

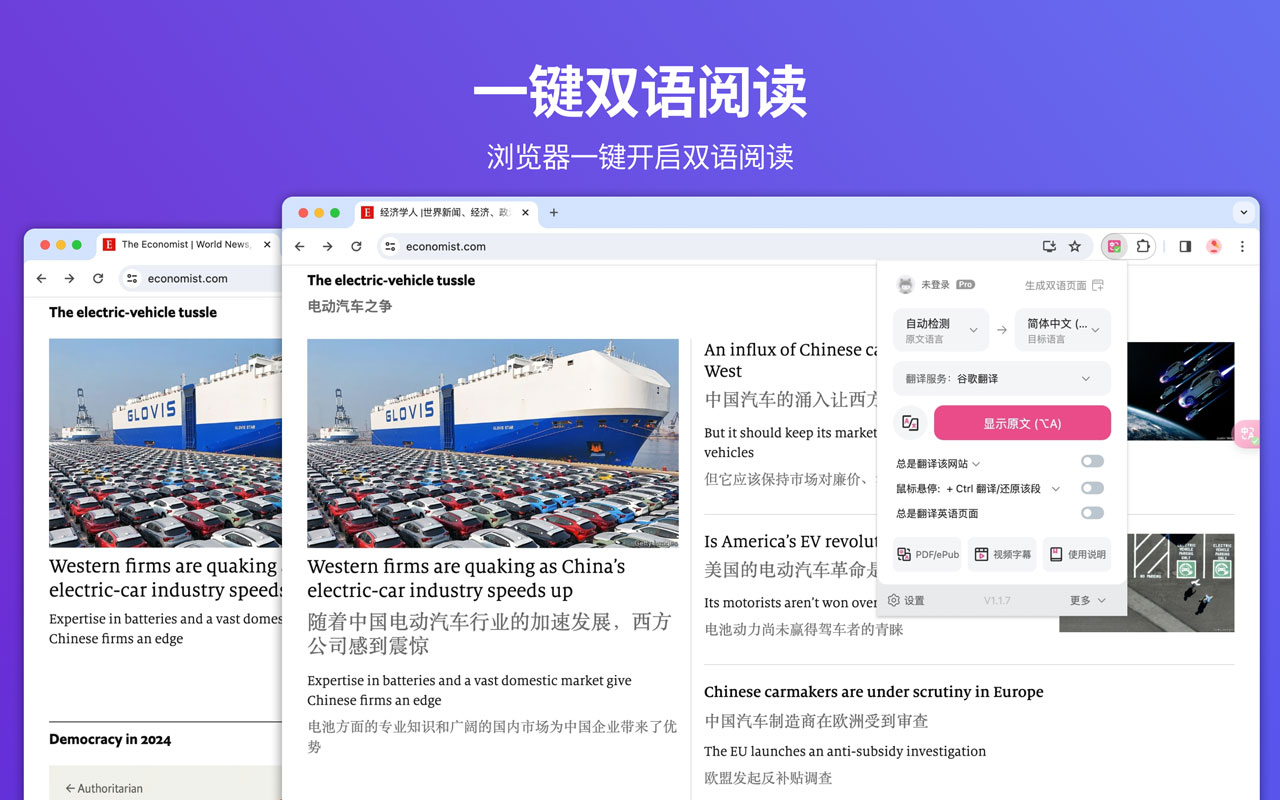
LatentSync: uma ferramenta de código aberto para gerar vídeo com sincronização labial diretamente do áudio

Introdução geral
O LatentSync é uma ferramenta de código aberto desenvolvida pela ByteDance e hospedada no GitHub. Ela aciona os movimentos labiais dos personagens no vídeo diretamente por meio do áudio, de modo que o formato da boca corresponda precisamente à voz. O projeto é baseado no modelo de difusão latente do Stable Diffusion, combinado com o Sussurro Os recursos de áudio são extraídos para gerar quadros de vídeo pela rede U-Net. A versão 1.5 do latentSync, lançada em 14 de março de 2025, otimiza a consistência temporal, oferece suporte a vídeos no idioma chinês e reduz o requisito de memória de vídeo de treinamento para 20 GB. Os usuários podem executar o código de inferência para gerar vídeos sincronizados com os lábios com resolução de 256x256, bastando ter uma placa de vídeo compatível com 6,8 GB de memória de vídeo. vídeos com resolução de 256x256. A ferramenta é totalmente gratuita, com código e modelos pré-treinados fornecidos, e é adequada para entusiastas e desenvolvedores de tecnologia.

