
MiDashengLM - Modelo de compreensão de som de código aberto da Xiaomi

O que é MiDashengLM
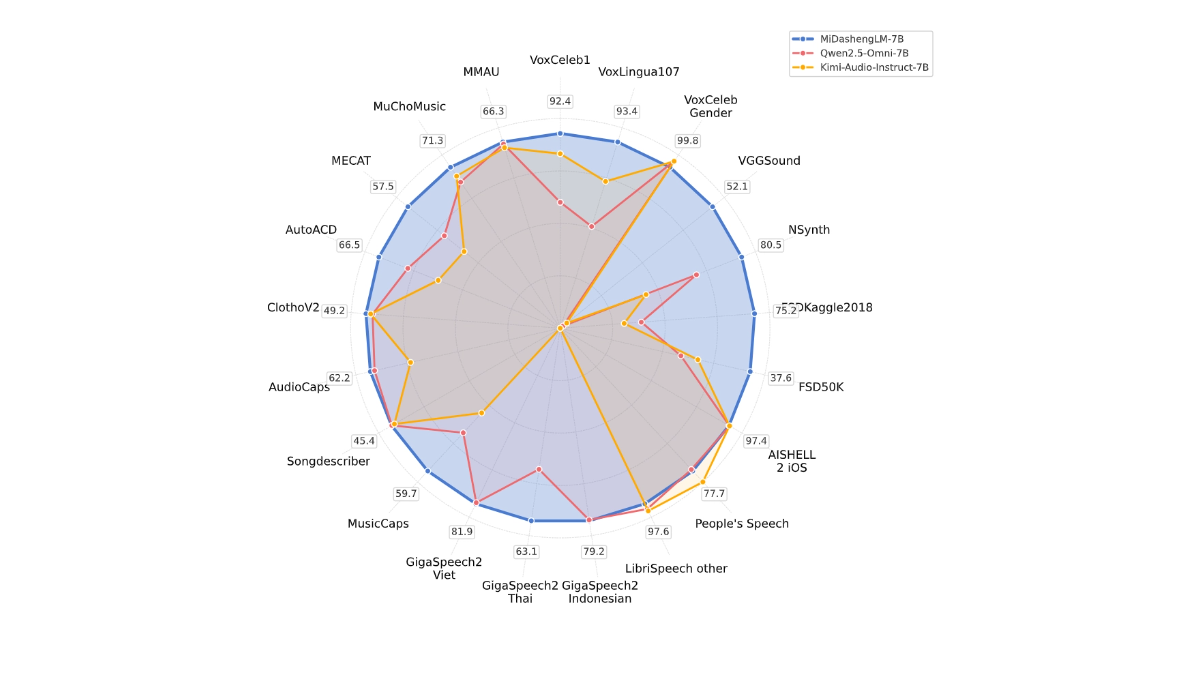
O MiDashengLM é o grande modelo de código aberto da Xiaomi para a compreensão eficiente do som, com a versão específica do parâmetro MiDashengLM-7B, com foco no processamento e na compreensão do áudio. O modelo foi desenvolvido com base no codificador de áudio Xiaomi Dasheng e no decodificador Qwen2.5-Omni-7B Thinker, que pode unificar a compreensão de fala, som ambiente e música. O modelo tem excelente eficiência de inferência, com o primeiro Token Os dados de treinamento do MiDashengLM são totalmente de código aberto, suportando o uso acadêmico e comercial e fornecendo suporte avançado para a atualização da experiência de interação multimodal.
Principais recursos do MiDashengLM
- Conteúdo de áudio para textoO modelo traduz vários tipos de áudio, como vozes faladas, sons da natureza ou música, em descrições textuais que ajudam as pessoas a entender rapidamente o que realmente está acontecendo no áudio.
- Identificar categorias de áudioO modelo pode dizer se um trecho de áudio é fala, som ambiente ou música, etc., assim como rotular o áudio para facilitar o uso em diferentes cenários.
- reconhecimento de falaConversão de texto: converte o que uma pessoa diz em texto, suporta vários idiomas e é particularmente adequado para uso em assistentes de voz ou dispositivos inteligentes.
