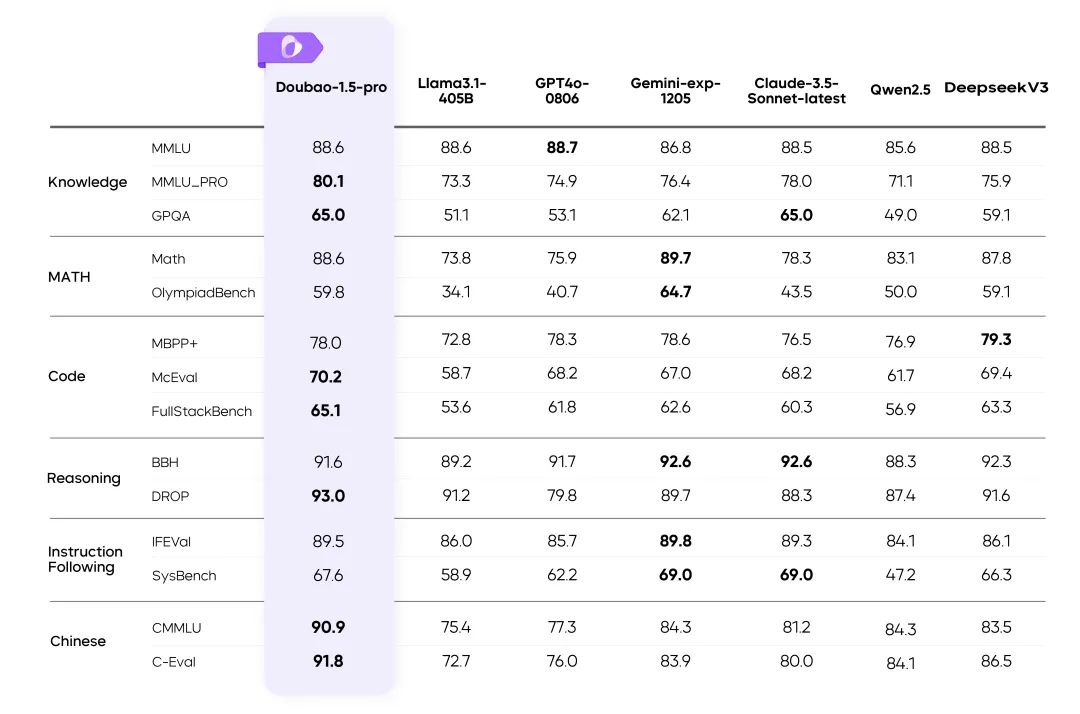
Análise detalhada dos 10 melhores projetos de conversão de texto em fala

-Projeto TTS (text-to-speech) de código aberto: para que os aplicativos injetem som de "voz" realista
Na onda da inteligência artificial, a tecnologia Text-to-Speech (TTS) tornou-se uma ponte importante que conecta o mundo digital e os sentidos humanos. Desde o diálogo homem-máquina em assistentes inteligentes até a orientação por voz em sistemas de navegação e auxílios à leitura, a tecnologia TTS está rompendo as limitações da palavra escrita com seu charme exclusivo, tornando a entrega de informações mais intuitiva e eficiente.
O espírito de código-fonte aberto impulsiona o rápido desenvolvimento da tecnologia TTS. Cada vez mais desenvolvedores e pesquisadores estão se juntando à comunidade de código aberto para criar e aprimorar o ecossistema TTS. Neste artigo, vamos nos concentrar em vários projetos de TTS de código aberto de alto nível, analisar seus recursos técnicos e potencial de aplicação e ajudar os leitores a encontrar o mecanismo de "som" mais adequado para suas próprias necessidades em uma ampla gama de opções.
Visão geral dos projetos de TTS de código aberto
A seguir, uma introdução a uma série de projetos de TTS de código aberto com suas próprias vantagens. Eles diferem em termos de cobertura de idioma, fidelidade de timbre, funcionalidade etc. Os leitores podem escolher de acordo com os cenários de aplicativos reais:
1. ChatTTS: síntese de fala natural para cenários de diálogo
Características do projeto: ChatTTS Com foco na otimização do efeito da síntese de fala em cenários de conversação, seus principais pontos fortes sãoExcelente processamento de contexto misto de chinês e inglêsresponder cantandoSimulação de vários falantes. Ele suporta seis configurações de idioma, incluindo chinês, inglês e japonês, e pode sintetizar textos mistos em chinês e inglês de forma suave e natural, o que é especialmente importante para cenários de aplicativos que precisam lidar com conteúdo de diálogo em vários idiomas. O recurso de vários alto-falantes permite que o ChatTTS simule as vozes de diferentes personagens, dando ao sistema de diálogo uma expressividade mais rica.
Cenários de aplicativos em potencial: Sistemas inteligentes de atendimento ao cliente, assistentes de IA para conversação, ferramentas de aprendizado multilíngue, criação de audiolivros e muito mais.
Vantagens: Otimização de cenas de conversação, leitura natural e suave de chinês e inglês misturados, suporte para vários tons de alto-falante.
Aspectos a serem enfocados: Em comparação com alguns projetos que buscam uma qualidade sonora extrema, o ChatTTS pode se concentrar mais na naturalidade e na funcionalidade do diálogo, e pode haver diferenças no desempenho da qualidade sonora em cenários específicos.

