
Ajuste fino do modelo DeepSeek R1 para permitir Q&A médica de precisão: revelando o potencial da IA de código aberto

DeepSeek Introduziu uma série de modelos de inferência avançados para desafiar a posição da OpenAI no setor, eTotalmente gratuito, sem restrições de usoO programa foi desenvolvido para beneficiar todos os usuários.
Neste artigo, descrevemos como fazer o ajuste fino do modelo DeepSeek-R1-Distill-Llama-8B usando o conjunto de dados Medical Mind Chain da Hugging Face. Essa versão lite do DeepSeek-R1 obtido pelo ajuste fino do modelo Llama 3 8B nos dados gerados pelo DeepSeek-R1, apresenta inferência superior semelhante ao modelo original.

Decodificação do DeepSeek R1
O DeepSeek-R1 e o DeepSeek-R1-Zero superam o modelo o1 da OpenAI em tarefas de matemática, programação e raciocínio lógico.Vale a pena mencionar que tanto o R1 quanto o R1-Zero são modelos de código aberto..
DeepSeek-R1-Zero
O DeepSeek-R1-Zero é o primeiro modelo de código aberto a ser treinado exclusivamente com o uso de RL (Reinforcement Learning, aprendizado por reforço) em larga escala, em oposição aos modelos tradicionais que usam SFT (Supervised Fine-Tuning, ajuste fino supervisionado) como etapa inicial. Essa abordagem inovadora capacita os modelos a explorar de forma independente o raciocínio CoT (Chain-of-Thought), permitindo que eles resolvam problemas complexos e otimizem o resultado de forma iterativa. No entanto, essa abordagem também apresenta alguns desafios, como a possível duplicação de etapas de raciocínio, legibilidade reduzida e estilos de linguagem inconsistentes, o que, por sua vez, afeta a clareza e a utilidade do modelo.
DeepSeek-R1
O lançamento do DeepSeek-R1 tem como objetivo superar as deficiências do DeepSeek-R1-Zero. Ao introduzir dados de início frio antes do aprendizado por reforço, o DeepSeek-R1 estabelece uma base mais sólida para tarefas de inferência e não-inferência. Essa estratégia de treinamento em vários estágios permite que o DeepSeek-R1 atinja um nível de desempenho líder em relação ao OpenAI-o1 em benchmarks de matemática, programação e inferência, além de melhorar significativamente a legibilidade e a coerência do resultado.
Modelo de destilação do DeepSeek
O DeepSeek também introduziu uma família de modelos de destilação. Esses modelos são menores e mais eficientes, mantendo um excelente desempenho de inferência. Embora os tamanhos dos parâmetros variem de 1,5B a 70B, todos esses modelos mantêm fortes recursos de inferência. Entre eles, o DeepSeek-R1-Distill-Qwen-32B supera o modelo OpenAI-o1-mini em vários benchmarks. Os modelos de menor escala herdam os padrões de inferência dos modelos maiores, demonstrando totalmente a eficácia da técnica de destilação.
-1")
Ajuste fino do DeepSeek R1 em ação
1. configuração ambiental
Nesse exercício de ajuste fino do modelo, o Kaggle foi escolhido como IDE de nuvem devido aos recursos gratuitos de GPU fornecidos pelo Kaggle. Duas GPUs T4 foram escolhidas inicialmente, mas apenas uma foi usada. Se os usuários desejarem realizar o ajuste fino do modelo em um computador local, eles precisarão ter pelo menosUma placa de vídeo RTX 3090 com 16 GB de memória..
