
Um artigo de 10.000 palavras sobre otimização de RAG em cenários reais de DB-GPT.
Prefácio
Nos últimos dois anos, a tecnologia Retrieval-Augmented Generation (RAG, Geração Aumentada por Recuperação) tornou-se gradualmente um componente essencial das inteligências aprimoradas. Ao combinar os recursos duplos de recuperação e geração, a RAG é capaz de introduzir conhecimento externo, oferecendo assim mais possibilidades para a aplicação de modelos grandes em cenários complexos. No entanto, em cenários práticos de aterrissagem, muitas vezes há problemas de baixa precisão de recuperação, interferência de ruído, integridade de recall e profissionalismo insuficiente, o que leva a sérias ilusões de LLM. Neste artigo, vamos nos concentrar nos detalhes de processamento e recuperação de conhecimento do RAG em cenários reais de aterrissagem, como otimizar o link RAG Pineline e, por fim, melhorar a precisão da recuperação.
É fácil criar rapidamente um aplicativo de perguntas e respostas inteligente RAG, mas colocá-lo em um cenário comercial real exige muita preparação.
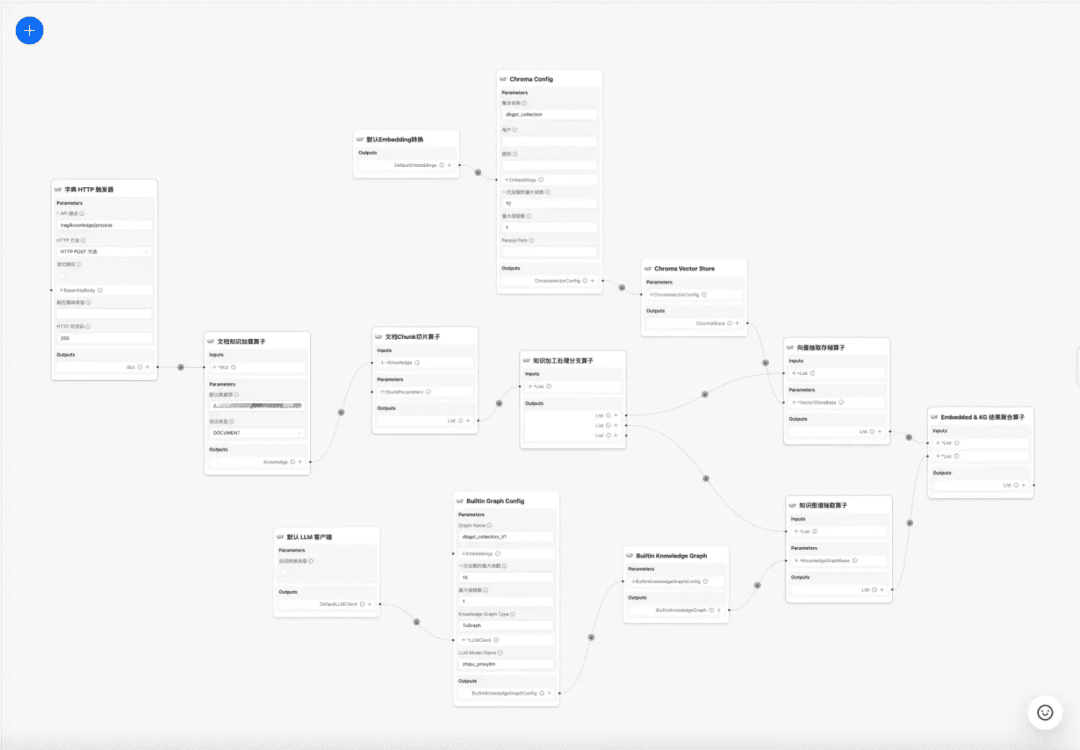
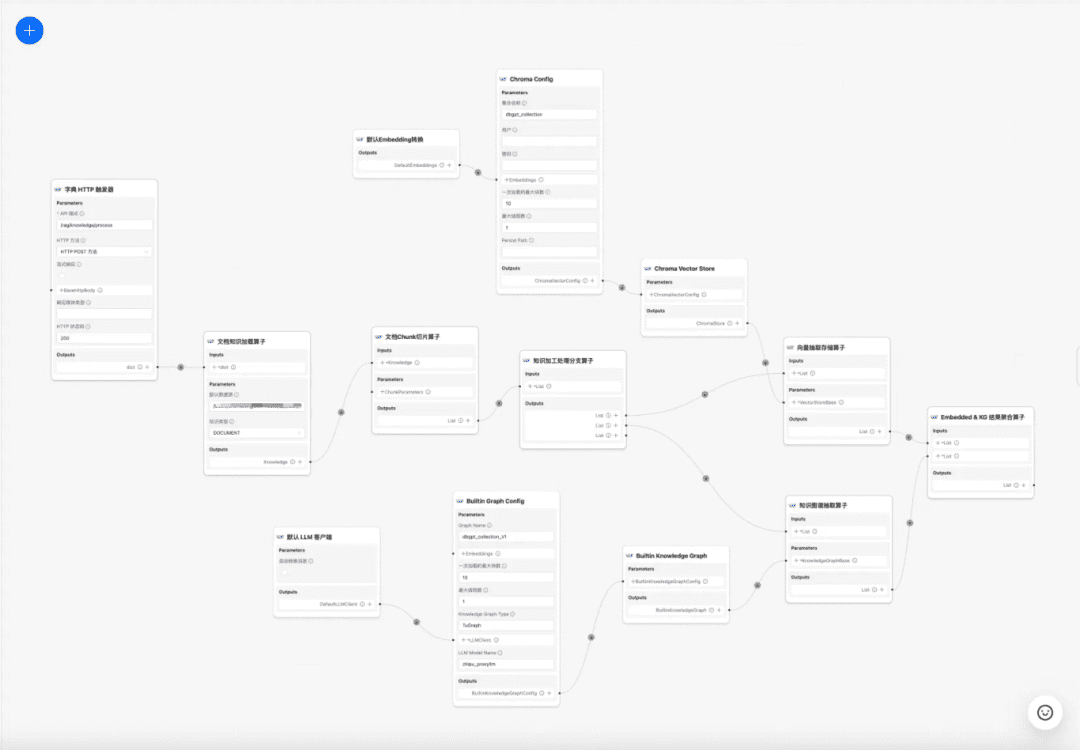
1.RAG Interpretação do código-fonte do processo-chave
centroprocessamento de conhecimentoresponder cantandoRAGAlguns dos principais processos:
1. processamento de conhecimento
Carregamento de conhecimento -> Fatiamento de conhecimento -> Extração de informações -> Processamento de conhecimento (incorporação/gráfico/palavras-chave) -> Armazenamento de conhecimento
- Carregamento de conhecimento
# 知识工厂进行实例化 KnowledgeFactory -> create() -> load() -> Document - knowledge - markdown - pdf - docx - txt - html - pptx - url - ...
Como expandir:
from abc import ABC from typing import List, Any class Knowledge(ABC): def load(self) -> List[Document]: """Load knowledge from data loader.""" pass @classmethod def document_type(cls) -> Any: """Get document type.""" pass @classmethod def support_chunk_strategy(cls) -> List[ChunkStrategy]: """Return supported chunk strategy.""" return [ ChunkStrategy.CHUNK_BY_SIZE, ChunkStrategy.CHUNK_BY_PAGE, ChunkStrategy.CHUNK_BY_PARAGRAPH, ChunkStrategy.CHUNK_BY_MARKDOWN_HEADER, ChunkStrategy.CHUNK_BY_SEPARATOR, ] @classmethod def default_chunk_strategy(cls) -> ChunkStrategy: """ Return default chunk strategy. Returns: ChunkStrategy: default chunk strategy """ return ChunkStrategy.CHUNK_BY_SIZE
- fatia de conhecimento
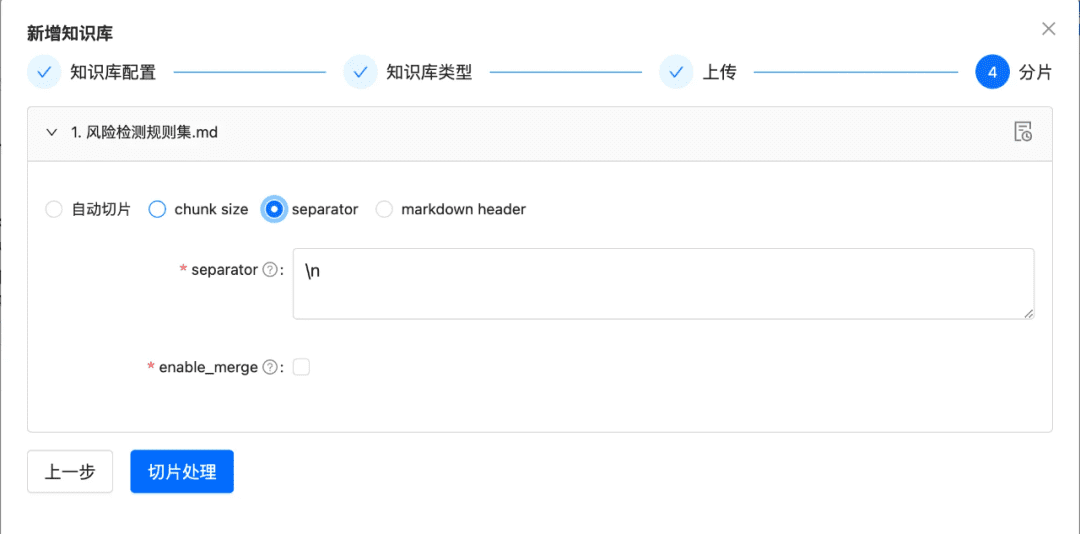
ChunkManager: encaminha os dados de conhecimento carregados para o processador de blocos correspondente para alocação com base na política de blocos especificada pelo usuário e nos parâmetros de blocos.
class ChunkManager: """Manager for chunks.""" def __init__( self, knowledge: Knowledge, chunk_parameter: Optional[ChunkParameters] = None, extractor: Optional[Extractor] = None, ): """ Create a new ChunkManager with the given knowledge. Args: knowledge: (Knowledge) Knowledge datasource. chunk_parameter: (Optional[ChunkParameters]) Chunk parameter. extractor: (Optional[Extractor]) Extractor to use for summarization. """ self._knowledge = knowledge self._extractor = extractor self._chunk_parameters = chunk_parameter or ChunkParameters() self._chunk_strategy = ( chunk_parameter.chunk_strategy if chunk_parameter and chunk_parameter.chunk_strategy else self._knowledge.default_chunk_strategy().name ) self._text_splitter = self._chunk_parameters.text_splitter self._splitter_type = self._chunk_parameters.splitter_type
Como estender: se você quiser personalizar uma nova estratégia de fatiamento na interface
- Nova estratégia de fatiamento
- Nova lógica de implementação do Splitter
class ChunkStrategy(Enum):
"""Chunk Strategy Enum."""
