
Dominando o Crawl4AI: preparando dados da Web de alta qualidade para LLM e RAG

As estruturas tradicionais de rastreamento da Web são versáteis, mas geralmente exigem limpeza e formatação adicionais ao processar dados, o que torna sua integração com os modelos de linguagem grande (LLMs) relativamente complexa. A saída de muitas ferramentas (por exemplo, dados brutos HTML ou não estruturado JSON) contém muito ruído e não é adequado para uso direto em cenários como o Retrieval Augmented Generation (RAG), pois degradaria o LLM Eficiência e precisão do processamento.
Crawl4AI oferece um tipo diferente de solução. Ela se concentra na geração direta de energia limpa e estruturada Markdown Conteúdo formatado. Esse formato preserva a estrutura semântica do texto original (por exemplo, cabeçalhos, listas, blocos de código) e, ao mesmo tempo, remove de forma inteligente elementos estranhos, como navegação, anúncios, rodapés etc., o que o torna ideal para ser usado como um LLM ou para a criação de produtos de alta qualidade RAG Conjunto de dados.Crawl4AI é um projeto totalmente de código aberto que não usa API A chave também não está definida em um limite de pay-per-view.
Instalação e configuração
Uso recomendado uv Criar e ativar um Python ambiente virtual para gerenciar as dependências do projeto.uv Ele se baseia em um Rust Desenvolvido Emergente Python gerenciador de pacotes, com sua vantagem significativa de velocidade (geralmente sobre o pip (3 a 5 vezes mais rápido) e resolução eficiente de dependências paralelas.
# 创建虚拟环境
uv venv crawl4ai-env
# 激活环境
# Windows
# crawl4ai-env\Scripts\activate
# macOS/Linux
source crawl4ai-env/bin/activate
Depois que o ambiente for ativado, use o comando uv montagem Crawl4AI Biblioteca principal:
uv pip install crawl4ai
Após a conclusão da instalação, execute o comando de inicialização, que cuidará da instalação ou atualização do Playwright Drivers de navegador necessários (por exemplo Chromium) e realizar inspeções ambientais.Playwright É uma daquelas coisas que é feita de Microsoft desenvolveu bibliotecas de automação de navegador.Crawl4AI Use-o para simular interações reais do usuário para poder lidar com o conteúdo carregado dinamicamente do JavaScript Site pesado.
crawl4ai-setup
Se você encontrar problemas relacionados ao driver do navegador, poderá tentar instalá-lo manualmente:
# 手动安装 Playwright 浏览器及依赖
python -m playwright install --with-deps chromium
Conforme necessário, isso pode ser feito por uv Instalação de pacotes de extensão contendo recursos adicionais:
# 安装文本聚类功能 (依赖 PyTorch)
uv pip install "crawl4ai[torch]"
# 安装 Transformers 支持 (用于本地 AI 模型)
uv pip install "crawl4ai[transformer]"
# 安装所有可选功能
uv pip install "crawl4ai[all]"
Exemplo básico de rastreamento
esse valor ou menos Python O script demonstra o Crawl4AI O uso básico do Markdown.
import asyncio
from crawl4ai import AsyncWebCrawler
async def main():
# 初始化异步爬虫
async with AsyncWebCrawler() as crawler:
# 执行爬取任务
result = await crawler.arun(
url="https://www.sitepoint.com/react-router-complete-guide/"
)
# 检查爬取是否成功
if result.success:
# 输出结果信息
print(f"标题: {result.title}")
print(f"提取的 Markdown ({len(result.markdown)} 字符):")
# 仅显示前 300 个字符作为预览
print(result.markdown[:300] + "...")
# 将完整的 Markdown 内容保存到文件
with open("example_content.md", "w", encoding="utf-8") as f:
f.write(result.markdown)
print(f"内容已保存到 example_content.md")
else:
# 输出错误信息
print(f"爬取失败: {result.url}")
print(f"状态码: {result.status_code}")
print(f"错误信息: {result.error_message}")
if __name__ == "__main__":
asyncio.run(main())
Após a execução desse script, oCrawl4AI ativará Playwright Acesso controlado do navegador a dados específicos URLPágina de execução JavaScriptEm seguida, identifica e extrai de forma inteligente as principais áreas de conteúdo, filtra os elementos que causam distração e, por fim, gera um conteúdo limpo. Markdown Documentação.
