Prática: Criando pesquisas multimodais avançadas com o Voyager-3 e o LangGraph
O Voyager 3 da Voyage AI é um novo modelo de última geração que permite incorporar texto e imagens no mesmo espaço. Nesta publicação, explicarei como extrair esses embeddings multimodais de revistas, armazená-los em um banco de dados vetorial (Weaviate) e realizar pesquisas de similaridade em textos e imagens usando os mesmos vetores de embedding.
A incorporação de imagens e texto no mesmo espaço nos permitirá realizar pesquisas altamente precisas em conteúdo multimodal, como páginas da Web, arquivos PDF, revistas, livros, folhetos e vários documentos. Por que essa técnica é tão interessante? O principal aspecto interessante da incorporação de texto e imagens no mesmo espaço é que você pode pesquisar e recuperar o texto associado a uma imagem específica e vice-versa. Por exemplo, se estiver pesquisando por gatos, você encontrará imagens que mostram gatos, mas também obterá textos que fazem referência a essas imagens, mesmo que o texto não diga explicitamente a palavra "gato".
Vou mostrar a diferença entre a pesquisa de similaridade de incorporação de texto tradicional e o espaço de incorporação multimodal:
EXEMPLO DE PERGUNTA: O que a revista diz sobre gatos?

Uma captura de tela de uma revista de fotografia - OUTDOOR
Respostas regulares de pesquisa de similaridade
Os resultados da pesquisa fornecidos não contêm informações específicas sobre gatos. Eles mencionam retratos de animais e técnicas de fotografia, mas não mencionam explicitamente gatos ou detalhes relacionados a eles.
Como mostrado acima, a palavra "gato" não é mencionada; há apenas uma imagem e uma explicação sobre como tirar fotos do animal. Como a palavra "cat" não foi mencionada, uma pesquisa de similaridade regular não produziu resultados.
Busca multimodal de respostas
Esta revista apresenta o retrato de um gato, destacando a captura refinada de suas características faciais e caráter. O texto enfatiza como retratos de animais bem feitos alcançam a alma do sujeito e criam uma conexão emocional com o espectador por meio de um contato visual atraente.
Usando uma pesquisa multimodal, encontraremos a foto de um gato e, em seguida, vincularemos um texto relevante a ela. O fornecimento desses dados ao modelo permitirá que ele responda melhor e compreenda o contexto.
Como criar um pipeline de incorporação e recuperação multimodal
Descreverei agora como esse pipeline funciona em algumas etapas:
- Usaremos o Não estruturado(uma biblioteca Python avançada para extração de dados) Extrai texto e imagens de arquivos PDF.
- Usaremos o Voyager Multimodal 3 O modelo cria vetores multimodais para texto e imagens no mesmo espaço vetorial.
- Vamos inseri-lo no armazenamento de vetores (Weaviate) em.
- Por fim, realizaremos uma pesquisa de similaridade e compararemos os resultados do texto e das imagens.
Etapa 1: Configure o armazenamento vetorial e extraia imagens e texto do documento (PDF)
Aqui temos de fazer algum trabalho manual. Normalmente, o Weaviate é um armazenamento de vetores muito fácil de usar que transforma automaticamente os dados e adiciona embeddings na inserção. No entanto, não há plug-in para o Voyager Multimodal v3, portanto, temos de calcular os embeddings manualmente.Nesse caso, temos que criar uma coleção sem definir um módulo vetorizador.
import weaviate
from weaviate.classes.config import Configure
client = weaviate.connect_to_local()
collection_name = "multimodal_demo"
client.collections.delete(collection_name)
try:
client.collections.create(
name=collection_name,
vectorizer_config=Configure.Vectorizer.none() # 不为此集合设置向量化器
)
collection = client.collections.get(collection_name)
except Exception:
collection = client.collections.get(collection_name)pyt
Aqui, estou executando uma instância local do Weaviate em um contêiner do Docker.
