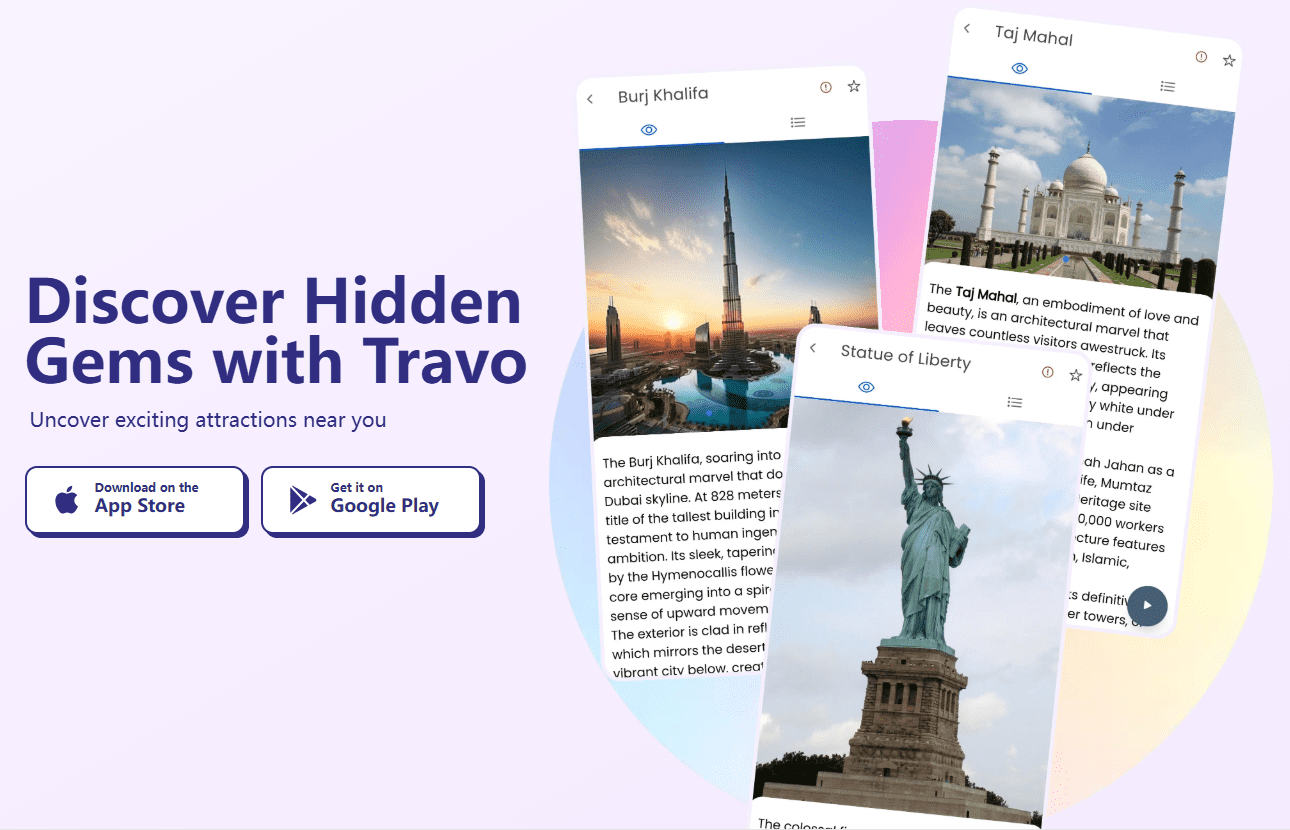
SVLS: SadTalker aprimorado para gerar pessoas digitais usando vídeo de retrato

Introdução geral
O SadTalker-Video-Lip-Sync é uma ferramenta de síntese labial de vídeo baseada na implementação do SadTalkers. O projeto gera formas labiais por meio da geração orientada por voz e usa o aprimoramento configurável da região facial para melhorar a clareza das formas labiais geradas. O projeto também usa o algoritmo de interpolação de quadros DAIN para preencher quadros no vídeo gerado para tornar a transição labial mais suave, realista e natural. Os usuários podem gerar rapidamente vídeos de formato de lábios de alta qualidade por meio de operações simples de linha de comando, que são adequadas para várias necessidades de produção e edição de vídeo.

SadTalker original

SadTalker aprimorado
Lista de funções
- Geração de lábios orientada por falaMovimentos labiais: conduz os movimentos labiais em um vídeo por meio de um arquivo de áudio.
- Aprimoramento da área facialAprimoramento configurável da imagem da área dos lábios ou do rosto inteiro para melhorar a nitidez do vídeo.
- Inserção de quadro DAINUse algoritmos de aprendizagem profunda para corrigir quadros em vídeos para melhorar a suavidade do vídeo.
- Várias opções de aprimoramentoSuporte a três modos: sem aprimoramento, aprimoramento dos lábios e aprimoramento do rosto inteiro.
- Modelo de pré-treinamentoForneça uma variedade de modelos pré-treinados para que os usuários possam começar rapidamente.
- Operação simples de linha de comandoFácil de configurar e executar por meio de parâmetros de linha de comando.
Usando a Ajuda
Preparação ambiental
- Instale as dependências necessárias:
pip install torch==1.12.1+cu113 torchvision==0.13.1+cu113 torchaudio==0.12.1 --extra-index-url https://download.pytorch.org/whl/cu113
conda install ffmpeg
pip install -r requirements.txt
- Se você precisar usar o modelo DAIN para preenchimento de quadros, também precisará instalar o Paddle:
python -m pip install paddlepaddle-gpu==2.3.2.post112 -f https://www.paddlepaddle.org.cn/whl/linux/mkl/avx/stable.html
Estrutura do projeto
checkpoints: armazenar modelos pré-treinadosdian_outputArmazena as saídas de inserção de quadro DAINexamplesArquivos de áudio e vídeo de amostraresultsGeração de resultadossrc: Código-fontesync_showDemonstração do efeito de síntesethird_partBibliotecas de terceirosinference.pyScript de raciocínioREADME.mdDocumento de descrição do projeto
raciocínio modelado
Use o seguinte comando para inferência de modelo:
python inference.py --driven_audio <audio.wav> --source_video <video.mp4> --enhancer <none, lip, face> --use_DAIN --time_step 0.5
--driven_audioArquivos de áudio de entrada--source_videoArquivos de vídeo de entrada--enhancerModos aprimorados (nenhum, lábio, rosto)--use_DAINSe deve usar quadros DAIN--time_stepTaxa de quadros interpolada: Taxa de quadros interpolada (padrão 0,5, ou seja, 25 fps -> 50 fps)
efeito de síntese
Os efeitos de vídeo gerados são mostrados na seção ./sync_show Catálogo:
original.mp4: Vídeo originalsync_none.mp4Efeitos de síntese sem qualquer aprimoramentonone_dain_50fps.mp4Adição de 25 fps a 50 fps usando apenas o modelo DAINlip_dain_50fps.mp4Aprimoramentos na área dos lábios + modelo DAIN para adicionar 25 fps a 50 fpsface_dain_50fps.mp4Aprimoramento da área total do rosto + modelo DAIN para adicionar 25 fps a 50 fps
Modelo de pré-treinamento
Caminho de download do modelo pré-treinado:
- Baidu.com:link (em um site) Código de extração: klfv
- Google Drive:link (em um site)
© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Artigos relacionados


Nenhum comentário...