 apresentar (alguém para um emprego etc.)
apresentar (alguém para um emprego etc.)
Visual RAG para PDF com Vespa - um aplicativo de demonstração baseado em Python

 apresentar (alguém para um emprego etc.)
apresentar (alguém para um emprego etc.)
Thomas entrou para a Vespa em abril de 2024 como engenheiro de software sênior. Em seu último trabalho anterior como consultor de IA, ele construiu uma coleção de PDFs em grande escala com base no software da Vespa RAG Aplicativos.
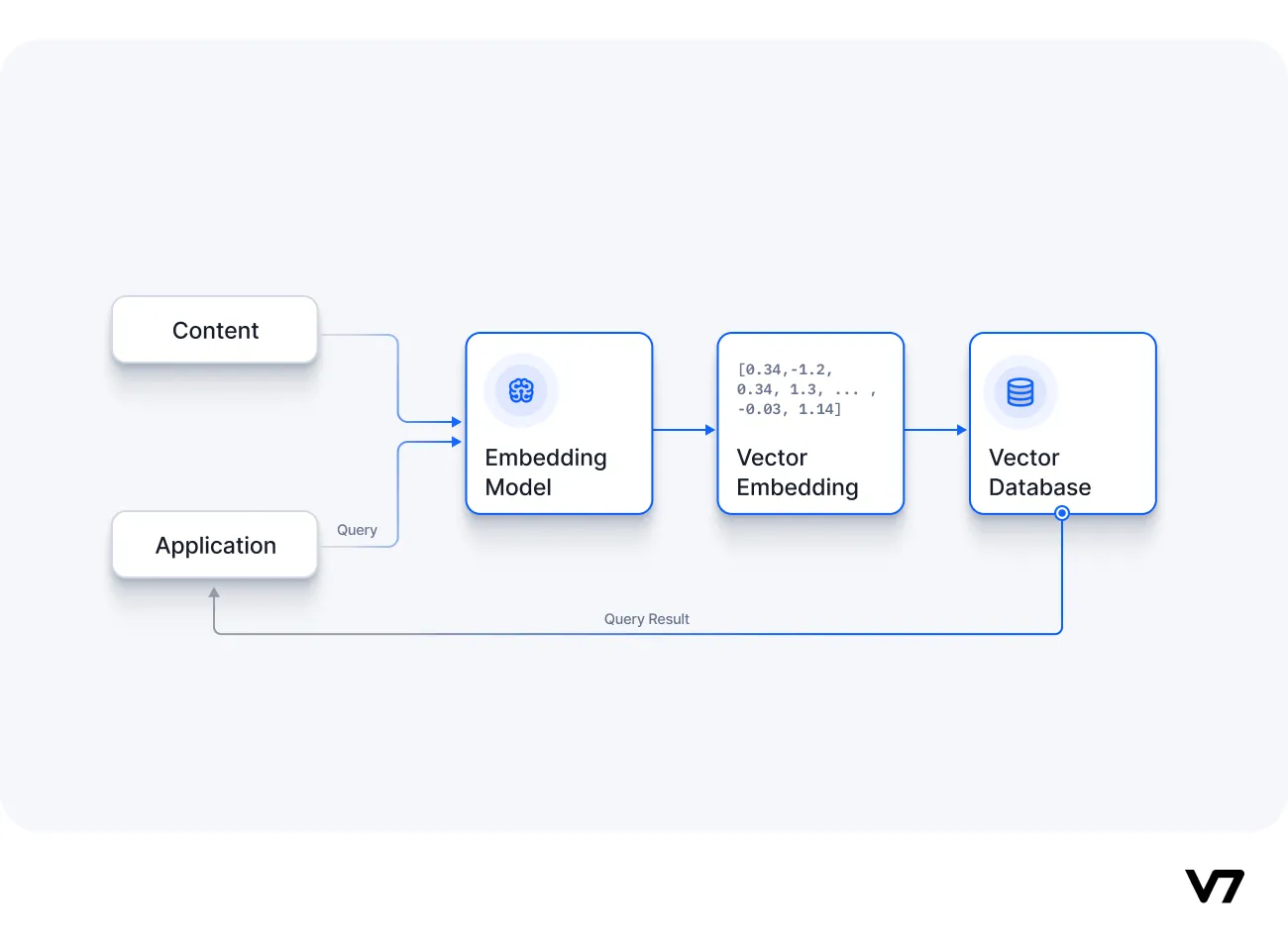
Os PDFs são onipresentes no mundo corporativo e a capacidade de pesquisar e recuperar informações deles é um caso de uso comum. O desafio é que muitos PDFs geralmente se enquadram em uma ou mais das seguintes categorias:
- O fato de serem documentos digitalizados significa que o texto não pode ser facilmente extraído, portanto, o OCR deve ser usado, o que aumenta a complexidade.