Etapa 2:Extraia documentos e imagens de PDFs
Essa é uma etapa fundamental para o funcionamento do processo. Aqui, obteremos um PDF com texto e imagens. Em seguida, extrairemos o conteúdo (imagens e texto) e o armazenaremos em blocos relevantes. Assim, cada bloco será um PDF contendo strings (texto real) e imagens (imagens). Imagens Python PIL A lista de elementos do
Usaremos o Não estruturado para fazer parte do trabalho pesado, mas ainda precisamos escrever alguma lógica e configurar os parâmetros da biblioteca.
from unstructured.partition.auto import partition
from unstructured.chunking.title import chunk_by_title
elements = partition(
filename="./files/magazine_sample.pdf",
strategy="hi_res",
extract_image_block_types=["Image", "Table"],
extract_image_block_to_payload=True)
chunks = chunk_by_title(elements)
Aqui, devemos usar o oi_res e usar a estratégia extract_image_block_to_payload Exporte a imagem para o payload, pois precisaremos dessas informações posteriormente para a incorporação real. Depois de extrair todos os elementos, nós os agruparemos em blocos com base nos títulos do documento.
Para obter mais informações, consulte Documentação não estruturada sobre chunking.
No script a seguir, usaremos esses blocos para gerar duas listas:
- Uma lista contendo os objetos que enviaremos à Voyager 3 para criar o vetor
- Uma lista que contém os metadados extraídos pelo Unstructured. Esses metadados são necessários porque precisamos adicioná-los ao armazenamento de vetores. Ele nos fornecerá atributos adicionais para filtrar e nos informará algo sobre os dados recuperados.
from unstructured.staging.base import elements_from_base64_gzipped_json
import PIL.Image
import io
import base64
embedding_objects = []
embedding_metadatas = []
for chunk in chunks:
embedding_object = []
metedata_dict = {
"text": chunk.to_dict()["text"],
"filename": chunk.to_dict()["metadata"]["filename"],
"page_number": chunk.to_dict()["metadata"]["page_number"],
"last_modified": chunk.to_dict()["metadata"]["last_modified"],
"languages": chunk.to_dict()["metadata"]["languages"],
"filetype": chunk.to_dict()["metadata"]["filetype"]
}
embedding_object.append(chunk.to_dict()["text"])
# 将图像添加到嵌入对象
if "orig_elements" in chunk.to_dict()["metadata"]:
base64_elements_str = chunk.to_dict()["metadata"]["orig_elements"]
eles = elements_from_base64_gzipped_json(base64_elements_str)
image_data = []
for ele in eles:
if ele.to_dict()["type"] == "Image":
base64_image = ele.to_dict()["metadata"]["image_base64"]
image_data.append(base64_image)
pil_image = PIL.Image.open(io.BytesIO(base64.b64decode(base64_image)))
# 如果图像大于 1000x1000,则在保持纵横比的同时调整图像大小
if pil_image.size[0] > 1000 or pil_image.size[1] > 1000:
ratio = min(1000/pil_image.size[0], 1000/pil_image.size[1])
new_size = (int(pil_image.size[0] * ratio), int(pil_image.size[1] * ratio))
pil_image = pil_image.resize(new_size, PIL.Image.Resampling.LANCZOS)
embedding_object.append(pil_image)
metedata_dict["image_data"] = image_data
embedding_objects.append(embedding_object)
embedding_metadatas.append(metedata_dict)
O resultado desse script será uma lista de listas cujo conteúdo é mostrado abaixo:
[['来自\n\n冰岛 KIRKJUFELL 的位置',
<PIL.Image.Image image mode=RGB size=1000x381>,
<PIL.Image.Image image mode=RGB size=526x1000>],
['这座标志性的山峰是我们冰岛拍摄地点的首选,而且在我们去那里之前,我们就看过许多从附近瀑布拍摄的照片。因此,这是我们在日出时前往的第一个地方 - 我们没有失望。这些瀑布为这张照片(顶部)提供了完美的近景趣味,而从这个角度来看,Kirkjufell 是一座完美的尖山。我们花了一两个小时简单地探索这些瀑布,找到了几个不同的角度。']]
Etapa 3: Vetorizar os dados extraídos
Nesta etapa, usaremos o bloco criado na etapa anterior com o parâmetro Pacotes Python do Voyager Envie-os para o Voyager, que nos retornará uma lista de todos os objetos incorporados. Podemos então usar esse resultado e, eventualmente, armazená-lo no Weaviate.
