
Enrolados! Modelos vetoriais de texto longo Estratégias de fragmentação Competição
O Modelo de Vetor de Texto Longo é capaz de codificar dez páginas de texto em um único vetor, o que parece poderoso, mas será que é realmente prático?
Muitas pessoas pensam... Não necessariamente.
É possível usá-lo diretamente? Ele deve ser dividido em pedaços? Como dividir o mais eficiente? Neste artigo, apresentaremos uma discussão aprofundada sobre diferentes estratégias de fragmentação para modelos de vetores de texto longo, analisaremos os prós e os contras e o ajudaremos a evitar armadilhas.
O problema da vetorização de textos longos
Primeiro, vamos ver quais são os problemas de compactar um artigo inteiro em um único vetor.
Como exemplo de criação de um sistema de pesquisa de documentos, um único artigo pode conter vários tópicos. Por exemplo, este blog sobre o relatório dos participantes do ICML 2024 contém uma introdução à conferência, uma apresentação do trabalho de Jina AI (jina-clip-v1) e resumos de outros artigos de pesquisa. Se o artigo inteiro for vetorizado em um único vetor, esse vetor misturará informações de três tópicos diferentes:
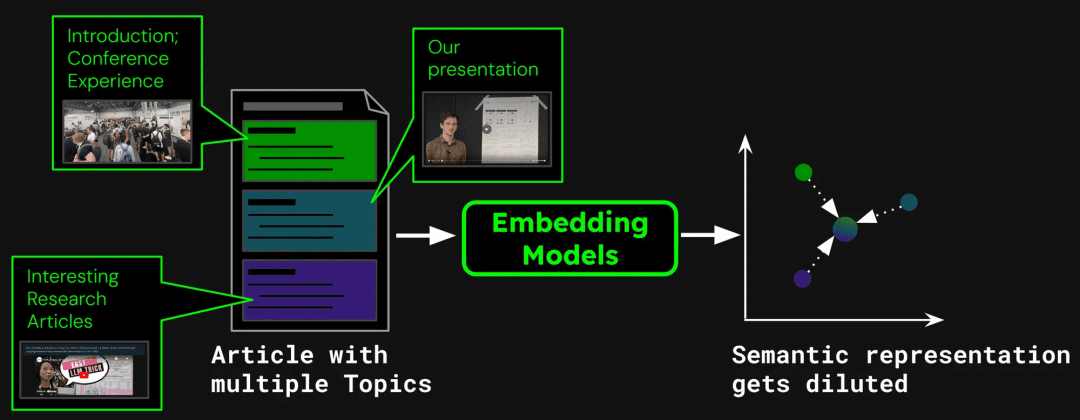
Isso pode levar aos seguintes problemas:
1. diluição da representação
indica que a diluição enfraquece a precisão dos vetores de texto. Embora a postagem do blog contenha vários tópicos, oNo entanto, as consultas de pesquisa dos usuários tendem a se concentrar em apenas uma delas. Representar todo o artigo com um único vetor é equivalente a comprimir todas as informações do tópico em um único ponto no espaço vetorial. À medida que mais texto é adicionado à entrada do modelo, esse vetor representa progressivamente o assunto geral do artigo, diluindo os detalhes de passagens ou tópicos específicos. Isso é como misturar vários pigmentos em uma única cor, o que dificulta para o usuário identificar uma determinada cor da mistura ao tentar encontrá-la.
2. capacidade limitada
As dimensões vetoriais geradas pelo modelo são fixas, e o texto longo contém muitas informações, o que inevitavelmente levará à perda de informações durante o processo de transformação. É como comprimir um mapa de alta definição em um selo postal, e muitos detalhes não são visíveis.
3. perda de informações
Muitos modelos de texto longo só conseguem lidar com até 8192 tokens. Um texto melhor terá que ser truncado, geralmente na parte de trás, e se as principais informações estiverem no final do documento, a recuperação poderá falhar.
4. requisitos de segmentação
Alguns aplicativos só precisam vetorizar segmentos específicos de texto, como sistemas de perguntas e respostas, em que somente os parágrafos que contêm as respostas precisam ser extraídos para vetorização. Nesse caso, a fragmentação do texto ainda é necessária.
