Implementação rápida do RAG 3-Pack para Dify com GPUStack
GPUStack Trata-se de uma plataforma de big model como serviço de código aberto que pode integrar e utilizar com eficiência vários recursos heterogêneos de GPU/NPU, como Nvidia, Apple Metal, Huawei Rise e Moore Threads, para oferecer implementação privada local de soluções de big model.
O GPUStack pode oferecer suporte a RAG Os três principais modelos exigidos pelo sistema: o modelo de diálogo de bate-papo (um modelo de linguagem grande), o modelo de incorporação de texto e o modelo de reordenação de classificação estão disponíveis em um conjunto de três peças, e é uma operação muito simples e infalível implantar os modelos privados locais exigidos pelo sistema RAG.
Veja como instalar o GPUStack e o Dify com o Dify para fazer a interface com o modelo de diálogo, o modelo de incorporação e o modelo de classificação implementado pelo GPUStack.
Instalação do GPUStack
Instale-o on-line no Linux ou macOS com o seguinte comando; é necessária uma senha sudo durante o processo de instalação: curl -sfL https://get.gpustack.ai | sh -
Se você não conseguir se conectar ao GitHub para baixar alguns binários, use os seguintes comandos para instalá-los com o --tools-download-base-url O parâmetro especifica o download a partir do Tencent Cloud Object Storage:curl -sfL https://get.gpustack.ai | sh - --tools-download-base-url "https://gpustack-1303613262.cos.ap-guangzhou.myqcloud.com"
Execute o Powershell como administrador no Windows e instale-o on-line com o seguinte comando:Invoke-Expression (Invoke-WebRequest -Uri "https://get.gpustack.ai" -UseBasicParsing).Content
Se você não conseguir se conectar ao GitHub para baixar alguns binários, use os seguintes comandos para instalá-los com o --tools-download-base-url O parâmetro especifica o download a partir do Tencent Cloud Object Storage:Invoke-Expression "& { $((Invoke-WebRequest -Uri 'https://get.gpustack.ai' -UseBasicParsing).Content) } --tools-download-base-url 'https://gpustack-1303613262.cos.ap-guangzhou.myqcloud.com'"
Quando você vir a seguinte saída, o GPUStack foi implantado e iniciado com sucesso:
[INFO] Install complete. GPUStack UI is available at http://localhost. Default username is 'admin'. To get the default password, run 'cat /var/lib/gpustack/initial_admin_password'. CLI "gpustack" is available from the command line. (You may need to open a new terminal or re-login for the PATH changes to take effect.)
Em seguida, siga as instruções na saída do script para obter a senha inicial para fazer login no GPUStack e execute o seguinte comando:
no Linux ou macOS:cat /var/lib/gpustack/initial_admin_password
No Windows:Get-Content -Path (Join-Path -Path $env:APPDATA -ChildPath "gpustackinitial_admin_password") -Raw
Acesse a UI do GPUStack em um navegador com o nome de usuário admin e a senha como a senha inicial obtida acima.
Após redefinir a senha, digite GPUStack: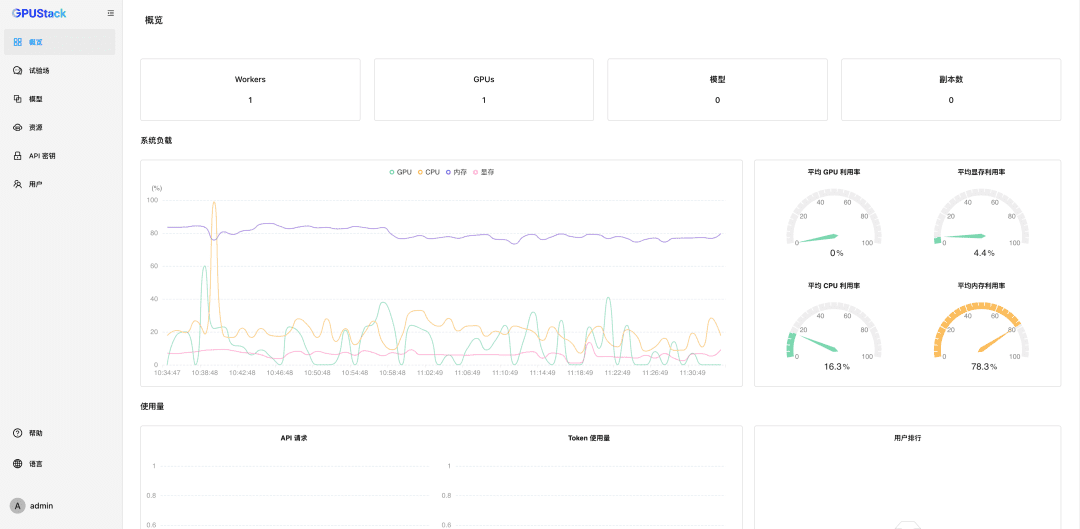
Recursos de GPU de nanogerenciamento
O GPUStack oferece suporte a recursos de GPU para dispositivos Linux, Windows e macOS e gerencia esses recursos de GPU seguindo estas etapas.
Outros nós precisam ser autenticados Token Entre no cluster do GPUStack e execute o seguinte comando no nó do servidor GPUStack para obter um token:
no Linux ou macOS:cat /var/lib/gpustack/token
No Windows:Get-Content -Path (Join-Path -Path $env:APPDATA -ChildPath "gpustacktoken") -Raw
Depois de obter o token, execute o seguinte comando nos outros nós para adicionar o Worker ao GPUStack e gerencie as GPUs nesses nós (substitua http://YOUR_IP_ADDRESS pelo seu endereço de acesso ao GPUStack e YOUR_TOKEN pelo token de autenticação usado para adicionar o Worker):
no Linux ou macOS:curl -sfL https://get.gpustack.ai | sh - --server-url http://YOUR_IP_ADDRESS --token YOUR_TOKEN --tools-download-base-url "https://gpustack-1303613262.cos.ap-guangzhou.myqcloud.com"
No Windows:Invoke-Expression "& { $((Invoke-WebRequest -Uri "https://get.gpustack.ai" -UseBasicParsing).Content) } --server-url http://YOUR_IP_ADDRESS --token YOUR_TOKEN --tools-download-base-url 'https://gpustack-1303613262.cos.ap-guangzhou.myqcloud.com'"
Com as etapas acima, criamos um ambiente GPUStack e gerenciamos vários nós de GPU, que podem ser usados para implantar grandes modelos privados.
