GLM-4.5V - Modelo de raciocínio visual multimodal de código aberto da Smart Spectrum
O que é GLM-4.5V?
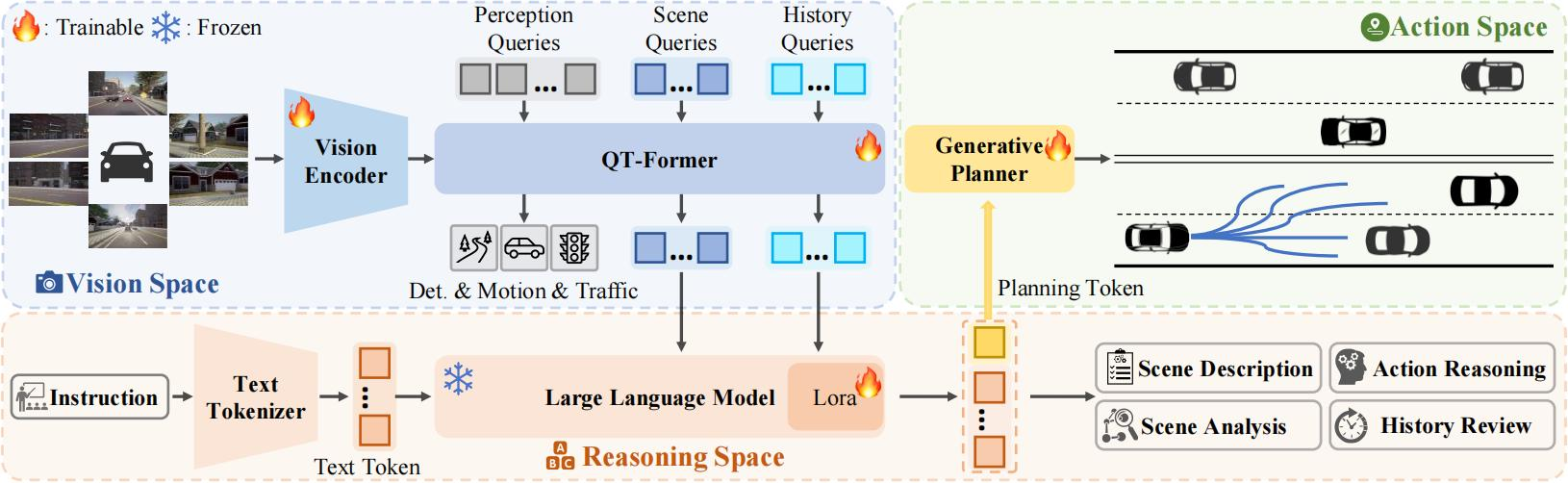
O GLM-4.5V é o principal modelo de inferência visual de código aberto do mundo lançado pela Smart Spectrum, com 106 bilhões de parâmetros totais e 12 bilhões de parâmetros ativados. O modelo é baseado em uma nova geração de modelos de base de textoGLM-4.5-AirO GLM-4.5 foi treinado para ter recursos sólidos de compreensão e raciocínio visual e pode lidar com uma ampla variedade de conteúdo visual, como imagens, vídeos e documentos. O modelo tem um bom desempenho em tarefas multimodais, abrangendo cenários como perguntas e respostas visuais, geração de descrição de imagens, compreensão de vídeos e replicação de front-end da Web, além de oferecer suporte à alternância flexível entre resposta rápida e inferência profunda. O GLM-4.5V alcança o desempenho SOTA em 41 listas multimodais visuais disponíveis publicamente e realiza inferência visual de cenários completos por meio de treinamento híbrido eficiente, oferecendo soluções econômicas de IA multimodal para empresas e desenvolvedores. para empresas e desenvolvedores.
Recursos funcionais do GLM-4.5V
- raciocínio gráficoCapacidade de entender objetos, relações entre personagens e informações de fundo em cenas complexas.
- Compreensão de vídeoSuporte à análise de conteúdo de vídeo longo, incluindo cenas divididas, reconhecimento de eventos e extração de informações importantes.
- Recursos de interação multimodal::
- Integração textual e visualSuporte para gerar imagens a partir de descrições de texto ou gerar descrições de texto a partir de imagens.
- geração multimodalCapacidade de converter conteúdo visual em texto ou conteúdo de texto em conteúdo visual.