3 Estratégias de processamento de textos longos
Antes de iniciarmos o experimento, para evitar confusão conceitual, primeiro definimos três estratégias em blocos:
1. sem fragmentação:Codifica o texto inteiro diretamente em um único vetor.
2. Naive Chunking:Primeiro, o texto é dividido em vários blocos de texto e vetorizado separadamente. Os métodos comumente usados incluem chunking de tamanho fixo, que divide o texto em token número de pedaços; chunking baseado em frases: chunking em frases; chunking baseado em semântica: chunking baseado em informações semânticas. Neste experimento, são usados blocos de tamanho fixo.
3. fragmentação tardia:É um novo método de leitura de todo o texto antes de dividi-lo em partes e consiste em duas etapas principais:
- Texto completo do códigoCodificação: Codifique todo o documento primeiro para obter uma representação vetorial de cada token, preservando todas as informações de contexto.
- agrupamento de partesGeração de vetores para cada bloco de texto por meio do agrupamento médio dos vetores de tokens do mesmo bloco de texto de acordo com o limite do bloco. Como o vetor de cada token é gerado no contexto do texto completo, o particionamento tardio pode preservar as informações contextuais entre os blocos.
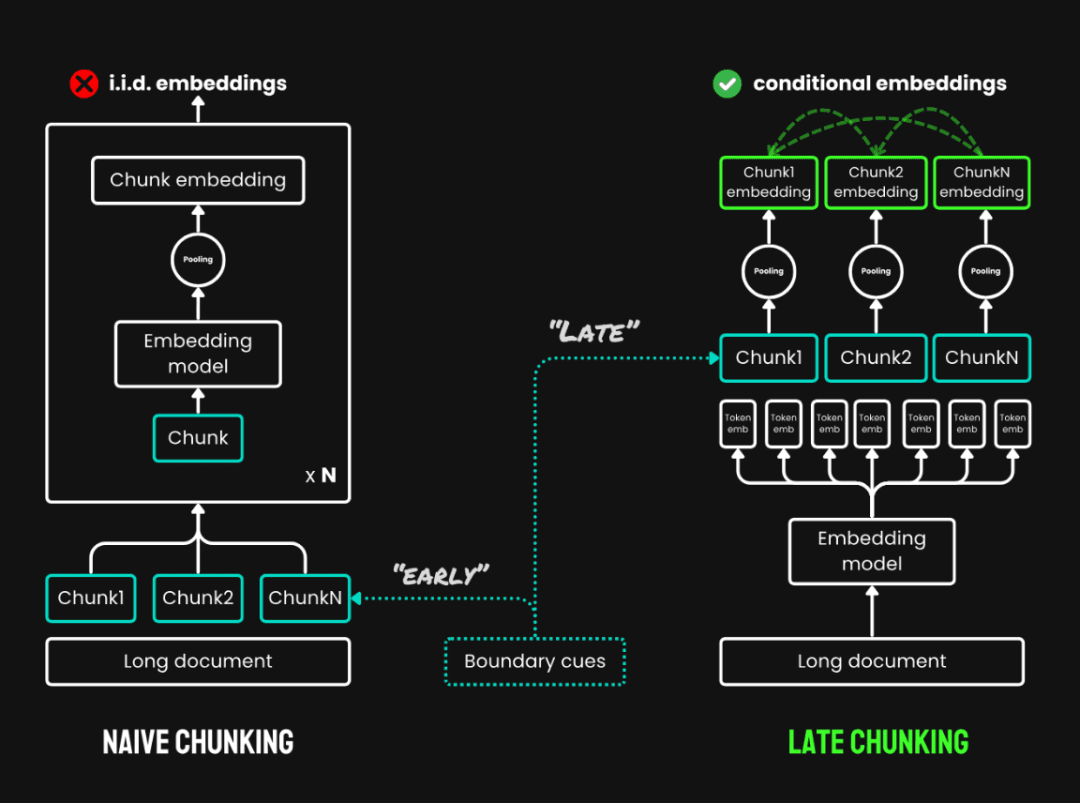
Divisão tardia vs. fragmentação simples
Para modelos que excedem o comprimento máximo de entrada (por exemplo, 8192 tokens), usamos o Chunking longo e tardioEm um modelo de divisão tardia, uma etapa de pré-segmentação é adicionada à divisão tardia, primeiro dividindo o documento em vários macroblocos sobrepostos, cada um com um comprimento dentro do intervalo processável do modelo. Em seguida, uma estratégia padrão de divisão tardia (codificação e pooling) é aplicada dentro de cada macrobloco. A sobreposição entre os macroblocos é usada para garantir a continuidade das informações contextuais.