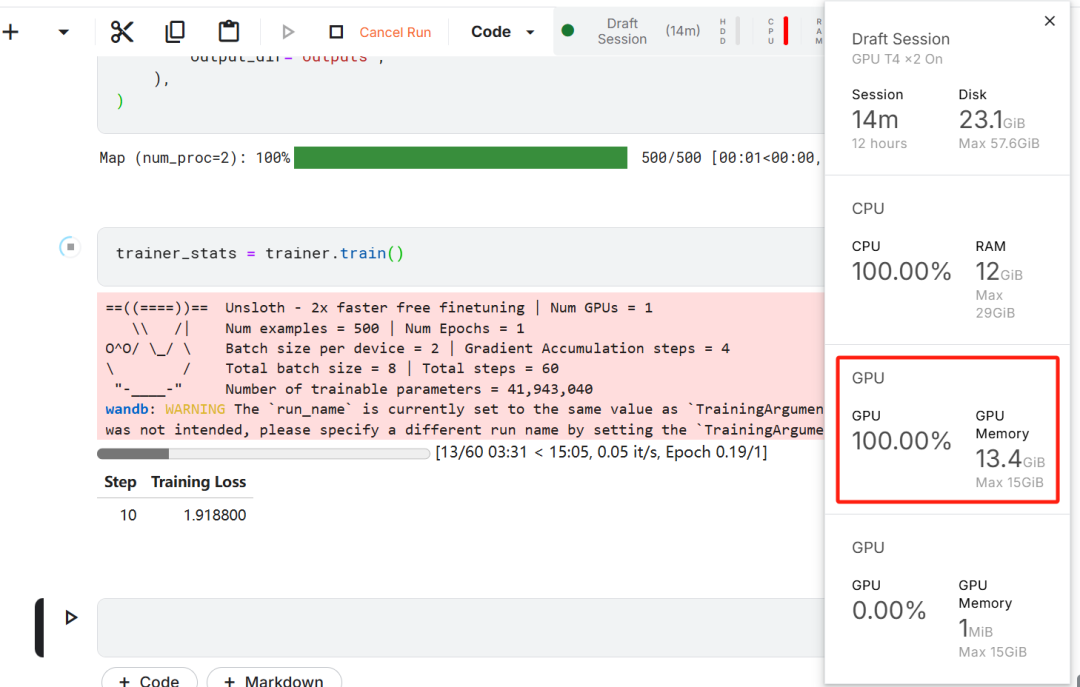
Primeiro, inicie um novo notebook do Kaggle com o Hugging Face do usuário token responder cantando Pesos & O token Biases é adicionado como uma chave.
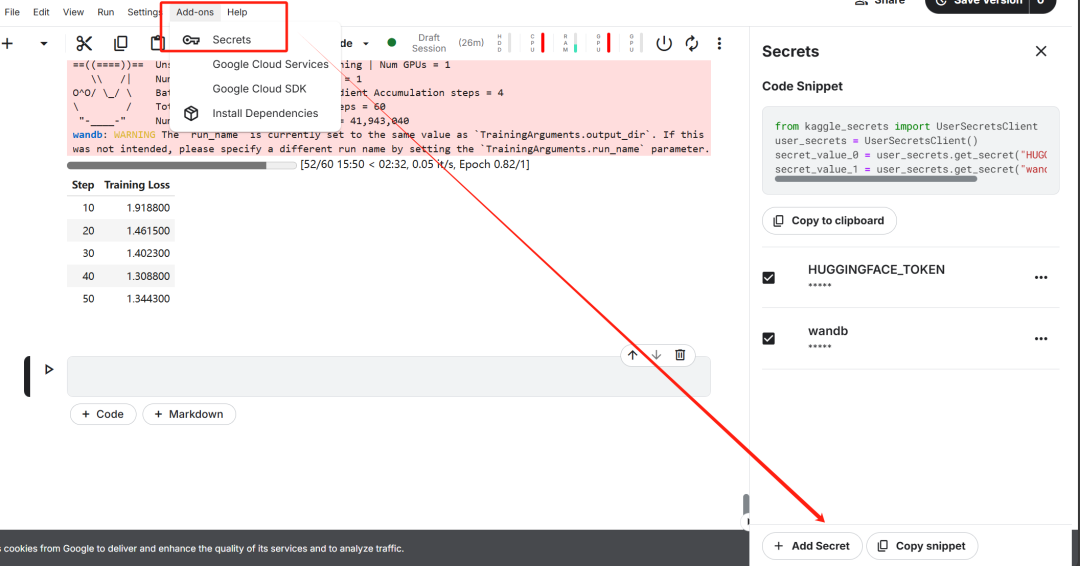
Após concluir a configuração da chave, instale o sem preguiça O Unsloth é uma estrutura de código aberto projetada para dobrar a velocidade de ajuste fino de modelos de linguagem grandes (LLMs) e melhorar significativamente a eficiência da memória.
