Avaliação do uso de modelos de inferência em sistemas RAG modulares
Neste artigo, apresentamos o trabalho recente da Kapa.ai no sistema Retrieval-Augmented Generation (RAG) da OpenAI no contexto da o3-mini Um relatório resumido da exploração do modelo etimológico de raciocínio.

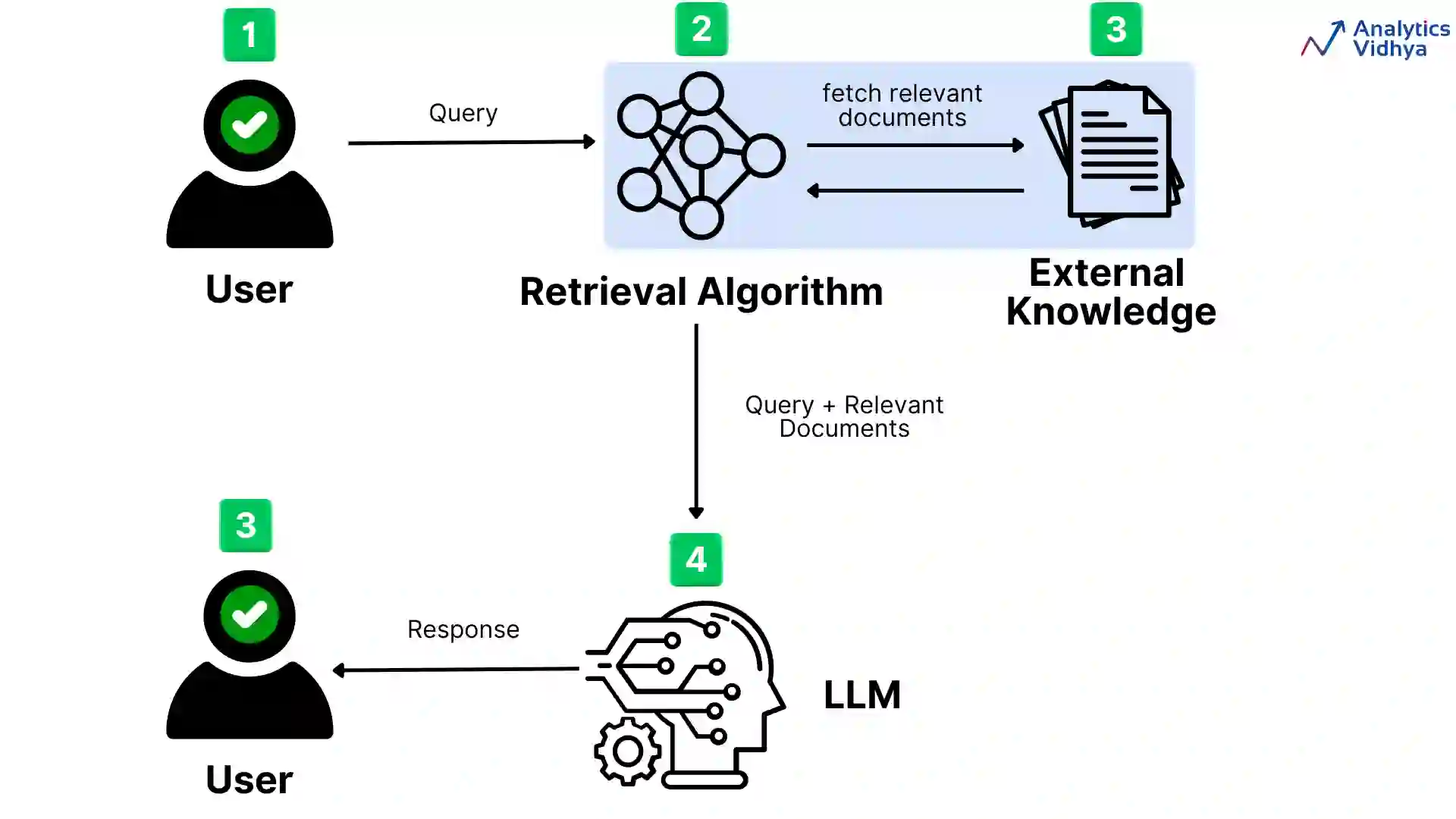
O Kapa.ai é um assistente de IA com base em um modelo de linguagem em grande escala (LLM) que RAG O processo é integrado à base de conhecimento para que as perguntas técnicas dos usuários possam ser respondidas e as ordens de serviço de suporte técnico possam ser processadas.
