
Lançamento da OpenAI: Aplicativos e práticas recomendadas para modelos de inferência de IA
No campo da IA, a escolha do modelo é fundamental. A openAI, líder do setor, oferece uma família de modelos de dois tipos principais:modelo de inferência (Modelos de raciocínio) e Modelo GPT (Modelos GPT). O primeiro é representado pela série O de modelos, como o1 responder cantando o3-miniEste último é conhecido por sua família de modelos GPT, como o GPT-4o. Compreender as diferenças entre esses dois tipos de modelos e os cenários de aplicação em que cada um deles se destaca é fundamental para utilizar plenamente o potencial da IA.
Este artigo vai se aprofundar nesse assunto:
- Principais diferenças entre os modelos de inferência OpenAI e os modelos GPT.
- Quando priorizar o uso dos modelos de inferência da OpenAI.
- Como utilizar modelos de inferência de dicas de forma eficaz para obter o melhor desempenho.
Outro dia, os engenheiros da Microsoft lançaram um Engenharia de dicas para os modelos de inferência OpenAI O1 e O3-mini Se você não tiver uma visão geral da aplicação, é possível comparar as diferenças de aplicação entre os dois.
Modelos de inferência vs. modelos de GPT: estrategistas vs. executores
Os modelos de inferência da série O da OpenAI, em oposição aos modelos GPT conhecidos, apresentam seus próprios pontos fortes em diferentes tipos de tarefas e exigem diferentes estratégias de sinalização. É importante entender que esses dois tipos de modelos não são simplesmente melhores ou piores, mas têm um foco de capacidade diferente. Isso reflete os esforços contínuos da OpenAI para expandir os limites dos recursos de seus modelos para atender às necessidades de aplicativos cada vez mais complexos que exigem raciocínio profundo.
A OpenAI treinou especialmente os modelos da série O, cujo codinome interno é Planners, para pensar de forma mais longa e profunda, o que lhes permite se destacar em áreas como formulação de estratégias, planejamento de problemas complexos e tomada de decisões com base em grandes quantidades de informações ambíguas. A capacidade desses modelos de concluir tarefas com um alto grau de precisão e exatidão os torna ideais para campos que tradicionalmente dependem de especialistas humanos, como áreas especializadas de matemática, ciências, engenharia, serviços financeiros e serviços jurídicos.
Por outro lado, os modelos GPT da OpenAI (com o codinome interno "Workhorses") são mais econômicos e de baixa latência e foram projetados para a execução direta de tarefas. Na prática, um padrão comum é usar uma combinação desses dois tipos de modelos: usar os modelos o-series para formular uma macroestratégia para a solução de problemas e, em seguida, executar com eficiência subtarefas específicas com a ajuda dos modelos GPT, especialmente em cenários em que a velocidade e a relação custo-benefício são mais importantes do que a precisão absoluta. Essa divisão de trabalho reflete a maturidade da filosofia de design do modelo de IA, que separa o planejamento da execução.
Como escolher o modelo certo? Entendendo suas necessidades
Ao escolher um modelo, a chave é definir os principais requisitos do cenário de seu aplicativo:
- Velocidade e custo. Se a velocidade e a eficiência de custos forem suas prioridades, o modelo GPT geralmente é a opção mais rápida e econômica.
- Tarefas claramente definidas. Para aplicativos com objetivos claros e limites de tarefas bem definidos, o modelo GPT é capaz de se destacar em tarefas de execução.
- Precisão e confiabilidade. Se a sua aplicação exigir extrema precisão e confiabilidade dos resultados, os modelos da série O são os tomadores de decisão mais confiáveis.
- Solução de problemas complexos. Diante da alta ambiguidade e complexidade, os modelos da série O são capazes de lidar com isso de forma eficaz.
Portanto, se a velocidade e o custo são as principais considerações e seus casos de uso envolvem principalmente tarefas diretas e bem definidas, os modelos GPT da OpenAI são ideais. No entanto, se a precisão e a confiabilidade forem essenciais e você estiver resolvendo problemas complexos e de várias etapas, os modelos da série O da OpenAI poderão ser mais adequados às suas necessidades.
Em muitos fluxos de trabalho de IA do mundo real, a melhor prática é usar uma combinação desses dois modelos: a família de modelos o atua como um "planejador" responsável pelo planejamento do agente e pela tomada de decisões, enquanto a família de modelos GPT atua como um "executor" responsável pela execução de tarefas específicas. Essa estratégia de combinação faz uso total dos pontos fortes dos dois tipos de modelos.

Por exemplo, os modelos GPT-4o e GPT-4o mini da OpenAI podem ser usados em cenários de atendimento ao cliente, em que as informações do cliente são usadas primeiro para classificar os detalhes do pedido, identificar problemas no pedido e políticas de devolução e, em seguida, esses pontos de dados são alimentados no modelo o3-mini, que toma a decisão final sobre a viabilidade de uma devolução com base em políticas predefinidas.
