
Dicas avançadas do Prompt: controle preciso da saída do LLM e definição da lógica de execução com pseudocódigo
Como todos sabemos, quando precisamos permitir que um modelo de linguagem grande execute uma tarefa, precisamos inserir um Prompt para orientar sua execução, que é descrita usando linguagem natural. Para tarefas simples, a linguagem natural pode descrevê-las claramente, como: "Por favor, traduza o seguinte para o chinês simplificado:", "Por favor, gere um resumo do seguinte:" e assim por diante.
Entretanto, quando nos deparamos com algumas tarefas complexas, como exigir que o modelo gere um formato JSON específico, ou quando a tarefa tem várias ramificações, cada ramificação precisa executar várias subtarefas e as subtarefas estão inter-relacionadas entre si, as descrições em linguagem natural não são suficientes.
tópico de discussão
Aqui estão duas perguntas instigantes para você experimentar antes de continuar lendo:
- Há várias sentenças longas, cada uma das quais precisa ser dividida em sentenças mais curtas de no máximo 80 caracteres e, em seguida, ser gerada em um formato JSON que descreva claramente a correspondência entre as sentenças longas e curtas.
Por exemplo:
[
{
"long": "This is a long sentence that needs to be split into shorter sentences.",
"short": [
"This is a long sentence",
"that needs to be split",
"into shorter sentences."
]
},
{
"long": "Another long sentence that should be split into shorter sentences.",
"short": [
"Another long sentence",
"that should be split",
"into shorter sentences."
]
}
]
- Um texto original legendado com apenas informações de diálogo, do qual agora você precisa extrair capítulos, falantes e, em seguida, listar o diálogo por capítulo e parágrafo. No caso de vários falantes, cada diálogo precisa ser precedido pelo falante, não se o mesmo falante estiver falando consecutivamente. (Na verdade, esse é um GPT que eu mesmo uso para organizar roteiros de vídeo Agrupamento de scripts de vídeo GPT)
Exemplo de entrada:
所以我要引用一下埃隆·马斯克的话,希望你不要介意。 我向你道歉。 但他并不认同这是一个保障隐私和安全的模型。 他将这种集成称为"令人毛骨悚然的间谍软件"。你对此有什么回应? 不在意? 那是他的观点。 显然,我不这么认为。 我们也不这么认为。 Mira,感谢你能和我们在一起。 我知道你可能稍微有点忙。 我有许多问题想向 Mira 提问,但我们只有 20 分钟。 所以我想先设定一下大家的期望。 我们会专注于一些主题, 包括一些近期的新闻和 Mira 作为首席技术官所负责的一些领域。 希望我们能深入探讨其中的一些话题。 我想我第一个问题是, 考虑到你现在极其忙碌, 以及新闻的攻击, 有些好有些坏, 你大约六年前加入了这个公司。 那时,它是一个截然不同的组织。 你相对低调,不太为人知晓。 你是否怀念那些能够全神贯注工作的日子? 我想说,我们依旧全神贯注在工作中。 只不过工作的内容已经发展变化了,它不仅仅关乎研究。 也是因为,你知道,研究已经得到了很大的进展。 这也是关于我们如何以一种有益且安全的方式将这种技术引入到世界中所以,使命依然如一, 我们在研究上也已经取得了很多进展,工作领域也在不断扩大。 公众对此的关注度也很高, 这对于我们这些正在研究技术和开发产品的人来说可能会感到有些不同寻常。 但你要知道, 鉴于我们所做的事情的重要性,这种关注是非常必要的, 而且这是积极的。
Saída de amostra:
### 引言 **主持人**: 所以我要引用一下埃隆·马斯克的话,希望你不要介意。我向你道歉,但他并不认同这是一个保障隐私和安全的模型。他将这种集成称为"令人毛骨悚然的间谍软件"。你对此有什么回应? **Mira**: 那是他的观点。显然,我不这么认为。我们也不这么认为。 ### 欢迎与介绍 **主持人**: Mira,感谢你能和我们在一起。我知道你可能稍微有点忙。我有许多问题想向你提问,但我们只有 20 分钟。所以我想先设定一下大家的期望。我们会专注于一些主题,包括一些近期的新闻和你作为首席技术官所负责的一些领域。希望我们能深入探讨其中的一些话题。 ### 职业生涯回顾 **主持人**: 我想我第一个问题是,考虑到你现在极其忙碌,以及新闻的攻击,有些好有些坏,你大约六年前加入了这个公司。那时,它是一个截然不同的组织。你相对低调,不太为人知晓。你是否怀念那些能够全神贯注工作的日子? **Mira**: 我想说,我们依旧全神贯注在工作中。只不过工作的内容已经发展变化了,它不仅仅关乎研究。也是因为,研究已经得到了很大的进展。这也是关于我们如何以一种有益且安全的方式将这种技术引入到世界中。所以,使命依然如一,我们在研究上也已经取得了很多进展,工作领域也在不断扩大。公众对此的关注度也很高,这对于我们这些正在研究技术和开发产品的人来说可能会感到有些不同寻常。但你要知道,鉴于我们所做的事情的重要性,这种关注是非常必要的,而且这是积极的。
A essência do Prompt
Talvez você tenha lido muitos artigos on-line sobre como escrever técnicas de Prompt e memorizado muitos modelos de Prompt, mas qual é a essência do Prompt? Por que precisamos do Prompt?
