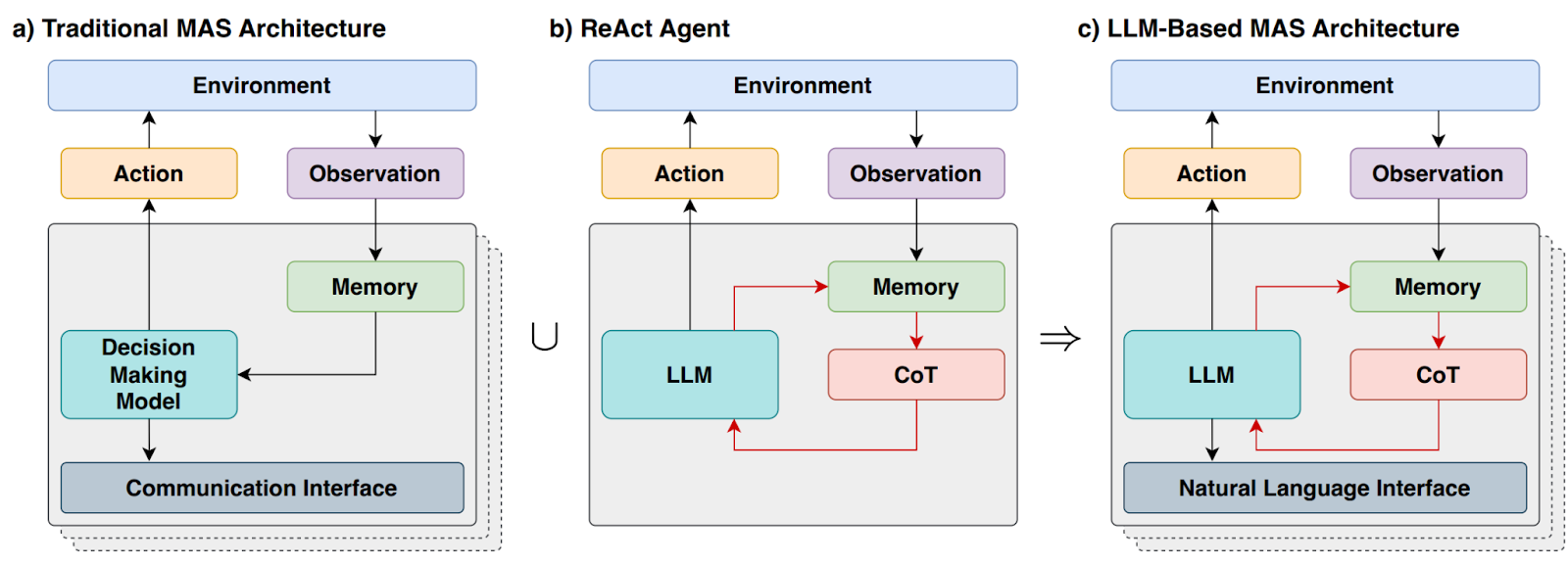
Avaliação da criatividade de grandes modelos de linguagem: além do paradigma LoTbench de múltipla escolha

No modelo de linguagem grande ( LLM ), modelando a área de pesquisa Leap-of-Thought A capacidade, ou criatividade, é tão importante quanto a capacidade de Chain-of-Thought para as habilidades de raciocínio lógico representadas. No entanto, atualmente há um aumento significativo no número de alunos que buscam LLM Discussões aprofundadas sobre criatividade e métodos de avaliação eficazes ainda são relativamente escassas, o que, de certa forma, limita LLM Potencial de desenvolvimento em aplicativos criativos.
A principal razão para isso é que é extremamente difícil construir um processo de avaliação objetivo, automatizado e confiável para o conceito abstrato de "criatividade".
No passado, muitas das respostas a LLM As tentativas de medir a criatividade, conforme mostrado na Figura 1, continuam a usar perguntas de múltipla escolha e de sequenciamento, que são comumente usadas para avaliar as habilidades de raciocínio lógico. Esses métodos são bons para examinar se o modelo consegue identificar a opção predefinida "melhor" ou "mais lógica", mas não são bons para avaliar a verdadeira criatividade - a capacidade de gerar conteúdo novo e exclusivo. Mas eles não são tão bons para avaliar a verdadeira criatividade - a capacidade de gerar conteúdo novo e exclusivo.
