
Qwen2.5-VL lançado: suporta compreensão de vídeos longos, localização visual, saída estruturada, código aberto ajustável

1.Introdução ao modelo
Nos cinco meses desde que o Qwen2-VL foi lançado, vários desenvolvedores criaram novos modelos com base no modelo de linguagem visual Qwen2-VL, fornecendo feedback valioso para a equipe do Qwen. Durante esse tempo, a equipe do Qwen se concentrou em criar modelos de linguagem visual mais úteis. Hoje, a equipe Qwen tem o prazer de apresentar o mais novo membro da família Qwen: Qwen2.5-VL.
Principais aprimoramentos:
- Compreensão visual: o Qwen 2.5-VL não apenas reconhece objetos comuns, como flores, pássaros, peixes e insetos, mas também analisa textos, tabelas, ícones, gráficos e layouts em imagens.
- Agenticidade: o Qwen2.5-VL desempenha diretamente o papel de um agente visual, com a funcionalidade de uma ferramenta de raciocínio e comando dinâmico que pode ser usada em computadores e telefones celulares.
- Compreensão de vídeos longos e captura de eventos: o Qwen 2.5-VL pode compreender vídeos com mais de uma hora de duração e, desta vez, tem a nova capacidade de capturar eventos ao identificar clipes de vídeo relevantes.
- Capacidade de localização visual em diferentes formatos: o Qwen2.5-VL pode localizar com precisão objetos em uma imagem gerando caixas ou pontos delimitadores e pode fornecer saída JSON estável para coordenadas e atributos.
- Geração de saída estruturada: para dados digitalizados, como faturas, formulários, tabelas etc., o Qwen 2.5-VL oferece suporte à saída estruturada de seu conteúdo, o que é benéfico para uso em finanças, negócios e outros campos.
Arquitetura do modelo:
- Resolução dinâmica e treinamento de taxa de quadros para compreensão de vídeo:
A extensão da resolução dinâmica para a dimensão temporal, empregando amostragem dinâmica de FPS, permite que o modelo compreenda o vídeo em várias taxas de amostragem. Da mesma forma, a equipe da Qwen atualizou o mRoPE com ID e alinhamento de tempo absoluto na dimensão temporal, permitindo que o modelo aprenda a ordem e a velocidade temporais e, por fim, obtenha a capacidade de identificar momentos específicos.
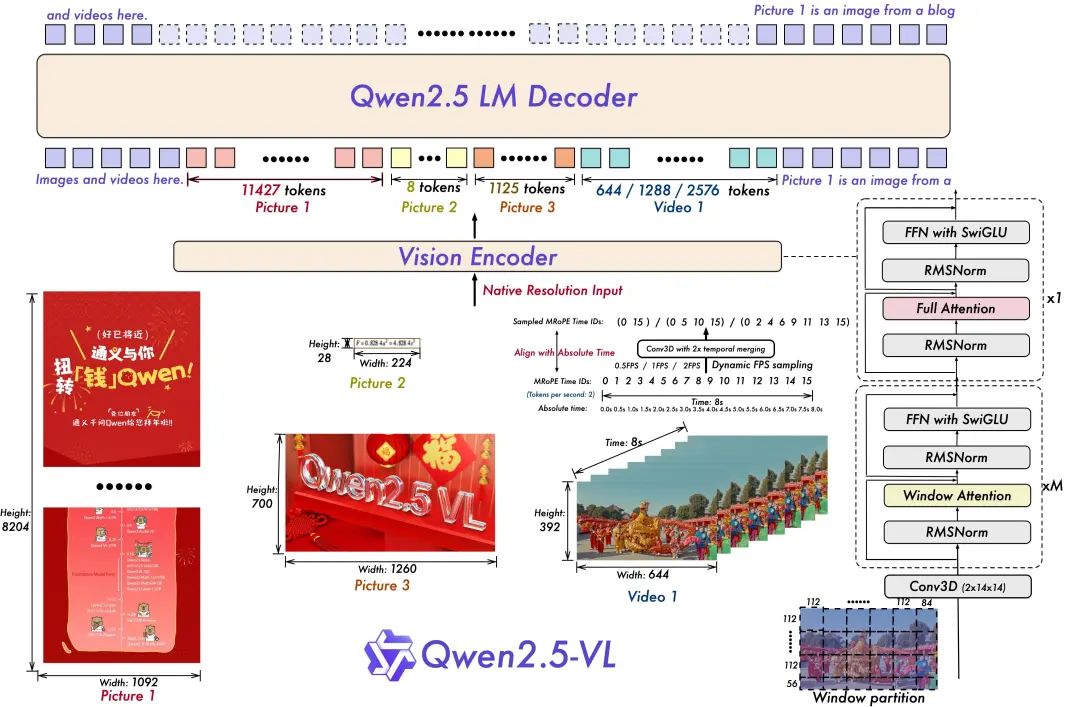
- Codificador visual simplificado e eficiente
A equipe do Qwen melhorou a velocidade de treinamento e inferência introduzindo estrategicamente o mecanismo de atenção em janelas no ViT. A arquitetura do ViT foi otimizada ainda mais com SwiGLU e RMSNorm para alinhá-la com a estrutura do Qwen 2.5 LLM.