Implantação de macromodelos privados
Visite o GPUStack e implemente modelos no menu Modelos. O GPUStack suporta a implementação de modelos do HuggingFace, da Biblioteca Ollama, do ModelScope e de repositórios de modelos privados; o ModelScope é recomendado para redes domésticas.
Suporte ao GPUStack vLLM O vLLM é otimizado para inferência de produção e é mais adequado às necessidades de produção em termos de concorrência e desempenho, mas o vLLM só é compatível com o Linux. O llama-box é um mecanismo de inferência flexível e compatível com várias plataformas que é llama.cpp Ele é compatível com os sistemas Linux, Windows e macOS e suporta não apenas ambientes de GPU, mas também ambientes de CPU para a execução de modelos grandes, o que o torna mais adequado para cenários que exigem compatibilidade com várias plataformas.
O GPUStack seleciona automaticamente o back-end de inferência apropriado com base no tipo de arquivo de modelo ao implantá-lo. O GPUStack usa o llama-box como back-end para executar o serviço de modelo se o modelo estiver no formato GGUF e o vLLM como back-end para executar o serviço de modelo se ele estiver em um formato não-GGUF.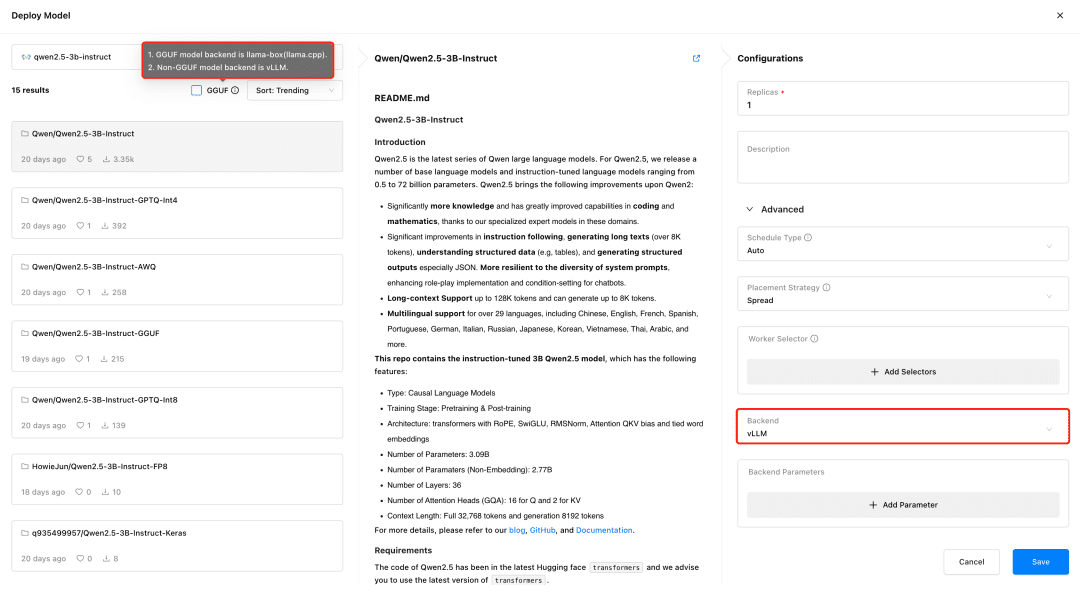
Implante o modelo de diálogo de texto, o modelo de incorporação de texto e o modelo Reranker necessários para o acoplamento do Dify e lembre-se de verificar o formato GGUF ao implantar:
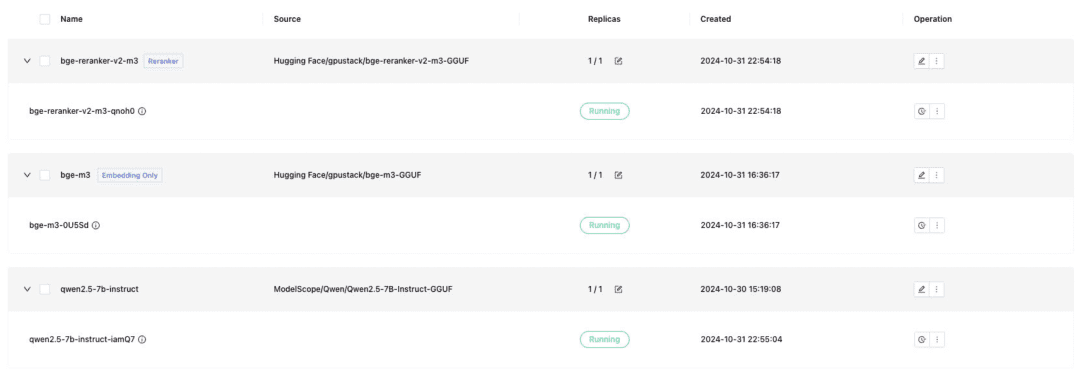
- Qwen/Qwen2.5-7B-Instruct-GGUF
- gpustack/bge-m3-GGUF
- gpustack/bge-reranker-v2-m3-GGUF
O GPUStack também oferece suporte a modelos multimodais VLM, cuja implantação requer o uso de um backend de inferência vLLM:
Qwen2-VL-2B-Instrução 

Depois que o modelo é implantado, um sistema RAG ou outro aplicativo de IA generativo pode fazer interface com o modelo implantado do GPUStack por meio da API compatível com OpenAI/Jina fornecida pelo GPUStack, seguida pelo Dify para fazer interface com o modelo implantado do GPUStack.
