdo do banco de dados pode prejudicar a precisão geral. Como o ChatGPT com recursos impressionantes em cenários de diálogo e geração de código [101], [27] avaliou seu desempenho de texto para SQL. Com uma configuração de amostra zero, os resultados mostram que o ChatGPT tem um desempenho encorajador de texto para SQL em comparação com os sistemas baseados em PLM de última geração. Para uma comparabilidade justa, [47] revelou construções eficazes de solicitação para texto para SQL baseado em LLM; eles investigaram diferentes estilos de construções de solicitação e concluíram um projeto de solicitação de amostra zero com base na comparação.
As chaves primárias e estrangeiras transmitem conhecimento contínuo de diferentes tabelas. [49] estudou seu impacto incorporando essas chaves em vários estilos de dicas para diferentes conteúdos de bancos de dados e analisando os resultados de dicas de amostra zero. O impacto das chaves estrangeiras também foi investigado em uma avaliação de benchmark [9], na qual foram incluídos cinco estilos diferentes de representação de dicas, cada um dos quais pode ser considerado como uma permutação de diretivas, significados de regras e chaves estrangeiras. Além das chaves externas, este estudo também explorou a combinação de dicas de amostra zero e implicações de regras "sem interpretação" para coletar resultados concisos. Com o apoio da anotação do conhecimento externo de especialistas humanos, [33] seguiu as dicas padrão e obteve melhorias combinando o conhecimento do oráculo anotado fornecido.
Com a explosão de LLMs de código aberto, esses modelos também são capazes de realizar tarefas de texto para SQL com amostra zero, de acordo com avaliações semelhantes [45, 46, 50], especialmente modelos de geração de código [46, 48]. Para a otimização de hinting de amostra zero, [46] apresentou o desafio de projetar modelos de hinting eficazes para LLMs; as construções de hinting anteriores não tinham unidade estrutural, o que dificultava a identificação de elementos específicos nos modelos de construções de hinting que afetam o desempenho dos LLMs. Para enfrentar esse desafio, eles investigaram uma série de modelos de dicas mais uniformes ajustados com diferentes prefixos, sufixos e prefixos-pós-fixos.
Algumas dicasA técnica de pequeno número de dicas tem sido amplamente usada em aplicações práticas e em pesquisas bem elaboradas, e tem se mostrado eficaz para melhorar o desempenho do LLM [28 , 102]. A sugestão de entrada geral do método de sugestão de texto para SQL baseado em LLM para um pequeno número de dicas pode ser formulada como uma extensão da Equação 3:

Como um estudo empírico, a sugestão de poucos disparos para texto para SQL foi avaliada em vários conjuntos de dados e vários LLMs [8 , 32] e mostrou bom desempenho em comparação com a sugestão de amostra zero. [33] fornece um exemplo detalhado de um disparo único de um modelo de texto para SQL para gerar SQL preciso. [55] investiga o impacto de um pequeno número de exemplos. [52] concentra-se nas estratégias de amostragem, investigando a similaridade e a diversidade entre diferentes exemplos, comparando a amostragem aleatória e avaliando diferentes estratégias8 e suas combinações para comparação. Além disso, além da seleção baseada em similaridade, [9] avalia os limites superiores da seleção de similaridade para problemas de mascaramento e métodos de similaridade com vários números de exemplos de amostras menores. Um estudo da seleção de amostras em níveis de dificuldade [51] comparou o desempenho do Codex de amostras pequenas [100] com a seleção aleatória e baseada em dificuldade de instâncias de amostras pequenas no conjunto de dados categóricos de dificuldade [13, 41]. Três estratégias de seleção baseadas em dificuldade foram projetadas com base no número de amostras selecionadas em diferentes níveis de dificuldade. [49] utilizaram uma estratégia híbrida para selecionar amostras que combinavam exemplos estáticos e exemplos dinâmicos baseados em similaridade para um pequeno número de pistas. Em sua configuração, eles também avaliaram os efeitos de diferentes estilos de padrões de entrada e vários tamanhos de amostras estáticas e dinâmicas.
O impacto de um pequeno número de exemplos entre domínios também está sendo investigado [54]. Quando diferentes números de exemplos dentro e fora do domínio foram incluídos, os exemplos dentro do domínio superaram os exemplos de ordem zero e fora do domínio, oÀ medida que o número de exemplos aumenta, o desempenho dos exemplos no domínio melhora. Para explorar a construção detalhada das dicas de entrada, [53] comparou as abordagens de design de dicas concisas e detalhadas. A primeira divide o esquema, os nomes das colunas, as chaves primárias e estrangeiras por entradas, enquanto a segunda as organiza em descrições de linguagem natural.