CHUNK_BY_SIZE: _STRATEGY_ENUM_TYPE = (
RecursiveCharacterTextSplitter,
[
{
"param_name": "chunk_size",
"param_type": "int",
"default_value": 512,
"description": "The size of the data chunks used in processing.",
},
{
"param_name": "chunk_overlap",
"param_type": "int",
"default_value": 50,
"description": "The amount of overlap between adjacent data chunks.",
},
],
"chunk size",
"split document by chunk size",
)
CHUNK_BY_PAGE: _STRATEGY_ENUM_TYPE = (
PageTextSplitter,
[],
"page",
"split document by page",
)
CHUNK_BY_PARAGRAPH: _STRATEGY_ENUM_TYPE = (
ParagraphTextSplitter,
[
{
"param_name": "separator",
"param_type": "string",
"default_value": "\n",
"description": "paragraph separator",
}
],
"paragraph",
"split document by paragraph",
)
CHUNK_BY_SEPARATOR: _STRATEGY_ENUM_TYPE = (
SeparatorTextSplitter,
[
{
"param_name": "separator",
"param_type": "string",
"default_value": "\n",
"description": "chunk separator",
},
{
"param_name": "enable_merge",
"param_type": "boolean",
"default_value": False,
"description": (
"Whether to merge according to the chunk_size after "
"splitting by the separator."
),
},
],
"separator",
"split document by separator",
)
CHUNK_BY_MARKDOWN_HEADER: _STRATEGY_ENUM_TYPE = (
MarkdownHeaderTextSplitter,
[],
"markdown header",
"split document by markdown header",
)
- Extração de conhecimento
- Extração de vetores -> incorporação, implementação
Embeddingsconector
@abstractmethod def embed_documents(self, texts: List[str]) -> List[List[float]]: """Embed search docs.""" @abstractmethod def embed_query(self, text: str) -> List[float]: """Embed query text.""" async def aembed_documents(self, texts: List[str]) -> List[List[float]]: """Asynchronous Embed search docs.""" return await asyncio.get_running_loop().run_in_executor( None, self.embed_documents, texts ) async def aembed_query(self, text: str) -> List[float]: """Asynchronous Embed query text.""" return await asyncio.get_running_loop().run_in_executor( None, self.embed_query, text )
# EMBEDDING_MODEL=proxy_openai
# proxy_openai_proxy_server_url=https://api.openai.com/v1
# proxy_openai_proxy_api_key={your-openai-sk}
# proxy_openai_proxy_backend=text-embedding-ada-002
## qwen embedding model, See dbgpt/model/parameter.py
# EMBEDDING_MODEL=proxy_tongyi
# proxy_tongyi_proxy_backend=text-embedding-v1
# proxy_tongyi_proxy_api_key={your-api-key}
## qianfan embedding model, See dbgpt/model/parameter.py
# EMBEDDING_MODEL=proxy_qianfan
# proxy_qianfan_proxy_backend=bge-large-zh
# proxy_qianfan_proxy_api_key={your-api-key}
# proxy_qianfan_proxy_api_secret={your-secret-key}
- Extração do gráfico de conhecimento -> gráfico de conhecimento
class TripletExtractor(LLMExtractor):
"""TripletExtractor class."""
def __init__(self, llm_client: LLMClient, model_name: str):
"""Initialize the TripletExtractor."""
super().__init__(llm_client, model_name, TRIPLET_EXTRACT_PT)
TRIPLET_EXTRACT_PT = (
"Some text is provided below. Given the text, "
"extract up to knowledge triplets as more as possible "
"in the form of (subject, predicate, object).\n"
"Avoid stopwords. The subject, predicate, object can not be none.\n"
"---------------------\n"
"Example:\n"
"Text: Alice is Bob's mother.\n"
"Triplets:\n(Alice, is mother of, Bob)\n"
"Text: Alice has 2 apples.\n"
"Triplets:\n(Alice, has 2, apple)\n"
"Text: Alice was given 1 apple by Bob.\n"
"Triplets:(Bob, gives 1 apple, Alice)\n"
"Text: Alice was pushed by Bob.\n"
"Triplets:(Bob, pushes, Alice)\n"
"Text: Bob's mother Alice has 2 apples.\n"
"Triplets:\n(Alice, is mother of, Bob)\n(Alice, has 2, apple)\n"
"Text: A Big monkey climbed up the tall fruit tree and picked 3 peaches.\n"
"Triplets:\n(monkey, climbed up, fruit tree)\n(monkey, picked 3, peach)\n"
"Text: Alice has 2 apples, she gives 1 to Bob.\n"
"Triplets:\n"
"(Alice, has 2, apple)\n(Alice, gives 1 apple, Bob)\n"
"Text: Philz is a coffee shop founded in Berkeley in 1982.\n"
"Triplets:\n"
"(Philz, is, coffee shop)\n(Philz, founded in, Berkeley)\n"
"(Philz, founded in, 1982)\n"
"---------------------\n"
"Text: {text}\n"
"Triplets:\n"
)
- Extração reversa de índices -> segmentação de palavras-chave
- Você pode usar o léxico padrão do es ou pode personalizar o léxico usando o modo de plug-in do es.
- Extração reversa de índices -> segmentação de palavras-chave
- Armazenamento de conhecimento
Toda a persistência do conhecimento é obtida de maneira uniformeIndexStoreBaseatualmente oferece três tipos de implementações: bancos de dados vetoriais, bancos de dados gráficos, indexação de texto completo

- VectorStore, a lógica principal do banco de dados vetorial está em load_document(), incluindo a criação do esquema de índice, gravação em lote de dados vetoriais e assim por diante.
# Base class hierarchy - VectorStoreBase - ChromaStore - MilvusStore - OceanbaseStore - ElasticsearchStore - PGVectorStore # Base class definition class VectorStoreBase(IndexStoreBase, ABC): """ Vector store base class. """ @abstractmethod def load_document(self, chunks: List[Chunk]) -> List[str]: """ Load document in index database. """ pass @abstractmethod async def aload_document(self, chunks: List[Chunk]) -> List[str]: """ Load document in index database asynchronously. """ pass @abstractmethod def similar_search_with_scores( self, text: str, topk: int, score_threshold: float, filters: Optional[MetadataFilters] = None, ) -> List[Chunk]: """ Perform a similar search with scores in the index database. """ pass def similar_search( self, text: str, topk: int, filters: Optional[MetadataFilters] = None, ) -> List[Chunk]: """ Perform a similar search in the index database. """ return self.similar_search_with_scores(text, topk, 1.0, filters)
- GraphStore , um armazenamento de gráficos concreto, fornece uma implementação de escrita ternária, que geralmente é feita chamando a linguagem de consulta de um banco de dados de gráficos concreto. Por exemplo
TuGraphStoreUma instrução Cypher específica será gerada e executada com base no ternário.
- A interface de armazenamento de gráficos GraphStoreBase fornece uma abstração unificada para o armazenamento de gráficos e atualmente possui
MemoryGraphStoreresponder cantandoTuGraphStoretambém fornecemos a interface do Neo4j aos desenvolvedores para acesso.
- A interface de armazenamento de gráficos GraphStoreBase fornece uma abstração unificada para o armazenamento de gráficos e atualmente possui
# GraphStoreBase -> TuGraphStore -> Neo4jStore
def insert_triplet(self, subj: str, rel: str, obj: str) -> None:
"""Add triplet."""
# Create queries to merge nodes and relationship
subj_query = f"MERGE (n1:{self._node_label} {{id:'{subj}'}})"
obj_query = f"MERGE (n2:{self._node_label} {{id:'{obj}'}})"
rel_query = (
f"MERGE (n1:{self._node_label} {{id:'{subj}'}})"
f"-[r:{self._edge_label} {{id:'{rel}'}}]->"
f"(n2:{self._node_label} {{id:'{obj}'}})"
)
# Execute queries
self.conn.run(query=subj_query)
self.conn.run(query=obj_query)
self.conn.run(query=rel_query)
- FullTextStore: construindo o índice do es, por meio do algoritmo interno de divisão de palavras do es para divisão de palavras e, em seguida, pelo es para construir o índice invertido keyword->doc_id.
{
"analysis": {
"analyzer": {
"default": {
"type": "standard"
}
}
},
"similarity": {
"custom_bm25": {
"type": "BM25",
"k1": self._k1,
"b": self._b
}
}
}
self._es_mappings = {
"properties": {
"content": {
"type": "text",
"similarity": "custom_bm25"
},
"metadata": {
"type": "keyword"
}
}
}
# FullTextStoreBase
# ElasticDocumentStore
# OpenSearchStore
2. recuperação de conhecimento
question -> rewrite -> similarity_search -> rerank -> context_candidates
A lógica atual de recuperação da comunidade é dividida principalmente nestas etapas: se você definir os parâmetros de reescrita da consulta, no momento, você terá uma rodada de reescrita da pergunta por meio do modelo grande e, em seguida, ela será encaminhada para o recuperador correspondente de acordo com sua forma de processamento de conhecimento; se você for processado por meio dos vetores, ela será recuperada por meio do EmbeddingRetriever; se você criar uma forma for construído por meio do gráfico de conhecimento, ele será recuperado de acordo com o modo do gráfico de conhecimento e, se você configurar o modelo de classificação, ele fornecerá aos valores candidatos, após a triagem grosseira, uma triagem fina para tornar os valores candidatos mais relevantes para a pergunta do usuário.