Por exemplo, considere a tarefa da Figura 2: Com base na imagem e no texto existente, preencha o campo "? O conteúdo deve ser criativo e bem-humorado.
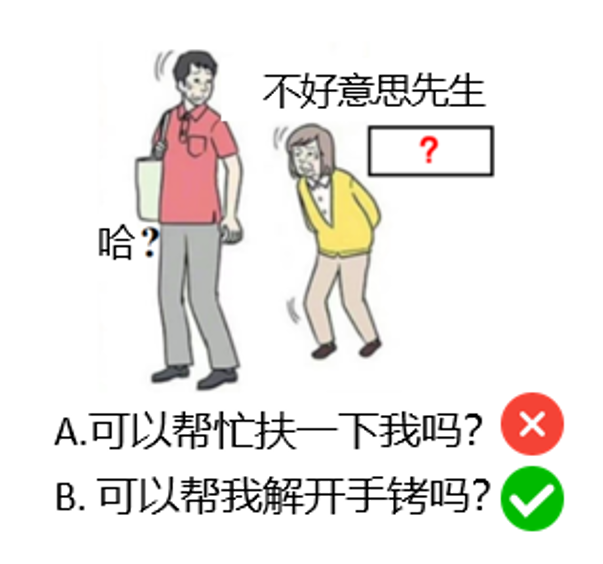
Se essa for uma pergunta de múltipla escolha, forneça as opções "A. Você pode me ajudar?" e "B. Você pode me ajudar a tirar as algemas?" e "B. Você pode me tirar as algemas?" e "B. Você pode me ajudar a tirar as algemas? LLM É provável que a opção B seja escolhida, não porque demonstre criatividade, mas simplesmente porque a opção B é mais "especial" ou "incomum" do que a opção A, e o modelo é capaz de fazer uma escolha por meio do reconhecimento de padrões e não do pensamento criativo.
avaliação LLM de criatividade, o núcleo deve ser examinado quanto à suagerandoA capacidade de inovar o conteúdo em vez demedidorA capacidade do conteúdo de ser inovador ou não. Os métodos tradicionais de avaliação, como a múltipla escolha, são mais focados na última opção e, portanto, têm limitações. Atualmente, os principais métodos que permitem uma avaliação direta da capacidade geradora são a avaliação manual e a avaliação de conteúdo. LLM-as-a-judge (Use LLM (como uma revisão). As avaliações manuais, embora precisas e consistentes com os valores humanos, são caras e difíceis de dimensionar. Considerando que LLM-as-a-judge O desempenho do método em tarefas de avaliação da criatividade ainda é imaturo e a estabilidade dos resultados precisa ser aprimorada.
Diante desses desafios, pesquisadores da Universidade Sun Yat-sen, da Universidade de Harvard, do Laboratório Pengcheng e da Universidade de Administração de Cingapura criaram uma nova forma de pensar. Em vez de julgar diretamente a "bondade" do conteúdo gerado, eles estão analisando a "bondade" do conteúdo estudando LLM O "custo" de gerar uma resposta que seja comparável ao conteúdo de inovações humanas de alta qualidade(que pode ser interpretado como o esforço necessário ou o custo da interação), construiu um sistema chamado LoTbench de um paradigma de avaliação de criatividade automatizada e interativa em várias rodadas. O método visa a fornecer uma medida de criatividade mais confiável e dimensionável. Os resultados de pesquisas relacionadas foram publicados em IEEE TPAMI Jornal.

- Título da tese: Um paradigma com reconhecimento de causalidade para avaliar a criatividade de modelos multimodais de linguagem grande
- Link para o artigo: https://arxiv.org/abs/2501.15147
- Página inicial do projeto: https://lotbench.github.io
Cena da missão: Espeto Frio Japonês
LoTbench O estudo se baseia em CVPR'24 Uma extensão do trabalho apresentado na conferência Let's Think Outside the Box: Exploring Leap-of-Thought in Large Language Models with Creative Humor Generation. Generation). Os pesquisadores escolheram um formulário de tarefa derivado do tradicional jogo japonês Oogiri, conhecido como "Japanese Cold Trolling" na Internet chinesa, conforme mostrado na Figura 2.
Esse tipo de tarefa exige que os participantes vejam as imagens e completem o texto, o que torna a combinação de imagens e texto inovadora e bem-humorada. Essa tarefa foi escolhida como base para a avaliação com base nas seguintes considerações:
- Altos requisitos de criatividade: A tarefa era uma solicitação direta para gerar conteúdo criativo e bem-humorado, um típico desafio de criatividade.