%%capture
!pip install unsloth
!pip install --force-reinstall --no-cache-dir --no-deps git+https://github.com/unslothai/unsloth.git
Em seguida, faça login na CLI do Hugging Face. Essa etapa é fundamental para os downloads subsequentes do conjunto de dados e o upload do modelo ajustado.
from huggingface_hub import login
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
hf_token = user_secrets.get_secret("HUGGINGFACE_TOKEN")
login(hf_token)
Em seguida, faça login no Weights & Biases (wandb) e crie um novo projeto para acompanhar o curso do experimento e ajustar o progresso.
import wandb
wb_token = user_secrets.get_secret("wandb")
wandb.login(key=wb_token)
run = wandb.init(
project='Fine-tune-DeepSeek-R1-Distill-Llama-8B on Medical COT Dataset',
job_type="training",
anonymous="allow"
)
2. carregamento de modelos e tokenizadores
Na prática deste artigo, foi carregada a versão Unsloth do modelo DeepSeek-R1-Distill-Llama-8B.
https://huggingface.co/unsloth/DeepSeek-R1-Distill-Llama-8B
Para otimizar o uso da memória e melhorar o desempenho, o modelo foi escolhido para ser carregado em uma forma quantificada de 4 bits.
from unsloth import FastLanguageModel
max_seq_length = 2048
dtype = None
load_in_4bit = True
model, tokenizer = FastLanguageModel.from_pretrained(
model_name="unsloth/DeepSeek-R1-Distill-Llama-8B",
max_seq_length=max_seq_length,
dtype=dtype,
load_in_4bit=load_in_4bit,
token=hf_token,
)
3. cartilha de capacidade de raciocínio do modelo de pré-ajuste fino
Para construir um modelo de prompt para o modelo, foi definido um prompt do sistema com espaços reservados para a geração de perguntas e respostas. O objetivo desse prompt é orientar o modelo por meio de um processo de raciocínio passo a passo e, por fim, gerar respostas logicamente rigorosas e precisas.
prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
### Instruction:
You are a medical expert with advanced knowledge in clinical reasoning, diagnostics, and treatment planning.
Please answer the following medical question.
### Question:
{}
### Response:
<think>{}"""
Neste exemplo, uma mensagem é enviada para o prompt_style forneceram um problema médico e o transformaram em tokens e, posteriormente, esses tokens passado para o modelo para gerar a resposta.
question = "A 61-year-old woman with a long history of involuntary urine loss during activities like coughing or sneezing but no leakage at night undergoes a gynecological exam and Q-tip test. Based on these findings, what would cystometry most likely reveal about her residual volume and detrusor contractions?"
FastLanguageModel.for_inference(model)
inputs = tokenizer([prompt_style.format(question, "")], return_tensors="pt").to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
use_cache=True,
)
response = tokenizer.batch_decode(outputs)
print(response[0].split("### Response:")[1])
O cerne da pergunta médica acima é:
Uma mulher de 61 anos com um longo histórico de perda involuntária de urina durante atividades como tosse ou espirro, mas sem perda noturna. Ela foi submetida a um exame ginecológico e a um teste com cotonete. Com base nesses achados, que informações a cistometria provavelmente revelaria sobre o volume residual de urina e o estado da contração do detrusor?
Mesmo sem ajuste fino, o modelo gera cadeias de pensamento com sucesso e executa um raciocínio rigoroso antes de dar a resposta final, sendo todo o processo de raciocínio encapsulado no <think></think> Marcado dentro de.
Então, por que o ajuste fino ainda é necessário? Embora o modelo exiba um processo de raciocínio detalhado, sua representação é um pouco longa e não é suficientemente concisa. Além disso, as respostas finais são apresentadas como listas com marcadores, o que se desvia da estrutura e do estilo do conjunto de dados que se espera que seja ajustado.
4. carregamento e pré-processamento de conjuntos de dados
O modelo de prompt foi ajustado para acomodar as necessidades de processamento do conjunto de dados, adicionando um terceiro espaço reservado para a coluna Complex Chain-of-Thought (Cadeia de pensamento complexa) no modelo de prompt.
train_prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
### Instruction:
You are a medical expert with advanced knowledge in clinical reasoning, diagnostics, and treatment planning.
Please answer the following medical question.
### Question:
{}
### Response:
<think>
{}
</think>
{}"""
Uma função Python foi escrita para criar uma coluna de "texto" no conjunto de dados. O conteúdo da coluna consiste em um modelo de prompt de treinamento com espaços reservados preenchidos com perguntas, cadeias de pensamento e respostas, respectivamente.
