
LongBench v2: Avaliação de texto longo +o1?

Avaliação de grandes modelos para "compreensão e raciocínio profundos" no mundo real, com textos longos e várias tarefas
Nos últimos anos, houve um progresso significativo no estudo de grandes modelos de linguagem para textos longos, com o comprimento da janela de contexto dos modelos tendo sido ampliado dos 8k iniciais para 128k ou até 1M de tokens. Em outras palavras, eles são capazes de entender, aprender e raciocinar profundamente com base nas informações contidas em textos longos?
Para responder a essa pergunta e impulsionar o avanço dos modelos de textos longos para compreensão e raciocínio profundos, uma equipe de pesquisadores da Universidade de Tsinghua e da Smart Spectrum lançou o LongBench v2, um teste de benchmark projetado para avaliar os recursos de compreensão e raciocínio profundos dos LLMs em multitarefas de textos longos do mundo real.
Acreditamos que o LongBench v2 avançará na exploração de como o dimensionamento da computação em tempo de inferência (por exemplo, o modelo o1) pode ajudar a resolver problemas de compreensão profunda e inferência em cenários de textos longos.
especificidades
O LongBench v2 tem vários recursos significativos em relação aos benchmarks existentes para a compreensão de textos longos:
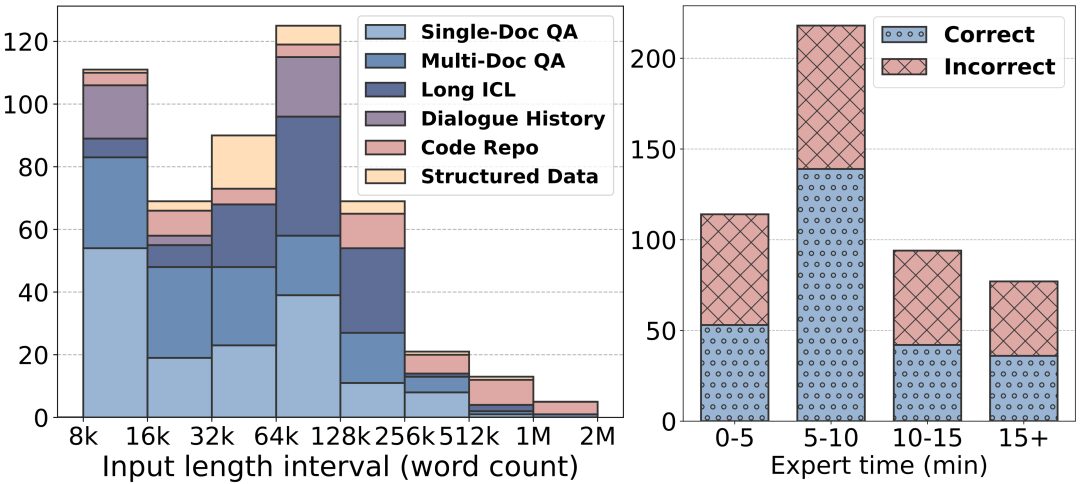
Comprimentos de texto mais longos: os comprimentos de texto do LongBench v2 variam de 8k a 2M palavras, sendo que a maior parte do texto tem menos de 128k de comprimento.
