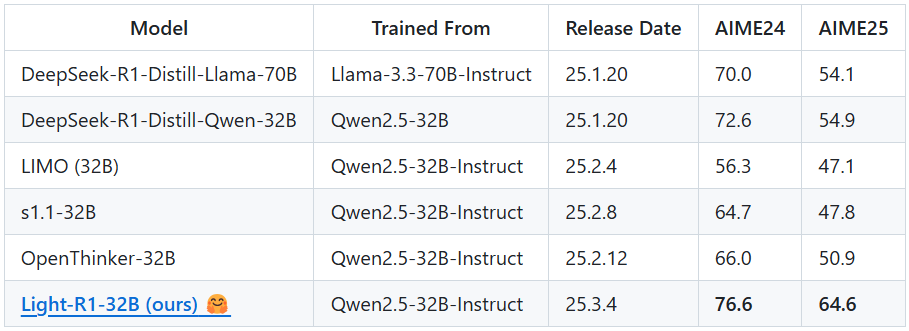
Rankify: um kit de ferramentas Python que oferece suporte à recuperação e reordenação de informações

Introdução geral
O Rankify é um kit de ferramentas Python de código aberto desenvolvido pelo Data Science Group da Universidade de Innsbruck, na Áustria. Ele se concentra na recuperação de informações, reordenação e geração de aumento de recuperação (RAG), fornecendo uma estrutura unificada. O kit de ferramentas vem com 40 conjuntos de dados de referência pré-obtidos incorporados, suporte para 7 técnicas de recuperação e 24 modelos de reordenação, e inclui uma variedade de RAG O Rankify é modular e facilmente extensível, adequado para pesquisadores e desenvolvedores para experimentação e avaliação comparativa. O código é aberto e bem documentado, e é compatível com Python 3.10 e superior.