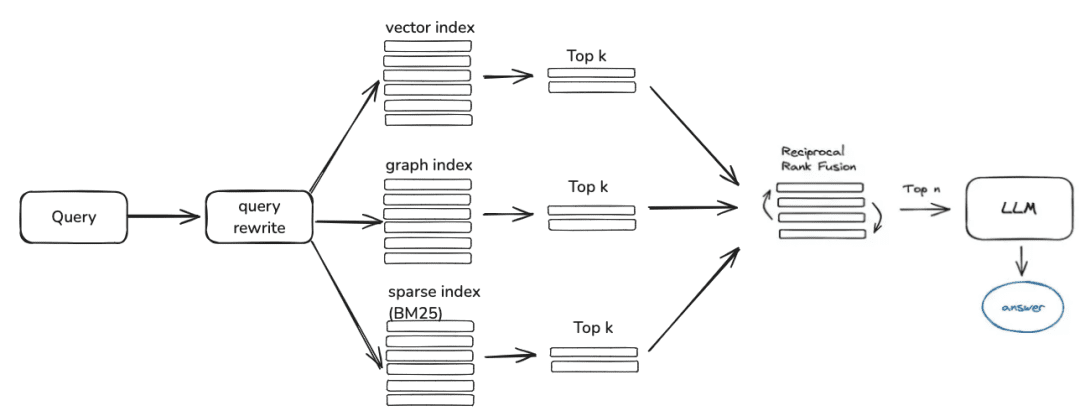
- EmbeddingRetriever
class EmbeddingRetriever(BaseRetriever): """Embedding retriever.""" def __init__( self, index_store: IndexStoreBase, top_k: int = 4, query_rewrite: Optional[QueryRewrite] = None, rerank: Optional[Ranker] = None, retrieve_strategy: Optional[RetrieverStrategy] = RetrieverStrategy.EMBEDDING, ): pass async def _aretrieve_with_score( self, query: str, score_threshold: float, filters: Optional[MetadataFilters] = None, ) -> List[Chunk]: """ Retrieve knowledge chunks with score. Args: query (str): Query text. score_threshold (float): Score threshold. filters: Metadata filters. Returns: List[Chunk]: List of chunks with score. """ queries = [query] new_queries = await self._query_rewrite.rewrite( origin_query=query, context=context, nums=1 ) queries.extend(new_queries) candidates_with_score = [ self._similarity_search_with_score( query, score_threshold, filters, root_tracer.get_current_span_id() ) for query in queries ] new_candidates_with_score = await self._rerank.arank( new_candidates_with_score, query ) return new_candidates_with_score
- index_store: banco de dados vetorial específico
- top_k: o número de blocos candidatos específicos retornados
- query_rewrite: função de reescrita de consulta
- rerank: função de reordenação
- consulta:consulta original
- score_threshold: pontuação; por padrão, filtramos os contextos com uma pontuação de similaridade menor que o limite
- filtros:
Optional[MetadataFilters]O filtro de informações de metadados pode ser usado principalmente para analisar as informações de atributos e filtrar algumas informações candidatas incompatíveis.
from enum import Enum from typing import Union, List from pydantic import BaseModel, Field class FilterCondition(str, Enum): """Vector Store Meta data filter conditions.""" AND = "and" OR = "or" class MetadataFilter(BaseModel): """Meta data filter.""" key: str = Field( ..., description="The key of metadata to filter." ) operator: FilterOperator = Field( default=FilterOperator.EQ, description="The operator of metadata filter." ) value: Union[str, int, float, List[str], List[int], List[float]] = Field( ..., description="The value of metadata to filter." )
- Gráfico RAG
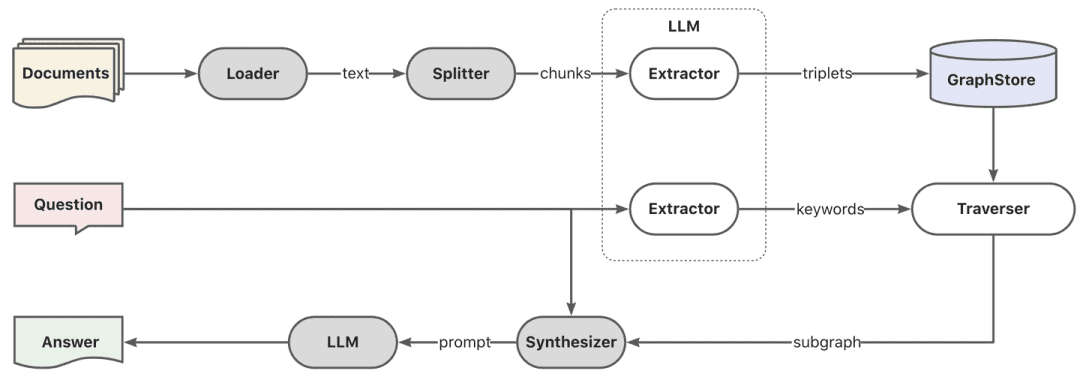
Em primeiro lugar, a extração de palavras-chave é realizada por meio do modelo, o que pode ser feito por meio da técnica tradicional de PNL para a divisão de palavras ou por meio do modelo grande para a divisão de palavras e, em seguida, as palavras-chave são feitas de acordo com os sinônimos para fazer a expansão, para encontrar a lista de palavras-chave candidatas, e é melhor chamar o método de exploração para recuperar os subgrafos locais de acordo com a lista de palavras-chave candidatas.
KEYWORD_EXTRACT_PT = (
"A question is provided below. Given the question, extract up to "
"keywords from the text. Focus on extracting the keywords that we can use "
"to best lookup answers to the question.\n"
"Generate as more as possible synonyms or alias of the keywords "
"considering possible cases of capitalization, pluralization, "
"common expressions, etc.\n"
"Avoid stopwords.\n"
"Provide the keywords and synonyms in comma-separated format."
"Formatted keywords and synonyms text should be separated by a semicolon.\n"
"---------------------\n"
"Example:\n"
"Text: Alice is Bob's mother.\n"
"Keywords:\nAlice,mother,Bob;mummy\n"
"Text: Philz is a coffee shop founded in Berkeley in 1982.\n"
"Keywords:\nPhilz,coffee shop,Berkeley,1982;coffee bar,coffee house\n"
"---------------------\n"
"Text: {text}\n"
"Keywords:\n"
)
def explore(
self,
subs: List[str],
direct: Direction = Direction.BOTH,
depth: Optional[int] = None,
fan: Optional[int] = None,
limit: Optional[int] = None,
) -> Graph:
"""Explore on graph."""
DBSchemaRetrieverEm parte, trata-se de uma pesquisa de vinculação de esquema para cenários de ChatDataPrincipalmente por meio do modo de vinculação de esquemas, por meio da recuperação de similaridade em dois estágios, primeiro encontre a tabela mais relevante e, em seguida, as informações de campo mais relevantes.
Prós: essa busca em dois estágios também tem o objetivo de atender aos comentários da comunidade sobre a experiência da mesa grande.
def _similarity_search(self, query, filters: Optional[MetadataFilters] = None) -> List[Chunk]:
"""Similar search."""
# Perform similarity search with scores
table_chunks = self._table_vector_store_connector.similar_search_with_scores(
query, self._top_k, 0, filters
)
# Filter out chunks with 'separated' metadata
not_sep_chunks = [
chunk for chunk in table_chunks if not chunk.metadata.get("separated")
]
separated_chunks = [
chunk for chunk in table_chunks if chunk.metadata.get("separated")
]
# If no separated chunks, return the non-separated chunks
if not separated_chunks:
return not_sep_chunks
# Create tasks list for retrieving fields from separated chunks
tasks = [
lambda c=chunk: self._retrieve_field(c, query) for chunk in separated_chunks
]
# Run tasks concurrently with a concurrency limit of 3
separated_result = run_tasks(tasks, concurrency_limit=3)
# Combine and return results
return not_sep_chunks + separated_result
- table_vector_store_connector: responsável por recuperar a tabela mais relevante.
- field_vector_store_connector: responsável por recuperar os campos mais relevantes.
2. processamento de conhecimento, ideias de otimização de recuperação de conhecimento
Atualmente, os aplicativos de questionário inteligente RAG têm vários pontos problemáticos:
- Após a inclusão de mais e mais documentos na base de conhecimento, a pesquisa fica ruidosa e a precisão da recuperação não é alta
- Recalls incompletos e falta de completude
- Os recalls e a intenção de perguntas do usuário têm pouca relevância
- O fato de só poder responder a dados estáticos e não poder acessar o conhecimento de forma dinâmica leva a um aplicativo de resposta monótono e sem graça.
1. Otimização do processamento de conhecimento
O processamento de dados não estruturados/semiestruturados/estruturados está pronto para determinar o limite superior do aplicativo RAG, portanto, antes de tudo, é necessário fazer muito trabalho de ETL refinado no processamento do conhecimento, no estágio de indexação e na otimização principal da direção da ideia:
- Não estruturado -> Estruturado: organização de informações de conhecimento de forma estruturada.
- Extrair informações semânticas mais ricas e diversificadas.
1.1 Carregamento de conhecimento
Objetivo: A análise precisa de documentos é necessária para identificar diferentes tipos de dados de forma mais diversificada.
Recomendações de otimização:
- Recomenda-se que docx, txt ou outro texto seja processado antes do formato pdf ou markdown, para que você possa usar algumas ferramentas de reconhecimento para extrair melhor o conteúdo do texto.