Modelos GPUStack de integração Dify
Instalar o Dify
Para executar o Dify usando o Docker, você precisa preparar um ambiente do Docker e tomar cuidado para evitar conflitos entre o Dify e a porta 80 do GPUStack, usar outros hosts ou modificar a porta. Execute o seguinte comando para instalar o Dify:git clone -b 0.10.1 https://github.com/langgenius/dify.gitVisite a interface de usuário da Dify em http://localhost para inicializar a conta de administrador e fazer login.
cd dify/docker/
cp .env.example .env
docker compose up -d
Para integrar um modelo GPUStack, primeiro adicione um modelo de diálogo do Chat. No canto superior direito do Dify, selecione "Settings - Model Providers" (Configurações - Provedores de modelos), localize o tipo GPUStack na lista e selecione Add Model (Adicionar modelo):
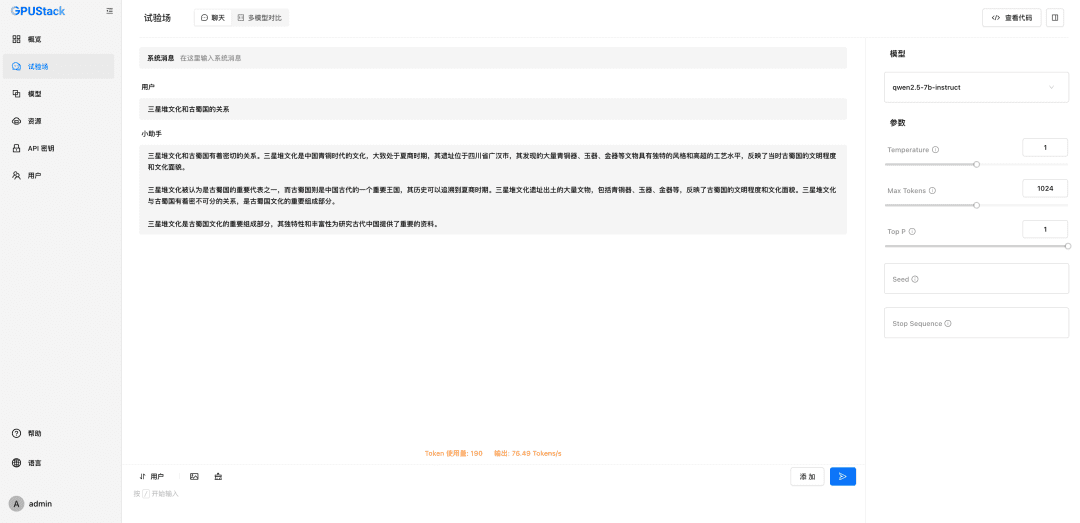
Preencha o nome do modelo LLM implantado no GPUStack (por exemplo, qwen2.5-7b-instruct), o endereço de acesso do GPUStack (por exemplo, http://192.168.0.111) e a chave de API gerada, além dos comprimentos de contexto das configurações do modelo 8192 e max tokens 2048: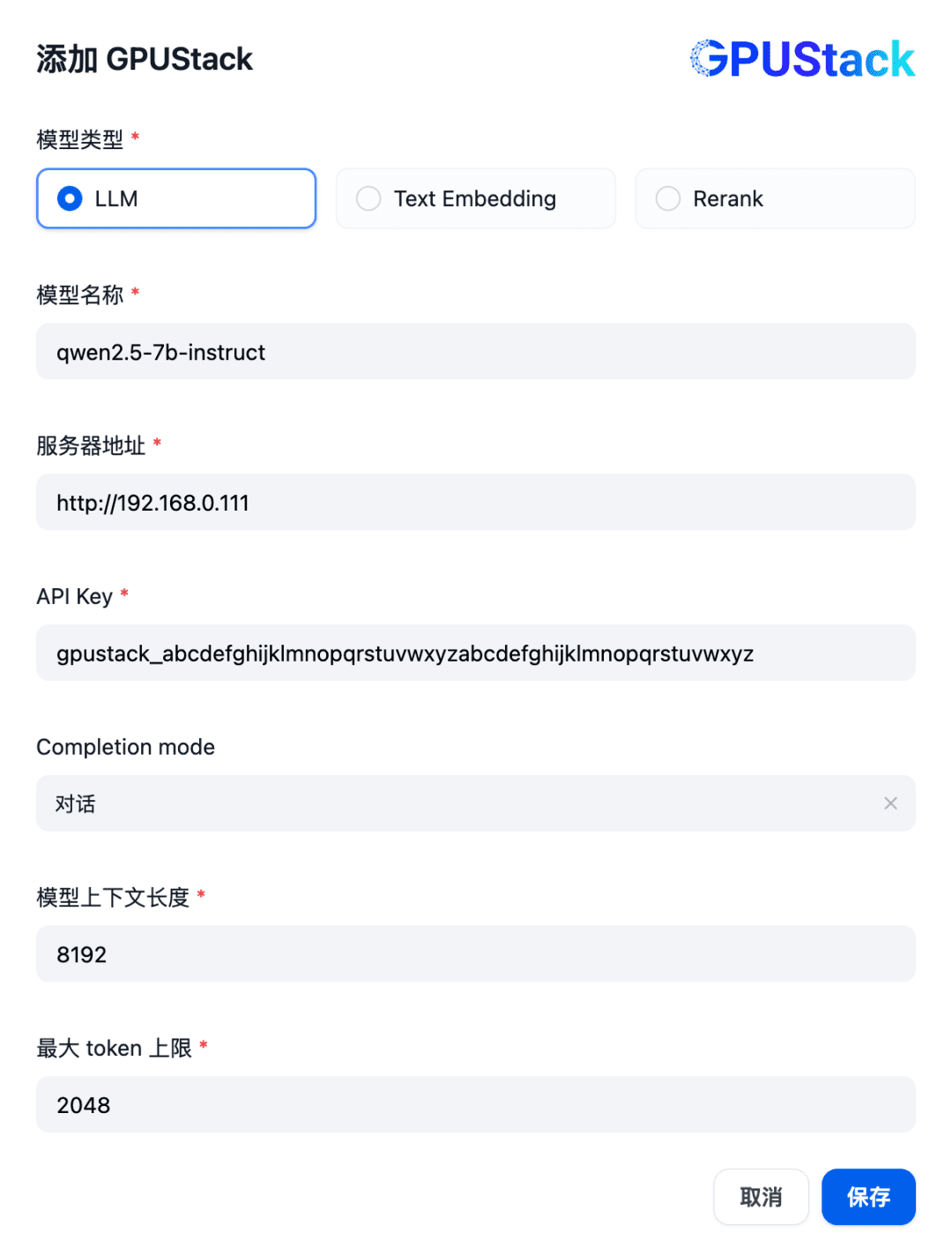
