
O primeiro grande modelo de raciocínio do setor financeiro de código aberto Regulus-FinX1! Produção pesada de Du Xiaoman, com foco na análise de complexos financeiros e na tomada de decisões
Du Xiaoman abre o código-fonte do primeiro grande modelo do mundo de raciocínio do setor financeiro - Regulus-FinX1!
O modelo é o primeiro macromodelo de inferência do tipo GPT-O1 no domínio financeiro, usando um inovador"Cadeia de pensamento + recompensas do processo + aprendizado por reforço"O paradigma de treinamento melhora significativamente o raciocínio lógico e pode demonstrar o processo de pensamento completo não revelado pelo modelo O1, fornecendo percepções mais profundas para a tomada de decisões financeiras. Objetivos do Regulus-FinX1Tarefas de análise, tomada de decisões e processamento de dados em cenários financeirosFoi realizada uma otimização profunda.
O Xuan Yuan-FinX1 foi desenvolvido pelo Du Xiaoman AI-Lab, e este lançamento é uma versão prévia, que agora está aberta na comunidade de código abertoDownload gratuito. As versões otimizadas subsequentes também continuarão a ser de código aberto para download e uso.
Endereço do Github: https://github.com/Duxiaoman-DI/XuanYuan
Resultados de benchmarking
O Regulus-FinX1 de primeira geração demonstrou excelente desempenho no FinanceIQ, um benchmark financeiro. NoCPA, qualificação bancária10 tipos de qualificações financeiras, como qualificações em títulos, etc.Na categoria de Atuários, as pontuações de todos os grandes modelos anteriores são geralmente baixas, enquanto o XuanYuan-FinX1 melhorou significativamente sua pontuação de 37,5 para 65,7, o que mostra que ele pode ser usado para raciocínio lógico financeiro e raciocínio matemático, e pode ser usado para raciocínio lógico financeiro e raciocínio matemático. Especialmente na categoria Atuário, todos os grandes modelos anteriores geralmente tiveram pontuação baixa, enquanto o XuanYuan-FinX1 melhorou sua pontuação de 37,5 para 65,7, o que demonstrou significativamente sua grande vantagem em raciocínio lógico financeiro e computação matemática. 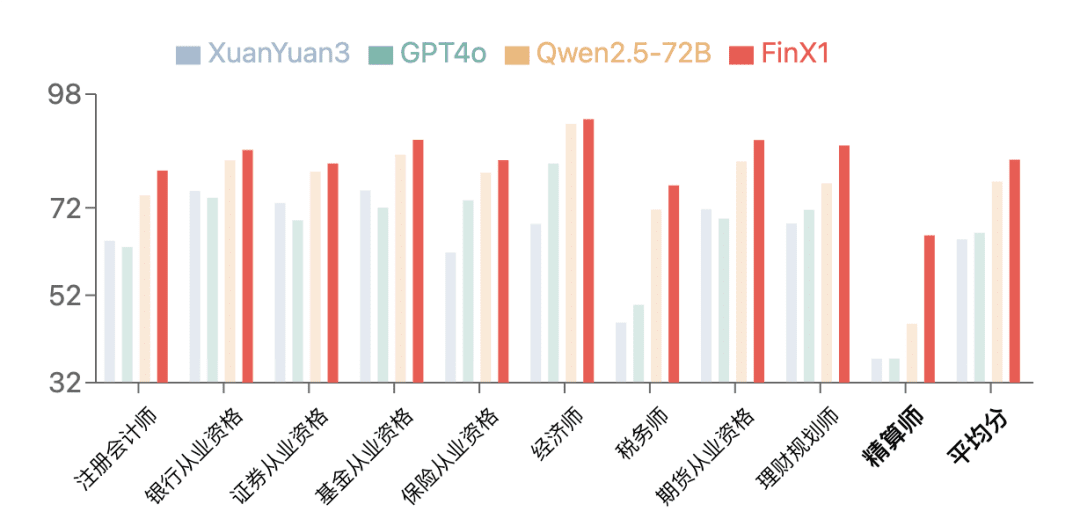
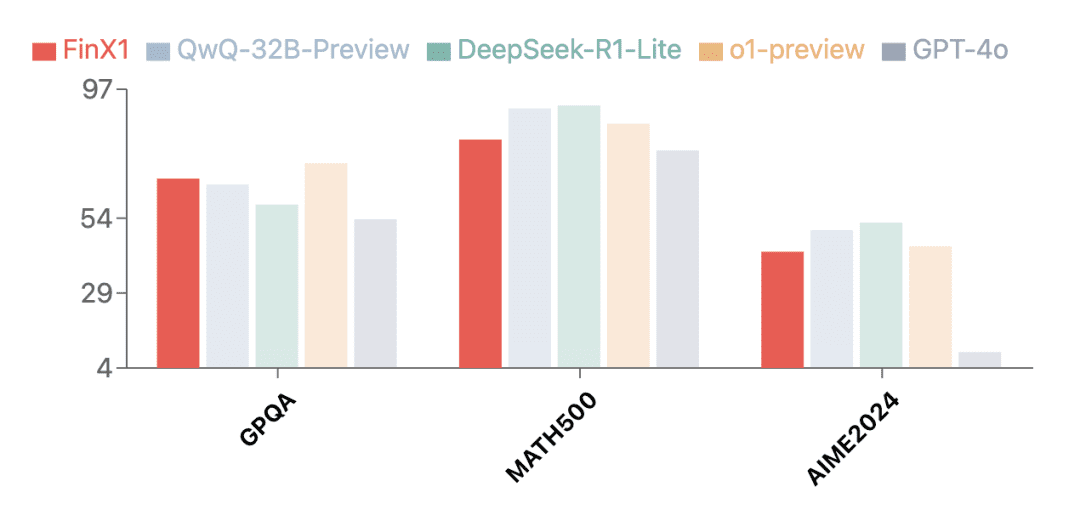