Criar e manter um sistema RAG estável e versátil não é uma tarefa fácil. Muitos parâmetros e configurações afetam a qualidade do resultado final, e há interações complexas entre esses fatores:
- Modelos de palavras de taco
- Tamanho do contexto
- Extensão de consulta
- pedaço
- reordenar
- Espere um pouco!
Ao fazer ajustes em um sistema RAG, especialmente ao integrar novos modelos, revisitar e otimizar esses parâmetros é essencial para manter o bom desempenho. No entanto, essa tarefa não é apenas demorada, mas também requer muita experiência para ser bem executada.
assemelhar-se DeepSeek-R1 Novos modelos de raciocínio, como o o3-mini da OpenAI, alcançaram resultados impressionantes ao usar prompts de Cadeia de Pensamento (CoT) incorporados para "pensar" sobre um problema, raciocinar passo a passo e até mesmo se autocorrigir quando necessário. Segundo informações, os modelos apresentam melhor desempenho em tarefas complexas que exigem raciocínio lógico e respostas verificáveis. Leitura relacionada:DeepSeek R1 no RAG: um resumo da experiência prática eOs resultados da geração de código em nível de projeto foram divulgados! o3/Claude 3.7 lidera o caminho, R1 está no nível superior!
Portanto, a Kapa.ai propõe uma ideia: se os modelos de inferência podem decompor problemas complexos e se autocorrigir, eles poderiam ser aplicados aos processos RAG para lidar com tarefas como expansão de consultas, recuperação de documentos e reordenação? Ao criar um kit de ferramentas de recuperação de informações e entregá-lo aos modelos de inferência, talvez seja possível criar um sistema mais adaptável que reduza a necessidade de ajuste manual dos parâmetros.
Esse paradigma às vezes é chamado de Geração Modular de Recuperação-Aumentada (Modular Retrieval-Augmented Generation, RAG). Neste documento, compartilhamos os resultados recentes da pesquisa da Kapa.ai sobre a refatoração do processo RAG padrão em um processo baseado em modelo de inferência.
suponha que...
O principal objetivo da Kapa.ai ao explorar essa ideia é simplificar o processo do RAG e reduzir a dependência do ajuste fino manual dos parâmetros. Os principais componentes do processo do RAG são a incorporação densa e a recuperação de documentos. Um processo típico de alto nível do RAG é o seguinte:
- Receber avisos do usuário.
- Pré-processamento de consultas para melhorar a recuperação de informações.
- Os documentos relevantes são encontrados por meio de pesquisas de similaridade em bancos de dados vetoriais.
- Reordene os resultados e use os documentos mais relevantes.
- Gerar uma resposta.

Cada etapa do processo é otimizada por meio de heurística, como regras de filtragem e ajustes de classificação para priorizar dados relevantes. Essas otimizações codificadas definem o comportamento do processo, mas também limitam sua adaptabilidade.
Para que o modelo de inferência utilizasse os vários componentes do processo RAG, o Kapa.ai precisava configurar o sistema de forma diferente. Em vez de definir uma sequência linear de etapas, cada componente é tratado como um módulo separado para o modelo chamar.

Nessa arquitetura, em vez de seguir um processo fixo, os modelos com recursos de raciocínio podem controlar seu próprio fluxo de trabalho com um grau maior de dinamismo. Ao utilizar ferramentas, os modelos podem decidir quando e com que frequência executar pesquisas completas ou simplificadas e quais parâmetros de pesquisa usar. Se for bem-sucedida, essa abordagem poderá substituir as estruturas tradicionais de orquestração de RAG, como o LangGraph.