- Eles contêm um grande número de gráficos, tabelas e diagramas, que não são facilmente recuperáveis, mesmo que o texto possa ser extraído.
- Eles contêm muitas imagens, que às vezes contêm informações valiosas.
Observe que o termo ColPali Há dois significados:
- particular modelagem e um discutir um artigo ou tese (antigo) Ele treina um adaptador LoRa sobre o VLM (PaliGemma) para gerar texto conjunto e embeddings de imagem (um embedding para cada patch na imagem) para "pós-interação" com base no ColBERT Métodos para ampliar modelos de linguagem visual.
- Ele também representa uma recuperação visual de documentos orientações que combina os recursos dos VLMs com mecanismos eficientes de pós-interação. Essa direção não se limita ao modelo específico do artigo original, mas também pode ser aplicada a outros VLMs, como a nossa proposta de usar o ColQwen2 e o Vespa's notebook .
Nesta postagem do blog, vamos nos aprofundar em como criar um aplicativo de demonstração em tempo real que mostre o RAG visual na Vespa usando incorporações ColPali. Descreveremos a arquitetura do aplicativo, a experiência do usuário e a pilha de tecnologia usada para criar o aplicativo.
Aqui estão algumas capturas de tela do aplicativo de demonstração:
O primeiro exemplo não é uma consulta comum, mas demonstra o poder da pesquisa visual para determinados tipos de consultas. Esse é um bom exemplo do paradigma "O que você vê é o que você pesquisa (WYSIWYS)".
O mapeamento de similaridade destaca as seções mais semelhantes para que os usuários possam ver facilmente quais partes da página são mais relevantes para a consulta.
 O segundo exemplo, uma consulta de usuário mais comum, demonstra o poder do ColPali em termos de similaridade semântica.
O segundo exemplo, uma consulta de usuário mais comum, demonstra o poder do ColPali em termos de similaridade semântica. 
Tendo experimentado em primeira mão as dificuldades de tornar os PDFs pesquisáveis, Thomas está particularmente interessado nos desenvolvimentos mais recentes no campo da modelagem de linguagem visual (VLM).
Depois de ler a postagem anterior sobre o ColPali Postagens no blog da Vespa colaboração com Jo Bergum Após uma série de discussões aprofundadas, ele se inspirou para propor um projeto de criação de um aplicativo RAG visual usando o Vespa.
Na Vespa, os funcionários têm a oportunidade de propor um programa de trabalho que gostariam de realizar em cada ciclo de iteração. Desde que o trabalho proposto esteja alinhado com as metas da empresa e não haja outras prioridades urgentes, podemos começar. Para Thomas, que vem do setor de consultoria, essa autonomia é uma lufada de ar fresco.
TL;DR
Construímos um Aplicativo de demonstração em tempo realEste artigo mostra como implementar um Visual RAG baseado em PDF usando a incorporação ColPali no Vespa e no Python apenas com o FastHTML.
Também fornecemos o código de reprodução:
- Um executável notebookIsso é usado para configurar seu próprio aplicativo Vespa para implementar o Visual RAG.
- Aplicativo FastHTML que você pode usar para configurar um aplicativo da Web que interaja com o aplicativo Vespa.
Objetivos do projeto
O projeto tem dois objetivos principais:
1. criar uma demonstração em tempo real
Embora os desenvolvedores possam ficar satisfeitos com uma demonstração com a saída JSON do terminal como interface do usuário, a verdade é que a maioria das pessoas prefere uma interface da Web.
 Isso nos permitirá demonstrar o PDF Visual RAG no Vespa com base na incorporação ColPali, que acreditamos ser relevante em uma ampla gama de domínios e casos de uso, como jurídico, financeiro, construção, acadêmico e médico.
Isso nos permitirá demonstrar o PDF Visual RAG no Vespa com base na incorporação ColPali, que acreditamos ser relevante em uma ampla gama de domínios e casos de uso, como jurídico, financeiro, construção, acadêmico e médico.
Estamos confiantes de que isso será importante no futuro, mas ainda não vimos nenhum aplicativo prático que demonstre isso.
Ao mesmo tempo, ele nos forneceu muitos insights valiosos em termos de eficiência, escalabilidade e experiência do usuário. Além disso, estávamos muito curiosos (ou um pouco nervosos) para ver se ele era rápido o suficiente para proporcionar uma boa experiência ao usuário.