Lista de funções
- Sete técnicas de recuperação estão disponíveis, incluindo BM25, DPR, ColBERT, ANCE, BGE, Contriever e HYDE.
- Há suporte para 24 modelos de reordenação, como MonoT5, RankGPT, Sentence Transformador etc., para melhorar a precisão dos resultados da pesquisa.
- RAG (Retrieval Augmented Generation) integrado com suporte para GPT, LLaMA, T5 e outras respostas de geração de modelos.
- 40 conjuntos de dados pré-obtidos incorporados que abrangem perguntas e respostas, diálogo, vinculação de entidades e outros cenários.
- Fornece ferramentas de avaliação para calcular métricas de recuperação, reordenação e geração de resultados, como Top-K, EM, Recall.
- Oferece suporte a índices pré-criados (por exemplo, Wikipedia e MS MARCO), eliminando a necessidade de criar seus próprios índices.
- Estrutura modular que permite aos usuários personalizar conjuntos de dados, recuperadores e modelos.
Usando a Ajuda
O Rankify é simples de instalar e usar. Abaixo estão as etapas e instruções detalhadas para ajudá-lo a começar rapidamente.
Processo de instalação
O Rankify requer o Python 3.10 ou superior. Recomenda-se instalá-lo em um ambiente virtual para evitar conflitos de dependência.
- Criação de um ambiente virtual (recomendado)
Crie um ambiente usando o Conda:
conda create -n rankify python=3.10
conda activate rankify
ou usar as próprias ferramentas do Python:
python -m venv rankify_env
source rankify_env/bin/activate # Linux/Mac
rankify_env\Scripts\activate # Windows
- Instale o PyTorch (versão recomendada 2.5.1)
Se você tiver uma GPU, instale a versão com CUDA 12.4:
pip install torch==2.5.1 torchvision==0.20.1 torchaudio==2.5.1 --index-url https://download.pytorch.org/whl/cu124
Se você não tiver uma GPU, instale a versão para CPU:
pip install torch==2.5.1
- Instalação da fundação
Instale a funcionalidade principal do Rankify:
pip install rankify
- Instalação completa (recomendada)
Instale todos os recursos:
pip install "rankify[all]"
- Instalação sob demanda (opcional)
Somente a função de pesquisa está instalada:
pip install "rankify[retriever]"
Somente a função de reordenação está instalada:
pip install "rankify[reranking]"
- Instale a versão mais recente do GitHub (opcional)
Obtenha a versão de desenvolvimento:
git clone https://github.com/DataScienceUIBK/Rankify.git
cd Rankify
pip install -e ".[all]"
- Instalação do ColBERT Retriever (opcional)
É necessária uma configuração adicional:
conda install -c conda-forge gcc=9.4.0 gxx=9.4.0
conda install -c conda-forge libstdcxx-ng
export LD_LIBRARY_PATH=$CONDA_PREFIX/lib:$LD_LIBRARY_PATH
export CC=gcc
export CXX=g++
rm -rf ~/.cache/torch_extensions/*
O Rankify está pronto para ser usado após a instalação.
Guia de operação de funções
1. uso de conjuntos de dados pré-pesquisados
O Rankify oferece 40 conjuntos de dados pré-obtidos que podem ser baixados do Hugging Face.
- mover::
- Módulo de importação de conjunto de dados.
- Selecione o retriever e o conjunto de dados.
- Baixar ou carregar dados.
- Código de amostra (computação)::
from rankify.dataset.dataset import Dataset
# 查看可用数据集
Dataset.available_dataset()
# 下载 BM25 的 nq-dev 数据集
dataset = Dataset(retriever="bm25", dataset_name="nq-dev", n_docs=100)
documents = dataset.download(force_download=False)
# 加载本地数据集
documents = Dataset.load_dataset('./bm25_nq_dev.json', 100)
2. uso da função de pesquisa
Oferece suporte a vários métodos de pesquisa, como BM25, DPR, etc.
- mover::
- Inicializar o recuperador.
- Insira um documento ou uma pergunta.
- Obter resultados de pesquisa.
- Código de amostra (computação)::
from rankify.retrievers.retriever import Retriever # 使用 BM25 检索 Wikipedia retriever = Retriever(method="bm25", n_docs=5, index_type="wiki") docs = [{"question": "太阳是什么?"}] results = retriever.retrieve(docs) print(results)
3. uso da função de reordenação
A reordenação otimiza os resultados da recuperação e oferece suporte a vários modelos.
- mover::
- Preparar os resultados iniciais da pesquisa.
- Inicializar o modelo de reordenação.
- Reordenação.
- Código de amostra (computação)::
from rankify.models.reranking import Reranking from rankify.dataset.dataset import Document, Question, Context # 准备数据 question = Question("太阳是什么?") contexts = [Context(text="太阳是恒星。", id=1), Context(text="月亮不是恒星。", id=2)] doc = Document(question=question, contexts=contexts) # 重排序 reranker = Reranking(method="monot5", model_name="monot5-base-msmarco") reranker.rank([doc]) for ctx in doc.reorder_contexts: print(ctx.text)
4. uso da função RAG
O RAG combina recuperação e geração para gerar respostas precisas.
- mover::
- Preparar documentação e perguntas.
- Inicialize o gerador.
- Gerar respostas.
- Código de amostra (computação)::
from rankify.generator.generator import Generator doc = Document(question=Question("法国首都是什么?"), contexts=[Context(text="法国首都是巴黎。", id=1)]) generator = Generator(method="in-context-ralm", model_name="meta-llama/Llama-3.1-8B") answers = generator.generate([doc]) print(answers) # 输出:["巴黎"]
5. avaliação dos resultados
Ferramenta de avaliação integrada para verificar o desempenho.
- Código de amostra (computação)::
from rankify.metrics.metrics import Metrics metrics = Metrics(documents) retrieval_metrics = metrics.calculate_retrieval_metrics(ks=[1, 5, 10]) print(retrieval_metrics)
advertência
- Os usuários de GPU precisam garantir que o PyTorch seja compatível com CUDA.
- Dispositivos de alta memória são recomendados para grandes conjuntos de dados.
- Para obter mais detalhes, consulte a documentação oficial em http://rankify.readthedocs.io/.
cenário do aplicativo
- pesquisa acadêmica
Os pesquisadores podem usar o Rankify para testar algoritmos de recuperação e reordenação e analisar o desempenho. - Perguntas e respostas inteligentes (Q&A)
Os desenvolvedores podem usar o RAG para criar sistemas de Q&A para responder às perguntas dos usuários. - Otimização de pesquisa
O recurso de reordenação melhora a relevância dos resultados de pesquisa e é adequado para aprimorar os mecanismos de pesquisa.
QA
- Quais sistemas são compatíveis com o Rankify?
Windows, Linux e macOS são compatíveis, desde que o Python 3.10+ esteja instalado. - Preciso fazer networking?
A funcionalidade principal está disponível off-line, mas os conjuntos de dados e alguns modelos precisam ser baixados. - Ele é compatível com o idioma chinês?
Suportado, mas os índices pré-criados estão principalmente em inglês (Wikipedia e MS MARCO).
© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Artigos relacionados

Nenhum comentário...