MiMo-VL - modelo multimodal de código aberto da Xiaomi
O que é o MiMo-VL
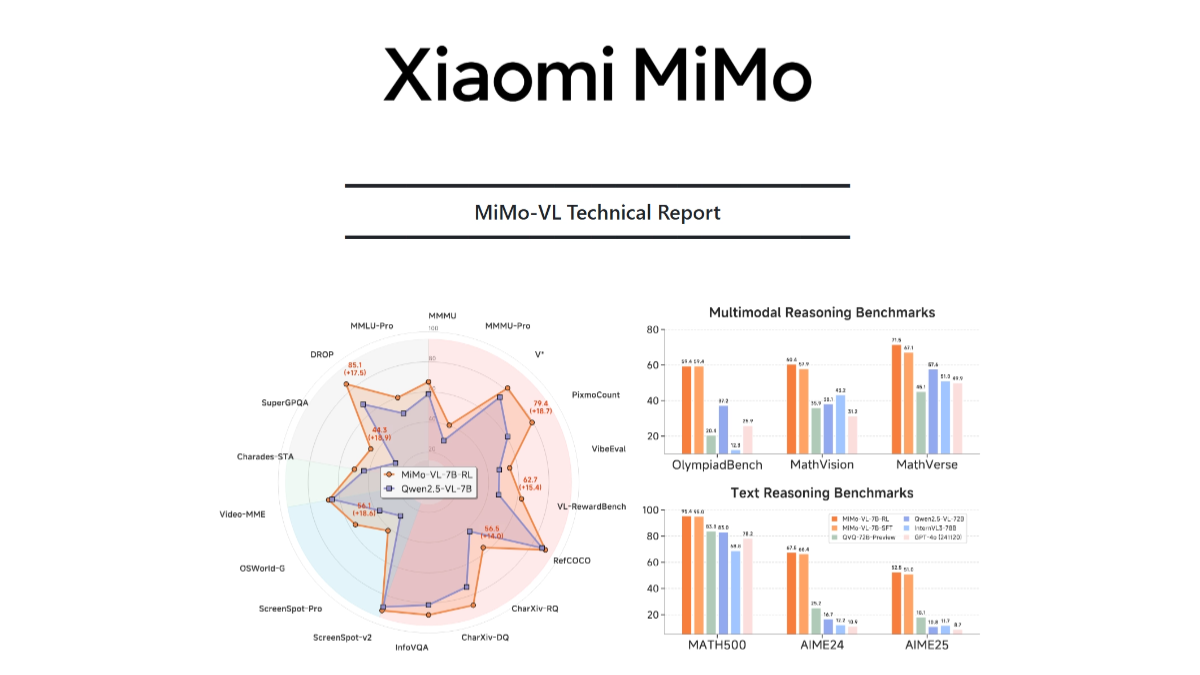
MiMo-VL é o grande modelo multimodal de código aberto da Xiaomi, que consiste em um codificador visual, uma camada de projeção multimodal e um modelo de linguagem. O codificador visual é baseado no Qwen2.5-ViT, que suporta entrada de resolução nativa e preserva mais detalhes; o modelo de linguagem é o MiMo-7B desenvolvido pela própria Xiaomi, otimizado para raciocínio complexo. O modelo baseia-se em uma estratégia de pré-treinamento em vários estágios, treinado com 2,4T tokens de dados multimodais, abrangendo tipos de dados como pares de texto-imagem, pares de texto-vídeo e sequências de operações de GUI. Com base no algoritmo de aprendizagem por reforço on-line híbrido (MORL), a inferência do modelo, o desempenho perceptual e a experiência do usuário são aprimorados em todos os aspectos. O MiMo-VL tem bom desempenho em inferência de imagens complexas, interação com GUI, compreensão de vídeo e análise de documentos longos; por exemplo, ele atinge 66,7% no MMMU-val, superando o Gemma 3 27B; 59,4% no OlympiadBench 59,4% no OlympiadBench, superando o modelo 72B.
