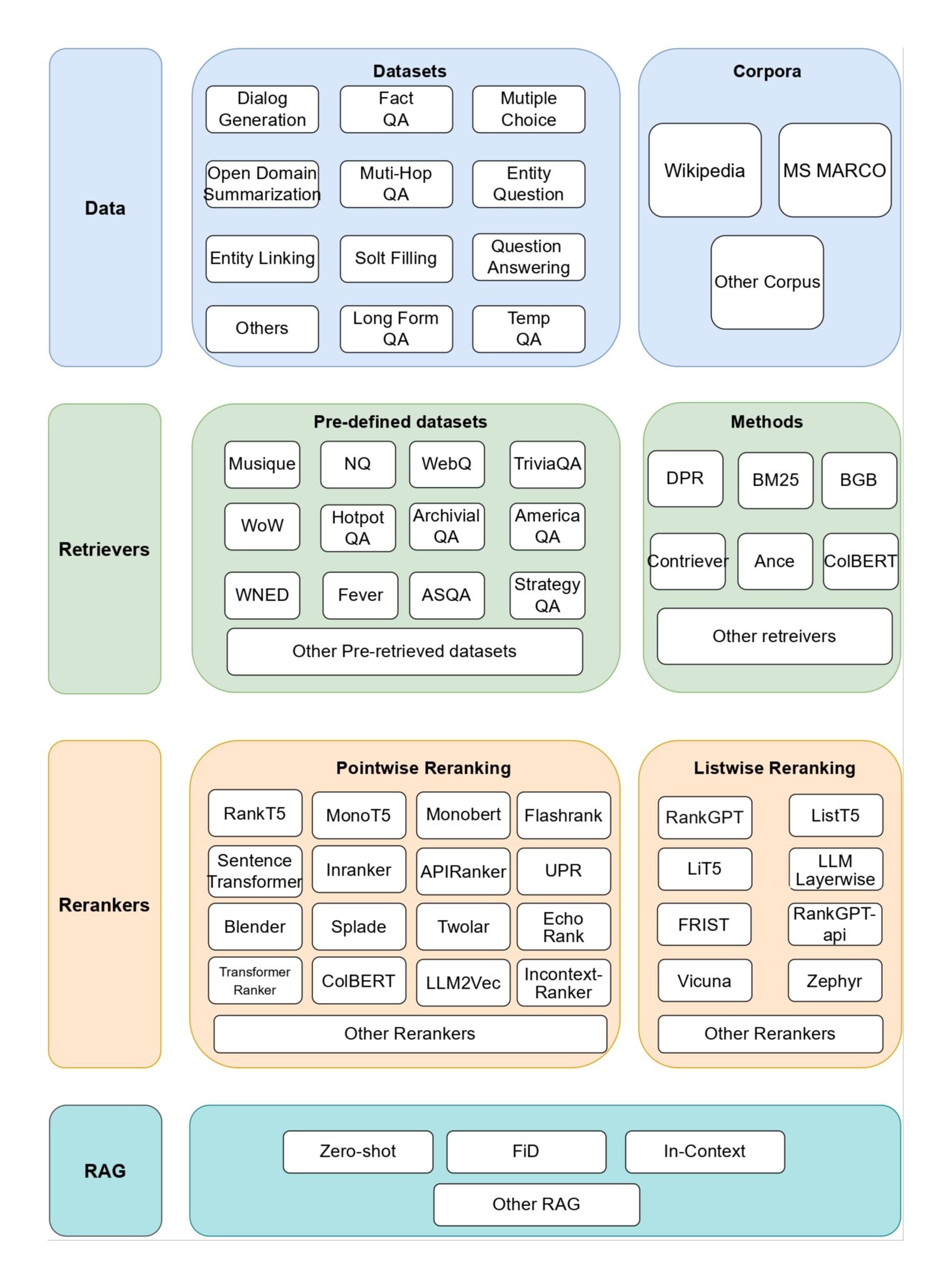
Estratégia de recuperação RAG simples e eficaz: pesquisa e rearranjo híbrido esparso + denso e uso de "cache de dicas" para gerar um contexto geral relevante para o documento para blocos de texto.