Em seguida, adicione o modelo de incorporação. Na parte superior do provedor de modelos, selecione o tipo GPUStack e selecione Adicionar modelo: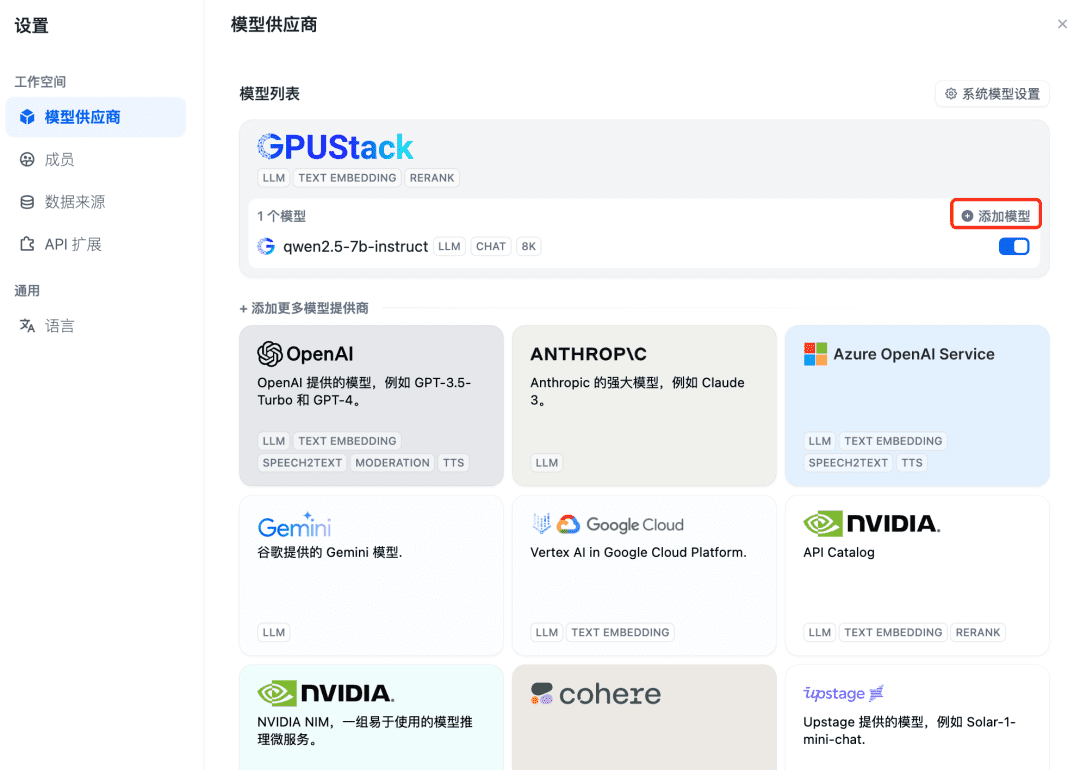
Adicione um modelo do tipo Text Embedding, preenchendo o nome do modelo Embedding implantado no GPUStack (por exemplo, bge-m3), o endereço de acesso do GPUStack (por exemplo, http://192.168.0.111) e a chave de API gerada, além de um comprimento de contexto de 8192 para as configurações do modelo: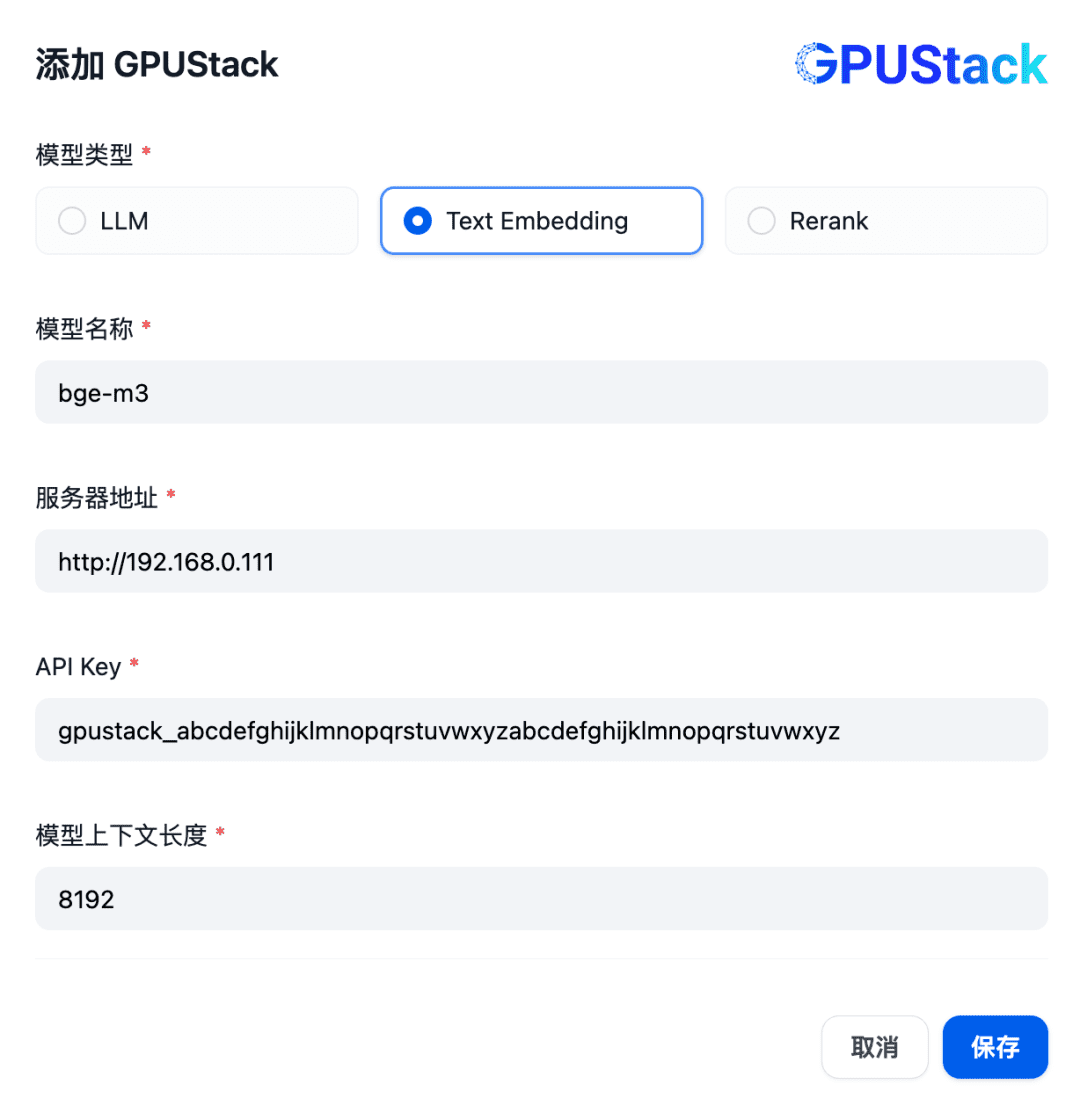
Em seguida, para adicionar um modelo de Rerank, selecione o tipo de GPUStack, selecione Add Model, adicione um modelo do tipo Rerank, preencha o nome do modelo de Rerank implementado no GPUStack (por exemplo, bge-reranker-v2-m3), o endereço de acesso do GPUStack (por exemplo, http://192.168. 0.111) e a chave de API gerada, bem como o comprimento do contexto 8192 para as configurações do modelo: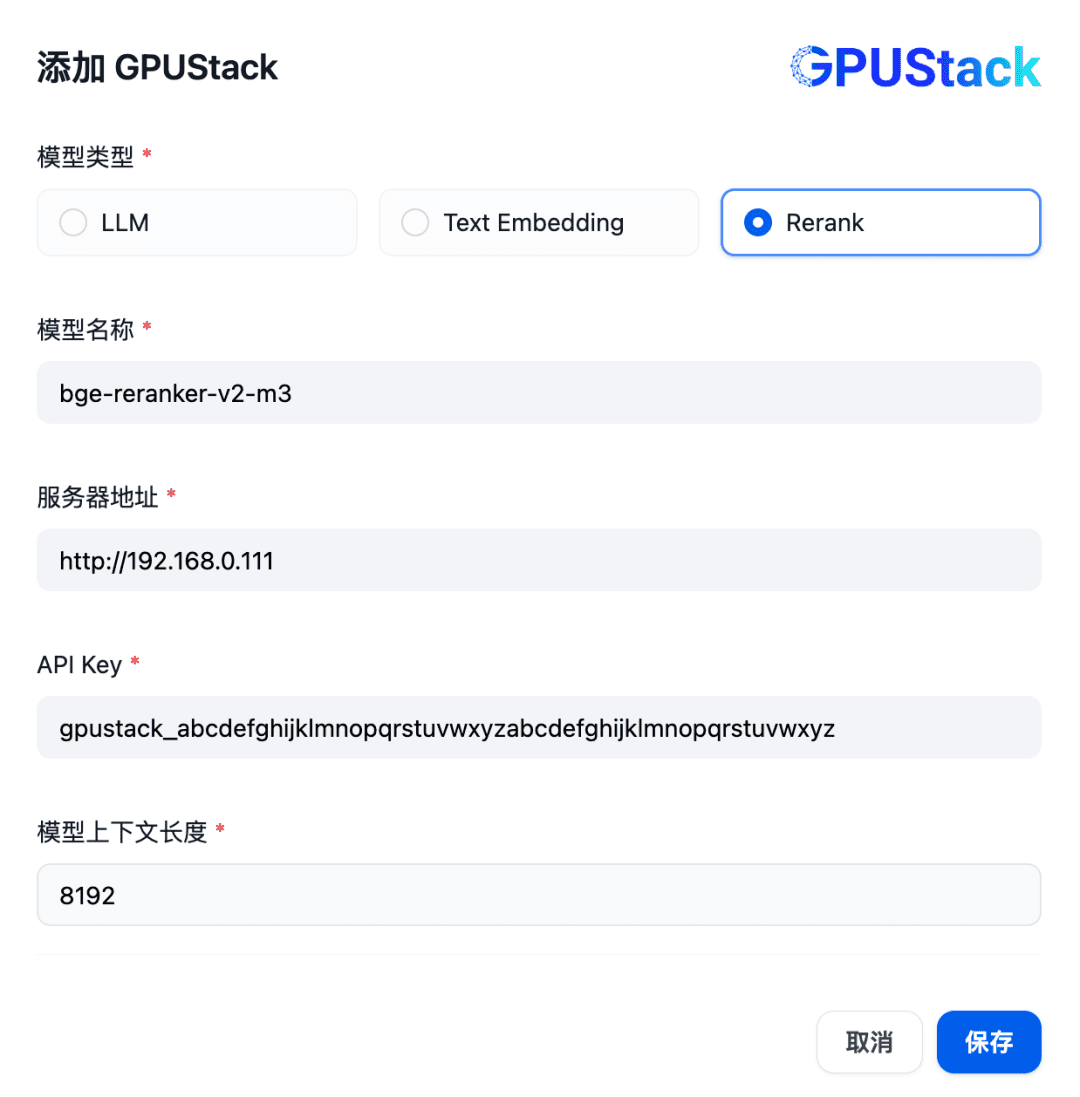
Atualize depois de adicionar e, em seguida, confirme no provedor de modelos que os modelos do sistema estão configurados para os três modelos adicionados acima: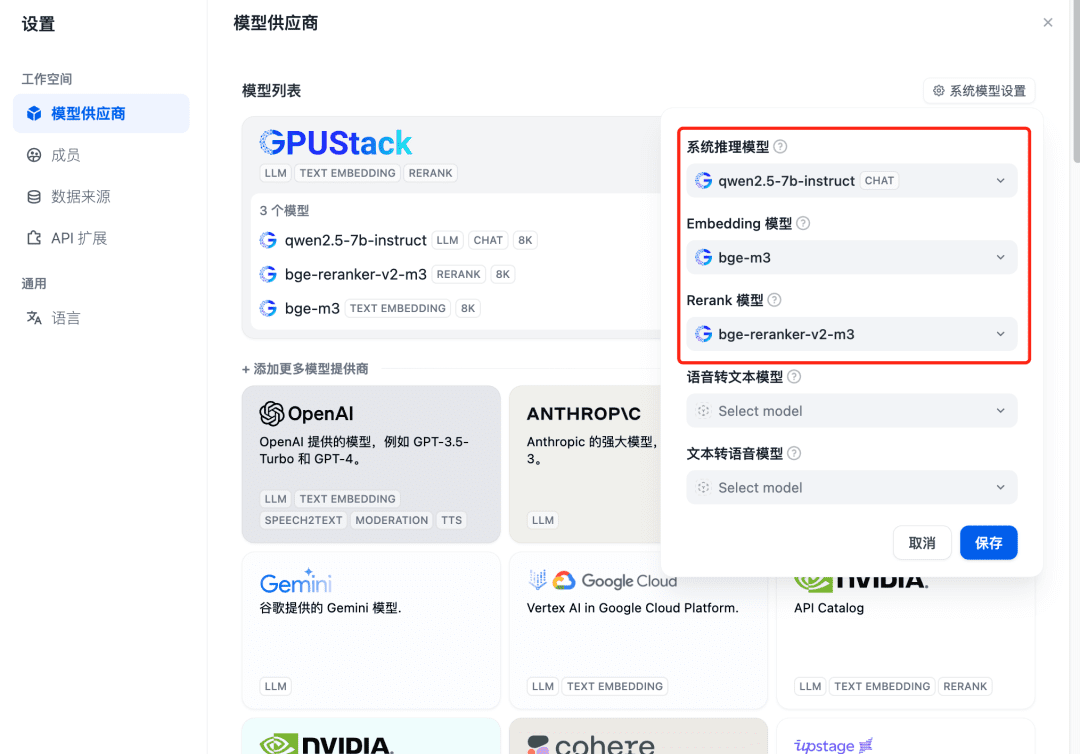
