
Implementação local do Vanna: conversões Text2SQL eficientes com facilidade

O Vanna é uma estrutura de código aberto Text2SQL altamente conceituada que transforma a linguagem natural em instruções de consulta SQL. Este artigo detalha como implantar o Vanna localmente e combiná-lo com um banco de dados MySQL e com o aplicativo Deepseek Os modelos são configurados e testados para ajudá-lo a começar a usar a ferramenta rapidamente. Todas as operações são baseadas em testes reais para garantir que as etapas sejam claras e viáveis.
Configuração do ambiente Python
Para executar o Vanna, primeiro você precisa de um ambiente Python estável. Aqui está um guia passo a passo para configurar o Vanna, usando o Miniconda3 como exemplo.
Instalação do Miniconda3
- Faça o download do pacote de instalação:
wget https://repo.continuum.io/miniconda/Miniconda3-latest-Linux-x86_64.sh - Execute o script de instalação:
sh Miniconda3-latest-Linux-x86_64.sh - Configurar variáveis de ambiente:
vim /etc/profileAdicione-o ao arquivo:
export PATH="/data/apps/miniconda3/bin:$PATH"Salve e atualize a configuração:
source /etc/profile - Se você precisar desinstalar, basta excluir o diretório de instalação:
rm -rf /data/apps/miniconda3/
Criação de um ambiente virtual
- Crie um ambiente Python 3.10:
conda create -n test python=3.10 - Ativar o ambiente (precisa entrar em vigor em um novo terminal ou após uma reinicialização):
conda activate test - Outros comandos comuns:
- Ambiente de saída:
conda deactivate - Exibir informações ambientais:
conda info --env
- Ambiente de saída:
Depois de concluir as etapas acima, você terá um ambiente virtual autônomo do Python que estabelece as bases para a implementação do Vanna.
Implementação e configuração do Vanna
Com o ambiente Python pronto, vamos passar para a configuração principal do Vanna. As operações a seguir referem-se à documentação oficial (https://vanna.ai/docs/) e usam o banco de dados MySQL como exemplo.
Configuração da conexão com o banco de dados
Primeiro, certifique-se de que você pode fazer login no banco de dados corretamente com sua conta, senha e porta do MySQL. Depois de testar uma conexão bem-sucedida, abra a página de configuração do MySQL na documentação oficial do Vanna (selecione MySQL na barra de menu à esquerda). A página mostrará um exemplo de código de conexão, como mostrado abaixo:
Com base nas informações do seu banco de dados, ajuste os parâmetros no código (por exemplo, host, usuário, senha etc.) para garantir que o Vanna se conecte sem problemas.
Escolha de um modelo de idioma
O Vanna oferece suporte a uma variedade de modelos de linguagem grande (LLMs). A página oficial solicita a seleção do modelo, por exemplo Ollama ou chamadas de API. O modelo Deepseek para fluxos baseados em silício é ilustrado aqui como um exemplo.
- Experiência OllamaTentativas de implementar o modelo Deepseek-7b quantificado foram feitas com resultados ruins e recomenda-se que essa opção seja ignorada.