from dotenv import load_dotenv
import voyageai
load_dotenv()
vo = voyageai.Client()
# 这将自动使用环境变量 VOYAGE_API_KEY。
# 或者,您可以使用 vo = voyageai.Client(api_key="<您的密钥>")
# 包含文本字符串和 PIL 图像对象的示例输入
inputs = embedding_objects
# 向量化输入
result = vo.multimodal_embed(
inputs,
model="voyage-multimodal-3",
truncation=False
)
Se acessarmos result.embeddings, obteremos uma lista contendo uma lista de todos os vetores de incorporação computados:
[[-0.052734375, -0.0164794921875, 0.050048828125, 0.01348876953125, -0.048095703125, ...]]Agora podemos usar o batch.add_object armazena esses dados incorporados no Weaviate como um único lote. Observe que também adicionamos metadados ao parâmetro properties.
with collection.batch.dynamic() as batch:
for i, data_row in enumerate(embedding_objects):
batch.add_object(
properties=embedding_metadatas[i],
vector=result.embeddings[i]
)
Etapa 4: Consultando os dados
Agora podemos realizar uma pesquisa de similaridade e consultar os dados. Isso é fácil porque o processo é semelhante a uma pesquisa de similaridade regular realizada em uma incorporação de texto. Como o Weaviate não tem um módulo para o Voyager Multimodal, precisamos calcular o vetor de consulta de pesquisa antes de passá-lo para o Weaviate para realizar uma pesquisa de similaridade.
from weaviate.classes.query import MetadataQuery
question = "杂志上关于瀑布说了什么?"
vector = vo.multimodal_embed([[question]], model="voyage-multimodal-3")
vector.embeddings[0]
response = collection.query.near_vector(
near_vector=vector.embeddings[0], # 您的查询向量在此处
limit=2,
return_metadata=MetadataQuery(distance=True)
)
# 显示结果
for o in response.objects:
print(o.properties['text'])
for image_data in o.properties['image_data']:
# 使用 PIL 显示图像
img = PIL.Image.open(io.BytesIO(base64.b64decode(image_data)))
width, height = img.size
if width > 500 or height > 500:
ratio = min(500/width, 500/height)
new_size = (int(width * ratio), int(height * ratio))
img = img.resize(new_size)
display(img)
print(o.metadata.distance)
A imagem abaixo mostra que uma pesquisa por cachoeiras retornará texto e imagens relevantes para essa consulta de pesquisa. Como você pode ver, as fotos refletem as cachoeiras, mas o texto em si não as menciona. O texto é sobre uma imagem com uma cachoeira, e é por isso que ele também foi recuperado. Isso não é possível para pesquisas regulares de incorporação de texto.

Uma imagem mostrando resultados de pesquisa de similaridade
Etapa 5: Adicione-o a todo o pipeline de pesquisa
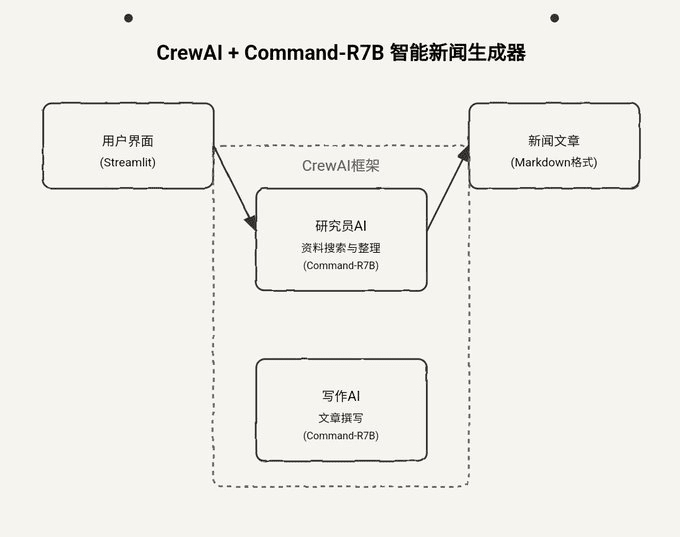
Agora que extraímos o texto e as imagens da revista, criamos embeddings para eles, os adicionamos ao Weaviate e configuramos nossa pesquisa de similaridade, vou adicioná-los ao pipeline de recuperação geral. Neste exemplo, usarei o LangGraph. O usuário fará uma pergunta sobre essa revista e o pipeline responderá a essa pergunta. Agora que todo o trabalho foi feito, essa parte é tão fácil quanto configurar um pipeline de recuperação típico usando texto regular.
