
Como escolher o melhor modelo de incorporação para aplicativos RAG

A incorporação de vetores está no centro dos atuais aplicativos RAG (Retrieval Augmented Generation). Eles capturam informações semânticas sobre objetos de dados (por exemplo, texto, imagens etc.) e as representam como matrizes de números. Nos aplicativos atuais de IA generativa, essas incorporações de vetores geralmente são geradas por modelos de incorporação. Como escolher o modelo de incorporação correto para um aplicativo RAG? Em geral, isso depende do caso de uso específico, bem como dos requisitos específicos. A seguir, vamos detalhar as etapas para analisar cada uma delas individualmente.
01. identificar casos de uso específicos
Consideramos as seguintes questões com base nos requisitos de aplicação do RAG:
Em primeiro lugar, um modelo genérico é suficiente para atender às necessidades?
Segundo, há necessidades específicas? Por exemplo, modalidade (por exemplo, somente texto ou imagem, para opções de incorporação multimodal, consulte a seçãoComo escolher o modelo de incorporação correto"), campos específicos (por exemplo, direito, medicina, etc.)
Na maioria dos casos, um modelo genérico é geralmente escolhido para os modos desejados.
02. seleção de modelos genéricos
Como escolher um modelo de uso geral? A tabela de classificação do Massive Text Embedding Benchmark (MTEB) no HuggingFace lista uma variedade de modelos atuais de incorporação de texto proprietários e de código aberto e, para cada modelo de incorporação, o MTEB lista uma variedade de métricas, incluindo parâmetros do modelo, memória, dimensões de incorporação, número máximo de tokens e suas pontuações em tarefas como recuperação e resumo.
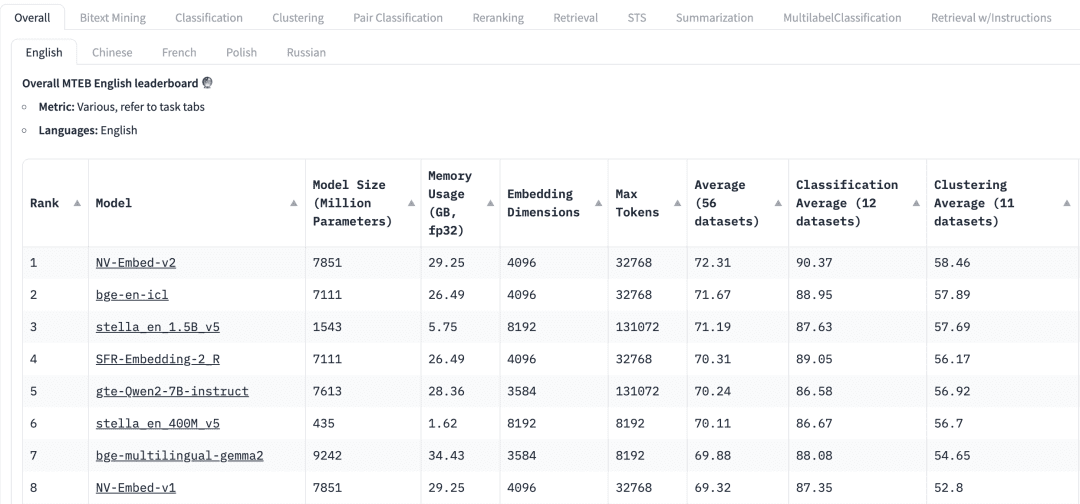
Os fatores a seguir precisam ser considerados ao selecionar um modelo de incorporação para um aplicativo RAG:
mandatosNa parte superior do MTEB Leaderboard, veremos várias guias de tarefas. Para um aplicativo RAG, talvez precisemos nos concentrar mais na tarefa "Retrieve" (Recuperar), na qual podemos escolher Retrial Essa guia.
multilinguismoCom base no idioma do conjunto de dados no qual o RAG é aplicado para selecionar o modelo de incorporação para o idioma correspondente.
pontuaçãoIndicação de desempenho: Indica o desempenho do modelo em um conjunto de dados de referência específico ou em vários conjuntos de dados de referência. Dependendo da tarefa, são usadas diferentes métricas de avaliação. Normalmente, essas métricas assumem valores que variam de 0 a 1, sendo que valores mais altos indicam melhor desempenho.
Tamanho do modelo e uso de memóriaEssas métricas nos dão uma ideia dos recursos computacionais necessários para executar o modelo. Embora o desempenho da recuperação melhore com o tamanho do modelo, é importante observar que o tamanho do modelo também afeta diretamente a latência. Além disso, modelos maiores podem ser excessivamente ajustados e ter baixo desempenho de generalização, o que resulta em um desempenho ruim na produção. Portanto, precisamos buscar um equilíbrio entre o desempenho e a latência em um ambiente de produção. Em geral, podemos começar com um modelo pequeno e leve e criar o aplicativo RAG rapidamente primeiro. Depois que o processo subjacente do aplicativo estiver funcionando corretamente, podemos mudar para um modelo maior e de desempenho mais alto para otimizar ainda mais o aplicativo.