EOS_TOKEN = tokenizer.eos_token # Must add EOS_TOKEN
def formatting_prompts_func(examples):
inputs = examples["Question"]
cots = examples["Complex_CoT"]
outputs = examples["Response"]
texts = []
for input, cot, output in zip(inputs, cots, outputs):
text = train_prompt_style.format(input, cot, output) + EOS_TOKEN
texts.append(text)
return {
"text": texts,
}
As primeiras 500 amostras do conjunto de dados FreedomIntelligence/medical-o1-reasoning-SFT foram carregadas do Hugging Face Hub.
https://huggingface.co/datasets/FreedomIntelligence/medical-o1-reasoning-SFT?row=46
Posteriormente, usando o formatting_prompts_func mapeia a coluna "text" do conjunto de dados.
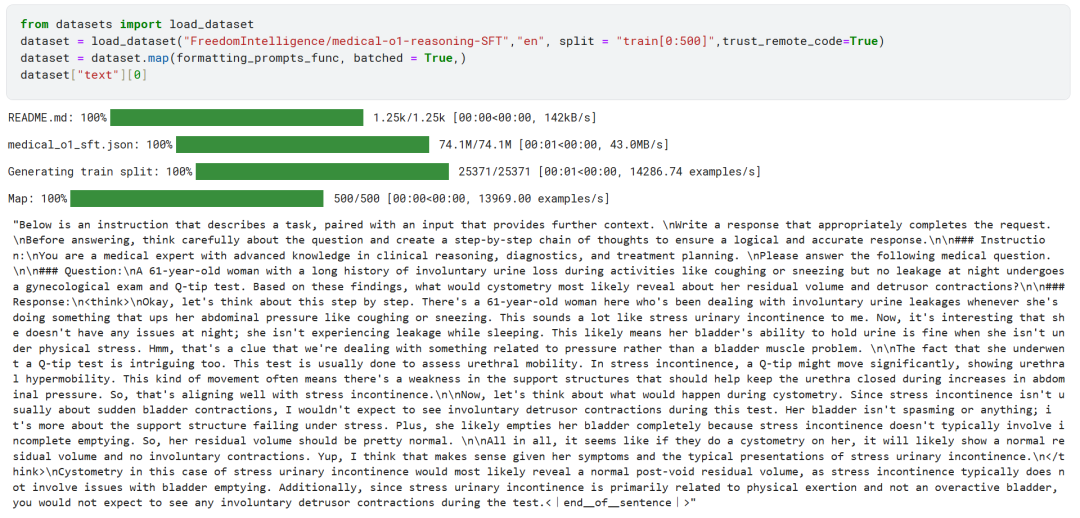
Como você pode ver acima, a coluna "texto" foi integrada com sucesso às dicas, instruções, cadeias de pensamento e respostas finais do sistema.
5. configuração do modelo
O modelo é configurado usando a técnica Low-Rank Adapter, definindo o módulo de destino.
model = FastLanguageModel.get_peft_model(
model,
r=16,
target_modules=[
"q_proj",
"k_proj",
"v_proj",
"o_proj",
"gate_proj",
"up_proj",
"down_proj",
],
lora_alpha=16,
lora_dropout=0,
bias="none",
use_gradient_checkpointing="unsloth", # True or "unsloth" for very long context
random_state=3407,
use_rslora=False,
loftq_config=None,
)
Em seguida, os parâmetros de treinamento e o instrutor (Trainer) foram configurados. O modelo, o tokenizador, o conjunto de dados e outros parâmetros importantes de treinamento foram fornecidos ao treinador para otimizar o processo de ajuste fino do modelo.
