
RAG avançado: arquitetura, tecnologia, aplicativos e perspectivas de desenvolvimento
A geração aumentada por recuperação (RAG) tornou-se uma estrutura importante no campo da IA, melhorando consideravelmente a precisão e a relevância de modelos de linguagem grandes (LLMs) ao gerar respostas usando fontes de conhecimento externas. De acordo com Telas de dados Os dados mostram que 60% dos aplicativos de LLM na empresa usam Retrieval Augmented Generation (RAG), sendo que 30% usam um processo de várias etapas. O RAG tem recebido muita atenção porque gera respostas quase tão boas quanto aquelas que dependem apenas do ajuste fino do modelo Melhoria da precisão do 43%Isso mostra que o RAG grande potencial para melhorar a qualidade e a confiabilidade do conteúdo gerado por IA.
No entanto, as abordagens tradicionais de RAG ainda enfrentam vários desafios para responder a consultas complexas, compreender contextos diferenciados e lidar com vários tipos de dados. Essas limitações estimularam a criação de RAGs avançados com o objetivo de aprimorar os recursos da IA na recuperação e geração de informações. Em especial.número de empresas O RAG foi integrado a aproximadamente 601 produtosTP3T, demonstrando sua importância e eficácia em aplicações práticas.
Um dos principais avanços nesse campo foi a introdução de RAGs multimodais e gráficos de conhecimento. O RAG multimodal amplia a capacidade dos RAGs de processar não apenas texto, mas também uma ampla variedade de dados, incluindo imagens, áudio e vídeo. Isso permite que os sistemas de IA sejam mais abrangentes e tenham uma compreensão contextual mais forte ao interagir com os usuários. Os gráficos de conhecimento, por outro lado, melhoram a coerência e a precisão do processo de recuperação de informações e do conteúdo gerado por meio da representação estruturada do conhecimento.Pesquisa da Microsoft sugere que o GraphRAG exigiu Token O número é reduzido de 26% para 97% em relação a outros métodos, mostrando maior eficiência e custo computacional reduzido.
Esses avanços na tecnologia RAG resultaram em ganhos significativos de desempenho em vários benchmarks e aplicativos do mundo real. Por exemplo.mapa de conhecimento obteve uma precisão de 86,31% no teste RobustQA, o que excede em muito outros métodos RAG. Além disso, oSequeda e Allemang de estudos de acompanhamento descobriram que a combinação de ontologias reduz a taxa de erro de 20%. As empresas também se beneficiaram muito com esses avanços, oLinkedIn relatou uma redução de 28,61 TP3T no tempo de resolução do suporte ao cliente por meio da abordagem RAG mais Knowledge Graph.
Neste artigo, vamos nos aprofundar na evolução dos RAGs avançados, explorando a complexidade dos RAGs multimodais e dos RAGs de gráficos de conhecimento e sua eficácia no aprimoramento da recuperação e geração de informações orientadas por IA. Também discutiremos o potencial dessas inovações para serem aplicadas em diferentes setores e os desafios enfrentados na promoção e aplicação dessas tecnologias.
- [O que é Retrieval Augmented Generation (RAG) e por que ele é importante para a modelagem de linguagem ampla (LLM)?
- [Tipos de arquitetura RAG].
- [Do RAG básico ao RAG avançado: como superar as limitações e aprimorar os recursos].
- [Componentes e processos avançados do sistema RAG na empresa].
- [Tecnologia RAG avançada].
- [Aplicativos RAG avançados e estudos de caso].
- [Como criar ferramentas de diálogo usando o RAG avançado?]
- [Como posso criar um aplicativo RAG avançado?]
- [A ascensão dos gráficos de conhecimento no RAG avançado]
- [RAG avançado: geração aprimorada de horizontes estendidos por meio de recuperação multimodal]
- [Como a plataforma de colaboração GenAI da LeewayHertz, ZBrain, se destaca entre os sistemas RAG avançados].