Endereço do GitHub: https://github.com/2noise/ChatTTS
2. IMS Toucan: recursos de síntese além dos limites da linguagem
Características do projeto:Tucano IMS por meio deAmplo suporte a idiomasé conhecido por sua capacidade de sintetizar a fala em mais de 7.000 idiomas. Essa impressionante cobertura de idiomas o torna ideal para a criação de aplicativos globais. O IMS Toucan também temSíntese de fala com vários alto-falantesA função é capaz de simular as características de voz de diferentes alto-falantes e fornecer uma rica seleção de tons.
Cenários de aplicativos em potencial: Implementação globalizada de aplicativos, plataformas de educação multilíngue, desenvolvimento de recursos de fala em idiomas raros, pesquisa linguística etc.
Vantagens: Cobertura extremamente alta de idiomas, suporte para vários falantes, comunidade ativa de código aberto.
Aspectos a serem enfocados: Uma variedade tão grande de suporte a idiomas pode significar que talvez não haja tanto refinamento da qualidade do som em idiomas específicos quanto os modelos que se concentram em menos idiomas. Recomenda-se a realização de testes práticos para avaliar a eficácia do suporte ao idioma de destino.
文本转语音工具-1")
Endereço do GitHub: https://github.com/DigitalPhonetics/IMS-Toucan
3. Fish Speech: o domínio da síntese de fala chinesa
Características do projeto: Discurso do peixe especializar-se emChinês, inglês e japonêsde síntese de fala, especialmente emProcessamento de fala em chinêsO desempenho é excepcional. O projeto enfatiza que sua qualidade de síntese de fala é próxima à de uma pessoa real, graças ao uso de cerca de 150.000 horas de dados trilíngues para treinamento. Vale a pena conferir o Fish Speech se os cenários de seus aplicativos forem principalmente em chinês e se você tiver altos requisitos de naturalidade e expressividade da fala.
Cenários de aplicativos em potencial: Assistente de voz chinês, plataforma de criação de conteúdo chinês, audiolivros chineses e navegação por voz chinesa.
Vantagens: Excelente qualidade de síntese de fala chinesa, alta naturalidade, comunidade de código aberto amigável ao suporte chinês.
Aspectos a serem enfocados: O suporte a idiomas está concentrado em chinês, inglês e japonês; o suporte a outros idiomas pode exigir avaliação adicional.

Endereço do GitHub: https://github.com/fishaudio/fish-speech
4. FunAudioLLM: um novo modelo de interação de voz habilitado para LLM
Características do projeto: O FunAudioLLM é de código aberto da Alibaba, e sua inovação está na profunda integração da tecnologia TTS e da modelagem de linguagem em larga escala (LLM), com o objetivo de alcançarInteração de voz mais natural e suave entre pessoas e LLMs. Ele não se concentra apenas na geração de fala de alta qualidade, mas também enfatiza a sinergia entre a compreensão e a geração de fala em aplicativos LLM, explorando a próxima geração de paradigmas de interação de fala. De interesse especial aqui são CosyVoice O sistema de clonagem de voz é excelente e rápido.
Cenários de aplicativos em potencial: Alto-falantes inteligentes de nova geração, assistentes inteligentes com recursos avançados de interação por voz, sistemas de diálogo baseados em LLM e centros de controle de residências inteligentes.
Vantagens: Com o apoio da Ali, uma forte força técnica, a LLM, combinada com a direção inovadora, deverá proporcionar uma experiência de interação de voz mais inteligente.
Aspectos a serem enfocados: Por ser um projeto relativamente novo, a maturidade e a estabilidade do modelo ainda podem estar em desenvolvimento e aprimoramento.

