
r1-reasoning-rag: novas ideias para RAG baseadas em raciocínio recursivo a partir de informações coletadas

Recentemente, descobri um projeto de código aberto que oferece uma excelente RAG A ideia de que ele DeepSeek-R1 A capacidade de raciocínio da combinação de Agentic Workflow Aplicado à pesquisa RAG
Endereço do projeto
https://github.com/deansaco/r1-reasoning-rag.git
O projeto está sendo implementado por meio de uma combinação de DeepSeek-R1eTavily responder cantando LangGraphque implementa um mecanismo dinâmico de resposta e recuperação de informações orientado por IA que utiliza deepseek (usado em uma expressão nominal) r1 Raciocínio para recuperar, descartar e sintetizar proativamente informações da base de conhecimento para responder completamente a uma pergunta complexa
RAG antigo vs. novo
O RAG (Retrieval Augmented Generation, geração aumentada de recuperação) tradicional é um pouco rígido. Normalmente, depois que a pesquisa é processada, algum conteúdo é encontrado por meio da pesquisa de similaridade e, em seguida, reordenado de acordo com o grau de correspondência, e as informações que parecem confiáveis são fornecidas a um modelo de linguagem grande (LLM) para gerar a resposta. Mas isso depende particularmente da qualidade do modelo de reordenação e, se o modelo não for sólido, é fácil perder informações importantes ou passar as informações erradas para o LLM, e a resposta resultante não será confiável.
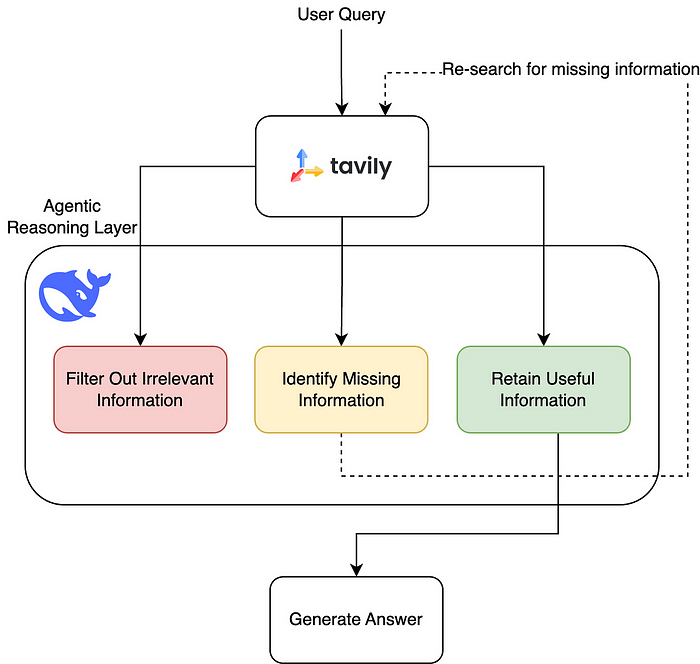
presente . LangGraph A equipe fez uma grande atualização no processo, usando o DeepSeek-R1 A poderosa capacidade de raciocínio da IA transformou o método de filtragem imóvel anterior em um processo mais flexível e dinâmico que pode ser ajustado de acordo com a situação. Eles chamam isso de "recuperação de agente", que permite que a IA não apenas encontre ativamente informações ausentes, mas também otimize continuamente sua própria estratégia no processo de busca de informações, formando uma espécie de efeito de otimização cíclica, de modo que o conteúdo entregue ao LLM seja mais preciso.
Esse aprimoramento, na verdade, aplica os conceitos de raciocínio de tempo de teste estendido de dentro do modelo para a recuperação de RAG, melhorando muito a precisão e a eficiência da recuperação. Vale a pena dar uma olhada nessa nova abordagem para quem trabalha com técnicas de recuperação de RAGs!
Tecnologia principal e destaques
DeepSeek-R1 Raciocínio
atualizado DeepSeek-R1 é um modelo de inferência poderoso
- Análise profunda do conteúdo das informações
- Avaliação do conteúdo existente
- Identificação de conteúdo ausente por meio de várias rodadas de raciocínio para melhorar a precisão dos resultados da pesquisa
Pesquisa de informações instantâneas da Tavily
Tavily Fornecer pesquisa de informações instantâneas, pode fazer com que o modelo grande no passado tenha as informações mais recentes, para expandir o escopo de conhecimento do modelo.
- Recuperação dinâmica para eliminar informações ausentes em vez de depender apenas de dados estáticos.
LangGraph Recuperação Recursiva (RR)
através de Agentic AI para permitir que o modelo grande forme um aprendizado de loop fechado após várias rodadas de recuperação e inferência, com o seguinte processo geral:
- A primeira etapa é a busca de informações sobre o problema
- A segunda etapa é analisar se as informações são suficientes para responder à pergunta.
- Etapa 3 Se as informações forem insuficientes, faça mais perguntas
- Etapa 4 Filtre o conteúdo irrelevante e mantenha apenas as informações válidas
tais 递归式 Mecanismo de recuperação para garantir que o modelo grande possa otimizar continuamente os resultados da consulta, tornando as informações filtradas mais completas e precisas.
análise de código-fonte
Pelo código-fonte, são três arquivos simples:agentellmeprompts
Agente
A ideia central desta seção é que create_workflow esta função
 Ele define isso
Ele define isso workflow O nó do add_conditional_edges Parte da definição é a borda condicional, e toda a ideia de processamento é a lógica recursiva do gráfico visto no início
Se não estiver familiarizado LangGraph Se tiver, você pode verificar as informações.LangGraph A construção é uma estrutura de dados de gráfico com nós e bordas, e suas bordas podem ser condicionais.
Depois de cada recuperação, ela é examinada pelo grande modelo, filtrando as informações inúteis (Filter Out Irrelevant Information), retendo as informações úteis (Retain Useful Information) e, para as informações ausentes (Identify Missing Information), ela é novamente examinada O processo é repetido até que a resposta desejada seja encontrada.
avisos
Há duas pistas principais definidas aqui.VALIDATE_RETRIEVAL Modelo de resposta: É usado para verificar se as informações recuperadas podem responder à pergunta fornecida. O modelo tem duas variáveis de entrada: retrieved_context e question. Seu principal objetivo é gerar uma resposta formatada em JSON que determina se elas contêm ou não informações que podem responder à pergunta com base nos blocos de texto fornecidos. 
ANSWER_QUESTIONModelo de resposta a perguntas: Usado para instruir um agente de resposta a perguntas a responder a uma pergunta com base em um bloco de texto fornecido. O modelo também tem duas variáveis de entrada: retrieved_context e question. Seu principal objetivo é fornecer uma resposta direta e concisa com base nas informações de contexto fornecidas.

