Step-Audio-AQAA - Modelo de linguagem de áudio grande de ponta a ponta da StepFun
O que é o Step-Audio-AQAA?
O Step-Audio-AQAA é um modelo de linguagem de áudio de ponta a ponta e em grande escala para tarefas de consulta de áudio e resposta de áudio (AQAA) da equipe StepFun. A capacidade de processar a entrada de áudio diretamente para gerar respostas de fala naturais e precisas sem depender dos módulos tradicionais de reconhecimento automático de fala (ASR) e de conversão de texto em fala (TTS) simplifica a arquitetura do sistema e elimina erros em cascata. O processo de treinamento do Step-Audio-AQAA envolve pré-treinamento multimodal, ajuste fino supervisionado (SFT), otimização direta de preferências (DPO) e fusão de modelos. Por meio desses métodos, os modelos têm um bom desempenho em tarefas complexas, como controle de emoção da fala, interpretação de papéis e raciocínio lógico. No benchmark StepEval-Audio-360, o Step-Audio-AQAA supera os modelos LALM existentes em várias dimensões importantes, demonstrando um forte potencial para a interação de fala de ponta a ponta.
Principais recursos do Step-Audio-AQAA
- Processamento direto de entradas de áudioGera respostas de voz diretamente da entrada de áudio bruta, sem depender dos módulos tradicionais de reconhecimento automático de fala (ASR) e de conversão de texto em fala (TTS).
- Interação de voz perfeitaSuporte à interação de voz para fala: os usuários podem fazer perguntas com a voz e o modelo responde diretamente com a voz, aumentando a naturalidade e a suavidade da interação.
- Ajuste do tom emocionalSuporte para ajustar o tom emocional da fala no nível da frase, por exemplo, para expressar emoções como felicidade, tristeza ou seriedade.
- controle da falaResposta de voz: O usuário pode ajustar a velocidade da resposta de voz conforme necessário para torná-la mais responsiva às necessidades do cenário.
- Controle de tom e alturaVoz: pode ajustar o tom e o timbre da voz de acordo com os comandos do usuário, adaptando-se a diferentes funções ou cenários.
- interação multilíngueSuporte a chinês, inglês, japonês e outros idiomas para atender às necessidades linguísticas de diferentes usuários.
- Suporte a dialetosCobertura de dialetos chineses como Sichuan e Cantonês para aumentar a aplicabilidade do modelo em regiões específicas.
- controle de emoções ativado por vozPode gerar respostas de voz com emoções específicas com base no contexto e nos comandos do usuário.
- role-playing (jogo)Suporte para desempenhar papéis específicos em um diálogo, por exemplo, atendimento ao cliente, professor, amigo etc., e gerar respostas de voz que correspondam às características do papel.
- Testes de raciocínio lógico e conhecimentoCapacidade de lidar com tarefas complexas de raciocínio lógico e questionários de conhecimento, gerando respostas de voz precisas.
- Saída de voz de alta qualidadeGeração de formas de onda de fala de alta fidelidade, naturais e suaves por meio de um vocoder neural para aprimorar a experiência do usuário.
- coerência fonéticaDiscurso: mantenha a coerência e a consistência do discurso na produção de frases ou parágrafos longos, evitando pausas no discurso ou mudanças abruptas.
- Saída de texto e fala intercaladosSuporte a texto intercalado e saída de voz, permitindo que os usuários escolham respostas de voz ou texto, conforme necessário.
- Compreensão de entrada multimodalCapacidade de entender entradas mistas contendo fala e texto, gerando respostas de fala apropriadas.