Advanced RAG: Arquitetura, tecnologia, aplicativos e perspectivas de desenvolvimento PDF Download:
RAG avançado: arquitetura, tecnologia, aplicativos e perspectivas de desenvolvimento
O que é o Retrieval Augmented Generation (RAG) e por que ele é importante para o Large Language Modelling (LLM)?
Os modelos de linguagem ampla (LLMs) tornaram-se fundamentais para os aplicativos de IA, que contam com seu poder para tudo, desde assistentes virtuais até ferramentas sofisticadas de análise de dados. Mas, apesar de seus recursos, esses modelos têm limitações para fornecer informações atualizadas e precisas. É nesse ponto que o Retrieval Augmented Generation (RAG) oferece um complemento poderoso ao LLM.
O que é Retrieval Augmented Generation (RAG)?
O Retrieval Augmented Generation (RAG) é uma técnica avançada que aprimora os recursos de geração dos Large Language Models (LLMs) por meio da integração de fontes de conhecimento externas. Os LLMs são treinados em grandes conjuntos de dados, com bilhões de parâmetros, e são capazes de executar uma ampla gama de tarefas, como responder a perguntas, tradução linguística e conclusão de texto. Os RAGs vão um passo além, fazendo referência a bases de conhecimento autorizadas e específicas do domínio para melhorar a relevância, a precisão e a utilidade do conteúdo gerado sem a necessidade de treinar novamente o modelo. Essa abordagem econômica e eficiente é ideal para empresas que buscam otimizar seus sistemas de IA.
Como o RAG (Retrieval Augmented Generation) pode ajudar o LLM (Large Language Modelling) a resolver o problema central?
Os modelos de linguagem ampla (LLMs) desempenham um papel fundamental na condução de chatbots inteligentes e outros aplicativos de processamento de linguagem natural (NLP). Por meio de treinamento extensivo, eles tentam fornecer respostas precisas em uma variedade de contextos. No entanto, os próprios LLMs têm algumas deficiências e enfrentam vários desafios:
- mensagem de erroRespostas imprecisas podem ser geradas quando o conhecimento do LLM é insuficiente.
- informações desatualizadasDados de treinamento: os dados de treinamento são estáticos, portanto, as respostas geradas pelo modelo podem estar desatualizadas.
- fonte não autorizadaResposta gerada: Às vezes, as respostas geradas podem vir de fontes não confiáveis, o que afeta a credibilidade.
- confusão terminológicaUso inconsistente da mesma terminologia por diferentes fontes de dados pode facilmente levar a mal-entendidos.
O RAG aborda esses problemas fornecendo ao LLM uma fonte de dados externa confiável para melhorar a precisão e a natureza em tempo real das respostas do modelo. Os pontos a seguir explicam por que o RAG é tão importante para o desenvolvimento do LLM:
- Melhorar a precisão e a relevânciaO RAG extrai as informações mais atualizadas e relevantes de fontes confiáveis para garantir que as respostas do modelo sejam mais precisas e relevantes para o contexto atual, já que os dados de treinamento são estáticos.
- Ultrapassando os limites dos dados estáticosO RAG dá ao LLM acesso aos dados mais recentes, mantendo as informações atualizadas e relevantes.
- Aumentar a confiança do usuárioO RAG aumenta a transparência e a confiança do usuário, permitindo que o LLM cite fontes e forneça informações verificáveis.
- economia de custosO RAG fornece uma alternativa mais econômica para o retreinamento do LLM com novos dados, fornecendo uma alternativa econômica para o retreinamento de todo o modelo usando fontes de dados externas, tornando as técnicas avançadas de IA mais amplamente disponíveis.
- Controle e flexibilidade aprimorados para o desenvolvedorRAG oferece aos desenvolvedores mais liberdade para especificar fontes de conhecimento de forma flexível, adaptar-se rapidamente às mudanças nos requisitos e garantir o tratamento adequado de informações confidenciais para dar suporte a uma ampla gama de aplicativos e melhorar a eficácia dos sistemas de IA.
