
O que é quantificação de modelo: explicação dos tipos de dados FP32, FP16, INT8 e INT4
guia (por exemplo, livro ou outro material impresso)
No vasto céu estrelado da tecnologia de IA, os modelos de aprendizagem profunda impulsionam a inovação e o desenvolvimento em muitos campos com seu excelente desempenho. No entanto, a expansão contínua da escala do modelo é como uma faca de dois gumes, que traz um aumento acentuado na demanda aritmética e na pressão de armazenamento enquanto melhora o desempenho. Especialmente em cenários de aplicativos com recursos limitados, a implantação e a operação de modelos enfrentam sérios desafios.
Diante desse dilema, surgiu uma tecnologia chamada "quantização", que é como um bisturi delicado, reduz de forma inteligente o tamanho do modelo, melhora a velocidade de computação e reduz significativamente o consumo de energia dentro da faixa aceitável de precisão do modelo. A técnica de quantificação pode converter os dados FP32 de alta precisão do modelo em dados INT4 de baixa precisão, o que permite "emagrecer" e "acelerar" o modelo. Neste artigo, analisaremos os princípios e métodos de quantização e sua aplicação no campo da aprendizagem profunda, para que até mesmo os iniciantes possam entender facilmente sua essência.
1. fundamentos da representação numérica
1.1 Conversão de binário para decimal
Na ciência da computação, a pedra angular do mundo digital, todos os dados são armazenados em formato binário. O sistema binário consiste em apenas dois números, 0 e 1, enquanto o sistema decimal, que usamos em nosso dia a dia, tem dez números de 0 a 9. A conversão entre esses dois sistemas, assim como a tradução entre idiomas diferentes, é a chave para entender a representação dos dados nos computadores.
O número decimal 13, por exemplo, é convertido para a forma binária como 1101. O processo de conversão é semelhante à decomposição do "todo" decimal em seus "componentes" binários. As etapas são as seguintes:
13 Dividido por 2, o quociente é 6 e o restante é 1 (menor dígito binário)
6 dividido por 2 dá um quociente de 3 e um resto de 0.
3 dividido por 2, quociente 1, resto 1
1 dividido por 2, o quociente é 0, o resto é 1 (dígito binário mais alto)
Os resíduos são listados de baixo para cima:
↑1
↑0
↑1
↑1
Obter resultado binário: 1101
Por outro lado, converter o binário 1101 de volta para decimal é como remontar as "partes" para formar o "todo". Da direita para a esquerda, o peso de cada bit aumenta em potências de dois, com o bit mais à direita tendo um peso de , , e assim por diante para a esquerda. Portanto, o binário 1101 é convertido em decimal da seguinte forma: 1× + 1× + 0× + 1× = 8 + 4 + 0 + 1 = 13.
1.2 Diferença entre números de ponto flutuante e números inteiros
(i) Tipos de números inteiros (INT)
INT é uma abreviação de Integer, que representa o tipo de número inteiro. Os números inteiros, como o nome indica, são números que não contêm partes decimais, como 1, 2, 3 etc.
INT4 significa que um número binário de 4 bits é usado para representar um número inteiro, enquanto INT8 usa um número binário de 8 bits para representar um número inteiro. O número de bits determina o intervalo de representação de números inteiros.
O intervalo de números inteiros que podem ser representados pela INT4 é limitado, pois um número binário de 4 bits pode representar até um número diferente. Para a INT4 com sinal, o intervalo geralmente é de -8 a 7 e, para a INT4 sem sinal, o intervalo é de 0 a 15. O mesmo ocorre com a INT8, que varia de -128 a 127, e com a INT8 sem sinal, que varia de 0 a 255, já que um número binário de 8 bits pode representar 256 números diferentes.
(ii) Tipo de ponto flutuante (FP)
FP significa Floating Point, o tipo de ponto flutuante. Os números de ponto flutuante, ao contrário dos inteiros, são usados para representar números com partes fracionárias.
Um número de ponto flutuante consiste em um bit de sinal, um bit de expoente e um bit de mantissa. Um número de ponto flutuante de 32 bits (FP32), por exemplo, consiste em 1 bit de sinal, 8 bits de expoente e 23 bits de mantissa. Esse design inteligente permite que os números de ponto flutuante representem uma faixa extremamente ampla de valores, desde números muito pequenos até números muito grandes, como uma fita métrica.