Há três modelos nesse código-fonte aberto, com parâmetros de 3 bilhões, 7 bilhões e 72 bilhões. Este repositório contém o 72B ajustado por comando Qwen2.5-VL Modelos.
Conjunto de modelos:
https://www.modelscope.cn/collections/Qwen25-VL-58fbb5d31f1d47
Experiência em modelagem:
https://chat.qwenlm.ai/
Blog de tecnologia:
https://qwenlm.github.io/blog/qwen2.5-vl/
Endereço do código:
https://github.com/QwenLM/Qwen2.5-VL
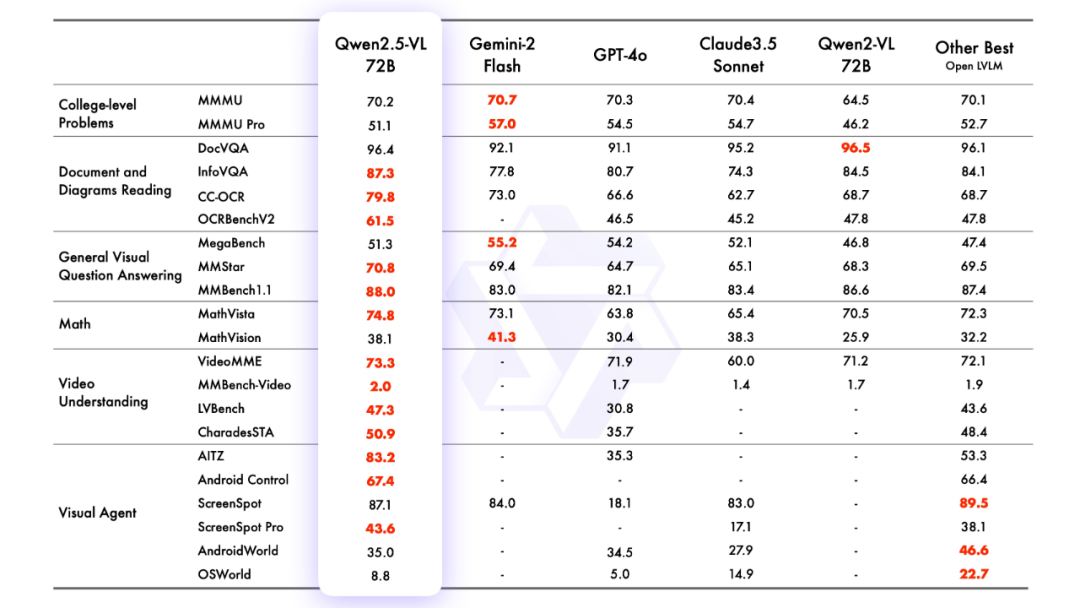
2.efeito de modelagem
avaliação de modelagem
Sr. José María González
3.raciocínio modelado
Raciocínio com transformadores
O código do Qwen2.5-VL está nos transformadores mais recentes, e é recomendável compilar a partir do código-fonte usando o comando:
pip install git+https://github.com/huggingface/transformersUm kit de ferramentas é fornecido para ajudar a facilitar o trabalho com vários tipos de entrada visual, assim como você faria com uma API. Isso inclui base64, URLs e imagens e vídeos intercalados. Ele pode ser instalado usando o seguinte comando:
pip install qwen-vl-utils[decord]==0.0.8Raciocínio sobre o código:
from transformers import Qwen2_5_VLForConditionalGeneration, AutoTokenizer, AutoProcessor
from qwen_vl_utils import process_vision_info
from modelscope import snapshot_download
# Download and load the model
model_dir = snapshot_download("Qwen/Qwen2.5-VL-3B-Instruct")
# Default: Load the model on the available device(s)
model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
model_dir, torch_dtype="auto", device_map="auto"
)