Pontuação tardia Código de implementação específico: https://github.com/jina-ai/late-chunking在 Experiência com notebook: https://colab.research.google.com/drive/1iz3ACFs5aLV2O_ uZEjiR1aHGlXqj0HY7?usp=sharing
Então, qual é o melhor método?
Para fins de comparação, usamos o conjunto de dados em 5 conjuntos de dados, usando o jina-embeddings-v3 Foram realizados experimentos em que todos os textos longos foram truncados para o tamanho máximo de entrada do modelo (8192 tokens) e segmentados em blocos de texto de 64 tokens cada.

Os 5 conjuntos de dados de teste também correspondem a 5 tarefas de recuperação diferentes
A figura abaixo mostra a diferença de desempenho entre os três métodos em diferentes tarefas; nenhum método é melhor em todos os casos e a escolha depende da tarefa específica.
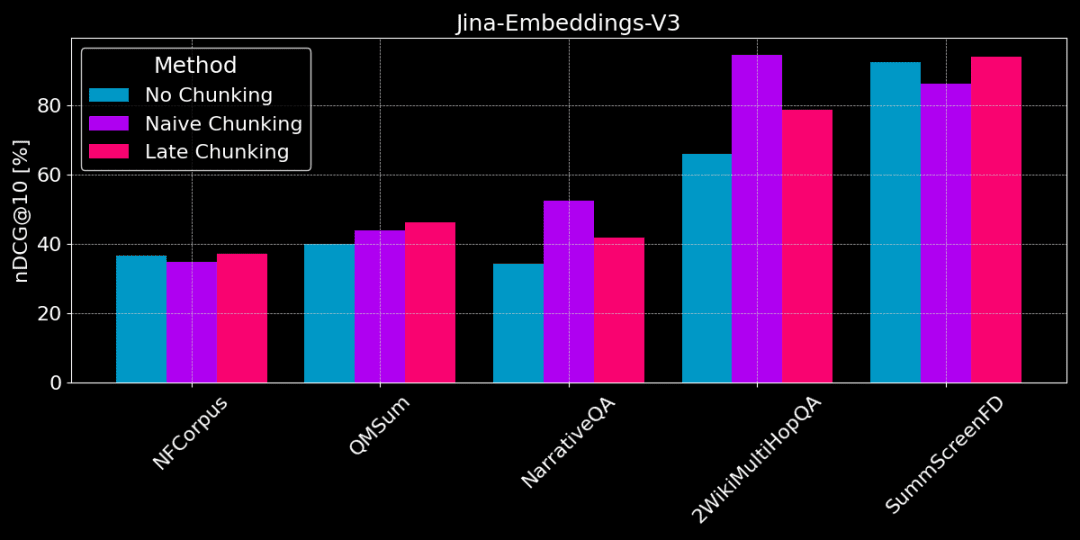
Sem chunking vs. chunking simples vs. chunking tardio
👩🏫 Encontre fatos específicos, o simples agrupamento é bom.
Se informações factuais específicas e localizadas precisarem ser extraídas do texto (por exemplo, "Quem roubou algo?) ), conjuntos de dados como QMSum, NarrativeQA e 2WikiMultiHopQA, a fragmentação simples tem um desempenho melhor do que a vetorização de todo o documento. Como as respostas geralmente estão localizadas em uma parte específica do texto, o chunking simples pode localizar com mais precisão a parte do texto que contém a resposta sem ser distraído por outras informações estranhas.
Mas a fragmentação simples também corta o contexto e pode perder informações globais para analisar corretamente as relações referenciais e as referências no texto.
👩🏫 O artigo é tematicamente coerente, e as pontuações tardias são melhores.
A marcação tardia é mais eficaz quando o assunto é claro e a estrutura do texto é coerente. Como a divisão tardia leva em conta o contexto, ela permite uma melhor compreensão do significado e da relevância de cada parte, incluindo as relações de referência em textos longos.
Entretanto, se houver muito conteúdo irrelevante no artigo, a pontuação tardia levará em conta o "ruído" e causará regressão no desempenho e degradação da precisão. Por exemplo, o NarrativeQA e o 2WikiMultiHopQA não têm um desempenho tão bom quanto o chunking simples porque há muitas informações irrelevantes nesses artigos.