Por exemplo, o FP32 pode representar números muito pequenos (aproximadamente) e muito grandes (aproximadamente). INT8 (números inteiros de 8 bits) só pode representar números inteiros entre -128 e 127. Essa diferença é análoga à medição de comprimento com uma régua de comprimento fixo (números inteiros) em comparação com uma fita métrica escalável (números de ponto flutuante), em que os números de ponto flutuante são muito superiores aos números inteiros em termos de flexibilidade e intervalo de representação numérica.
(iii) Tipos de dados comumente usados
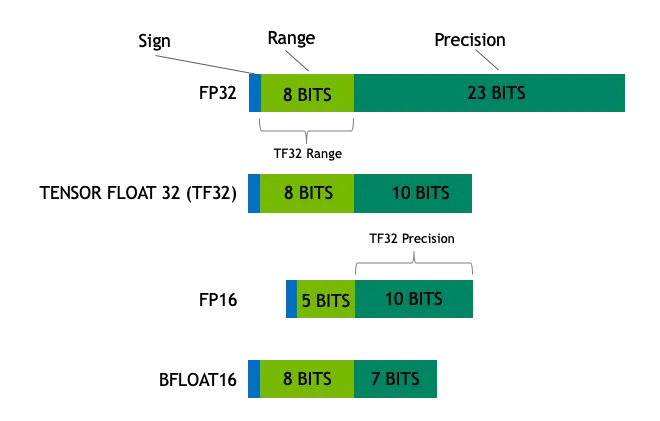
Os tipos de dados comuns na aprendizagem profunda e na computação de uso geral incluem:
- Float32 (FP32)FP32: Esse é o formato padrão de ponto flutuante de 32 bits, conhecido por sua alta precisão e ampla gama de valores. As operações de FP32 dominam o treinamento e a inferência de modelos devido à sua versatilidade, que é amplamente suportada por uma grande variedade de hardware.
- Float16 (FP16)FP16 é um número de ponto flutuante de meia precisão de 16 bits, que tem uma precisão reduzida em comparação com o FP32, mas tem um espaço de memória significativamente reduzido e uma velocidade de computação substancialmente mais rápida. No entanto, em práticas de aprendizagem profunda, comoDimensionamento de perdas A aplicação de técnicas como essas pode aliviar efetivamente esses problemas.
- BFloat16 (BF16)BF16: BF16 é outro formato de ponto flutuante de 16 bits. Ele é único no sentido de que o BF16 mantém o mesmo bit de expoente de 8 bits que o FP32 e, portanto, tem o mesmo intervalo dinâmico que o FP32; no entanto, o bit final é de apenas 7 bits, o que é menos preciso que o FP16. No entanto, o BF16 tem apenas 7 bits finais, o que é menos preciso do que o FP16. O BF16 tem bom desempenho em cenários com uma ampla faixa de valores, mas pode haver compensações em tarefas sensíveis à precisão.
- Int8A INT8 é usada principalmente em técnicas de quantificação de modelos, em que a conversão dos parâmetros do modelo de FP32 ou FP16 de alta precisão para INT8 reduz significativamente o requisito de espaço de armazenamento e a complexidade computacional do modelo, abrindo caminho para a implantação eficiente do modelo em dispositivos com recursos limitados.
2. conceitos quantitativos
2.1 Definições quantitativas
A quantificação refere-se à conversão de dados em um modelo de uma representação de alta precisão para uma representação de baixa precisão, como no caso doCompensações entre a qualidade da imagem e o tamanho do arquivoNa aprendizagem profunda, a quantização é o processo de compactação de uma imagem de alta precisão em uma imagem JPEG de baixa precisão, o que reduz significativamente o tamanho do arquivo e, ao mesmo tempo, mantém as principais informações da imagem. No campo da aprendizagem profunda, a quantização geralmente se refere à redução dos pesos do modelo e dos valores de ativação de FP32 (ponto flutuante de 32 bits) para FP16 (ponto flutuante de 16 bits) ou até mesmo INT8 (inteiro de 8 bits) ou precisão inferior.