# Optional: Enable flash_attention_2 for better acceleration and memory saving
# model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
# "Qwen/Qwen2.5-VL-3B-Instruct",
# torch_dtype=torch.bfloat16,
# attn_implementation="flash_attention_2",
# device_map="auto",
# )
# Load the default processor
processor = AutoProcessor.from_pretrained(model_dir)
# Optional: Set custom min and max pixels for visual token range
# min_pixels = 256 * 28 * 28
# max_pixels = 1280 * 28 * 28
# processor = AutoProcessor.from_pretrained(
# "Qwen/Qwen2.5-VL-3B-Instruct", min_pixels=min_pixels, max_pixels=max_pixels
# )
# Define input messages
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg",
},
{"type": "text", "text": "Describe this image."},
],
}
]
# Prepare inputs for inference
text = processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt",
)
inputs = inputs.to("cuda")
# Inference: Generate output
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [
out_ids[len(in_ids):] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
# Print the generated output
print(output_text)
Chamado diretamente usando a API-Inference do Magic Hitch
A API-Inference da plataforma Magic Match também é a primeira a oferecer suporte para a série de modelos Qwen2.5-VL. Os usuários do Magic Match podem usá-lo diretamente por meio da chamada de API. A maneira específica de usar a API-Inference pode ser encontrada na página do modelo (por exemplo, https://www.modelscope.cn/models/Qwen/Qwen2.5-VL-72B-Instruct):

Ou consulte a documentação da API-Inference:
https://www.modelscope.cn/docs/model-service/API-Inference/intro