O Prompt é essencialmente uma instrução de controle para o LLM, descrita em linguagem natural, que permite que o LLM entenda nossos requisitos e transforme as entradas em nossas saídas desejadas, conforme necessário.
Por exemplo, a técnica de poucos disparos comumente usada é permitir que o LLM entenda nossos requisitos por meio de exemplos e, em seguida, consulte os exemplos para produzir os resultados desejados. Por exemplo, a CoT (Chain of Thought, cadeia de raciocínio) consiste em decompor artificialmente a tarefa e limitar o processo de execução, de modo que o LLM possa seguir o processo e as etapas especificadas por nós, sem ser muito difuso ou pular as etapas principais e, assim, obter melhores resultados.
É como quando vamos à escola, quando o professor está falando sobre teoremas matemáticos, ele precisa nos dar exemplos para que possamos entender o significado dos teoremas por meio dos exemplos; quando estamos fazendo experimentos, precisamos saber as etapas dos experimentos e, mesmo que não entendamos os princípios dos experimentos, mas possamos executá-los de acordo com as etapas, ainda assim obteremos mais ou menos os mesmos resultados.
Por que, às vezes, os resultados do Prompt não são tão bons?
Isso ocorre porque o LLM não consegue entender com precisão nossos requisitos, que são limitados, por um lado, pela capacidade do LLM de entender e seguir instruções e, por outro, pela clareza e precisão da descrição do Prompt.
Como controlar com precisão a saída do LLM e definir sua lógica de execução com a ajuda de pseudocódigo
Como o Prompt é essencialmente uma instrução de controle para o LLM, podemos escrever o Prompt sem nos limitarmos às descrições tradicionais de linguagem natural, mas também podemos usar pseudocódigo para controlar com precisão a saída do LLM e definir sua lógica de execução.
O que é pseudocódigo?
O pseudocódigo é um método de descrição formal para descrever algoritmos, que é um tipo de método de descrição entre a linguagem natural e a linguagem de programação para descrever etapas e processos de algoritmos. Em vários livros e artigos sobre algoritmos, vemos com frequência a descrição de pseudocódigo, mesmo que você não precise conhecer uma linguagem, mas também por meio do pseudocódigo para entender a execução do fluxo do algoritmo.
Então, até que ponto o LLM entende bem o pseudocódigo? Na verdade, a compreensão de pseudocódigo do LLM é bastante forte. O LLM foi treinado com muitos códigos de qualidade e consegue entender facilmente o significado do pseudocódigo.
Como escrever um Prompt de pseudocódigo?
O pseudocódigo é muito familiar para os programadores e, para quem não é programador, é possível escrever pseudocódigo simples apenas lembrando-se de algumas regras básicas. Alguns exemplos:
- Variáveis, que são usadas para armazenar dados, por exemplo, para representar entradas ou resultados intermediários com alguns símbolos específicos
- Tipo, usado para definir o tipo de dados, como cadeias de caracteres, números, matrizes, etc.
- função que define a lógica de execução de uma subtarefa
- Fluxo de controle, usado para controlar o processo de execução do programa, como loops, julgamentos condicionais, etc.
- instrução if-else, se a condição A for satisfeita, execute a tarefa A; caso contrário, execute a tarefa B.
- Um loop for que executa uma tarefa para cada elemento da matriz.
- No loop while, quando a condição A for satisfeita, a tarefa B será executada continuamente.