Endereço do GitHub: https://github.com/FunAudioLLM
5. Parler-TTS: a fusão de fala leve e estilizada
Características do projeto: Parler-TTS foco emclasse de peso leve (no atletismo)responder cantandoSíntese de fala estilizada. Ele gera uma fala de alta qualidade e aparência natural que imita o gênero, o tom, a velocidade e outras características personalizadas do falante-alvo, ao mesmo tempo em que especifica o estilo do falante. Isso permite que o Parler-TTS seja executado com eficiência em dispositivos com recursos limitados e dá à síntese de fala um toque mais pessoal e expressivo.
Cenários de aplicativos em potencial: Aplicativos móveis, sistemas incorporados, aplicativos que exigem fala personalizada, clonagem de fala e estudos de migração de estilo, etc.
Vantagens: O modelo é leve, tem baixo consumo de recursos, suporta a geração de fala estilizada e é capaz de imitar as características de timbre do locutor.
Aspectos a serem enfocados: Por ser um modelo leve, ele pode não ser tão bom quanto alguns dos modelos maiores na busca por uma qualidade de som extrema.

Endereço do GitHub: https://github.com/huggingface/parler-tts
6. F5-TTS: clonagem de som de amostra zero eficiente em tempo real
Características do projeto: F5-TTS Com código aberto conjunto da Shanghai Jiao Tong University e da University of Cambridge, o principalClonagem de som de amostra zeroresponder cantandosíntese de fala em tempo real. Sua taxa de inferência em tempo real chega a 0,15, o que significa que a velocidade de síntese é muito mais rápida do que em tempo real e pode atender às necessidades de aplicativos sensíveis à latência. Além disso, o F5-TTS suportacontrole da falaresponder cantandoTransições suaves entre idiomas/dialetosO RTF=0,15 significa que são necessários apenas 0,15 segundos para sintetizar 1 segundo de fala. O termo "Real-Time Factor 0,15" geralmente se refere ao Real-Time Factor (RTF), em que quanto menor o valor, mais rápida é a síntese; RTF=0,15 significa que são necessários apenas 0,15 segundos para sintetizar um discurso de 1 segundo.
Cenários de aplicativos em potencial: Sistema de interação de voz em tempo real, dublagem de personagens de jogos, aplicativos interativos ao vivo, sistema de conferência em vários idiomas, tradução instantânea de voz, etc.
Vantagens: A inferência em tempo real é rápida, com suporte para clonagem de voz de amostra zero, taxa de fala controlada e transições suaves entre idiomas.
Aspectos a serem enfocados: A qualidade do som e a clonagem de clones de amostra zero podem ser afetadas pela qualidade do áudio de referência.