- Fornecimento de respostas personalizadasEnquanto os LLMs tradicionais tendem a fornecer respostas excessivamente gerais, o RAG combina os LLMs com os bancos de dados internos da organização, informações sobre produtos e manuais do usuário para fornecer respostas mais específicas e relevantes, melhorando consideravelmente a experiência de interação e suporte ao cliente.
O RAG (Retrieval Augmented Generation) permite que o LLM gere respostas mais precisas, contextualizadas e em tempo real por meio da integração com bases de conhecimento externas. Isso é vital para as organizações que dependem de IA, desde o atendimento ao cliente até a análise de dados, o RAG não apenas melhora a eficiência, mas também aumenta a confiança do usuário nos sistemas de IA.
Tipos de arquitetura RAG
O Retrieval Augmented Generation (RAG) representa um grande avanço na tecnologia de IA, combinando modelos de linguagem com sistemas externos de recuperação de conhecimento. Essa abordagem híbrida aprimora a capacidade de geração de respostas de IA, obtendo informações detalhadas e relevantes de grandes fontes de dados externas. Compreender os diferentes tipos de arquiteturas RAG nos ajuda a aproveitar melhor seus benefícios de acordo com nossas necessidades específicas. Veja a seguir uma análise detalhada das três principais arquiteturas de RAG:
1. RAG ingênuo
O Naive RAG é o método mais básico de geração de aprimoramento de recuperação. Seu princípio é simples: o sistema extrai pedaços de informações relevantes da base de conhecimento com base na consulta do usuário e, em seguida, usa esses pedaços de informações como contexto para gerar a resposta por meio da modelagem de linguagem.
Características:
- mecanismo de recuperaçãoMétodo de recuperação simples: Um método de recuperação simples é usado para extrair blocos de documentos relevantes de um índice pré-estabelecido, geralmente por meio de correspondência de palavras-chave ou similaridade semântica básica.
- integração contextualFusão: Os documentos recuperados são combinados com a consulta do usuário e inseridos no modelo de linguagem para gerar uma resposta. Essa fusão fornece um contexto mais rico para que o modelo gere respostas mais relevantes.
- fluxo de processamentoO sistema segue um processo fixo: recuperar, unir, gerar. O modelo não modifica as informações extraídas, mas as usa diretamente para gerar respostas.
2. RAG avançado
O Advanced RAG é baseado no Naive RAG e adota técnicas mais avançadas para melhorar a precisão da recuperação e a relevância contextual. Ele supera algumas das limitações do Naive RAG ao combinar mecanismos avançados para processar e utilizar melhor as informações contextuais.
Características:
- Recuperação aprimoradaMelhorar a qualidade e a relevância das informações recuperadas usando estratégias de pesquisa avançadas, como a expansão da consulta (adição de termos relevantes à consulta inicial) e a pesquisa iterativa (otimização de documentos em vários estágios).
- Otimização de contextoO foco seletivo nas partes mais relevantes do contexto por meio de técnicas como o mecanismo de atenção ajuda o modelo de linguagem a gerar respostas mais precisas e contextualmente mais precisas.
- estratégia de otimizaçãoEstratégias de otimização, como pontuação de relevância e aprimoramento contextual, são usadas para garantir que o modelo capture as informações mais relevantes e de alta qualidade para gerar respostas.
3) RAG modular
O RAG modular é a arquitetura RAG mais flexível e personalizável. Ele divide o processo de recuperação e geração em módulos separados, permitindo a otimização e a substituição de acordo com as necessidades de aplicativos específicos.
Características:
- Design modularDecompor o processo RAG em diferentes módulos, como expansão de consulta, recuperação, reordenação e geração. Cada módulo pode ser otimizado de forma independente e substituído sob demanda.