Para que um modelo de IA seja útil em um cenário específico, ele geralmente precisa ter acesso ao conhecimento prévio. Por exemplo, um chatbot de suporte ao cliente precisa entender o negócio específico que atende, enquanto um bot de análise jurídica precisa ter acesso a um grande número de casos anteriores.
Os desenvolvedores geralmente aumentam o conhecimento dos modelos de IA usando o Retrieval-Augmented Generation (RAG), um método de recuperar informações relevantes de uma base de conhecimento e anexá-las às solicitações do usuário para melhorar significativamente a capacidade de resposta do modelo. O problema é que os modelos tradicionais de RAG Os programas perdem o contexto ao codificar as informações, o que muitas vezes faz com que o sistema não consiga recuperar informações relevantes da base de conhecimento.
Neste artigo, descrevemos uma abordagem que pode melhorar significativamente a etapa de recuperação no RAG. Essa abordagem é chamada de Recuperação Contextual e usa duas subtécnicas: Contextual Embeddings e Contextual BM25. Essa abordagem reduz o número de falhas de recuperação em 491 TP3T e em 671 TP3T quando combinada com o reranking. Esses aprimoramentos aumentam consideravelmente a precisão da recuperação, o que se traduz diretamente em melhor desempenho em tarefas posteriores.
A essência é uma mistura de resultados semanticamente semelhantes e de frequência de palavras semelhantes, às vezes os resultados semânticos não representam a verdadeira intenção. Leia o link fornecido no final do texto, já faz 2 anos que essa estratégia "antiga" foi lançada e o método ainda é raramente usado, seja por cair na estratégia RAG extremamente complexa, seja por usar apenas embedding + rearranging.
Este artigo é um pequeno aprimoramento da antiga estratégia de usar "dicas de cache" para gerar contexto para blocos de texto que se encaixam no contexto geral do documento a baixo custo. É uma pequena mudança, mas os resultados são impressionantes!
Você pode fazer isso Nosso código de amostra fazer uso de Claude Implante sua própria solução de recuperação contextual.
Uma observação sobre o uso simples de pontas mais longas
Às vezes, a solução mais simples também é a melhor. Se a sua base de conhecimento tiver menos de 200.000 tokens (cerca de 500 páginas de material), você poderá incluir toda a base de conhecimento diretamente nos prompts fornecidos ao modelo, sem a necessidade de um RAG ou método semelhante.
Há algumas semanas, lançamos para o Claude Cue CacheAlém da nova API, aceleramos e reduzimos significativamente o custo dessa abordagem. Os desenvolvedores agora podem armazenar em cache as dicas usadas com frequência entre as chamadas de API, reduzindo a latência em mais de duas vezes e o custo em até 90% (você pode ver como isso funciona lendo nosso Código de amostra do cache de dicas (Entender como ele funciona).
No entanto, à medida que sua base de conhecimento cresce, você precisará de soluções mais escaláveis, e é aí que entra a pesquisa contextual. Com esse histórico fora do caminho, vamos ao que interessa.
Fundamentos do RAG: expansão para uma base de conhecimento maior
O RAG é a solução típica para grandes bases de conhecimento que não cabem em uma janela de contexto:
- Decomposição da base de conhecimento (documento "corpus") em fragmentos de texto menores, geralmente não mais do que algumas centenas de tokens; (blocos de texto excessivamente longos expressam mais significado, ou seja, são muito ricos semanticamente)
- Os segmentos são convertidos em embeddings de vetores que codificam o significado usando um modelo de embedding;
- Armazene essas incorporações em um banco de dados vetorial para pesquisa por similaridade semântica.
No tempo de execução, quando o usuário insere uma consulta no modelo, o banco de dados vetorial encontra o fragmento mais relevante com base na similaridade semântica da consulta. O fragmento mais relevante é então adicionado ao prompt enviado ao modelo generativo (respondendo à pergunta como o contexto da referência maior do modelo).