C1-DecomposiçãoComo uma solução intuitiva, a decomposição de problemas desafiadores do usuário em subproblemas mais simples ou sua implementação usando vários componentes pode reduzir a complexidade da tarefa geral de texto para SQL [8, 51]. Ao lidar com problemas menos complexos, o LLM tem o potencial de gerar SQL mais preciso. Os métodos de decomposição de texto para SQL baseados em LLM se enquadram em dois paradigmas:(1) Detalhamento das subtarefasAlém disso, ao dividir toda a tarefa de conversão de texto em SQL em subtarefas mais gerenciáveis e eficientes (por exemplo, vinculação de esquema [71], classificação de domínio [54]), a análise adicional é fornecida para ajudar na geração final do SQL.(2) Decomposição do subproblemaDecompor o problema do usuário em subproblemas para reduzir a complexidade e a dificuldade do problema e, em seguida, derivar a consulta SQL final resolvendo esses problemas para gerar sub-SQL.
DIN-SQL[8] propôs um método de aprendizado de contexto decomposto, incluindo quatro módulos: vinculação de esquema, classificação e decomposição, geração de SQL e autocorreção. O DIN-SQL primeiro gera a vinculação de esquema entre o problema do usuário e o banco de dados de destino; o módulo subsequente decompõe o problema do usuário em subproblemas relacionados e classifica a dificuldade. Com base nas informações acima, o módulo de geração de SQL gera o SQL correspondente, e o módulo de autocorreção identifica e corrige possíveis erros no SQL previsto. Essa abordagem trata a decomposição do subproblema como um módulo da decomposição da subtarefa. A estrutura Coder-Reviewer [56] propõe uma abordagem de reordenação que combina um modelo Coder para gerar instruções e um modelo Reviewer para avaliar a probabilidade das instruções.
Referindo-se às dicas Chain-of-Thought [103] e Least-to-Most [104], oQDecomp[51] introduziu a dica de decomposição do problema, que segue a fase de redução do problema da última à última dica e instrui o LLM a realizar a decomposição do problema complexo original como uma etapa intermediária de raciocínio.
C3 O ChatGPT [ 30 ] consiste em três componentes principais: dicas de clareza, dicas de viés de calibração e consistência; esses componentes são obtidos atribuindo-se diferentes tarefas ao ChatGPT. Primeiro, o componente de dicas de clareza gera links de esquema e esquemas refinados relacionados à pergunta como dicas de clareza. Em seguida, várias rodadas de diálogo sobre dicas de texto para SQL são usadas como dicas de viés de calibração, que são combinadas com dicas claras para orientar a geração de SQL. As consultas SQL geradas são filtradas por consistência e votação baseada em execução para obter o SQL final.
MAC-SQL[57] propôs uma estrutura colaborativa com vários agentes; o processo de conversão de texto em SQL é feito em colaboração com agentes como seletores, decompositores e refinadores. O Seletor mantém tabelas relevantes para o problema do usuário; o Decompositor divide o problema do usuário em subproblemas e fornece soluções; finalmente, o Refinador valida e otimiza o SQL defeituoso.
DEA- SQL [58] apresenta um paradigma de fluxo de trabalho que visa melhorar a atenção e o escopo de solução de problemas do texto para SQL baseado em LLM por meio da decomposição. A abordagem decompõe a tarefa geral de modo que o módulo de geração de SQL tenha subtarefas correspondentes de pré-requisito (determinação de informações, classificação de problemas) e subsequentes (autocorreção, aprendizado ativo). O paradigma do fluxo de trabalho permite que o LLM gere consultas SQL mais precisas
SGU-SQL [ 32 ] é uma estrutura de estrutura para SQL que usa informações estruturais inerentes para auxiliar na geração de SQL. Especificamente, a estrutura cria estruturas gráficas para perguntas de usuários e bancos de dados correspondentes, respectivamente, e depois usa gráficos codificados para criar links estruturais [105 , 106]. Os metoperadores são usados para decompor os problemas do usuário usando árvores de sintaxe e, finalmente, os metoperadores em SQL são usados para projetar prompts de entrada.
MetaSQL A [ 59 ] apresenta uma abordagem de três fases para a geração de SQL: decomposição, geração e classificação. A fase de decomposição usa uma combinação de decomposição semântica e metadados para lidar com os problemas do usuário. Usando os dados processados anteriormente como entrada, algumas consultas SQL candidatas são geradas usando o modelo de texto para SQL gerado a partir das condições de metadados. Por fim, um pipeline de classificação em dois estágios é aplicado para obter a consulta SQL global ideal.
PET-SQL [ 60 ] apresenta uma estrutura de dois estágios aprimorada por dicas. Primeiro, dicas bem projetadas instruem o LLM a gerar SQL preliminar (PreSQL), em que algumas pequenas demonstrações são selecionadas com base na similaridade. Em seguida, os links de esquema são encontrados com base no PreSQL e combinados para solicitar que o LLM gere o SQL final (FinSQL). Por fim, o FinSQL é gerado usando vários LLMs para garantir a consistência com base nos resultados da execução.