Cenários de aplicativos para modelos de inferência: excelência em complexidade e ambiguidade
A OpenAI desenvolveu alguns padrões típicos de aplicações bem-sucedidas de seus modelos de inferência por meio da colaboração com clientes e observações internas. Os cenários de aplicação listados abaixo não são exaustivos, mas sim guias práticos criados para ajudá-lo a avaliar e testar melhor os modelos o-series da OpenAI.
1. navegação em tarefas ambíguas: compreensão da intenção a partir de informações fragmentadas
Os modelos de raciocínio são particularmente bons para lidar com tarefas com informações incompletas ou dispersas. Mesmo quando solicitados com informações limitadas, os modelos de inferência podem entender com eficácia a verdadeira intenção do usuário e lidar adequadamente com as ambiguidades nas instruções. Vale a pena mencionar que os modelos de inferência geralmente não se apressam em fazer suposições imprudentes nem tentam preencher as lacunas de informações por conta própria, mas fazem perguntas de esclarecimento de forma proativa para garantir que os requisitos da tarefa sejam compreendidos com precisão. Esse é um bom exemplo das vantagens dos modelos de raciocínio ao lidar com incertezas e tarefas complexas.
A Hebbia, uma plataforma de conhecimento de IA para os setores jurídico e financeiro, disse: "Os recursos superiores de inferência da o1 permitem que a Matrix, a plataforma multiagente da OpenAI, processe com eficiência documentos complexos e gere respostas detalhadas, bem estruturadas e informativas. Por exemplo, a o1 facilita para a Matrix identificar, com simples comandos, o montante de dinheiro disponível em um contrato de crédito com capacidade de pagamento restrita. Nenhum outro modelo atingiu esse nível de desempenho anteriormente. Nos testes de dicas complexas de contratos de crédito intensivos do 52%, o o1 obteve resultados mais significativos em comparação com outros modelos."
-Hebbia, uma empresa de plataforma de conhecimento de IA para os setores jurídico e financeiro
2. recuperação de informações: encontrar a agulha no palheiro, identificar o local
Quando confrontado com grandes quantidades de informações não estruturadas, o modelo de inferência demonstra uma forte compreensão das informações e é capaz de extrair com precisão as informações mais relevantes para a pergunta, respondendo, assim, com eficiência à pergunta do usuário. Isso destaca o desempenho superior dos modelos de inferência na recuperação de informações e na filtragem de informações importantes, especialmente ao lidar com conjuntos de dados em grande escala.
A Endex, a plataforma de inteligência financeira de IA, compartilha: "Para analisar profundamente as aquisições de empresas, o modelo da o1 foi usado para revisar dezenas de documentos da empresa, incluindo contratos e acordos de arrendamento, com o objetivo de encontrar cláusulas em potencial que poderiam afetar negativamente o negócio. O modelo foi encarregado de sinalizar as principais cláusulas. Ao fazer isso, a o1 identificou com perspicácia uma cláusula importante de "mudança de controle" em uma nota de rodapé: uma cláusula que exigia o pagamento imediato de um empréstimo de US$ 75 milhões se a empresa fosse vendida. A alta atenção da o1 aos detalhes permite que os agentes de IA da OpenAI apoiem efetivamente o trabalho dos profissionais financeiros, identificando com precisão as informações de missão crítica."
--Endex, plataforma de inteligência financeira de IA
3. descoberta de relacionamento e identificação de nuances: aprofundando-se no valor dos dados
A OpenAI descobriu que os modelos de inferência são particularmente bons na análise de documentos densos e não estruturados de centenas de páginas, como contratos legais, demonstrações financeiras e reclamações de seguros. Esses modelos são eficazes na extração de informações de documentos complexos, estabelecendo conexões entre diferentes documentos e tomando decisões inferenciais com base em fatos implícitos nos dados. Isso mostra que os modelos de inferência têm vantagens significativas no processamento de documentos complexos e na mineração de informações profundas.
Blue J, a plataforma de IA para pesquisa tributária, menciona: "A pesquisa tributária geralmente exige a integração de informações de vários documentos para formar uma conclusão final e convincente. Depois de substituir o modelo GPT-4o pelo modelo o1, a OpenAI descobriu que o o1 tem um desempenho melhor no raciocínio sobre as interações entre os documentos e é capaz de tirar conclusões lógicas que não são aparentes em um único documento. Como resultado, ao mudar para o modelo o1, a OpenAI observou uma impressionante melhoria de 4x no desempenho de ponta a ponta."
--Blue J, Plataforma de IA para pesquisa tributária
Os modelos de raciocínio são igualmente hábeis em compreender políticas e regras diferenciadas e aplicá-las a tarefas específicas para chegar a conclusões razoáveis.