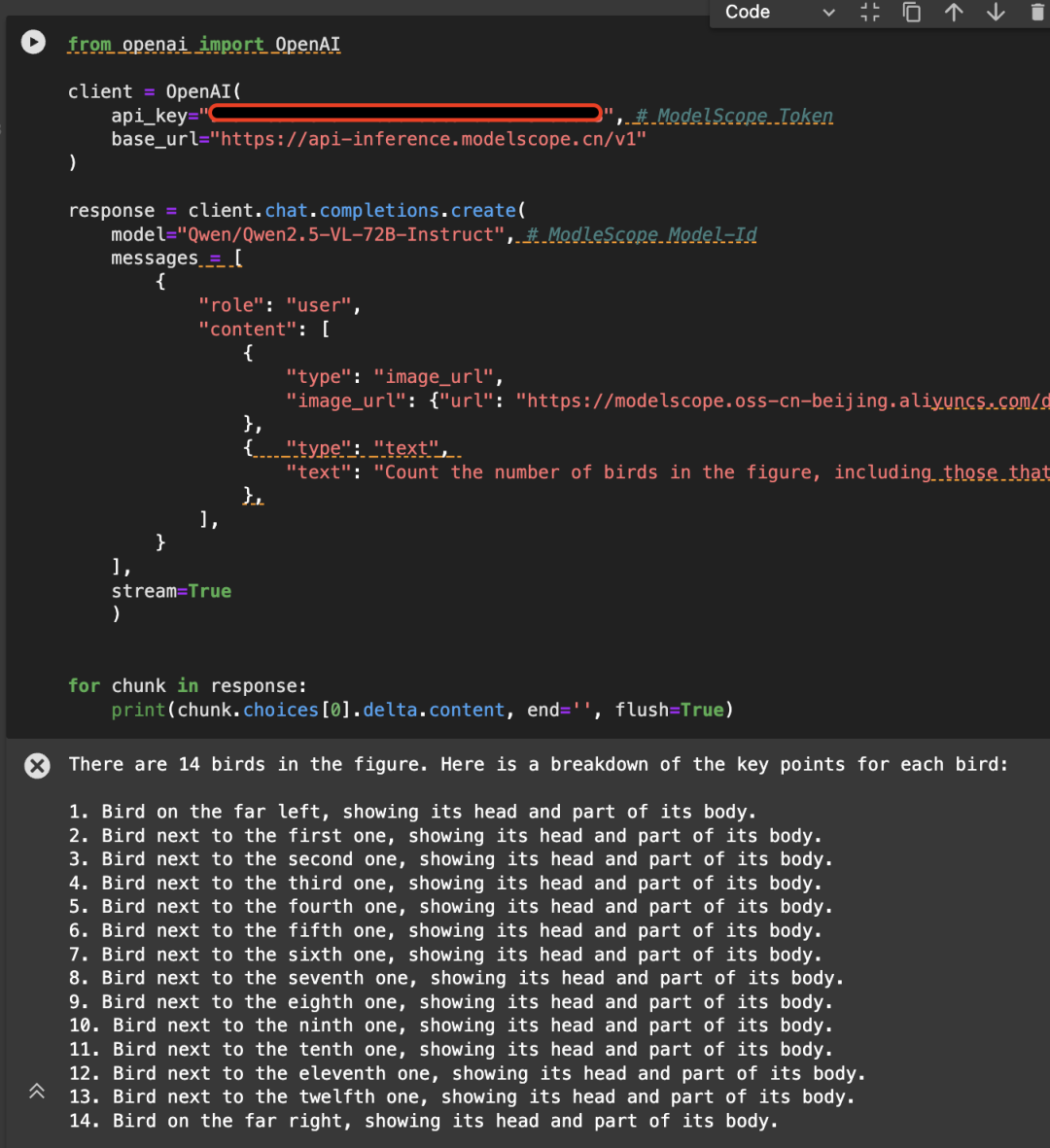
Aqui está um exemplo da imagem a seguir, chamando a API usando o modelo Qwen/Qwen2.5-VL-72B-Instruct:

from openai import OpenAI
# Initialize the OpenAI client
client = OpenAI(
api_key="<MODELSCOPE_SDK_TOKEN>", # ModelScope Token
base_url="https://api-inference.modelscope.cn/v1"
)
# Create a chat completion request
response = client.chat.completions.create(
model="Qwen/Qwen2.5-VL-72B-Instruct", # ModelScope Model-Id
messages=[
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": "https://modelscope.oss-cn-beijing.aliyuncs.com/demo/images/bird-vl.jpg"
}
},
{
"type": "text",
"text": (
"Count the number of birds in the figure, including those that "
"are only showing their heads. To ensure accuracy, first detect "
"their key points, then give the total number."
)
},
],
}
],
stream=True
)
# Stream the response
for chunk in response:
print(chunk.choices[0].delta.content, end='', flush=True)
4. ajuste fino do modelo
Apresentamos o uso do ms-swift no ajuste fino do Qwen/Qwen2.5-VL-7B-Instruct. O ms-swift é a comunidade de passeio mágico oficialmente fornecida pelo modelo grande e pela estrutura de implantação de ajuste fino de modelo grande multimodal:
https://github.com/modelscope/ms-swift
Aqui, mostraremos demonstrações de ajuste fino executáveis e forneceremos o formato do conjunto de dados autodefinido.
Certifique-se de que seu ambiente esteja pronto antes de iniciar o ajuste fino.
git clone https://github.com/modelscope/ms-swift.git cd ms-swift pip install -e .
