
Análise do SuperCLUE: DeepSeek-R1 Crossover de estabilidade de plataforma de terceiros, escolha a plataforma certa e o desempenho dispara!
Relatório de avaliação de estabilidade do DeepSeek-R1 em plataformas de terceiros
O rápido desenvolvimento do campo da inteligência artificial deu origem a vários modelos de inferência excepcionais. O DeepSeek-R1 tornou-se rapidamente o foco de atenção do setor devido ao seu excelente desempenho e capacidade de lidar com tarefas complexas. No entanto, com a proliferação de usuários e o aumento de ataques cibernéticos externos, o problema de estabilidade do DeepSeek-R1 foi gradualmente exposto. Para enfrentar esse desafio, várias plataformas de terceiros lançaram suas próprias soluções para o DeepSeek-R1 Serviços de otimização de modelos e nos esforçamos para oferecer aos usuários uma experiência mais estável e eficiente.
Para ajudar os usuários a entender completamente a qualidade do serviço de diferentes plataformas e fazer uma escolha informada com base em suas necessidades, a organização realizou uma pesquisa em várias plataformas de terceiros que suportam o DeepSeek-R1.Avaliação da estabilidadeEssa avaliação foi realizada em 12 plataformas de terceiros representativas. Nessa avaliação, foram selecionadas 12 plataformas de terceiros representativas e 20 perguntas originais de raciocínio do oráculo de escolas primárias foram elaboradas para examinar o desempenho real do modelo DeepSeek-R1 em cada plataforma. As dimensões da avaliação abrangem indicadores importantes, como taxa de resposta, tempo de raciocínio e precisão. Este relatório tem como objetivo apresentar os primeiros resultados da avaliação das plataformas baseadas na Web, refletindo o nível de estabilidade de cada plataforma no momento do lançamento. No futuro, a organização continuará a