
V-JEPA 2 - O modelo grande mais poderoso do mundo da Meta AI
O que é V-JEPA 2
V-JEPA 2 Sim Meta AI Lançou um modelo de tamanho mundial baseado em dados de vídeo com 1,2 bilhão de parâmetros. O modelo é treinado com base no aprendizado autossupervisionado de mais de 1 milhão de horas de vídeo e 1 milhão de imagens para entender objetos, ações e movimentos no mundo físico e prever estados futuros. O modelo usa uma arquitetura de codificador-previsor, combinada com a previsão de condições de ação, para dar suporte ao planejamento de robôs com amostra zero, permitindo que os robôs concluam tarefas em novos ambientes. O modelo é equipado com recursos de vídeo de perguntas e respostas e suporta a combinação de modelos de linguagem para responder a perguntas relacionadas ao conteúdo do vídeo. O V-JEPA 2 é excelente em tarefas como reconhecimento de ações, previsão e vídeo de perguntas e respostas, fornecendo suporte técnico avançado para controle de robôs, vigilância inteligente, educação e saúde, além de ser um passo importante em direção à inteligência avançada de máquinas.
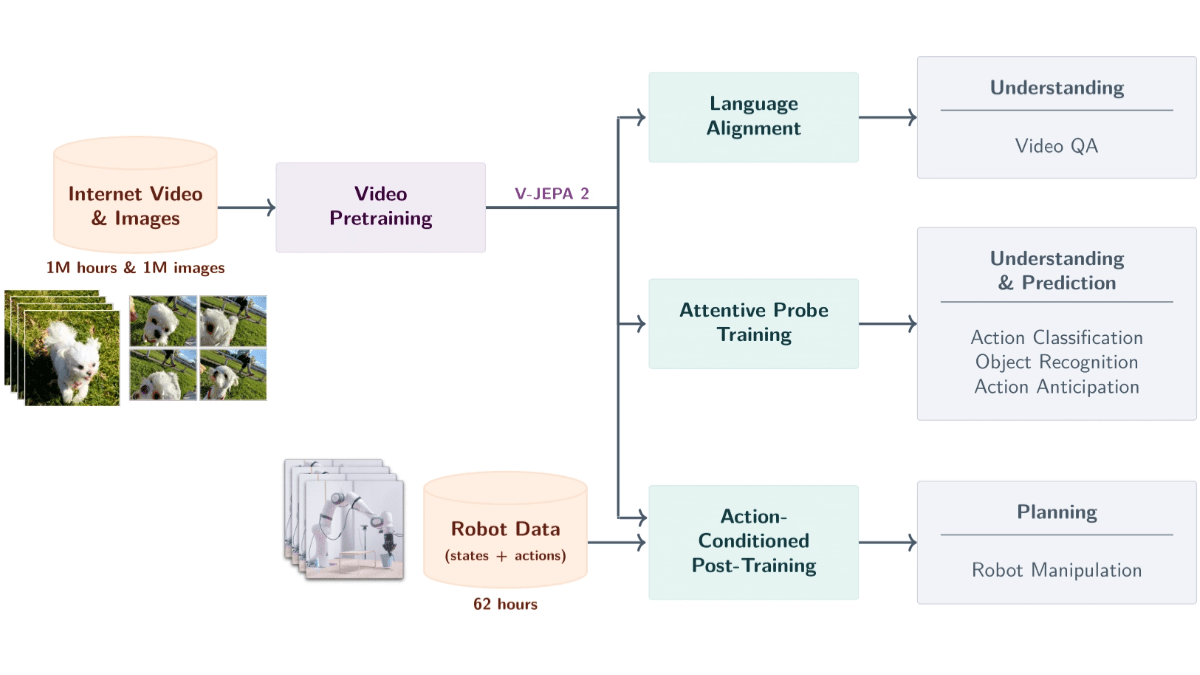
Principais recursos do V-JEPA 2
- Análise semântica de vídeoReconhecimento de objetos, ações e movimentos em vídeos e extração precisa de informações semânticas sobre a cena.
- Previsão de eventos futurosPrevisão de futuros quadros de vídeo ou resultados de ações com base no estado e nas ações atuais, com suporte a previsões de curto e longo prazo.
- Planejamento de amostra zero do robôDescrição: Planejamento de tarefas para robôs em novos ambientes, como agarrar e manipular objetos, com base em recursos preditivos, sem dados de treinamento adicionais.
- Interação com vídeo de perguntas e respostasResposta a perguntas relacionadas ao conteúdo do vídeo em conjunto com a modelagem de linguagem, abrangendo a causa física e a compreensão da cena.
- Generalização entre cenasO sistema de aprendizado de amostra zero e a adaptação em novas cenas são compatíveis.
Endereço do site oficial da V-JEPA 2
- Site do projeto::https://ai.meta.com/blog/v-jepa-2
- Repositório do GitHub::https://github.com/facebookresearch/vjepa2
- Documentos técnicos::https://scontent-lax3-2.xx.fbcdn.net/v/t39.2365-6
Como usar o V-JEPA 2
- Acesso a recursos de modeloDownload dos arquivos do modelo pré-treinado e do código associado no repositório do GitHub. Os arquivos de modelo são fornecidos no formato .pth ou .ckpt.