Além do campo financeiro, o Regulus-FinX1 de primeira geração também demonstrou excelentes recursos de uso geral. Os resultados dos testes em vários conjuntos de avaliação confiáveis mostram que o Regulus-FinX1 não está apenas naGPQA (Raciocínio Científico)eMATH-500 (Matemática)responder cantandoAIME2024 (Competição de Matemática)Ele também ultrapassou o GPT-4o, classificando-se no escalão superior junto com o O1 e a versão de inferência recém-lançada do Big Model na China, o que comprova sua forte capacidade de inferência básica.
Quebrando a "caixa preta": apresentando a cadeia completa de pensamento
Uma das características do Regulus FinX1 é que ele pode apresentar todo o processo de raciocínio antes de gerar uma resposta, criando uma cadeia de raciocínio totalmente transparente, desde a desmontagem do problema até a conclusão final. Por meio desse mecanismo, o Regulus FinX1 não apenas melhora a interpretabilidade do raciocínio, mas também resolve o problema da "caixa preta" dos grandes modelos tradicionais, oferecendo às instituições financeiras uma ferramenta de apoio à decisão mais confiável.

Regulus Exemplo de geração de cadeia de pensamento para FinX1
Foco na complexidade financeira e na tomada de decisões analíticas
Quando o GPT-O1 da OpenAI chamou a atenção do setor com seu "poder de raciocínio" superior, surgiu uma proposta importante:Como esse recurso de raciocínio profundo pode criar um valor substancial em cenários profissionais financeiros?Du Xiaoman Regulus FinX1 dá respostas inovadoras -Pela primeira vez, o recurso de raciocínio profundo dos grandes modelos foi injetado no domínio financeiro, promovendo, assim, a aplicação de grandes modelos ao setor financeiro.Use para aprofundar desde cenários genéricos até níveis de negócios essenciais, como decisões de controle de risco.
Na onda de transformação da inteligência digital no setor financeiro, a"Recursos de tomada de decisão e controle de riscos", "recursos de pesquisa e análise" e "recursos de inteligência de dados"constituem as principais dimensões que impulsionam a inovação empresarial e o aumento de valor. Esses recursos trazem um crescimento sustentado de valor para a instituição por meio da identificação e do controle precisos de riscos, da pesquisa aprofundada de mercado e da descoberta de valor, além da modelagem e da análise eficientes de dados, respectivamente.
O Regulus FinX1 integra profundamente os recursos de raciocínio profundo com a experiência financeira por meio de um paradigma de treinamento inovador, permitindo que esses três recursos sejam totalmente liberados em cenários específicos e trazendo novas soluções inteligentes para o setor financeiro.