Eu abstraí parte da lógica que discutimos na seção anterior em outros módulos. Veja como eu a integrei no módulo LangGraph Exemplos no pipeline.
class MultiModalRetrievalState(TypedDict):
messages: Annotated[Sequence[BaseMessage], add_messages]
results: List[Document]
base_64_images: List[str]
class RAGNodes(BaseNodes):
def __init__(self, logger, mode="online", document_handler=None):
super().__init__(logger, mode)
self.weaviate = Weaviate()
self.mode = mode
async def multi_modal_retrieval(self, state: MultiModalRetrievalState, config):
collection_name = config.get("configurable", {}).get("collection_name")
self.weaviate.set_collection(collection_name)
print("正在运行多模态检索")
print(f"正在搜索 {state['messages'][-1].content}")
results = self.weaviate.similarity_search(
query=state["messages"][-1].content, k=3, type="multimodal"
)
return {"results": results}
async def answer_question(self, state: MultiModalRetrievalState, config):
print("正在回答问题")
llm = self.llm_factory.create_llm(mode=self.mode, model_type="default")
include_images = config.get("configurable", {}).get("include_images", False)
chain = self.chain_factory.create_multi_modal_chain(
llm,
state["messages"][-1].content,
state["results"],
include_images=include_images,
)
response = await chain.ainvoke({})
message = AIMessage(content=response)
return {"messages": message}
# 定义配置
class GraphConfig(TypedDict):
mode: str = "online"
collection_name: str
include_images: bool = False
graph_nodes = RAGNodes(logger)
graph = StateGraph(MultiModalRetrievalState, config_schema=GraphConfig)
graph.add_node("multi_modal_retrieval", graph_nodes.multi_modal_retrieval)
graph.add_node("answer_question", graph_nodes.answer_question)
graph.add_edge(START, "multi_modal_retrieval")
graph.add_edge("multi_modal_retrieval", "answer_question")
graph.add_edge("answer_question", END)
multi_modal_graph = graph.compile()
__all__ = ["multi_modal_graph"]
O código acima gerará o seguinte gráfico

Representação visual dos gráficos criados

Nesse rastreamento, oVocê pode ver o conteúdo e as imagens que estão sendo enviados à OpenAI para responder às perguntas.
chegar a um veredicto
A incorporação multimodal abre a possibilidade de integrar e recuperar informações de diferentes tipos de dados (por exemplo, texto e imagens) no mesmo espaço de incorporação. Combinando ferramentas de ponta, como o modelo Voyager Multimodal 3, Weaviate e LangGraph, mostramos como criar um pipeline de recuperação robusto que compreende e vincula o conteúdo de forma mais intuitiva do que as abordagens tradicionais somente de texto.
Essa abordagem melhora significativamente a precisão da pesquisa e da recuperação em uma variedade de fontes de dados, como revistas, folhetos e PDFs. Ela também demonstra como a incorporação multimodal pode fornecer percepções mais ricas e contextuais que vinculam imagens a textos descritivos, mesmo na ausência de palavras-chave explícitas. Este tutorial permite que você explore e aplique essas técnicas em seus projetos.
Exemplo de notebook: https://github.com/vectrix-ai/vectrix-graphs/blob/main/examples/multi-model-embeddings.ipynb
© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Artigos relacionados


Nenhum comentário...