acompanhar e realizar avaliações mais abrangentes em várias plataformas, incluindo versões baseadas na Web, API, APP e até mesmo versões implantadas localmente.
Resumo da experiência de avaliação da estabilidade do DeepSeek-R1
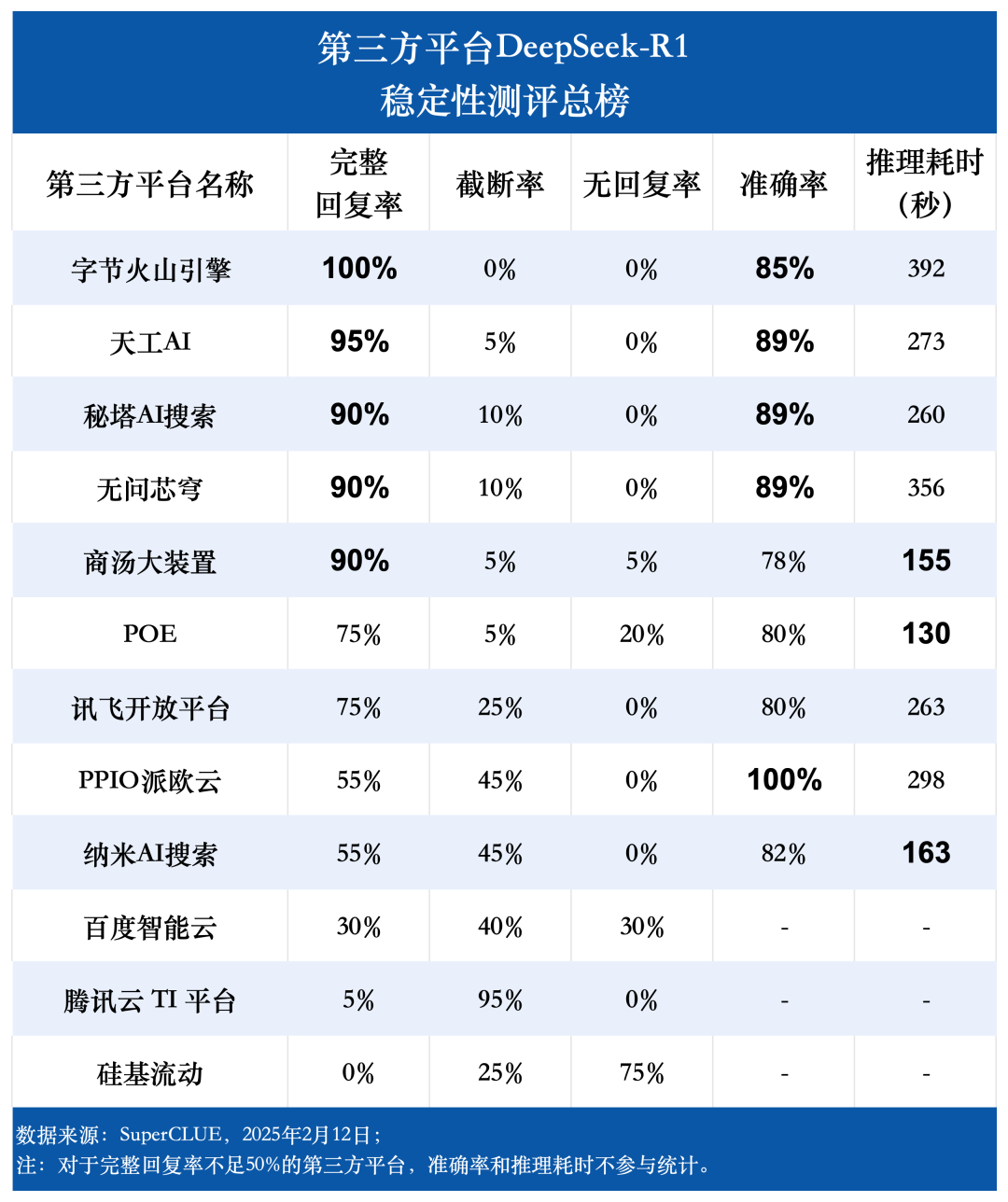
Ponto de avaliação 1: Há uma diferença significativa na taxa de resposta completa da plataforma de terceiros DeepSeek-R1.
Os resultados da avaliação mostram que o Byte Volcano Engine (100%), o Tiangong AI (95%), o Secret Pagoda AI Search, o Unquestioning Core Dome e o Shangtang Big Device (todos com 90%) têm um desempenho excepcional em termos de taxa de resposta completa, demonstrando excelente estabilidade. Em contrapartida, a Baidu Intelligent Cloud, a Tencent Cloud TI Platform e a Silicon Mobility tiveram taxas de resposta completas abaixo de 50%, sugerindo que sua estabilidade poderia ser melhorada. Essa descoberta destaca a importância da estabilidade da plataforma no processo de seleção de usuários.