Otimização de C2-PromptComo descrito anteriormente, o aprendizado de poucas ordens para dar dicas a LLMs foi amplamente estudado [85]. Para o aprendizado de texto para SQL (text-to-SQL) e de contexto baseado em LLM, os métodos triviais de poucos minutos produziram resultados promissores [8, 9, 33], e a otimização adicional da sugestão de poucos minutos tem o potencial de melhorar o desempenho. Como a precisão da geração de SQL em LLMs prontos depende muito da qualidade das dicas de entrada correspondentes [107], muitos determinantes que afetam a qualidade das dicas têm sido o foco das pesquisas atuais [9] (por exemplo, qualidade e quantidade da organização das oligo-hints, similaridade entre o problema do usuário e as instâncias das oligo-hints, conhecimento externo/dicas).
DESEM O [ 62 ] é uma estrutura de engenharia de dicas com semanticização e recuperação de esqueleto. A estrutura emprega primeiro um módulo de mascaramento de palavras específico do domínio para remover tokens semânticos que preservam a intenção nas perguntas do usuário. Em seguida, utiliza um módulo de dicas ajustável para recuperar um pequeno número de exemplos com a mesma intenção da pergunta e combina isso com a filtragem de relevância de padrão para orientar a geração de SQL para o LLM.
QDecomp [A estrutura apresenta um mecanismo InterCOL que combina de forma incremental subproblemas decompostos com nomes de tabelas e colunas associados. Por meio da seleção baseada em dificuldade, um pequeno número de exemplos de QDecomp é amostrado quanto à dificuldade. Além da amostragem por similaridade-diversidade, [ 52 ] propôs a estratégia de amostragem SD+SA+Voting (similaridade-diversidade+aumento de padrão+votação). Primeiro, eles fizeram uma amostragem de um pequeno número de exemplos usando similaridade semântica e diversidade de agrupamento k-Means e, em seguida, aumentaram as dicas usando conhecimento de padrão (aumento semântico ou estrutural).
C3 A estrutura de [ 30 ] consiste em um componente de dica clara, que recebe perguntas e esquemas como entrada para os LLMs, e um componente de calibração que fornece dicas, que gera uma dica clara que inclui um esquema que remove informações redundantes não relacionadas à pergunta do usuário e um link de esquema. A estrutura de aprimoramento de recuperação apresenta dicas com reconhecimento de amostra [64], que simplificam o problema original e extraem o esqueleto do problema do problema simplificado e, em seguida, concluem a recuperação de amostras no repositório com base na semelhança dos esqueletos. As amostras recuperadas são combinadas com o problema original para um pequeno número de dicas.
ODIS [54] introduz a seleção de amostras usando apresentações fora do domínio e dados sintéticos no domínio, que recuperam um pequeno número de apresentações de uma mistura de fontes para aprimorar a caracterização da sugestão
DAIL- SQL[9] propôs uma nova abordagem para resolver o problema de amostragem e organização de um pequeno número de exemplos, alcançando um melhor equilíbrio entre a qualidade e a quantidade de um pequeno número de exemplos. O DAIL Selection primeiro mascara o vocabulário específico do domínio dos usuários e um pequeno número de problemas de exemplo e, em seguida, classifica os exemplos candidatos com base na distância euclidiana incorporada. Ao mesmo tempo, é calculada a similaridade entre as consultas SQL pré-previstas. Por fim, o mecanismo de seleção obtém exemplos candidatos classificados por similaridade com base em critérios predefinidos. Com essa abordagem, garante-se que um pequeno número de exemplos tenha boa similaridade com o problema e a consulta SQL.
ACT-SQL[49] apresentou exemplos dinâmicos de seleção com base em pontuações de similaridade.
FUSIONADO[O pipeline do FUSED faz a amostragem de apresentações a serem fundidas por agrupamento e, em seguida, funde as apresentações amostradas para criar um pool de apresentações, melhorando assim a eficácia do aprendizado de poucas fotos.
Conhecimento em SQL [31] O objetivo da estrutura é criar LLMs especialistas em dados (DELLMs) para fornecer conhecimento para a geração de SQL.
DELLM O DELLM gera quatro tipos de conhecimento e métodos bem projetados (por exemplo, DAIL-SQL [9], MAC-SQL [57]) incorporam o conhecimento gerado para obter melhor desempenho para texto para SQL baseado em LLM por meio do aprendizado contextual.
C3 - Aprimoramento do raciocínio:Os LLMs demonstraram boas habilidades em tarefas que envolvem raciocínio de senso comum, raciocínio simbólico e raciocínio aritmético [108]. Em tarefas de texto para SQL, o raciocínio numérico e o raciocínio sinônimo aparecem com frequência em cenários realistas [33, 41]. Pesquisas recentes se concentraram na integração de métodos de aprimoramento de raciocínio bem projetados para adaptação de texto para SQL, aprimorando os LLMs para lidar com os desafios de problemas complexos que exigem raciocínio sofisticado3 e autoconsistência na geração de SQL.