Também queríamos destacar alguns dos recursos úteis da Vespa, por exemplo:
- Ordenar por estágio
- Sugestões de associação de palavras-chave
- Cálculo do MaxSim multivetorial
2. criar um modelo de código aberto
Gostaríamos de fornecer um modelo para que outras pessoas possam criar seus próprios aplicativos Visual RAG.
Esse modelo deve ser suficiente para outrosmais simplesNão há necessidade de dominar um grande número de linguagens ou estruturas de programação específicas.
Criação de um conjunto de dados
Para nossa demonstração, queríamos usar um conjunto de dados de documentos PDF que contivesse uma grande quantidade de informações importantes na forma de imagens, tabelas e gráficos. Também precisamos de um conjunto de dados de tamanho suficiente para demonstrar que não é viável fazer upload de todas as imagens diretamente para o VLM (pulando a etapa de recuperação).
fazer uso de gemini-1.5-flash-8bO número máximo atual de imagens de entrada é 3600.
Como não havia nenhum conjunto de dados público que atendesse às nossas necessidades, decidimos criar o nosso próprio.
Como noruegueses orgulhosos, ficamos satisfeitos ao descobrir que o Fundo de Pensão Global do Governo da Noruega (GPFG, também conhecido como Fundo Petrolífero) publica relatórios anuais e documentos de governança em seu site desde 2000. Não há menção a direitos autorais no site e seus recentesrepresentaçõesdemonstrou que é o fundo mais transparente do mundo, portanto, estamos confiantes de que podemos usar esses dados para fins de demonstração.
O conjunto de dados inclui 116 relatórios em PDF diferentes de 2000 a 2024, totalizando 6.992 páginas.
O conjunto de dados, que inclui imagens, textos, URLs, números de página, perguntas geradas, consultas e embeddings do ColPali, está agora publicado no Aqui estão.

Gerar consultas e perguntas sintéticas
Também geramos consultas e perguntas sintéticas para cada página. Elas podem ser usadas para duas finalidades:
- Fornecer sugestões de associação de palavras-chave para a caixa de pesquisa à medida que o usuário digita.
- Para fins de avaliação.
As dicas que usamos para gerar perguntas e consultas vêm do Esta excelente publicação no blog de Daniel van Strien.
您是一名投资者、股票分析师和金融专家。接下来您将看到挪威政府全球养老基金(GPFG)发布的报告页面图像。该报告可能是年度或季度报告,或关于责任投资、风险等主题的政策报告。
您的任务是生成检索查询和问题,这些查询和问题可以用于在大型文档库中检索此文档(或基于该文档提出问题)。
请生成三种不同类型的检索查询和问题。
检索查询是基于关键词的查询,由 2-5 个单词组成,用于在搜索引擎中找到该文档。
问题是自然语言问题,文档中包含该问题的答案。
查询类型如下:
1. 广泛主题查询:覆盖文档的主要主题。
2. 具体细节查询:涵盖文档的某个具体细节或方面。
3. 可视元素查询:涵盖文档中的某个可视元素,例如图表、图形或图像。
重要指南:
- 确保查询与检索任务相关,而不仅仅是描述页面内容。
- 使用基于事实的自然语言风格来书写问题。
- 设计查询时,以有人在大型文档库中搜索此文档为前提。
- 查询应多样化,代表不同的搜索策略。
将您的回答格式化为如下结构的 JSON 对象:
{
"broad_topical_question": "2019 年的责任投资政策是什么?",
"broad_topical_query": "2019 责任投资政策",
"specific_detail_question": "可再生能源的投资比例是多少?",
"specific_detail_query": "可再生能源投资比例",
"visual_element_question": "总持有价值的时间趋势如何?",
"visual_element_query": "总持有价值趋势"
}
如果没有相关的可视元素,请在可视元素问题和查询中提供空字符串。
以下是需要分析的文档图像:
请基于此图像生成查询,并以指定的 JSON 格式提供响应。
只返回 JSON,不返回任何额外说明文本。
Usamos gemini-1.5-flash-8b Gerar perguntas e consultas.
tomar nota de
Na primeira execução, descobrimos que alguns problemas muito longos foram gerados, então adicionamos uma nova seção ao generationconfig Adicionado o maxOutputTokens=500É muito útil.
Também notamos algumas estranhezas nas perguntas e consultas geradas, como o fato de "string" aparecer várias vezes nas perguntas. Queremos uma validação mais aprofundada das perguntas e consultas geradas.