- Ajuste do modelo multimodal: A entrada é gráfica e a saída é de preenchimento de texto, em total conformidade com o atual sistema multimodal
LLMO escopo de competência do - Recursos de dados avançados: A popularidade do "Japanese Cold Trolling" na comunidade on-line acumulou uma grande quantidade de exemplos de alta qualidade de criações humanas e dados com informações de avaliação, o que facilita a criação de conjuntos de dados de avaliação.
Assim, o "cuspe frio japonês" é uma ferramenta útil para avaliar a qualidade multimodal do cuspe. LLM de criatividade oferece uma plataforma ideal e única.
Metodologia de avaliação do LoTbench

Diferentemente dos paradigmas tradicionais de avaliação (por exemplo, seleção, classificação), o LoTbench A ideia central é:Medindo um LLM Quantas rodadas de interações são necessárias para gerar uma resposta de inovação de qualidade humana que corresponda à predefinição ( HHCR A resposta é "o mesmo". Esse "número de rodadas" exigido reflete LLM A "distância" ou o "custo" para atingir uma determinada meta criativa.
Conforme mostrado no lado direito da Figura 3, para um determinado HHCR (matemática) gênero LoTbench Não é um requisito LLM Replique-o exatamente, mas observe o LLM É possível gerar, em várias rodadas de tentativas, uma ideia que, embora expressa de forma diferente, tenha um núcleo e um efeito criativos semelhantes (ou seja, um DAESO - Abordagem diferente, mas resultado igualmente satisfatório).
LoTbench O fluxo específico do processo é mostrado na Figura 4:
- Construção de tarefas: Selecionado a partir dos dados do "Japanese Cold Tweets".
HHCRAmostra. Para cada rodada, é necessário que a amostra a ser testadaLLMGerar uma resposta com base nas informações do gráficoRtpara preencher as lacunas do texto. - Julgamento da DAESO: Julgar o gerado
RtRelevância para o objetivoHHCR(Denotado comoR) alcançou oDAESO. Se sim, registre o número atual de rodadas para os cálculos de pontuação subsequentes; se não, vá para a etapa 3. - Questionamento interativo: Caso contrário
DAESOSe o teste for realizado na mesma embarcação, é necessárioLLMUma pergunta geral com base no histórico atual da interaçãoQt(por exemplo, pedir dicas sobre a direção criativa desejada). - Feedback do sistema: O sistema de avaliação é baseado em
HHCRA lógica interna doLLMQuestões levantadasQtResponda "Sim" ou "Não". - Integração e iteração de informações: Coloque todas as informações de interação para essa rodada (incluindo o
LLMgeração, questionamento e feedback do sistema) e a integração dos prompts fornecidos pelo sistema para formar a próxima rodada dohistory promptSe não tiver certeza, volte à etapa 1 e inicie uma nova rodada de tentativas.
Esse processo continua até que LLM gerado DAESO resposta, ou o limite máximo predefinido de rodadas foi atingido.
Pontuação final de criatividade Sc com base em uma revisão de n classificador para coisas ou pessoas individuais, classificador geral, abrangente HHCR Amostra, conduta m Os resultados foram calculados com base nos resultados de várias repetições do experimento. Os cálculos são aproximadamente os seguintes (em fórmulas HTML):
Sc = ( 1 / n ) ∑i=1n [ ( 1 / m ) ∑j=1m ( 1 / ( 1 + kij ) ) ]
Entre eles.k_ij é o modelo no primeiro j A segunda repetição do experimento para a primeira i classificador para coisas ou pessoas individuais, classificador geral, abrangente HHCR amostras, gerando com sucesso DAESO O número de rodadas usadas para a resposta.
Essa pontuação de criatividade Sc Com as seguintes características:
- Relação inversa: Pontuação e número de rodadas necessárias
kInversamente proporcional. Quanto menor o número de rodadas, maisLLMQuanto mais rápido você atingir o nível desejado de criatividade, maior será a sua pontuação e mais criativo você será. - Limite inferior de zero pontos: no caso de
LLMFalha consistente na geração dentro do limite máximo de rodadasDAESO(equivalente ao número de rodadas que tende ao infinito), sua pontuação para essa amostra tende a 0, indicando criatividade insuficiente nessa tarefa. - Robustez: Isso é feito por meio do uso de vários
HHCRA média das amostras foi calculada em várias repetições do experimento, e as pontuações levaram em conta a diversidade e a dificuldade das ideias, reduzindo o efeito de aleatoriedade de um único experimento.
