:边查边写的检索策略,适合查询实时数据-1")
:边查边写的检索策略,适合查询实时数据-2")
:边查边写的检索策略,适合查询实时数据-3")
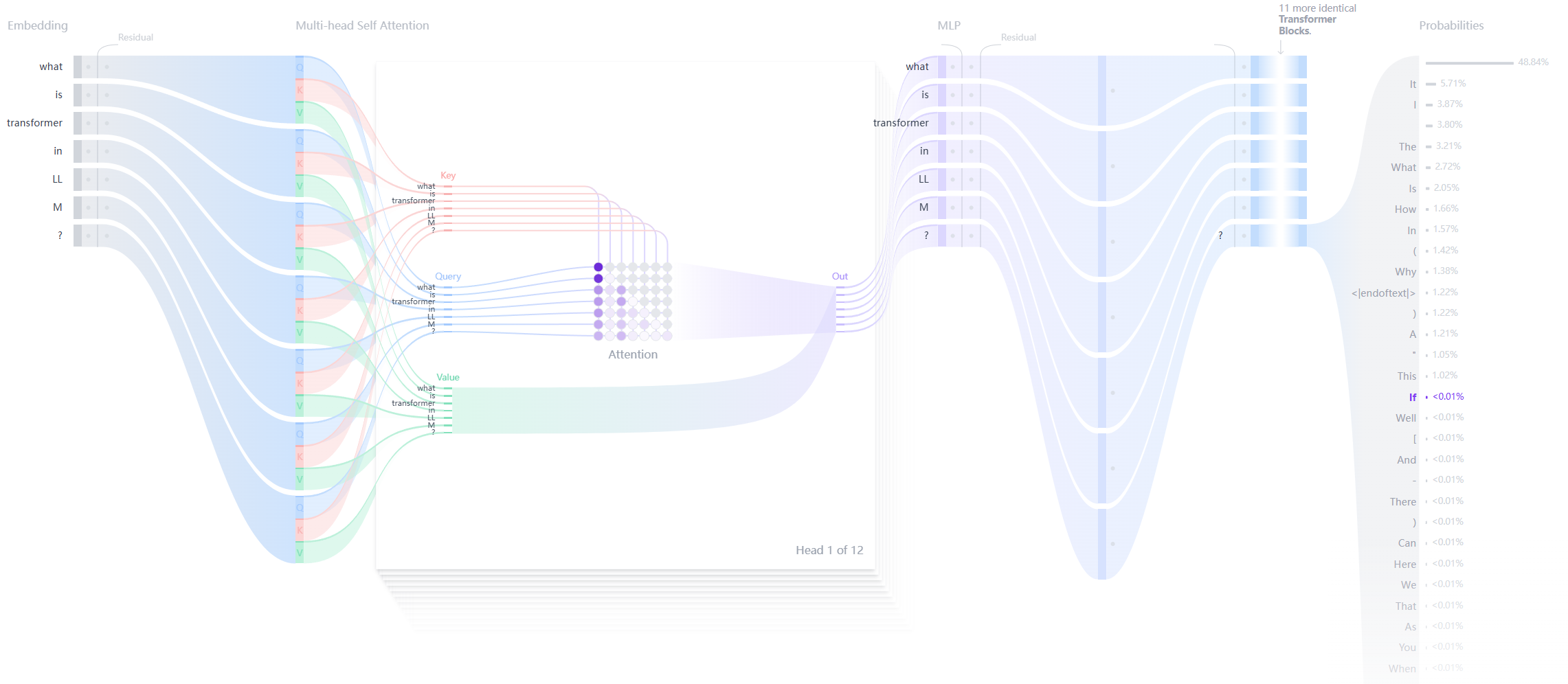
RIG (Retrieval Interleaved Generation): uma estratégia de recuperação de escrita durante a pesquisa, adequada para consultar dados em tempo real

Núcleo da tecnologia: Retrieval Interleaved Generation (RIG)
- O que é RIG?
O RIG é uma metodologia geradora inovadora projetada para resolver o problema de alucinação no processamento de dados estatísticos por grandes modelos de linguagem. Enquanto os modelos tradicionais podem gerar números ou fatos imprecisos do nada, o RIG garante a autenticidade dos dados inserindo consultas a fontes de dados externas no processo de geração. - Princípio de funcionamento ::
- Quando o modelo recebe uma pergunta que requer estatísticas, ele chama dinamicamente o Data Commons (uma base de conhecimento de dados públicos alimentada pelo Google) à medida que gera a resposta.