A BlueFlame AI, uma plataforma de IA de gerenciamento de investimentos, dá um exemplo: "No campo da análise financeira, os analistas geralmente precisam lidar com situações complexas relacionadas aos direitos dos acionistas e precisam ter uma compreensão profunda das complexidades jurídicas associadas. A OpenAI testou cerca de 10 modelos de diferentes fornecedores usando uma pergunta desafiadora, mas comum: como o comportamento do financiamento afetará os acionistas existentes, especialmente quando eles exercerem seu privilégio de antidiluição? Essa pergunta requer um raciocínio sobre as avaliações da empresa antes e depois do financiamento e o tratamento das complexidades da diluição cíclica - uma pergunta que levaria de 20 a 30 minutos para ser respondida por um analista financeiro de alto nível. A OpenAI descobriu que os modelos o1 e o3-mini resolvem esse problema perfeitamente! Os modelos até geraram uma tabela computacional clara que mostra em detalhes o impacto do comportamento de financiamento sobre acionistas de US$ 100.000."
--BlueFlame AI, uma plataforma de IA de gerenciamento de investimentos
4. planejamento de agência em várias etapas: um plano estratégico para operações, uma estratégia para o sucesso
Os modelos de inferência desempenham um papel fundamental no planejamento de agentes e na formulação de estratégias. A OpenAI observou que os modelos de inferência, quando posicionados como "planejadores", são capazes de gerar soluções detalhadas e de várias etapas para problemas complexos. Posteriormente, o sistema pode selecionar e atribuir o modelo de GPT mais adequado ("executor") para executar cada etapa, com base em demandas variáveis de latência e inteligência. Isso demonstra ainda mais as vantagens de usar uma combinação de modelos, com o modelo de inferência atuando como o "cérebro" para o planejamento da estratégia e o modelo de GPT atuando como os "braços e pernas" para a execução.
A Argon AI, uma plataforma de conhecimento de IA para o setor farmacêutico, revela: "A OpenAI usa o modelo o1 como um planejador em sua infraestrutura de agentes, permitindo que ele orquestre outros modelos no fluxo de trabalho para concluir com eficiência tarefas de várias etapas. A OpenAI descobriu que o modelo o1 é muito bom em escolher o tipo certo de dados e dividir problemas grandes e complexos em módulos menores e gerenciáveis para que outros modelos possam se concentrar em execuções específicas."
--Argon AI, uma plataforma de conhecimento de IA para o setor farmacêutico
Lindy.AI, um assistente de IA em funcionamento, compartilhou: "O modelo o1 oferece suporte avançado para os diversos fluxos de trabalho de agentes do Lindy, o assistente de IA em funcionamento da OpenAI. O modelo é capaz de usar chamadas de função para extrair informações importantes do calendário ou e-mail de um usuário para ajudá-lo automaticamente a agendar reuniões, enviar e-mails e gerenciar outros aspectos de suas tarefas diárias. A OpenAI mudou todas as etapas anteriores do agente da Lindy que estavam causando problemas para o modelo o1 e observou que a funcionalidade do agente da Lindy se tornou impecável quase da noite para o dia!"
--Lindy.AI, assistente de IA para trabalho
5 Raciocínio visual: percepção das informações por trás da imagem
A partir de hoje.o1 é o único modelo de inferência que oferece suporte a recursos de inferência visual. o1 junto com GPT-4o A diferença significativa entre oso1 Até mesmo as informações visuais mais desafiadoras, como gráficos e tabelas estruturados de forma complexa ou fotografias com qualidade de imagem ruim, podem ser tratadas com eficiência. Isso destaca a importância de o1 Vantagens exclusivas no campo do processamento de informações visuais.
A Safetykit, uma plataforma de monitoramento de comerciantes com IA, menciona: "A OpenAI tem o compromisso de automatizar as análises de risco e conformidade de milhões de produtos on-line, incluindo réplicas de joias de luxo, espécies ameaçadas de extinção e itens regulamentados. Na tarefa de classificação de imagens mais desafiadora da OpenAI, o modelo GPT-4o foi preciso apenas em 50%. e
o1O modelo atinge uma precisão impressionante de até 88% sem nenhuma modificação nos processos existentes da OpenAI."-Safetykit, plataforma de monitoramento de comerciantes com IA
Os próprios testes internos da OpenAI também mostraram queo1 Os modelos são capazes de identificar acessórios e materiais a partir de desenhos arquitetônicos altamente detalhados e gerar listas de materiais abrangentes. Um dos fenômenos mais surpreendentes observados pela OpenAI é que oo1 O modelo é capaz de fazer conexões entre diferentes imagens - por exemplo, ele pode pegar a legenda em uma página de um desenho arquitetônico e aplicá-la exatamente a outra página sem instruções explícitas. No exemplo abaixo, podemos ver que, para a "Coluna de madeira 4x4 PT", a legendao1 O modelo foi capaz de identificar corretamente que "PT" significava "pressure treated" (tratado sob pressão) com base na legenda. Essa é uma boa demonstração da o1 a potência do modelo na compreensão de informações visuais complexas e no raciocínio entre documentos.

