
Qwen3-ASR-Flash - uma série de modelos de reconhecimento de fala lançados por Ali Tongyi Qianqian

O que é o Qwen3-ASR-Flash?
O Qwen3-ASR-Flash é o mais recente modelo de reconhecimento de fala de alta precisão da Alibaba, baseado no Qwen3 Modelo básico, treinado por dados multimodais massivos. Ele é compatível com 11 idiomas e vários sotaques, incluindo dialetos como mandarim, sichuan, minnan, wu, cantonês, bem como inglês britânico e americano. Os principais recursos incluem precisão de reconhecimento líder, capacidade impressionante de reconhecimento de músicas (taxa de erro abaixo de 8%), reconhecimento personalizado (os usuários podem fornecer texto de fundo para obter resultados personalizados), reconhecimento de idiomas com rejeição não vocal e alta robustez em ambientes acústicos complexos. Os usuários podem experimentar o modelo gratuitamente por meio do ModelScope, do Hugging Face e da API Hundred Refinements do AliCloud.
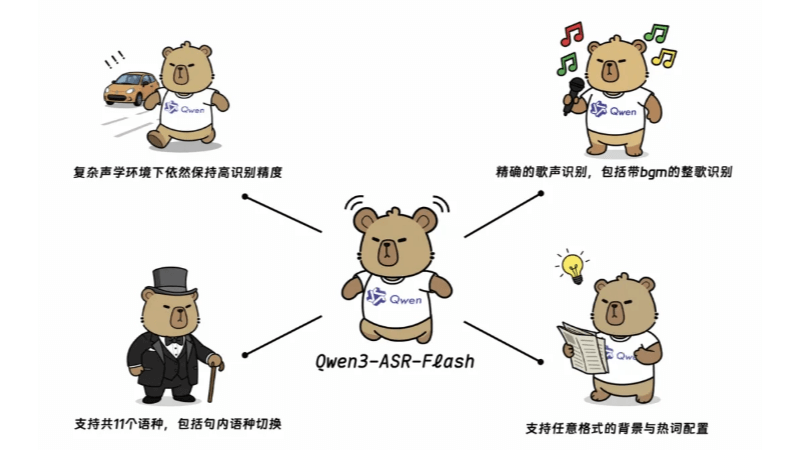
Características funcionais do Qwen3-ASR-Flash
- Reconhecimento altamente precisoO melhor desempenho em benchmarks de inglês, chinês e multilíngue, com reconhecimento preciso de vários idiomas e dialetos.
- reconhecimento de músicasO sistema suporta o reconhecimento de canto limpo e de canções inteiras com música de fundo, e a taxa de erro medida é menor que 8%.
- Identificação personalizadaO usuário pode fornecer texto de fundo em qualquer formato, e o modelo pode ajustar os resultados de reconhecimento de acordo, sem pré-processamento.
- Reconhecimento de idiomas e rejeição não vocalDistingue com precisão os idiomas de fala e filtra automaticamente os segmentos que não são de fala, como silêncio e ruído de fundo.
- alta robustezManteve alta precisão em ambientes acústicos complexos e quando confrontado com padrões de texto difíceis, como frases longas e difíceis e troca de idioma no meio da frase.
Principais benefícios do Qwen3-ASR-Flash
- Reconhecimento altamente precisoDesempenho excelente em testes de reconhecimento de vários idiomas e dialetos, com taxas de erro menores do que as dos produtos concorrentes.
- Suporte a vários idiomasO modelo único suporta 11 idiomas e vários dialetos, abrangendo mandarim, inglês, francês, alemão e outros.
- Identificação personalizadaOs usuários podem fornecer texto de fundo em qualquer formato, e o modelo pode usar de forma inteligente as informações contextuais para gerar resultados de reconhecimento personalizados.
- reconhecimento de músicasEle suporta o reconhecimento de canções limpas e completas com música de fundo, e a taxa de erro medida é menor que 8%, o que representa um excelente desempenho no campo do reconhecimento de canções.
- Reconhecimento de idiomas e rejeição não vocalCapacidade de distinguir com precisão os idiomas da fala e filtrar automaticamente os segmentos que não são de fala, como silêncio e ruído de fundo, melhora a eficiência do reconhecimento.
- alta robustezManteve alta precisão em ambientes acústicos complexos e quando confrontado com padrões de texto difíceis, como frases longas e difíceis e troca de idioma no meio da frase.
Qual é o site oficial do Qwen3-ASR-Flash?
- Site do projeto: https://bailian.console.aliyun.com/?spm=5176.29597918.J_tAwMEW-mKC1CPxlfy227s.1.4f007b08aWhTjW&tab=model#/model-market/detail /group-qwen3-asr-flash?modelGroup=group-qwen3-asr-flash
- Demonstração da experiência on-line:: https://huggingface.co/spaces/Qwen/Qwen3-ASR-Demo
Pessoas para as quais o Qwen3-ASR-Flash é adequado
- Usuários que precisam de transcrição de voz de alta precisãoPor exemplo, jornalistas, gravadores de conferências, pesquisadores, etc., podem converter conteúdo de voz em texto com rapidez e precisão.
- poliglotaPor exemplo, alunos de idiomas estrangeiros, funcionários de empresas multinacionais, participantes de conferências internacionais, etc., podem ajudar a transpor as barreiras do idioma.
- criador de conteúdoPor exemplo, blogueiros de vídeo, apresentadores de podcast, etc., podem gerar legendas e transcrições com eficiência.
- Profissionais da áreaPor exemplo, os profissionais dos setores médico, financeiro e jurídico podem usar recursos de reconhecimento personalizados para identificar com precisão a terminologia.
- Pessoas com necessidades especiais de reconhecimento de falaPor exemplo, pessoas com deficiência auditiva, que podem entender melhor as informações de fala com a ajuda do modelo, e usuários que precisam de reconhecimento de fala em ambientes barulhentos, como o pessoal de atendimento ao cliente e jornalistas no local.
© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Artigos relacionados


Nenhum comentário...