Embora os modelos de incorporação sejam bons para capturar relações semânticas, eles podem perder correspondências exatas críticas. Felizmente, uma técnica mais antiga pode ajudar nesses casos. O BM25 é uma função de classificação que encontra correspondências exatas de palavras ou frases por meio de correspondência lexical. Ela é particularmente eficaz para consultas que contêm identificadores exclusivos ou termos técnicos.
BM25 Aprimorado com base no conceito de TF-IDF (Word Frequency-Inverse Document Frequency), que mede a importância de uma palavra em uma coleção de documentos. O BM25 evita que palavras comuns dominem os resultados, levando em conta o tamanho do documento e aplicando uma função de saturação à frequência de palavras.
Veja como o BM25 funciona quando a incorporação semântica falha: suponha que um usuário consulte o banco de dados de suporte técnico para obter o "código de erro TS-999". (O modelo de incorporação (vetorial) pode encontrar conteúdo genérico sobre o código de erro, mas pode não encontrar a correspondência exata "TS-999". Em vez disso, o BM25 procura essa sequência de texto específica para identificar o documento relevante.
Ao combinar as técnicas de incorporação e BM25, o programa RAG pode recuperar os fragmentos mais relevantes com mais precisão, como segue:
- A base de conhecimento (o "corpus" do documento) é dividida em partes menores de texto, geralmente não mais do que algumas centenas de tokens;
- Crie codificações TF-IDF e incorporação semântica (vetorial) para esses segmentos;
- Use o BM25 para encontrar o melhor fragmento com base em uma correspondência exata;
- Use a incorporação (vetorial) para encontrar os segmentos com a maior similaridade semântica;
- Os resultados das etapas (3) e (4) são mesclados e reduzidos usando uma técnica de fusão de classificação; por exemplo, o modelo de reordenação dedicado Rerank 3.5.
- Adicione os primeiros segmentos K ao prompt para gerar uma resposta.
Ao combinar o BM25 e os modelos de incorporação, os sistemas RAG tradicionais conseguem atingir um equilíbrio entre a correspondência precisa de termos e uma compreensão semântica mais ampla, fornecendo resultados mais abrangentes e precisos.

Um sistema RAG (Retrieval Augmentation Generation) padrão que combina incorporação e Best Match 25 (BM25) para recuperar informações. O TF-IDF (Word Frequency-Inverse Document Frequency) mede a importância das palavras e forma a base do BM25.
Essa abordagem permite que você dimensione uma base de conhecimento muito maior do que a que pode ser acomodada por um único prompt, a um baixo custo. No entanto, esses sistemas RAG tradicionais têm uma limitação significativa: eles geralmente quebram o contexto.
Falando aqui com base no esquema de pesquisa para criar um design razoável, ainda não falamos do bloco de texto truncado para exibição, o bloco de texto truncado deve expressar o mesmo conteúdo, nunca deve ser truncado, mas o esquema RAG acimaInevitavelmente, o contexto é truncado. Esse é um problema simples e complexo. Vamos ao ponto principal deste artigo.
Dificuldades contextuais no RAG tradicional
No RAG tradicional, os documentos geralmente são divididos em partes menores para uma recuperação eficiente. Essa abordagem é adequada para muitos cenários de aplicativos, mas pode causar problemas quando os blocos individuais não têm contexto suficiente.
Por exemplo, suponha que você tenha algumas informações financeiras incorporadas em sua base de conhecimento (por exemplo, um relatório da SEC dos EUA) e receba a seguinte pergunta:"Qual é o crescimento da receita da ACME Corporation no segundo trimestre de 2023?"
Um bloco relacionado pode conter o seguinte texto:"As receitas da empresa aumentaram 3% em relação ao trimestre anterior." No entanto, o bloco em si não menciona explicitamente empresas específicas ou períodos de tempo relevantes, o que dificulta a obtenção das informações corretas ou seu uso eficaz.
