GPUStack: gerenciamento de clusters de GPU para executar modelos de linguagem grandes e integrar rapidamente serviços de inferência comuns para LLMs.
Introdução geral
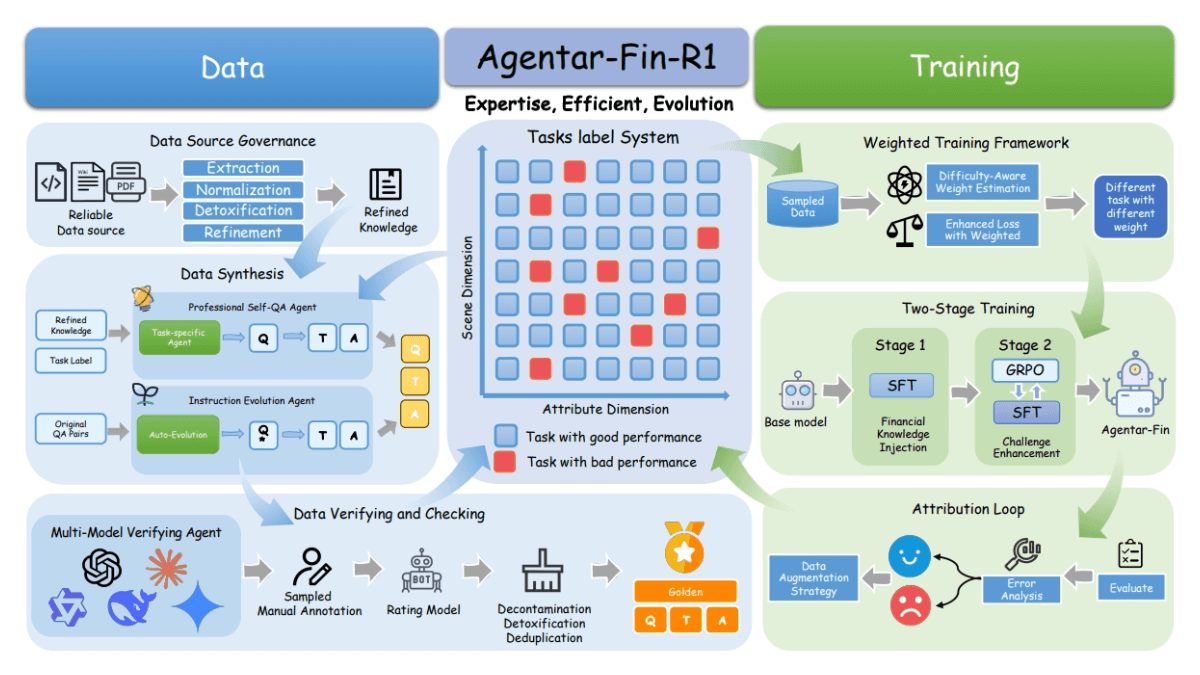
O GPUStack é uma ferramenta de gerenciamento de clusters de GPU de código aberto projetada para executar modelos de linguagem grandes (LLMs). O GPUStack oferece recursos de inferência distribuída, suporta inferência e serviços de nó único, multi-GPU e multi-nó, e é compatível com a API OpenAI, simplificando o gerenciamento de chaves de usuário e API e o monitoramento em tempo real do desempenho e da utilização da GPU. Ele é compatível com a API OpenAI, simplifica o gerenciamento de chaves de usuário e de API e monitora o desempenho e a utilização da GPU em tempo real. Seu design de pacote Python leve garante o mínimo de dependências e sobrecarga operacional, tornando-o ideal para desenvolvedores e pesquisadores.

Lista de funções
- Suporte a vários hardwares: compatível com Apple Metal, NVIDIA CUDA, Ascend CANN, Moore Threads MUSA e muito mais.
- Inferência distribuída: suporta inferência e serviços de nó único, multi-GPU e multi-nó.
- Vários backends de inferência: suporte para llama-box (llama.cpp) e vLLM.
- Pacotes Python leves: dependências e sobrecarga operacional mínimas.
- API compatível com OpenAI: fornece serviços de API compatíveis com o padrão OpenAI.
- Gerenciamento de chaves de usuário e API: simplifica o gerenciamento de chaves de usuário e API.
- Monitoramento do desempenho da GPU: monitore o desempenho e a utilização da GPU em tempo real.
- Uso de tokens e monitoramento de taxas: gerencie com eficiência o uso de tokens e a limitação de taxas.
Usando a Ajuda
Processo de instalação
Linux ou MacOS
- Abra o terminal.
- Execute o seguinte comando para instalar o GPUStack:
curl -sfL https://get.gpustack.ai | sh -s -
- Após a instalação, o GPUStack será executado como um serviço no sistema systemd ou launchd.
Windows (computador)
- Execute o PowerShell como administrador (evite usar o PowerShell ISE).
- Execute o seguinte comando para instalar o GPUStack:
Invoke-Expression (Invoke-WebRequest -Uri "https://get.gpustack.ai" -UseBasicParsing).Content
Diretrizes para uso
Configuração inicial
- Acesso à interface do usuário do GPUStack: abrir no navegador
http://myserver. - Use o nome de usuário padrão
admine a senha inicial para fazer login. Método para obter a senha inicial:- Linux ou MacOS: execute
cat /var/lib/gpustack/initial_admin_password. - Windows: em execução
Get-Content -Path "$env:APPDATA\gpustack\initial_admin_password" -Raw.
- Linux ou MacOS: execute
Criação de chaves de API
- Depois de fazer login na interface do usuário do GPUStack, clique em "API Keys" (Chaves de API) no menu de navegação.
- Clique no botão "New API Key" (Nova chave de API), preencha o nome e salve-o.
- Copie a chave de API gerada e salve-a corretamente (visível somente no momento da criação).
Usando a API
- Configuração de variáveis de ambiente:
export GPUSTACK_API_KEY=myapikey
- Use curl para acessar APIs compatíveis com OpenAI:
curl http://myserver/v1-openai/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $GPUSTACK_API_KEY" \
-d '{
"model": "llama3.2",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello!"}
],
"stream": true
}'
Corra e converse
- Execute o seguinte comando no terminal para conversar com o modelo llama3.2:
gpustack chat llama3.2 "tell me a joke."
- Clique em "Playground" na interface do usuário do GPUStack para interagir.
Monitoramento e gerenciamento
- Monitore o desempenho e a utilização da GPU em tempo real.
- Gerencie chaves de usuário e de API, rastreie o uso e as taxas de token.
Modelos e plataformas compatíveis
- Modelos compatíveis: LLaMA, Mistral 7B, Mixtral MoE, Falcon, Baichuan, Yi, Deepseek, Qwen, Phi, Grok-1 e outros.
- Modelos multimodais compatíveis: Llama3.2-Vision, Pixtral, Qwen2-VL, LLaVA, InternVL2 e outros.
- Plataformas compatíveis: macOS, Linux, Windows.
- Aceleradores suportados: Apple Metal, NVIDIA CUDA, Ascend CANN, Moore Threads MUSA, com planos futuros para suportar AMD ROCm, Intel oneAPI, Qualcomm AI Engine.
Documentação e comunidade
- Documentação oficial: visite Documentação do GPUStack Obtenha o guia completo e a documentação da API.
- Guia de contribuição: Leitura Diretrizes de contribuição Descubra como você pode contribuir com o GPUStack.
© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Artigos relacionados



Nenhum comentário...