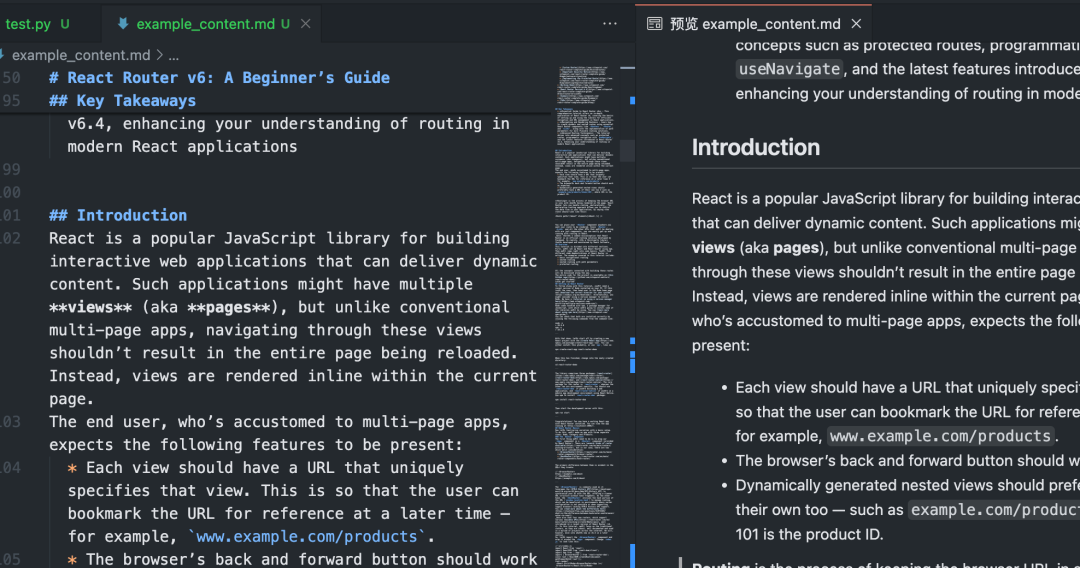
Rastreamento em lote e paralelo
processo múltiplo URL quandoCrawl4AI de processamento paralelo pode aumentar drasticamente a eficiência. Ao configurar o CrawlerRunConfig acertou em cheio concurrency que controla o número de páginas processadas simultaneamente.
import asyncio
from crawl4ai import AsyncWebCrawler, BrowserConfig, CrawlerRunConfig, CacheMode
async def main():
urls = [
"https://example.com/page1",
"https://example.com/page2",
"https://example.com/page3",
# 添加更多 URL...
]
# 浏览器配置:无头模式,增加超时
browser_config = BrowserConfig(
headless=True,
timeout=45000, # 45秒超时
)
# 爬取运行配置:设置并发数,禁用缓存以获取最新内容
run_config = CrawlerRunConfig(
concurrency=5, # 同时处理 5 个页面
cache_mode=CacheMode.BYPASS # 禁用缓存
)
results = []
async with AsyncWebCrawler(browser_config=browser_config) as crawler:
# 使用 arun_many 进行批量并行爬取
# 注意:arun_many 需要将 run_config 列表传递给 configs 参数
# 如果所有 URL 使用相同配置,可以创建一个配置列表
configs = [run_config.clone(url=url) for url in urls] # 为每个URL克隆配置并设置URL
# arun_many 返回一个异步生成器
async for result in crawler.arun_many(configs=configs):
if result.success:
results.append(result)
print(f"已完成: {result.url}, 获取了 {len(result.markdown)} 字符")
else:
print(f"失败: {result.url}, 错误: {result.error_message}")
# 将所有成功的结果合并到一个文件
with open("combined_results.md", "w", encoding="utf-8") as f:
for i, result in enumerate(results):
f.write(f"## {result.title}\n\n")
f.write(result.markdown)
f.write("\n\n---\n\n")
print(f"所有成功内容已合并保存到 combined_results.md")
if __name__ == "__main__":
asyncio.run(main())
tomar nota deO código acima usa o arun_many que é a maneira recomendada de lidar com grandes listas de URLs, em vez de fazer um looping por meio de uma chamada ao método arun Mais eficiente.arun_many É necessária uma lista de configurações, cada uma correspondendo a um URL. Se todos os URL Usando a mesma configuração básica, o clone() cria uma cópia e define um URL.