Apresentando a pesquisa contextual
A recuperação contextual é feita adicionando um bloco específico a cada bloco antes de incorporar oContexto interpretativo("Context Embedding") e a criação de um índice BM25 ("Context BM25") resolvem esse problema.
Vamos voltar ao exemplo da coleta de relatórios da SEC. Aqui está um exemplo de como um bloco é convertido:
original_chunk = "该公司的收入比上一季度增长了 3%。"
contextualized_chunk = "该块来自一份关于 ACME 公司 2023 年第二季度表现的 SEC 报告;上一季度的收入为 3.14 亿美元。该公司的收入比上一季度增长了 3%。"
Vale a pena observar que várias outras maneiras de usar o contexto para melhorar a recuperação foram sugeridas no passado. Outras sugestões incluem:Adição de um resumo genérico de documento a um bloco(Fizemos experimentos e descobrimos que o ganho é muito limitado),Incorporação hipotética de documentos responder cantando Indexação baseada em abstratos(Nós o avaliamos e descobrimos que o desempenho é baixo). Esses métodos são diferentes do proposto neste documento.
Muitos dos métodos para melhorar a qualidade do contexto demonstraram experimentalmente ter um ganho limitado, e até mesmo os melhores métodos relativos mencionados acima permanecem questionáveis.O fato de adicionar contexto explicativo a esse processo de conversão resulta em uma perda de mais ou menos informações.
Mesmo que um parágrafo completo seja dividido em blocos de texto e vários níveis de cabeçalhos sejam adicionados ao conteúdo do parágrafo completo, esse parágrafo isolado e fora de contexto pode não transmitir o conhecimento com precisão, como os exemplos acima já sonharam.
Esse método resolve de forma eficaz o problema da falta de significado isolada causada pela falta de fundo contextual quando o conteúdo de um bloco de texto existe sozinho.
Ativação da pesquisa contextual
É claro que anotar manualmente o contexto de milhares ou até milhões de blocos em uma base de conhecimento é muito trabalhoso. Para possibilitar a recuperação contextual, recorremos ao Claude e escrevemos uma dica que instrui o modelo a fornecer um contexto conciso e específico do bloco com base no contexto de todo o documento. Veja como usamos as dicas do Claude 3 Haiku para gerar contexto para cada bloco:
<document>
{{WHOLE_DOCUMENT}}
</document>
这是我们希望置于整个文档中的块
<chunk>
{{CHUNK_CONTENT}}
</chunk>
请提供一个简短且简明的上下文,以便将该块置于整个文档的上下文中,从而改进块的搜索检索。仅回答简洁的上下文,不要包含其他内容。
O texto de contexto gerado normalmente tem de 50 a 100 tokens e é adicionado ao bloco antes da incorporação e da criação do índice BM25.
Esse cue run precisa fazer referência ao documento completo correspondente ao bloco de texto (que não deve ter mais de 500 páginas, certo?) como um cache de dicas, a fim de gerar com precisão o contexto associado ao bloco de texto em relação ao documento completo.
Isso se baseia nos recursos de armazenamento em cache do Claude, o documento completo como um prompt para armazenar em cache a entrada não precisa ser pago todas as vezes, o armazenamento em cache, basta pagar uma vez, portanto, o programa para atingir os pré-requisitos éO modelo grande permite o armazenamento em cache de documentos longosModelos como o DeepSeek têm recursos semelhantes.
O processo de pré-processamento na prática é o seguinte:

A pesquisa contextual é uma técnica de pré-processamento que melhora a precisão da pesquisa.
Se você estiver interessado em usar a pesquisa contextual, consulte nosso manual de operação Início.