Use Python em todo o processo
Nosso público-alvo é a crescente comunidade de ciência de dados e IA. É provável que essa comunidade seja uma das maiores contribuidoras do Python no GitHub. Relatório de status do OctoverseUm dos principais motivos pelos quais ela é classificada como a linguagem de programação mais popular (e de crescimento mais rápido) é o fato de ser uma das linguagens de programação mais populares do mundo.
Precisamos usar o Python no back-end para raciocínio incorporado à consulta (usando o motor colpali-), até que a Vespa suporte nativamente a biblioteca ColpaliEmbedder (Em desenvolvimento, consulte problema no github). Se outras linguagens (e suas estruturas) forem usadas para o front-end, isso aumentará a complexidade do projeto, dificultando a reprodução do aplicativo por outras pessoas.
Por isso, decidimos criar todo o aplicativo em Python.
Escolha da estrutura de front-end
Streamlit e Gradio
Admitimos que é muito fácil criar PoCs (Prova de Conceitos) simples usando o Gradio e o Streamlit, e já os usamos no passado para essa finalidade. Mas há dois motivos principais pelos quais decidimos não usá-los:
- Precisávamos de uma interface de usuário com aparência profissional que pudesse ser usada em um ambiente de produção.
- Precisamos de um bom desempenho. Esperar alguns segundos ou ter a interface do usuário congelada intermitentemente não é suficiente para o aplicativo que queremos apresentar.
Por mais que gostemos de nos exercitar, não gostamos da mensagem "Running" (Em execução) no canto superior direito da tela do Streamlit.
FastHTML para o resgate
Nós somos. answer.ai de seus fãs fiéis. Portanto, quando eles lançaram no início deste ano FastHTML3Quando o fizermos, ficaremos felizes em experimentar.
O FastHTML é uma estrutura para criar aplicativos da Web modernos usando Python puro. De acordo com seu visão (do futuro)::
O FastHTML é um sistema de programação da Web de uso geral e de pilha completa, na mesma categoria do Django, NextJS e Ruby on Rails. Sua visão é ser a maneira mais fácil de criar protótipos rápidos, mas também a maneira mais fácil de criar aplicativos escalonáveis, poderosos e avançados.
O FastHTML usa o estrela responder cantando uvicórnio.
Ele vem com Pico CSS para a criação de estilos. Como Leandro, um desenvolvedor web experiente da equipe, queria experimentar o Tailwind CSS, juntamente com nosso recém-descoberto shad4fastDecidimos combinar o FastHTML e o shadcn/ui Os belos componentes da interface do usuário no
Pyvespa
Nosso cliente Vespa Python pyvespa No passado, ele era usado principalmente para criar protótipos de aplicativos Vespa. No entanto, trabalhamos recentemente para oferecer mais suporte à funcionalidade Vespa por meio do pyvespa. Agora, há suporte para a implantação em produção e foi adicionada a configuração avançada do Vespa por meio do pyvespa! services.xml do arquivo. Para obter detalhes, consulte esses Exemplos e detalhes no caderno.
Como resultado, a maioria dos aplicativos Vespa que não requerem componentes Java personalizados pode ser criada com o pyvespa.
Anedota:
Os recursos de configuração avançada do pyvespa são, na verdade, influenciados pelo fato de que o FastHTML ft-inspirado na maneira como os componentes são agrupados e convertidos em tags HTML. No pyvespa, temos um vtO componente - executa uma operação semelhante, convertendo-o em uma Vespa services.xml Tags. Os leitores interessados no assunto podem dar uma olhada em Esse PR Saiba mais. Essa abordagem nos poupa muito trabalho em comparação com a implementação de classes personalizadas para todas as tags compatíveis.
Além disso, o processo de criação de um aplicativo Vespa usando o pyvespa nos permitiu realizar uma validação prática.
software
Como um incorporador ColPali com suporte nativo para Vespa, ele ainda está no WIP sabemos que a GPU é necessária para concluir a inferência. Com base em nossos experimentos no Colab, concluímos que uma instância T4 é suficiente.
Para gerar a incorporação antes de incorporar as páginas PDF do conjunto de dados no Vespa, consideramos o uso de um provedor de GPU sem servidor (Modal (um dos nossos favoritos). No entanto, como o conjunto de dados tem "apenas" 6.692 páginas, usamos um Macbook M2 Pro e trabalhamos de 5 a 6 horas para criar essas incorporações.
administração fiduciária
Há muitas opções aqui. Poderíamos optar por um provedor de nuvem tradicional, como AWS, GCP ou Azure, mas isso exigiria mais esforço de nossa parte para configurar e gerenciar a infraestrutura e dificultaria a replicação do aplicativo por outras pessoas.