O FP32 é um formato de ponto flutuante de alta precisão que representa com exatidão valores em binário de 32 bits (1 bit de sinal, 8 bits de expoente e 23 bits de mantissa). O FP32 é uma escala de precisão que pode medir valores pequenos a grandes, mas sua natureza de alta precisão vem com uma alta sobrecarga de armazenamento e uma velocidade de computação relativamente lenta.
O FP16 é um formato de ponto flutuante de meia precisão que requer apenas 16 bits binários (1 bit de sinal, 5 bits de expoente, 10 bits de mantissa) para representar um valor. Em comparação com o FP32, o FP16 sacrifica a precisão pela metade do espaço de armazenamento e melhora a eficiência computacional, e é como uma escala um pouco mais grossa, atingindo um bom equilíbrio entre precisão e eficiência.
INT8 é um tipo de número inteiro de 8 bits que só pode representar números inteiros no intervalo de -128 a 127. INT8 tem a vantagem de ocupar muito pouco espaço na memória e ter uma velocidade de computação muito alta, mas também tem a menor precisão numérica. INT8 é semelhante a um contador simples que só conta números inteiros, mas é rápido e conveniente.
2.2 Objetivo quantitativo
O objetivo central da quantificação éRedução dos requisitos de armazenamento e da complexidade computacional dos modelose, ao mesmo tempo, busca manter a perda de precisão dentro de limites aceitáveis. Especificamente, a quantificação visa atingir os seguintes objetivos:
Requisitos de armazenamento reduzidosModelos modernos de aprendizagem profunda, especialmente modelos grandes com tamanhos de parâmetros enormes, geralmente têm centenas de milhões ou até centenas de bilhões de parâmetros, o que exerce uma enorme pressão sobre o espaço de armazenamento. Tomando o modelo FP32 como exemplo, cada parâmetro ocupa 4 bytes de espaço de armazenamento. Se o modelo for quantificado para FP16, cada parâmetro exigirá apenas 2 bytes, reduzindo pela metade o requisito de armazenamento. Se o modelo for ainda mais quantificado para INT8, cada parâmetro precisará de apenas 1 byte, e o espaço de armazenamento poderá ser reduzido em 75%.
Aprimoramento da eficiência computacionalO modelo quantificado é significativamente menos intensivo em termos de computação na fase de inferência, o que resulta em um aumento na velocidade de inferência. Por exemplo, quando o modelo FP32 é executado na GPU, a velocidade de computação pode ser limitada pela largura de banda da memória. Por outro lado, nos modelos FP16 ou INT8, graças à aceleração otimizada do hardware para computação de baixa precisão, a velocidade de computação pode ser significativamente aumentada. A melhoria de desempenho proporcionada pela quantização é especialmente significativa em cenários em que os recursos de computação são limitados, como dispositivos de borda ou dispositivos móveis.
reduzir o consumo de energiaA redução nos requisitos de recursos de computação do modelo se traduz diretamente em uma redução no consumo de energia. Para dispositivos móveis e sistemas incorporados, o consumo de energia é uma consideração fundamental. As técnicas de quantificação podem reduzir efetivamente o consumo de energia do modelo, aumentar a vida útil do dispositivo e reduzir os requisitos de dissipação de calor.
Redução dos requisitos de largura de bandaDescrição: em sistemas de computação distribuída, a redução do tamanho do modelo também significa a redução da largura de banda de transmissão de dados. Em um cenário com vários servidores, os modelos quantitativos podem ser distribuídos e sincronizados em uma taxa mais rápida, melhorando assim a eficiência geral da transferência de dados.
3. INT4, INT8 Quantificação
3.1 Intervalo de representação de INT4 e INT8
INT4 e INT8 são métodos de quantificação do tipo inteiro que armazenam dados em formato binário em sistemas de computador, mas diferem no intervalo e na precisão da representação numérica.