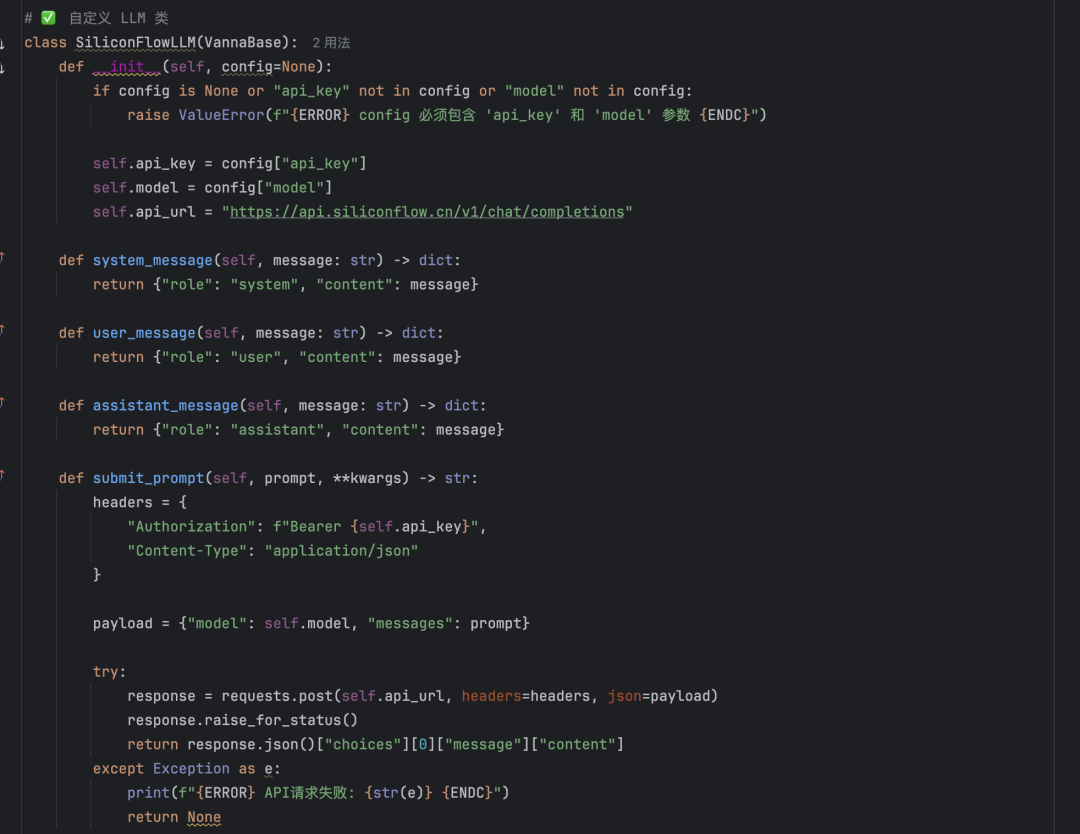
- API do DeepseekChamada de modelos do Deepseek por meio de fluxos in silico tem melhor desempenho. Observe, no entanto, que as classes LLM personalizadas são necessárias para usar modelos que não são oficialmente suportados. Consulte o site do projeto de código aberto Vanna Mistral (mistral.py), crie uma classe adaptada ao Deepseek de acordo.
A tela de configuração é a seguinte:
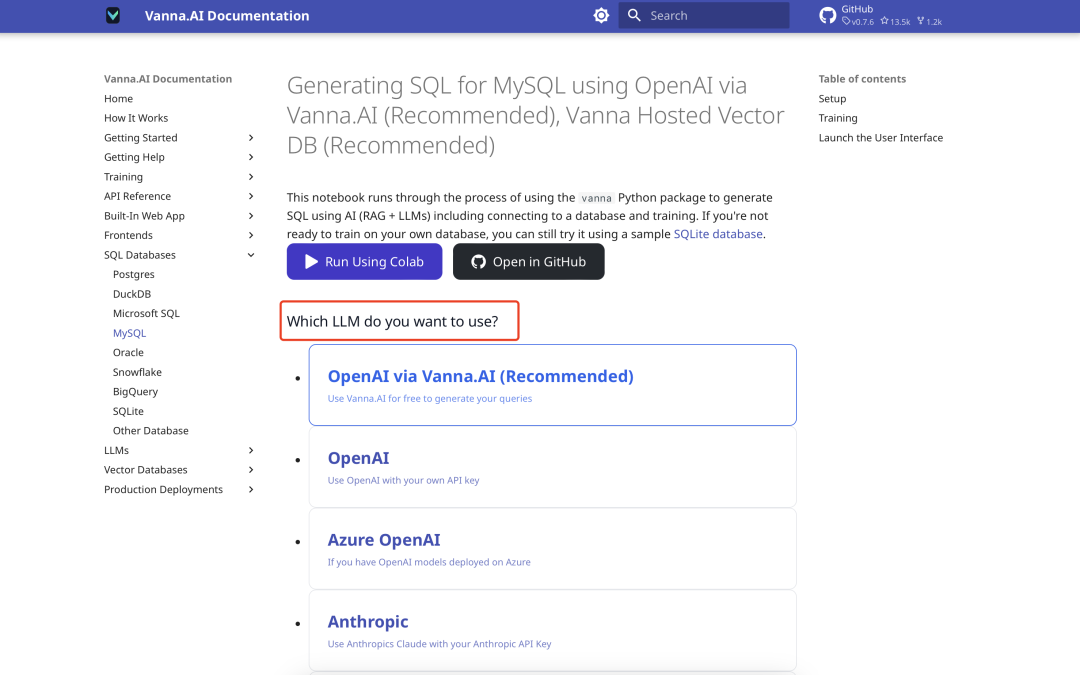
Configuração do banco de dados vetorial
O Vanna integra o ChromaDB como um pequeno banco de dados vetorial por padrão, não sendo necessária nenhuma instalação adicional. A documentação oficial gerará o código de acordo com sua escolha, como mostrado abaixo:
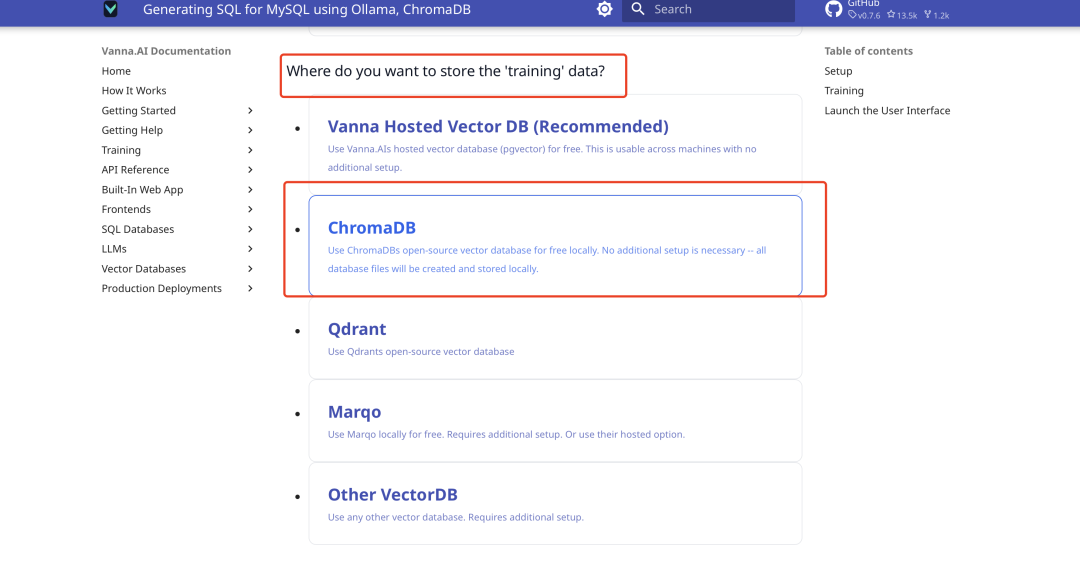
Instalação de dependências e preparação de código
- Instale o Vanna e suas dependências em um ambiente virtual ativado:
pip install vanna - Criar um
.pycopie o código oficial gerado para esse arquivo. Abaixo está um exemplo de trecho de código para adaptar o MySQL e o Deepseek (você precisa ajustar os parâmetros de acordo com a situação real):from vanna.remote import VannaDefault vn = VannaDefault(model='deepseek', api_key='your_api_key') vn.connect_to_mysql(host='localhost', dbname='test_db', user='root', password='your_password', port=3306)
treinamento de dados
O Vanna suporta três tipos de dados de treinamento: instruções SQL, documentação do produto e descrições da estrutura da tabela do banco de dados. Aqui recomendamos o uso da descrição da estrutura da tabela, pois o efeito é mais intuitivo. As etapas de treinamento são as seguintes:
- Preparar os dados da estrutura da tabela (por exemplo, arquivo DDL).