01 Capacidade de tomada de decisões e controle de riscos
A capacidade de tomada de decisões e de controle de riscos é a tábua de salvação das instituições financeiras, o que está relacionado à sua operação sólida e ao seu desenvolvimento sustentável. Nas principais tarefas de identificação e previsão de riscos, construção de modelos de controle de riscos e formulação de estratégias, o Regulus FinX1 pode analisar sistematicamente a correlação e os caminhos de condução entre os fatores de risco com sua poderosa capacidade de raciocínio e mecanismo completo de cadeia mental, fornecendo às instituições percepções de risco abrangentes e profundas. Por exemplo, com base na água do banco carregada pela autorização do usuário, o Regulus FinX1 é capaz de identificar com precisão sinais de risco, como consumo de loteria de alta frequência, consumo de jogos, etc., a partir de milhares de registros de transações e avaliar cientificamente a capacidade de pagamento do usuário e o risco de crédito em conjunto com o nível de renda e o ônus da dívida.

Regulus FinX1 respondeu ao clipe
02 Capacidade analítica e de pesquisa
A capacidade de pesquisa e análise é o suporte básico para a tomada de decisões financeiras, que aprimora a ciência da alocação de capital por meio de percepções aprofundadas em nível macro, setorial e empresarial. O Regulus FinX1 é capaz de realizar análises multidimensionais de dados macroeconômicos, sentimento do mercado, impactos de políticas, etc., e desmontar gradualmente questões complexas por meio de uma cadeia lógica clara. Por exemplo, ao prever o corte da taxa de juros do Fed em 2025 com base em dados econômicos, o modelo explora uma ampla gama de possibilidades por meio da análise de diversos fatores econômicos e com base em diferentes cenários hipotéticos, demonstrando de forma abrangente e objetiva a perspectiva de um corte da taxa de juros do Fed em 2025, o que atualmente está de acordo com as visões analíticas preditivas de várias instituições. 
03 Recursos de inteligência de dados
A capacidade de inteligência de dados é um suporte importante para que as instituições financeiras tomem decisões precisas, cujo núcleo é a capacidade eficiente de processamento de dados e a capacidade de análise aprofundada. O Regulus FinX1 pode ajudar as instituições financeiras a explorar rapidamente a lógica e o valor comercial por trás dos dados. Por exemplo, se os dados financeiros trimestrais de uma empresa forem inseridos no Regulus FinX1, o modelo poderá extrair com precisão as principais informações e exibir visualmente a qualidade dos ativos, a liquidez e a dinâmica dos negócios. Ao analisar os principais indicadores, como "pressão de liquidez" e "impulso de expansão de ativos", o Regulus FinX1 acrescenta explicações qualitativas com base em comparações quantitativas, revelando riscos potenciais e oportunidades de crescimento por trás dos dados financeiros e ajudando as empresas a otimizar suas tomadas de decisão. 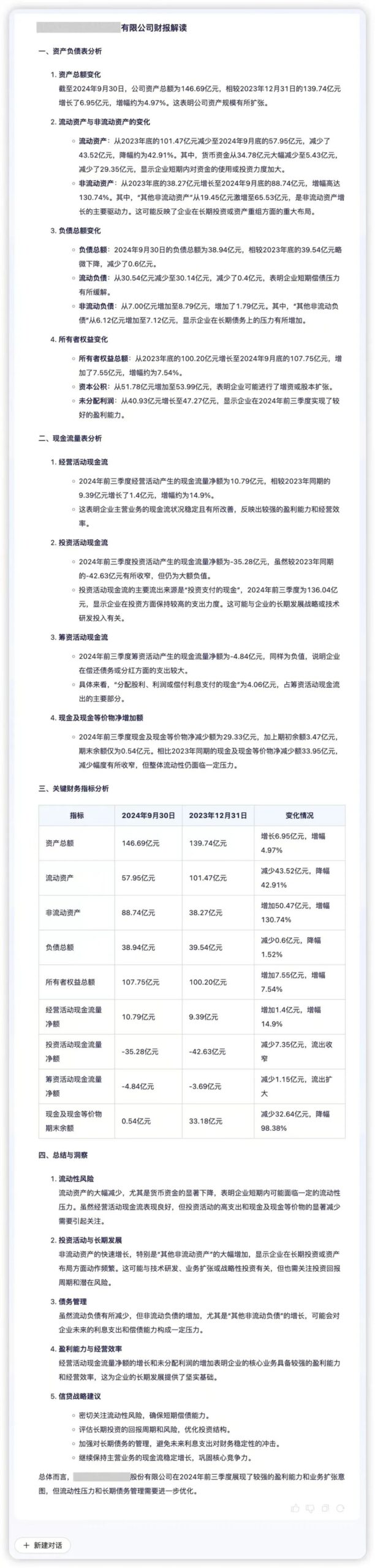
Implementação técnica do Regulus-FinX1
Para obter modelos grandes com recursos de raciocínio do tipo O1, especialmente em cenários de análise de decisões complexas no domínio financeiro, propomos uma solução técnica que contém três etapas principais após ampla exploração e validação:Em direção a um modelo estável de geração de cadeia de pensamento, um modelo de recompensa dupla para aprimoramento de decisões financeiras e ajuste fino do aprendizado por reforço sob orientação dupla de PRM e ORM.