Endereço do projeto Step-Audio-AQAA
- Biblioteca do modelo HuggingFace:: https://huggingface.co/stepfun-ai/Step-Audio-AQAA
- Artigo técnico do arXiv:: https://arxiv.org/pdf/2506.08967
Princípios técnicos do Step-Audio-AQAA
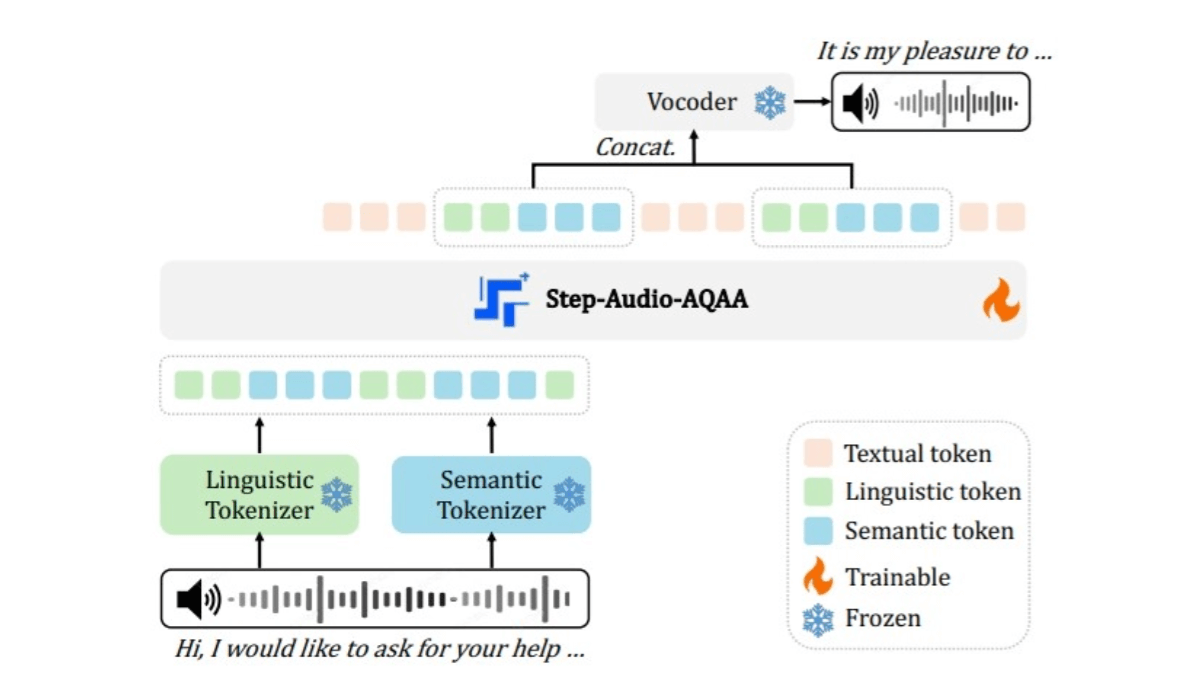
- Divisor de áudio de livro de código duploSinal de áudio de entrada: converte o sinal de áudio de entrada em uma sequência estruturada de tokens. Ele consiste em dois lexers: um lexer linguístico extrai fonemas e atributos linguísticos da fala, amostrados a 16,7 Hz com um tamanho de livro de códigos de 1024, e um lexer semântico captura recursos acústicos da fala, como emoção e entonação, amostrados a 25 Hz com um tamanho de livro de códigos de 4096, que é uma maneira melhor de capturar a complexidade das informações na fala.
- Backbone LLMDados de pré-treinamento: Usando um LLM multimodal pré-treinado de 130 bilhões de parâmetros (Step-Omni), os dados de pré-treinamento abrangem três modalidades: texto, fala e imagem. Os tokens de áudio de texto em bicode são incorporados em um espaço vetorial unificado por meio de vários Transformador blocos para compreensão semântica profunda e extração de recursos.
- vocoder neuralSintetiza os tokens de áudio gerados em formas de onda de fala naturais e de alta qualidade. A arquitetura U-Net, combinada com a camada ResNet-1D e o bloco Transformer, converte com eficiência tokens de áudio discretos em formas de onda de fala contínua.
Benefícios principais do Step-Audio-AQAA
- Interação de áudio de ponta a pontaO Step-Audio-AQAA gera respostas de voz naturais e suaves diretamente da entrada de áudio bruta, eliminando a necessidade de depender dos módulos tradicionais de reconhecimento automático de fala (ASR) e de conversão de texto em fala (TTS). O design de ponta a ponta evita a distorção dos resultados causada por erros no ASR ou no TTS nas soluções tradicionais.
- Suporte a vários idiomasIdiomas: O modelo suporta vários idiomas, inclusive chinês (incluindo sichuanês e cantonês), inglês, japonês etc., o que pode atender às necessidades de idioma de diferentes usuários.
- Controle detalhado dos recursos de vozStep-Audio-AQAA permite o controle refinado de recursos de voz, como entonação emocional, velocidade de fala etc., para gerar respostas de voz mais responsivas. Ele é particularmente bom no controle de emoções de voz.
A quem se destina o Step-Audio-AQAA?
- Usuários de assistentes de voz inteligentesUsuários que desejam usar dispositivos de interação por voz (por exemplo, alto-falantes inteligentes, assistentes inteligentes) para operações diárias (por exemplo, verificar informações, definir lembretes, tocar música etc.).
- entusiasta de jogosJogadores que gostam de interagir com NPCs no jogo para uma experiência de jogo mais imersiva.
- Usuários educacionaisAlunos e pais que desejam aprender por meio de interação por voz (por exemplo, aprendizado de idiomas, testes de conhecimento etc.).
- Idosos e criançasInteração por voz: A interação por voz é mais conveniente e natural para usuários que não são bons em usar entradas de texto.
- criador de audiolivrosCriadores que precisam gerar conteúdo de voz de alta qualidade, como audiolivros, peças de rádio, etc.
- produtor de vídeoCriadores que precisam de interação por voz ou recursos de geração de voz ao produzir conteúdo de vídeo (por exemplo, vídeos curtos, transmissões ao vivo).
© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Artigos relacionados


Nenhum comentário...