Principais recursos do MiMo-VL
- Raciocínio e questionário sobre imagens complexasCompreender com precisão o conteúdo de imagens complexas, dando explicações e respostas razoáveis.
- Operação e interação da GUISuporte a até mais de 10 etapas de operações de GUI para entender e executar instruções complexas.
- Compreensão de vídeos e idiomasCompreensão do conteúdo do vídeo, raciocínio e questionamento em conjunto com a linguagem.
- Análise e raciocínio de documentos longosProcessamento de documentos longos para raciocínio complexo e extração de informações.
- Otimização da experiência do usuário: Aprimoramento da inferência, do desempenho perceptual e da experiência do usuário com base no aprendizado por reforço on-line híbrido.
Endereço do site oficial da MiMo-VL
- Repositório do Github::https://github.com/XiaomiMiMo/MiMo-VL
- Biblioteca do modelo HuggingFace::https://huggingface.co/collections/XiaomiMiMo/mimo-vl
- Documentos técnicos::https://github.com/XiaomiMiMo/MiMo-VL/blob/main/MiMo-VL-Technical-Report
Como usar o MiMo-VL
- Plataforma Hugging Face::
- Acesso à biblioteca de modelos do Hugging FaceAcesso a MiMo-VLsBiblioteca de modelos de rostos abraçadosPágina.
- Modelos de carregamentoUse a biblioteca Python da Hugging Face para carregar o modelo MiMo-VL. Exemplo:
from transformers import AutoModelForVision2Seq, AutoProcessor
model = AutoModelForVision2Seq.from_pretrained("XiaomiMiMo/mimo-vl")
processor = AutoProcessor.from_pretrained("XiaomiMiMo/mimo-vl")- Processamento de dados de entradaDados de entrada, como imagens, vídeos ou texto, são pré-processados com base no processador.
- Gerar saídaEntrada de dados: insira os dados processados no modelo e obtenha a saída do modelo.
- Repositório do GitHub::
- Clonagem de repositórios do GitHub: AcessoRepositório do GitHubclonar o repositório localmente.
git clone https://github.com/XiaomiMiMo/MiMo-VL.git- Instalação de dependênciasInstale as dependências necessárias do Python de acordo com o arquivo requirements.txt no repositório.
pip install -r requirements.txt- código de execuçãoSiga as instruções no repositório para executar o código de amostra ou abrir um aplicativo.
Principais vantagens do MiMo-VL
- Forte capacidade de fusão multimodalProcessamento de dados multimodais, como imagens, vídeo e texto, para entender cenários complexos.
- Excelente desempenho de inferênciaDesempenho excelente em vários benchmarks, como 66,71 TP3T no MMMU-val e 59,41 TP3T no OlympiadBench.
- Otimização da experiência do usuárioBaseado no aprendizado por reforço on-line misto (MORL), os comportamentos do modelo são ajustados dinamicamente com base no feedback do usuário para aprimorar a experiência do usuário.
- Ampla gama de cenários de aplicaçãoAplicável a uma variedade de campos, como atendimento inteligente ao cliente, casa inteligente e pesquisa científica.
- Código aberto e suporte da comunidadeFornecimento de código-fonte aberto e suporte à comunidade para facilitar a pesquisa e o desenvolvimento do desenvolvedor.
Pessoas a quem o MiMo-VL se destina
- Pesquisadores de IAFoco em pesquisas nas áreas de fusão multimodal, raciocínio complexo, visão e compreensão da linguagem.
- Desenvolvedores e engenheirosO desenvolvimento de aplicativos inteligentes, como atendimento inteligente ao cliente, casa inteligente, assistência médica inteligente etc., exige a integração da funcionalidade multimodal.
- cientista de dadosProcessamento e análise de dados multimodais para melhorar o desempenho do modelo e a eficiência do processamento de dados.
- Educadores e alunosAuxílio ao ensino e à aprendizagem, por exemplo, resolução de problemas de matemática, aprendizagem de programação, etc.
- Profissionais da área médicaAnálise de imagens médicas e compreensão de textos para melhorar a eficiência e a precisão do diagnóstico.
© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Artigos relacionados


Nenhum comentário...