Agora vamos escrever o Prompt em pseudocódigo, usando as duas perguntas de reflexão anteriores como exemplo.
Pseudocódigo para gerar um formato JSON específico
O formato JSON desejado pode ser claramente descrito com a ajuda de um pseudocódigo semelhante à definição de tipo do TypeScript:
Please split the sentences into short segments, no more than 1 line (less than 80 characters, ~10 English words) each.
Please keep each segment meaningful, e.g. split from punctuations, "and", "that", "where", "what", "when", "who", "which" or "or" etc if possible, but keep those punctuations or words for splitting.
Do not add or remove any words or punctuation marks.
Input is an array of strings.
Output should be a valid json array of objects, each object contains a sentence and its segments.
Array<{
sentence: string;
segments: string[]
}>
Organização de scripts de legendas com pseudocódigo
A tarefa de agrupar textos legendados é relativamente complexa. Se você imaginar escrever um programa para realizar essa tarefa, pode haver muitas etapas, como extrair capítulos, depois extrair falantes e, por fim, agrupar diálogos de acordo com capítulos e falantes. Com a ajuda do pseudocódigo, podemos decompor essa tarefa em várias subtarefas, para as quais nem é necessário escrever um código específico, mas apenas descrever claramente a lógica de execução das subtarefas. Em seguida, execute essas subtarefas passo a passo e, por fim, integre a saída do resultado.
