


A estrutura GTR: uma nova abordagem para perguntas e respostas entre tabelas com base em gráficos heterogêneos e recuperação hierárquica

1. introdução
Na atual explosão de informações, uma grande quantidade de conhecimento é armazenada na forma de tabelas em páginas da Web, na Wikipédia e em bancos de dados relacionais. No entanto, os sistemas tradicionais de perguntas e respostas geralmente têm dificuldade para lidar com consultas complexas em várias tabelas, o que se tornou um grande desafio no campo da inteligência artificial. Para enfrentar esse desafio, os pesquisadores propuseram GTR (Graph-Table-RAG) Estrutura. A estrutura permite perguntas e respostas entre tabelas mais eficientes, organizando dados tabulares em gráficos heterogêneos e incorporando técnicas inovadoras de recuperação e inferência. Neste documento, desmontamos a abordagem central da estrutura GTR em detalhes e mostramos o design de suas principais dicas.
2. MUTLITABLEQA: o primeiro conjunto de dados de referência de Q&A entre tabelas
Para avaliar a eficácia do modelo de perguntas e respostas em tabelas cruzadas, os pesquisadores criaram o MUTLITABLEQAEste é o primeiro conjunto de dados de referência de perguntas e respostas entre tabelas criado a partir de formulários e consultas de usuários do mundo real. Veja a seguir as principais etapas da construção do conjunto de dados:
2.1 Métodos de construção do conjunto de dados
- Fonte da tabelaColeta de dados brutos de tabela única de conjuntos de dados do mundo real rotulados por humanos, como HybridQA, SQA, Tabfact e WikiTables, e filtragem de tabelas excessivamente simplificadas, resultando em 20.000 tabelas.
- Detalhamento da tabelaDivisão de linha/coluna de tabelas coletadas em 60.000 subtabelas como dados de várias tabelas. Os métodos específicos incluem:
- divisão de linhasDivisão: Divida as entradas da tabela em vários subconjuntos disjuntos ao longo da dimensão da linha, cada um preservando o mesmo esquema de tabela e metadados da tabela original.
- divisão de colunasColuna de entrada: mantenha a primeira coluna (geralmente a chave primária ou o atributo principal) e divida as entradas restantes em vários subconjuntos disjuntos ao longo da dimensão da coluna.

Figura 1: Fluxograma de construção do conjunto de dados MUTLITABLEQA mostrando a construção direta de um conjunto de dados com várias tabelas e o processo de construção do MUTLITABLEQA. - Portfólio de consultasPara aumentar a complexidade da recuperação de consultas, os pesquisadores combinam consultas simples existentes para gerar consultas complexas que exigem raciocínio em várias etapas. As etapas específicas incluem:
- Desduplicação e filtragem de consultasFiltragem de consultas ambíguas e contextualmente repetitivas usando heurística linguística comum e com reconhecimento de contexto (por exemplo, análise de proporção de palavras de desativação, limites mínimos de comprimento de consulta e detecção de redundância baseada em similaridade).
- Mesclagem de consultasPara consultas complexas ou sequenciais da mesma tabela única, combine-as em uma única consulta estendida usando termos de concatenação (por exemplo, "AND", "furthermore", "Based on [previous query]"). ") para combiná-las em uma única consulta estendida.
- Descontextualização de consultasPara melhorar a clareza e a autocontenção, é usada uma abordagem de descontextualização, substituindo pronomes indicativos vagos e marcadores de discurso por referências explícitas.
- Definição do tipo de tarefa::
- Verificação de fatos baseada em tabela (TFV)Determinar se as declarações fornecidas pelo usuário são compatíveis com os dados tabulares.
- TQA de salto únicoA resposta a uma pergunta precisa ser obtida de apenas uma célula da tabela, mas é necessário raciocinar em várias tabelas para encontrar a célula correta.
- TQA de múltiplos saltosRespostas a perguntas exigem raciocínio complexo a partir de várias células em várias tabelas.
Figura 2: Exemplos dos três tipos diferentes de tarefas no conjunto de dados MUTLITABLEQA.
3. a estrutura GTR: uma abordagem inovadora para P&R entre tabelas
A estrutura GTR foi projetada para enfrentar os principais desafios de Q&A entre tabelas das seguintes maneiras:
3.1 Construção de tabela para figura
A ideia central do GTR é transformar dados tabulares em hipergrafos heterogêneos para capturar melhor as informações relacionais e semânticas entre as tabelas.
- Linearização da tabelaConverta tabelas em sequências lineares, preservando suas informações estruturais e conteúdo semântico. Por exemplo, junte os cabeçalhos e os títulos de coluna de uma tabela em uma sequência e use marcadores especiais para identificar a posição estrutural da tabela.
s = [ [Table], ⊕( [Caption], C ), ⊕( [Header], h_k ) ]em que ⊕ denota a concatenação da sequência e h_k denota o título da kª coluna.