- INT8INT8 é um tipo de número inteiro de 8 bits com um intervalo de -128 a 127. Ele pode ser comparado a um contador de 8 bits, em que cada bit pode ser 0 ou 1, e diferentes valores inteiros podem ser representados por diferentes combinações de 0/1. Por exemplo, noanotado INT8 significa médio, variando de -128 a 127, e 11111111 em binário significa -1 em decimal. Se forsem sinal (ou seja, o valor absoluto, independentemente do sinal de mais ou menos) A INT8, que varia de 0 a 255, caso em que 11111111 representa 255 em decimal, é suficiente para atender às necessidades de muitos cenários de aplicativos, como os valores de pixel no processamento de imagens, que geralmente estão no intervalo de 0 a 255 e podem ser representados com eficiência pela INT8.
- INT4A INT4 é um tipo de número inteiro de 4 bits com um intervalo de representação de -8 a 7 menor do que a INT8. A INT4 sacrifica o intervalo numérico para reduzir o espaço de armazenamento e acelerar a computação. A INT4 é como um contador menor, com um intervalo numérico limitado, mas com um "espaço" menor, o que é mais eficiente em termos de recursos. Ela é mais eficiente em termos de recursos. Em alguns cenários de aplicativos com requisitos de precisão relativamente frouxos, como algumas camadas de redes neurais leves, o uso da quantificação INT4 pode reduzir significativamente os custos de armazenamento e computação.Por exemplo, ao implantar um modelo de classificação de imagem leve em um dispositivo móvel, os parâmetros do modelo e os resultados de computação intermediários podem ser armazenados e computados usando o formato INT4 para reduzir o espaço de memória e acelerar a inferência.
3.2 Fórmulas quantitativas e exemplos
O processo de quantização é essencialmente a conversão de um mapa numérico de ponto flutuante de alta precisão em um inteiro de baixa precisão. Tomando como exemplo a quantificação de FP32 para INT8, a fórmula de quantificação é a seguinte:
é o número de ponto flutuante original.
é um número inteiro quantificado.
é o fator de escala, usado para mapear números de ponto flutuante para intervalos de inteiros.
Indica o arredondamento para o número inteiro mais próximo.
Indica que o resultado está limitado ao intervalo de INT8, ou seja, [-128, 127].
Cálculo do fator de escala
O fator de escala geralmente é calculado como o máximo do valor absoluto do número de ponto flutuante. Supondo que haja um conjunto de números de ponto flutuante, o procedimento é o seguinte:
- Encontre o valor absoluto máximo do grupo de números de ponto flutuante:
- Calcule o fator de escala: .
Na prática, há várias maneiras de calcular o fator de escala, como Max Quantization, Mean-Std Quantization e assim por diante. A Max Quantization usa o valor absoluto máximo do tensor para calcular o fator de escala, que é simples de implementar, mas pode ser sensível a valores discrepantes. A Quantização Média-Std usa as informações de média e desvio padrão dos dados para determinar o fator de escala de forma mais robusta, mas a complexidade computacional é um pouco maior. A escolha do método adequado de cálculo do fator de escala requer uma compensação entre a precisão e a sobrecarga computacional.
exemplo típico
Supondo que tenhamos um conjunto de números de ponto flutuante [-0,5, 0,3, 1,2, -2,1], apresentamos a seguir uma demonstração passo a passo do processo de quantificação:
1) Calcule o valor absoluto máximo:
2. cálculo do fator de escala:
3. quantificar cada número de ponto flutuante:
- Para -0,5.
- Para 0,3.
- Para 1.2.
- Para -2.1.
A representação INT8 final e quantificada é [-1, 1, 4, -7].
Por meio das etapas acima, podemos ver claramente como a técnica de quantização converte números de ponto flutuante em números inteiros. Embora o processo de quantização inevitavelmente introduza uma certa perda de precisão, ao escolher o fator de escala com sabedoria, o nível de desempenho do modelo pode ser mantido ao máximo e, ao mesmo tempo, reduzir significativamente os custos de armazenamento e computação. Para reduzir ainda mais os erros de quantificação, a quantificação de ponto zero também pode ser introduzida. A quantificação de ponto zero adiciona um deslocamento de ponto zero à fórmula de quantificação, o que permite que os zeros de ponto flutuante sejam mapeados com precisão para zeros inteiros, melhorando assim a precisão da quantificação, especialmente se houver um grande número de zeros nos valores de ativação.
4. quantificação de FP8, FP16, FP32
4.1 Representações de FP8, FP16 e FP32
FP8, FP16 e FP32 são números de ponto flutuante que são armazenados em formato binário no computador, mas com diferentes larguras de bits e, portanto, diferentes intervalos e precisão.