from trl import SFTTrainer
from transformers import TrainingArguments
from unsloth import is_bfloat16_supported
trainer = SFTTrainer(
model=model,
tokenizer=tokenizer,
train_dataset=dataset,
dataset_text_field="text",
max_seq_length=max_seq_length,
dataset_num_proc=2,
args=TrainingArguments(
per_device_train_batch_size=2,
gradient_accumulation_steps=4,
# Use num_train_epochs = 1, warmup_ratio for full training runs!
warmup_steps=5,
max_steps=60,
learning_rate=2e-4,
fp16=not is_bfloat16_supported(),
bf16=is_bfloat16_supported(),
logging_steps=10,
optim="adamw_8bit",
weight_decay=0.01,
lr_scheduler_type="linear",
seed=3407,
output_dir="outputs",
),
)
6. treinamento de modelos
trainer_stats = trainer.train()
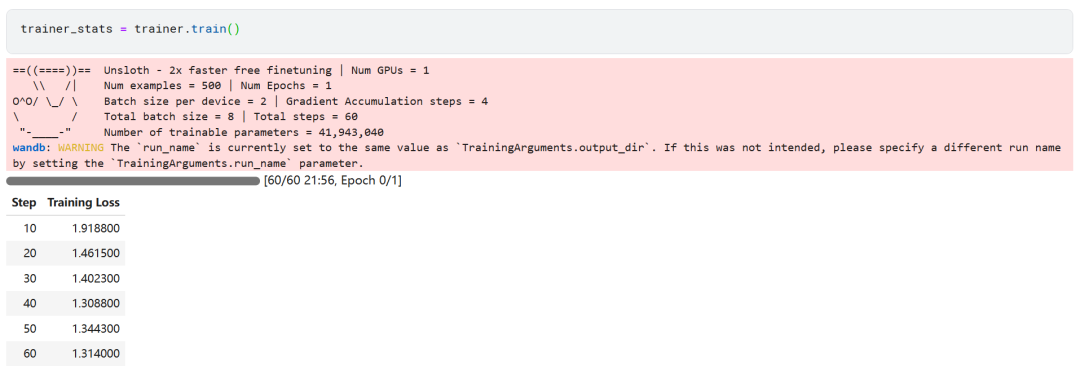
O processo de treinamento do modelo levou 22 minutos. A perda de treinamento (perda) diminui gradualmente, o que é um sinal positivo de que o desempenho do modelo melhorou.
Os usuários podem visitar o site da Weights & Biases para visualizar o relatório completo de avaliação do modelo.
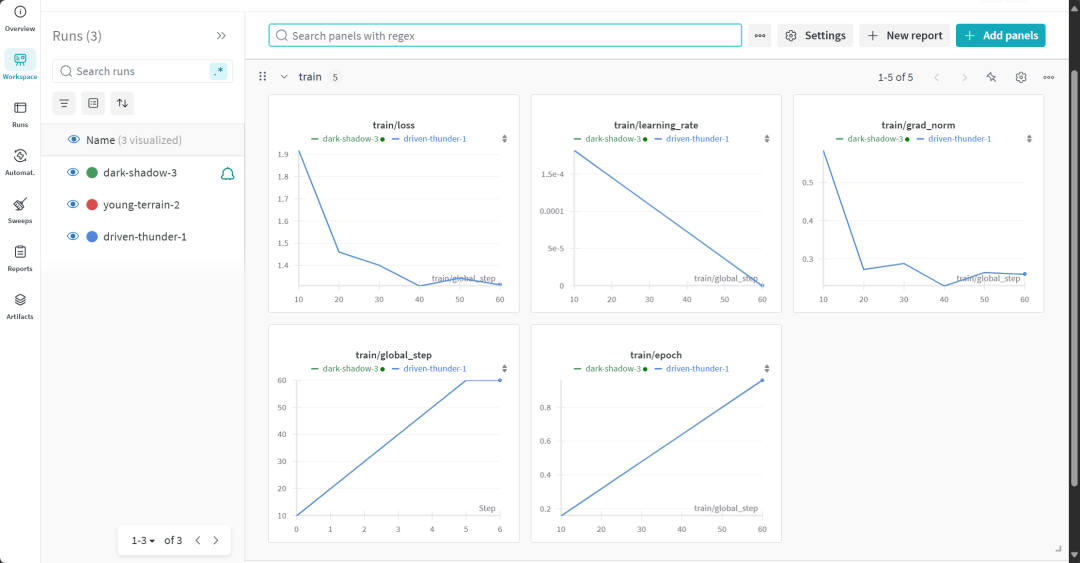
7. avaliação da capacidade de raciocínio do modelo ajustado
Para a análise comparativa, as mesmas perguntas foram feitas novamente ao modelo ajustado e antes do ajuste fino para observar a mudança no desempenho do modelo.
question = "A 61-year-old woman with a long history of involuntary urine loss during activities like coughing or sneezing but no leakage at night undergoes a gynecological exam and Q-tip test. Based on these findings, what would cystometry most likely reveal about her residual volume and detrusor contractions?"
FastLanguageModel.for_inference(model) # Unsloth has 2x faster inference!
inputs = tokenizer([prompt_style.format(question, "")], return_tensors="pt").to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
use_cache=True,
)
response = tokenizer.batch_decode(outputs)
print(response[0].split("### Response:")[1])
Os resultados experimentais mostram que a qualidade da saída do modelo ajustado foi significativamente aprimorada e as respostas são mais precisas. A cadeia de pensamentos foi apresentada de forma mais concisa e a resposta final foi mais direta e clara em apenas um parágrafo, indicando o sucesso desse ajuste fino do modelo.