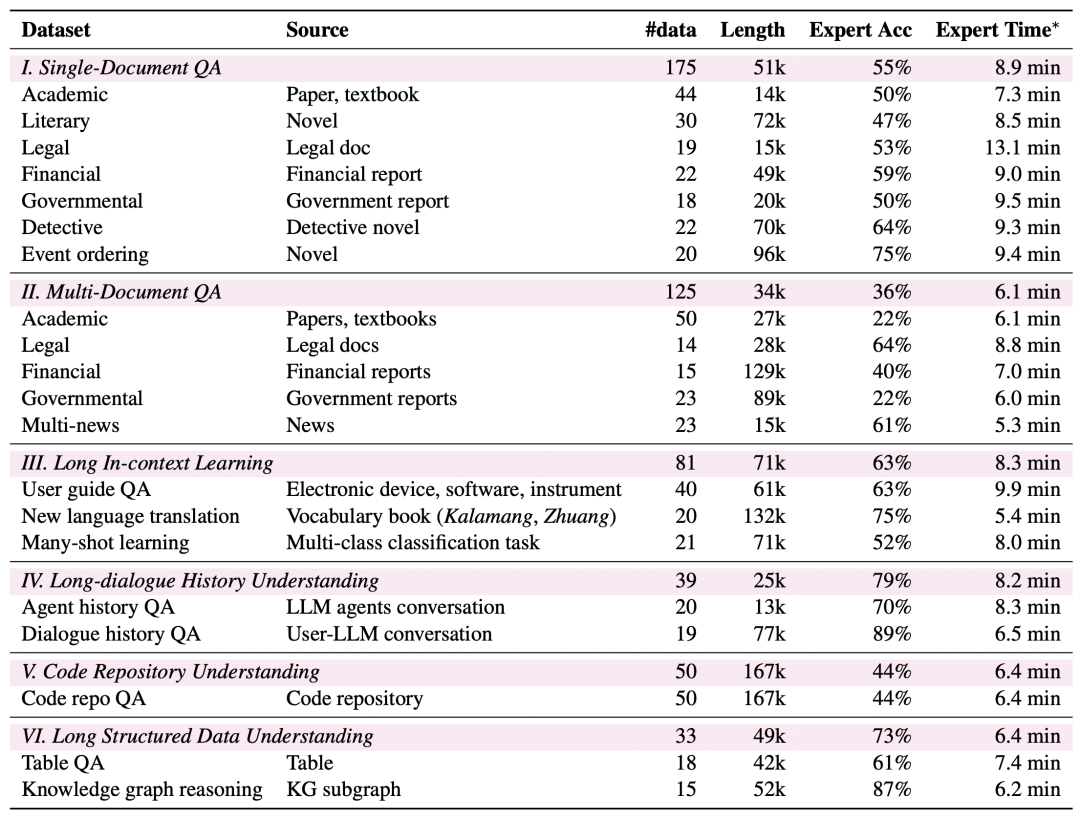
Maior dificuldade: o LongBench v2 contém 503 perguntas desafiadoras de múltipla escolha com quatro opções - perguntas que até mesmo especialistas humanos usando a ferramenta de pesquisa no documento teriam dificuldade para responder corretamente em um curto período de tempo. Os especialistas humanos obtiveram uma média de apenas 53,71 TP3T de precisão (251 TP3T aleatoriamente) no limite de tempo de 15 minutos.
Cobertura de tarefas mais ampla: o LongBench v2 abrange seis categorias de tarefas principais, incluindo questionamento de um único documento, questionamento de vários documentos, aprendizado de contexto de texto longo, compreensão de histórico de diálogo longo, compreensão de repositório de código e compreensão de dados estruturados longos, com um total de 20 subtarefas que abrangem uma variedade de cenários do mundo real.
Maior confiabilidade: para garantir a confiabilidade da avaliação, todas as perguntas do LongBench v2 estão no formato de múltipla escolha e passam por um rigoroso processo manual de rotulagem e revisão para garantir a alta qualidade dos dados.
