MiniMax-M1 - Modelo de inferência de código aberto da MiniMax
O que é o MiniMax-M1
O MiniMax-M1 é um modelo de inferência de código aberto da equipe do MiniMax, baseado em uma combinação da MoE (Mixed Expert Architecture) e do mecanismo Lightning Attention, com um total de 456 bilhões de parâmetros. O modelo suporta 1 milhão de token O miniMax-M1 tem uma entrada de contexto longo e saída de 80.000 tokens, o que o torna adequado para documentos longos e tarefas de raciocínio complexas. O modelo está disponível nas versões de orçamento de raciocínio de 40K e 80K para otimizar os recursos computacionais e reduzir os custos de raciocínio. O miniMax-M1 supera vários modelos de código aberto em tarefas como engenharia de software, compreensão de contextos longos e uso de ferramentas. O poder computacional eficiente e os recursos de raciocínio robustos do modelo fazem dele uma base poderosa para a próxima geração de agentes de modelagem de linguagem.

Principais recursos do MiniMax-M1
- processamento de contexto longoSuporte a entradas de até 1 milhão de tokens e saídas de 80.000 tokens, podendo processar com eficiência documentos longos, relatórios longos, artigos acadêmicos e outros conteúdos de texto longo, o que é adequado para tarefas de raciocínio complexas.
- Raciocínio eficienteOferece duas versões de orçamento de inferência, 40K e 80K, para otimizar a alocação de recursos de computação, reduzir os custos de inferência e manter o alto desempenho.
- Otimização de tarefas multidisciplinaresEm geral, os alunos são excelentes em tarefas como raciocínio matemático, engenharia de software, compreensão contextual longa e uso de ferramentas.
- chamada de funçãoSuporte a chamadas de funções estruturadas, pode identificar e gerar parâmetros de chamadas de funções externas, facilitando a interação com ferramentas externas para aumentar a automação e a eficiência do trabalho.
Desempenho do MiniMax-M1
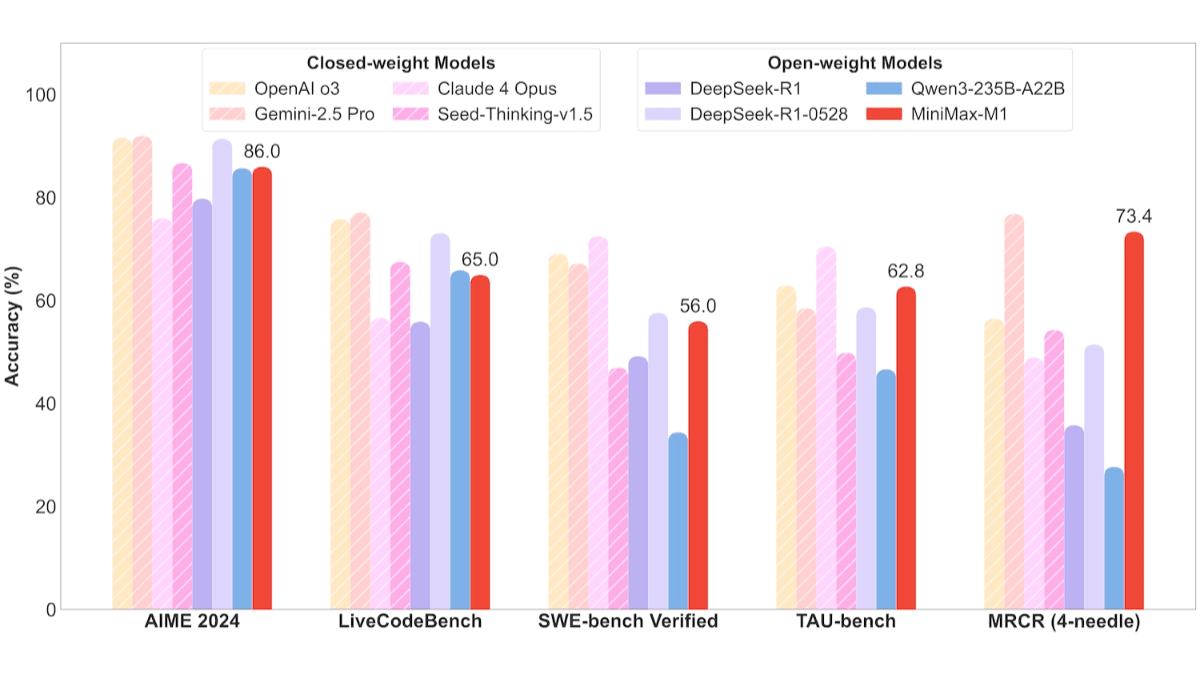
- Tarefas de engenharia de softwareNo benchmark SWE-bench, o MiniMax-M1-40k e o MiniMax-M1-80k alcançaram 55,61 TP3T e 56,01 TP3T, respectivamente, um pouco atrás dos 57,61 TP3T do DeepSeek-R1-0528 e superando significativamente outros modelos de código aberto.
- Tarefas longas de compreensão contextualizadaO MiniMax-M1 se destaca em tarefas longas de compreensão de contexto, superando todos os modelos de código aberto, superando até mesmo o OpenAI o3 e o Claude 4 Opus e ficando em segundo lugar globalmente, atrás do Gemini 2.5 Pro.