FP32
O FP32, como um formato padrão de ponto flutuante de 32 bits, consiste nas três partes a seguir:
- Bit de sinal (1 bit)Valor de referência: Usado para identificar valores positivos e negativos, com 0 representando um número positivo e 1 representando um número negativo.
- Dígitos exponenciais (8 dígitos)é usado para definir o intervalo de tamanho de um valor, permitindo que o FP32 represente valores de muito pequenos a muito grandes.
- Último dígito (23 bits)Dígitos finais: Usados para determinar a precisão de um valor; quanto mais dígitos finais, maior a precisão.
Com uma ampla faixa de valores de aproximadamente a , e uma precisão de aproximadamente 6 casas decimais, o FP32 é como uma fita métrica de alta precisão que pode medir escalas tão pequenas quanto um grão de poeira e distâncias tão grandes quanto uma montanha. O FP32 é um tipo de dados indispensável em computação científica, modelagem financeira e outros campos que exigem um alto grau de precisão.
FP16

O FP16 é um formato de ponto flutuante de meia precisão que ocupa apenas 16 bits de memória, metade do tamanho do FP32:
- Bit de sinal (1 bit)Identificação de valores positivos e negativos: Identifica valores positivos e negativos.
- Dígito exponencial (5 dígitos)Define um intervalo de tamanhos de valores.
- Último dígito (10 dígitos)Determinação da precisão numérica: Determina a precisão numérica.
O intervalo do FP16 é de cerca de a e a precisão é reduzida para cerca de 3 casas decimais em comparação com o FP32. O FP16 é como uma régua com uma escala um pouco mais grossa, que tem uma precisão menor, mas tem mais vantagens em termos de espaço de armazenamento e eficiência computacional. O FP16 é comumente usado para treinamento e inferência de modelos de aprendizagem profunda, o que exige alta velocidade computacional e largura de banda de memória. Especialmente em cenários acelerados por GPU, o FP16 pode fazer uso total das unidades de aceleração de hardware, como o Tensor Core, para obter melhorias significativas no desempenho.
FP8
O FP8 é um formato emergente de número de ponto flutuante de baixa precisão, usado principalmente no campo da aprendizagem profunda, visando à computação eficiente:
- Bit de sinal (1 bit)Identificação de valores positivos e negativos: Identifica valores positivos e negativos.
- Dígitos exponenciais (3 ou 4 dígitos)Tamanho do valor: defina um intervalo de tamanhos de valores (existem duas variantes de FP8).
- Último dígito (4 ou 3 dígitos)Precisão numérica: determina a precisão numérica (corresponde ao número de dígitos do índice).
O alcance e a precisão da representação numérica do FP8 são ainda mais reduzidos, mas as vantagens são um espaço de memória menor e velocidades de computação mais rápidas. Se o FP32 for uma fita métrica de precisão e o FP16 for uma régua com uma escala um pouco mais grossa, o FP8 será uma fita métrica mais precisa. É como uma régua simples com uma escala de centímetros.Além disso, o alcance e a precisão são ainda mais reduzidos, mas a tarefa de medição ainda pode ser feita rapidamente em uma determinada situação. Como um tipo de dados de precisão extremamente baixa, o FP8 apresenta grande potencial em cenários com requisitos extremos de latência e taxa de transferência, como inferência em tempo real, computação de ponta etc. No entanto, o FP8 também exige mais do hardware e dos algoritmos. No entanto, a aplicação do FP8 também impõe maiores exigências ao hardware e aos algoritmos, exigindo suporte especial de hardware e estratégias de quantização para garantir a precisão.
4.2 Processo de quantificação e fórmulas
A quantização é o processo de conversão de um número de ponto flutuante de alta precisão em um número de ponto flutuante de baixa precisão ou em um número inteiro. Tomando como exemplo a quantificação de FP32 para FP16, a fórmula de quantificação é a seguinte:
é o número de ponto flutuante original.
é um número de ponto flutuante de baixa precisão quantificado.
é o fator de escala, usado para mapear números de ponto flutuante para intervalos de precisão mais baixos.