Podemos usar algumas variáveis para armazenar, como subjectespeakersechapterseparagraphs etc.
Na saída, também podemos usar loops For para iterar pelos capítulos e parágrafos e instruções If-else para determinar se precisamos emitir o nome do orador.
Sua tarefa é reorganizar as transcrições de vídeo para facilitar a leitura e reconhecer os falantes em diálogos com várias pessoas. Aqui estão os pseudocódigos de como fazer isso Aqui estão os pseudocódigos de como fazer isso
def extract_subject(transcript):
# Find the subject in the transcript and return it as a string.
def extract_chapters(transcript):
# Find the chapters in the transcript and return them as a list of strings.
def extract_speakers(transcript):
# Find the speakers in the transcript and return them as a list of strings.
def find_paragraphs_and_speakers_in_chapter(chapter):
# Find the paragraphs and speakers in a chapter and return them as a list of tuples.
# Each tuple contains the speaker and their paragraphs.
def format_transcript(transcript):
# extract the subject, speakers, chapters and print them
subject = extract_subject(transcript)
print("Subject:", subject)
speakers = extract_speakers(transcript)
print("Speakers:", speakers)
chapters = extract_chapters(transcript)
print("Chapters:", chapters)
# format the transcript
formatted_transcript = f"# {subject}\n\n"
for chapter in chapters:
formatted_transcript += f"## {chapter}\n\n"