Experiência: https://huggingface.co/spaces/fffiloni/LatentSync
Endereço de demonstração da API: https://fal.ai/models/fal-ai/latentsync

Lista de funções
- Sincronização labial do driver de áudioVídeo: insira áudio e vídeo para gerar automaticamente movimentos labiais que correspondam ao som.
- Geração de vídeo de ponta a pontaNão há necessidade de representação intermediária, saída direta de vídeo com sincronização labial nítida.
- Otimização da consistência de tempoRedução do salto de imagem por meio da tecnologia TREPA e das camadas de temporização.
- Suporte a vídeo chinêsVersão 1.5: A versão 1.5 aprimora o manuseio de áudio e vídeo chineses.
- Suporte eficiente ao treinamentoA U-Net está disponível em uma variedade de configurações de U-Net, com requisitos de memória tão baixos quanto 20 GB.
- Pipeline de processamento de dadosFerramentas incorporadas para limpar dados de vídeo e garantir a qualidade da geração.
- parametrizaçãoSuporte para ajustar as etapas de inferência e as escalas de orientação para otimizar a geração.
Usando a Ajuda
O LatentSync é uma ferramenta executada localmente para usuários com base técnica. O processo de instalação, raciocínio e treinamento é descrito em detalhes a seguir.
Processo de instalação
- Requisitos de hardware e software
- Requer placa de vídeo NVIDIA com pelo menos 6,8 GB de memória de vídeo (para inferência), 20 GB ou mais recomendados para treinamento (por exemplo, RTX 3090).
- Compatível com Linux ou Windows (o Windows requer ajuste manual do script).
- Instale o Python 3.10, o Git e o PyTorch com suporte a CUDA.
- Código de download
É executado no terminal:
git clone https://github.com/bytedance/LatentSync.git
cd LatentSync
- Instalação de dependências
Execute o seguinte comando para instalar as bibliotecas necessárias:
pip install -r requirements.txt
Instalação adicional do ffmpeg para processamento de áudio e vídeo:
sudo apt-get install ffmpeg # Linux
- Modelos para download
- através de (uma lacuna) Cara de abraço download
latentsync_unet.ptresponder cantandotiny.pt. - Coloque o arquivo no diretório
checkpoints/com a seguinte estrutura:checkpoints/ ├── latentsync_unet.pt ├── whisper/ │ └── tiny.pt - Se você treinar o SyncNet, também precisará fazer o download de
stable_syncnet.pte outros modelos auxiliares.
- Ambiente de verificação
Execute o comando de teste:
python gradio_app.py --help
Se nenhum erro for relatado, o ambiente foi criado com êxito.
processo de inferência
O LatentSync oferece dois métodos de inferência, ambos com requisitos de 6,8 GB de memória de vídeo.
Método 1: Interface do Gradio
- Inicie o aplicativo Gradio:
python gradio_app.py
- Abra seu navegador e acesse o endereço local solicitado.
- Faça o upload dos arquivos de vídeo e áudio, clique em Run (Executar) e aguarde a geração dos resultados.
Método 2: Linha de comando
- Prepare o arquivo de entrada:
- Vídeo (por exemplo.
input.mp4), precisam conter faces claras. - Áudio (por exemplo.
audio.wav), recomenda-se 16000Hz.
- Execute o script de raciocínio:
python -m scripts.inference
--unet_config_path "configs/unet/stage2_efficient.yaml"
--inference_ckpt_path "checkpoints/latentsync_unet.pt"
--inference_steps 25
--guidance_scale 2.0
--video_path "input.mp4"
--audio_path "audio.wav"
--video_out_path "output.mp4"
inference_steps: 20-50, quanto maior o valor, maior a qualidade e mais lenta a velocidade.guidance_scale: 1,0-3,0, quanto maior o valor, mais preciso será o formato do lábio, podendo haver uma leve distorção.