Processo de coleta de dados
Para garantir a qualidade e a dificuldade dos dados, o LongBench v2 emprega um rigoroso processo de coleta de dados que consiste nas seguintes etapas:
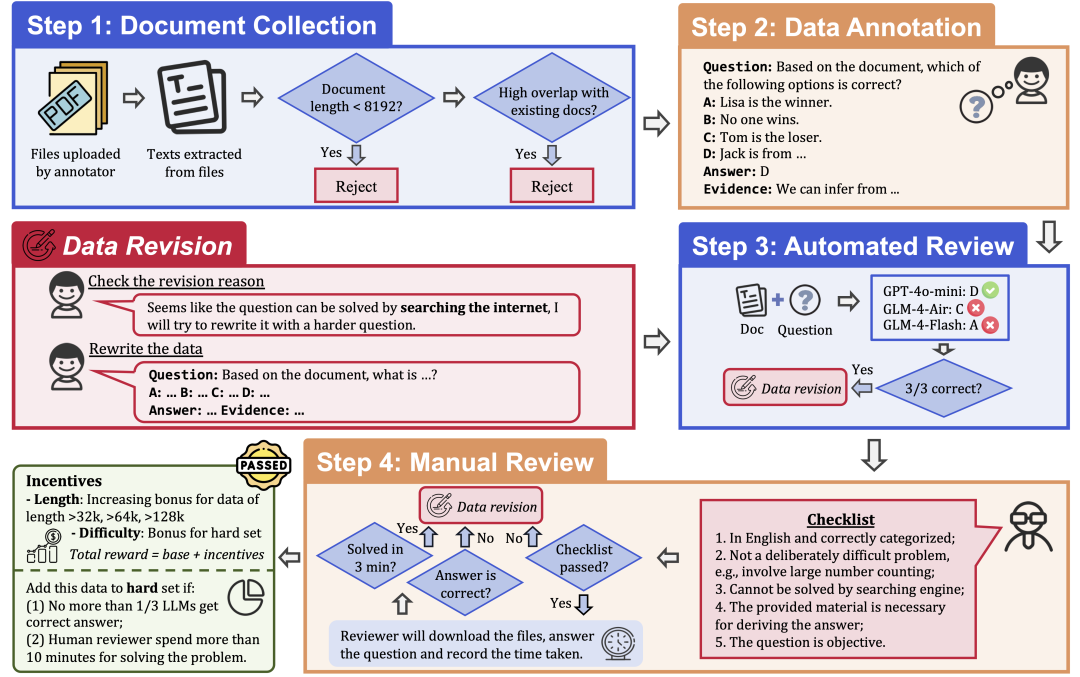
Coleta de documentos: Recrute 97 anotadores das melhores universidades, com uma variedade de formações e graus acadêmicos, para coletar documentos longos que eles tenham lido ou usado pessoalmente, como trabalhos de pesquisa, livros didáticos, romances e assim por diante.
Rotulagem de dados: com base nos documentos coletados, o rotulador faz uma pergunta de múltipla escolha com quatro opções, uma resposta correta e a evidência correspondente.
Revisão automática: os dados anotados foram revisados automaticamente usando três LLMs (GPT-4o-mini, GLM-4-Air e GLM-4-Flash) com uma janela de contexto de 128k e, se todos os três modelos responderam corretamente à pergunta, ela foi considerada muito simples e precisou ser rotulada novamente.
Revisão humana: os dados que passam pela revisão automatizada são atribuídos a uma revisão humana por 24 especialistas humanos profissionais que tentam responder à pergunta e determinar se a pergunta é apropriada e se a resposta está correta. Se o especialista conseguir responder corretamente à pergunta em 3 minutos, a pergunta será considerada muito simples e precisará ser rotulada novamente. Além disso, se o especialista acreditar que a pergunta em si não é adequada ou que a resposta está incorreta, ela será devolvida para nova avaliação.
Revisão de dados: os dados que não forem aprovados na auditoria serão devolvidos ao anotador para revisão até que sejam aprovados em todas as etapas da auditoria.
Resultados da avaliação
A equipe avaliou 10 LLMs de código aberto e 6 LLMs de código fechado usando o LongBench v2. Dois cenários foram considerados na avaliação: zero-shot versus zero-shot+CoT (ou seja, permitir que o modelo produza a cadeia de raciocínio primeiro e, em seguida, permitir que o modelo produza a resposta escolhida).