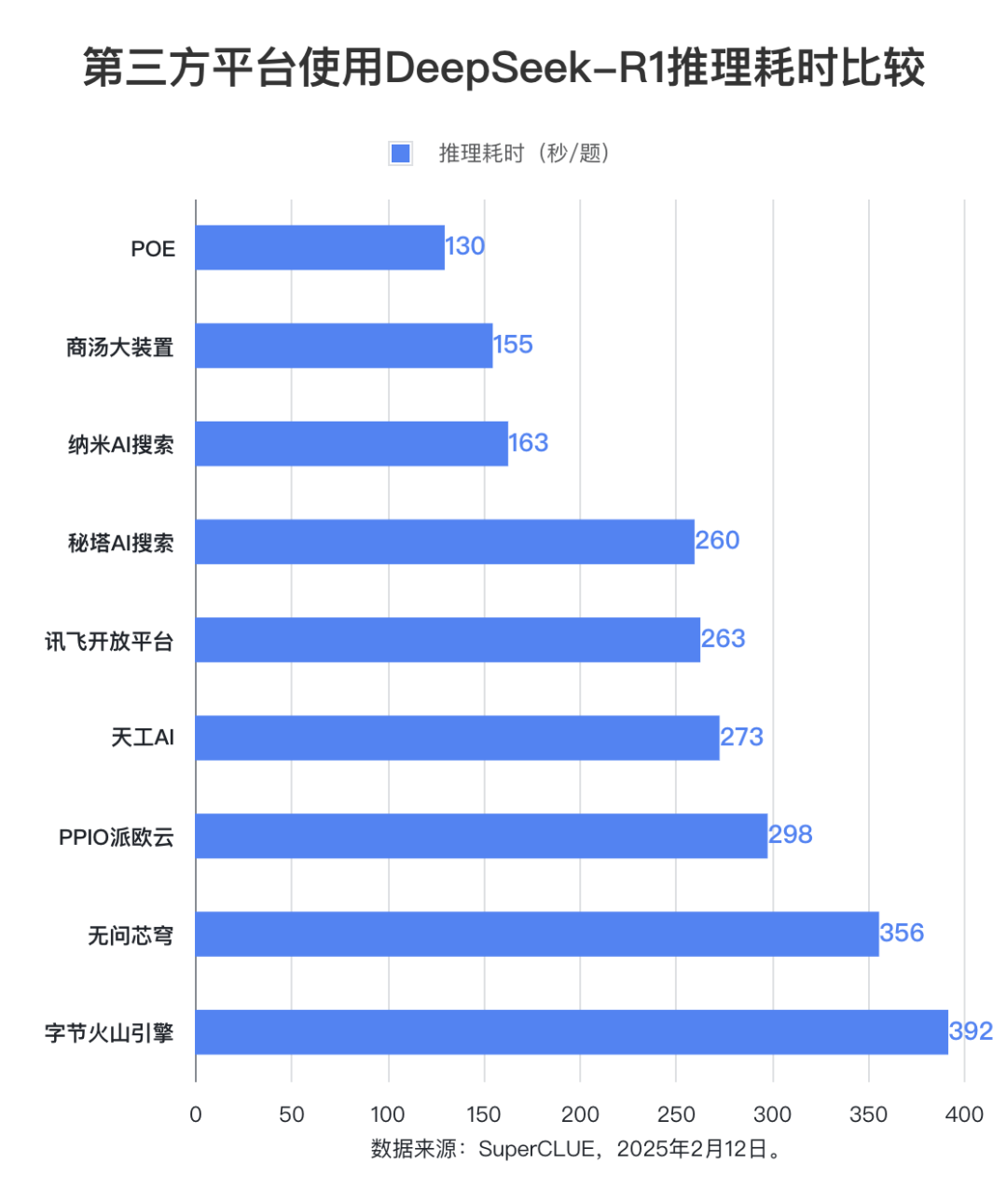
Ponto de avaliação 2: Há uma diferença significativa no tempo de inferência do modelo DeepSeek-R1 entre as plataformas, com a diferença entre a plataforma mais longa e a mais curta sendo quase três vezes.
Em termos de tempo de inferência, a plataforma POE tem o melhor desempenho, com um tempo médio de 130 segundos por pergunta. O Shangtang Big Device e o Nano AI Search vêm logo atrás, com um tempo médio por pergunta de 155 segundos e 163 segundos, respectivamente. O Byte Volcano Engine obteve o maior tempo médio por pergunta, chegando a 392 segundos.
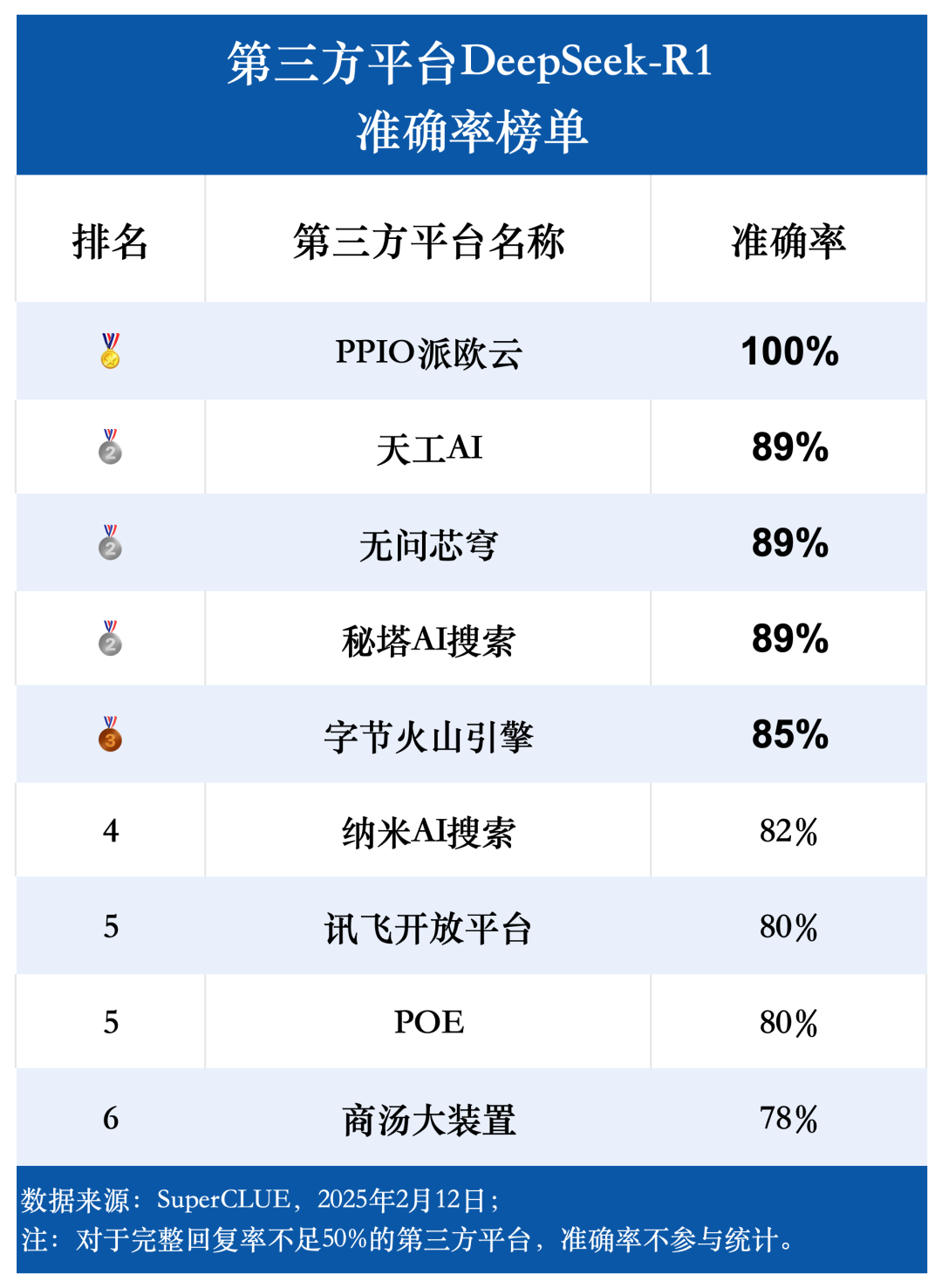
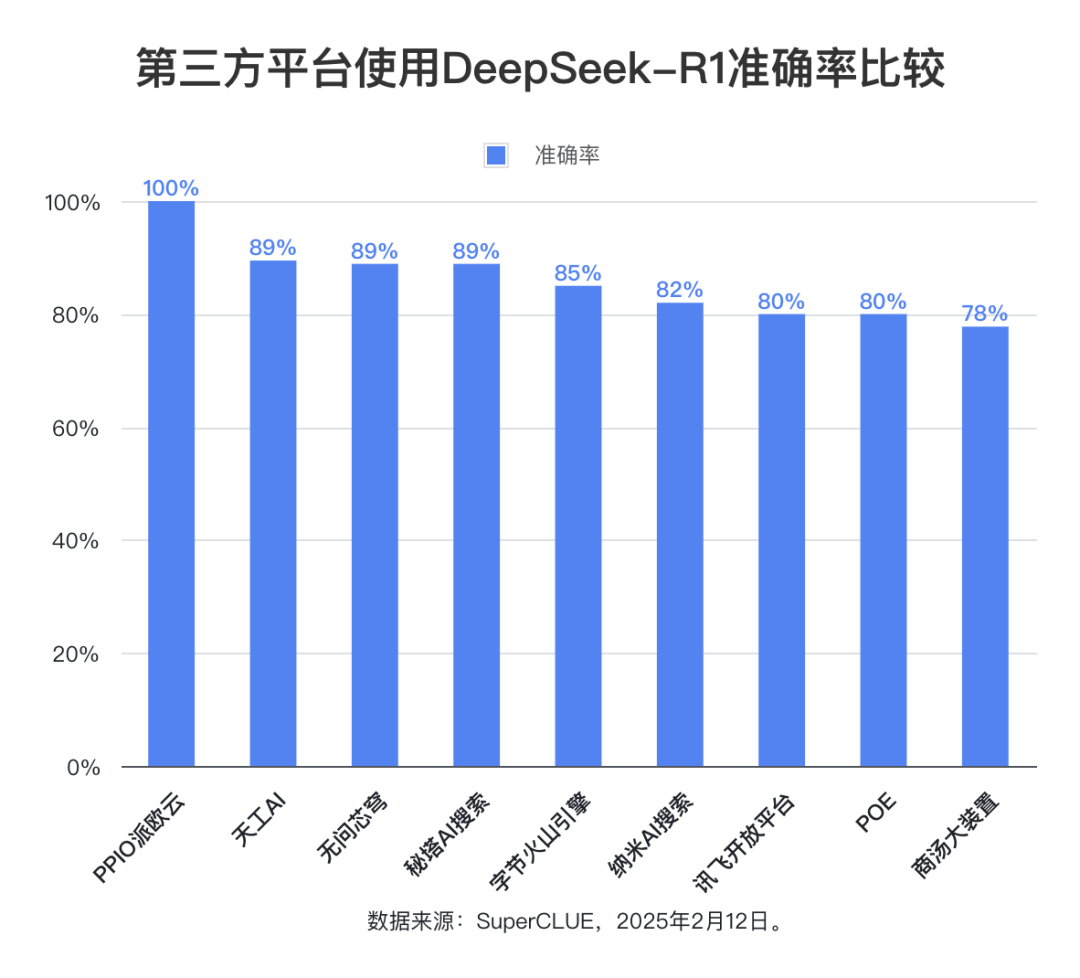
Ponto de avaliação 3: A precisão geral do modelo DeepSeek-R1 é alta em todas as plataformas, refletindo o desempenho sólido e confiável do próprio modelo.