Aprendemos que Espaços para abraçar o rosto Eles oferecem um serviço de hospedagem em que você pode adicionar GPUs conforme necessário. Eles também oferecem um botão de um clique "Clonar este espaço" que facilita muito a cópia do aplicativo por outras pessoas.
Encontramos answer.ai Cria um Bibliotecas reutilizáveisque pode ser usado para implementar aplicativos FastHTML no Hugging Face Spaces. No entanto, após uma pesquisa mais aprofundada, descobrimos que a abordagem deles usa o Docker SDK para manipular os Spaces e que, na verdade, há maneiras mais simples de fazer isso.
Por meio do uso de Espaços Python personalizados.
solo Documentação do huggingface-hub::
Embora esse não seja um fluxo de trabalho oficial, você pode executar sua própria pilha de interface Python + no Spaces escolhendo o Gradio como SDK e fornecendo uma interface de front-end na porta 7860.
Anedota 2: Há um erro de digitação na documentação informando que a porta na qual o serviço é fornecido é 7680. Felizmente, não demorou muito para descobrirmos que a porta correta deveria ser 7860e enviou um RPO erro foi corrigido por Julien Chaumond, CTO da Hugging Face. Tarefas da lista de verificação concluídas!
modelo de linguagem visual
Para a parte de "Geração" do Visual RAG, precisamos de um Modelo de Linguagem Visual (VLM) para gerar respostas com base nos documentos com as melhores classificações obtidos no Vespa.
Suporte Vespa Native LLM(Large Language Model), seja externa ou internamente integrado, mas o VLM (Visual Language Model) ainda não é suportado nativamente no Vespa.
Com a OpenAI, a Anthropic e o Google lançando excelentes modelos de linguagem visual (VLMs) no ano passado, o campo está crescendo rapidamente. Por motivos de desempenho, queríamos escolher um modelo menor, já que o Google Gêmeos melhorou recentemente a experiência do desenvolvedor, decidimos usar a API gemini-1.5-flash-8b.
Obviamente, recomenda-se a avaliação quantitativa de diferentes modelos antes de selecionar um modelo em um ambiente de produção, mas isso está além do escopo deste projeto.
construir
Com a pilha de tecnologia pronta, podemos começar a criar o aplicativo. A arquitetura de alto nível do aplicativo é a seguinte:

Aplicativo Vespa
Os principais componentes do aplicativo Vespa incluem:
- Documentos que contêm campos e tipos definição do esquema.
- Perfil de classificação Definição.
- e
services.xmlArquivo de configuração.
Todos eles. possível Definido em Python usando pyvespa, mas recomendamos também verificar os arquivos de configuração gerados, o que pode ser feito chamando o comando app.package.to_files() para realizar. Para obter informações detalhadas, consulte documentação do pyvespa.
Configuração de classificação
Um dos recursos mais subestimados da Vespa é a Classificação por estágio Função. Ela permite definir vários perfis de classificação, cada um dos quais pode conter fases de classificação diferentes (ou herdadas) que podem ser executadas em nós de conteúdo (fase 1 e fase 2) ou nós de contêiner (palco global).
Isso nos permite lidar com muitos casos de uso diferentes separadamente e encontrar o equilíbrio ideal entre latência, custo e qualidade para cada situação.
Leia o que nosso CEO Jon Bratseth tem a dizer sobre a inversão arquitetônica de mover a computação para o lado dos dados da equação. Esta postagem do blog.
Para esse aplicativo, definimos três configurações de classificação diferentes:
tomar nota de recuperar (dados)A etapa é passar a consulta pelo yql especificado, e oestratégia de classificaçãoé especificado no arquivo de configuração de classificação (que faz parte do pacote do aplicativo fornecido no momento da implantação).
1. puro ColPali
O yql usado para esse modo de classificação em nosso aplicativo é:
select title, text from pdf_page where targetHits:{100}nearestNeighbor(embedding,rq{i}) OR targetHits:{100}nearestNeighbor(embedding,rq{i+1}) .. targetHits:{100}nearestNeighbor(embedding,rq{n}) OR userQuery();
Também hnsw.exploreAdditionalHits O parâmetro é ajustado para 300 para garantir que nenhuma correspondência relevante seja perdida durante a fase de recuperação. Observe que isso acarretará um custo de desempenho.
Entre eles rq{i} é o i-ésimo na consulta Token (que deve ser fornecido como um parâmetro na solicitação HTTP).n é o número máximo de tokens de consulta a serem recuperados (usamos 64 neste aplicativo).