Além disso, um sistema mais modular oferece alguns benefícios adicionais:
- Os módulos individuais podem ser substituídos ou atualizados sem a necessidade de renovar completamente todo o processo.
- A segregação mais clara de funções facilita o gerenciamento da depuração e dos testes.
- Diferentes módulos (por exemplo, recuperadores com diferentes embeddings) podem ser testados e substituídos para comparar o desempenho.
- Os módulos podem ser estendidos de forma independente para diferentes fontes de dados.
- Isso poderia permitir que a Kapa.ai criasse diferentes módulos personalizados para tarefas ou domínios específicos.
Por fim, a Kapa.ai também quer explorar se essa abordagem pode ajudar a "contornar" consultas abusivas ou fora do tópico de forma mais eficaz. Os casos mais difíceis geralmente envolvem ambiguidade, ou seja, não está claro se a consulta é relevante para o produto. As consultas abusivas geralmente são projetadas deliberadamente para evitar a detecção. Embora os casos mais simples já possam ser tratados de forma eficaz, a Kapa.ai espera que o modelo de inferência ajude a identificar e solucionar problemas mais complexos mais cedo.
configuração de teste
Para experimentar esse fluxo de trabalho, a Kapa.ai criou um sistema RAG em área restrita que contém os componentes necessários, dados estáticos e um conjunto de avaliação com o LLM como árbitro. Em uma configuração, a Kapa.ai usou um processo linear fixo típico com otimizações codificadas incorporadas.
Para o processo modular RAG, o Kapa.ai usou o modelo o3-mini como um modelo de inferência e executou várias configurações do processo sob diferentes políticas para avaliar quais abordagens funcionaram e quais não funcionaram:
- Uso de ferramentas: O Kapa.ai tenta dar ao modelo acesso total a todas as ferramentas e a todo o processo, e também tenta limitar o uso da ferramenta a uma combinação de uma única ferramenta com um processo linear fixo.
- Dicas e parametrização: A Kapa.ai testou tanto dicas abertas, usando instruções mínimas, quanto dicas altamente estruturadas. A Kapa.ai também experimentou vários graus de chamadas de ferramentas pré-parametrizadas, em vez de deixar o modelo determinar seus próprios parâmetros.
Em todos os testes conduzidos pela Kapa.ai, o número de chamadas de ferramentas foi limitado a um máximo de 20 - para qualquer consulta, o modelo só permite o uso de um máximo de 20 chamadas de ferramentas:
- Médio: Etapas mais curtas da CoT (cadeia de pensamento)
- Mais alto: Etapas de CoT mais longas com raciocínio mais detalhado
No total, a Kapa.ai realizou 58 avaliações de diferentes configurações modulares de RAGs.
no final
Os resultados dos experimentos foram mistos. Em algumas configurações, a Kapa.ai observou algumas melhorias modestas, principalmente na geração de código e, em uma extensão limitada, na fatoração. No entanto, as principais métricas, como a qualidade da recuperação de informações e a extração de conhecimento, permaneceram praticamente inalteradas em comparação com o fluxo de trabalho tradicional ajustado manualmente da Kapa.ai.
Um problema recorrente em todo o processo de teste é que o raciocínio da Cadeia de Pensamento (CoT) aumenta a latência. Embora o raciocínio mais aprofundado permita que o modelo decomponha consultas complexas e se autocorrija, isso tem o custo do tempo adicional necessário para chamadas iterativas de ferramentas.
O maior desafio identificado pela Kapa.ai é a "falácia da inferência ≠ experiência": o modelo de inferência, apesar de ser capaz de pensar passo a passo, não tem experiência a priori com ferramentas de recuperação. Mesmo com dicas rigorosas, ele teve dificuldades para obter resultados de alta qualidade e distinguir entre resultados bons e ruins. O modelo muitas vezes hesitava em usar as ferramentas fornecidas pela Kapa.ai, semelhante aos experimentos realizados pela Kapa.ai no ano passado usando o modelo o1. Isso destaca um problema mais amplo: os modelos de inferência são bons na solução de problemas abstratos, mas a otimização do uso de ferramentas sem treinamento prévio continua sendo um desafio notável.