- Personalização flexívelPermite um alto grau de personalização, em que os desenvolvedores podem experimentar diferentes configurações e tecnologias em cada etapa para encontrar a melhor solução. A metodologia oferece soluções personalizadas para uma variedade de cenários de aplicativos.
- Integração e adaptaçãoA arquitetura é capaz de integrar funcionalidades adicionais, como um módulo de memória (para registrar interações passadas) ou um módulo de pesquisa (para extrair dados de mecanismos de pesquisa ou gráficos de conhecimento). Essa capacidade de adaptação permite que o sistema RAG seja adaptado de forma flexível para atender a necessidades específicas.
Compreender esses tipos e características é fundamental para selecionar e implementar a arquitetura RAG mais adequada.
Do RAG básico ao avançado: superando as limitações e aprimorando os recursos
A geração aumentada por recuperação (RAG) é usada na Processamento de linguagem natural (NLP) Ele se tornou um método muito eficaz para combinar a recuperação de informações e a geração de texto para produzir resultados mais precisos e contextualizados. Entretanto, com o desenvolvimento da tecnologia, os sistemas RAG "básicos" iniciais revelaram algumas falhas, o que levou ao surgimento de versões mais avançadas. A evolução do RAG básico para o RAG avançado significa que estamos superando gradualmente essas deficiências e melhorando muito os recursos gerais do sistema RAG.
Limitações do RAG básico

A estrutura subjacente do RAG é uma tentativa inicial de combinar recuperação e geração para PNL. Embora essa abordagem seja inovadora, ela ainda enfrenta algumas limitações:
- Métodos de pesquisa simplesA maioria dos sistemas RAG básicos depende da simples correspondência de palavras-chave, uma abordagem que dificulta a compreensão das nuances e do contexto da consulta e, portanto, recupera informações insuficientes ou parcialmente relevantes.
- Dificuldade de entender o contextoÉ difícil para esses sistemas entender adequadamente o contexto de uma consulta do usuário. Por exemplo, o sistema RAG subjacente pode recuperar documentos que contenham as palavras-chave de uma consulta, mas não consegue captar a verdadeira intenção ou o contexto do usuário, não atendendo, assim, com precisão às necessidades do usuário.
- Capacidade limitada de lidar com consultas complexasOs sistemas RAG básicos têm um desempenho ruim quando confrontados com consultas complexas ou em várias etapas. Suas limitações na compreensão do contexto e na recuperação precisa dificultam o tratamento eficaz de problemas complexos.
- Base de conhecimento estáticaO sistema RAG subjacente depende de uma base de conhecimento estática e não possui um mecanismo de atualização dinâmica; as informações podem ficar desatualizadas com o tempo, afetando a precisão e a relevância da resposta.
- Falta de otimização iterativaRAG subjacente: O RAG subjacente não tem um mecanismo de otimização baseado em feedback, não pode melhorar o desempenho por meio de aprendizado iterativo e fica estagnado com o tempo.
Transição para o RAG avançado
Com a evolução da tecnologia, soluções mais sofisticadas tornaram-se disponíveis para solucionar as deficiências dos sistemas RAG básicos. Os sistemas RAG avançados superam esses desafios de várias maneiras:
- Algoritmos de pesquisa mais complexosOs sistemas RAG avançados usam técnicas sofisticadas, como pesquisa semântica e compreensão contextual, que podem ir além da correspondência de palavras-chave para compreender o significado real por trás de uma consulta, melhorando assim a relevância dos resultados recuperados.
- Integração contextual aprimoradaEsses sistemas incorporam pesos de contexto e relevância para integrar os resultados da recuperação e garantir que as informações não sejam apenas precisas, mas também adequadas ao contexto e respondam melhor à consulta e à intenção do usuário.