Os dados da avaliação mostram que, com exceção das plataformas com taxa de resposta completa inferior a 50%, a taxa de precisão média das outras nove plataformas é de 85,76%, a taxa de precisão mais alta chega até mesmo a 100% e a taxa de precisão mais baixa também fica em 78%, o que prova plenamente que o modelo DeepSeek-R1 em si tem excelente desempenho e confiabilidade e pode oferecer suporte estável e de alta precisão para todos os tipos de aplicativos de terceiros. Isso prova que o próprio modelo DeepSeek-R1 tem excelente desempenho e confiabilidade e pode oferecer suporte estável e de alta precisão para vários aplicativos de terceiros.
Visão geral da lista
Taxa de resposta completa + taxa de truncamento + taxa de ausência de resposta = 100%
- Taxa de resposta completaResposta completa: O modelo fornece respostas completas sem problemas como truncamento ou ausência de resposta, mas não leva em conta se a resposta está correta ou não. Calculado como o número de perguntas com resposta completa dividido pelo número total de perguntas.
- taxa de truncamentoO modelo teve uma interrupção no processo de resposta e não conseguiu dar uma resposta completa. Calculado como o número de perguntas truncadas dividido pelo número total de perguntas.
- taxa de não respostaModelos que não fornecem respostas por motivos especiais (por exemplo, sem resposta/erro de solicitação). Calculado como o número de perguntas sem resposta dividido pelo número total de perguntas.
- precisãoPara perguntas com respostas completas ao modelo, a proporção de respostas que concordam com a resposta padrão. Apenas a correção da resposta final é avaliada, o processo de solução não é examinado.
- Tempo de raciocínio consumido (segundos/pergunta)Tempo médio usado pelo modelo para raciocinar sobre cada resposta para perguntas com respostas completas do modelo.
Metodologia
1. Para cada uma das plataformas de terceiros, foi realizado um teste padronizado usando 20 perguntas da OU do ensino fundamental para garantir a imparcialidade e a comparabilidade da avaliação.2. Considerando que o conteúdo de saída das perguntas de raciocínio geralmente é longo, para o suporte do ajuste da saída máxima token Para plataformas com max_tokens, defina esse parâmetro como o valor máximo e deixe o restante dos parâmetros com as configurações padrão da plataforma.3. Método estatístico de consumo de tempo de inferência: para plataformas com função de cronometragem de inferência, são usados os resultados estatísticos fornecidos pela plataforma; para plataformas sem essa função, é usada a cronometragem manual.