Usando modelos no sistema RAG Selecione a Base de conhecimento do Dfiy, selecione Criar base de conhecimento, importe um arquivo de texto, confirme a opção Modelo de incorporação, use a Pesquisa híbrida recomendada para as Configurações de recuperação e ative o modelo Rerank: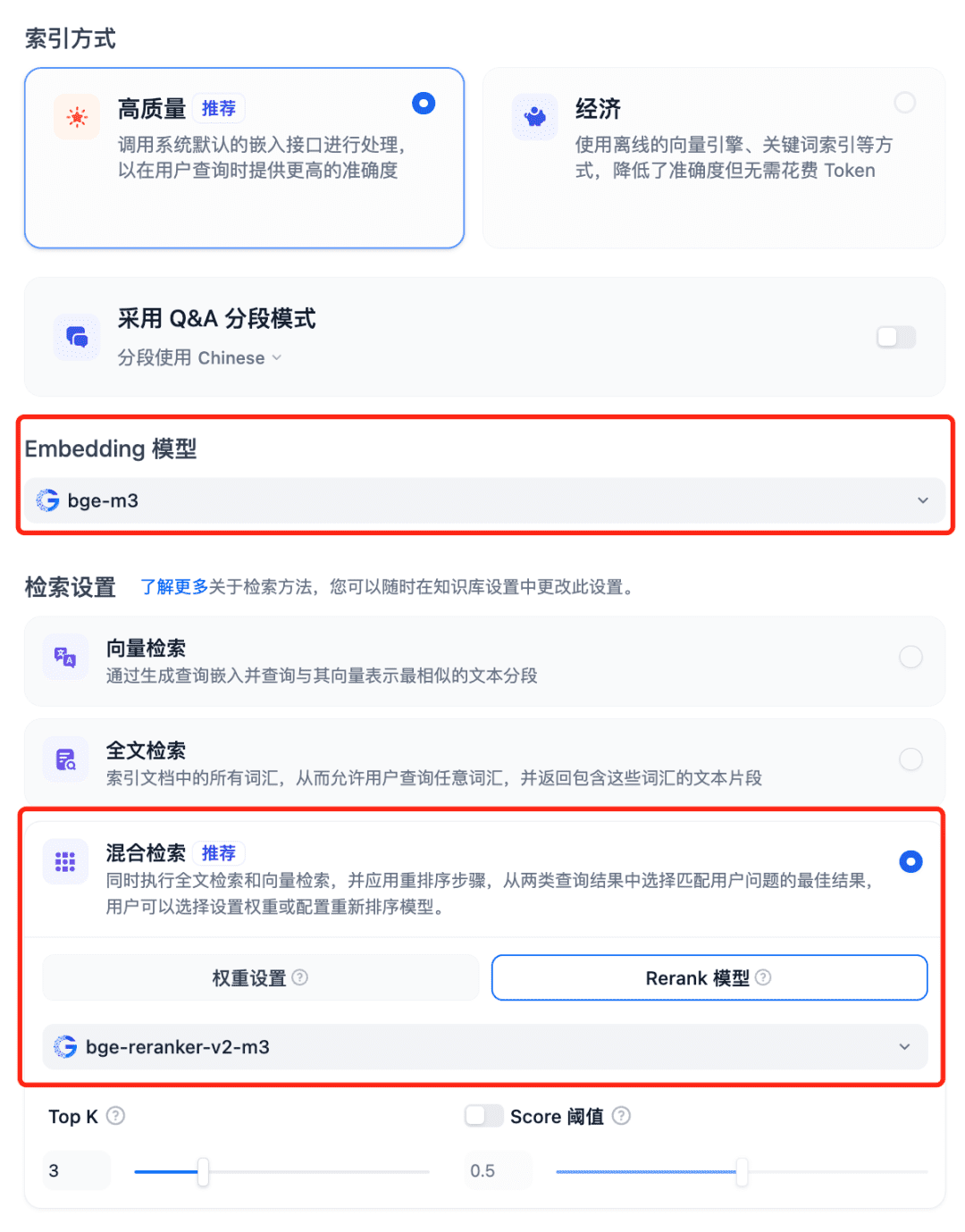
Salve e inicie o processo de vetorização do documento. Quando a vetorização estiver concluída, a base de conhecimento estará pronta para ser usada.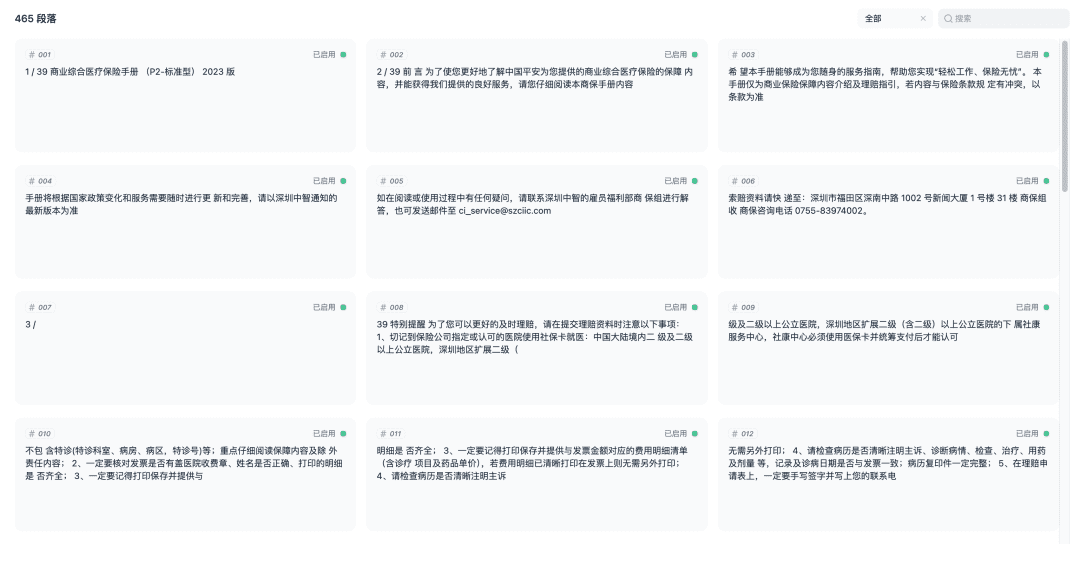
O teste de recuperação pode ser usado para confirmar a eficácia da recuperação da base de conhecimento, e o modelo Rerank será refinado para recuperar documentos mais relevantes a fim de obter melhores resultados de recuperação: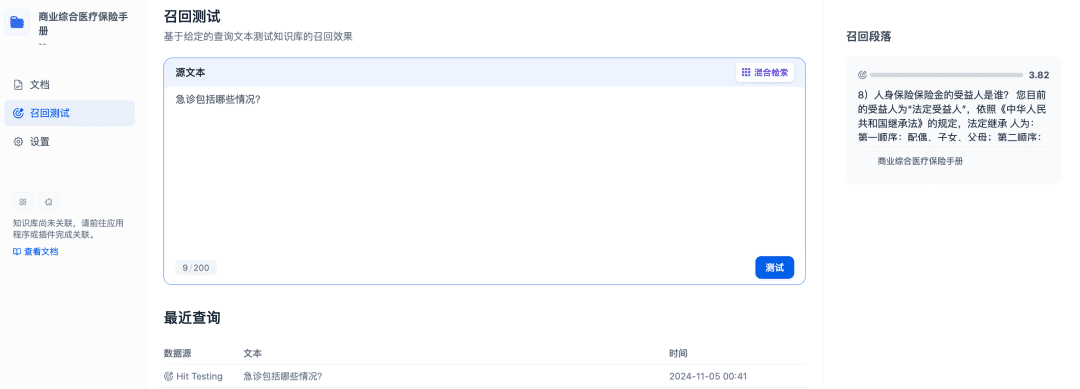
Em seguida, crie um aplicativo de assistente de bate-papo na sala de bate-papo: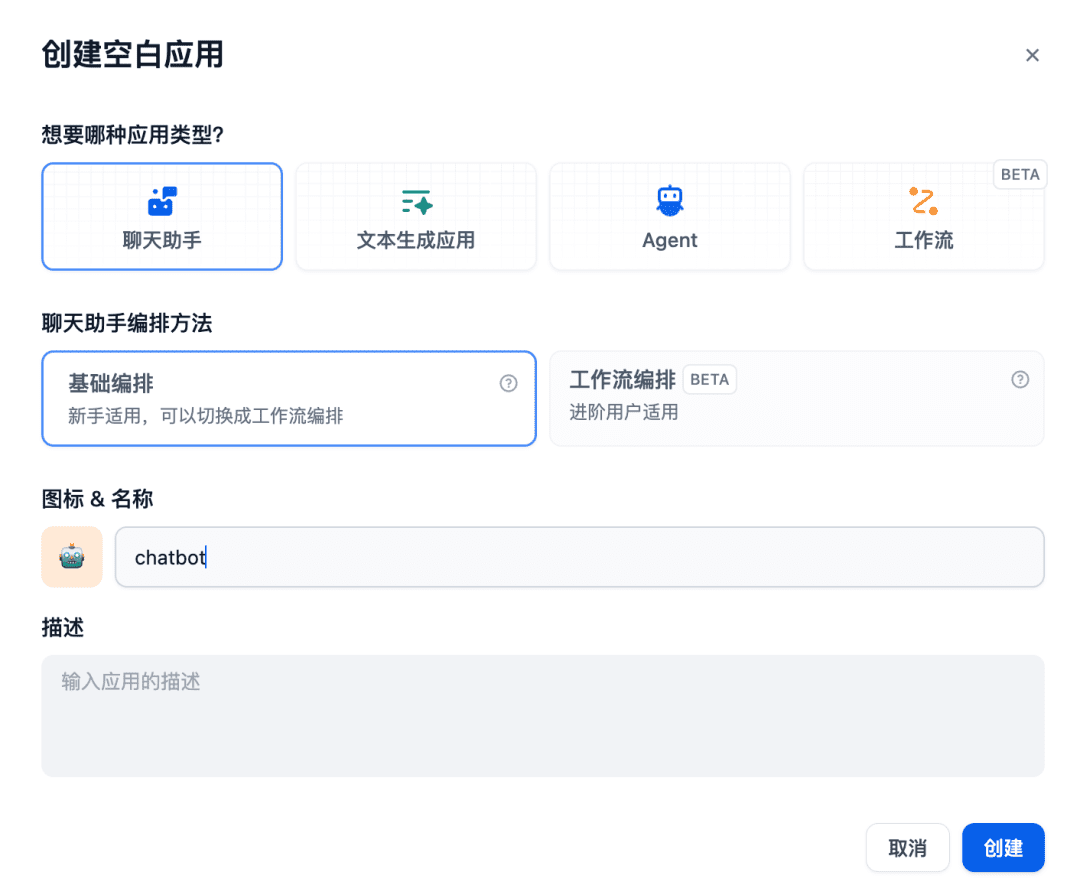
A base de conhecimento relevante é adicionada ao contexto a ser usado e, nesse momento, o modelo de bate-papo, o modelo de incorporação e o modelo de ranqueamento trabalharão juntos para dar suporte ao aplicativo RAG, com o modelo de incorporação responsável pela vetorização, o modelo de ranqueamento responsável pelo ajuste fino do conteúdo da chamada e o modelo de bate-papo responsável por responder com base no conteúdo da pergunta e no contexto da chamada: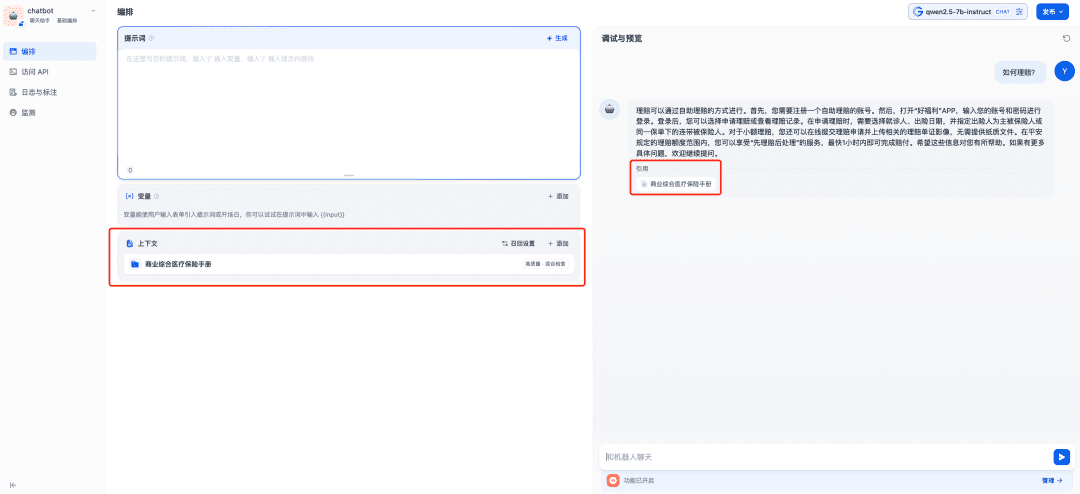