6. revisão de código, depuração e aprimoramento da qualidade: busca pela excelência, otimização de código
Os modelos de inferência são excelentes na revisão e no aprimoramento do código e são particularmente bons para lidar com bases de código em grande escala. Dada a latência relativamente alta dos modelos de inferência, as tarefas de revisão de código geralmente são executadas em segundo plano. Isso sugere que, apesar da latência, os modelos de inferência têm aplicações importantes na análise de código e no controle de qualidade, especialmente em cenários que não exigem alto desempenho em tempo real.
A CodeRabbit, startup de revisão de código de IA, revela: "A OpenAI oferece serviços automatizados de revisão de código de IA em plataformas de hospedagem de código, como GitHub e GitLab. O processo de revisão de código é inerentemente insensível à latência, mas requer uma compreensão profunda das alterações de código em vários arquivos. É nesse ponto que o modelo o1 se destaca: ele detecta de forma confiável alterações sutis na base de código que podem ser facilmente ignoradas por um revisor humano. Depois de mudar para os modelos da série o, a OpenAI registrou um aumento de três vezes nas conversões de produtos."
-CodeRabbit, a startup de revisão de código de IA
mesmo que GPT-4o responder cantando GPT-4o mini pode ser mais adequado para cenários de codificação de baixa latência, mas a OpenAI também observa que o3-mini é excelente em casos de uso de geração de código insensível à latência. Isso significa que o modelo o3-mini Ele também tem potencial na área de geração de código, especialmente em cenários de aplicativos que exigem alta qualidade de código e são relativamente indulgentes com a latência.
Startups de preenchimento de código orientado por IA Códice comentou: "Mesmo diante de tarefas de codificação desafiadoras, a
o3-miniOs modelos também são capazes de gerar códigos conclusivos e de alta qualidade de forma consistente e, com muita frequência, fornecem a solução correta quando o problema é bem definido. Outros modelos podem ser adequados apenas para iterações de código pequenas e rápidas, mas oo3-miniOs modelos são especializados no planejamento e na execução de sistemas complexos de design de software."--Codeium, a startup de extensão de código orientada por IA
7. avaliação de modelos e benchmarking: avaliação objetiva e seleção do melhor dos melhores
A OpenAI também descobriu que os modelos de inferência tiveram um bom desempenho no benchmarking e na avaliação de outras respostas do modelo. A validação de dados é fundamental para garantir a qualidade e a confiabilidade dos conjuntos de dados, especialmente em áreas sensíveis como a saúde. Os métodos tradicionais de validação dependem de regras e padrões predefinidos, mas métodos como o1 responder cantando o3-mini Esses modelos avançados são capazes de entender o contexto e raciocinar sobre ele, possibilitando métodos de verificação mais flexíveis e inteligentes. Isso sugere que os modelos de inferência podem atuar como "árbitros" para avaliar a qualidade dos resultados de outros modelos, o que é fundamental para a otimização iterativa dos sistemas de IA.
Braintrust, a plataforma de avaliação de IA, observa: "Muitos clientes usam o recurso LLM como juiz na plataforma Braintrust como parte de seu processo de avaliação. Por exemplo, uma empresa de saúde pode usar uma ferramenta como
gpt-4oEsse modelo mestre para resumir o problema do histórico do paciente e, em seguida, usar oo1para avaliar a qualidade dos resumos. Um cliente da Braintrust descobriu que usar4oA pontuação F1 é de 0,12 quando o modelo é usado como árbitro, e a mudança para o modeloo1Após a modelagem, a pontuação F1 saltou para 0,74! Nesses casos de uso, eles descobriram queo1O poder de raciocínio do modelo é transformador na captura das nuances dos resultados finais, especialmente nas tarefas de pontuação mais difíceis e complexas."--Braintrust, uma plataforma de avaliação de IA
Dicas para solicitar modelos de raciocínio de forma eficaz: a simplicidade vem em primeiro lugar
Os modelos de raciocínio tendem a ter melhor desempenho quando recebem instruções claras e concisas. Algumas técnicas tradicionais de engenharia de dicas, como instruir o modelo a "pensar passo a passo", podem não ser eficazes para melhorar o desempenho e, às vezes, podem até ser contraproducentes. Aqui estão algumas práticas recomendadas, ou você pode simplesmente consultar os exemplos de dicas para começar.
- As mensagens do desenvolvedor substituem as mensagens do sistema. através de (uma lacuna)
o1-2024-12-17A partir da versão 2.0, o modelo de inferência começou a oferecer suporte a mensagens do desenvolvedor, em vez de mensagens tradicionais do sistema, para estar em conformidade com o comportamento da cadeia de instruções descrita na especificação do modelo. - Mantenha os avisos simples e diretos. Os modelos de raciocínio são bons em compreender e responder a instruções claras e concisas. Portanto, instruções claras e diretas são mais eficazes para modelos de raciocínio do que técnicas complexas de engenharia de dicas.