Indica o arredondamento para o valor mais próximo.
Cálculo do fator de escala
O fator de escala geralmente é calculado como o máximo do valor absoluto do número de ponto flutuante. Supondo que haja um conjunto de números de ponto flutuante, o procedimento é o seguinte:
- Encontre o valor absoluto máximo do grupo de números de ponto flutuante:
- Calcule o fator de escala: , onde é o máximo do formato de baixa precisão de destinoPode ser expresso como um valor absoluto. Para FP16, esse valor é de aproximadamente 65504.
Semelhante à quantificação INT8, os fatores de escala na quantificação FP16 podem ser calculados de várias maneiras, que podem ser escolhidas de acordo com diferentes requisitos de precisão e desempenho. Além disso, a quantificação do FP16 é frequentemente usada em conjunto com o MPT (Mixed Precision Training, treinamento de precisão mista). Durante o processo de treinamento do modelo, o FP16 é usado para algumas operações de computação intensiva (por exemplo, multiplicação de matriz, convolução), enquanto o FP32 é usado para operações que exigem maior precisão (por exemplo, cálculo de perda, atualização de gradiente), de modo a acelerar o processo de treinamento e reduzir o consumo de memória, garantindo a precisão do modelo.
exemplo típico
Supondo que tenhamos um conjunto de números de ponto flutuante FP32 [-0,5, 0,3, 1,2, -2,1], apresentamos a seguir uma demonstração passo a passo da quantização de FP32 para FP16:
1) Calcule o valor absoluto máximo:
2. cálculo do fator de escala:
3. quantificar cada número de ponto flutuante:
- Para -0,5.
- Para 0,3.
- Para 1.2.
- Para -2.1.
O FP16 final e quantificado é expresso como [-0,5, 0,3, 1,2, -2,1].
Por meio das etapas acima, é possível observar como as técnicas de quantização convertem números de ponto flutuante de alta precisão em números de ponto flutuante de baixa precisão. A quantização certamente traz alguma perda de precisão, mas, ao escolher o fator de escala com sabedoria, o desempenho do modelo pode ser mantido o máximo possível, reduzindo o custo de armazenamento e computação. Para melhorar ainda mais a precisão da quantificação do FP16, a Quantização dinâmica pode ser usada. A quantização dinâmica ajusta dinamicamente o fator de escala de acordo com o intervalo real dos dados de entrada durante o processo de inferência, de modo a se adaptar melhor às alterações na distribuição de dados e reduzir o erro de quantização.
5. aplicações quantitativas e vantagens
5.1 Aplicativos em aprendizagem profunda
As técnicas quantitativas têm uma ampla gama de aplicações promissoras na aprendizagem profunda, especialmente nas fases de treinamento e inferência de modelos, onde são cada vez mais valiosas. Veja a seguir algumas das principais aplicações das técnicas de quantificação na aprendizagem profunda:
Aceleração do treinamento de modelos
Durante a fase de treinamento do modelo, a computação com tipos de dados de baixa precisão, como FP16 ou FP8, pode acelerar significativamente o processo de treinamento. Por exemplo, as GPUs da arquitetura NVIDIA Hopper suportam operações do Tensor Core com precisão FP8. O treinamento em FP8 pode ser de 2 a 3 vezes mais rápido do que o treinamento tradicional em FP32. Essa aceleração do treinamento é especialmente importante para modelos com grandes tamanhos de parâmetros, reduzindo significativamente o tempo de treinamento e o consumo de recursos computacionais. Por exemplo, ao treinar modelos de linguagem em grande escala, como o GPT-3, o uso do treinamento de precisão mista FP16 ou BF16 pode reduzir significativamente o tempo de treinamento e economizar muitos recursos computacionais.
para IA de inflexão O Inflection-2, por exemplo, foi treinado em 5.000 GPUs da arquitetura NVIDIA Hopper usando uma estratégia de treinamento de precisão mista FP8, totalizando FLOPs de operações de ponto flutuante e, em vários benchmarks de desempenho de IA padrão, o Inflection-2 demonstrou uma vantagem de desempenho superior em relação ao modelo PaLM 2, carro-chefe do Google, que também pertence à categoria de computação de treinamento. Em vários benchmarks de desempenho de IA padrão, o Inflection-2 demonstrou uma vantagem significativa de desempenho em relação ao principal modelo do Google, o PaLM 2, na mesma categoria de computação de treinamento.