Resultados da avaliação
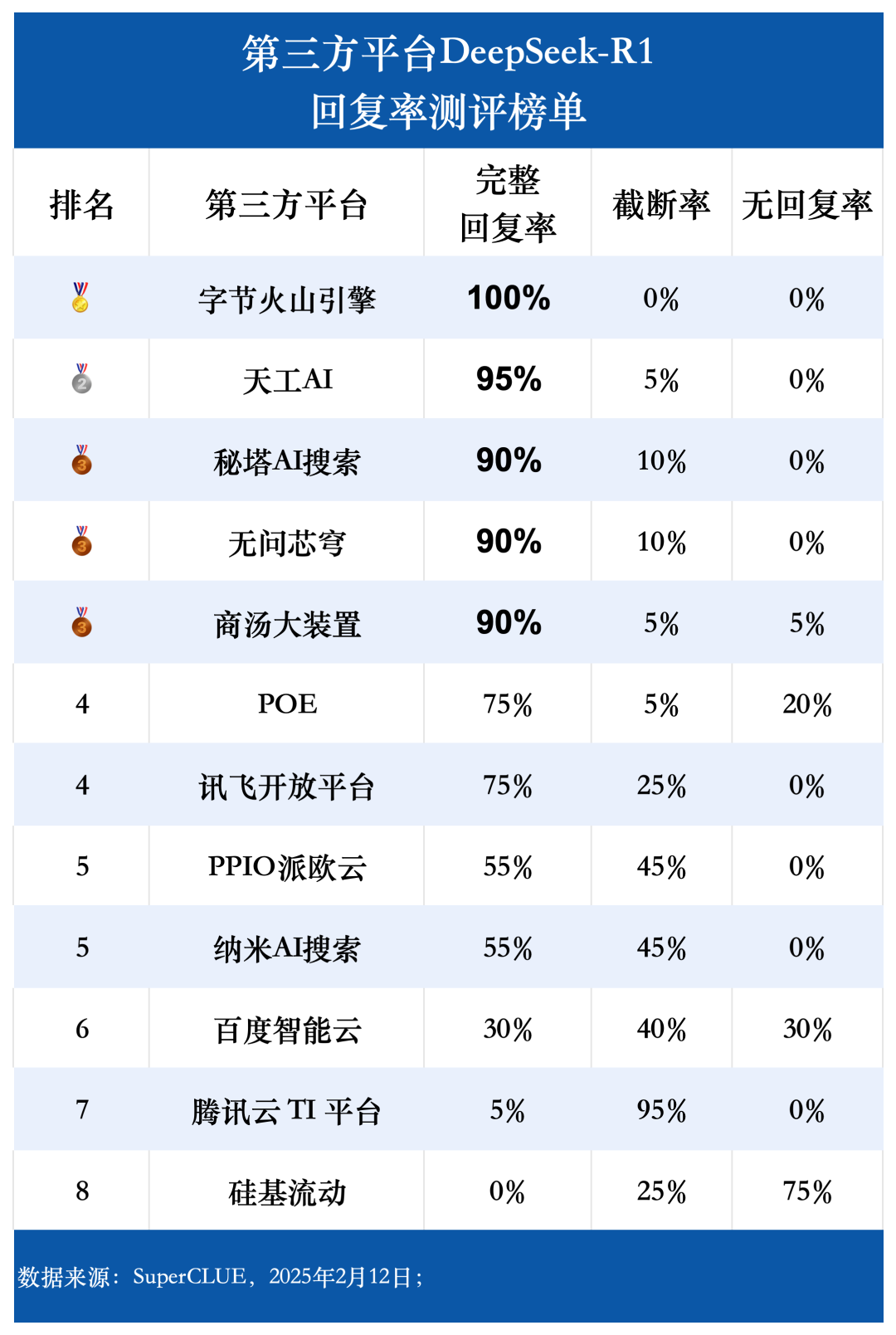
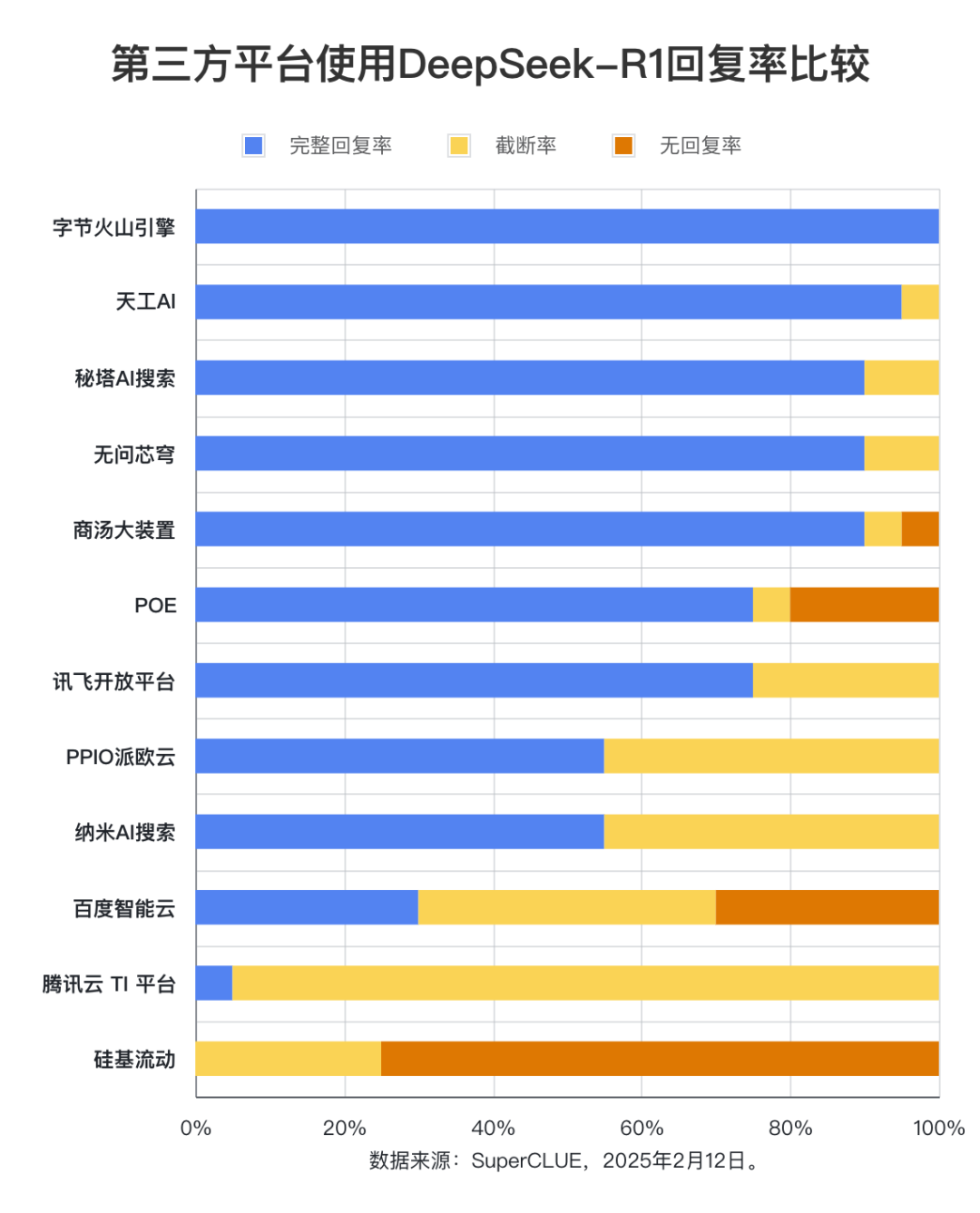
(1) Taxa de resposta completa
Os dados da avaliação mostram que a taxa de resposta completa do Byte Volcano Engine, Tiangong AI, Secret Tower AI Search, Unquestionable Core Dome e Shangtang Big Device atingiu mais de 90%. Entre eles, o Byte Volcano Engine tem o melhor desempenho, com uma taxa de resposta completa de 100%. Por outro lado, a taxa de resposta completa do Baidu Intelligent Cloud, da plataforma Tencent Cloud TI e da Silicon Mobility é significativamente menor, com uma taxa inferior a 50%. Em termos de taxa de truncamento, a plataforma Tencent Cloud TI chega a 95%. A Silicon Mobility tem os casos mais frequentes de não resposta ou erro de solicitação durante o teste, com uma taxa de não resposta de 75%. A taxa de resposta atingiu 75%.
(2) Precisão
O intervalo estatístico da taxa de precisão é limitado às perguntas para as quais o modelo fornece uma resposta completa, refletindo a proporção de perguntas que são respondidas corretamente pelo modelo. Os resultados da avaliação mostram que a taxa de precisão média de nove plataformas de terceiros usando o modelo DeepSeek-R1 atinge 85,76%, o que confirma ainda mais a alta qualidade e a confiabilidade do próprio modelo DeepSeek-R1 e sua capacidade de fornecer suporte estável e preciso para vários cenários de aplicativos.
(3) Raciocínio demorado
Em termos de tempo médio de inferência por pergunta, a plataforma POE tem o melhor desempenho, com 130 segundos. O tempo de raciocínio do Shangtang Big Device e do Nano AI Search também é relativamente curto, ambos dentro de 200 segundos. O tempo de raciocínio do No Question Vault e do Byte Volcano Engine é relativamente longo, ambos com mais de 350 segundos. Outras plataformas levam entre 250 e 300 segundos.

Exemplos
Título: Um sapo sobe em um poço de 10 metros às 6h00. A cada 2 metros que sobe, ele escorrega 0,5 metro devido ao deslizamento das paredes. O tempo que leva para escorregar 0,5 metro é a metade do tempo que leva para subir 2 metros no poço. A rã está a 2,5 metros da boca do poço às 6h12. Quantos minutos a rã levou para subir do fundo do poço até a boca do poço?