01 Construção inicial de um modelo gerador estável da cadeia de pensamento
Para os cenários complexos de análise de decisão no domínio financeiro, construímos um modelo básico com capacidade de geração de cadeia de pensamento estável. A primeira etapa é a síntese de dados de COT/Resposta de alta qualidade, que primeiro gera o processo de raciocínio com base na pergunta e, em seguida, gera a resposta final com base na pergunta e no processo de raciocínio. Com essa estratégia, o modelo pode se concentrar em cada estágio da tarefa e gerar cadeias de raciocínio e respostas mais coerentes.
Para diferentes domínios (por exemplo, matemática, raciocínio lógico, análise financeira etc.), projetamos métodos especiais de síntese de dados, por exemplo, para tarefas de análise financeira, projetamos um método de síntese iterativa para garantir a abrangência do processo de análise e, em seguida, treinamos o modelo com base no modelo XuanYuan 3.0 usando o ajuste fino do comando e usando um formato de saída unificado de processo de pensamento resposta (também divulgaremos os nós de pensamento de granularidade grossa desta vez) e, ao mesmo tempo, nos concentramos na construção de um número maior de dados de texto longo para aprimorar a capacidade do modelo de processar contextos longos, de modo que ele possa "gerar um processo de pensamento detalhado antes de gerar uma resposta". Isso estabelece uma base sólida para o treinamento supervisionado por processos subsequentes e para a otimização do aprendizado por reforço.
02 Um modelo de dupla recompensa para aprimoramento de decisões financeiras
Para avaliar o desempenho do modelo em cenários de tomada de decisões financeiras, projetamos oDois modelos de recompensa complementares, orientados para resultados (ORM) e em nível de processo (PRM). Entre eles, o ORM dá continuidade à solução técnica do XuanYuan 3.0, que é treinado pelo aprendizado por contraste e pelo aprendizado por reforço inverso; o PRM é nossa inovação para o processo de raciocínio, que se concentra em resolver a dificuldade de avaliar problemas financeiros abertos (por exemplo, análise de mercado, decisões de investimento etc.).
Para a construção de dados de treinamento do PRM, adotamos diferentes estratégias para diferentes cenários: para perguntas com respostas definidas, como classificações de risco, usamos um método de validação reversa com base no MCTS; para perguntas abertas de análise financeira, nós as anotamos em termos de dimensões como correção, necessidade e lógica por meio de vários modelos grandes e resolvemos o problema de desequilíbrio de dados por meio de redução de amostragem e aprendizagem ativa. Durante o treinamento, o PRM usa o ajuste fino supervisionado para otimizar o modelo, pontuando cada etapa de raciocínio.03 Ajuste fino do aprendizado por reforço com orientação dupla de PRM e ORMNa fase de aprendizado por reforço, usamos o algoritmo PPO para otimização do modelo, que usa PRM e ORM como sinais de recompensa. Para o processo de raciocínio entre e , o PRM é usado para pontuar cada etapa do raciocínio, de modo que os erros no caminho do raciocínio possam ser detectados e corrigidos em tempo hábil; para a parte da resposta, diferentes estratégias de avaliação são usadas para diferentes tipos de perguntas: a correspondência de regras é usada para calcular as recompensas para perguntas financeiras com uma resposta definida (por exemplo, avaliação do nível de risco) e a correspondência de regras é usada para calcular as recompensas para perguntas abertas ( Por exemplo, análises de mercado) são pontuadas de forma holística usando ORM. Técnicas como coeficientes KL dinâmicos e normalização da função de dominância são introduzidas simultaneamente para estabilizar o processo de treinamento. EsseMecanismos de treinamento baseados em recompensas duplasque não apenas supera as limitações de um modelo de recompensa única, mas também melhora significativamente a capacidade de raciocínio do modelo em cenários de tomada de decisões financeiras por meio de treinamento estável de aprendizado por reforço.
Como se pode ver, a chave da rota acima é a construção de dados da cadeia de pensamento e a avaliação de modelos de recompensa para problemas em aberto na análise financeira que são diferentes da matemática ou da lógica, e ainda estamos otimizando e iterando, e continuaremos a explorar rotas técnicas mais eficazes.
© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Artigos relacionados




Nenhum comentário...