- sonda
output.mp4O efeito da sincronização labial é confirmado.
Pré-processamento de entrada
- Recomenda-se que a taxa de quadros do vídeo seja ajustada para 25 FPS:
ffmpeg -i input.mp4 -r 25 resized.mp4
- A taxa de amostragem de áudio precisa ser de 16000 Hz:
ffmpeg -i audio.mp3 -ar 16000 audio.wav
Fluxo de processamento de dados
Se o modelo precisa ser treinado, os dados precisam ser processados primeiro:
- Execute o script:
./data_processing_pipeline.sh
- modificações
input_dirpara seu catálogo de vídeos. - O processo inclui:
- Exclua o vídeo corrompido.
- Ajuste o vídeo para 25 FPS e o áudio para 16000Hz.
- Divida a cena usando o PySceneDetect.
- Corte o vídeo em segmentos de 5 a 10 segundos.
- Detecte faces com alinhamento de faces e redimensione para 256x256.
- Filtra vídeos com uma pontuação de sincronização inferior a 3.
- Calcule a pontuação do hyperIQA e remova os vídeos abaixo de 40.
- O vídeo processado é salvo no arquivo
high_visual_quality/Catálogo.
Treinamento U-Net
- Prepare os dados e todos os pontos de controle.
- Selecione o perfil (por exemplo
stage2_efficient.yaml). - Treinamento de corrida:
./train_unet.sh
- Modifique o caminho de dados e o caminho de salvamento no arquivo de configuração.
- Requisitos de memória gráfica:
stage1.yaml: 23GB.stage2.yaml: 30GB.stage2_efficient.yaml: 20 GB para placas de vídeo comuns.
advertência
- Os usuários do Windows precisam definir a opção
.shMude para a execução do comando Python. - Se a tela pular, aumente a
inference_stepsou ajustar a taxa de quadros do vídeo. - O suporte ao áudio chinês foi otimizado na versão 1.5 para garantir que os modelos mais recentes sejam usados.
Com essas etapas, os usuários podem instalar e usar facilmente o LatentSync para gerar vídeos de sincronização labial ou treinar mais o modelo.
cenário do aplicativo
- pós-produção
Substitua o áudio de vídeos existentes para gerar novos lábios adequados para ajustes de dublagem. - imagem virtual
Entrada de áudio para gerar vídeos de avatares falando para vídeos ao vivo ou curtos. - produção de jogos
Adicione animações dinâmicas de diálogo aos personagens para aprimorar a experiência de jogo. - multilinguismo
Gerar vídeos instrutivos com áudio em diferentes idiomas, adaptados para usuários globais.
QA
- Ele oferece suporte à geração em tempo real?
Não suportado. A versão atual requer áudio e vídeo completos e leva de segundos a minutos para ser gerada. - Qual é a memória de vídeo mínima?
O raciocínio requer 6,8 GB e o treinamento recomenda 20 GB (após a otimização na versão 1.5). - Você consegue lidar com vídeos de anime?
Pode. Exemplos oficiais incluem vídeos de anime que funcionam bem. - Como melhorar o suporte ao idioma chinês?
Use o LatentSync versão 1.5, que foi otimizado para o processamento de áudio chinês.
Instalador do LatentSync com um clique
Quark: https://pan.quark.cn/s/c3b482dcca83
Instalador autônomo WIN/MAC
Quark: https://pan.quark.cn/s/90d2784bc502
Baidu: https://pan.baidu.com/s/1HwN1k6v-975uLfI0d8N_zQ?pwd=gewd
LatentSync Enhanced:https://pan.quark.cn/s/f8d3d9872abb
LatentSync 1.5 Implementação local 1: https://pan.baidu.com/s/1QLqoXHxGbAXV3dWOC5M5zg?pwd=ijtt
LatentSync 1.5 Implementação local 2: https://pan.baidu.com/share/init?surl=zIUPiJc0qZaMp2NMYNoAug&pwd=8520
© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Artigos relacionados


Nenhum comentário...