Otimização da inferência de modelos
No estágio de inferência do modelo, as técnicas de quantificação podem reduzir significativamente os requisitos de armazenamento e a complexidade computacional do modelo e, assim, melhorar a eficiência da inferência. Por exemplo, ao quantificar um modelo FP32 para INT8, o espaço de armazenamento do modelo pode ser reduzido em 75% e a velocidade de inferência pode ser aumentada em várias vezes. Isso é fundamental para a implantação de modelos de aprendizagem profunda em dispositivos móveis ou de borda, que geralmente são desafiados por recursos de computação e espaço de armazenamento limitados. Por exemplo, ao implantar modelos de reconhecimento de imagem em telefones celulares, a quantificação do modelo como INT8 pode reduzir efetivamente o tamanho do modelo, reduzir o consumo de memória, acelerar a velocidade de inferência e melhorar a experiência do usuário.
Por exemplo, o Google trabalhou em estreita colaboração com a equipe da NVIDIA para aplicar a técnica de otimização TensorRT-LLM ao modelo Gemma e combinou-a com a tecnologia FP8 para obter a aceleração da inferência. Os resultados experimentais mostram que o FP8 alcança uma melhoria de mais de três vezes na taxa de transferência em comparação com o FP16 ao usar GPUs Hopper para inferência.
Compressão e implantação de modelos
As técnicas de quantificação também podem ser usadas para compactação e implantação de modelos. Ao quantificar modelos de alta precisão em modelos de baixa precisão, o tamanho do modelo pode ser reduzido de forma eficaz, o que permite a implantação de modelos em ambientes com recursos limitados. Por exemplo, zero-um-tudoUtilizar A pilha combinada de tecnologia de hardware e software da NVIDIA concluiu o treinamento e a validação do modelo FP8 de grande porte, com um aumento de 1,3x na taxa de transferência de treinamento de modelo de grande porte em comparação com o BF16. Além da quantificação INT8 e FP16/FP8, há também INT4 e técnicas de quantificação de bits ainda menores, como a Rede Neural Binária (BNN) e a Rede Neural Ternária (TNN). Essas técnicas de quantização de bits muito baixos podem comprimir o modelo ao extremo, mas geralmente com uma grande perda de precisão, e são adequadas para cenários com requisitos extremos de tamanho e velocidade do modelo.
Além disso, o modelo quantificado pode ser aprimorado ainda mais com a ajuda de técnicas específicas de aceleração de hardware. Por exemplo, a NVIDIA Transformador O mecanismo foi integrado às principais estruturas de aprendizagem profunda, como PyTorch, JAX, PaddlePaddle, etc., fornecendo suporte eficiente em nível de hardware para inferência de modelos quantitativos. Além das GPUs NVIDIA, outras plataformas de hardware, como CPUs de arquitetura ARM e NPUs móveis, também são otimizadas e aceleradas para computação quantitativa, fornecendo uma base de hardware para a implantação generalizada de modelos quantitativos.
5.2 Pontos fortes e limitações
de ponta
Melhoria da eficiência computacionalA quantificação de baixa precisão pode acelerar significativamente a computação e reduzir o consumo de recursos computacionais. Tanto o FP16 quanto o FP8 têm um rendimento computacional várias vezes maior do que o FP32. Esse efeito de aceleração é particularmente significativo no treinamento e na inferência de modelos em grande escala.
Menores requisitos de armazenamentoAs técnicas de quantificação podem reduzir significativamente os requisitos de armazenamento do modelo. Por exemplo, a quantificação de um modelo FP32 para INT8 reduz o espaço de armazenamento em 75%, o que é importante para a implantação de modelos em ambientes com recursos de armazenamento limitados.
Redução do consumo de energiaDescrição: A computação de baixa precisão requer menos recursos computacionais, o que reduz o consumo de energia do dispositivo. Em dispositivos móveis e sistemas incorporados, o consumo de energia é uma das principais considerações de projeto. Os modelos quantificados ajudam a aumentar a vida útil da bateria do dispositivo e a reduzir os requisitos de dissipação de calor.