Reduzindo o custo da recuperação contextual com o cache de dicas
A recuperação por meio de contextos Claude pode ser obtida a um baixo custo graças ao recurso especial de cache de dicas que mencionamos. Com o cache de dicas, você não precisa passar documentos de referência para cada bloco. Basta carregar o documento no cache uma vez e, em seguida, fazer referência ao conteúdo armazenado em cache anteriormente. Considerando 800 tokens por bloco, 8k tokens por documento, 50 tokens por instrução de contexto e 100 tokens por contexto de bloco, oO custo único da geração de um bloco contextualizado é de $1,02 por milhão de tokens de documento.
metodologia
Realizamos experimentos em vários domínios de conhecimento (base de código, romances, artigos do ArXiv, artigos científicos), modelos de incorporação, estratégias de recuperação e métricas de avaliação. Realizamos nossos experimentos em Apêndice II Alguns exemplos das perguntas e respostas que usamos para cada domínio estão listados a seguir.
A figura abaixo mostra o desempenho médio em todos os domínios de conhecimento ao usar a configuração de incorporação com melhor desempenho (Gemini Text 004) e recuperar os primeiros 20 trechos. Usamos 1 menos recall@20 como métrica de avaliação, que mede a porcentagem de documentos relevantes que não foram recuperados nos primeiros 20 snippets. Os resultados completos podem ser visualizados no Apêndice - A contextualização melhora o desempenho em todas as combinações de fontes incorporadas que avaliamos.
aprimoramento do desempenho
Nossos experimentos mostram que:
- A incorporação contextual reduziu a taxa de falha de pesquisa dos primeiros 20 fragmentos em 35%(5,7% → 3,7%).
- A combinação de incorporação contextual e BM25 contextual reduziu a taxa de falha de pesquisa dos primeiros 20 fragmentos em 49%(5,7% → 2,9%).

A combinação de incorporação contextual e BM25 contextual reduziu a taxa de falha de recuperação dos primeiros 20 fragmentos em 49%.
Considerações sobre a implementação
Os seguintes pontos devem ser levados em conta ao implementar a pesquisa contextual:
- Limites de fragmentos: Considere como o documento será dividido em fragmentos. A escolha do tamanho do fragmento, os limites e a sobreposição podem afetar o desempenho da recuperação ^1^.
- Modelos de incorporação: Embora a recuperação contextual melhore o desempenho de todos os modelos de incorporação que testamos, alguns modelos podem se beneficiar mais. Descobrimos que Gêmeos responder cantando Viagem A incorporação é particularmente eficaz.
- Dicas contextuais personalizadas: Embora os prompts genéricos que fornecemos funcionem bem, é possível obter melhores resultados personalizando os prompts para domínios ou casos de uso específicos (por exemplo, incluindo um glossário de termos-chave que podem ser definidos em outros documentos da base de conhecimento).
- Número de clipes: Adicionar mais fragmentos à janela de contexto pode aumentar as chances de incluir informações relevantes. No entanto, o excesso de informações pode distrair o modelo, portanto, o número precisa ser controlado. Experimentamos 5, 10 e 20 fragmentos e descobrimos que o uso de 20 fragmentos teve o melhor desempenho com essas opções (consulte o Apêndice para obter detalhes), mas vale a pena experimentar dependendo do seu caso de uso.
Sempre faça avaliações: A geração de respostas pode ser aprimorada com a transmissão de trechos contextualizados e a distinção entre contexto e trechos.
Uso da reordenação para melhorar ainda mais o desempenho
Na última etapa, podemos combinar a recuperação contextual com outra técnica para melhorar ainda mais o desempenho. No RAG (Retrieval-Augmented Generation) tradicional, o sistema de IA pesquisa sua base de conhecimento em busca de informações potencialmente relevantes. Para grandes bases de conhecimento, a pesquisa inicial geralmente retorna um grande número de fragmentos - às vezes até centenas - de relevância e importância variadas.