- Evitando cadeias de pensamento Dica. Não há necessidade de solicitar que o modelo de raciocínio "pense passo a passo" ou "explique seu processo de raciocínio", pois ele já possui recursos de raciocínio internamente. Essa solicitação redundante pode, em vez disso, degradar o desempenho do modelo.
- Use delimitadores para melhorar a clareza. O uso de separadores como Markdown, tags XML e títulos de seção para rotular claramente as diferentes partes da entrada ajuda o modelo a entender com precisão o conteúdo das diferentes seções.
- Priorizar as tentativas de pistas de amostra zero antes de considerar pistas de amostra menores: o Os modelos de inferência geralmente produzem bons resultados sem a necessidade de poucos exemplos de amostra. Portanto, é recomendável que você tente primeiro escrever dicas de amostra zero sem exemplos. Se você tiver requisitos mais complexos para os resultados de saída, pode ser útil incluir alguns exemplos de entradas e saídas desejadas em suas dicas. Entretanto, é importante garantir que os exemplos sejam altamente consistentes com as instruções do prompt, pois os desvios entre os dois podem levar a resultados ruins.
- Forneça orientações claras e específicas. Se houver restrições explícitas que possam limitar a gama de respostas do modelo (por exemplo, "Proponha uma solução com um orçamento inferior a US$ 500"), articule claramente essas restrições no prompt.
- Esclarecimento do objetivo final. Nas instruções, seja o mais específico possível ao descrever os critérios pelos quais as respostas bem-sucedidas serão julgadas e incentive o modelo a continuar raciocinando e repetindo até que seus critérios de sucesso sejam atendidos.
- Controle de formatação Markdown. através de (uma lacuna)
o1-2024-12-17A partir da versão 1, os modelos de inferência na API evitam gerar respostas com formatação Markdown por padrão. Se você quiser que o modelo inclua a formatação Markdown em suas respostas, adicione a stringFormatting re-enabled.
Exemplos de uso da API do modelo de inferência
Os modelos de raciocínio são únicos em seu processo de "pensamento". Diferentemente dos modelos de linguagem tradicionais, os modelos de inferência pensam profundamente internamente e constroem uma longa cadeia de raciocínio antes de dar uma resposta. Conforme consta na descrição oficial da OpenAI, esses modelos pensam profundamente antes de responder ao usuário. Esse mecanismo dá aos modelos de inferência a capacidade de se sobressair em tarefas como a resolução de quebra-cabeças complexos, codificação, raciocínio científico e planejamento de várias etapas para fluxos de trabalho de agentes.
Semelhante ao modelo GPT da OpenAI, a OpenAI oferece dois modelos de inferência para atender a diferentes necessidades:o3-mini O modelo se destaca por seu tamanho menor e velocidade mais rápida, enquanto o token Os custos também são relativamente baixos; e o1 Os modelos, por outro lado, trocam uma escala maior e uma velocidade um pouco mais lenta por uma solução de problemas mais eficiente.o1 Em geral, os modelos geram respostas de melhor qualidade ao lidar com tarefas complexas e apresentam melhor desempenho de generalização entre domínios.
Início rápido
Para ajudar os desenvolvedores a começar rapidamente, a OpenAI oferece uma interface de API fácil de usar. Aqui está um exemplo de início rápido de como usar o modelo de inferência em conclusões de bate-papo:
Uso de modelos de inferência em conclusões de bate-papo
import OpenAI from "openai";
const openai = new OpenAI();
const prompt = `
编写一个 bash 脚本,该脚本接收一个以字符串形式表示的矩阵,
格式为 '[1,2],[3,4],[5,6]',并以相同的格式打印转置矩阵。
`;
const completion = await openai.chat.completions.create({
model: "o3-mini",
reasoning_effort: "medium",
messages: [
{
role: "user",
content: prompt
}
],
});
console.log(completion.choices[0].message.content);
from openai import OpenAI
client = OpenAI();
prompt = """
编写一个 bash 脚本,该脚本接收一个以字符串形式表示的矩阵,
格式为 '[1,2],[3,4],[5,6]',并以相同的格式打印转置矩阵。
"""
response = client.chat.completions.create(
model="o3-mini",
reasoning_effort="medium",
messages=[
{
"role": "user",
"content": prompt
}
]
);
print(response.choices[0].message.content);
curl https://api.openai.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"model": "o3-mini",
"reasoning_effort": "medium",
"messages": [
{
"role": "user",
"content": "编写一个 bash 脚本,该脚本接收一个以字符串形式表示的矩阵,格式为 \"[1,2],[3,4],[5,6]\",并以相同的格式打印转置矩阵。"
}
]
}'
Intensidade do raciocínio: controle da profundidade do pensamento no modelo
No exemplo acima, oreasoning_effort O parâmetro (carinhosamente chamado de "suco" durante o desenvolvimento desses modelos) é usado para orientar o modelo quanto ao cálculo de inferência que ele executa antes de gerar uma resposta. O usuário pode especificar para esse parâmetro lowemedium talvez high Um dos três valores. Onde.low O modelo se concentra na velocidade e na redução dos custos de token, enquanto o high solicita um raciocínio mais profundo e abrangente do modelo, mas aumenta o consumo de tokens e o tempo de resposta. O valor padrão é definido como mediumO objetivo do sistema de inferência é alcançar um equilíbrio entre a velocidade e a precisão da inferência. Os desenvolvedores podem ajustar com flexibilidade a intensidade da inferência de acordo com as necessidades dos cenários de aplicativos reais para obter o desempenho ideal e a economia.
