
SiliconCloud x FastGPT: permitindo que 200.000 usuários criem uma base de conhecimento de IA exclusiva

O FastGPT é um sistema de perguntas e respostas de base de conhecimento baseado no modelo LLM, desenvolvido pela equipe do Circle Cloud, que fornece processamento de dados pronto para uso, invocação de modelos e outros recursos. O FastGPT recebeu 19,4 mil estrelas no Github.
O SiliconCloud do Silicon Flow é uma grande plataforma de serviço de nuvem de modelos com seu próprio mecanismo de aceleração. O SiliconCloud pode ajudar os usuários a testar e usar modelos de código aberto de forma rápida e de baixo custo. A experiência real é que a velocidade e a estabilidade de seus modelos são muito boas, e eles são ricos em variedade, abrangendo dezenas de modelos, como idiomas, vetores, reordenação, TTS, STT, mapeamento, geração de vídeo etc., que podem satisfazer todas as necessidades de modelos no FastGPT.
Este artigo é um tutorial escrito pela equipe do FastGPT para apresentar uma solução para a implantação do FastGPT no desenvolvimento local usando exclusivamente modelos do SiliconCloud.
1 Obtenção da chave da API da plataforma SiliconCloud
- Abra o site do SiliconCloud e registre-se/conecte-se para obter uma conta.
- Após concluir o registro, abra API Key , crie uma nova chave de API e clique na chave para copiá-la para uso futuro.

2 Modificando as variáveis de ambiente do FastGPT
OPENAI_BASE_URL=https://api.siliconflow.cn/v1 # 填写 SiliconCloud 控制台提供的 Api Key CHAT_API_KEY=sk-xxxxxx
Documentação de desenvolvimento e implantação do FastGPT: https://doc.fastgpt.cn
3 Modificação do arquivo de configuração do FastGPT
Os modelos no SiliconCloud foram selecionados como configurações FastGPT. Aqui, o Qwen2.5 72b é configurado com modelos puros de linguagem e visão; o bge-m3 é selecionado como o modelo de vetor; o bge-reranker-v2-m3 é selecionado como o modelo de reorganização. Escolha fish-speech-1.5 como o modelo de fala; escolha SenseVoiceSmall como o modelo de entrada de fala.
Observação: O modelo ReRank ainda precisa ser configurado com a chave de API uma vez.
{
"llmModels": [
{
"provider": "Other", // 模型提供商,主要用于分类展示,目前已经内置提供商包括:https://github.com/labring/FastGPT/blob/main/packages/global/core/ai/provider.ts, 可 pr 提供新的提供商,或直接填写 Other
"model": "Qwen/Qwen2.5-72B-Instruct", // 模型名(对应OneAPI中渠道的模型名)
"name": "Qwen2.5-72B-Instruct", // 模型别名
"maxContext": 32000, // 最大上下文
"maxResponse": 4000, // 最大回复
"quoteMaxToken": 30000, // 最大引用内容
"maxTemperature": 1, // 最大温度
"charsPointsPrice": 0, // n积分/1k token(商业版)
"censor": false, // 是否开启敏感校验(商业版)
"vision": false, // 是否支持图片输入
"datasetProcess": true, // 是否设置为文本理解模型(QA),务必保证至少有一个为true,否则知识库会报错
"usedInClassify": true, // 是否用于问题分类(务必保证至少有一个为true)
"usedInExtractFields": true, // 是否用于内容提取(务必保证至少有一个为true)
"usedInToolCall": true, // 是否用于工具调用(务必保证至少有一个为true)