Principais conclusões
- O experimento revelou uma óbvia "falácia do raciocínio ≠ experiência": o modelo de raciocínio em si não "entende" a ferramenta de recuperação. Ele entende a função e a finalidade da ferramenta, mas não sabe como usá-la, enquanto os seres humanos possuem esse conhecimento tácito depois de usar a ferramenta. Diferentemente dos processos tradicionais, em que a experiência é codificada em heurística e otimização, o modelo de raciocínio deve ser explicitamente ensinado a usar a ferramenta de forma eficaz.
- Embora o modelo o3-mini seja capaz de lidar com contextos maiores, a Kapa.ai observa que ele não oferece melhorias significativas em relação a modelos como o 4o ou o Sonnet em termos de extração de conhecimento. O simples aumento do tamanho do contexto não é uma panaceia para melhorar o desempenho da recuperação.
- O conjunto de dados da kapa.ai concentra-se em conteúdo técnico relevante para casos de uso no mundo real, em vez de problemas de competição de matemática ou desafios avançados de codificação. O impacto da força da inferência pode variar de acordo com o domínio e pode produzir resultados diferentes para conjuntos de dados que contenham consultas mais estruturadas ou computacionalmente complexas.
- Uma área em que o modelo se sobressai é a geração de código, sugerindo que os modelos de inferência podem ser particularmente adequados para domínios que exigem saída lógica e estruturada em vez de pura recuperação.
- Os modelos de raciocínio não têm conhecimento relacionado à ferramenta.
Raciocínio ≠ falácia empírica
A principal conclusão dos experimentos é que o modelo de inferência não possui naturalmente conhecimento específico da ferramenta. Ao contrário dos processos RAG bem ajustados, que codificam a lógica de recuperação em etapas predefinidas, os modelos de inferência processam cada chamada de recuperação do zero. Isso leva à ineficiência, à indecisão e ao uso subótimo da ferramenta.
Para atenuar isso, várias estratégias possíveis podem ser consideradas. Pode ser útil um refinamento adicional da estratégia de dicas, ou seja, a construção de instruções específicas para a ferramenta de modo a fornecer uma orientação mais explícita ao modelo. Os modelos de pré-treinamento ou ajuste fino para o uso de ferramentas também podem familiarizá-los com mecanismos de recuperação específicos.
Além disso, é possível considerar uma abordagem híbrida, em que a heurística predefinida lida com determinadas tarefas e os modelos de inferência intervêm seletivamente quando necessário.
Essas ideias ainda estão em fase de especulação, mas indicam maneiras de preencher a lacuna entre a capacidade de raciocínio e a implementação real da ferramenta.
resumos
Embora o RAG baseado em inferência modular não tenha apresentado vantagens significativas em relação aos processos tradicionais no contexto dos casos de uso do Kapa.ai, o experimento forneceu informações valiosas sobre seu potencial e suas limitações. A flexibilidade de uma abordagem modular continua sendo atraente. Ela permite maior adaptabilidade, atualizações simplificadas e adaptação dinâmica a novos modelos ou fontes de dados.
Olhando para o futuro, várias tecnologias promissoras merecem ser mais exploradas:
- Usar diferentes estratégias de sugestão e pré-treinamento/ajuste fino para melhorar a maneira como o modelo entende e interage com a ferramenta de recuperação.
- Usar modelos de raciocínio estrategicamente em determinadas partes do processo, por exemplo, para casos de uso ou tarefas específicas, como respostas a perguntas complexas ou geração de códigos, em vez de orquestrar todo o fluxo de trabalho.
Nesse estágio, os modelos de raciocínio como o o3-mini não superaram os processos RAG tradicionais para as principais tarefas de recuperação dentro de restrições de tempo razoáveis. À medida que os modelos avançam e as estratégias de uso das ferramentas evoluem, os sistemas RAG baseados em raciocínio modular podem se tornar uma alternativa viável, especialmente para domínios que exigem fluxos de trabalho dinâmicos e com uso intensivo de lógica.
© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Artigos relacionados




Nenhum comentário...