O script de ajuste fino de OCR de imagem é o seguinte:
MAX_PIXELS=1003520 \
CUDA_VISIBLE_DEVICES=0 \
swift sft \
--model Qwen/Qwen2.5-VL-7B-Instruct \
--dataset AI-ModelScope/LaTeX_OCR:human_handwrite#20000 \
--train_type lora \
--torch_dtype bfloat16 \
--num_train_epochs 1 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--learning_rate 1e-4 \
--lora_rank 8 \
--lora_alpha 32 \
--target_modules all-linear \
--freeze_vit true \
--gradient_accumulation_steps 16 \
--eval_steps 50 \
--save_steps 50 \
--save_total_limit 5 \
--logging_steps 5 \
--max_length 2048 \
--output_dir output \
--warmup_ratio 0.05 \
--dataloader_num_workers 4
Recursos de memória de vídeo de treinamento:

O script de ajuste fino do vídeo está abaixo:
# VIDEO_MAX_PIXELS等参数含义可以查看:
# https://swift.readthedocs.io/zh-cn/latest/Instruction/%E5%91%BD%E4%BB%A4%E8%A1%8C%E5%8F%82%E6%95%B0.html#id18
nproc_per_node=2
CUDA_VISIBLE_DEVICES=0,1 \
NPROC_PER_NODE=$nproc_per_node \
VIDEO_MAX_PIXELS=100352 \
FPS_MAX_FRAMES=24 \
swift sft \
--model Qwen/Qwen2.5-VL-7B-Instruct \
--dataset swift/VideoChatGPT:all \
--train_type lora \
--torch_dtype bfloat16 \
--num_train_epochs 1 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--learning_rate 1e-4 \
--lora_rank 8 \
--lora_alpha 32 \
--target_modules all-linear \
--freeze_vit true \
--gradient_accumulation_steps $(expr 16 / $nproc_per_node) \
--eval_steps 50 \
--save_steps 50 \
--save_total_limit 5 \
--logging_steps 5 \
--max_length 2048 \
--output_dir output \
--warmup_ratio 0.05 \
--dataloader_num_workers 4 \
--deepspeed zero2
Recursos de memória de vídeo de treinamento:

O formato do conjunto de dados personalizado é o seguinte (o campo do sistema é opcional), basta especificar `--dataset `:
{"messages": [{"role": "user", "content": "浙江的省会在哪?"}, {"role": "assistant", "content": "浙江的省会在杭州。"}]}
{"messages": [{"role": "user", "content": "<image><image>两张图片有什么区别"}, {"role": "assistant", "content": "前一张是小猫,后一张是小狗"}], "images": ["/xxx/x.jpg", "xxx/x.png"]}
{"messages": [{"role": "system", "content": "你是个有用无害的助手"}, {"role": "user", "content": "<video>视频中是什么"}, {"role": "assistant", "content": "视频中是一只小狗在草地上奔跑"}], "videos": ["/xxx/x.mp4"]}
O script de ajuste fino da tarefa de aterramento é o seguinte:
CUDA_VISIBLE_DEVICES=0 \
MAX_PIXELS=1003520 \
swift sft \
--model Qwen/Qwen2.5-VL-7B-Instruct \
--dataset 'AI-ModelScope/coco#20000' \
--train_type lora \
--torch_dtype bfloat16 \
--num_train_epochs 1 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--learning_rate 1e-4 \
--lora_rank 8 \
--lora_alpha 32 \
--target_modules all-linear \
--freeze_vit true \
--gradient_accumulation_steps 16 \
--eval_steps 100 \
--save_steps 100 \
--save_total_limit 2 \
--logging_steps 5 \
--max_length 2048 \
--output_dir output \
--warmup_ratio 0.05 \
--dataloader_num_workers 4 \
--dataset_num_proc 4
Recursos de memória de vídeo de treinamento:

O formato do conjunto de dados personalizado da tarefa de aterramento é o seguinte:
{"messages": [{"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": "<image>描述图像"}, {"role": "assistant", "content": "<ref-object><bbox>和<ref-object><bbox>正在沙滩上玩耍"}], "images": ["/xxx/x.jpg"], "objects": {"ref": ["一只狗", "一个女人"], "bbox": [[331.5, 761.4, 853.5, 1594.8], [676.5, 685.8, 1099.5, 1427.4]]}}
{"messages": [{"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": "<image>找到图像中的<ref-object>"}, {"role": "assistant", "content": "<bbox><bbox>"}], "images": ["/xxx/x.jpg"], "objects": {"ref": ["羊"], "bbox": [[90.9, 160.8, 135, 212.8], [360.9, 480.8, 495, 532.8]]}}
Após a conclusão do treinamento, a inferência é realizada no conjunto de validação do treinamento usando o seguinte comando.
Aqui, `--adapters` precisa ser substituído pela última pasta de ponto de verificação gerada pelo treinamento. Como a pasta adapters contém os arquivos de parâmetros para o treinamento, não há necessidade de especificar `--model` adicionalmente:
CUDA_VISIBLE_DEVICES=0swift infer--adapters output/vx-xxx/checkpoint-xxx--stream false--max_batch_size 1--load_data_args true--max_new_tokens 2048
Empurre o modelo para o ModelScope:
CUDA_VISIBLE_DEVICES=0swift export--adapters output/vx-xxx/checkpoint-xxx--push_to_hub true--hub_model_id '<your-model-id>'--hub_token '<your-sdk-token>'
© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Artigos relacionados




Nenhum comentário...