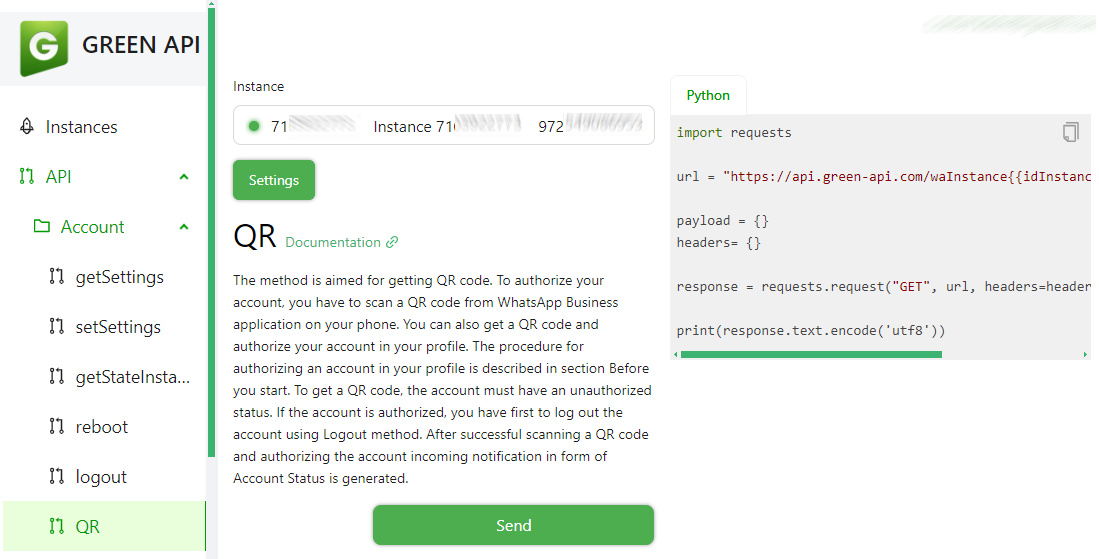
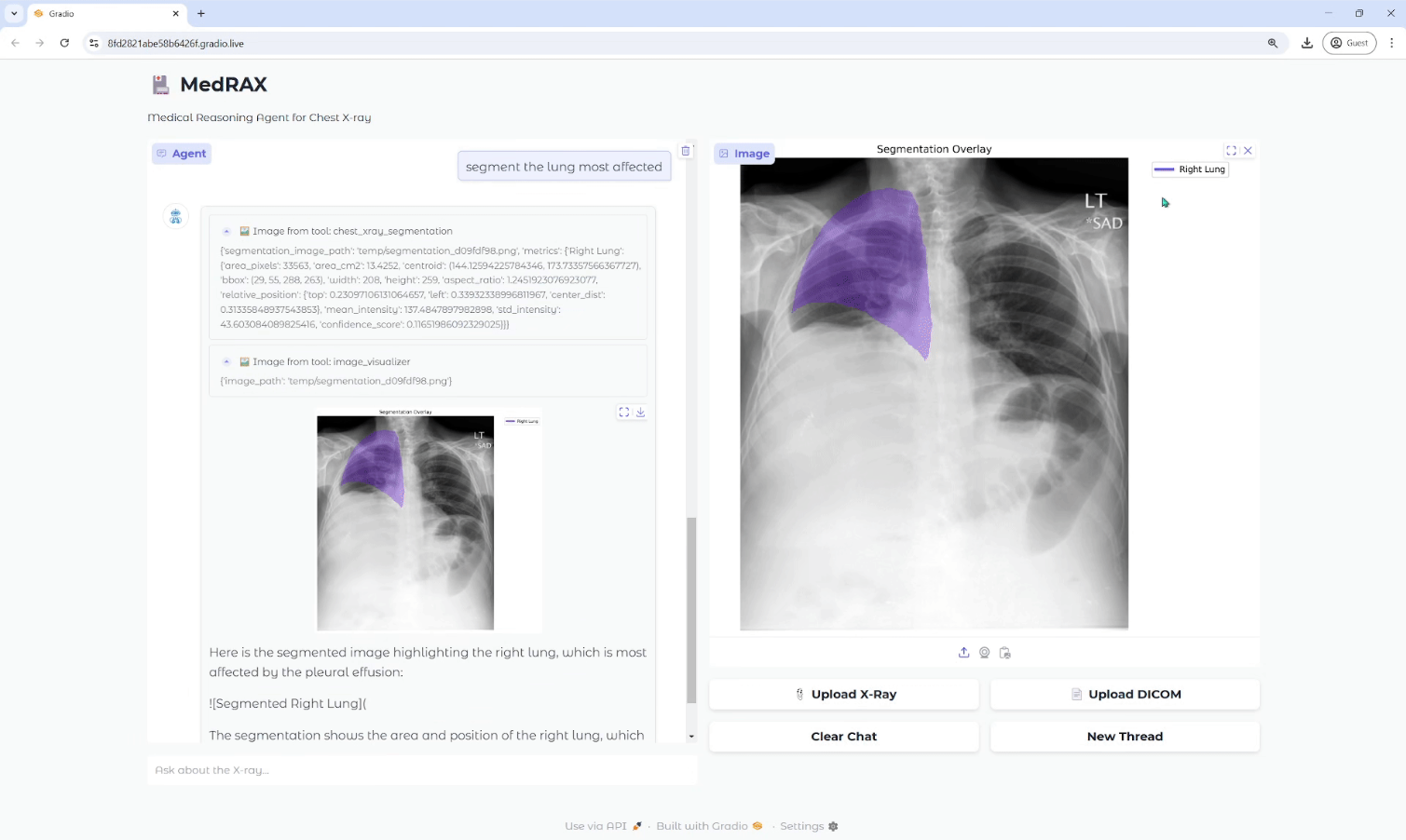
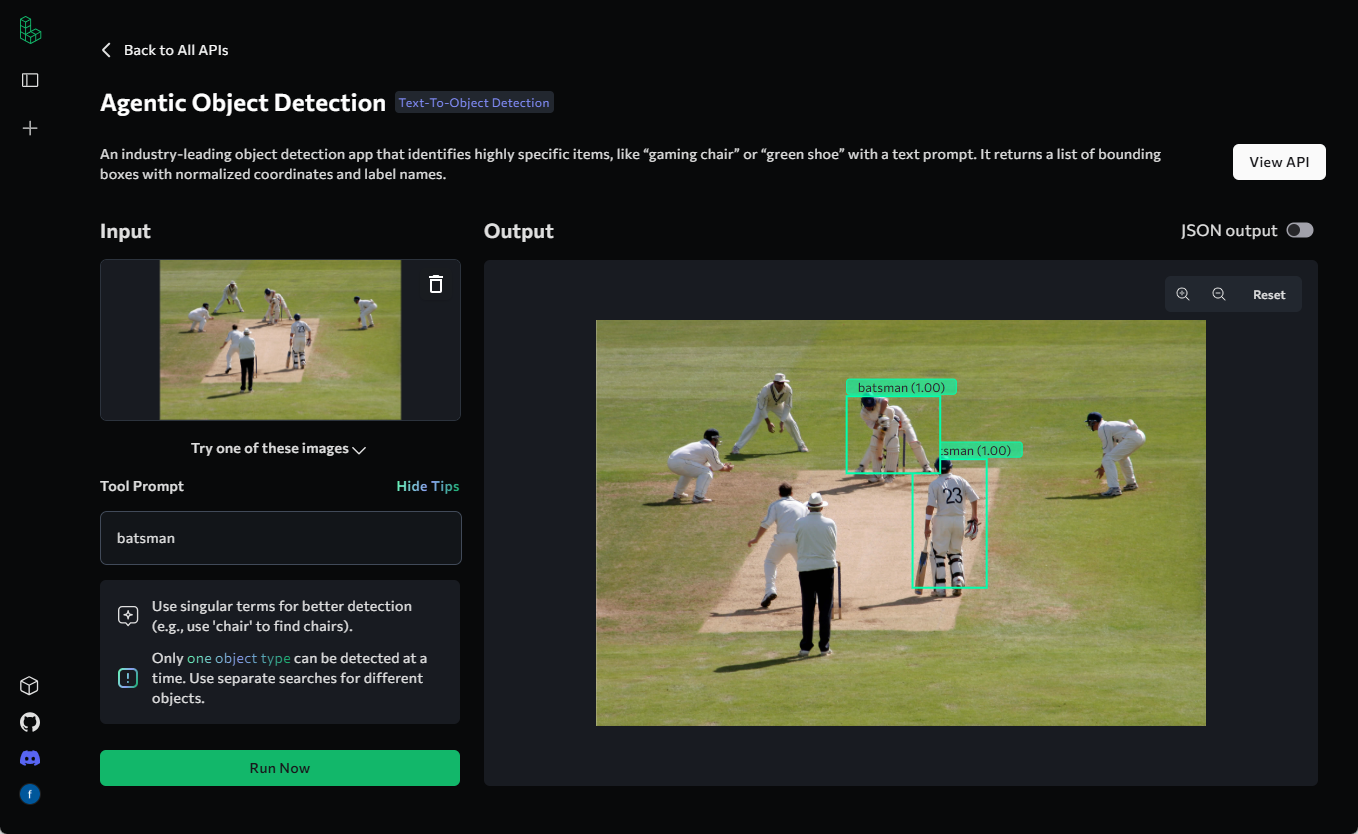
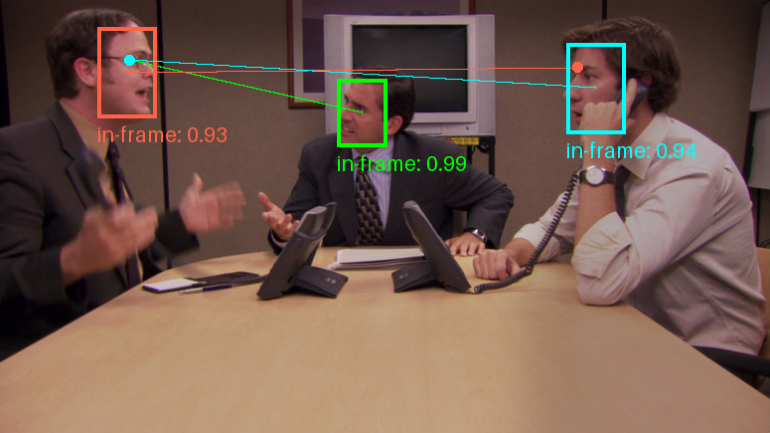
Trackers: biblioteca de ferramentas de