Como determinar "semelhanças e diferenças" ( DAESO )?
DAESO A determinação do LoTbench Uma das principais dificuldades da metodologia.
Por que você precisa dele DAESO Julgamento? Uma das principais características das tarefas de criatividade é sua abertura e variedade. Os seres humanos podem apresentar muitas respostas diferentes, mas igualmente criativas e bem-humoradas, para o mesmo cenário de "troll frio japonês". Conforme mostrado na Fig. 5, "despertador vibrante" e "telefone celular vibrante" estão centrados na ideia central de "o objeto bate e emite um som devido à sua vibração" e obtêm efeitos humorísticos semelhantes. O efeito humorístico é semelhante.
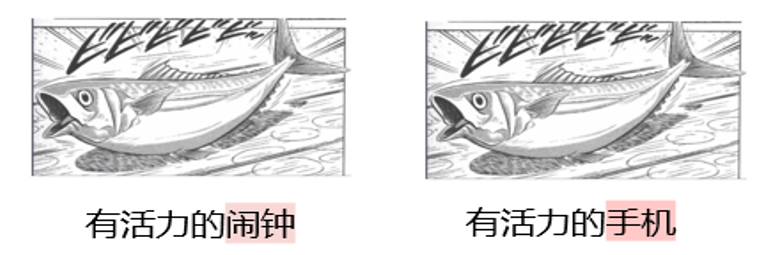
Essas semelhanças criativas profundas não podem ser capturadas com precisão por uma simples correspondência de superfície de texto ou por cálculos convencionais de semelhança semântica. Por exemplo, embora "energetic flea" também tenha a palavra "energetic", ela não tem a associação funcional de "sound reminder" implícita em "alarm clock" ou "mobile phone". A associação funcional de "lembrete sonoro" implícita em "despertador" ou "telefone celular" está ausente. Portanto, é importante introduzir um mecanismo para determinar "semelhanças e diferenças".
Como realizar DAESO Julgamento?
No artigo, o pesquisador sugere que duas respostas para satisfazer o DAESO Para que isso ocorra, duas condições precisam ser atendidas ao mesmo tempo:
- A mesma inovação central explicada: A lógica criativa ou o humor por trás de ambas as respostas é essencialmente o mesmo.
- Mesma similaridade funcional: As duas respostas são semelhantes em termos da "função" ou "papel na cena" que provoca o humor.
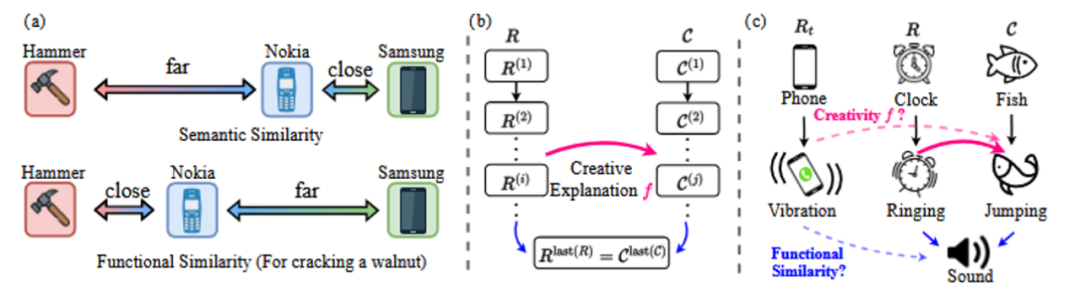
A similaridade funcional é diferente da similaridade semântica pura. Como mostra o exemplo da Fig. 6(a), no cenário funcional específico de "quebrar nozes", a similaridade funcional entre "celular Nokia" e "martelo" pode ser maior do que a similaridade semântica entre "celular Samsung" e "celular Samsung". A semelhança semântica entre "Nokia mobile phone" e "hammer" pode ser maior do que a semelhança entre "Samsung mobile phone" e "Samsung mobile phone".