- Os resultados da consulta são incorporados na saída em linguagem natural, por exemplo:[DC("What is the population of France?") --> "67 million"].
- Essa "intercalação de recuperação e geração" permite que o modelo mantenha a fluência linguística e, ao mesmo tempo, forneça informações estatísticas validadas.
Detalhes do modelo
- modelo básico Gemma 2 (versão de parâmetro 27B), um modelo de linguagem eficiente de código aberto projetado para pesquisa e experimentação.
- Metas de ajuste fino Treinados especificamente para reconhecer quando o Data Commons precisa ser consultado e para integrar perfeitamente esses dados ao processo de geração.
- Entradas e saídas ::
- Entrada: qualquer prompt de texto (como uma pergunta ou declaração).
- Saída: texto em inglês, pode conter resultados de consulta do Data Commons incorporados.
- multilinguismo Inglês: O idioma suportado é principalmente o inglês ("it" pode significar "instruction-tuned", ou seja, versão ajustada para instruções, mas a página não especifica o intervalo de idiomas).
cenário do aplicativo
- usuário-alvo pesquisadores acadêmicos, cientistas de dados.
- uso Adequado para cenários em que são necessárias estatísticas precisas, por exemplo, respostas para "a população de um país", "emissões globais de CO2 em um determinado ano", etc.
- restrição : Atualmente, em uma versão inicial, é apenas para testadores confiáveis e não é recomendado para ambientes de produção ou uso comercial.
Modelos:https://huggingface.co/google/datagemma-rig-27b-it
Texto original:https://arxiv.org/abs/2409.13741
Processo de realização do RIG
O RIG é uma abordagem que intercala a recuperação com a geração, com o objetivo de melhorar a precisão dos resultados gerados, fazendo com que o LLM gere consultas em linguagem natural para recuperar dados do Data Commons. Veja a seguir as etapas detalhadas da implementação do RIG:
1. Model Fine-tuning (Ajuste fino do modelo)
objetivosPara que o LLM aprenda a gerar consultas em linguagem natural que possam ser usadas para recuperar estatísticas do Data Commons.
mover::
- Consulta e geração iniciaisQuando o LLM recebe uma consulta estatística, ele geralmente gera um texto contendo uma resposta numérica. Vamos nos referir a essa resposta numérica comoValores estatísticos gerados pelo LLM (LLM-SV)Por exemplo, para a consulta "Qual é a população total da Califórnia? Por exemplo, para a consulta "Qual é a população total da Califórnia?" o LLM pode gerar "A população total da Califórnia é de aproximadamente 39 milhões".
- Identificação de dados relevantesA partir do texto gerado pelo LLM, precisamos identificar os dados mais relevantes do banco de dados do Data Commons para disponibilizá-los aos usuários como um mecanismo de verificação de fatos. Referimo-nos a esse valor recuperado comoValores estatísticos da Data Commons (DC-SV).
- Gerar consultas em linguagem naturalPara isso, ajustamos o LLM para que ele gere uma consulta em linguagem natural descrevendo o LLM-SV junto com o LLM-SV. Essa consulta será usada para recuperar dados do Data Commons.
:边查边写的检索策略,适合查询实时数据-1")
Figura 1: Comparação das respostas às consultas; linha de base Gemma (Gemma 7B IT, Gemma 2 27B IT) sem interface com o Data Commons e respostas Retrieve Interleaved Generation (RIG).Figura 1É mostrada uma comparação das respostas do modelo Gemma de linha de base e do modelo RIG. O modelo RIG não apenas gera os valores estatísticos, mas também as consultas usadas para recuperação.
- Conjunto de dados de treinamentoUsamos um conjunto de dados de resposta a comandos contendo cerca de 700 consultas de usuários para ajuste fino. Para cada consulta, selecionamos respostas geradas pelo modelo básico contendo dados estatísticos (cerca de 400 exemplos) e usamos um LLM mais avançado (por exemplo, Gemini 1.5 Pro) para gerar chamadas de linguagem natural do Data Commons.
exemplo típico::
- consultar (um documento etc.)Conte-me uma estatística sobre a Califórnia, São Francisco, Alabama e os EUA.
- resposta bruta::
- A Califórnia está em primeiro lugar como o estado mais populoso do país, com cerca de 39 milhões de pessoas em 2020.
- Em São Francisco, a taxa de diabetes é de 9,2 casos por 10.000 pessoas.