Endereço do GitHub: https://github.com/SWivid/F5-TTS
7. MaskGCT: TTS versátil de amostragem zero com arquitetura não autorregressiva
Características do projeto: MáscaraGCT é umtotalmente não-autoregressivoO modelo TTS, que também tem um potenteamostra zeroRecursos. Ele é rico em recursos e oferece suporte aTradução e dublagem entre idiomas, clonagem de fala, conversão de idiomas, controle de emoçõesA arquitetura não-autoregressiva permite garantir a qualidade da síntese com maior velocidade e eficiência. A arquitetura não-autoregressiva permite que ele tenha maior velocidade e eficiência de geração, garantindo a qualidade da síntese, enquanto as funções diversificadas permitem que ele seja usado em uma gama mais ampla de cenários de aplicativos.
Cenários de aplicativos em potencial: Dublagem de filmes em vários idiomas, localização de conteúdo de voz, serviços personalizados de customização de voz, tecnologia de proteção de direitos autorais de voz, sistema de interação emocional por voz, ferramentas de comunicação entre idiomas, etc.
Vantagens: Arquitetura não-autoregressiva, geração rápida, funcionalidade avançada, suporte para vários idiomas, clonagem de fala, controle de emoções e muitos outros recursos avançados.
Aspectos a serem enfocados: A funcionalidade é mais complexa e pode exigir um certo nível de habilidade técnica para navegar totalmente em seus recursos avançados.
-1")
Endereço do GitHub: https://github.com/open-mmlab/Amphion/tree/main/models/tts/maskgct
8. OuteTTS (anteriormente Smol TTS): um TTS leve e flexível para a arquitetura LLaMa
Características do projeto: OuteTTS (também conhecido como Smol TTS) com base em Arquitetura LLaMaCriado para ser umclonagem de fala de amostra zeroModelos. Suas principais características são ser leve, flexível e fácil de implantar e usar. O OuteTTS é uma opção de nível básico que vale a pena para os desenvolvedores que desejam experimentar rapidamente a clonagem de amostra zero, mas não querem usar modelos muito complexos.
Cenários de aplicativos em potencial: Desenvolvimento rápido de aplicativos leves, prototipagem, personalização de assistentes de voz pessoais, experimentação de técnicas de clonagem de voz etc.
Vantagens: Com base na arquitetura LLaMa, o modelo é leve, fácil de implantar e suporta clonagem de fala com amostra zero.
Aspectos a serem enfocados: Por ser um modelo leve, a qualidade do som e a riqueza de recursos podem ser relativamente limitadas. Os itens geralmente aparecem com os nomes OuteTTS ou Smol TTS, referindo-se ao mesmo item.
Endereço do GitHub: https://github.com/edwko/OuteTTS
9. Kokoro: pequeno número de referências, modelo compacto com suporte multilíngue
Características do projeto: Kokoro é um modelo TTS de código aberto relativamente pequeno, com apenas 82 milhões de parâmetros e treinado em um conjunto de dados de áudio relativamente pequeno. Apesar do tamanho pequeno do modelo, o Kokoro ainda apresenta boasSuporte a vários idiomasdemonstrando o potencial de modelos pequenos no espaço de TTS multilíngue. O Kokoro pode ser uma opção viável se a funcionalidade TTS multilíngue precisar ser implementada em ambientes com recursos limitados.
Cenários de aplicativos em potencial: Aplicativos de dispositivos com poucos recursos, sistemas incorporados, recursos multilíngues de rápida implantação, soluções TTS sensíveis ao custo e muito mais.
Vantagens: O modelo tem um pequeno número de participantes, poucos requisitos de recursos, suporta vários idiomas e é fácil de implantar.
Aspectos a serem enfocados: Limitada pelo tamanho do modelo e pela quantidade de dados de treinamento, a qualidade e a naturalidade do som podem ficar aquém de modelos maiores.

Endereço do GitHub: https://github.com/hexgrad/kokoro
10. Llasa: tecnologia de clonagem de fala de alta fidelidade com amostra zero
Características do projeto: Llasa é um laboratório de áudio de código aberto da Universidade de Ciência e Tecnologia de Hong Kong.Clonagem de fala de amostra zero e modelagem de TTSO Llasa é compatível com a geração de fala a partir de texto simples e com a clonagem de alta precisão usando uma determinada fala de referência. Ele suporta tanto a geração de fala a partir de texto simples quanto a clonagem de fala altamente precisa usando uma determinada fala de referência.Fidelidade e naturalidade da clonagem de falaA Llasa é uma tecnologia de clonagem de voz que se esforça para obter uma reprodução de tons altamente realista em condições de amostra zero. Se você tem grandes exigências quanto à qualidade da tecnologia de clonagem de voz, vale a pena estudar e aplicar a Llasa.
Cenários de aplicativos em potencial: Clonagem de voz de alta precisão, dublagem de personagens e personalização de voz, geração de conteúdo de voz personalizado, proteção de direitos autorais de conteúdo de voz, síntese de voz emocional, etc.
Vantagens: Clonagem de fala de alta qualidade com zero amostra, com alta naturalidade e similaridade de fala, produzida pelo Laboratório de Áudio da Universidade de Ciência e Tecnologia de Hong Kong, com grande força técnica.
Aspectos a serem enfocados: Tamanhos maiores de modelos (nível de 1 bilhão de parâmetros) podem exigir mais dos recursos computacionais.