"usedInQueryExtension": true, // 是否用于问题优化(务必保证至少有一个为true)
"toolChoice": true, // 是否支持工具选择(分类,内容提取,工具调用会用到。)
"functionCall": false, // 是否支持函数调用(分类,内容提取,工具调用会用到。会优先使用 toolChoice,如果为false,则使用 functionCall,如果仍为 false,则使用提示词模式)
"customCQPrompt": "", // 自定义文本分类提示词(不支持工具和函数调用的模型
"customExtractPrompt": "", // 自定义内容提取提示词
"defaultSystemChatPrompt": "", // 对话默认携带的系统提示词
"defaultConfig": {}, // 请求API时,挟带一些默认配置(比如 GLM4 的 top_p)
"fieldMap": {} // 字段映射(o1 模型需要把 max_tokens 映射为 max_completion_tokens)
},
{
"provider": "Other",
"model": "Qwen/Qwen2-VL-72B-Instruct",
"name": "Qwen2-VL-72B-Instruct",
"maxContext": 32000,
"maxResponse": 4000,
"quoteMaxToken": 30000,
"maxTemperature": 1,
"charsPointsPrice": 0,
"censor": false,
"vision": true,
"datasetProcess": false,
"usedInClassify": false,
"usedInExtractFields": false,
"usedInToolCall": false,
"usedInQueryExtension": false,
"toolChoice": false,
"functionCall": false,
"customCQPrompt": "",
"customExtractPrompt": "",
"defaultSystemChatPrompt": "",
"defaultConfig": {}
}
],
"vectorModels": [
{
"provider": "Other",
"model": "Pro/BAAI/bge-m3",
"name": "Pro/BAAI/bge-m3",
"charsPointsPrice": 0,
"defaultToken": 512,
"maxToken": 5000,
"weight": 100
}
],
"reRankModels": [
{
"model": "BAAI/bge-reranker-v2-m3", // 这里的model需要对应 siliconflow 的模型名
"name": "BAAI/bge-reranker-v2-m3",
"requestUrl": "https://api.siliconflow.cn/v1/rerank",
"requestAuth": "siliconflow 上申请的 key"
}
],
"audioSpeechModels": [
{
"model": "fishaudio/fish-speech-1.5",
"name": "fish-speech-1.5",
"voices": [
{
"label": "fish-alex",
"value": "fishaudio/fish-speech-1.5:alex",
"bufferId": "fish-alex"
},
{
"label": "fish-anna",
"value": "fishaudio/fish-speech-1.5:anna",
"bufferId": "fish-anna"
},
{
"label": "fish-bella",
"value": "fishaudio/fish-speech-1.5:bella",
"bufferId": "fish-bella"
},
{
"label": "fish-benjamin",
"value": "fishaudio/fish-speech-1.5:benjamin",
"bufferId": "fish-benjamin"
},
{
"label": "fish-charles",
"value": "fishaudio/fish-speech-1.5:charles",
"bufferId": "fish-charles"
},
{
"label": "fish-claire",
"value": "fishaudio/fish-speech-1.5:claire",
"bufferId": "fish-claire"
},
{
"label": "fish-david",
"value": "fishaudio/fish-speech-1.5:david",
"bufferId": "fish-david"
},
{
"label": "fish-diana",
"value": "fishaudio/fish-speech-1.5:diana",
"bufferId": "fish-diana"
}
]
}
],
"whisperModel": {
"model": "FunAudioLLM/SenseVoiceSmall",
"name": "SenseVoiceSmall",
"charsPointsPrice": 0
}
}
4 Reinicie o FastGPT
5 Teste de experiência
Teste o diálogo e o reconhecimento de imagens
Sinta-se à vontade para criar um novo aplicativo simples, selecionar o modelo correspondente e testá-lo com o upload de imagens ativado.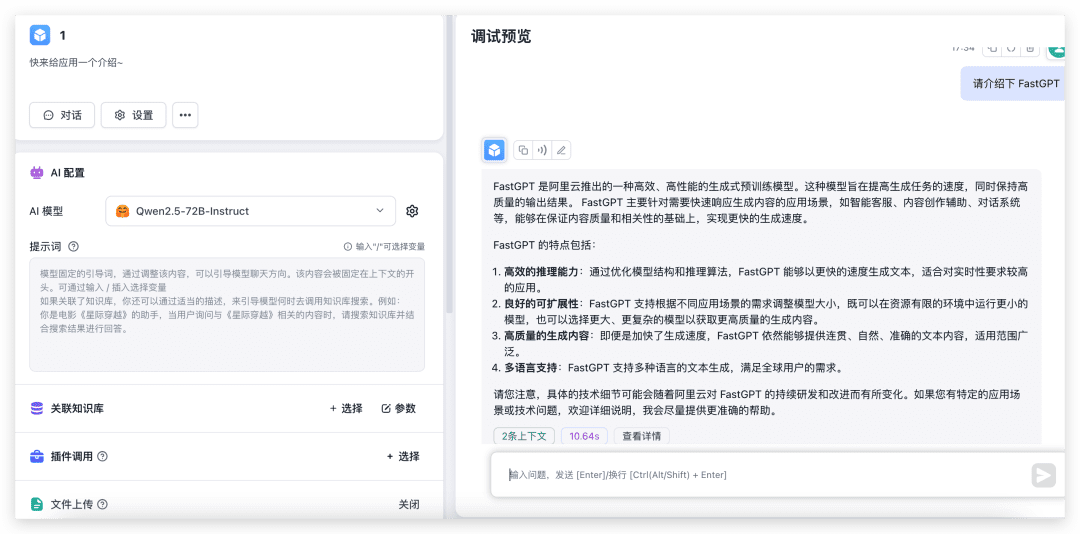
Como você pode ver, o desempenho do modelo 72B é muito rápido e, se não houver alguns 4090 locais, sem mencionar a configuração do ambiente, temo que a saída demore 30s.