- Extrai informações de tabela do texto.
- Preservar as informações de hierarquia de títulos de PDF e markdown para a próxima árvore de relacionamento hierárquico e outros métodos de indexação a serem preparados.
- Retenha links de imagens, fórmulas e outras informações, também processadas de maneira uniforme no formato markdown.
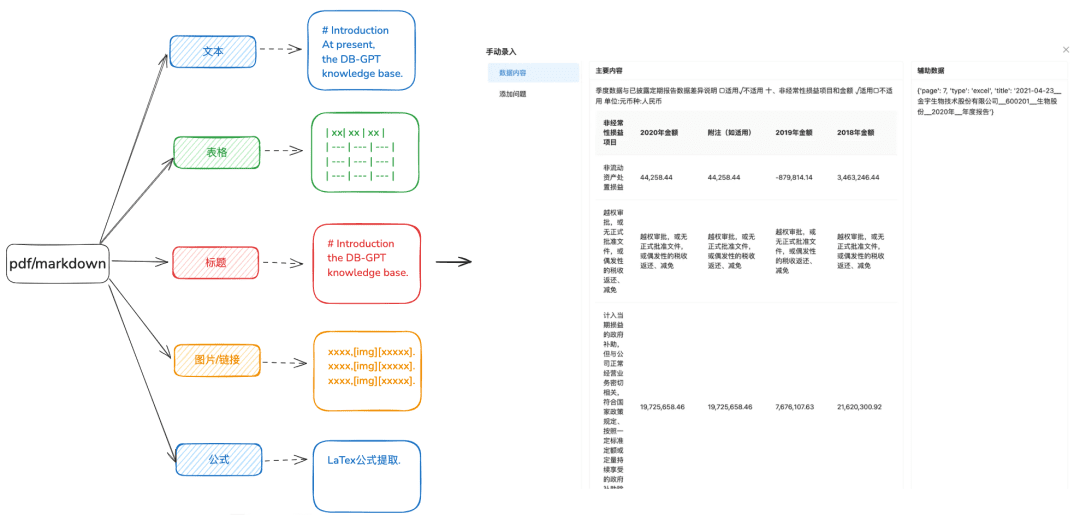
1.2 Fatie o pedaço o mais intacto possível
Objetivo: preservar a integridade e a relevância do contexto, o que está diretamente relacionado à precisão da resposta.
Mantendo-se dentro dos limites contextuais do modelo maior, o chunking garante que a entrada de texto nos LLMs não exceda seus limites de tokens.
Recomendações de otimização:
- Imagens + tabelas extraídas como blocos separados, mantendo as legendas das tabelas e das imagens nos metadados
- O conteúdo do documento é dividido o máximo possível de acordo com a hierarquia de cabeçalhos ou com o Markdown Header, preservando a integridade do bloco o máximo possível.
- Se houver um separador personalizado, você poderá cortar e dividir pelo separador personalizado.
1.3 Extração de informações diversificadas
Além da extração do vetor de incorporação de documentos, outras extrações de informações diversificadas podem aprimorar os dados dos documentos e melhorar significativamente o efeito de recuperação do RAG.
- mapa de conhecimento
- Vantagens: 1. Ao lidar com a falta de integridade do NativeRAG, ainda há o problema da ilusão, e a precisão do conhecimento, incluindo a integridade dos limites do conhecimento, a clareza da estrutura e da semântica do conhecimento, é um complemento semântico para a capacidade de recuperação de similaridade.
- Cenários: para domínios profissionais rigorosos (saúde, O&M etc.) em que a preparação do conhecimento precisa ser limitada e em que as relações hierárquicas entre os conhecimentos podem ser claramente estabelecidas.
- Como conseguir:
1) Depender do grande modelo para extrair o relacionamento ternário (entidade, relacionamento, entidade).
2) Confiar na preparação, limpeza e extração de conhecimento estruturado e de pré-qualidade por meio de regras de negócios por meio de um processo SOP manual ou personalizado para criar o gráfico de conhecimento.
- Árvore de Doces
- Cenários aplicáveis: resolve o problema de integridade contextual insuficiente, mas também faz correspondências com base apenas em semântica e palavras-chave, e pode reduzir o ruído
- Como fazer: construir um nó de árvore de pedaços no nível do título para formar uma estrutura de árvore multinomial, em que cada nó de nível só precisa armazenar o título do documento e os nós de folha armazenam o conteúdo de texto específico. Dessa forma, usando o algoritmo de passagem de árvore, se uma pergunta do usuário atingir um nó de título não-folha relevante, os dados do nó filho relevante poderão ser recuperados. Dessa forma, não há problema de deficiência na integridade dos blocos.
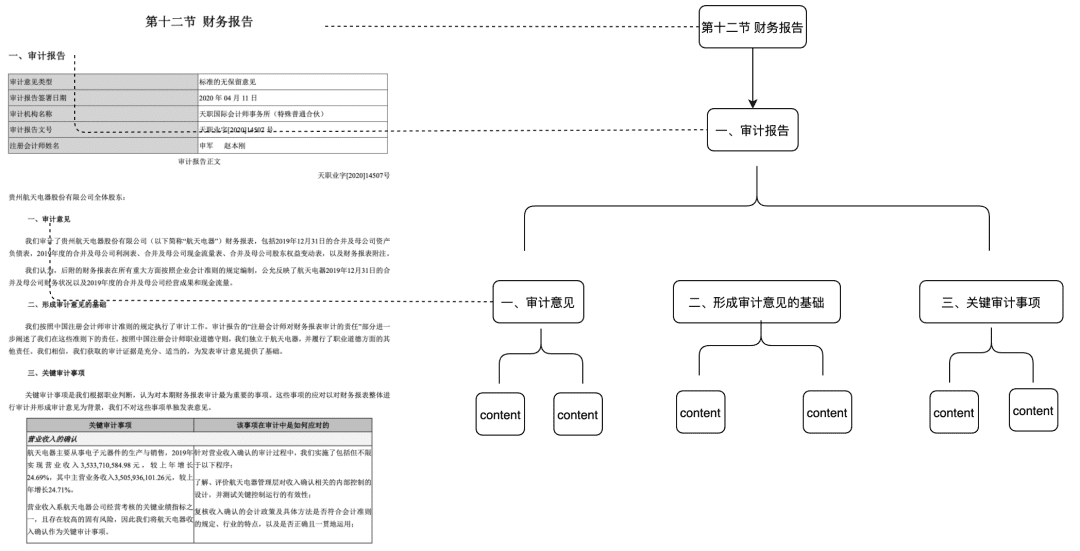
Essa parte do recurso também será colocada na comunidade no início do próximo ano.
- A extração de pares de controle de qualidade requer a extração de front-end de informações de pares de controle de qualidade por métodos de extração predefinidos ou de modelo
- Cenários aplicáveis:
- A capacidade de acertar a pergunta na recuperação e na recuperação direta, recuperar diretamente a resposta que o usuário deseja, aplicável a alguns cenários de perguntas frequentes, a integridade da recuperação não é suficiente.
- Como conseguir:
- Predefinido: adicione algumas perguntas para cada bloco com antecedência.
- Extração de modelo: dado um contexto, deixe o modelo realizar a extração de pares de QA.
- Extração de metadados
- Como fazer: de acordo com as características de seus próprios dados comerciais, extraia as características dos dados para retenção, como tags, categorias, tempo, versão e outros atributos de metadados.
- Cenários aplicáveis: a recuperação pode ser pré-filtrada com base em atributos de metadados para filtrar a maior parte do ruído.
- Resumir e extrair
- Cenários aplicáveis: resolução
这篇文章讲了个啥(matemática) gênero总结一下e outros cenários de problemas globais. - Como implementar: extração segmentada por meio de mapreduce etc., extraindo informações resumidas para cada parte por meio de um modelo.
- Cenários aplicáveis: resolução
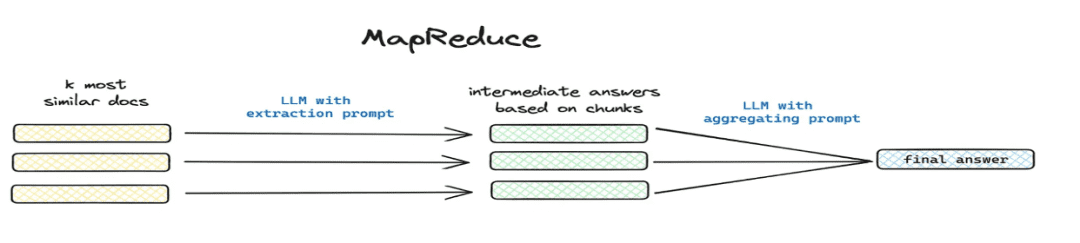
1.4 Fluxo de trabalho de processamento de conhecimento
no momento atual DB-GPT A base de conhecimento oferece recursos de processamento de conhecimento, como upload de documentos -> análise -> fatiamento -> incorporação -> extração de tríade de gráfico de conhecimento -> armazenamento de banco de dados vetorial -> armazenamento de banco de dados gráfico etc., mas não tem a capacidade de extrair informações complexas e personalizadas de documentos, portanto, espera-se que a construção de um modelo de fluxo de trabalho de processamento de conhecimento conclua os processos de extração, transformação e processamento de conhecimento complexos, visuais e definidos pelo usuário. Portanto, esperamos criar um modelo de fluxo de trabalho de processamento de conhecimento para concluir o processo de extração, conversão e processamento de conhecimento complexo, visual e definido pelo usuário.