O fato de se encontrar apenas a mesma interpretação da inovação central pode resultar em uma resposta que se desvie do tema (por exemplo, a "pulga vibrante" no exemplo da Figura 5, que não tem a função de "lembrete vocal"); o fato de se encontrar apenas a mesma semelhança funcional pode não capturar o núcleo da ideia (por exemplo, o "tambor vibrante" no exemplo da Figura 5, que também é um objeto vocal, mas não tem a sensação de batida devido à sua própria "vibração"). O "Energetic Drum" (tambor energético) no exemplo da Figura 5 também é um objeto audível, mas não tem a sensação de batida devido ao seu próprio "vigor").
em termos concretos DAESO Na realização do julgamento, o pesquisador primeiro fornece um novo conjunto de critérios para cada HHCR As amostras foram rotuladas com uma explicação detalhada da fonte de seu humor e criatividade. Em seguida, as informações do título (legenda) da imagem foram combinadas e usadas com o LLM no espaço de texto, para a capacidade de HHCR Construa uma cadeia causal (conforme mostrado na Fig. 6(c)) para analisar sua composição criativa. Por fim, crie instruções específicas (instrução) para outro LLM (por exemplo GPT-4o mini ) Com base nessas informações, a resposta a ser medida é avaliada no espaço do texto Rt colaboração com o alvo HHCR Se ambos os itens acima DAESO Condições.
Estudos demonstraram que o uso de GPT-4o mini ir em frente DAESO julgamento, a precisão de 80%-90% pode ser obtida com um custo computacional menor. Considerando a LoTbench Serão realizadas várias repetições do experimento, com uma única DAESO O efeito de pequenos erros de julgamento na pontuação média final é ainda mais reduzido, garantindo assim a confiabilidade da avaliação geral.
Resultados da avaliação
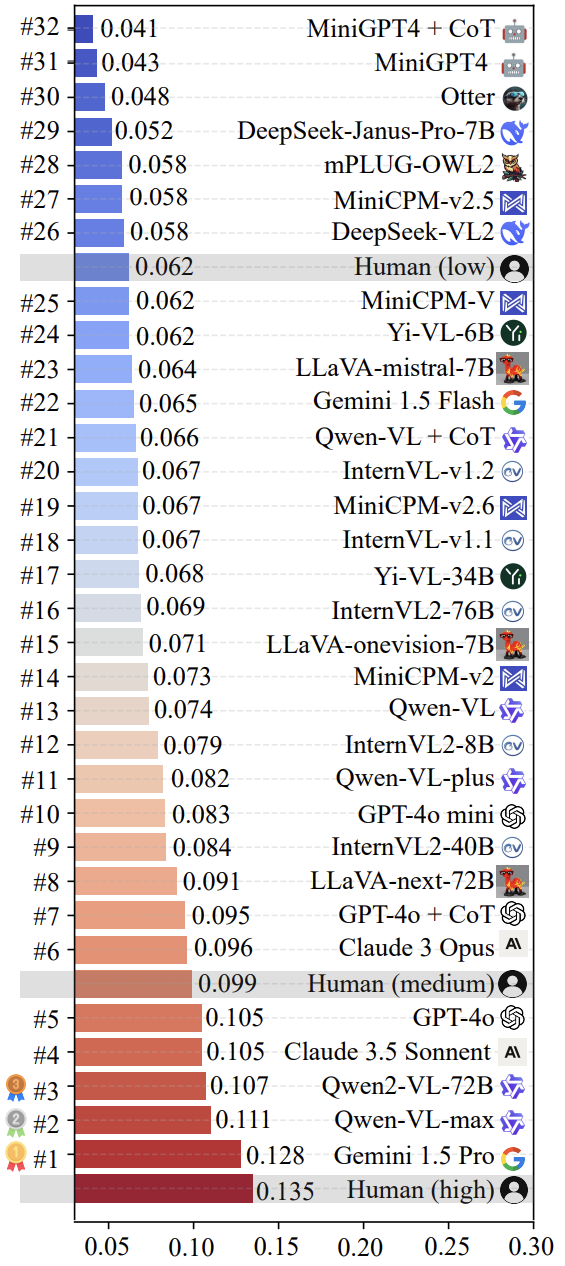
A equipe de pesquisa usou LoTbench Uma análise de alguns dos principais produtos multimodais atuais LLM A avaliação foi realizada. Conforme mostrado na Figura 7, os resultados mostram que os resultados são baseados na LoTbench existente LLM da criatividade geralmente não é considerado forte, em comparação com a resposta criativa humana de alta qualidade ( HHCR ) ainda ficam aquém na comparação. Entretanto, em comparação com o nível humano geral (não explicitamente identificado na figura, mas inferido) ou o nível humano primário, alguns dos principais LLM (por exemplo Gemini 1.5 Pro responder cantando Qwen-VL-max ) demonstrou alguma competitividade e também dá a entender que o LLM Possui o potencial de transcender a humanidade em termos de criatividade.