- Otimização iterativa e mecanismos de feedback::
O sistema Advanced RAG emprega um processo de otimização iterativo que melhora continuamente a precisão e a relevância ao longo do tempo, incorporando o feedback do usuário. - Atualização dinâmica do conhecimento::
O avançado sistema RAG é capaz de atualizar dinamicamente a base de conhecimento, introduzindo continuamente as informações mais recentes e garantindo que o sistema sempre reflita as últimas tendências e desenvolvimentos. - Compreensão contextual complexa::
Aproveitando técnicas de PNL mais avançadas, os sistemas RAG avançados têm uma compreensão mais profunda da consulta e do contexto, e são capazes de analisar nuances semânticas, dicas contextuais e intenção do usuário para gerar respostas mais coerentes e relevantes.
Aprimoramentos avançados do sistema RAG em componentes
A evolução do RAG básico para o avançado significa que o sistema alcança melhorias significativas em cada um dos quatro componentes principais: armazenamento, recuperação, aprimoramento e geração.
- estoqueOs sistemas RAG avançados tornam a recuperação de informações mais eficiente ao armazenar dados por meio de indexação semântica, organizada pelo significado dos dados em vez de simples palavras-chave.
- recuperar (dados)Com o aprimoramento da pesquisa semântica e da recuperação contextual, o sistema não apenas encontra dados relevantes, mas também entende a intenção e o contexto do usuário.
- reforçarO módulo de aprimoramento do sistema Advanced RAG gera respostas mais personalizadas e precisas por meio de um mecanismo dinâmico de aprendizagem e adaptação que é continuamente otimizado com base nas interações do usuário.
- gerandoO módulo Generation utiliza compreensão contextual sofisticada e otimização iterativa para permitir a geração de respostas mais coerentes e contextuais.
A evolução do RAG básico para o RAG avançado é um salto significativo. Com o uso de técnicas sofisticadas de recuperação, integração contextual aprimorada e mecanismos dinâmicos de aprendizado, os sistemas RAG avançados oferecem uma abordagem mais precisa e consciente do contexto para a recuperação e geração de informações. Esse avanço melhora a qualidade das interações de IA e estabelece a base para uma comunicação mais refinada e eficiente.