Extração de dados estruturados (com base em seletor)
além de Markdown(matemática) gêneroCrawl4AI Também disponível CSS Seletor ou XPath Extrai dados estruturados, ideais para sites com formatos de dados regulares.
import asyncio
import json
from crawl4ai import AsyncWebCrawler, ExtractorConfig
async def main():
# 定义提取规则 (CSS 选择器)
extractor_config = ExtractorConfig(
strategy="css", # 明确指定策略为 CSS
rules={
"products": {
"selector": "div.product-card", # 主选择器
"type": "list",
"properties": {
"name": {"selector": "h2.product-title", "type": "text"},
"price": {"selector": ".price span", "type": "text"},
"link": {"selector": "a.product-link", "type": "attribute", "attribute": "href"}
}
}
}
)
async with AsyncWebCrawler() as crawler:
result = await crawler.arun(
url="https://example-shop.com/products",
extractor_config=extractor_config
)
if result.success and result.extracted_data:
extracted_data = result.extracted_data
with open("products.json", "w", encoding="utf-8") as f:
json.dump(extracted_data, f, ensure_ascii=False, indent=2)
print(f"已提取 {len(extracted_data.get('products', []))} 个产品信息")
print("数据已保存到 products.json")
elif not result.success:
print(f"爬取失败: {result.error_message}")
else:
print("未提取到数据或提取规则匹配失败")
if __name__ == "__main__":
asyncio.run(main())
Essa abordagem não requer LLM A intervenção, que é rápida e de baixo custo, é adequada para cenários em que o elemento-alvo é claro.
Extração de dados aprimorada por IA
Para páginas com estruturas complexas ou sem padrão fixo, você pode usar o LLM Realizar extração inteligente.
import asyncio
import json
from crawl4ai import AsyncWebCrawler, BrowserConfig, AIExtractorConfig
async def main():
# 配置 AI 提取器
ai_config = AIExtractorConfig(
provider="openai", # 或 "local", "anthropic" 等
model="gpt-4o-mini", # 使用 OpenAI 的模型
# api_key="YOUR_OPENAI_API_KEY", # 如果环境变量未设置,在此提供
schema={
"type": "object",
"properties": {
"article_summary": {"type": "string", "description": "A brief summary of the article."},
"key_topics": {"type": "array", "items": {"type": "string"}, "description": "List of main topics discussed."},
"sentiment": {"type": "string", "enum": ["positive", "negative", "neutral"], "description": "Overall sentiment of the article."}
},
"required": ["article_summary", "key_topics"]
},
instruction="Extract the summary, key topics, and sentiment from the provided article text."
)
browser_config = BrowserConfig(timeout=60000) # AI 处理可能需要更长时间
async with AsyncWebCrawler(browser_config=browser_config) as crawler:
result = await crawler.arun(
url="https://example-news.com/article/complex-analysis",
ai_extractor_config=ai_config
)
if result.success and result.ai_extracted:
ai_extracted = result.ai_extracted
print("AI 提取的数据:")
print(json.dumps(ai_extracted, indent=2, ensure_ascii=False))
# 也可以选择保存到文件
# with open("ai_extracted_data.json", "w", encoding="utf-8") as f:
# json.dump(ai_extracted, f, ensure_ascii=False, indent=2)
elif not result.success:
print(f"爬取失败: {result.error_message}")
else:
print("AI 未能提取所需数据。")
if __name__ == "__main__":
asyncio.run(main())
A extração de IA oferece grande flexibilidade para entender o conteúdo e gerar resultados estruturados sob demanda, mas incorre em custos adicionais API Custo da chamada (se estiver usando um serviço de nuvem) LLM) e o tempo de processamento. Selecione o modelo local (por exemplo Mistral, Llama) podem reduzir os custos e proteger a privacidade, mas têm requisitos de hardware locais.