Resposta padrão: 15,2 minutos (ou seja, 15 minutos e 12 segundos)
Resposta de referência (do modelo: Gemini-2.0-Flash-Exp):

Análise das causas
1. A limitação do comprimento máximo de saída do modelo é um dos fatores importantes que levam à interrupção das respostas. As estatísticas mostram que algumas plataformas não oferecem ajuste flexível do parâmetro max_tokens (por exemplo, Baidu Intelligent Cloud, plataforma Tencent Cloud TI etc.). Isso torna o modelo mais propenso a truncamento ao gerar respostas mais longas. Os dados mostram que a taxa média de truncamento das plataformas que não podem definir o parâmetro max_tokens é de 39%, enquanto a taxa de truncamento das plataformas que podem definir o parâmetro é de 16.43%. Especialmente nessa avaliação, a complexidade das perguntas das olimpíadas do ensino fundamental e a tediosidade da resolução das perguntas levam a um aumento significativo no comprimento do conteúdo que precisa ser gerado pelo modelo, e o problema da limitação de tokens é ainda mais ampliado. Isso exacerbou a ocorrência de truncamento de saída.

2. A carga de usuários da plataforma também é um fator potencial que afeta a estabilidade dos serviços de modelo.
Considerando as diferenças no volume de usuários de diferentes plataformas, as plataformas com um número maior de usuários podem enfrentar um risco maior de instabilidade devido a servidores sobrecarregados. A falta de estabilidade do serviço da plataforma pode afetar indiretamente a integridade e a velocidade de inferência das respostas geradas pelo modelo.
Conclusões e recomendações
1. Existem diferenças significativas no desempenho da estabilidade de diferentes plataformas de terceiros ao implantar e executar o modelo DeepSeek-R1. Os usuários são aconselhados a escolher uma plataformaAvaliação integrada A arquitetura técnica, os recursos de programação de recursos e a carga de usuários de cada plataforma, eIntegração de suas próprias necessidades(por exemplo, taxa de resposta, consumo de tempo de raciocínio e outros indicadores) para ponderar. Para os usuários que buscam maior estabilidade, eles podem priorizar plataformas com relativamente menos usuários, mas com alocação de recursos mais equilibrada para reduzir o risco de flutuações de desempenho devido à alta simultaneidade.
2. Os dados da avaliação mostram que plataformas como Byte Volcano Engine, Tiangong AI, Secret Tower AI Search, No Questions Asked Core Dome e Shangtang Big DeviceForam alcançadas taxas de resposta completa de 90% e acimaOs resultados mostram que essas plataformas têm um bom desempenho na garantia da integridade e da confiabilidade da saída do modelo. Para cenários de aplicativos que precisam garantir uma alta taxa de resposta, recomenda-se que as plataformas acima sejam priorizadas para o suporte técnico.
3. existirraciocínio demoradoAspectos.Plataformas POE e grandes instalações em Shangtang Demonstrando vantagens óbvias, suas características de baixa latência a tornam mais adequada para cenários de aplicativos com altos requisitos de tempo real. Os usuários são aconselhados a priorizar a sensibilidade do consumo de tempo de inferência de acordo com os requisitos comerciais específicos ao selecionar uma plataforma para obter o melhor equilíbrio entre desempenho e custo.
Em anexo está o site de experiência do DeepSeek-R1 para cada plataforma:
Byte Volcano Engine:https://console.volcengine.com/ark/region:ark+cn-beijing/experience/chat
Fluxo baseado em silício: https://cloud.siliconflow.cn/playground/chat/17885302724
Baidu Smart Cloud: https://console.bce.baidu.com/qianfan/ais/console/onlineTest/LLM/DeepSeek-R1
Pesquisa de IA da Torre Secreta: https://metaso.cn/
Não há perguntas sobre o núcleo da cúpula: https://cloud.infini-ai.com/genstudio/experience
PPIO Paio Cloud:https://ppinfra.com/llm
Pesquisa de Nano AI: https://bot.n.cn/chat?src=AIsearch
O grande dispositivo de Shang Tang: https://console.sensecore.cn/aistudio/experience/conversation
Skyworks AI: https://www.tiangong.cn/
POE:https://poe.com/
Plataforma Tencent Cloud TI: https://console.cloud.tencent.com/tione/v2/aimarket/detail/deepseek_series?regionId=1&detailTab=deep_seek_v1
Plataforma aberta Cyberoam:https://training.xfyun.cn/experience/text2text?type=public&modelServiceId=2501631186799621
© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Artigos relacionados



Nenhum comentário...