- Use o código de treinamento fornecido oficialmente:
vn.train(ddl="CREATE TABLE employees (id INT, name VARCHAR(255), salary INT)") - O processo de treinamento é mostrado a seguir:
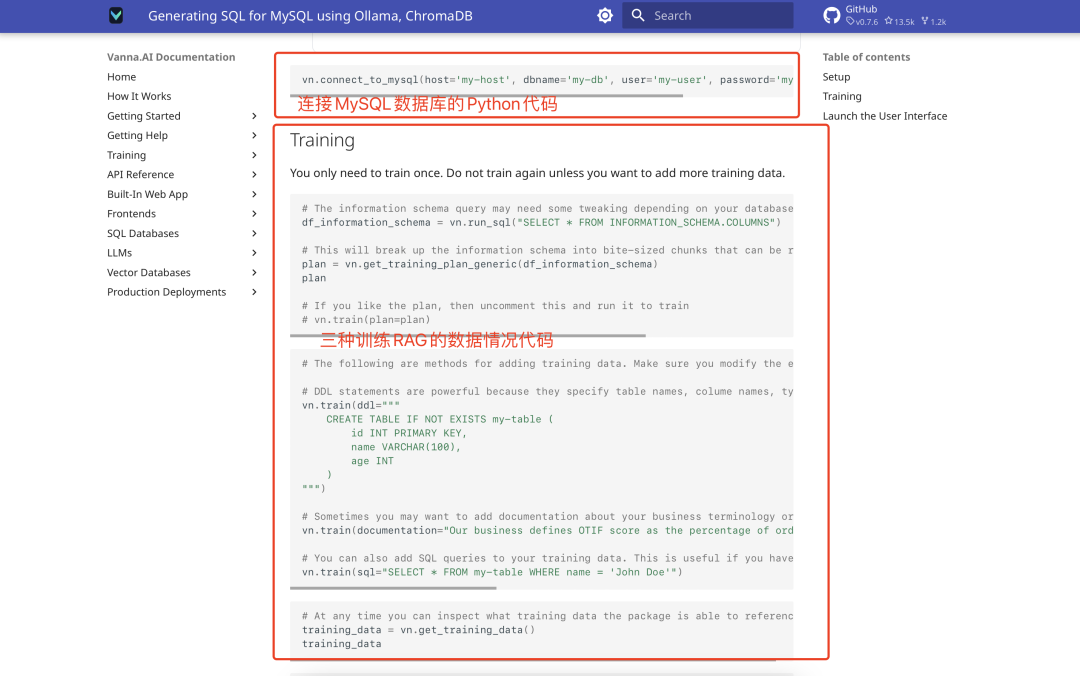
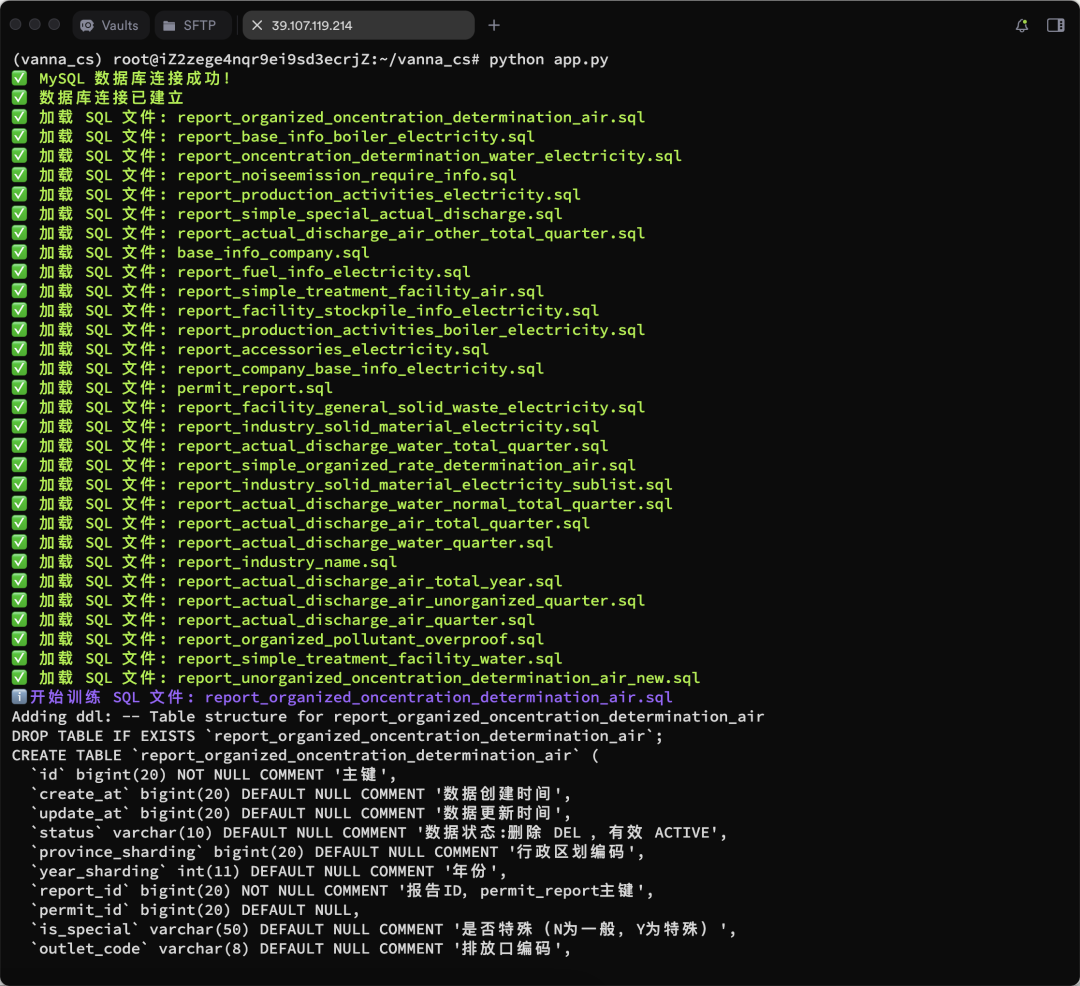