Dimensões de incorporaçãoComprimento do vetor de incorporação: Esse é o comprimento do vetor de incorporação. Embora dimensões de incorporação maiores possam capturar detalhes mais finos nos dados, os resultados não são necessariamente ideais. Por exemplo, será que realmente precisamos de 8192 dimensões para dados de documentos? Provavelmente não. Por outro lado, dimensões de incorporação menores proporcionam inferência mais rápida e são mais eficientes em termos de armazenamento e memória. Portanto, precisamos encontrar um bom equilíbrio entre a captura do conteúdo dos dados e a eficiência da execução.
Número máximo de tokensindica o número máximo de tokens para uma única incorporação. Para aplicativos RAG comuns, o melhor tamanho de fragmento para incorporação é geralmente um único parágrafo, caso em que um modelo de incorporação com um token máximo de 512 deve ser suficiente. Entretanto, em alguns casos especiais, podemos precisar de modelos com um número maior de tokens para lidar com textos mais longos.
03. avaliação de modelos em aplicativos RAG
Embora possamos encontrar modelos genéricos nas tabelas de classificação do MTEB, precisamos tratar seus resultados com cautela. Levando em conta que esses resultados são informados pelos próprios modelos, é possível que alguns modelos produzam pontuações que aumentam seu desempenho porque podem ter incluído os conjuntos de dados do MTEB em seus dados de treinamento, que são, afinal, conjuntos de dados disponíveis publicamente. Além disso, o conjunto de dados que o modelo usa para avaliação comparativa pode não representar com precisão os dados usados em nosso aplicativo. Portanto, precisamos avaliar os modelos de incorporação em nossos próprios conjuntos de dados.
3.1 Conjuntos de dados
Podemos gerar um pequeno conjunto de dados marcados a partir dos dados usados pelo aplicativo RAG. Vamos usar o seguinte conjunto de dados como exemplo.
| Idioma | Descrição |
|---|---|
| C/C++ | Linguagem de programação de uso geral, conhecida por seu desempenho e eficiência, que oferece recursos de manipulação de memória de baixo nível e é amplamente usada no desenvolvimento de sistemas/software, desenvolvimento de jogos e aplicativos que exigem alto desempenho. |
| Java | Uma linguagem de programação versátil e orientada a objetos, projetada para ter o mínimo possível de dependências de implementação. É amplamente usada para criar aplicativos de escala empresarial, aplicativos móveis (especialmente Android) e aplicativos da Web devido à sua portabilidade e robustez. |
| Python | Linguagem de programação interpretada de alto nível, conhecida por sua legibilidade e simplicidade. Suporta vários paradigmas de programação e é amplamente Oferece suporte a vários paradigmas de programação e é amplamente utilizada no desenvolvimento da Web, na análise de dados, na inteligência artificial, na computação científica e na automação. |
| JavaScript | Linguagem de programação dinâmica e de alto nível usada principalmente para criar conteúdo interativo e dinâmico na Web. É uma tecnologia essencial para o desenvolvimento front-end da Web e é cada vez mais usada no lado do servidor com ambientes como o Node.js. |
| C# | É usado para o desenvolvimento de uma ampla gama de aplicativos, incluindo web, desktop, dispositivos móveis e jogos, especialmente dentro do ecossistema da Microsoft. É usado para o desenvolvimento de uma ampla variedade de aplicativos, incluindo Web, desktop, móveis e jogos, especialmente no ecossistema da Microsoft. |
| SQL | Linguagem específica de domínio usada na programação e no gerenciamento de bancos de dados relacionais, essencial para consultar, atualizar e gerenciar dados em bancos de dados. É essencial para consultar, atualizar e gerenciar dados em bancos de dados e é amplamente usada em análise de dados e business intelligence. |
| PHP | Ele é incorporado ao HTML e é amplamente usado para criar páginas da Web e aplicativos dinâmicos, com uma forte presença em sistemas de gerenciamento de conteúdo como o WordPress. aplicativos, com uma forte presença em sistemas de gerenciamento de conteúdo como o WordPress. |
| Golang | Linguagem de programação compilada e estaticamente tipada, projetada pelo Google. Conhecida por sua simplicidade e eficiência, é usada para criar aplicativos escalonáveis e de alto desempenho, principalmente em serviços de nuvem e sistemas distribuídos. -desempenho, especialmente em serviços de nuvem e sistemas distribuídos. |
| Ferrugem | Linguagem de programação de sistemas focada em segurança e simultaneidade. Fornece segurança de memória sem usar um coletor de lixo e é usada para criar software confiável e eficiente. Fornece segurança de memória sem usar um coletor de lixo e é usada para criar software confiável e eficiente, especialmente em programação de sistemas e montagem na Web. |
3.2 Criação de incorporação
Em seguida, usamos opymilvus[model]Para o conjunto de dados acima, o vetor Embedding correspondente é gerado. pymilvus[model] Para uso, consulte https://milvus.io/blog/introducing-pymilvus-integrations-with-embedding-models.md
def gen_embedding(model_name): openai_ef = model.dense.OpenAIEmbeddingFunction( model_name=model_name, api_key=os.environ["OPENAI_API_KEY"] ) docs_embeddings = openai_ef.encode_documents(df['description'].tolist()) return docs_embeddings, openai_ef
Em seguida, o Embedding gerado é depositado na coleção do Milvus.