Fluxo de trabalho de processamento de conhecimento:
https://www.yuque.com/eosphoros/dbgpt-docs/vg2gsfyf3x9fuglf
2. otimização do processo de RAG A otimização do processo de RAG é subdividida em RAG de documentos estáticos e RAG de aquisição de dados dinâmicos. A maior parte do RAG atual envolve apenas os ativos estáticos de documentos não estruturados, mas o negócio real de muitos cenários de P&R é por meio da ferramenta para obter dados dinâmicos + dados de conhecimento estático juntos para responder ao cenário, não apenas a necessidade de recuperar o conhecimento estático, mas também a necessidade de ser RAG Além de recuperar o conhecimento estático, o RAG também precisa recuperar as informações das ferramentas dentro da biblioteca de ativos da ferramenta e executar a aquisição de dados dinâmicos.
2.1 Otimização do RAG de conhecimento estático
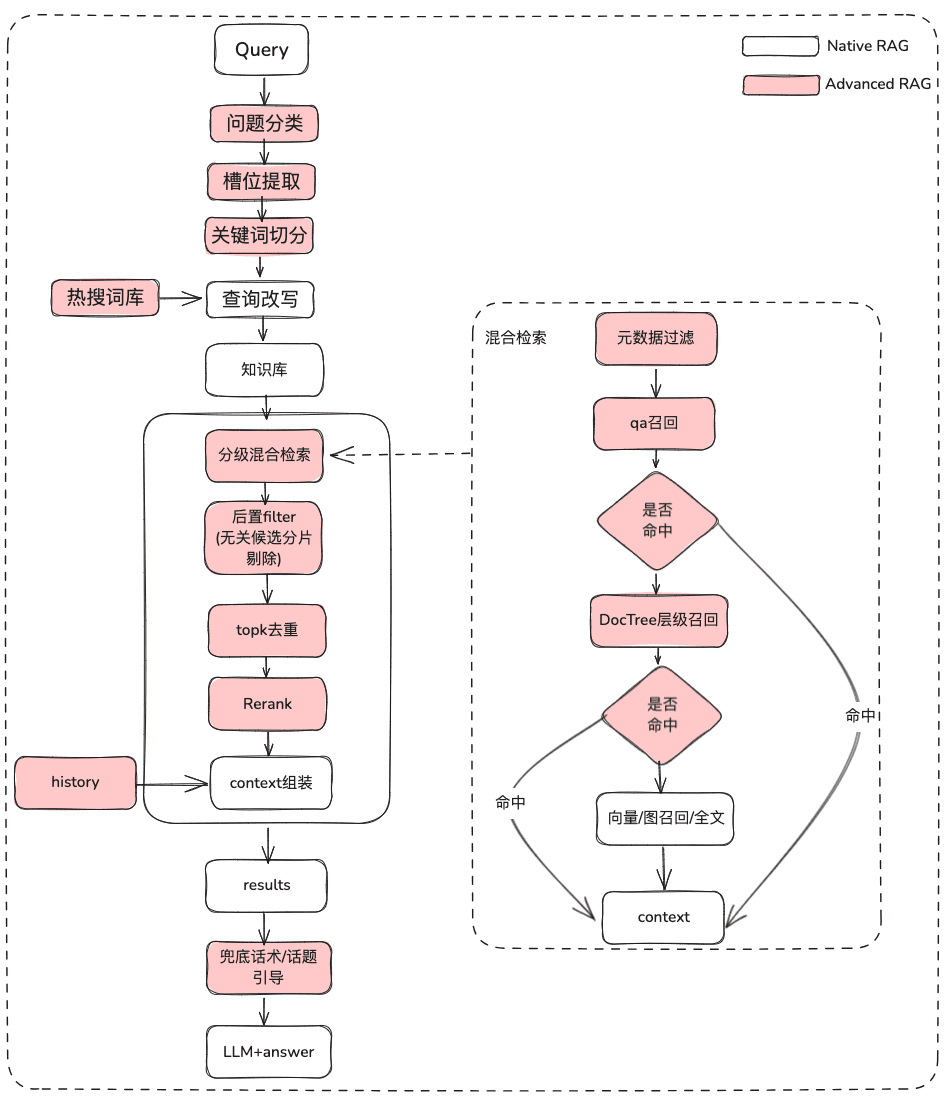
(1) Tratamento do problema original
Objetivo: Esclarecer a semântica do usuário e otimizar a pergunta original do usuário de uma consulta difusa e mal definida para uma consulta recuperável que seja mais rica em significado.
- Classificação de problemas brutos, por meio da qual os problemas podem ser
- Classificação do LLM (
LLMExtractor) - Criação de incorporação + regressão logística para implementar um modelo de duas torres, text2nlu DB-GPT-Hub/src/dbgpt-hub-nlu/README.zh.md at main - eosphoros-ai/DB-GPT-Hub
- Classificação do LLM (
- Dica: se você precisar de um modelo de incorporação de alta qualidade, recomende o bge-v1.5-large
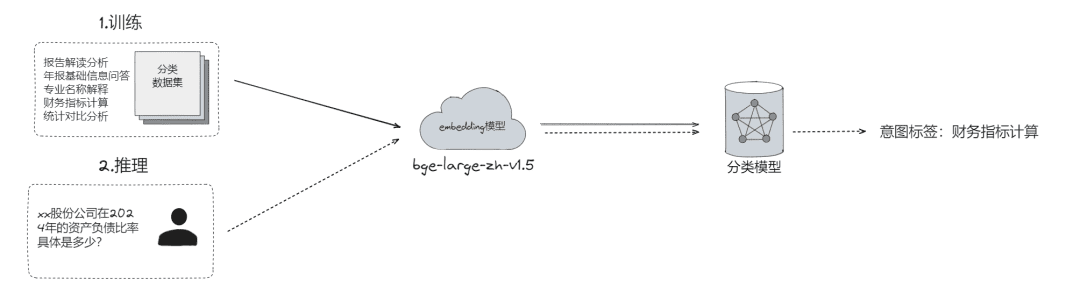
- Pergunte de volta ao usuário e, se a semântica não estiver clara, envie a pergunta de volta ao usuário para esclarecimento, por meio de várias rodadas de interação
- Sugere uma lista de perguntas para o usuário com base na relevância semântica usando um dicionário de sinônimos pesquisável.
- Extração de slots, que visa obter as principais informações de slots na pergunta do usuário, como intenção, atributos comerciais, etc.
- Extração do LLM (
LLMExtractor)
- Extração do LLM (
- Reescreva a pergunta
- Reescrevendo o Hot Search Thesaurus
- interação em várias camadas
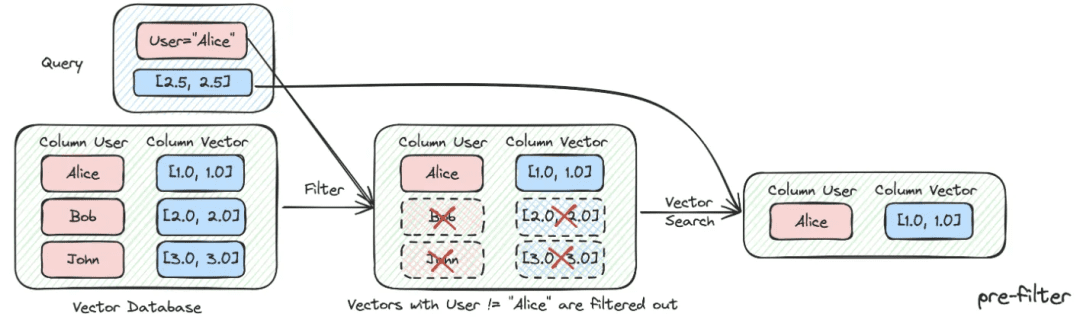
(2) Filtragem de metadados
Quando dividimos o índice em muitos blocos e eles são armazenados no mesmo espaço de conhecimento, a eficiência da recuperação se torna um problema. Por exemplo, quando os usuários solicitam informações sobre a "Zhejiang I Wu Technology Company", eles não querem recuperar informações sobre outras empresas. Portanto, se você puder filtrar primeiro pelo atributo de metadados do nome da empresa, isso aumentará muito a eficiência e a relevância.
async def aretrieve( self, query: str, filters: Optional[MetadataFilters] = None ) -> List[Chunk]: """ Retrieve knowledge chunks. Args: query (str): async query text. filters (Optional[MetadataFilters]): metadata filters. Returns: List[Chunk]: list of chunks """ return await self._aretrieve(query, filters)
(3) Recuperação híbrida de múltiplas estratégias
- Definir prioridades para diferentes recuperadores, de acordo com a prioridade de recuperação, e retornar o conteúdo assim que ele for recuperado
- Defina diferentes recuperações, como qa_retriever, doc_tree_retriever, a serem gravadas na fila e obtenha recuperação prioritária por meio da propriedade first-in-first-out da fila.
class RetrieverChain(BaseRetriever): """Retriever chain class.""" def __init__( self, retrievers: Optional[List[BaseRetriever]] = None, executor: Optional[Executor] = None, ): """Create retriever chain instance.""" self._retrievers = retrievers or [] self._executor = executor or ThreadPoolExecutor() async def retrieve(self, query: str, score_threshold: float, filters: Optional[dict] = None): """Perform retrieval with the given query, score threshold, and filters.""" for retriever in self._retrievers: candidates_with_scores = await retriever.aretrieve_with_scores( query=query, score_threshold=score_threshold, filters=filters ) if candidates_with_scores: return candidates_with_scores
- Indexação de múltiplos conhecimentos/recuperação paralela espacial
- Obtenção de listas de candidatos por meio de recuperação paralela através de diferentes formas de indexação de conhecimento para garantir a integridade da recuperação
(4) Pós-filtragem
Depois de passar pela lista de candidatos da triagem grosseira, como você filtra o ruído por meio da triagem fina?
- Eliminação de fatias de candidatos irrelevantes
- Rejeição de pontualidade
- Os atributos de negócios não satisfazem a seleção
- desduplicação de topk
- Reordenação Não basta confiar na recuperação da triagem grosseira; nesse momento, precisamos ter algumas estratégias para reordenar os resultados recuperados, por exemplo, reajustar alguns fatores, como combinação, relevância, correspondência etc., para obter uma ordenação mais alinhada com nossos cenários de negócios. Como após essa etapa, enviaremos os resultados ao LLM para o processamento final, os resultados dessa parte são muito importantes.