Outros sistemas RAG também podem interagir com o GPUStack por meio de APIs compatíveis com OpenAI/Jina e podem aproveitar os vários modelos de Chat, Incorporação e Reranker implementados pela plataforma GPUStack para oferecer suporte a sistemas RAG.
A seguir, há uma breve descrição da função GPUStack.
Recursos do GPUStack
- Suporte a GPU heterogênea: suporte a recursos de GPU heterogênea, atualmente compatível com Nvidia, Apple Metal, Huawei Rise e Moore Threads e outros tipos de GPU/NPUs
- Suporte a back-end de várias inferências: há suporte para back-ends de inferência vLLM e llama-box (llama.cpp), levando em conta os requisitos de desempenho de produção e de compatibilidade com várias plataformas.
- Suporte multiplataforma: compatível com as plataformas Linux, Windows e macOS, abrangendo as arquiteturas amd64 e arm64.
- Suporte a vários tipos de modelos: oferece suporte a vários tipos de modelos, como o modelo de texto LLM, o modelo multimodal VLM, o modelo de incorporação de texto e o modelo de reordenação Reranker.
- Suporte a repositórios de vários modelos: suporta a implantação de modelos do HuggingFace, da Ollama Library, do ModelScope e de repositórios de modelos privados.
- Políticas avançadas de agendamento automático/manual: suporta várias políticas de agendamento, como agendamento compacto, agendamento descentralizado, agendamento de tag de trabalhador especificado, agendamento de GPU especificado e assim por diante.
- Inferência distribuída: se uma única GPU não puder executar um modelo grande, o recurso de inferência distribuída do GPUStack poderá ser usado para executar automaticamente o modelo em várias GPUs nos hosts
- Raciocínio da CPU: se não houver GPU ou se os recursos da GPU forem insuficientes, o GPUStack poderá usar os recursos da CPU para executar modelos grandes, oferecendo suporte a dois modos de raciocínio da CPU: raciocínio híbrido GPU&CPU e raciocínio puro da CPU.
- Comparação de vários modelos: GPUStack em Playground Uma exibição de comparação de vários modelos é fornecida para comparar o conteúdo de perguntas e respostas e os dados de desempenho de vários modelos ao mesmo tempo, para avaliar o efeito de atendimento do modelo de diferentes modelos, diferentes pesos, diferentes parâmetros do Prompt, diferentes quantificações, diferentes GPUs e diferentes back-ends de inferência.
- Observáveis de GPU e LLM: fornece desempenho abrangente, utilização, monitoramento de status e métricas de dados de uso para avaliar a utilização de GPU e LLM
O GPUStack fornece todos os recursos de classe empresarial necessários para criar uma plataforma privada de modelo como serviço de grande porte. Como um projeto de código aberto, ele requer instalação e configuração muito simples para criar uma plataforma privada de modelo como serviço de grande porte pronta para uso.
resumos
O texto acima é um tutorial de configuração para instalar o GPUStack e integrar os modelos do GPUStack usando o Dify. O endereço de código aberto do projeto é: https://github.com/gpustack/gpustack.
GPUStack como uma solução de baixa barreira, fácil de usar e pronta para usoplataforma de código abertoEle pode ajudar as empresas a integrar e aproveitar rapidamente recursos heterogêneos de GPU e criar rapidamente uma plataforma privada de grande modelo como serviço de nível empresarial em um curto período de tempo.
© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Artigos relacionados



Nenhum comentário...