Essa configuração de classificação usa o max_sim_binary Expressão de classificação que aproveita a funcionalidade de cálculo otimizado da distância de Hamming no Vespa (para obter mais informações, consulte Dimensionamento do ColPali para bilhões. Isso é usado no primeiro estágio da classificação e as 100 melhores correspondências são classificadas novamente usando a representação completa de ponto flutuante da incorporação ColPali.
2. classificação puramente baseada em texto (BM25)
Nesse caso, estamos nos baseando apenas no weakAnd Recuperar o documento.
select title, text from pdf_page where userQuery();
Na fase de classificação, usamos bm25 Conduzir a classificação da Fase I (sem Fase II).
Observe que, para obter o melhor desempenho, provavelmente desejamos usar uma combinação de recursos de classificação baseados em texto e em visão (por exemplo, usando o Integração de classificação recíproca), mas, nesta demonstração, queremos mostrar as diferenças entre eles em vez de encontrar a combinação ideal.
3. mistura BM25 + ColPali
Na fase de recuperação, usamos o mesmo yql que a configuração de classificação pura do ColPali.
Percebemos que, para algumas consultas, especialmente as mais curtas, o ColPali puro correspondia a muitas páginas sem texto (somente imagens), enquanto muitas das respostas que estávamos procurando apareciam em páginas com texto.
Para resolver esse problema, adicionamos uma expressão de classificação de segundo estágio combinando a pontuação BM25 e a pontuação ColPali, usando uma combinação linear das duas pontuações (max_sim + 2 * (bm25(title) + bm25(text))).
Esse método é baseado em heurística simples, mas seria mais vantajoso encontrar os pesos ideais para diferentes recursos realizando experimentos de classificação.
Geração de fragmentos na Vespa
No front-end da pesquisa, é comum incluir trechos do texto de origem com determinadas palavras em um negrito (tipo de letra) (Destacado) Tela.

A exibição de trechos de termos de consulta correspondentes no contexto permite que os usuários determinem rapidamente se os resultados provavelmente atenderão às suas necessidades de informação.
No Vespa, esse recurso é chamado de "snippets dinâmicos" e há vários parâmetros que podem ser ajustados, como a quantidade de contexto circundante a ser incluída e os rótulos usados para destacar as palavras correspondentes.
Nesta demonstração, mostramos tanto o snippet quanto o texto completo extraído da página para comparação.
Para reduzir o ruído visual nos resultados, removemos as palavras de parada (and, in, the, etc.) da consulta do usuário para que elas não fossem destacadas.
Saiba mais sobre os segmentos dinâmicos da Vespa.
Recomendações de consulta no Vespa
Um recurso comum na pesquisa são as "sugestões de pesquisa", que são exibidas à medida que o usuário digita.
As consultas de usuários reais são frequentemente usadas para fornecer resultados pré-calculados, mas aqui não temos nenhum tráfego de usuários para analisar.

Neste exemplo, usamos uma pesquisa de substring simples que corresponde a um prefixo inserido pelo usuário a uma pergunta relevante gerada a partir de uma página de PDF para fornecer sugestões.
A consulta yql que usamos para obter essas sugestões é:
select questions from pdf_page where questions matches (".*{query}.*")
Uma vantagem dessa abordagem é que qualquer pergunta que apareça nas recomendações pode ser confirmada como tendo respostas nos dados disponíveis!
Poderíamos ter assegurado que a página que gerou a pergunta sugerida sempre aparecesse entre as três principais respostas (adicionando uma métrica de similaridade entre a consulta do usuário e a pergunta gerada pelo documento na configuração de classificação), mas isso teria sido um pouco "enganoso" do ponto de vista da demonstração da funcionalidade do modelo ColPali.
experiência do usuário
Temos a sorte de contar com o cientista-chefe da Jo Bergum Ele recebeu um ótimo feedback de UX de nós. Ele nos incentivou a tornar a experiência do usuário "rápida e fluida". As pessoas estão acostumadas com o Google, portanto, não há dúvida de que a velocidade é fundamental para a experiência do usuário na pesquisa (e no RAG). É algo que ainda é um pouco subestimado na comunidade de IA, onde muitas pessoas parecem estar satisfeitas em esperar de 5 a 10 segundos por uma resposta. E nós queremos atingir tempos de resposta em milissegundos.
Com base em seu feedback, precisamos configurar um processo de solicitação em etapas para evitar a espera pelo retorno da imagem completa e do tensor de mapeamento de similaridade do Vespa antes de exibir os resultados.
A solução é extrair primeiro apenas os dados mais importantes dos resultados. Para nós, isso significa extrair apenas os titleeurletextepage_nobem como uma versão reduzida (desfocada) da imagem (32x32 pixels) para a exibição inicial dos resultados da pesquisa. Isso nos permite exibir os resultados imediatamente e continuar carregando a imagem completa e o mapeamento de similaridade em segundo plano.