Teste a Importação da Base de Conhecimento e o Questionário da Base de Conhecimento
Crie uma nova base de conhecimento (como apenas um modelo vetorial está configurado, a seleção do modelo vetorial não será exibida na página).
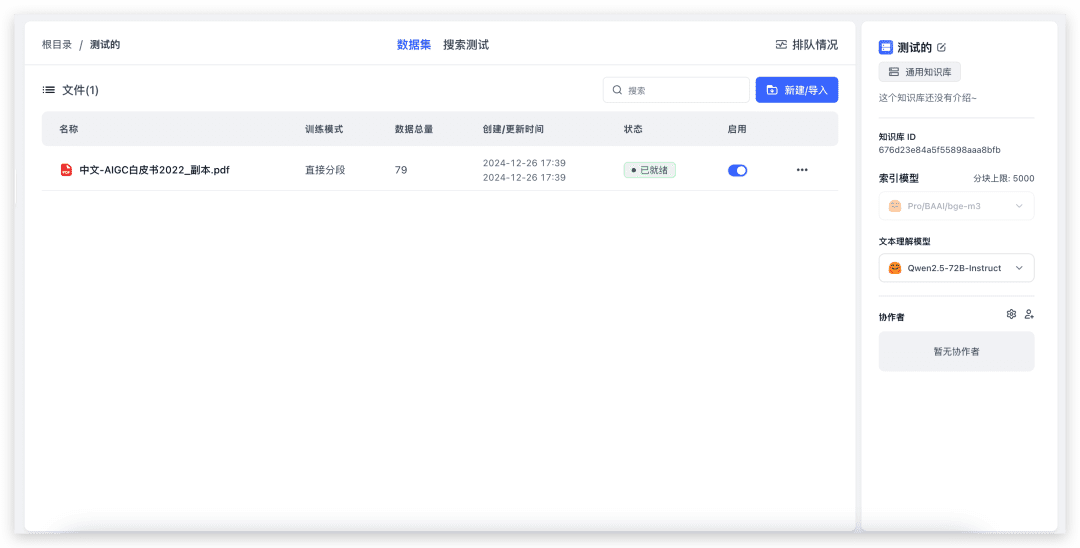
Para importar um arquivo local, basta selecionar o arquivo e ir até o próximo. 79 índices e levou cerca de 20 segundos para ser concluído. Agora vamos testar o questionário da Base de Conhecimento.
Primeiro, volte ao aplicativo que acabamos de criar, selecione Knowledge Base, ajuste os parâmetros e inicie o diálogo.
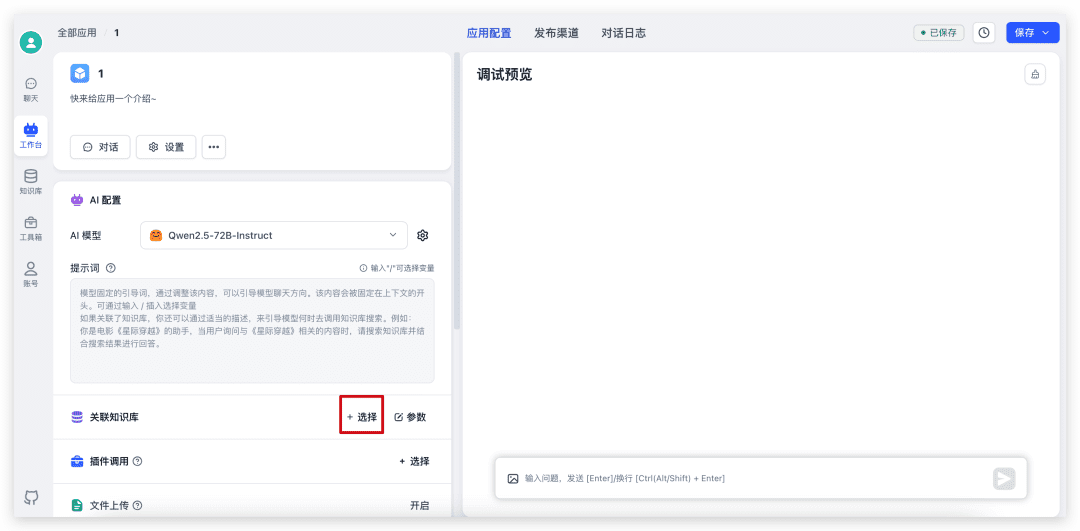
Quando o diálogo estiver concluído, clique na citação na parte inferior para visualizar os detalhes da citação, bem como para ver as pontuações específicas de recuperação e reordenação.