A técnica de dicas de Chain-of-Thoughts (CoT) [103] consiste em um processo de raciocínio abrangente que orienta o LLM para um raciocínio preciso e estimula a capacidade de raciocínio do LLM. Estudos baseados em texto para SQL de LLM utilizam dicas de CoT como dicas de regras [9], com instruções do tipo "vamos pensar passo a passo" definidas na construção da dica [9, 32, 33, 51]. Entretanto, a estratégia direta (primitiva) de CoT para tarefas de texto para SQL não demonstrou o potencial que tem para outras tarefas de raciocínio; a pesquisa sobre a adaptação de CoT ainda está em andamento [51]. Como as dicas de CoT são sempre demonstradas usando exemplos estáticos com anotações manuais, isso requer julgamento empírico para selecionar com eficácia um pequeno número de exemplos para os quais as anotações manuais são essenciais.
Como uma solução.ACT-SQL [ 49] propõe um método para gerar automaticamente exemplos de CoT. Especificamente, o ACT-SQL, dado um problema, trunca o conjunto de fatias do problema e, em seguida, enumera cada coluna que aparece na consulta SQL correspondente. Cada coluna será associada à sua fatia mais relevante por meio de uma função de similaridade e anexada a uma dica de CoT.
QDecomp [51] Por meio de um estudo sistemático do aprimoramento da geração de SQL para LLMs em conjunto com dicas de CoT, é proposta uma nova estrutura para enfrentar o desafio de como a CoT propõe etapas de raciocínio para prever consultas SQL. A estrutura usa cada fragmento de uma consulta SQL para construir as etapas lógicas do raciocínio de CoT e, em seguida, usa modelos de linguagem natural para elaborar cada fragmento de uma consulta SQL e organizá-los em uma ordem lógica de execução.
Do menor para o maior A técnica de dica [104] é outra técnica que divide o problema em subproblemas e os resolve sequencialmente. Como uma dica iterativa, experimentos-piloto [51] sugerem que essa abordagem pode não ser necessária para a análise de texto para SQL. O uso de etapas de raciocínio detalhadas tende a criar mais problemas de propagação de erros.
Como uma variante do CoT, oPrograma de Pensamentos (PoT)Estratégias de dicas [109] foram propostas para aprimorar o raciocínio aritmético do LLM.
Ao avaliar [55], o PoT aprimora os LLMs gerados por SQL, especialmente em conjuntos de dados complexos [33].
SQL-CRAFT [A política de PoT exige que o modelo gere código Python e consultas SQL, forçando o modelo a incorporar o código Python em seu processo de raciocínio.
Autoconsistência[110] é uma estratégia de dicas para melhorar o raciocínio LLM que explora a intuição de que um problema de raciocínio complexo normalmente permite várias maneiras diferentes de pensar para chegar a uma resposta exclusivamente correta. Em tarefas de texto para SQL, a autoconsistência se aplica à amostragem de um conjunto de SQLs diferentes e à votação de SQLs consistentes por meio de feedback de execução [30 , 53].
Da mesma forma.SD+SA+Votação [52] A estrutura rejeita erros de execução identificados por um sistema de gerenciamento de banco de dados (DBMS) determinístico e seleciona a previsão que recebe a maioria dos votos.
Além disso, impulsionado por pesquisas recentes sobre o uso de ferramentas para ampliar a funcionalidade do LLM, oFUXI [66] é proposto para aprimorar a geração de SQL para LLM, invocando com eficiência ferramentas bem projetadas.
Refinamento de execução C4Ao projetar padrões para a geração precisa de SQL, a prioridade é sempre saber se o SQL gerado pode ser executado com sucesso e recuperar o conteúdo para responder corretamente à pergunta do usuário [13]. Como uma tarefa de programação complexa, gerar o SQL correto de uma só vez é muito desafiador. Intuitivamente, considerar o feedback/resultados da execução durante a geração de SQL ajuda a alinhar com o ambiente de banco de dados correspondente, permitindo que o LLM colete possíveis erros de execução e resultados para refinar o SQL gerado ou obter um voto majoritário [30]. As abordagens com reconhecimento de execução de texto para SQL incorporam o feedback de execução de duas maneiras principais:
1) Geração de feedback com uma segunda rodada de promptsPara cada consulta SQL gerada na resposta inicial, ela será executada no banco de dados apropriado para obter feedback do banco de dados. Esse feedback pode ser erros ou resultados que serão anexados à segunda rodada de prompts. Ao aprender esse feedback no contexto, o LLM é capaz de refinar ou regenerar o SQL original para melhorar a precisão.
2) Usar política de seleção baseada em execução para SQL geradoA partir do LLM, a amostragem de várias consultas SQL geradas e a execução de cada consulta no banco de dados. Com base no resultado da execução de cada consulta SQL, uma estratégia de seleção (por exemplo, autoconsistência, votação majoritária [60]) é usada para definir uma consulta SQL do conjunto SQL que satisfaça as condições como o SQL final previsto.