Otimização de modelosAs técnicas de quantificação impulsionam a otimização e a compactação do modelo durante o treinamento e a inferência, reduzindo ainda mais os custos de implantação. Por exemplo, a aplicação do FP8 permite que os modelos explorem estratégias de quantificação mais refinadas durante a fase de treinamento, melhorando assim a eficiência geral do modelo.
limitações
Perda de precisãoDescrição: o processo de quantificação é inevitavelmente acompanhado por uma perda de precisão, que pode ser significativa, especialmente quando são usados formatos de precisão muito baixa (por exemplo, FP8), e pode levar à degradação do desempenho do modelo em uma determinada tarefa. Embora a perda de precisão possa ser atenuada até certo ponto, por exemplo, por meio de uma escolha cuidadosa dos fatores de escala, a eliminação completa da perda de precisão geralmente é difícil de ser alcançada. Para atenuar a perda de precisão causada pela quantização, o treinamento com reconhecimento de quantização (QAT) pode ser usado. O QAT simula a operação de quantização durante o processo de treinamento do modelo e leva em conta o erro de quantização no treinamento, de modo a treinar um modelo que seja mais robusto à quantização. Em geral, o QAT pode melhorar significativamente a precisão dos modelos de quantização, mas o custo do treinamento aumentará proporcionalmente.
Suporte de hardware: Nem todas as plataformas de hardware suportam totalmente a computação de baixa precisão. Por exemplo, os cálculos FP8 e FP16 geralmente exigem hardware específico (por exemplo, GPUs de arquitetura NVIDIA Hopper). Se a plataforma de hardware não for otimizada para computação de baixa precisão, os benefícios da quantização não serão totalmente explorados. Com a popularidade da computação de baixa precisão, cada vez mais plataformas de hardware começam a oferecer suporte a tipos de dados de baixa precisão, como FP16, BF16 e até mesmo FP8, o que proporciona uma base de hardware mais sólida para a ampla aplicação de técnicas de quantificação.
Maior complexidade: o próprio processo de quantificação pode aumentar a complexidade do desenvolvimento do modelo. Por exemplo, o processo de quantificação exige o cálculo refinado de fatores de escala e pode exigir calibração adicional e ajuste fino do modelo. Isso definitivamente aumenta a dificuldade de desenvolvimento e implantação do modelo. Para reduzir a complexidade da implantação da quantificação, surgiram no setor muitas ferramentas e plataformas de quantificação automatizadas, como NVIDIA TensorRT, Qualcomm AI Engine etc., que ajudam os desenvolvedores a quantificar e implantar modelos de forma rápida e fácil em plataformas de hardware de destino.
cenário do aplicativo: As técnicas de quantização não são adequadas em todos os cenários de aplicação. Em tarefas que exigem precisão muito alta (por exemplo, computação científica, modelagem financeira etc.), a quantização pode levar a uma perda inaceitável de precisão. Para tarefas sensíveis à precisão, pode-se tentar uma estratégia de quantificação de precisão mista, em que diferentes precisões de quantificação são aplicadas a diferentes camadas ou parâmetros no modelo, por exemplo, FP32 ou FP16 para camadas ou parâmetros importantes e INT8 ou inferior para outras camadas ou parâmetros, a fim de obter um melhor equilíbrio entre precisão e eficiência.
Em resumo, as técnicas de quantificação, como uma tecnologia fundamental no campo da aprendizagem profunda, apresentam grande potencial para melhorar a eficiência computacional, reduzir os requisitos de armazenamento e o consumo de energia. No entanto, as técnicas de quantificação também têm limitações, como perda de precisão e dependência de hardware. Portanto, em aplicações práticas, as estratégias de quantização devem ser cuidadosamente selecionadas de acordo com os requisitos específicos do aplicativo e as características do cenário, a fim de obter um equilíbrio ideal entre o desempenho e a eficiência do modelo. No futuro, com o desenvolvimento contínuo de hardware e algoritmos, a tecnologia quantitativa desempenhará um papel mais importante no campo da aprendizagem profunda e promoverá o enraizamento da aplicação da inteligência artificial em uma variedade maior de cenários.
© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Publicações relacionadas




Nenhum comentário...