- ...
- Resposta com ajuste fino::
- A Califórnia está em primeiro lugar como o estado mais populoso do país, com cerca de [DC("qual era a população da Califórnia em 2020?") --> "39 milhões"] pessoas.
- Em São Francisco, a taxa de diabetes é de [DC("qual é a prevalência de diabetes em São Francisco?") --> "9,2 casos por 10.000 pessoas"].
- ...
2. Conversão de consulta
objetivosConverte consultas em linguagem natural geradas pelo LLM em consultas estruturadas para recuperação de dados do Data Commons.
mover::
- decompor uma consultaDecompor a consulta de linguagem natural nos seguintes componentes:
- Variáveis ou tópicos estatísticos:: por exemplo, "Taxa de desemprego", "Dados demográficos", etc.
- locaisPor exemplo, "Califórnia".
- causalidade:: por exemplo, "classificação", "comparação", "taxa de mudança", etc.
- Mapeamento e identificaçãoMapeie esses componentes para suas IDs correspondentes no Data Commons, por exemplo, usando a indexação de pesquisa semântica baseada em incorporação para identificar variáveis estatísticas e o reconhecimento de entidade nomeada baseado em cadeia para implementar a identificação de locais.
- Correspondência de categorias e modelosClassificação: classifica as consultas em um conjunto fixo de modelos de consulta com base nos componentes identificados. Exemplo:
- Quantos XX em YY(YY有多少XX))
- What is the correlation between XX and YY across ZZ in AA (Qual é a correlação entre XX e YY em ZZ em AA)
- Quais XX em YY têm o maior número de ZZ (YY中哪些XX的ZZ数量最多)
- Quais são os XX mais significativos em YY(YYY中最显著的XX是什么 35 quais são os XX mais significativos em YY 34)
Figura 2: Comparação dos métodos de linha de base, RIG e RAG para gerar respostas com estatísticas. A abordagem de linha de base relata estatísticas diretamente sem fornecer evidências, enquanto o RIG e o RAG utilizam o Data Commons para fornecer dados confiáveis.Figura 2O método RIG gera tags estatísticas intercalando-as com perguntas em linguagem natural adequadas para recuperação no Data Commons.
- Execução de consultasAPI de Dados Estruturados do Data Commons: chame a API de Dados Estruturados do Data Commons para recuperar dados com base em modelos de consulta e IDs de variáveis e locais.
3. Atendimento
objetivosApresentação dos dados recuperados ao usuário, juntamente com os valores estatísticos gerados pelo LLM.
mover::
- Apresentação de dadosApresenta as respostas retornadas pelo Data Commons ao usuário, juntamente com as estatísticas geradas pelo LLM original. Isso dá aos usuários a oportunidade de verificar os fatos do LLM.
Figura 3: Ferramenta de avaliação do RIG. Esta figura mostra capturas de tela das duas fases de avaliação, exibidas lado a lado. Há dois painéis para cada estágio. À esquerda, o usuário vê a resposta completa que está sendo avaliada (excluída na imagem acima para economizar espaço). No lado direito está a tarefa de avaliação. No estágio 1, o avaliador realiza uma verificação rápida para detectar erros óbvios. No estágio 2, o avaliador avalia cada estatística presente na resposta.Figura 3Demonstra o processo de utilização da ferramenta de avaliação RIG. O avaliador pode verificar rapidamente se há erros óbvios e avaliar todas as estatísticas presentes na resposta.
- experiência do usuárioHá várias maneiras de apresentar esse novo resultado, como lado a lado, destacando diferenças, notas de rodapé, ações de passar o mouse etc., que podem ser exploradas em um trabalho futuro.
resumos
O processo de implementação do RIG inclui as seguintes etapas principais:
- Modelagem do ajuste finoPermita que o LLM gere consultas em linguagem natural que descrevam os valores estatísticos gerados pelo LLM.
- Conversão de consultaConversão de consultas em linguagem natural em consultas estruturadas para recuperação de dados do Data Commons.
- Recuperação e apresentação de dadosDados: recupera dados do Data Commons e apresenta os dados recuperados ao usuário juntamente com as estatísticas geradas pelo LLM.
Por meio dessas etapas, o método RIG combina efetivamente os recursos geradores do LLM com os recursos de dados do Data Commons, melhorando assim a precisão do LLM no processamento de consultas estatísticas.
© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Artigos relacionados



Nenhum comentário...