MRC-EXEC [ 67 ] propôs uma estrutura de tradução de linguagem natural para código (NL2Code) com execução que classifica cada consulta SQL amostrada e seleciona o exemplo com o menor resultado de execução com base no risco de Bayes [111].ALAVANCA [68] propõe um método para validar o NL2Code por execução, usando os módulos de geração e execução para coletar amostras do conjunto de SQL e seus resultados de execução, respectivamente, e, em seguida, usando um validador de aprendizado para gerar a probabilidade de correção.
Em uma linha semelhante.DEPURAÇÃO AUTOMÁTICA [A estrutura também ensina o LLM a depurar seu SQL previsto com um pequeno número de demonstrações. O modelo é capaz de corrigir erros sem intervenção humana, investigando os resultados da execução e interpretando o SQL gerado em linguagem natural.
Conforme mencionado anteriormente, a implicação em dois estágios foi amplamente utilizada para combinar uma estrutura bem projetada com o feedback da implementação:1. amostragem de um conjunto de consultas SQL. 2. votação majoritária (autoconsistente).Especificamente.C3[30] A estrutura elimina erros e identifica o SQL mais consistente;A estrutura de aprimoramento de recuperação [64] introduz cadeias de revisão dinâmicasA biblioteca SQL foi projetada para ser um módulo de autocorreção que combina mensagens de execução refinadas com o conteúdo do banco de dados para solicitar aos LLMs que convertam as consultas SQL geradas em interpretações de linguagem natural; foi solicitado aos LLMs que identificassem lacunas semânticas e modificassem seu próprio SQL gerado. O DIN-SQL [8] desenvolveu dicas genéricas e suaves em seu módulo de autocorreção; as dicas genéricas exigem que o LLM identifique e corrija os erros, e as dicas suaves exigem que o modelo verifique os possíveis problemas.
estrutura multiagenteMAC-SQL[57] inclui um agente de refinamento que detecta e corrige automaticamente erros de SQL, emprega classes de erro e exceção do SQLite para regenerar o SQL corrigido, já que problemas diferentes podem exigir números diferentes de revisões.SQL-CRAFT [55] A estrutura introduz a calibração interativa e o controle automático do processo de determinação para evitar a supercorreção ou a subcorreção. FUXI [66] considera o feedback de erros no raciocínio baseado em ferramentas para a geração de SQL. Conhecimento em SQL [31] introduziu uma estrutura de aprendizado de preferências que combina o feedback da execução do banco de dados com a otimização direta de preferências [112] para aprimorar o DELLM proposto.PET-SQL[60] propuseram a consistência cruzada, que consiste em duas variantes: 1) votação simples: vários LLMs são instruídos a gerar uma consulta SQL e, em seguida, uma votação majoritária é utilizada para decidir o SQL final com base nos resultados das diferentes execuções; e 2) votação refinada: a votação simples é refinada com base no nível de dificuldade para atenuar o viés da votação.
B. Ajuste fino
Como o ajuste fino supervisionado (SFT) é a abordagem dominante para o treinamento de LLMs [29, 91], para LLMs de código aberto (por exemplo, LLaMA-2 [94], Gemma [113]), a maneira mais direta de adaptar rapidamente o modelo a um domínio específico é executar o SFT no modelo usando rótulos de domínio coletados. O processo de geração de regressão automática para a consulta SQL Y pode ser formulado da seguinte forma:

A abordagem SFT também é um método de ajuste fino fictício para texto para SQL e foi amplamente adotada por vários LLMs de código aberto na pesquisa de texto para SQL [9, 10 , 46 ]. O paradigma de ajuste fino prefere pontos de partida de texto para SQL baseados em LLMs em vez de abordagens de aprendizado contextual (ICL). Vários estudos que exploram melhores métodos de ajuste fino foram publicados. Os métodos de ajuste fino bem projetados são categorizados em diferentes grupos de acordo com seus mecanismos, conforme mostrado na Tabela IV:
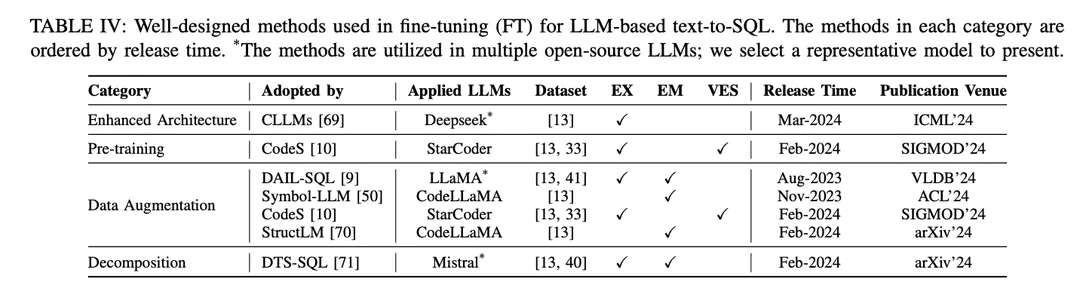
Arquitetura aprimoradaA estrutura do Generative Pretrained Transformer (GPT), amplamente usada, utiliza uma arquitetura de transformador somente de decodificador e decodificação autorregressiva tradicional para gerar texto. Estudos recentes sobre a eficiência dos LLMs revelaram um desafio comum: a latência dos LLMs é alta devido à necessidade de incorporar um mecanismo de atenção ao gerar sequências longas usando padrões autorregressivos [115 , 116 ]. No texto para SQL baseado em LLM, a geração de consultas SQL é significativamente mais lenta em comparação com a modelagem de linguagem tradicional [21 , 28], o que se torna um desafio para a criação de NLIDBs locais eficientes. Como uma das soluções, o CLLM [69] tem como objetivo abordar os desafios acima e acelerar a geração de SQL por meio de uma arquitetura de modelo aprimorada.