Como funciona o raciocínio: uma análise aprofundada do processo de "pensamento" dos modelos
O modelo de inferência se baseia nos tokens tradicionais de entrada e saída, introduzindo o Raciocínio sobre tokens Esse conceito. Esses tokens de inferência são análogos ao "processo de pensamento" do modelo, e o modelo os utiliza para decompor sua compreensão das dicas do usuário e para explorar vários caminhos possíveis para gerar respostas. Somente após a conclusão da geração de tokens de inferência, o modelo gera a resposta final, um token complementar visível para o usuário, e descarta o token de inferência do contexto.
A figura a seguir mostra um exemplo de diálogo em várias etapas entre um usuário e um assistente. Em cada etapa do diálogo, os tokens de entrada e saída são mantidos, enquanto os tokens de inferência são descartados pelo modelo.
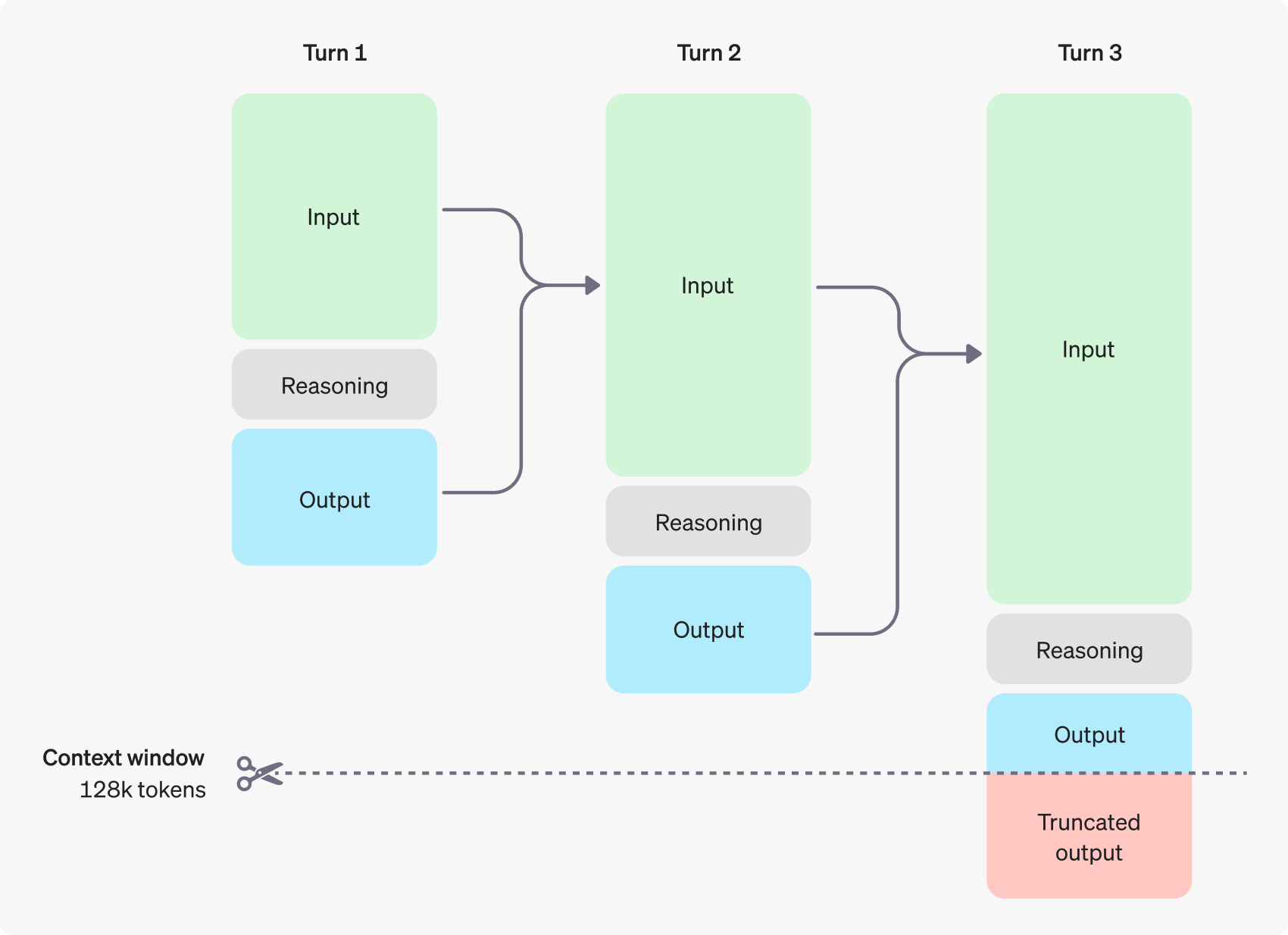
É importante observar que, embora os tokens de inferência não sejam visíveis por meio da interface da API, eles ainda ocupam o espaço da janela de contexto do modelo e contam para o uso total de tokens, e precisam ser pagos da mesma forma que os tokens de saída. Portanto, na prática, os desenvolvedores precisam considerar o impacto dos tokens de inferência e gerenciar adequadamente a janela de contexto do modelo e o consumo de tokens.