- Perguntas e respostas em áudioResposta a perguntas com base no conteúdo de áudio, por exemplo, pergunta "What was that sound?" (Que som foi esse?) no carro, e o modelo responde.
- interação multimodalCapacidade de entender áudio e outras informações (por exemplo, texto, imagens) em conjunto, permitindo interações mais inteligentes e naturais com o dispositivo.
Endereço do site oficial da MiDashengLM
- Repositório do GitHub:: https://github.com/xiaomi-research/dasheng-lm
- Biblioteca do modelo HuggingFace:: https://huggingface.co/mispeech/midashenglm-7b
- Documentos técnicos:: https://github.com/xiaomi-research/dasheng-lm/blob/main/technical_report/MiDashengLM_techreport.pdf
- Demonstração da experiência on-line:: https://huggingface.co/spaces/mispeech/MiDashengLM-7B
Como usar o MiDashengLM
- Experiência on-lineVisite a demonstração da experiência on-line da MiDashengLM.
- Carregamento de arquivos de áudioUpload de um arquivo de áudio (os formatos compatíveis incluem WAV, MP3, etc.).
- Aguardando para ser processadoApós fazer o upload do áudio, o modelo processa automaticamente o áudio e gera os resultados.
- Exibir resultadosApós a conclusão do processamento, visualize a descrição ou os resultados da classificação gerados pelo modelo.
Principais pontos fortes da MiDashengLM
- Desempenho eficiente da inferênciaEficiência de inferência do MiDashengLM: a eficiência de inferência do MiDashengLM é extremamente alta, a latência do primeiro token é muito baixa e a taxa de transferência é muito melhor, o que o torna adequado para cenários de interação em tempo real.
- Compreensão de áudio avançadaO sistema de áudio de alta qualidade da Microsoft permite uma compreensão unificada de uma ampla variedade de áudio, incluindo fala, som ambiente e música, evitando as limitações dos métodos tradicionais.
- Dados e modelos de código abertoOs dados e modelos de treinamento são totalmente de código aberto, facilitando a pesquisa e o desenvolvimento secundário por parte dos desenvolvedores e apoiando o uso acadêmico e comercial.
- Ampla gama de cenários de aplicaçãoAplica-se a uma variedade de campos, como cockpit inteligente, casa inteligente, assistente de voz, criação de conteúdo de áudio e educação e aprendizado.
- Otimização de tecnologiaMiDashengLM: Com base em um projeto otimizado de codificador e decodificador de áudio, o MiDashengLM é excelente para lidar com tarefas complexas de áudio e, ao mesmo tempo, reduzir a carga computacional.
- Estratégias de treinamentoEstratégia de treinamento: uma estratégia de treinamento baseada no alinhamento genérico da descrição de áudio e na análise de vários especialistas garante que o modelo aprenda as associações semânticas profundas do áudio e melhore a generalização.
Pessoas a quem o MiDashengLM se destina
- Pesquisadores de inteligência artificialO modelo fornece aos pesquisadores modelos de compreensão de áudio de código aberto e dados de treinamento para facilitar a pesquisa e a inovação em campos relacionados.
- Desenvolvedores de dispositivos inteligentesPara equipes que desenvolvem produtos como cockpits inteligentes, casas inteligentes, assistentes de voz, etc., o modelo é rapidamente integrado ao produto para aprimorar a experiência de interação.
- Criadores de conteúdo de áudioCriadores de áudio usam modelos para gerar automaticamente descrições e rótulos de áudio para aumentar a eficiência da criação de conteúdo.
- Educadores e alunosProfessor de música: na área de aprendizado de idiomas e educação musical, auxiliando com feedback de pronúncia e orientação teórica para ajudar os alunos a adquirir melhor o conhecimento.
- usuário corporativoUma solução eficiente para empresas que precisam de funcionalidade de compreensão de áudio compatível com o uso comercial e que pode ser usada para desenvolvimento de produtos e otimização de serviços.
© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Artigos relacionados


Nenhum comentário...