- Triagem fina usando modelos de reordenação relevantes, modelos de código aberto ou modelos com ajuste fino de semântica comercial.
## Rerank model # RERANK_MODEL = bce-reranker-base #### If you do not set RERANK_MODEL_PATH, DB-GPT will read the model path from EMBEDDING_MODEL_CONFIG based on the RERANK_MODEL. # RERANK_MODEL_PATH = /Users/chenketing/Desktop/project/DB-GPT-NEW/DB-GPT/models/bce-reranker-base_v1 #### The number of rerank results to return # RERANK_TOP_K = 5
- Seleção de pontuação composta ponderada por RRF de negócios com base em diferentes recalls indexados
score = 0.0 for q in queries: if d in result(q): score += 1.0 / (k + rank(result(q), d)) return score # where: # k is a ranking constant # q is a query in the set of queries # d is a document in the result set of q # result(q) is the result set of q # rank(result(q), d) is d's rank within the result(q) starting from 1
(5) Otimização de exibição + Touting / Liderança de tópico
- Obter a saída do modelo usando a formatação markdown
基于以下给出的已知信息,遵守规范约束,专业、简要回答用户的问题。 规范约束: 1. 如果已知信息包含的图片、链接、表格、代码块等特殊 markdown 标签格式的信息,确保在答案中包含原文这些图片、链接、表格和代码标签,不要丢弃不要修改,例如: - 图片格式:`` - 链接格式:`[xxx](xxx)` - 表格格式:`|xxx|xxx|xxx|` - 代码格式:```xxx```。 2. 如果无法从提供的内容中获取答案,请说:“知识库中提供的内容不足以回答此问题”,禁止胡乱编造。 3. 回答的时候最好按照 1.2.3. 点进行总结,并以 Markdown 格式显示。
2.2 Otimização do RAG de conhecimento dinâmico
O conhecimento da documentação é relativamente estático, não pode responder a informações personalizadas e dinâmicas, precisa contar com algumas ferramentas de plataformas de terceiros para responder. Com base nessa situação, precisamos de uma abordagem RAG dinâmica, por meio da definição de ativos de ferramentas -> seleção de ferramentas -> validação de ferramentas -> execução de ferramentas para obter dados dinâmicos.
(1) Biblioteca de ativos de ferramentas
Crie uma biblioteca de ativos de ferramentas de domínio corporativo para integrar APIs de ferramentas, scripts de ferramentas espalhados por várias plataformas e, assim, fornecer recursos de uso de ponta a ponta para inteligências. Por exemplo, além da base de conhecimento estática, podemos processar ferramentas importando bibliotecas de ferramentas.

(2) Recall de ferramentas
A recuperação de ferramentas segue a ideia da recuperação RAG para conhecimento estático e, em seguida, o ciclo de vida completo da execução da ferramenta é usado para obter os resultados da execução da ferramenta.
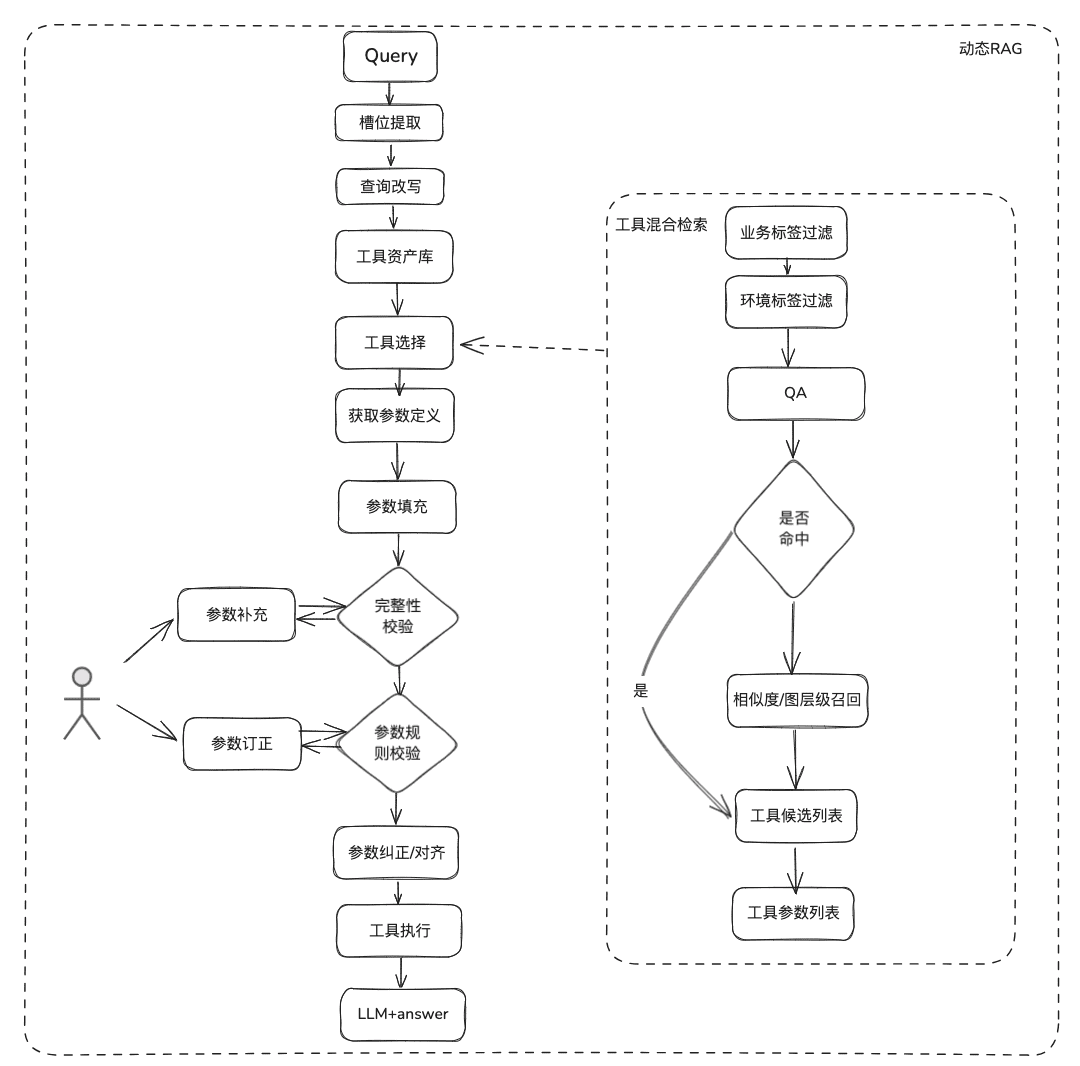
- Extração de slots: obtenha LLM por meio de nlp tradicional para analisar o problema do usuário, incluindo tipos de negócios comuns, marcadores de ambiente, parâmetros de modelo de domínio, etc.
- Seleção de ferramentas: chamada de acordo com as linhas do RAG estático com duas camadas principais, chamada do nome da ferramenta e chamada do parâmetro da ferramenta.
- O Tool Parameter Recall, cuja ideia é semelhante à do TableRAG, recupera primeiro o nome da tabela e depois o nome do campo.
- Preenchimento de parâmetros: é necessário fazer a correspondência dos parâmetros extraídos dos slots de acordo com as definições dos parâmetros da ferramenta dos recalls
- Você pode codificar para preenchê-lo ou pode fazer com que o modelo o preencha.
- Ideias de otimização: como os nomes dos mesmos parâmetros das várias ferramentas da plataforma não são unificados e não é conveniente ir até a governança, sugere-se que primeiro seja realizada uma rodada de expansão dos dados do modelo de domínio e, depois de obter todo o modelo de domínio, os parâmetros necessários estarão presentes.
- calibração de parâmetros
- Verificação de integridade: realiza a verificação de integridade no número de parâmetros
- Verificação de regras de parâmetros: executa a verificação de regras no tipo de nome de parâmetro, valor de parâmetro, enumeração etc.
- Correção/alinhamento de parâmetros: essa parte tem como objetivo principal reduzir o número de interações com o usuário, a conclusão automatizada da correção de erros de parâmetros do usuário, incluindo regras de caso, regras de enumeração etc., por exemplo.
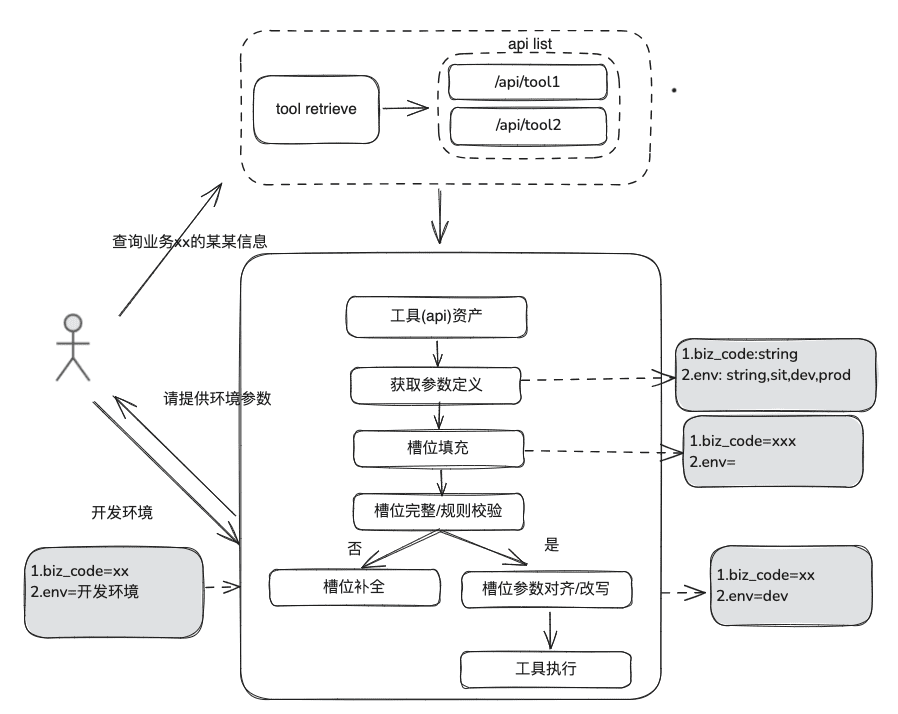
2.3 Revisão do RAG
Ao avaliar o processo de Q&A inteligente, a precisão da relevância da recordação e a relevância do modelo de Q&A precisam ser avaliadas separadamente e, em seguida, consideradas em conjunto para determinar onde o processo de RAG ainda precisa ser aprimorado.