- Configuração do ambiente de desenvolvimento::
- Instalação do PythonVerifique se o Python está instalado (recomenda-se o Python 3.8 ou superior).
- Instalação de bibliotecas dependentesUse o pip para instalar as dependências exigidas pelo projeto. Normalmente, os projetos fornecem um arquivo requirements.txt para instalar dependências com base nos seguintes comandos:
pip install -r requirements.txt- Instalação de estruturas de aprendizagem profundaO V-JEPA 2 é baseado no PyTorch e requer que o PyTorch seja instalado, dependendo da configuração do sistema e do GP; obtenha os comandos de instalação no site do PyTorch.
- Modelos de carregamento::
- Carregamento de modelos pré-treinadosCarregamento de arquivos de modelos pré-treinados com o PyTorch.
import torch
from vjepa2.model import VJEPA2 # 假设模型类名为 VJEPA2
# 加载模型
model = VJEPA2()
model.load_state_dict(torch.load("path/to/model.pth"))
model.eval() # 设置为评估模式- Preparação para inserir dados::
- Pré-processamento de dados de vídeoV-JEPA 2 requer dados de vídeo como entrada. Os dados de vídeo são convertidos para o formato (geralmente tensor) exigido pelo modelo. Abaixo está um exemplo simples de pré-processamento:
from torchvision import transforms
from PIL import Image
import cv2
# 定义视频帧的预处理
transform = transforms.Compose([
transforms.Resize((224, 224)), # 调整帧大小
transforms.ToTensor(), # 转换为张量
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 标准化
])
# 读取视频帧
cap = cv2.VideoCapture("path/to/video.mp4")
frames = []
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
frame = Image.fromarray(frame)
frame = transform(frame)
frames.append(frame)
cap.release()
# 将帧堆叠为一个张量
video_tensor = torch.stack(frames, dim=0).unsqueeze(0) # 添加批次维度- Previsão com modelos::
- Projeções de implementaçãoEntrada dos dados de vídeo pré-processados no modelo para obter os resultados da previsão. A seguir, o código de amostra:
with torch.no_grad(): # 禁用梯度计算
predictions = model(video_tensor)- Analisar e aplicar os resultados da previsão::
- Análise dos resultados da previsãoAnalisar a saída do modelo de acordo com os requisitos da tarefa.
- Aplicação a cenários do mundo realAplicar previsões a tarefas do mundo real, como controle de robôs, questionários em vídeo ou detecção de anomalias.
Principais benefícios do V-JEPA 2
- Forte compreensão do mundo físicoV-JEPA 2 pode reconhecer com precisão ações e movimentos de objetos com base em entradas de vídeo, capturando informações semânticas sobre a cena e fornecendo suporte básico para tarefas complexas.
- Previsão eficiente de estados futurosCom base no estado e nas ações atuais, o modelo pode prever futuros quadros de vídeo ou resultados de ações, oferecendo suporte a previsões de curto e longo prazo, alimentando aplicativos como planejamento de robôs e monitoramento inteligente.
- Recursos de aprendizado e generalização de amostra zeroV-JEPA 2 tem bom desempenho em ambientes e objetos não vistos, suporta aprendizado e adaptação de amostra zero e não requer dados de treinamento adicionais para concluir novas tarefas.
- Recurso de vídeo Q&A combinado com modelagem de linguagemQuando combinado com um modelo de linguagem, o V-JEPA 2 é capaz de responder a perguntas relacionadas ao conteúdo de vídeo, abrangendo causalidade física e compreensão de cenas, expandindo as aplicações em áreas como educação e saúde.
- Treinamento eficiente com base no aprendizado autossupervisionadoAprendizado de representações visuais genéricas a partir de dados de vídeo em larga escala com base no aprendizado autossupervisionado sem rotular manualmente os dados, reduzindo o custo e melhorando a generalização.
- Treinamento em vários estágios e previsão das condições de movimentoTreinamento em vários estágios: Com base no treinamento em vários estágios, o V-JEPA 2 pré-treina o codificador e, em seguida, treina o preditor de condição de movimento, combinando informações visuais e de movimento para oferecer suporte ao controle preditivo preciso.
Pessoas a quem o V-JEPA 2 se destina
- Pesquisadores de inteligência artificialPesquisa acadêmica e inovação tecnológica com a tecnologia de ponta do V-JEPA 2 para promover a inteligência de máquina.
- Engenheiro de robóticaDesenvolvimento de sistemas robóticos adaptados a novos ambientes e tarefas complexas com a ajuda de recursos de planejamento de modelo de amostra zero.
- Desenvolvedor de visão computacionalV-JEPA 2: Aumente a eficiência da análise de vídeo com o V-JEPA 2, usado em segurança inteligente, automação industrial e outros campos.
- especialista em processamento de linguagem natural (NLP)Análise de dados: combinação de modelagem visual e linguística para desenvolver sistemas de interação inteligente, como assistentes virtuais e atendimento inteligente ao cliente.
- educadorDesenvolvimento de ferramentas educacionais imersivas baseadas em funções de questionário em vídeo para aprimorar o ensino e a aprendizagem.
© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Artigos relacionados


Nenhum comentário...