O processo UX completo é mostrado abaixo:
 As principais fontes de atraso são:
As principais fontes de atraso são:
- Tempo de inferência para gerar embeddings ColPali (feito na GPU, dependendo do número de tokens na consulta)
- Por isso, decidimos usar o
@lru_cachepara evitar recalcular a incorporação várias vezes para a mesma consulta.
- Por isso, decidimos usar o
- Latência de rede entre o Face Spaces e a Vespa (incluindo handshakes TCP)
- O tempo de transferência de imagens completas também é significativo (cerca de 0,5 MB por imagem).
- O tamanho do tensor de mapeamento de similaridade é maior (
n_query_tokensxn_images(x 1030 patches x 128).
- A criação de uma imagem híbrida mapeada por similaridade é uma tarefa que consome muita CPU, mas é feita com o
fastcore(usado em uma expressão nominal)@threadedO decorador é feito em uma tarefa em segundo plano com vários threads, em que cada imagem pesquisa seu ponto de extremidade correspondente para verificar se o mapeamento de similaridade está pronto.
teste de estresse
Estávamos preocupados com o desempenho do nosso aplicativo durante um aumento no tráfego, por isso realizamos um experimento simples de teste de estresse. O experimento foi realizado usando uma ferramenta de desenvolvimento de navegador para enviar solicitações /fetch_results O comando cURL foi copiado (com o cache não ativado) e executado em um loop em 10 terminais paralelos. (Nesse ponto, desativamos a função @lru_cache Decorador).
no final
Embora os testes tenham sido muito básicos, os primeiros testes mostraram que o gargalo na taxa de transferência da pesquisa era o cálculo das incorporações ColPali nas GPUs no espaço Huggingface, enquanto o back-end Vespa podia lidar facilmente com mais de 20 consultas por segundo com uso muito baixo de recursos. Acreditamos que isso é mais do que suficiente para demonstrações. Se precisarmos escalonar, nossa primeira etapa seria habilitar uma instância de GPU maior para o espaço Huggingface.
O aplicativo Vespa tem um bom desempenho sob carga, conforme mostrado nos gráficos a seguir.


Reflexões sobre o uso do FastHTML
A principal vantagem de usar o FastHTML é que ele rompe as barreiras entre o desenvolvimento front-end e back-end. O código é totalmente integrado, permitindo que todos nós entendamos e contribuamos para cada parte do aplicativo. Isso não deve ser subestimado.
Gostamos muito de poder usar as ferramentas de desenvolvimento do navegador para inspecionar o código de front-end e realmente ver e entender a maior parte dele.
O processo de desenvolvimento e implantação é significativamente simplificado em comparação com o uso de uma estrutura de front-end autônoma.
Ele nos permite usar uv gerencial propriedade o que muda radicalmente a maneira como lidamos com dependências no Python.
A visão de Thomas:
Como desenvolvedor com experiência em ciência de dados e IA, preferindo Python, mas tendo trabalhado com várias estruturas JS, minha experiência foi muito positiva. Eu me senti mais capaz de me envolver em tarefas relacionadas ao front-end sem acrescentar muita complexidade ao projeto. Gostei muito de poder entender cada parte do aplicativo.
A visão de Andreas:
Estou trabalhando na Vespa há muito tempo, mas não me interessei muito por Python ou desenvolvimento front-end. Senti-me um pouco sobrecarregado no primeiro ou segundo dia, mas é muito empolgante poder trabalhar em pilha completa e ver os efeitos de minhas alterações quase em tempo real! Com a ajuda do modelo de linguagem grande, é mais fácil do que nunca entrar em um ambiente desconhecido. Gostei muito do fato de termos conseguido criar mapeamentos de similaridade com latência e consumo de recursos muito menores, calculando a similaridade dos patches de imagem por meio de expressões de tensor no Vespa (os vetores já estão armazenados na memória) e retornando-os com os resultados da pesquisa.
A visão de Leandro:
Como desenvolvedor com uma base sólida em desenvolvimento web usando React, JavaScript, TypeScript, HTML e CSS, a mudança para o FastHTML foi relativamente simples. O mapeamento direto de elementos HTML da estrutura foi altamente consistente com meu conhecimento prévio, o que reduziu a curva de aprendizado. O principal desafio foi a adaptação à sintaxe baseada em Python do FastHTML, que difere da estrutura HTML/JS padrão.
A tecnologia visual é tudo o que você precisa?
