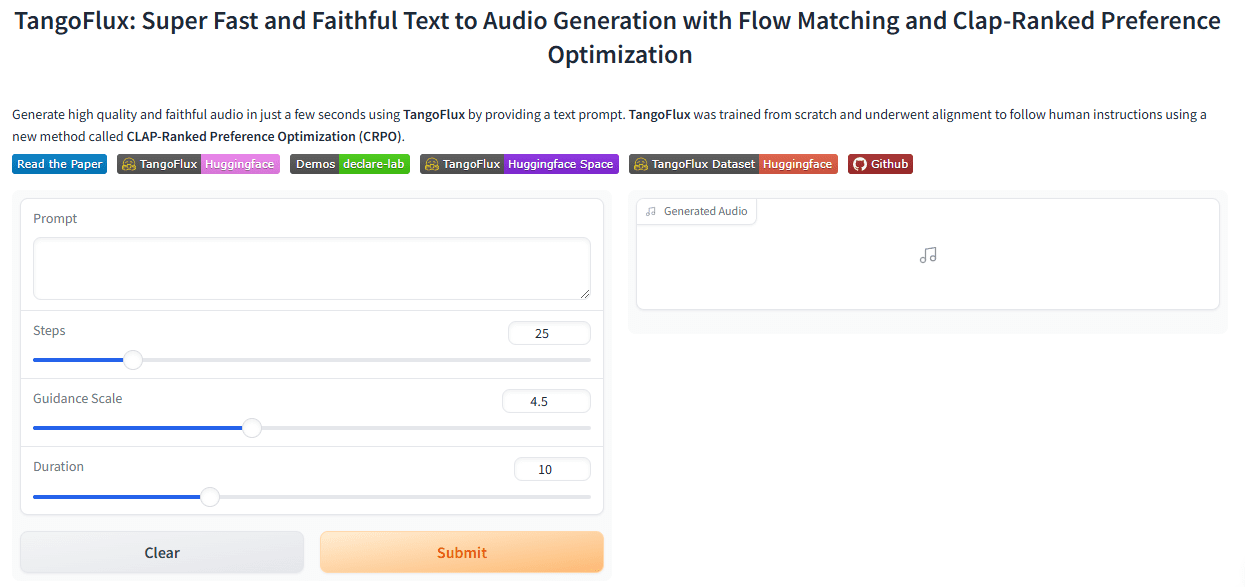
Gaze-LLE: ferramenta de previsão de alvos para o olhar de pessoas em vídeos
Introdução geral
O Gaze-LLE é uma ferramenta de previsão de alvos de olhares baseada em um codificador de aprendizado em larga escala. Desenvolvido por Fiona Ryan, Ajay Bati, Sangmin Lee, Daniel Bolya, Judy Hoffman e James M. Rehg, o projeto tem como objetivo permitir a previsão eficiente do alvo do olhar com modelos de base visual pré-treinados, como o DINOv2. A arquitetura do Gaze-LLE é limpa e simples, e apenas congela o codificador visual pré-treinado para aprender um decodificador de olhar leve, o que reduz a quantidade de parâmetros em uma ou duas ordens de grandeza em comparação com o trabalho anterior, e não exige modalidades de entrada adicionais, como informações de profundidade e pose.

Lista de funções
- Foco na previsão de metasPrevisão eficiente de alvos de olhar com base em codificadores visuais pré-treinados.
- Previsão de múltiplos olharesSuporte à previsão de olhares para vários indivíduos em uma única imagem.
- Modelo de pré-treinamentoOferece uma variedade de modelos pré-treinados para suportar diferentes redes de backbone e dados de treinamento.
- Arquitetura leveLearning lightweight gaze decoders only on frozen pre-trained visual coders (Aprendizado de decodificadores de olhar leves somente em codificadores visuais pré-treinados congelados).
- Nenhum modo de entrada adicionalProfundidade e atitude: Não são necessárias entradas adicionais de informações de profundidade e atitude.
Usando a Ajuda
Processo de instalação
- Armazém de Clonagem:
git clone https://github.com/fkryan/gazelle.git
cd gazelle
- Crie um ambiente virtual e instale as dependências:
conda env create -f environment.yml
conda activate gazelle
pip install -e .
- Opcional: Instale o xformers para acelerar os cálculos de atenção (se suportado pelo sistema):
pip3 install -U xformers --index-url https://download.pytorch.org/whl/cu118
Uso de modelos pré-treinados
O Gaze-LLE oferece uma variedade de modelos pré-treinados que os usuários podem baixar e usar conforme necessário:
- gazeladinov2vitb14Modelo baseado no DINOv2 ViT-B com dados de treinamento do GazeFollow.
- gazeladinov2vitl14Modelo baseado no DINOv2 ViT-L com dados de treinamento do GazeFollow.
- gazeladinov2vitb14_inoutModelo baseado no DINOv2 ViT-B com dados de treinamento para GazeFollow e VideoAttentionTarget.
- gazelagrandevitl14_inoutModelo baseado no DINOv2 ViT-L com dados de treinamento para GazeFollow e VideoAttentionTarget.
exemplo de uso
- Carregue o modelo no PyTorch Hub:
import torch
model, transform = torch.hub.load('fkryan/gazelle', 'gazelle_dinov2_vitb14')
- Confira o caderno de demonstração no Google Colab para saber como detectar o alvo do olhar de todos em uma imagem.
Fique atento às previsões
O Gaze-LLE é compatível com a previsão de olhares para várias pessoas, ou seja, uma única imagem é codificada uma vez e, em seguida, os recursos são usados para prever alvos de olhares para várias pessoas na imagem. O modelo gera um mapa de calor espacial que representa a probabilidade do local do alvo do olhar na cena com valores que variam de [0,1], em que 1 representa a maior probabilidade do local do alvo do olhar.
© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Artigos relacionados


Nenhum comentário...