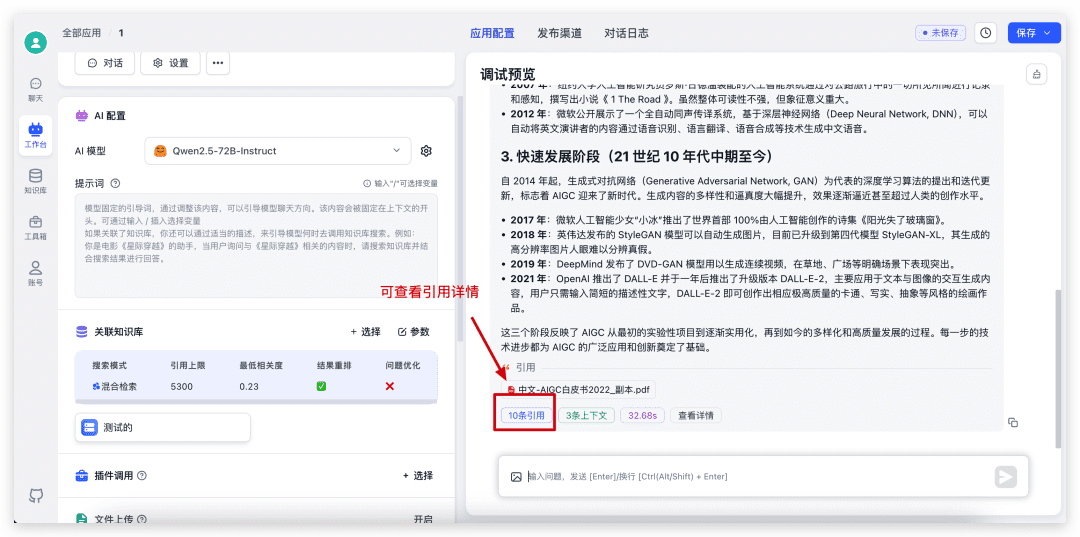
Teste a reprodução de voz
Continuando no aplicativo agora, encontre o Voice Play no lado esquerdo da configuração e clique nele para selecionar um modelo de voz na janela pop-up e experimentá-lo.