paragraphs_and_speakers = find_paragraphs_and_speakers_in_chapter(chapter)
for speaker, paragraphs in paragraphs_and_speakers:
# if there are multiple speakers, print the speaker's name before each paragraph
if speakers.size() > 1:
formatted_transcript += f"{speaker}:"
formatted_transcript += f"{speaker}:"
for paragraph in paragraphs:
formatted_transcript += f" {paragraph}\n\n"
formatted_transcript += "\n\n"
return formatted_transcript
print(format_transcript($user_input))
Vamos ver como isso funciona:
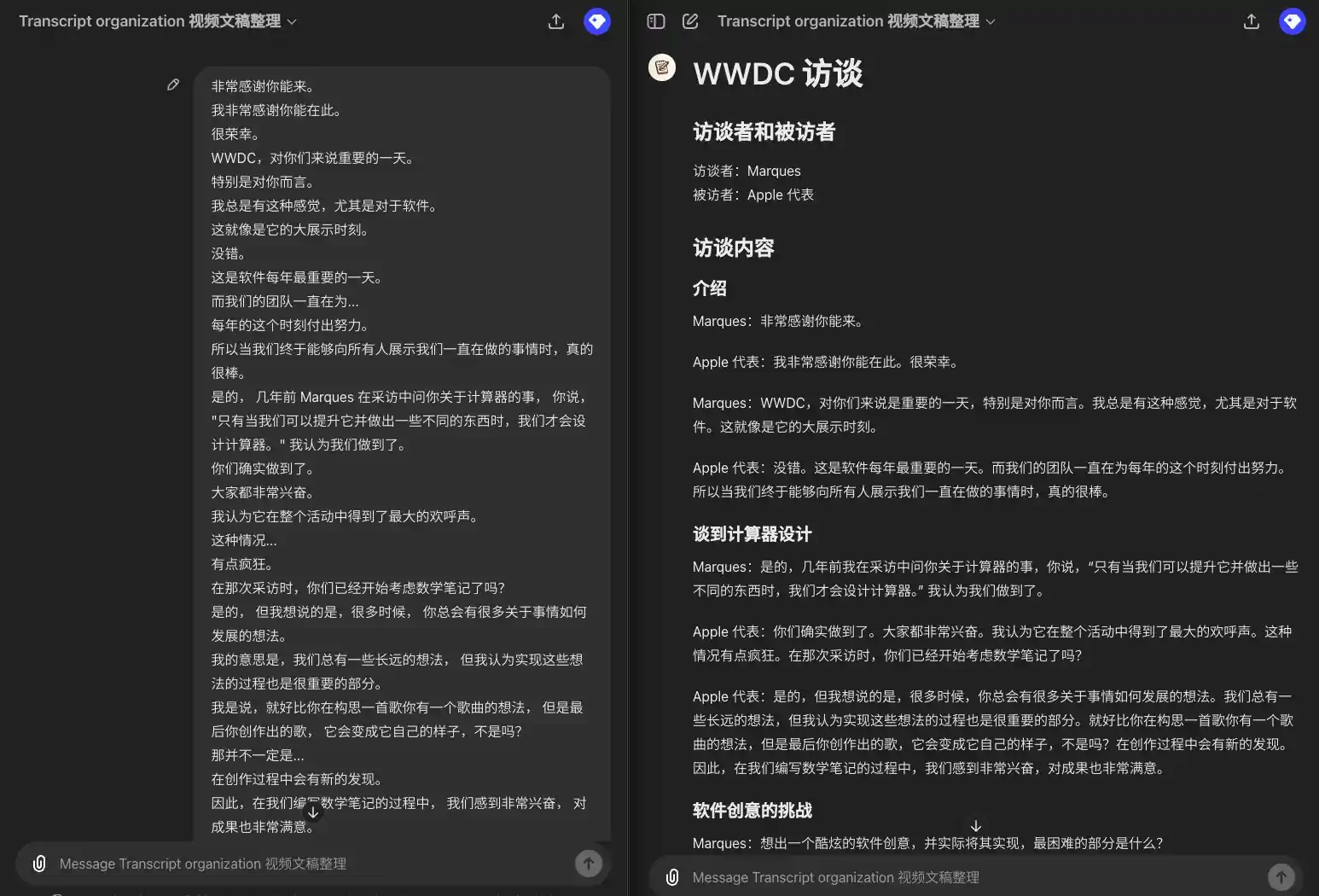
Coletando transcrições de entrevistas da WWDC
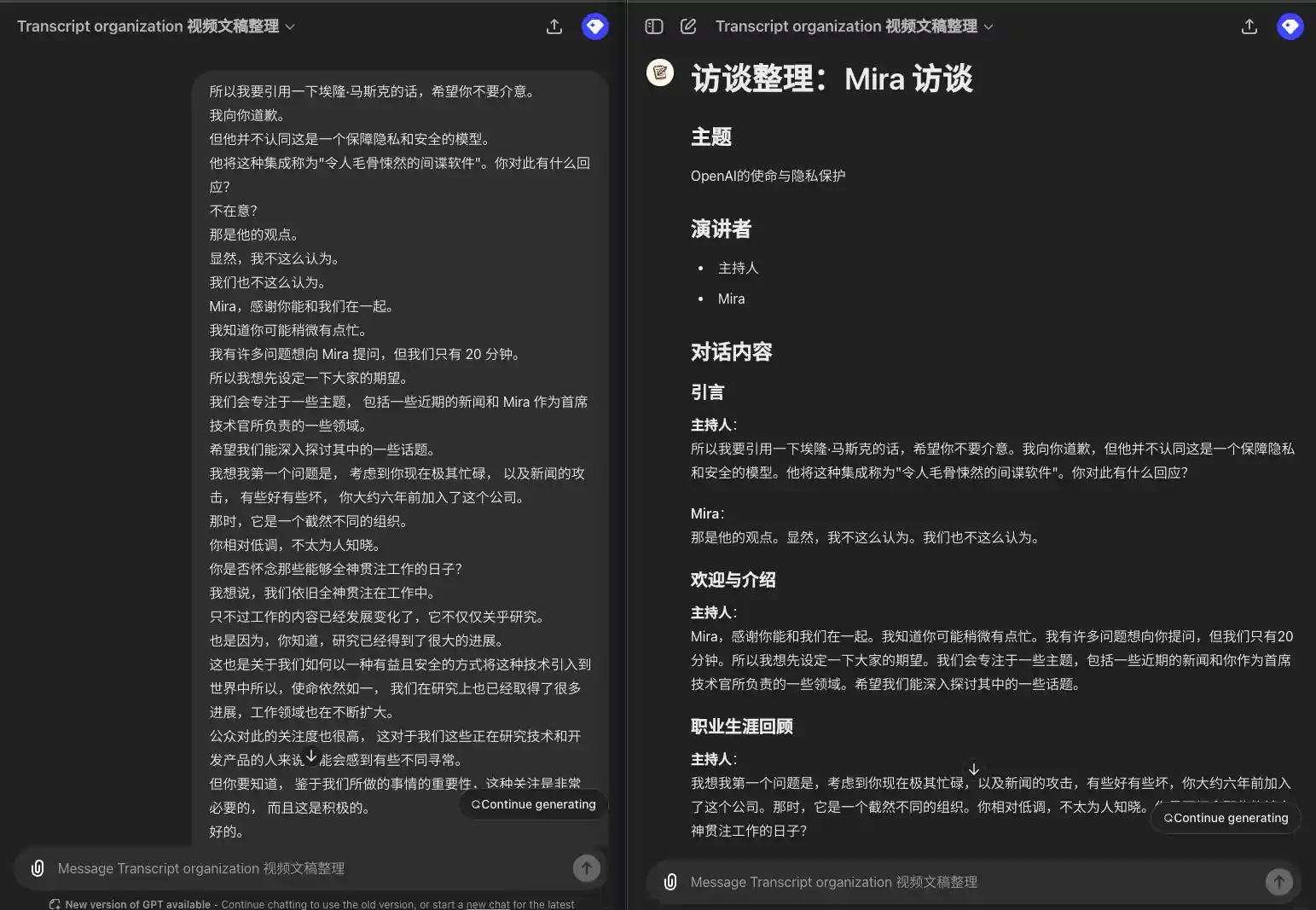
Vários palestrantes, palestrantes de shows
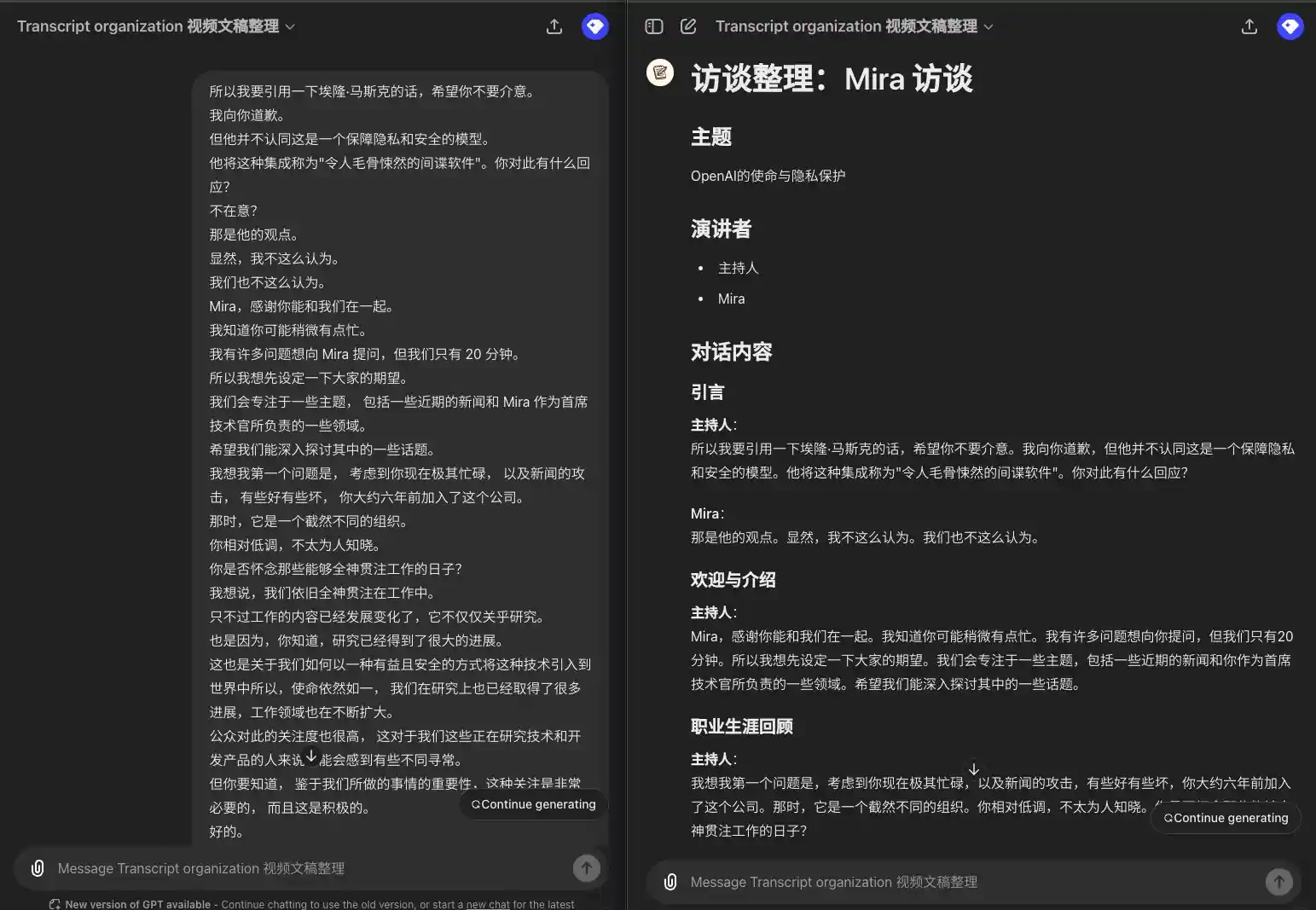
1 Alto-falante, nenhum alto-falante mostrado
Você também pode usar apenas o GPT que gerei com esse prompt:Organização de transcrição GPT
Faça o ChatGPT desenhar várias imagens de uma vez com o código pseudo
Também aprendi recentemente um uso muito interessante do termo com um internauta taiwanês, Sensei Yoon Sang-chi.Faça o ChatGPT desenhar várias imagens de uma vez com pseudocódigo.
Agora, se você quiser fazer ChatGPT Se quiser gerar mais de uma imagem por vez, você pode usar o pseudocódigo para decompor a tarefa de gerar várias imagens em várias subtarefas e, em seguida, executar várias subtarefas por vez e, finalmente, integrar a saída do resultado.
下面是一段画图的伪代码,请按照伪代码的逻辑,用DALL-E画图:
images_prompts = [
{
style: "Kawaii",
prompt: "Draw a cute dog",
aspectRatio: "Wide"