O tamanho do bloco tem algum efeito?
A figura a seguir mostra o desempenho dos métodos de chunking simples e chunking tardio em diferentes conjuntos de dados com diferentes tamanhos de pedaços:
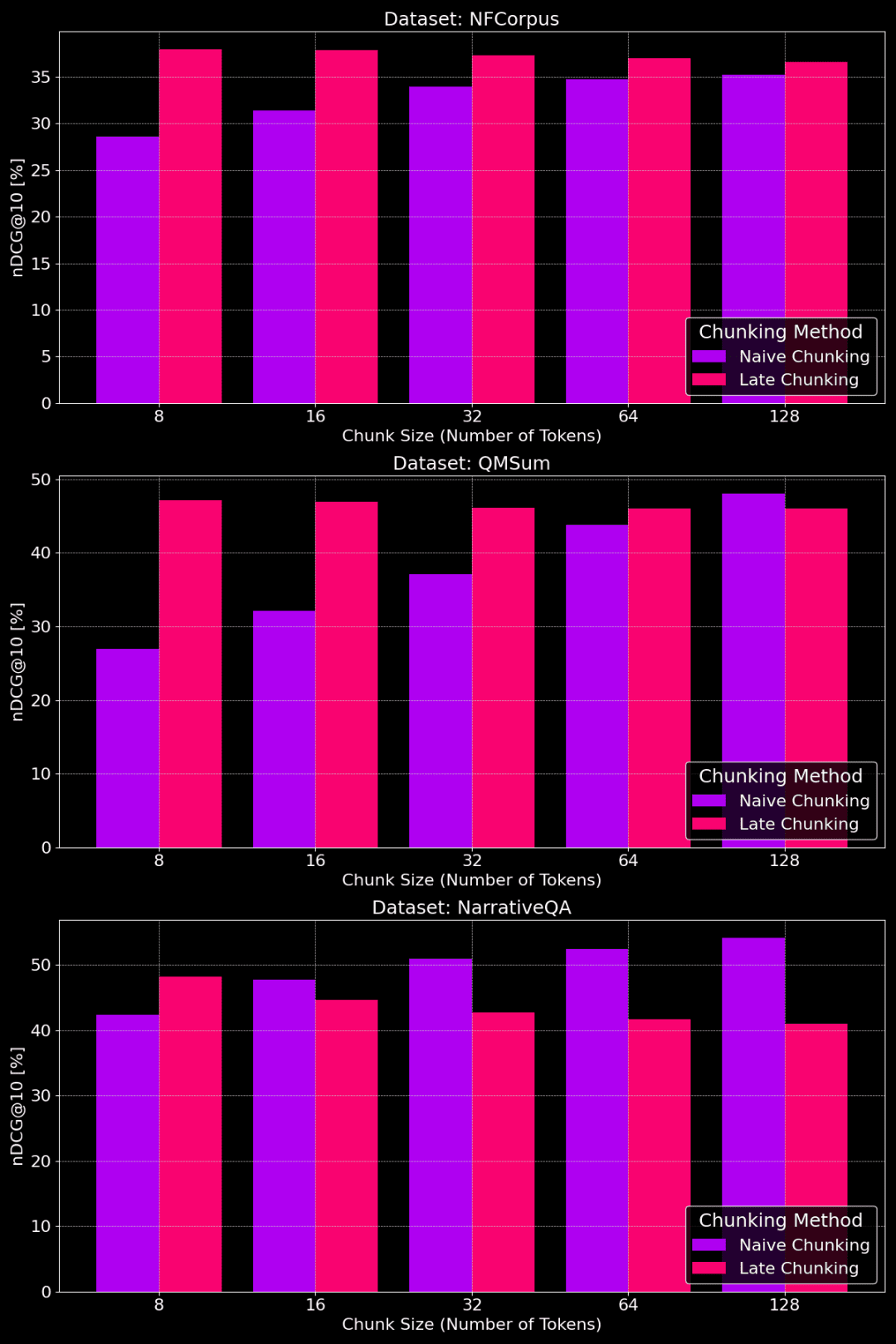
Comparação de desempenho de chunking simples e chunking tardio com diferentes tamanhos de chunk
Como podemos ver na figura, o tamanho ideal do bloco depende, na verdade, da aparência do conjunto de dados específico.