Mais resultados de treinamento são mostrados:
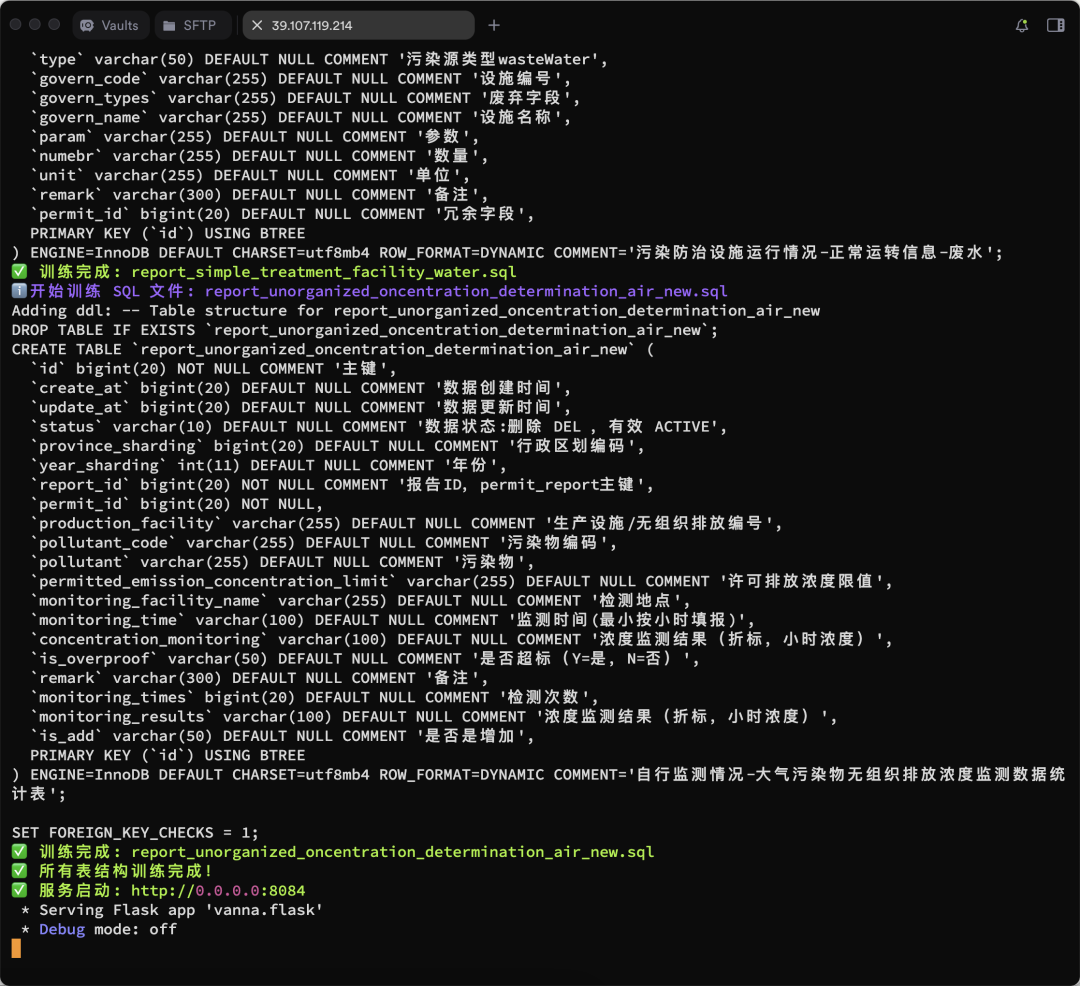
Execução da interface da Web
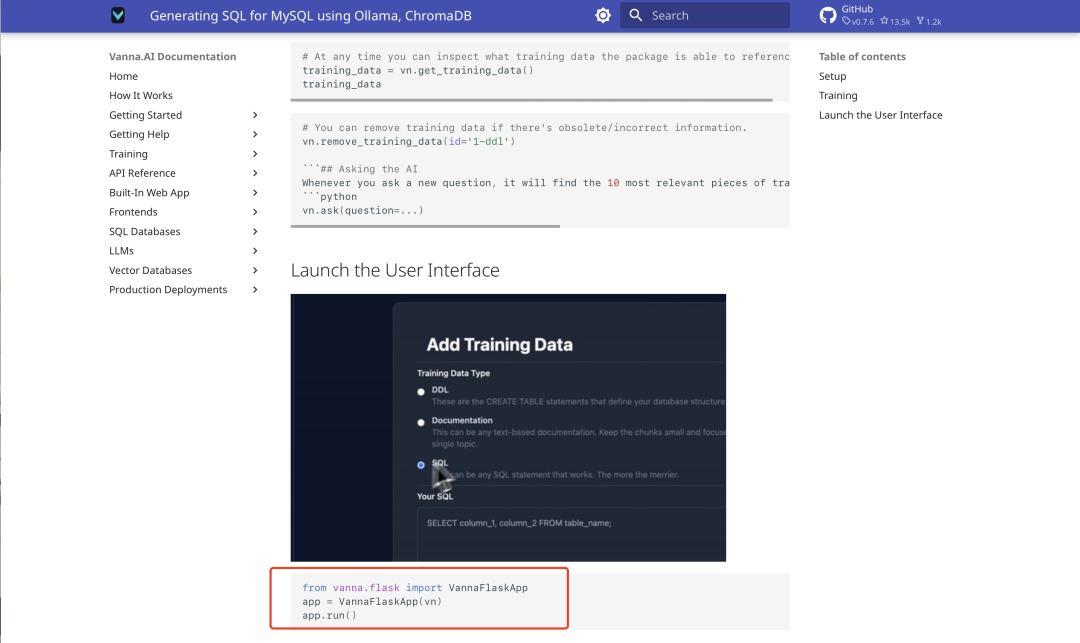
Após a conclusão do treinamento, execute o seguinte código da API do Flask para iniciar a interface do usuário da Web do Vanna:
from vanna.flask import VannaFlaskApp
app = VannaFlaskApp(vn)
app.run()
Acesso ao endereço local (geralmente http://127.0.0.1:5000), você pode fazer consultas SQL por meio da interface.