def save_embedding(docs_embeddings, collection_name, dim):
data = [
{"id": i, "vector": docs_embeddings[i].data, "text": row.language}
for i, row in df.iterrows()
]
if milvus_client.has_collection(collection_name=collection_name):
milvus_client.drop_collection(collection_name=collection_name)
milvus_client.create_collection(collection_name=collection_name, dimension=dim)
res = milvus_client.insert(collection_name=collection_name, data=data)
3.3 Consultas
Definimos funções de consulta para facilitar a recuperação do vetor Embedding.
def query_results(query, collection_name, openai_ef):
query_embeddings = openai_ef.encode_queries(query)
res = milvus_client.search(
collection_name=collection_name,
data=query_embeddings,
limit=4,
output_fields=["text"],
)
result = {}
for items in res:
for item in items:
result[item.get("entity").get("text")] = item.get('distance')
return result
3.4 Avaliação do desempenho do modelo de incorporação
Usamos dois modelos de incorporação da OpenAI.text-embedding-3-small responder cantando text-embedding-3-largepara as duas consultas a seguir são comparados. Há muitas métricas de avaliação, como precisão, recall, MRR, MAP etc. Aqui, usamos a precisão e a recuperação.
Precisão Avalia a porcentagem de conteúdo genuinamente relevante nos resultados da pesquisa, ou seja, quantos dos resultados retornados são relevantes para a consulta de pesquisa.
Precisão = TP / (TP + FP)
Nesse caso, os True Positives (TP) são aqueles que são realmente relevantes para a consulta, enquanto os False Positives (FP) referem-se àqueles que não são relevantes nos resultados da pesquisa.
O recall avalia a quantidade de conteúdo relevante recuperado com êxito de todo o conjunto de dados.
Recuperação = TP / (TP + FN)
Os falsos negativos (FN) referem-se a todos os itens relevantes que não estão incluídos no conjunto de resultados finais.
Para obter uma explicação mais detalhada desses dois conceitos
Consulta 1::auto garbage collection
Itens relacionados: Java, Python, JavaScript, Golang
| Classificação | incorporação de texto-3-pequeno | incorporação de texto-3-grande |
|---|---|---|
| 1 | ❎ Ferrugem | ❎ Ferrugem |
| 2 | ❎ C/C++ | ❎ C/C++ |
| 3 | ✅ Golang | ✅ Java |
| 4 | ✅ Java | ✅ Golang |
| Precisão | 0.50 | 0.50 |
| Recall | 0.50 | 0.50 |
Consulta 2::suite for web backend server development
Itens relacionados: Java, JavaScript, PHP, Python (as respostas incluem julgamento subjetivo)
| Classificação | incorporação de texto-3-pequeno | incorporação de texto-3-grande |
|---|---|---|
| 1 | ✅ PHP | ✅ JavaScript |
| 2 | ✅ Java | ✅ Java |
| 3 | ✅ JavaScript | ✅ PHP |
| 4 | ❎ C# | ✅Python |
| Precisão | 0.75 | 1.0 |
| Recall | 0.75 | 1.0 |
Nessas duas consultas, comparamos os dois modelos de incorporação de acordo com a precisão e a recuperação text-embedding-3-small responder cantando text-embedding-3-large O modelo Embedding pode ser usado como ponto de partida. Podemos usá-lo como ponto de partida para aumentar o número de objetos de dados no conjunto de dados, bem como o número de consultas, para que o modelo de incorporação possa ser avaliado com mais eficácia.
04. resumo
Nos aplicativos Retrieval Augmented Generation (RAG), a seleção de modelos de incorporação de vetores adequados é crucial. Neste artigo, ilustramos que, depois de selecionar um modelo genérico do MTEB a partir dos requisitos reais do negócio, a precisão e a recuperação são usadas para testar o modelo com base em um conjunto de dados específico do negócio, de modo a selecionar o modelo de incorporação mais adequado, o que, por sua vez, melhora efetivamente a precisão da recuperação do aplicativo RAG.
O código completo está disponível para download
© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Artigos relacionados



Nenhum comentário...