- Extração de vários recursosCálculo de três vetores próprios para cada sequência linearizada:
- Recursos semânticos (x^(sem))Gerado usando um codificador de sequência que captura o conteúdo semântico do formulário.
- Características estruturais (x^(struct))Use o spaCy para extrair os principais recursos de formatação, como contagens de tokens, frequências de tags léxicas e contagens de pontuação.
- Recursos heurísticos (x^(heur))Gerado por heurística, por exemplo, usando vetores TF-IDF para gerar representações de saco de palavras.
- construção hipergráfica (matemática)Hipergráfico heterogêneo: construa um hipergráfico heterogêneo agrupando tabelas com recursos semelhantes por meio de um algoritmo de agrupamento multiplex e definindo cada agrupamento como uma hipercorda.
Figura 3: Visão geral da estrutura GTR mostrando o processo de construção de tabela para gráfico.
3.2 Pesquisa multiplexada de granulação grossa
- Pontuação representativaDefinir pontuações representativas entre nós para comparar a similaridade entre nós e entre nós e consultas.
- Atribuição de cluster de consultaApós a incorporação da consulta, a pontuação representativa entre ela e cada nó é calculada e os clusters mais relevantes são selecionados para cada tipo de recurso.
- Seleção típica de nósUm pequeno número de nós é selecionado para representar melhor cada cluster, e o melhor cluster multiplexado final é o conjunto concatenado de todos os tipos de recursos.
3.3 Recuperação de subgrafos com granulação fina
- Construção de subgrafos locaisSubgrafo local: Com base nos resultados de recuperação de granulação grossa, um subgrafo local densamente conectado é construído e a matriz de similaridade entre os nós é computada usando recursos semânticos.
- PageRank personalizado iterativoMatriz de similaridade: calcula a matriz de similaridade dos nós candidatos e realiza a normalização das linhas para obter a matriz de transferência. O vetor PageRank personalizado é calculado de forma iterativa, os nós são classificados e o nó com a melhor classificação é finalmente selecionado como o nó da tabela recuperada final.
3.4 Pistas de percepção de figuras
Para permitir que os LLMs downstream interpretem com eficácia as tabelas recuperadas e façam inferências, o GTR emprega uma abordagem de dicas com reconhecimento de gráficos. A seguir, apresentamos um projeto detalhado das dicas usadas na estrutura do GTR:
3.4.1 Inserção de informações de figuras
- Indexação de nós e incorporação relacionalNúmero de nós da tabela recuperada e os incorpora às dicas para que o LLM possa reconhecer diferentes fontes de tabela. Ao mesmo tempo, as relações de similaridade entre os nós são incorporadas às dicas em um formato JSON estruturado, descrevendo a similaridade semântica ou outras relações entre diferentes formulários.
## Retrieved Tables: <table1>Table 1: ...</table1> <table2>Table 2: ...</table2> ... ## Graph-Related Information: { "source_node": "Table 1", "target_node": "Table 2", "relationship": { "type": "similarity", "score": 0.674 } }
3.4.2 Geração hierárquica de pensamento de cadeia longa (CoT)
- Identificar formulários relevantesFormulário de consulta: solicita ao LLM que identifique o formulário mais relevante para a consulta a partir do conjunto de formulários fornecidos.
1. Identify the most relevant tables from the provided table set <V_final^*>. - Esclarecer o vínculo entre consultas e tabelasPrompt LLM Explique a conexão entre a consulta e os formulários selecionados, explicando por que eles são essenciais para responder à consulta.
2. Elucidate the connection between the query and the selected tables. - Processo de raciocínio detalhadoDica: o Hint LLM examina detalhadamente cada entrada de linha e coluna, extraindo as informações mais relevantes para a consulta e raciocinando passo a passo para chegar à resposta final.
3. Conduct a detailed examination of each row and column entry to extract the information most pertinent to the query. - Saída da resposta finalDicas: Os LLMs argumentarão sobre o processo de raciocínio e a resposta final separadamente usando o
<reasoning>responder cantando</reasoning>e<answer>responder cantando</answer>Etiqueta embalada.# Now Output Your response below: <reasoning> [Detailed reasoning steps] </reasoning> <answer> [Final answer] </answer>
3.4.3 Exemplo de saída
A seguir, um exemplo de saída gerada pela estrutura GTR:
<reasoning>
1. The query asks for the release date of a game called "Mario Kart Advance".
2. From Table 1, we can find that "Mario Kart Advance" is listed under the "Game Title" column.
3. The corresponding entry in the "Release Date" column is "December 16, 2011".
4. Therefore, the release date of "Mario Kart Advance" is December 16, 2011.
</reasoning>
<answer>
December 16, 2011
</answer>
4. resultados experimentais
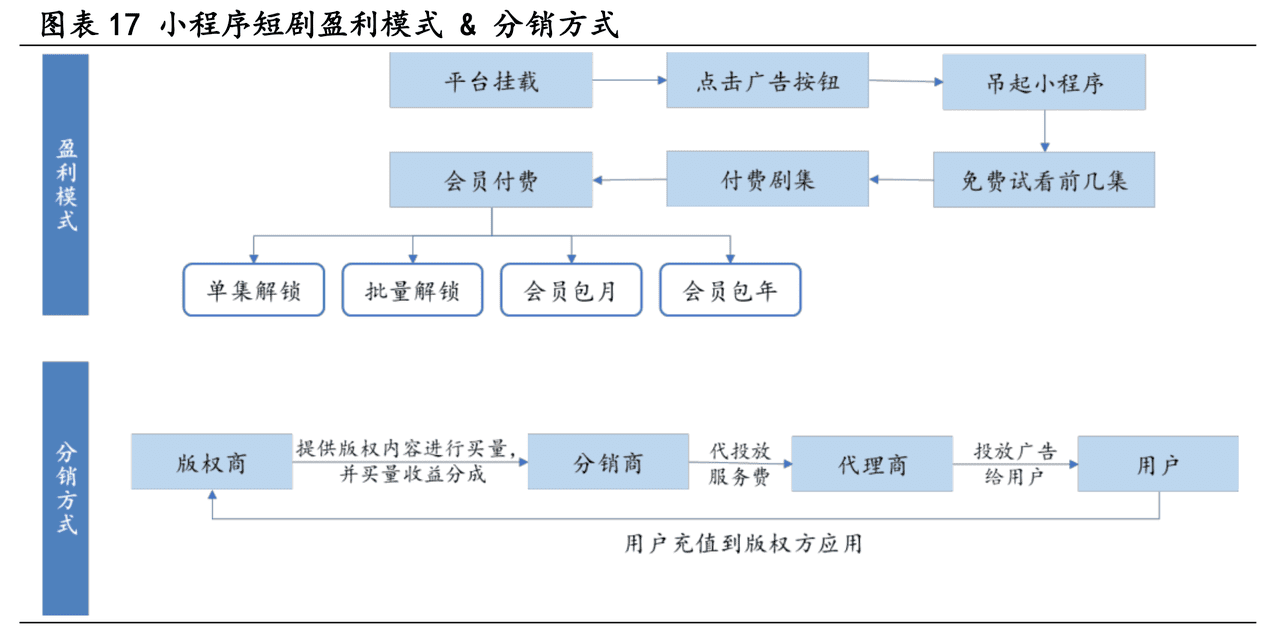
Os resultados experimentais no conjunto de dados MUTLITABLEQA mostram que o GTR tem um bom desempenho tanto na recuperação quanto na geração e inferência downstream. Em comparação com os métodos tradicionais de recuperação de tabelas, o GTR apresenta uma melhoria significativa na precisão e na recuperação. Por exemplo, na tarefa TFV, a recuperação @50 do GTR é melhorada em 9.4%Na tarefa TQA multi-hop, o recall @10 melhorou em 8.2%.
A seguir estão os principais resultados experimentais do GTR com outros métodos de linha de base no conjunto de dados MUTLITABLEQA:
| formulário | metodologias | Precisão do TFV @10 | Precisão do TFV @20 | Precisão do TFV @50 | ... | Taxa de recuperação de TQA de vários saltos @50 |
|---|---|---|---|---|---|---|
| pesquisa na tabela | DTR | 21.1 | 27.8 | 36.2 | ... | 62.0 |
| Mesa-Contriever | 23.4 | 30.1 | 40.1 | ... | 68.9 | |
| ... | ... | ... | ... | ... | ... | |
| GTR | GTR | 36.1 | 47.9 | 59.4 | ... | 76.8 |
5 Conclusão
A estrutura GTR demonstra sua capacidade de lidar com consultas complexas entre tabelas, organizando dados tabulares em gráficos heterogêneos e combinando-os com métodos inovadores de recuperação multiplexada e de dicas com reconhecimento de gráficos. Essa nova abordagem traz novas ideias e possibilidades para o campo de consultas entre tabelas.
6. perspectivas futuras
Os pesquisadores planejam ampliar ainda mais o conjunto de dados MUTLITABLEQA e explorar técnicas mais avançadas de rede neural gráfica (GNN) e de otimização LLM para melhorar ainda mais o desempenho dos modelos de perguntas e respostas entre tabelas. Além disso, eles planejam aplicar a estrutura GTR a outros domínios, como inferência de gráficos de conhecimento e perguntas e respostas entre modalidades.
Endereço para correspondência: https://arxiv.org/pdf/2504.01346
© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Artigos relacionados



Nenhum comentário...