Avaliação de indicadores:
EvaluationMetric ├── LLMEvaluationMetric │ ├── AnswerRelevancyMetric ├── RetrieverEvaluationMetric │ ├── RetrieverSimilarityMetric │ ├── RetrieverMRRMetric │ └── RetrieverHitRateMetric
RAGRetrieverEvaluationMetric:RetrieverHitRateMetric:: A taxa de acerto mede o RAGretrieverA proporção de recalls que aparecem nos principais documentos dos resultados de recuperação.RetrieverMRRMetric:Mean Reciprocal RankA precisão de cada consulta é calculada analisando a classificação dos documentos mais relevantes nos resultados da pesquisa. Mais especificamente, é a média da classificação inversa dos documentos relevantes para todas as consultas. Por exemplo, se o documento mais relevante for classificado em primeiro lugar, sua classificação inversa será 1; se for classificado em segundo lugar, será 1/2; e assim por diante.RetrieverSimilarityMetricMétricas de similaridade: as métricas de similaridade são calculadas para calcular a similaridade entre o conteúdo recuperado e o conteúdo previsto.
模型生成Indicador de resposta.
AnswerRelevancyMetric: métrica de relevância da resposta do corpo inteligente, que mede a correspondência da resposta do corpo inteligente com a pergunta do usuário. Uma resposta de alta relevância não só exige que o modelo compreenda a pergunta do usuário, mas também que ele gere uma resposta que esteja intimamente relacionada à pergunta. Isso afeta diretamente a satisfação do usuário e a utilidade do modelo.
3.Compartilhamento de casos de aterrissagem RAG
1. RAG na área de infraestrutura de dados
1.1 Histórico do órgão de inteligência de O&M
No espaço da infraestrutura de dados, há muitos SREs de operações que recebem um grande número de alertas todos os dias, portanto, muito tempo é gasto respondendo a emergências, o que, por sua vez, leva à solução de problemas e, em seguida, à revisão da solução de problemas, o que, por sua vez, leva à experiência. Outra parte do tempo é gasta respondendo a consultas de usuários, exigindo que eles respondam a perguntas com seu conhecimento e experiência de uso das ferramentas.
Portanto, esperamos resolver esses problemas de diagnóstico de alarme e resposta a perguntas criando uma inteligência geral para a infraestrutura de dados.
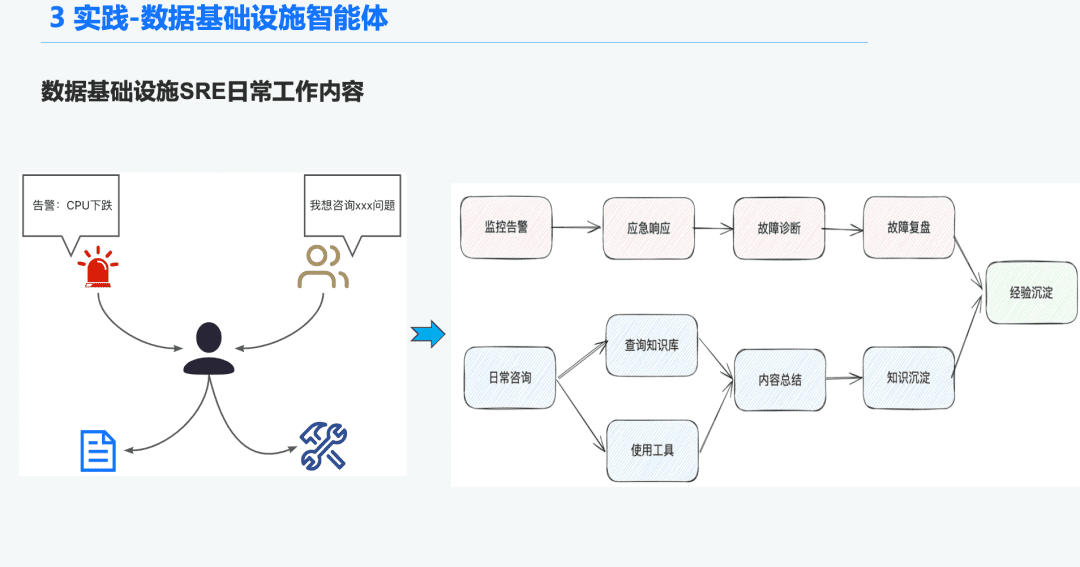
1.2 RAG rigoroso e profissional
A tecnologia tradicional RAG + Agent pode resolver cenários de tarefas de uma única etapa, de uso geral e menos determinísticos. No entanto, ao enfrentar cenários profissionais no campo da infraestrutura de dados, todo o processo de recuperação deve ser determinístico, profissional e realista, e requer um raciocínio passo a passo.
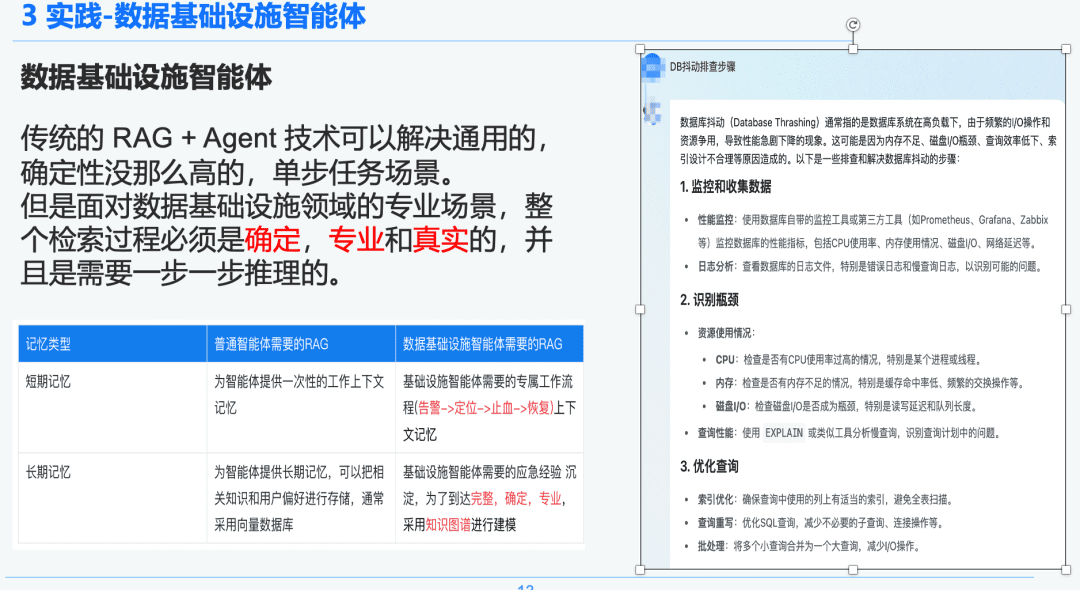
À direita, há um resumo generalizado por meio do NativeRAG, que pode ser uma informação útil para um usuário C-suite que não tenha muito conhecimento do domínio e, para um profissional, essa parte da resposta não fará muito sentido.
Portanto, comparamos a diferença entre as inteligências genéricas e as inteligências de infraestrutura de dados em relação ao RAG:
- Inteligências de uso geral: os RAGs tradicionais não exigem tanto rigor intelectual e conhecimento especializado e são adequados para alguns cenários de negócios, como atendimento ao cliente, turismo e bots de plataforma de perguntas e respostas.
- Corpo de inteligência da infraestrutura de dados: o processo RAG é rigoroso e profissional, exigindo fluxos de trabalho RAG exclusivos com contextos que incluem (Alerta -> Localizar -> Parar o sangramento -> Recuperar) e extração estruturada de perguntas e respostas e experiência de resposta a emergências precipitada por especialistas para estabelecer relações hierárquicas. Por isso, escolhemos o Knowledge Graph como portador de dados.
1.3 Processamento de conhecimento
Com base no determinismo e na especificidade da infraestrutura de dados, optamos por usá-la como portadora de conhecimento para diagnosticar experiências de resposta a emergências por meio da combinação de gráficos de conhecimento. Nossa experiência de conhecimento de eventos de solução de problemas de emergência precipitados pelo SRE Combinado com o processo de revisão de emergência, estabelecemos um gráfico de conhecimento orientado por eventos de emergência de BD, tomamos o jitter do BD como exemplo, vários eventos que afetam o jitter do BD, incluindo problemas de SQL lento, problemas de capacidade, estabelecemos relações entre cada evento de emergência.
Por fim, estabelecemos um sistema de processamento de conhecimento padronizado de conhecimento de várias fontes -> extração estruturada de conhecimento -> extração de relacionamento de emergência -> revisão especializada -> armazenamento de conhecimento, passo a passo, normalizando as regras de eventos de emergência.

1.4 Recuperação de conhecimento
Na fase de recuperação inteligente de corpos, usamos o GraphRAG como portador da recuperação de conhecimento estático; portanto, depois de identificar a anomalia de jitter do BD, encontramos os nós relacionados ao nó de anomalia de jitter do BD como base de nossa análise, pois cada nó também retém algumas informações de metadados para cada evento na fase de extração de conhecimento, incluindo o nome do evento, a descrição do evento, as ferramentas relacionadas, os parâmetros da ferramenta e assim por diante.