Aprimoramento de dadosAjuste fino: No processo de ajuste fino, o fator mais direto que afeta o desempenho do modelo é a qualidade dos rótulos de treinamento [117]. O ajuste fino com baixa qualidade ou falta de rótulos de treinamento é uma "moleza", e o ajuste fino com dados de alta qualidade ou aumentados sempre supera os métodos de ajuste fino bem projetados em dados brutos ou de baixa qualidade [29, 74]. Houve um progresso substancial no ajuste fino aprimorado por dados de texto para SQL, com foco no aprimoramento da qualidade dos dados no processo de SFT.
[117] "Learning from noisy labels with deep neural networks: a survey" (Aprendendo com rótulos ruidosos com redes neurais profundas: uma pesquisa)[74] Avanços recentes em conversão de texto em SQL: uma pesquisa sobre o que temos e o que esperamos[29] "A survey of large language models" (Uma pesquisa de modelos de linguagem grandes)O DAIL-SQL [9] foi projetado como uma estrutura de aprendizado contextual que utiliza uma estratégia de amostragem para obter um número menor de instâncias de amostra. A incorporação de instâncias amostradas no processo SFT melhora o desempenho do LLM de código aberto. O Symbol-LLM [50] propõe instruções de aumento de dados ajustadas às fases injetadas e infundidas. O CodeS [10] aprimora os dados de treinamento por meio da geração bidirecional com a ajuda do ChatGPT. O StructLM [70] é treinado em várias tarefas de conhecimento estrutural para melhorar a capacidade geral.
pré-treinamentoPré-treinamento: O pré-treinamento é o estágio fundamental de todo o processo de ajuste fino, com o objetivo de obter recursos de geração de texto por meio do treinamento de regressão automática em uma grande quantidade de dados [118]. Tradicionalmente, os LLMs proprietários poderosos atuais (por exemplo, ChatGPT [119], GPT-4 [86], Claude [120]) são pré-treinados em corpora híbridos, que se beneficiam principalmente de cenários de diálogo que exibem recursos de geração de texto [85]. Os LLMs específicos de código (por exemplo, CodeLLaMA [121], StarCoder [122]) são pré-treinados em dados de código [100], e a combinação de várias linguagens de programação permite que os LLMs gerem códigos que estejam em conformidade com as instruções do usuário [123]. O principal desafio das técnicas de pré-treinamento voltadas para SQL como uma subtarefa de geração de código é que o conteúdo relacionado a SQL/bancos de dados é apenas uma pequena parte de todo o corpus pré-treinado.
Como resultado, os LLMs de código aberto com recursos de síntese relativamente limitados (em comparação com o ChatGPT, GPT-4) não têm um bom entendimento de como transformar problemas de NL em SQL durante o pré-treinamento. A partir do LLM básico específico de código [122], o CodeS executa o pré-treinamento incremental em um corpus de treinamento misto (incluindo dados relacionados a SQL, dados de NL para código e dados relacionados a NL). A compreensão e o desempenho de texto para SQL são significativamente aprimorados.
decomposiçãoA decomposição de uma tarefa em várias etapas ou o uso de vários modelos para resolver a tarefa é uma solução intuitiva para resolver cenários complexos, como mostra o paradigma ICL, apresentado anteriormente no Capítulo IV-A. Os modelos proprietários usados nas abordagens baseadas em ICL têm um grande número de parâmetros, que estão em um nível de parâmetro diferente dos modelos de código aberto usados nas abordagens de ajuste fino. Esses modelos são inerentemente capazes de executar bem as subtarefas atribuídas (por meio de mecanismos como o aprendizado com menos amostras) [30, 57]. Portanto, para replicar o sucesso desse paradigma em uma abordagem de ICL, é importante atribuir racionalmente as subtarefas apropriadas (por exemplo, gerar conhecimento externo, vincular esquemas e refinar esquemas) aos modelos de código aberto para ajustá-los para as subtarefas específicas e construir os dados apropriados para uso no ajuste fino para auxiliar na geração do SQL final.