- Cenários de uso da ferramentaNo teste de bancada TAU, o MiniMax-M1-40k liderou todos os modelos de código aberto, superando o Gemini-2.5 Pro.
Endereço do site oficial do MiniMax-M1
- Repositório do GitHub::https://github.com/MiniMax-AI/MiniMax-M1
- Biblioteca do modelo HuggingFace::https://huggingface.co/collections/MiniMaxAI/minimax-m1
- Documentos técnicos::https://github.com/MiniMax-AI/MiniMax-M1/blob/main/MiniMax_M1_tech_report.pdf
Como usar o MiniMax-M1
- Chamadas de API::
- Visite o site oficial: Visite a MiniMax Site oficialRegistre-se e faça login na sua conta.
- Obtendo a chave da APISolicite uma chave de API na Central pessoal ou na página do desenvolvedor.
- Usando a APIInvoque o modelo com base em solicitações HTTP, de acordo com a documentação oficial da API. Por exemplo, envie uma solicitação usando a biblioteca de solicitações do Python:
import requests
url = "https://api.minimax.cn/v1/chat/completions"
headers = {
"Authorization": "Bearer YOUR_API_KEY",
"Content-Type": "application/json"
}
data = {
"model": "MiniMax-M1",
"messages": [
{"role": "user", "content": "请生成一段关于人工智能的介绍。"}
]
}
response = requests.post(url, headers=headers, json=data)
print(response.json())- Uso do rosto de abraço::
- Instalação da biblioteca Hugging FaceVerifique se as dependências, como transformadores e tocha, estão instaladas.
pip install transformers torch- Modelos de carregamentoCarregar um modelo MiniMax-M1 do Hugging Face Hub.
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "MiniMaxAI/MiniMax-M1"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
input_text = "请生成一段关于人工智能的介绍。"
inputs = tokenizer(input_text, return_tensors="pt")
output = model.generate(**inputs, max_length=100)
print(tokenizer.decode(output[0], skip_special_tokens=True))- Use no MiniMax APP ou na Web::
- Acesso à WebResposta: Faça login no site da MiniMax, insira uma pergunta ou tarefa na página, e o modelo gera a resposta diretamente.
- FAZER DOWNLOAD DO APLICATIVOFaça o download do aplicativo MiniMax em seu celular e interaja com ele usando operações semelhantes.
Preços de produtos para MiniMax-M1
- Preço de custo de inferência de chamada de API::
- 0-32k Comprimento de entrada::
- custo de insumos: US$ 0,8/milhão de tokens.
- custo de produção: US$ 8/milhão de tokens.
- 32k-128k Comprimento de entrada::
- custo de insumos: US$ 1,2/milhão de tokens.
- custo de produção: US$ 16 por milhão de tokens.
- 128k-1M Comprimento de entrada::
- custo de insumos: US$ 2,4/milhão de tokens.
- custo de produção: US$ 24 por milhão de tokens.
- 0-32k Comprimento de entrada::
- APP e Web::
- Uso gratuitoO aplicativo MiniMax e a Web oferecem acesso gratuito ilimitado, adequado para usuários em geral e usuários sem formação técnica.
Principais benefícios do MiniMax-M1
- capacidade de processamento de contexto longoEle suporta entradas de até 1 milhão de tokens e saídas de até 80.000 tokens, o que o torna adequado para o processamento de documentos longos e tarefas de raciocínio complexas.
- Desempenho eficiente da inferênciaFornecimento de duas versões de orçamento de inferência de 40K e 80K, combinadas com o mecanismo de atenção relâmpago para otimizar os recursos computacionais e reduzir os custos de inferência.
- Otimização de tarefas multidisciplinaresExperiência em engenharia de software: excelente em tarefas como engenharia de software, compreensão de contextos longos, raciocínio matemático e uso de ferramentas, adaptando-se a diversos cenários de aplicativos.
- Arquitetura de tecnologia avançadaArquitetura especializada híbrida (MoE) e treinamento de aprendizagem por reforço (RL) em larga escala para melhorar a eficiência computacional e o desempenho do modelo.
- alta relação qualidade-preçoO desempenho está próximo dos principais modelos internacionais, ao mesmo tempo em que oferece estratégias de preços flexíveis e acesso gratuito ao APP e à Web para reduzir a barreira ao uso.
Pessoas a quem o MiniMax-M1 se destina
- desenvolvedoresDesenvolvedores de software: geram código com eficiência, otimizam a estrutura do código, depuram programas ou geram automaticamente a documentação do código.
- Pesquisadores e acadêmicosProcessamento de artigos acadêmicos longos, realização de revisões de literatura ou análises de dados complexas, uso de modelos para organizar ideias rapidamente, geração de relatórios e resumo de descobertas.
- criador de conteúdoO MiniMax-M1 é uma ferramenta de apoio à criação de ideias, à elaboração de esboços de histórias, ao retoque de textos ou à criação de ficção longa, entre outras coisas.
- crianças em idade escolar: por fornecer soluções claras e suporte à escrita.
- usuário corporativoAs empresas as integram em soluções de automação, como atendimento inteligente ao cliente, ferramentas de análise de dados ou automação de processos de negócios.
© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Artigos relacionados


Nenhum comentário...