Configurações avançadas e dicas
Crawl4AI Oferece uma grande variedade de opções de configuração para lidar com cenários complexos.
Configuração do navegador (BrowserConfig)
BrowserConfig Controla a inicialização e o comportamento do próprio navegador.
from crawl4ai import BrowserConfig
config = BrowserConfig(
browser_type="firefox", # 使用 Firefox 浏览器
headless=False, # 显示浏览器界面,方便调试
user_agent="MyCustomCrawler/1.0", # 设置自定义 User-Agent
proxy_config={ # 配置代理服务器
"server": "http://proxy.example.com:8080",
"username": "proxy_user",
"password": "proxy_password"
},
ignore_https_errors=True, # 忽略 HTTPS 证书错误 (开发环境常用)
use_persistent_context=True, # 启用持久化上下文
user_data_dir="./my_browser_profile", # 指定用户数据目录,用于保存 cookies, local storage 等
timeout=60000, # 全局浏览器操作超时 (毫秒)
verbose=True # 打印更详细的日志
)
# 在初始化 AsyncWebCrawler 时传入
# async with AsyncWebCrawler(browser_config=config) as crawler:
# ...
Rastrear a configuração do tempo de execução (CrawlerRunConfig)
CrawlerRunConfig Controle único arun() talvez arun_many() O comportamento específico da chamada.
from crawl4ai import CrawlerRunConfig, CacheMode
run_config = CrawlerRunConfig(
cache_mode=CacheMode.READ_ONLY, # 只读缓存,不写入新缓存
check_robots_txt=True, # 检查并遵守 robots.txt 规则
wait_until="networkidle", # 等待网络空闲再提取,适合JS动态加载内容
wait_for="css:div#final-content", # 等待特定 CSS 选择器元素出现
js_code="window.scrollTo(0, document.body.scrollHeight);", # 页面加载后执行 JS 代码 (例如滚动到底部触发加载)
scan_full_page=True, # 尝试自动滚动页面以加载所有内容 (用于无限滚动)
screenshot=True, # 截取页面截图 (结果在 result.screenshot,Base64编码)
pdf=True, # 生成页面 PDF (结果在 result.pdf,Base64编码)
word_count_threshold=50, # 过滤掉少于 50 个单词的文本块
excluded_tags=["header", "nav", "footer", "aside"], # 从 Markdown 中排除特定 HTML 标签
exclude_external_links=True # 不提取外部链接
)
# 在调用 arun() 或创建配置列表给 arun_many() 时传入
# result = await crawler.arun(url="...", config=run_config)
Manipulação de JavaScript e conteúdo dinâmico
graças a Playwright(matemática) gêneroCrawl4AI Lida bem com as dependências JavaScript Site renderizado. Configuração principal:
wait_until: Definido como"networkidle"talvez"load"Geralmente é um pouco mais eficiente do que o padrão"domcontentloaded"Mais adequado para páginas dinâmicas.wait_for: espera por um elemento específico ouJavaScriptCondições atendidas.js_codePersonalização: executar a personalização após o carregamento da páginaJavaScriptcomo clicar em botões e rolar páginas.scan_full_pageTratamento automático de páginas comuns de rolagem infinita.delay_before_return_htmlAdicionar um pequeno atraso antes da extração para garantir que todos os scripts sejam executados.