Endereço de download do modelo: https://huggingface.co/HKUSTAudio/Llasa-1B
Como escolher o projeto de TTS de código aberto certo para você?
Com tantos projetos excelentes de TTS de código aberto disponíveis, é fundamental escolher aquele que melhor atenda às suas necessidades. Aqui estão algumas considerações importantes para ajudá-lo a tomar uma decisão informada:
- Cobertura de idiomas: Quais idiomas o seu aplicativo precisa suportar? É dada preferência a projetos que suportem o idioma de destino.
- Qualidade e naturalidade da voz: Quais são suas expectativas em relação à qualidade sonora e à naturalidade da fala sintetizada? Recomenda-se ouvir as demonstrações fornecidas por cada projeto para ter uma impressão visual dos efeitos de fala dos diferentes modelos e fazer uma avaliação abrangente combinando métricas de avaliação subjetiva (por exemplo, MOS - Mean Opinion Score) e dados de avaliação objetiva.
- Requisitos de características funcionais: Seu aplicativo requer recursos avançados, como clonagem de amostra zero, vários alto-falantes, controle de emoção, ajuste da taxa de fala etc.? Escolha um item com os recursos adequados com base em suas necessidades reais.
- Considerações sobre desempenho e eficiência: O cenário de seu aplicativo tem requisitos de tempo real? Quais são as limitações da velocidade de inferência e do consumo de recursos dos modelos? Por exemplo, aplicativos interativos em tempo real precisam escolher modelos com velocidade de inferência rápida; dispositivos com restrição de recursos precisam considerar modelos leves.
- Facilidade de uso e melhoria da documentação: A documentação do projeto é completa e fácil de entender? Ele oferece fácil implementação e uso? Para os desenvolvedores novatos, a escolha de um projeto com documentação clara e fácil de iniciar pode reduzir efetivamente os custos de aprendizado.
- Atividade e manutenção da comunidade: A comunidade de código aberto do projeto está ativa? Há atualizações e manutenção contínuas? Uma comunidade ativa geralmente significa suporte técnico mais oportuno e iteração mais rápida.
- Contrato de Licença: Sempre preste atenção ao contrato de licença de código aberto do projeto para saber se ele permite o uso comercial e se o uso comercial está sujeito a termos específicos. As licenças de código aberto comuns incluem a Licença MIT, a Licença Apache 2.0, a Licença GPL etc. Licenças diferentes têm restrições diferentes quanto ao uso comercial.
- Requisitos de recursos de hardware: Diferentes modelos TTS têm diferentes requisitos de recursos de hardware. Alguns modelos grandes podem exigir GPUs de alto desempenho para serem executados sem problemas, enquanto modelos leves podem ser executados em um ambiente de CPU. Escolha o modelo certo de acordo com suas condições de hardware.
Recomendamos que você combine os fatores acima e avalie e teste cuidadosamente cada projeto de acordo com o cenário específico do seu aplicativo e seus recursos técnicos. Muitos dos projetos fornecem modelos pré-treinados e exemplos de demonstração, para que você possa experimentá-los e escolher o projeto que melhor atenda às suas necessidades.
observações finais
A proliferação de projetos de TTS de código aberto impulsionou a inovação na tecnologia de fala e ofereceu aos desenvolvedores uma grande variedade de opções. Seja você um desenvolvedor comercial, um pesquisador acadêmico ou um entusiasta da tecnologia, é possível encontrar o mecanismo de voz ideal na comunidade de código aberto para proporcionar ao seu aplicativo uma experiência de interação de voz mais vívida e natural. Com o progresso contínuo da tecnologia, temos motivos para esperar que mais inovações surjam no campo de TTS de código aberto no futuro e continuem a promover a popularidade e a aplicação da tecnologia de voz.
© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Artigos relacionados

Nenhum comentário...