8. armazenamento local de modelos
Agora, salve o adaptador, o modelo completo e o tokenizador localmente para uso em outros projetos.
new_model_local = "DeepSeek-R1-Medical-COT"
model.save_pretrained(new_model_local)
tokenizer.save_pretrained(new_model_local)
model.save_pretrained_merged(new_model_local, tokenizer, save_method="merged_16bit")
9. modelo carregado no Hugging Face Hub
Adaptadores, tokenizadores e modelos completos também foram enviados para o Hugging Face Hub, com o objetivo de permitir que a comunidade de IA faça uso total desse modelo ajustado e o integre facilmente em seus sistemas.
new_model_online = "realyinchen/DeepSeek-R1-Medical-COT"
model.push_to_hub(new_model_online)
tokenizer.push_to_hub(new_model_online)
model.push_to_hub_merged(new_model_online, tokenizer, save_method="merged_16bit")
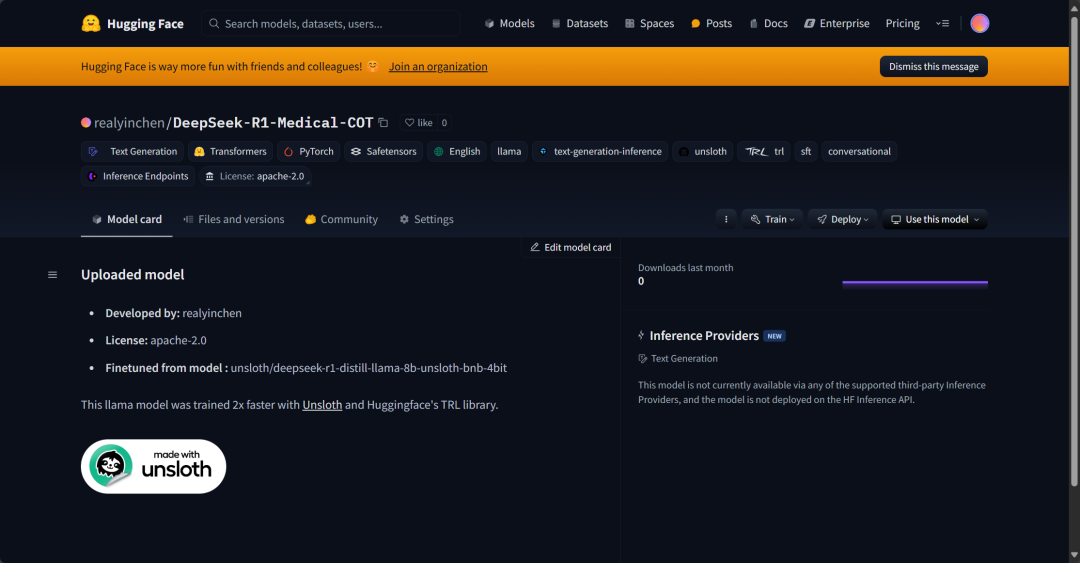
resumos
O campo da inteligência artificial (IA) está passando por mudanças rápidas. O surgimento da comunidade de código aberto representa um grande desafio para o cenário da IA, que tem sido dominado por modelos proprietários nos últimos três anos. Os modelos de linguagem grande (LLMs) de código aberto estão cada vez mais rápidos e eficientes, tornando mais fácil do que nunca ajustá-los com menos recursos computacionais e de memória.
Este documento fornece uma visão detalhada do DeepSeek R1 e detalha como sua versão lite pode ser ajustada para aplicação em cenários de perguntas e respostas médicas. O modelo de inferência ajustado não apenas oferece melhorias significativas de desempenho, mas também o torna prático para uso em áreas importantes, como medicina, serviços de emergência e saúde.
Em resposta ao lançamento do DeepSeek R1, a OpenAI também introduziu rapidamente duas ferramentas importantes: um modelo de inferência mais avançado, o3, e o Operador O último conta com o novo agente de uso do computador (CUA, Computer Usage Agent). Computador Use Agent) que demonstra a capacidade de navegar de forma autônoma em sites e executar tarefas complexas.
Código-fonte:
https://www.kaggle.com/code/realyinchen/deepseek-r1-medical-cot
© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Artigos relacionados


Nenhum comentário...