Tratamento de erros e depuração
- sonda
result.successNão se esqueça de verificar essa propriedade após cada rastreamento. - confira
result.status_coderesponder cantandoresult.error_messageObter o motivo da falha. - configurar
headless=False: EmBrowserConfigVocê pode observar a operação do navegador e diagnosticar o problema visualmente. - começar a usar
verbose=True: EmBrowserConfigDefina para obter um registro de tempo de execução mais detalhado. - fazer uso de
try...except: Parcelasarun()talvezarun_many()que captura uma possível chamadaPythonExceção.
import asyncio
from crawl4ai import AsyncWebCrawler, BrowserConfig
async def debug_crawl():
# 启用调试模式:显示浏览器,打印详细日志
debug_browser_config = BrowserConfig(headless=False, verbose=True)
async with AsyncWebCrawler(browser_config=debug_browser_config) as crawler:
try:
result = await crawler.arun(url="https://problematic-site.com")
if not result.success:
print(f"Crawl failed: {result.error_message} (Status: {result.status_code})")
else:
print("Crawl successful.")
# ... process result ...
except Exception as e:
print(f"An unexpected error occurred: {e}")
if __name__ == "__main__":
asyncio.run(debug_crawl())
observância robots.txt
Ao realizar um rastreamento da Web, respeite a robots.txt A documentação é uma prática básica de netiqueta e evita o bloqueio de IP.Crawl4AI Ele pode ser processado automaticamente.
existir CrawlerRunConfig configurar check_robots_txt=True::
respectful_config = CrawlerRunConfig(
check_robots_txt=True
)
# result = await crawler.arun(url="https://example.com", config=respectful_config)
# if not result.success and result.status_code == 403:
# print("Access denied by robots.txt")
Crawl4AI Baixado, armazenado em cache e analisado automaticamente robots.txt se a regra proibir o acesso ao arquivo de destino URL(matemática) gêneroarun() falhará.result.success por causa de False(matemática) gênerostatus_code Isso geralmente é 403 com a mensagem de erro apropriada.
Gerenciamento de sessões (Session Management)
Para operações de várias etapas que exigem login ou manutenção de estado (por exemplo, envio de formulário, navegação paginada), o gerenciamento de sessão pode ser usado. Isso pode ser feito adicionando um novo gerenciador de sessão à variável CrawlerRunConfig Especifique o mesmo no session_idO sistema pode ser usado em mais de uma arun() A mesma instância de página do navegador é reutilizada entre as chamadas, preservando a cookies responder cantando JavaScript Status.
import asyncio
from crawl4ai import AsyncWebCrawler, CrawlerRunConfig, CacheMode
async def session_example():
async with AsyncWebCrawler() as crawler:
session_id = "my_unique_session"
# Step 1: Load login page (hypothetical)
login_config = CrawlerRunConfig(session_id=session_id, cache_mode=CacheMode.BYPASS)
await crawler.arun(url="https://example.com/login", config=login_config)
print("Login page loaded.")
# Step 2: Execute JS to fill and submit login form (hypothetical)
login_js = """
document.getElementById('username').value = 'user';
document.getElementById('password').value = 'pass';
document.getElementById('loginButton').click();
"""
submit_config = CrawlerRunConfig(
session_id=session_id,
js_code=login_js,
js_only=True, # 只执行 JS,不重新加载页面
wait_until="networkidle" # 等待登录后跳转完成
)
await crawler.arun(config=submit_config) # 无需 URL,在当前页面执行 JS
print("Login submitted.")
# Step 3: Crawl a protected page within the same session
protected_config = CrawlerRunConfig(session_id=session_id, cache_mode=CacheMode.BYPASS)
result = await crawler.arun(url="https://example.com/dashboard", config=protected_config)
if result.success:
print("Successfully crawled protected page:")
print(result.markdown[:200] + "...")
else:
print(f"Failed to crawl protected page: {result.error_message}")
# 清理会话 (可选,但推荐)
# await crawler.crawler_strategy.kill_session(session_id)
if __name__ == "__main__":
asyncio.run(session_example())
O gerenciamento mais avançado da sessão inclui a exportação e a importação do estado de armazenamento do navegador (cookies, localStorage), permitindo que o login seja mantido entre as execuções do script.
Crawl4AI Oferece um conjunto de recursos avançado e flexível que, quando configurado corretamente, pode extrair de forma eficiente e confiável as informações necessárias de diversos sites e preparar dados de alta qualidade para aplicativos de IA downstream.
© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Artigos relacionados

Nenhum comentário...