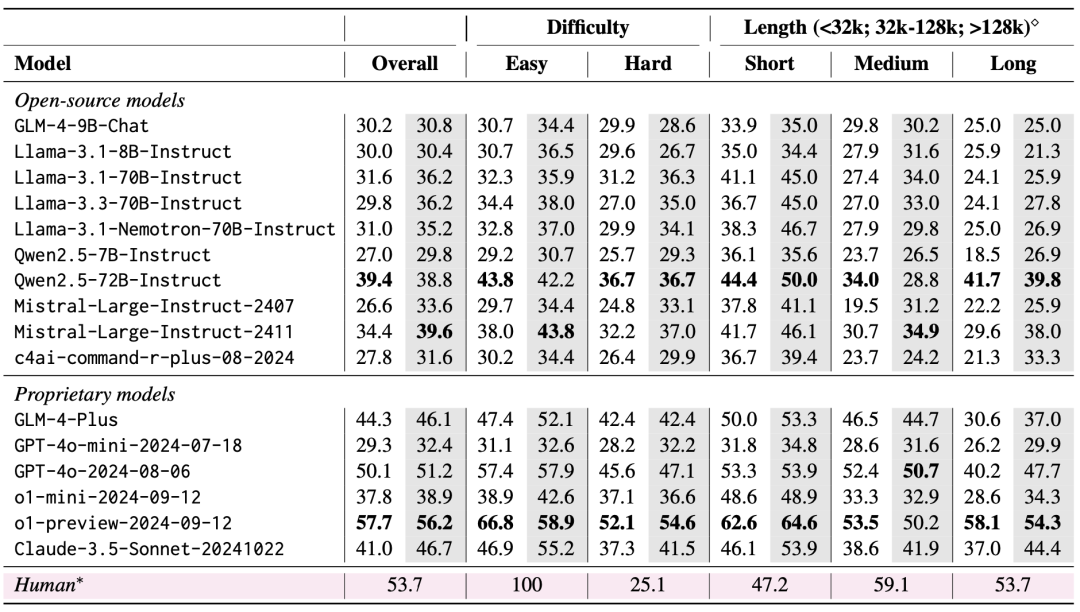
Os resultados da avaliação mostram que o LongBench v2 é um grande desafio para os LLMs atuais, sendo que até mesmo o modelo de melhor desempenho alcança uma precisão de apenas 50,1% com saída de resposta direta, enquanto o modelo o1-preview, que introduz uma cadeia de inferência mais longa, alcança uma precisão de 57,7%, superando o especialista humano em 4%.
1. importância de dimensionar a computação do tempo de inferência
Uma constatação muito importante nos resultados da avaliação é que o desempenho dos modelos no LongBench v2 pode ser significativamente aprimorado pelo Scaling Inference-Time Compute. Por exemplo, o modelo o1-preview obtém melhorias significativas em tarefas como questionamento de vários documentos, aprendizado de contexto de texto longo e compreensão de repositório de código ao integrar mais etapas de inferência em comparação com o GPT-4o.
Isso sugere que o LongBench v2 exige mais dos recursos de raciocínio dos modelos atuais, e que aumentar o tempo gasto pensando e raciocinando sobre o raciocínio parece ser uma etapa natural e essencial para enfrentar esses desafios de raciocínio textual longo.
2. RAG + experimentos de contexto longo

Verifica-se que ambos os modelos, Qwen2.5 e GLM-4-Plus, não apresentam melhoria significativa no desempenho ou até mesmo degradação depois que o número de blocos recuperados excede um determinado limite (32 mil tokens, cerca de 64 blocos de 512 de comprimento).
Isso sugere que o simples aumento da quantidade de informações recuperadas nem sempre leva a melhorias no desempenho. Por outro lado, o GPT-4o é capaz de utilizar eficientemente contextos de recuperação mais longos com um ótimo RAG O desempenho ocorre em um comprimento de recuperação de 128k.
Em resumo, o RAG é de uso limitado quando confrontado com tarefas longas de perguntas e respostas textuais que exigem compreensão e raciocínio profundos, especialmente quando o número de blocos recuperados excede um determinado limite. O modelo precisa ter recursos de raciocínio mais fortes, em vez de se basear apenas nas informações recuperadas, para lidar efetivamente com os problemas desafiadores do LongBench v2.
Isso também implica que as futuras direções de pesquisa também precisam se concentrar mais em como melhorar os recursos de compreensão e raciocínio de textos longos do próprio modelo, em vez de depender apenas da recuperação externa.
Esperamos que o LongBench v2 ultrapasse os limites das técnicas de compreensão e raciocínio de textos longos. Fique à vontade para ler nosso artigo, usar nossos dados e saber mais!
Página inicial: https://longbench2.github.io
Tese: https://arxiv.org/abs/2412.15204
Dados e códigos: https://github.com/THUDM/LongBench
© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Artigos relacionados



Nenhum comentário...