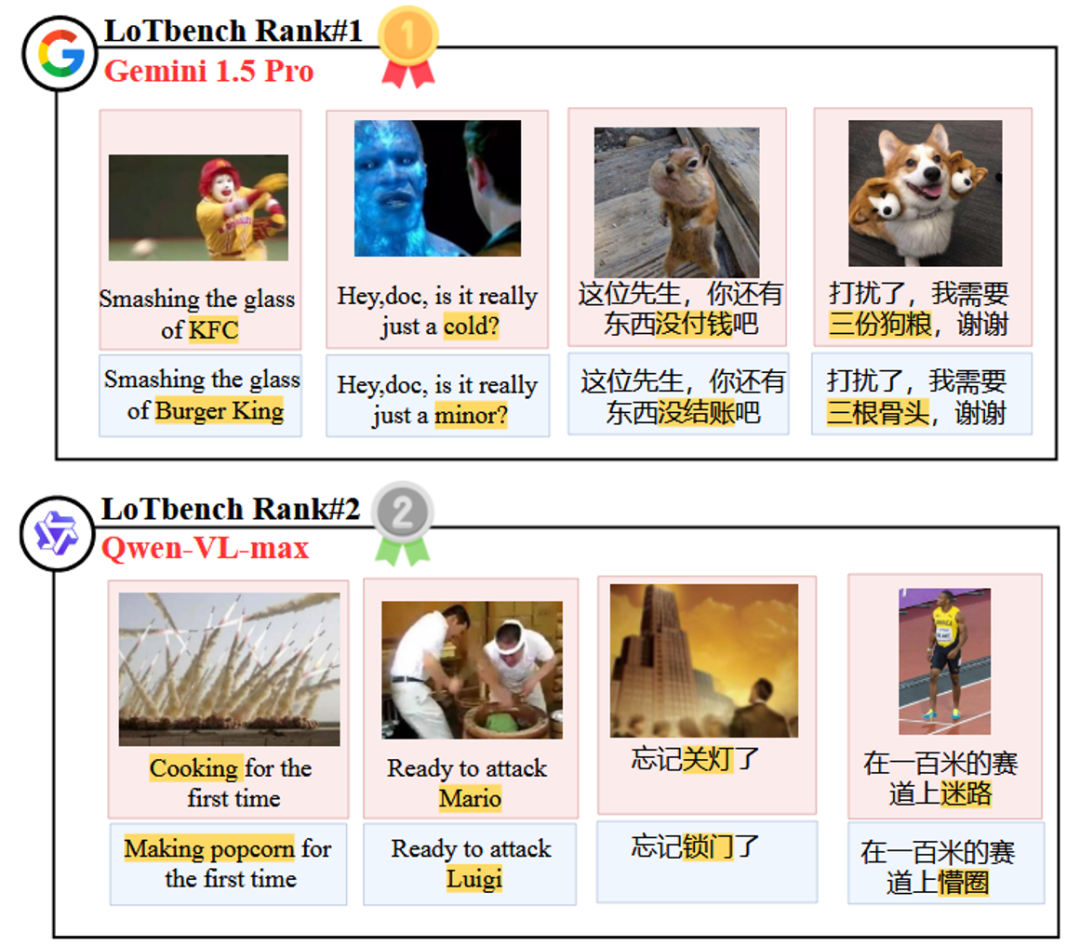
A Figura 8 mostra os dois primeiros da lista de Gemini 1.5 Pro responder cantando Qwen-VL-max componente específico do modelo HHCR (destacadas em vermelho) geradas DAESO Resposta (marcada em azul).
Vale a pena observar que a recente e altamente divulgada DeepSeek-VL2 responder cantando Janus-Pro-7B Os modelos de série também foram avaliados. Os resultados mostraram que sua criatividade em LoTbench A estrutura do sistema é mais ou menos no nível do primário humano. Isso sugere que, ao aprimorar a comunicação multimodal LLM Ainda há um espaço considerável para exploração em termos da profunda criatividade do
© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Artigos relacionados




Nenhum comentário...