O DTS-SQL [71] propõe uma decomposição em dois estágios da estrutura de ajuste fino de texto para SQL e projeta uma tarefa de pré-geração de link de esquema antes da geração final do SQL.
contar
Apesar do progresso significativo na pesquisa de texto para SQL, ainda há alguns desafios que precisam ser abordados. Nesta seção, são discutidos os desafios restantes que devem ser superados em trabalhos futuros.
A. Robustez em aplicações práticas
A conversão de texto em SQL, implementada por LLMs, é uma promessa de generalidade e robustez em cenários de aplicativos complexos do mundo real. Apesar do recente progresso substancial em conjuntos de dados específicos de robustez [ 37 , 41], seu desempenho ainda não é suficiente para aplicativos do mundo real [ 33]. Ainda há alguns desafios a serem superados em pesquisas futuras. Do lado do usuário, há um fenômeno em que o usuário nem sempre é um autor explícito de perguntas, o que significa que a pergunta do usuário pode não ter valores exatos no banco de dados ou pode ser diferente do conjunto de dados padrão, onde sinônimos, erros de ortografia e expressões difusas podem ser incluídos [40].
Por exemplo, no paradigma de ajuste fino, o modelo é treinado em problemas explicitamente indicativos com representações concretas. Como o modelo não aprende o mapeamento de problemas do mundo real para os bancos de dados correspondentes, há uma lacuna de conhecimento quando aplicado a cenários do mundo real [33]. Conforme relatado nas avaliações correspondentes em conjuntos de dados com sinônimos e instruções incompletas [7 , 51], as consultas SQL geradas pelo ChatGPT contêm cerca de 40% de execuções incorretas, o que é 10% menor do que a avaliação original [51]. Ao mesmo tempo, o ajuste fino usando texto nativo para conjuntos de dados SQL pode conter amostras e rótulos não padronizados. Por exemplo, os nomes de tabelas ou colunas nem sempre são representações precisas de seus conteúdos, o que leva a inconsistências na construção dos dados de treinamento.
B. Eficiência computacional
A eficiência computacional é determinada pela velocidade do raciocínio e pelo custo dos recursos computacionais, o que vale a pena considerar tanto nos aplicativos quanto nos esforços de pesquisa [49, 69]. Com o aumento da complexidade dos bancos de dados nos últimos benchmarks de texto para SQL [15, 33], os bancos de dados terão mais informações (incluindo mais tabelas e colunas) e o comprimento do token do esquema do banco de dados aumentará de acordo, apresentando vários desafios. Ao lidar com bancos de dados ultracomplexos, o uso do esquema correspondente como entrada pode enfrentar o desafio de que o custo de invocar LLMs proprietários aumentará significativamente, podendo exceder o comprimento máximo de token do modelo, especialmente ao implementar modelos de código aberto com comprimentos de contexto curtos.
Enquanto isso, outro desafio óbvio é que a maioria dos estudos usa padrões completos como entradas do modelo, o que introduz uma grande quantidade de redundância [57]. Fornecer ao LLM os padrões filtrados exatos relevantes para o problema diretamente do lado do usuário para reduzir o custo e a redundância é uma possível solução para melhorar a eficiência computacional [30]. O projeto de um método preciso de filtragem de padrões continua sendo uma direção futura. Embora o paradigma de aprendizagem de contexto tenha alcançado uma precisão promissora, estruturas de vários estágios bem projetadas ou métodos de contexto estendidos aumentam o número de chamadas de API, o que melhora o desempenho do ponto de vista da eficiência computacional, mas também leva a um aumento significativo no custo [8].
Em abordagens relacionadas [49], o compromisso entre desempenho e eficiência computacional deve ser cuidadosamente considerado, e o projeto de uma abordagem de aprendizado de contexto comparável (ou até melhor) com um custo menor de interface de programação de aplicativos seria uma implementação prática que ainda está sendo explorada. Em comparação com as abordagens baseadas em PLM, as abordagens baseadas em LLM têm um raciocínio significativamente mais lento [ 21, 28]. Acelerar o raciocínio diminuindo o tamanho da entrada e reduzindo o número de estágios no processo de implementação é intuitivo para o paradigma de aprendizagem contextual. Para LLM local, a partir do ponto de partida [69], mais estratégias de aceleração podem ser investigadas para aprimorar a arquitetura do modelo em explorações futuras.
Para enfrentar esse desafio, o ajuste do LLM ao viés intencional e a criação de estratégias de treinamento para cenários ruidosos beneficiariam o progresso recente. Enquanto isso, a quantidade de dados em aplicativos do mundo real é relativamente menor do que os benchmarks baseados em pesquisa. Como o dimensionamento de uma grande quantidade de dados por meio de anotação manual incorre em altos custos de mão de obra, a criação de métodos de expansão de dados para mais pares pergunta-SQL fornecerá suporte para LLMs quando os dados forem escassos. Além disso, o ajuste fino do LLM de código aberto para estudos de adaptação local em conjuntos de dados de pequena escala é potencialmente benéfico. Além disso, as extensões para cenários multilíngues [ 42 , 124 ] e multimodais [ 125 ] devem ser investigadas de forma abrangente em pesquisas futuras, o que beneficiaria mais comunidades linguísticas e ajudaria a criar interfaces de banco de dados mais gerais.