Vimos que a utilização da incorporação de interação tardia em nível de token do Vision Language Model (VLM) é muito eficiente para determinados tipos de consultas, mas não a vemos como uma solução única, e sim como uma ferramenta muito valiosa na caixa de ferramentas.
Além do ColPali, vimos outras inovações na recuperação visual no ano passado. Duas abordagens particularmente interessantes são:
- Document Screenshot Embeddings (DSE)5 - Um modelo de codificador duplo para a geração de embeddings densos para capturas de tela de documentos e o uso desses embeddings para recuperação.
- IBM Docagem - Uma biblioteca para analisar vários tipos de documentos (por exemplo, PDF, PPT, DOCX etc.) em Markdown, evitando o OCR e usando um modelo de visão computacional.
O Vespa suporta a combinação dessas abordagens e permite que os desenvolvedores encontrem o equilíbrio mais atraente entre latência, custo e qualidade para casos de uso específicos.
Podemos imaginar um aplicativo que combine extração de texto de alta qualidade com o Docling ou ferramentas semelhantes, recuperação intensiva usando a incorporação de capturas de tela de documentos e recuperação intensiva por meio de recursos de texto e modelagem do tipo ColPali do MaxSim As pontuações são classificadas. Se você realmente deseja melhorar o desempenho, pode até combinar todos esses recursos com outros, como XGBoost talvez LightGBM A combinação do modelo GBDT do
Portanto, embora o ColPali seja uma ferramenta poderosa para tornar recuperáveis informações difíceis de extrair em textos, ele não é uma panaceia e deve ser combinado com outras abordagens para obter o desempenho ideal.
elo perdido
A modelagem é temporária, enquanto a avaliação é permanente.
A adição de avaliações automatizadas está além do escopo desta demonstração, mas recomendamos enfaticamente que você crie um conjunto de dados de avaliação para seu próprio caso de uso. Você pode usar o LLM-as-a-judge para fazer o bootstrap (consulte este Publicações do blogSaiba mais sobre como fornecemos search.vespa.ai (Percebendo isso).
O Vespa oferece vários parâmetros ajustáveis e, ao fornecer feedback quantitativo sobre diferentes experimentos, você pode encontrar as compensações mais atraentes para o seu caso de uso específico.
chegar a um veredicto
Criamos um aplicativo de demonstração ao vivo que mostra como executar a recuperação visual RAG de PDFs no Vespa usando a incorporação ColPali.
Se você leu até aqui, talvez esteja interessado no código. Você pode encontrar o código na seção aqui (literário) Encontre o código do aplicativo.
Agora, crie seu próprio aplicativo RAG visual!
Para quem quiser saber mais sobre recuperação visual, ColPali ou Vespa, fique à vontade para participar! Comunidade Slack da Vespa Faça uma pergunta, procure ajuda da comunidade ou saiba mais sobre os últimos desenvolvimentos na Vespa.
problemas comuns
O uso do ColPali requer o uso de uma GPU para inferência?
Atualmente, para raciocinar sobre as consultas em um período de tempo razoável, precisamos usar a GPU.
No futuro, esperamos que a qualidade e a eficiência (por exemplo, embeddings menores) dos modelos do tipo ColPali melhorem e que surjam modelos mais semelhantes, como vimos com a família de modelos ColBERT, como o modelo da answer.ai answerai-colbert-small-v1O modelo ColBERT foi desenvolvido pela primeira vez, e seu desempenho excede o do modelo ColBERT original, embora tenha menos de um terço do tamanho do modelo original.
Veja também Blog da Vespa Saiba mais sobre como usar o Vespa's answerai-colbert-small-v1.
É possível usar o ColPali em conjunto com um filtro de consulta no Vespa?
Pode. Nesse aplicativo, adicionamos a página à pasta published_year mas sua funcionalidade como opção de filtro ainda não foi implementada no front-end.
Quando a Vespa oferecerá suporte nativo a incorporações ColPali?
Veja também Este problema do GitHub.
Isso pode ser dimensionado para bilhões de documentos?
Sim. O Vespa suporta escalonamento horizontal e permite ajustar a relação entre latência, custo e qualidade para casos de uso específicos.
Essa demonstração pode ser adaptada para suportar o ColQwen2?
É possível, mas há algumas diferenças no cálculo dos mapas de similaridade.
Veja também Este notebook Como ponto de partida.
Posso executar essa demonstração com meus próprios dados?
Com certeza! Ajustando o notebook Apontando para seus dados, você pode configurar seu próprio aplicativo Vespa para o Visual RAG. Você também pode usar o aplicativo da Web fornecido como ponto de partida para seu próprio front-end.
bibliografia
© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Artigos relacionados



Nenhum comentário...