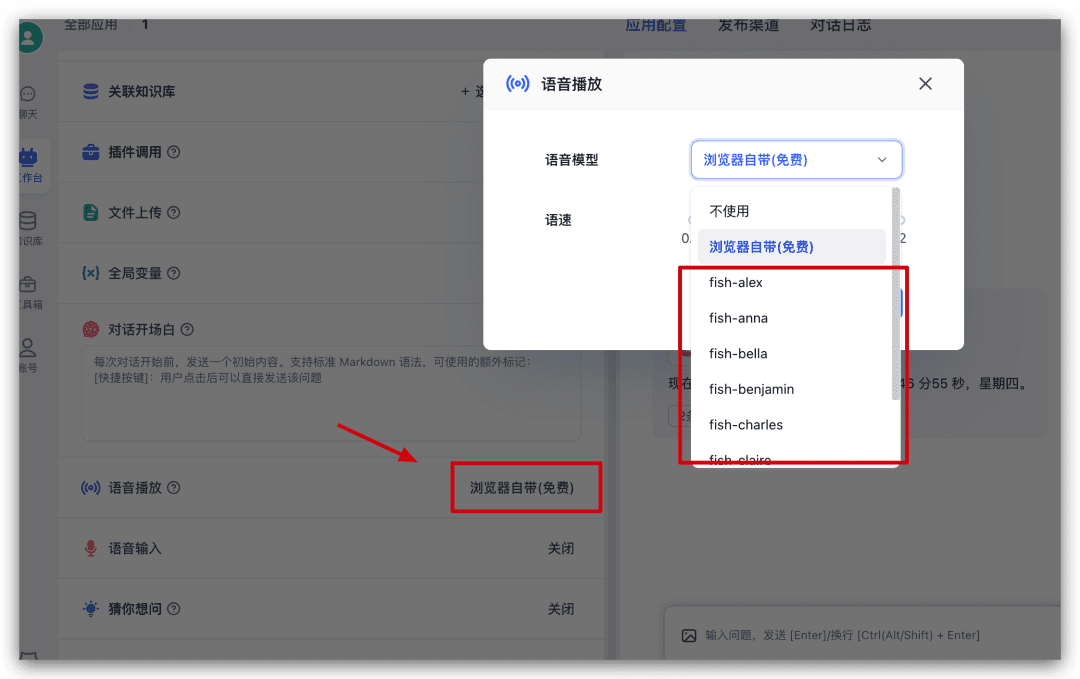
Entrada de idioma de teste
Vá em frente e encontre a entrada de voz na configuração do lado esquerdo do aplicativo e clique nela para ativar a entrada de idioma na janela pop-up.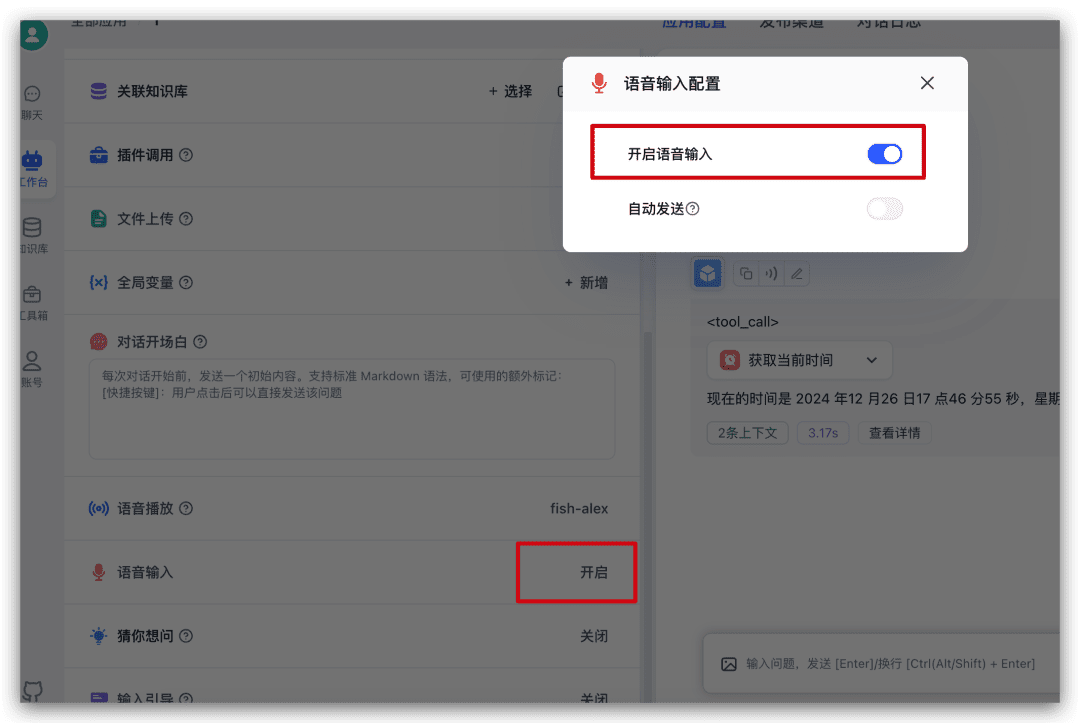
Quando estiver ativado, na caixa de entrada de diálogo, um ícone de microfone será adicionado, e você poderá clicar nele para fazer a entrada de voz.
resumos
Se você quiser experimentar rapidamente o modelo de código aberto ou usar rapidamente o FastGPT e não quiser solicitar todos os tipos de chave de API em diferentes provedores de serviços, poderá escolher o modelo do SiliconCloud para uma experiência rápida.
© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Artigos relacionados




Nenhum comentário...