Gerenciamento de janelas contextuais: garantir que os modelos tenham bastante "espaço para pensar"
Ao criar uma solicitação de conclusão, é importante certificar-se de que a janela de contexto tenha espaço suficiente para os tokens de inferência gerados pelo modelo. Dependendo da complexidade do problema, o modelo pode precisar gerar de centenas a dezenas de milhares de tokens de inferência. completion_tokens_details para ver o número exato de tokens de inferência usados pelo modelo para uma solicitação específica:
{
"usage": {
"prompt_tokens": 9,
"completion_tokens": 12,
"total_tokens": 21,
"completion_tokens_details": {
"reasoning_tokens": 0,
"accepted_prediction_tokens": 0,
"rejected_prediction_tokens": 0
}
}
}
Os comprimentos da janela de contexto para diferentes modelos estão disponíveis para o usuário na página Referência do modelo. A avaliação e o gerenciamento adequados da janela de contexto são essenciais para garantir que o modelo de inferência funcione de forma eficaz.
Controle de custos: ajuste fino e otimização do consumo de tokens
Para gerenciar com eficiência o custo do modelo de inferência, os usuários podem usar a função max_completion_tokens parâmetro que limita o número total de tokens gerados pelo modelo, incluindo tokens de inferência e tokens complementares.
Nos modelos anteriores, omax_tokens O parâmetro controla tanto o número de tokens gerados pelo modelo quanto o número de tokens visíveis para o usuário, que são sempre os mesmos. No entanto, para modelos de inferência, o número total de tokens gerados pelo modelo pode exceder o número de tokens finalmente vistos pelo usuário devido à introdução de tokens de inferência interna.
Considere que alguns aplicativos podem depender de max_tokens é consistente com o número de tokens retornados pela API, a OpenAI introduziu um parâmetro especial max_completion_tokens para controlar de forma mais explícita o número total de tokens gerados pelo modelo, incluindo tokens de inferência e tokens de complemento visíveis pelo usuário. Essa configuração explícita de parâmetros garante uma transição suave para os aplicativos existentes que usam o novo modelo, evitando possíveis problemas de compatibilidade. Para todos os modelos anteriores, o parâmetromax_tokens A função do parâmetro permanece inalterada.
Dar espaço para o raciocínio: evitar interrupções para "pensar"
Se o número de tokens gerados atingir o limite da janela de contexto ou o limite definido pelo usuário max_completion_tokens a API retornará uma resposta de conclusão de bate-papo com o valor finish_reason O campo é definido como length. Isso pode ocorrer antes que o modelo gere tokens complementares visíveis ao usuário, o que significa que o usuário pode ter que pagar por tokens de entrada e tokens de inferência, mas não receber nenhuma resposta visível.
Para evitar isso, sempre verifique se a janela de contexto tem bastante espaço reservado ou coloque o max_completion_tokens O parâmetro openAI recomenda reservar espaço para pelo menos 25.000 tokens para os processos de inferência e saída ao experimentar esses modelos de inferência pela primeira vez. À medida que os usuários se familiarizam com o número de tokens de inferência necessários para seus prompts, esse tamanho de buffer pode ser ajustado conforme apropriado para um controle de custo mais granular.
Sugestão de dica: desbloquear o potencial dos modelos de raciocínio
Há algumas diferenças importantes das quais o usuário precisa estar ciente ao solicitar modelos de inferência e modelos GPT. De modo geral, o modelo de inferência tende a apresentar melhores resultados para tarefas em que apenas orientações de alto nível são fornecidas. Isso contrasta com o modelo GPT, que normalmente tem melhor desempenho quando são recebidas instruções muito precisas.
- Modelos de raciocínio como colegas seniores experientes -- Os usuários podem ser encarregados de resolver os detalhes específicos de forma autônoma, bastando dizer-lhes o que desejam alcançar.
- O modelo GPT é mais parecido com um assistente júnior -- Eles funcionam melhor quando têm instruções claras e detalhadas para criar resultados específicos.
Para saber mais sobre as práticas recomendadas para o uso de modelos de inferência, consulte o guia oficial da OpenAI.