lm
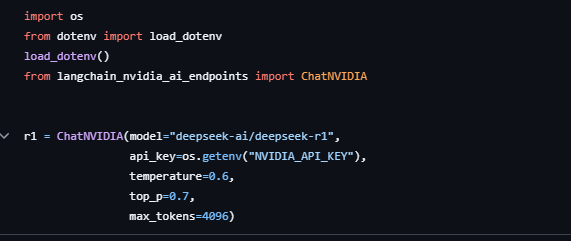
Aqui é simples definir o uso de r1 modelagem
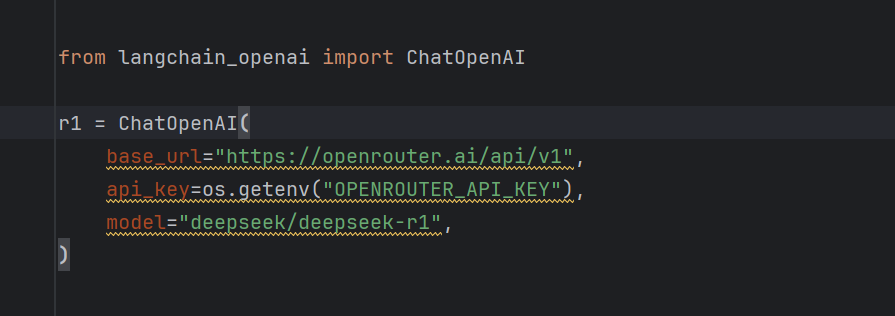
É possível mudar para modelos fornecidos por outros fornecedores, por exemplo openrouter gratuito r1 modelagem
efeito do teste
Escrevi um script separado aqui que não usa o que está no projeto, perguntando sobre o 《哪吒2》中哪吒的师傅的师傅是谁
Primeiro, ele chamará a pesquisa para procurar as informações e, em seguida, começará a validar o

Em seguida, ele começará a analisar e obterá 哪吒的师父是太乙真人 Essas informações são válidas, mas também encontramos informações faltando A identidade ou o nome específico do mestre de Taiyi (ou seja, o mestre de Nezha)

Em seguida, ele procura as informações que faltam e continua analisando e verificando as informações que recebe.
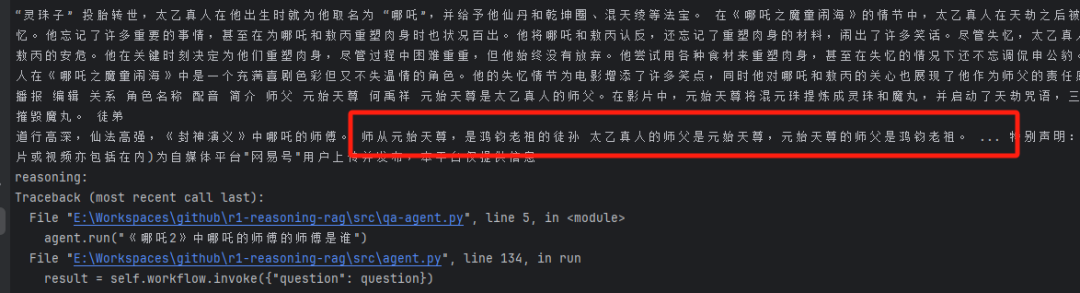
Ele relatou um erro mais tarde porque a rede estava inoperante no meu lado, mas, como você pode ver na imagem acima, ele deveria ter conseguido encontrar essa informação importante
© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Artigos relacionados




Nenhum comentário...