Portanto, podemos obter os resultados de retorno por meio do link do ciclo de vida da execução da ferramenta de execução para obter os dados dinâmicos a serem usados como base do diagnóstico de emergência para solução de problemas. Por meio dessa abordagem de recall híbrido dinâmico e estático, a certeza, o profissionalismo e o rigor da execução das inteligências de infraestrutura de dados são garantidos em comparação com o recall RAG puro e simples.
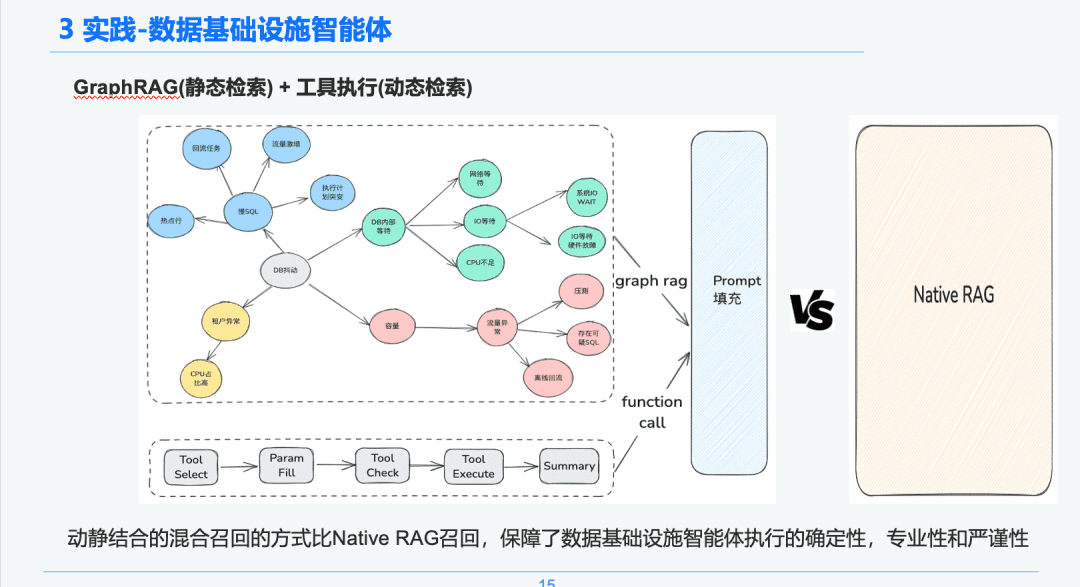
1,5 AWEL + Agente
Por fim, por meio da tecnologia comunitária AWEL+AGENT, o paradigma da orquestração AGENT foi usado para criar um especialista de intenção -> especialista em diagnóstico de emergência -> especialista em análise de causa raiz do diagnóstico.
Cada agente tem uma função diferente. O especialista em intenção é responsável por identificar e analisar a intenção do usuário e identificar mensagens de alerta. O especialista em diagnóstico precisa localizar o nó de causa raiz a ser analisado por meio do GraphRAG e obter informações específicas sobre a causa raiz. O especialista em análise precisa combinar os dados de cada nó de causa raiz + relatório de revisão de análise histórica para gerar um relatório de análise de diagnóstico.
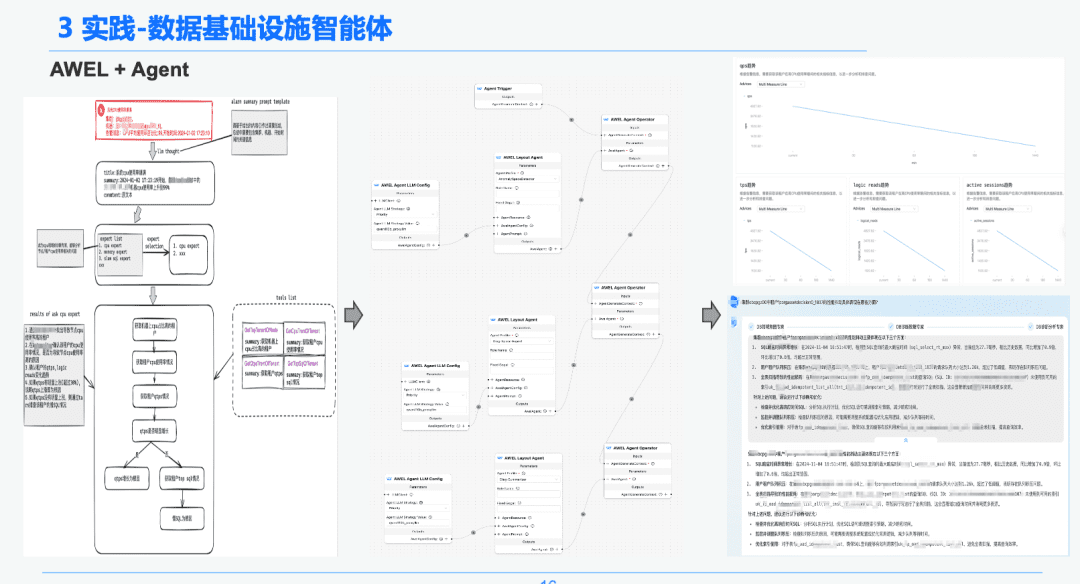
2. RAG na área de análise de relatórios financeiros
Última prática! Como criar um assistente de análise de relatórios financeiros com base no DB-GPT?
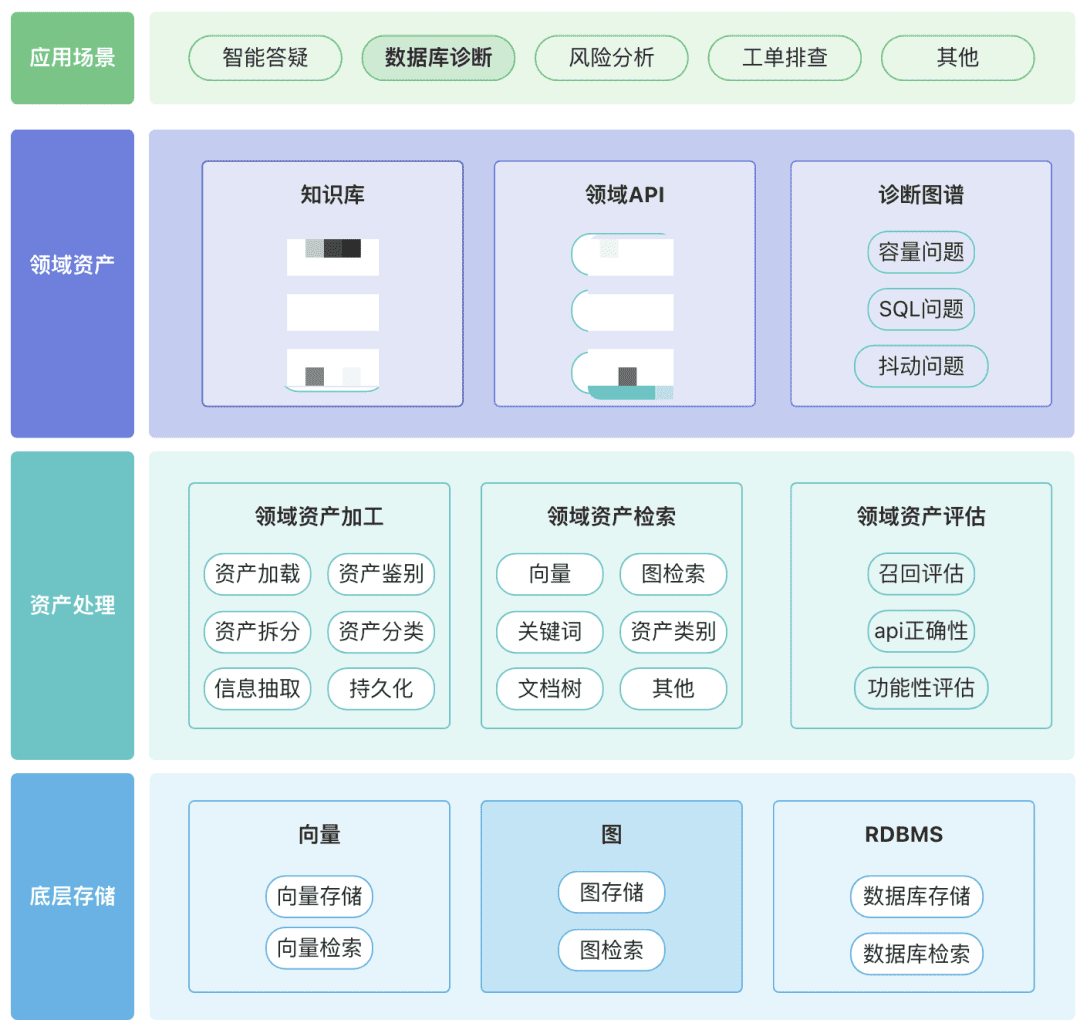
Você pode criar seu próprio repositório de ativos de domínio, incluindo ativos de conhecimento, ativos de ferramentas e ativos de gráficos de conhecimento sobre seu domínio.
- Ativos de domínio: os ativos de domínio incluem bases de conhecimento, APIs e scripts de ferramentas.
- Processamento de ativos, todo o link de dados de ativos envolve o processamento de ativos de domínio, a recuperação de ativos de domínio e a avaliação de ativos de domínio.
- Não estruturado -> Estruturado: categorizado de forma estruturada, informações de conhecimento corretamente organizadas.
- Extrair informações semânticas mais ricas.
- Recuperação de ativos:
- Esperamos que seja uma pesquisa em cascata e priorizada, em vez de uma única pesquisa
- A pós-filtragem é importante, de preferência por meio da semântica comercial de algumas regras.
© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Artigos relacionados




Nenhum comentário...