C. Privacidade e interpretabilidade dos dados
Como parte da pesquisa de LLM, o texto para SQL baseado em LLM também enfrenta alguns desafios gerais que existem na pesquisa de LLM [4 , 126 , 127 ]. Do ponto de vista do texto para SQL, esses desafios também levam a possíveis melhorias que podem beneficiar muito a pesquisa de LLM. Conforme mencionado anteriormente no Capítulo IV-A, os paradigmas de aprendizagem contextual dominaram as pesquisas recentes em termos de volume e desempenho, com a maior parte do trabalho implementado usando modelos proprietários [8, 9]. Um desafio imediato é apresentado em termos de privacidade de dados, pois invocar APIs proprietárias para lidar com a confidencialidade de bancos de dados locais pode representar um risco de vazamento de dados. O uso de paradigmas de ajuste fino local pode resolver parcialmente esse problema.
No entanto, o desempenho do ajuste fino básico está abaixo do ideal [9], e as estruturas avançadas de ajuste fino podem depender de LLMs proprietários para aumentar os dados [10]. Com base no estado atual das coisas, estruturas mais personalizadas no paradigma de ajuste fino local de texto para SQL merecem muita atenção. De modo geral, o desenvolvimento da aprendizagem profunda sempre enfrentou desafios em termos de interpretabilidade [127 , 128].
Como um desafio de longa data, uma grande quantidade de pesquisas foi realizada para resolver esse problema [129 , 130]. No entanto, a interpretabilidade das implementações baseadas em LLM ainda não foi discutida na pesquisa de texto para SQL, seja em paradigmas de aprendizado contextual ou de ajuste fino. As abordagens com estágios de decomposição explicam as implementações de texto para SQL a partir de uma perspectiva de geração em etapas [8, 51]. Com base nisso, a incorporação de pesquisas avançadas em interpretabilidade [131, 132] para melhorar o desempenho de texto para SQL, bem como a explicação de arquiteturas de modelos locais em termos de conhecimento de banco de dados, continua sendo uma direção futura.
D. Expansão
Como um subcampo da pesquisa de LLM e de compreensão de linguagem natural, grande parte da pesquisa nessas áreas foi alimentada pelo uso de tarefas de texto para SQL [103 , 110 ]. No entanto, a pesquisa de texto para SQL também pode ser estendida para uma pesquisa mais ampla nessas áreas. Por exemplo, a geração de SQL faz parte da geração de código. Métodos de geração de código bem projetados também podem obter bom desempenho em texto para SQL [48, 68] e podem ser generalizados em uma ampla gama de linguagens de programação. A possibilidade de estender algumas estruturas personalizadas de texto para SQL para estudos de NL para código também pode ser discutida.
Por exemplo, as estruturas que integram a saída de execução em NL-para-código também alcançam excelente desempenho na geração de SQL [8]. Vale a pena discutir as tentativas de estender a abordagem com reconhecimento de execução em text-to-SQL com outros módulos de avanço [30, 31] para a geração de código. De outra perspectiva, foi discutido anteriormente que o texto para SQL pode aprimorar a resposta a perguntas (QA) baseada em LLM fornecendo informações factuais. Os bancos de dados podem armazenar conhecimento relacional como informações estruturais, e a GQ baseada em estrutura pode se beneficiar da conversão de texto em SQL (por exemplo, resposta a perguntas baseada em conhecimento, KBQA [ 133 , 134 ]). A utilização de estruturas de banco de dados para construir o conhecimento factual e, em seguida, combiná-lo com um sistema de texto para SQL para permitir a recuperação de informações tem o potencial de ajudar a QA adicional na obtenção de conhecimento factual mais preciso [ 135 ]. Espera-se que, em trabalhos futuros, seja realizada uma pesquisa mais ampla de texto para SQL.
Apresentação do produto OlaChat Digital Intelligence Assistant

O OlaChat Digital Intelligence Assistant é um novo produto de análise de dados inteligente lançado pelo Departamento de Plataforma de Big Data PCG da Tencent, usando grandes modelos no campo da análise de dados na prática de aterrissagem, e foi integrado ao DataTalk, ao OlaIDE e a outras plataformas de dados principais internas da Tencent, para fornecer suporte inteligente para todo o processo de cenários de análise de dados. Ele contém uma série de recursos, como text2sql, análise de indicadores, otimização inteligente de SQL, etc. Desde a análise de dados (análise de arrastar e soltar, consulta SQL), visualização de dados até a interpretação e atribuição de resultados, o OlaChat auxilia de forma abrangente a tornar o trabalho de análise de dados mais simples e eficiente!
© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Artigos relacionados




Nenhum comentário...