Para o método de divisão tardia, os pedaços menores capturam melhor as informações contextuais e, portanto, funcionam melhor. Em particular, se houver muito conteúdo no conjunto de dados que não esteja relacionado ao tópico (como no caso do conjunto de dados NarrativeQA), o excesso de contexto pode introduzir ruído e prejudicar o desempenho.
Para o chunking simples, os blocos maiores às vezes funcionam melhor porque as informações contidas são mais abrangentes e têm menos perdas. Entretanto, às vezes os blocos são muito grandes e as informações ficam muito confusas, o que, por sua vez, reduz a precisão da recuperação. Portanto, o tamanho ideal do bloco precisa ser ajustado ao conjunto de dados e à tarefa específicos, e não há uma resposta única para todos.
Depois de entender as vantagens e desvantagens das diferentes estratégias de fragmentação, como escolher a correta?
1) Onde a vetorização de texto completo (sem chunking) é apropriada?
- O tema é singular, com as principais informações centralizadas no início:Por exemplo, em notícias estruturadas, as principais informações geralmente estão nas manchetes e nos parágrafos iniciais. Nesse caso, o uso direto da vetorização de texto completo geralmente oferece bons resultados porque o modelo captura as informações principais.
- Em geral, colocar o máximo possível de conteúdo de texto no modelo não afetará os resultados da recuperação. Entretanto, os modelos de texto longo tendem a dar mais atenção à parte inicial (título, introdução etc.), e as informações nas partes intermediárias e finais podem ser ignoradas. Portanto, se as principais informações estiverem no meio ou no final do artigo, esse método será muito menos eficaz.
- Os resultados experimentais detalhados são fornecidos em:https://jina.ai/news/still-need-chunking-when-long-context-models-can-do-it-all
2) Onde o Naive Chunking é apropriado?
- Variedade de tópicos, necessidade de recuperar informações específicasSe o seu texto contiver mais de um tópico ou se uma consulta do usuário tiver como alvo um fato específico no texto, o chunking simples é uma boa opção. Ele pode efetivamente evitar a diluição de informações e melhorar a precisão da recuperação de informações específicas.
- Necessidade de mostrar snippets de texto localizadosEstratégia de chunking: semelhante a um mecanismo de pesquisa, a necessidade de exibir trechos de texto relacionados à consulta nos resultados exige uma estratégia de chunking.
- Além disso, o chunking afeta o espaço de armazenamento e o tempo de processamento, pois é necessário vetorizar mais blocos de texto.
3) Onde se encaixa o Late Chunking?
- Coerência temática, necessidade de informações contextuaisPara textos longos com tópicos coerentes, como redações, relatórios longos etc., o método de particionamento tardio pode reter com eficácia as informações contextuais para entender melhor a semântica geral do texto. Ele é especialmente adequado para tarefas que exigem a compreensão da relação entre diferentes partes de um texto, como compreensão de leitura e correspondência semântica de textos longos.
- Necessidade de equilibrar detalhes locais com a semântica globalO método de divisão tardia pode equilibrar efetivamente os detalhes locais e a semântica global em pedaços menores e, em muitos casos, pode obter melhores resultados do que os outros dois métodos. Entretanto, deve-se observar que, se houver muito conteúdo irrelevante no artigo, o particionamento tardio afetará o efeito devido à consideração dessas informações irrelevantes.
chegar a um veredicto
A seleção de uma estratégia de vetorização de textos longos é uma questão complexa, sem uma solução única que sirva para todos, e requer a consideração das características dos dados e dos objetivos de recuperação, incluindo o comprimento do texto mencionado anteriormente, o número de tópicos e a localização das principais informações.
Neste artigo, esperamos oferecer uma estrutura de análise comparativa sobre diferentes estratégias de fragmentação e fornecer algumas referências por meio de resultados experimentais. Na aplicação prática, você pode comparar mais experimentos e escolher a estratégia mais adequada para o seu cenário.
Se você estiver interessado em vetorização de textos longosjina-embeddings-v3Oferecendo recursos avançados de processamento de texto longo, suporte a vários idiomas e pontuação tardia, vale a pena experimentar.
© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Publicações relacionadas



Nenhum comentário...