A reordenação é uma técnica comum de filtragem que garante que somente as partes mais relevantes sejam passadas para o modelo. A reordenação fornece uma resposta melhor e reduz o custo e a latência, pois o modelo processa menos informações. As principais etapas são as seguintes:
- Uma pesquisa inicial foi realizada para obter os segmentos relevantes mais prováveis (usamos os primeiros 150);
- Passe os primeiros N segmentos e a consulta do usuário para o modelo de reordenação;
- Um modelo de reordenação foi usado para pontuar cada clipe com base na relevância e na importância da pista e, em seguida, os K clipes principais foram selecionados (usamos os 20 principais);
- Os primeiros K segmentos são passados como contexto para o modelo para gerar o resultado final.
 A combinação de pesquisa contextual e reordenação maximiza a precisão da pesquisa.
A combinação de pesquisa contextual e reordenação maximiza a precisão da pesquisa.
aprimoramento do desempenho
Há vários modelos de reordenamento disponíveis no mercado. Usamos o Reordenador de coesões Executou o teste. voyage Também é fornecido um reordenadormas não tivemos tempo de testá-lo. Nossos experimentos mostram que adicionar uma etapa de reordenação pode otimizar ainda mais a recuperação em vários domínios.
Especificamente, descobrimos que a reordenação das incorporações contextuais e do BM25 contextual reduz a taxa de falha de recuperação dos 20 principais fragmentos em 671 TP3T (5,71 TP3T → 1,91 TP3T).
 A reordenação das incorporações contextuais e do BM25 contextual reduziu a taxa de falha de recuperação dos primeiros 20 fragmentos em 67%.
A reordenação das incorporações contextuais e do BM25 contextual reduziu a taxa de falha de recuperação dos primeiros 20 fragmentos em 67%.
Considerações sobre custos e atrasos
Uma consideração importante para a reordenação é o impacto sobre a latência e o custo, especialmente ao reordenar um grande número de fragmentos. Como a reordenação adiciona uma etapa extra no tempo de execução, ela inevitavelmente adiciona alguma latência, mesmo que o reordenador esteja pontuando todos os fragmentos lado a lado. Há uma compensação entre reordenar mais fragmentos para obter maior desempenho e reordenar menos fragmentos para reduzir a latência e o custo. Recomendamos experimentar diferentes configurações para o seu caso de uso específico para encontrar o equilíbrio ideal.
chegar a um veredicto
Executamos vários testes comparando diferentes combinações de todas as técnicas acima (modelos de incorporação, uso de BM25, uso de pesquisa contextual, uso de reordenadores e número dos K principais resultados de recuperação) e realizamos experimentos em vários tipos de conjuntos de dados. A seguir, um resumo de nossas descobertas:
- A incorporação + BM25 é melhor do que usar apenas a incorporação;
- Viagem e Gêmeos é o modelo de incorporação que funcionou melhor em nossos testes;
- Passar os primeiros 20 segmentos para o modelo é mais eficaz do que passar apenas os primeiros 10 ou 5;
- A adição de contexto aos segmentos melhora muito a precisão da recuperação;
- Reordenar é melhor do que não reordenar;
- Todas essas vantagens podem ser acumuladas: Para maximizar as melhorias de desempenho, podemos usar uma combinação de incorporação contextual (do Voyage ou Gemini), BM25 contextual, reordenação de etapas e adição de 20 trechos ao prompt.
Incentivamos todos os desenvolvedores que usam a base de conhecimento a usar o Nosso Manual de Práticas Faça experiências com esses métodos para desbloquear novos níveis de desempenho.
Apêndice I
Abaixo está um detalhamento dos resultados do Retrievals @ 20 em conjuntos de dados, provedores incorporados, BM25 usado em conjunto com a incorporação, uso de recuperação contextual e uso de reordenação.
Para obter um detalhamento dos Retrievals @ 10 e @ 5 e exemplos de perguntas e respostas para cada conjunto de dados, consulte Apêndice II.
 1 menos recall @ 20 para o conjunto de dados e resultados do provedor incorporado.
1 menos recall @ 20 para o conjunto de dados e resultados do provedor incorporado.
notas de rodapé
© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Artigos relacionados


Nenhum comentário...