Exibição do efeito de consulta
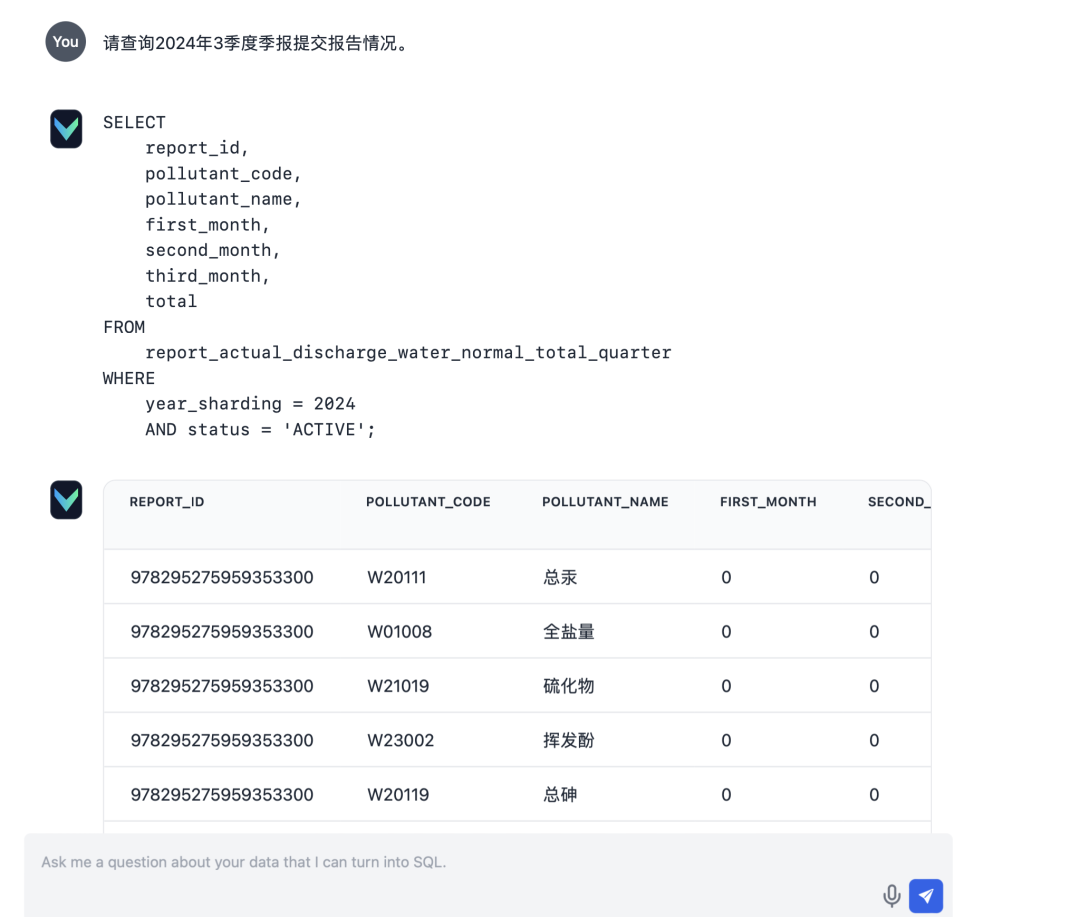
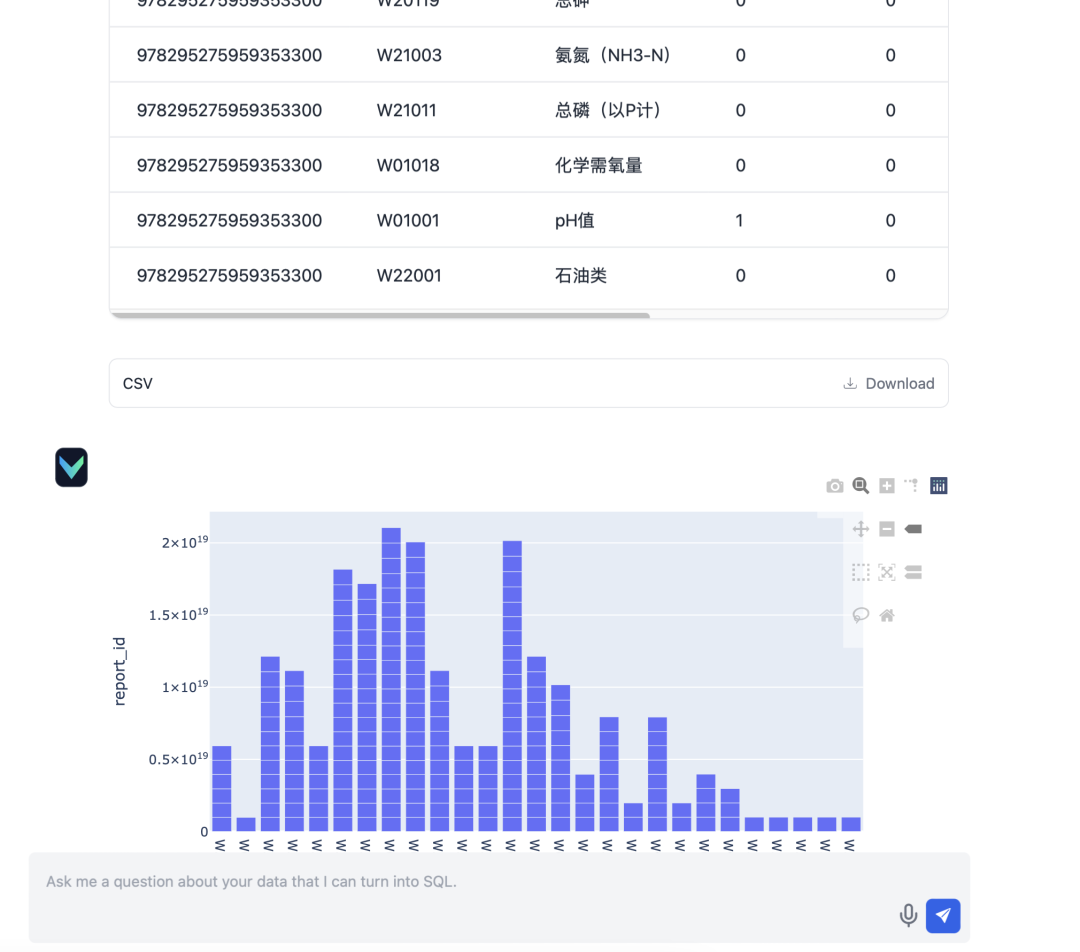
Após a implementação, a funcionalidade de perguntas e respostas do Vanna teve um desempenho satisfatório. Veja a seguir alguns resultados reais de testes:
- Entrada: "Por favor, informe-se sobre o status do envio de relatórios para o relatório trimestral do trimestre de março de 2024."

- Entrada: "Number of statistics" (Número de estatísticas)
- Entrada: "Pollutant statistics" (Estatísticas de poluentes)
Resumo e recomendações
Seguindo essas etapas, você poderá implantar com sucesso o Vanna localmente e implementar uma funcionalidade Text2SQL eficiente em combinação com os modelos MySQL e Deepseek. Em comparação com outras ferramentas, o Vanna tem vantagens óbvias em termos de facilidade de uso e eficácia. Recomenda-se que os iniciantes deem prioridade ao uso de estruturas de tabela para treinar dados e ajustem a configuração do modelo de idioma de acordo com as necessidades reais.
© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Artigos relacionados


Nenhum comentário...