código aberto para rastreamento de objetos de vídeo
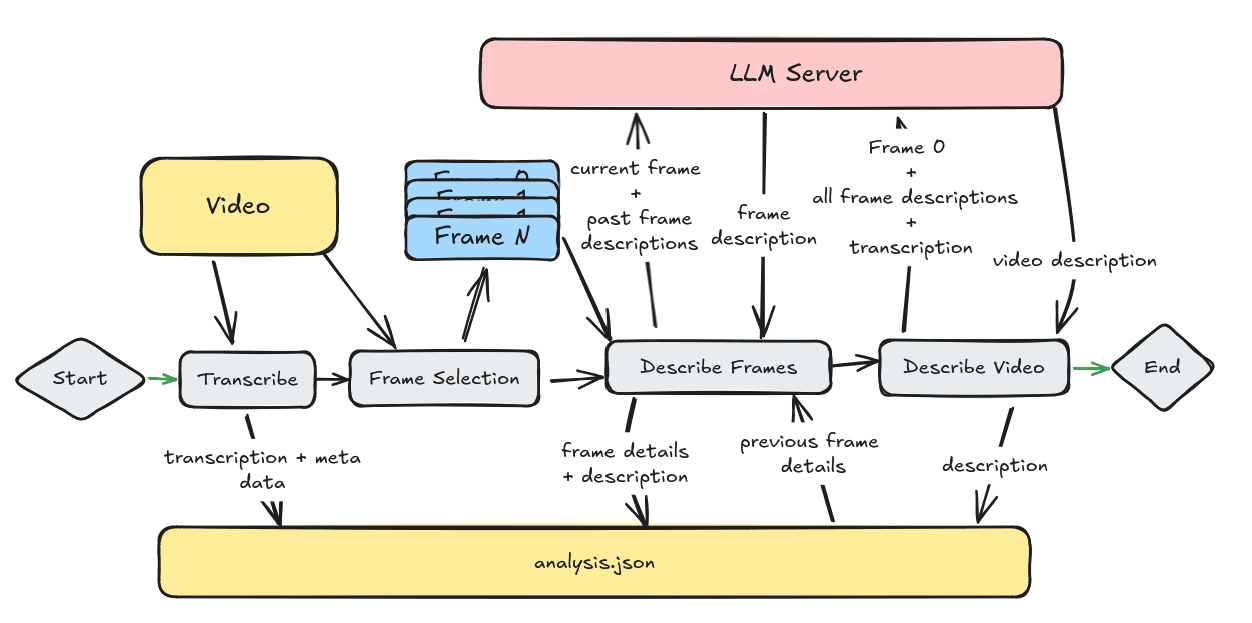
Introdução geral Trackers é uma biblioteca de ferramentas Python de código aberto voltada para o rastreamento de vários objetos em vídeo. Ela integra vários dos principais algoritmos de rastreamento, como o SORT e o DeepSORT, e permite que os usuários combinem diferentes modelos de detecção de objetos (como o YOLO...