},
{
style: "Realistic",
prompt: "Draw a realistic dog",
aspectRatio: "Square"
}
]
images_prompts.forEach((image_prompt) =>{
print("Generating image with style: " + image_prompt.style + " and prompt: " + image_prompt.prompt + " and aspect ratio: " + image_prompt.aspectRatio)
image_generation(image_prompt.style, image_prompt.prompt, image_prompt.aspectRatio);
})

resumos
Por meio do exemplo acima, podemos ver que, com a ajuda do pseudocódigo, podemos controlar com mais precisão o resultado de saída do LLM e definir sua lógica de execução, em vez de nos limitarmos apenas à descrição da linguagem natural. Quando nos deparamos com algumas tarefas complexas ou tarefas com várias ramificações, cada ramificação precisa executar várias subtarefas e as subtarefas estão relacionadas umas às outras, o uso de pseudocódigo para descrever o Prompt será mais claro e preciso.
Quando escrevemos um Prompt, lembramos que um Prompt é essencialmente uma instrução de controle para o LLM, descrita em linguagem natural, que permite que o LLM entenda o que queremos e, em seguida, transforme as entradas nas saídas que esperamos, conforme necessário. Quanto à forma de descrição do Prompt, ela pode ser flexível em várias formas, como few-shot, CoT, pseudocódigo etc.
Mais exemplos:
Gerar meta prompts de "pseudocódigo" para controle preciso da formatação da saída
© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Artigos relacionados



Nenhum comentário...