- Réplica do front-end da WebEle pode gerar código de front-end com base em desenhos de design da Web para desenvolvimento rápido da Web. Os usuários só precisam carregar capturas de tela de páginas da Web ou vídeos interativos, e o modelo pode gerar códigos HTML, CSS e JavaScript completos.
- Jogos TouhouSuporte a tarefas de pesquisa e correspondência baseadas em imagens. Por exemplo, encontrar rapidamente imagens-alvo específicas em cenas complexas, adequadas para vigilância de segurança, varejo inteligente e desenvolvimento de jogos de entretenimento.
- Interpretação de documentação complexaCapacidade de trabalhar com documentos longos e diagramas complexos, extraindo, resumindo e traduzindo informações. Suporta a exportação de seu próprio "ponto de vista", não apenas a simples extração de informações.
Principais benefícios do GLM-4.5V
- Forte compreensão visual e raciocínioCapacidade de compreender profundamente conteúdos visuais complexos, incluindo imagens, vídeos e documentos. É capaz de reconhecer não apenas objetos, cenas e relações entre pessoas, mas também realizar raciocínios avançados, como inferir informações contextuais a partir de pistas sutis em uma imagem
- Interação multimodal e recursos de geraçãoSuporte para integração perfeita de conteúdo textual e visual, com a capacidade de gerar imagens a partir de descrições de texto ou descrições de texto a partir de imagens. O modelo oferece suporte à implementação de geração multimodal, por exemplo, convertendo conteúdo visual em texto ou conteúdo de texto em conteúdo visual.
- Adaptação eficiente de tarefas e modelo de raciocínioO sistema de raciocínio visual de cena completa é um recurso eficiente de treinamento híbrido que pode lidar com uma ampla gama de tarefas, como raciocínio de imagem, compreensão de vídeo, tarefas de GUI e análise de diagramas complexos e documentos longos.
- Implementação econômica e rápidaEquilíbrio entre velocidade de inferência e custo de implantação, mantendo alta precisão. Seu preço de chamada de API é tão baixo quanto US$ 2/M tokens para entrada e US$ 6/M tokens para saída, com uma velocidade de resposta de 60-80 tokens/s.
- Código aberto e amplo suporte da comunidadeFornecimento de vários canais, como o repositório GitHub, o repositório de modelos Hugging Face e a comunidade Magic Ride, para facilitar o início rápido e o desenvolvimento secundário dos desenvolvedores, além de fornecer um aplicativo de assistente de desktop para oferecer suporte à captura de tela e gravação de tela em tempo real, de modo a facilitar a experiência dos desenvolvedores com a capacidade do modelo.
- Ampla gama de cenários de aplicaçãoPara uma variedade de cenários de aplicativos do mundo real, incluindo replicação de front-end da Web, questionamento visual, jogos de busca de gráficos, compreensão de vídeo, geração de descrição de imagens e interpretação de documentos complexos.
Qual é o site oficial do GLM-4.5V?
- Repositório do GitHub:: https://github.com/zai-org/GLM-V/
- Biblioteca do modelo HuggingFace:: https://huggingface.co/collections/zai-org/glm-45v-68999032ddf8ecf7dcdbc102
- Documentos técnicos:: https://github.com/zai-org/GLM-V/tree/main/resources/GLM-4.5V_technical_report.pdf
- Aplicativo Desktop Assistant:: https://huggingface.co/spaces/zai-org/GLM-4.5V-Demo-App
Pessoas para as quais o GLM-4.5V é adequado
- desenvolvedoresOferece aos desenvolvedores recursos avançados de desenvolvimento multimodal para ajudá-los a criar rapidamente aplicativos como questionários visuais, geração de imagens, análise de vídeo e muito mais.
- usuário corporativoAs empresas usam recursos de compreensão visual para otimizar cenários comerciais, como segurança e vigilância, varejo inteligente e recomendação de vídeo.
- pesquisadorPesquisadores estão aproveitando os modelos e conjuntos de dados de código aberto do GLM-4.5V para realizar pesquisas de ponta nas áreas de raciocínio multimodal, fusão de linguagem visual e muito mais.
- usuário regularUsuários comuns usam recursos como descrição de imagens e compreensão de vídeos para melhorar a eficiência da criação de conteúdo e o acesso às informações.
- Educadores e alunosEducadores e alunos para auxiliar o ensino e a aprendizagem e aprimorar a experiência educacional.
© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Publicações relacionadas


Nenhum comentário...