Exemplo de dica: Demonstração do cenário do aplicativo
Codificação (refatoração de código)
Os modelos da série o da OpenAI demonstram recursos avançados de compreensão algorítmica e geração de código. O exemplo a seguir demonstra como o modelo o1 pode ser usado para refatorar critérios específicos Reagir Componente.
refatorar código
import OpenAI from "openai";
const openai = new OpenAI();
const prompt = `
指令:
- 给定以下 React 组件,修改它,使非小说类书籍显示红色文本。
- 回复中仅返回代码
- 不要包含任何额外的格式,例如 markdown 代码块
- 对于格式,使用四个空格缩进,并且不允许任何代码行超过 80 列
const books = [
{ title: 'Dune', category: 'fiction', id: 1 },
{ title: 'Frankenstein', category: 'fiction', id: 2 },
{ title: 'Moneyball', category: 'nonfiction', id: 3 },
];
export default function BookList() {
const listItems = books.map(book =>
<li>
{book.title}
</li>
);
return (
<ul>{listItems}</ul>
);
}
`.trim();
const completion = await openai.chat.completions.create({
model: "o3-mini",
messages: [
{
role: "user",
content: prompt,
},
],
});
console.log(completion.usage.completion_tokens_details);
from openai import OpenAI
client = OpenAI();
prompt = """
指令:
- 给定以下 React 组件,修改它,使非小说类书籍显示红色文本。
- 回复中仅返回代码
- 不要包含任何额外的格式,例如 markdown 代码块
- 对于格式,使用四个空格缩进,并且不允许任何代码行超过 80 列
const books = [
{ title: 'Dune', category: 'fiction', id: 1 },
{ title: 'Frankenstein', category: 'fiction', id: 2 },
{ title: 'Moneyball', category: 'nonfiction', id: 3 },
];
export default function BookList() {
const listItems = books.map(book =>
<li>
{book.title}
</li>
);
return (
<ul>{listItems}</ul>
);
}
"""
response = client.chat.completions.create(
model="o3-mini",
messages=[
{
"role": "user",
"content": prompt
}
]
);
print(response.choices[0].message.content);
Código (planejamento de projeto)
O modelo da série o da OpenAI também é bom para desenvolver planos de projeto de várias etapas. O exemplo a seguir mostra como usar o modelo o1 para criar uma estrutura completa de sistema de arquivos para um aplicativo Python e gerar código Python que implemente a funcionalidade necessária.
Planejar e criar um projeto Python
import OpenAI from "openai";
const openai = new OpenAI();
const prompt = `
我想构建一个 Python 应用程序,它可以接收用户的问题,并在数据库中查找答案。
数据库中存储了问题到答案的映射关系。如果找到密切匹配的问题,则检索匹配的答案。
如果没有找到,则要求用户提供答案,并将问题/答案对存储在数据库中。
为我创建一个目录结构计划,我需要这个结构,然后完整地返回每个文件中的代码。
只在开头和结尾提供你的推理过程,不要在代码中穿插推理。
`.trim();
const completion = await openai.chat.completions.create({
model: "o3-mini",
messages: [
{
role: "user",
content: prompt,
},
],
});
console.log(completion.usage.completion_tokens_details);
from openai import OpenAI
client = OpenAI();
prompt = """
我想构建一个 Python 应用程序,它可以接收用户的问题,并在数据库中查找答案。
数据库中存储了问题到答案的映射关系。如果找到密切匹配的问题,则检索匹配的答案。
如果没有找到,则要求用户提供答案,并将问题/答案对存储在数据库中。
为我创建一个目录结构计划,我需要这个结构,然后完整地返回每个文件中的代码。
只在开头和结尾提供你的推理过程,不要在代码中穿插推理。
"""
response = client.chat.completions.create(
model="o3-mini",
messages=[
{
"role": "user",
"content": prompt
}
]
);
print(response.choices[0].message.content);
Pesquisa STEM
Os modelos o-series da OpenAI demonstraram excelente desempenho em pesquisas STEM (Ciência, Tecnologia, Engenharia e Matemática). Esses modelos geralmente apresentam resultados impressionantes em solicitações criadas para dar suporte a tarefas básicas de pesquisa.
Levantamento de questões relacionadas à pesquisa em ciências básicas
import OpenAI from "openai";
const openai = new OpenAI();
const prompt = `
为了推进新型抗生素的研究,我们应该考虑研究哪三种化合物?
为什么我们应该考虑它们?
`;
const completion = await openai.chat.completions.create({
model: "o3-mini",
messages: [
{
role: "user",
content: prompt,
}
],
});
console.log(completion.choices[0].message.content);
from openai import OpenAI
client = OpenAI();
prompt = """
为了推进新型抗生素的研究,我们应该考虑研究哪三种化合物?
为什么我们应该考虑它们?
"""
response = client.chat.completions.create(
model="o3-mini",
messages=[
{
"role": "user",
"content": prompt
}
]
);
print(response.choices[0].message.content);
exemplo oficial
© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Artigos relacionados


Nenhum comentário...