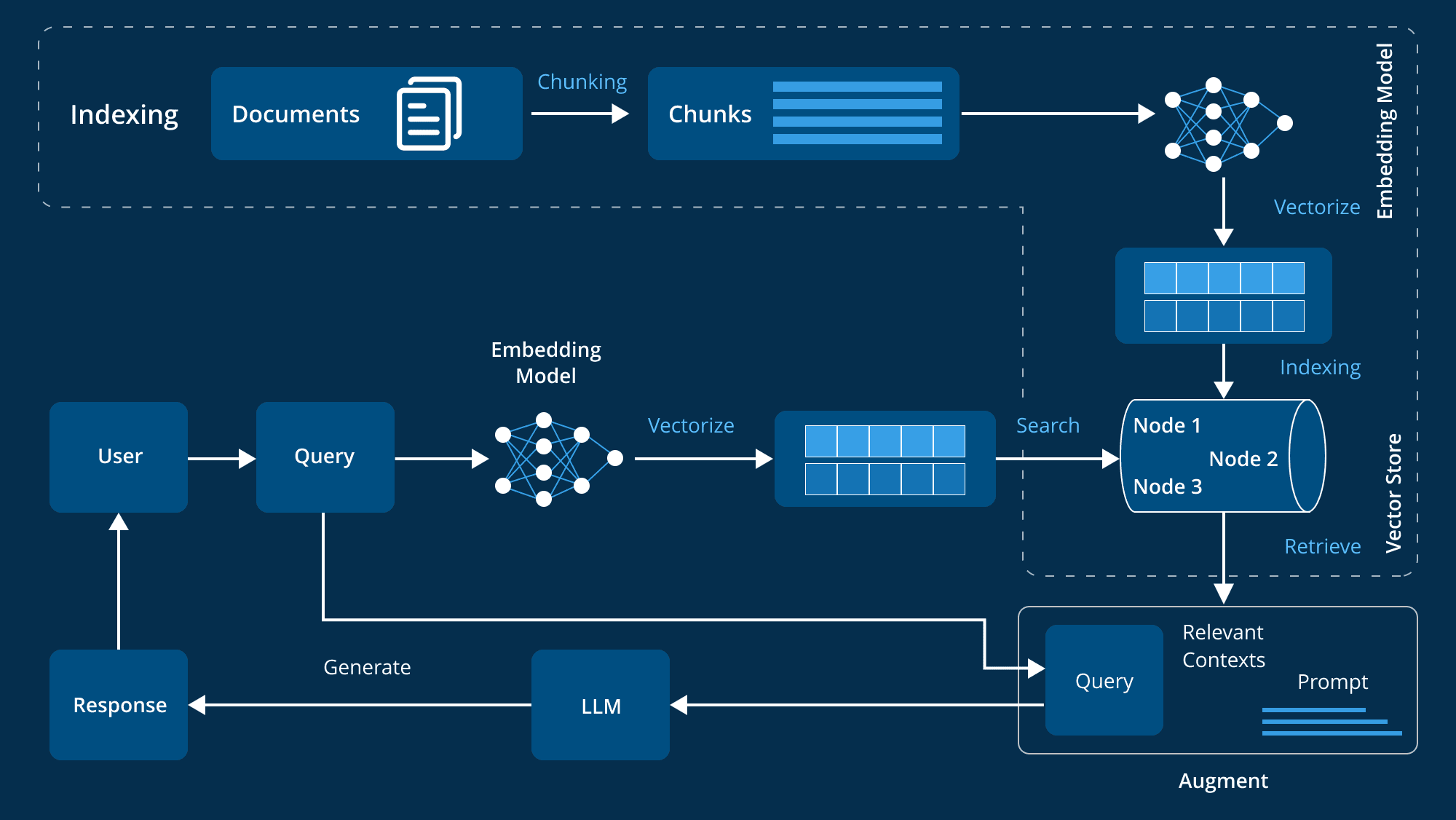
Componentes e fluxos de trabalho de um sistema RAG avançado em nível empresarial
Na área de aplicativos empresariais, há uma necessidade crescente de sistemas que possam recuperar e gerar informações relevantes de forma inteligente. Os sistemas RAG (Retrieval Augmented Generation) surgiram como soluções poderosas que combinam a precisão da recuperação de informações com o poder de geração dos LLMs (Large Language Models). Entretanto, para criar um sistema RAG avançado que atenda às necessidades complexas de uma organização, sua arquitetura deve ser cuidadosamente projetada.
Componentes da arquitetura principal
Um sistema RAG (Retrieval Augmentation Generation) avançado requer vários componentes principais que trabalham juntos para garantir a eficiência e a eficácia do sistema. Esses componentes abrangem o gerenciamento de dados, o processamento de entradas do usuário, a recuperação e a geração de informações e o aprimoramento contínuo do desempenho do sistema. A seguir, apresentamos uma análise detalhada desses componentes principais:
- Preparação e gerenciamento de dados
A base de um sistema RAG avançado é a preparação e o gerenciamento de dados, que envolve vários componentes importantes:
- Divisão e vetorização de dados: Os dados são divididos em partes mais gerenciáveis e convertidos em representações vetoriais, o que é fundamental para melhorar a eficiência e a precisão da recuperação.
- Geração de metadados e resumos: A geração de metadados e resumos permite uma referência rápida e reduz o tempo de recuperação.
- Limpeza de dados: Garantir que os dados estejam limpos, organizados e livres de ruídos é fundamental para assegurar que as informações recuperadas sejam precisas.
- Lida com formatos de dados complexos: A capacidade do sistema de lidar com formatos de dados complexos garante que os vários tipos de dados da organização sejam utilizados de forma eficaz.
- Gerenciamento da configuração do usuário: A personalização é importante em um ambiente corporativo e, ao gerenciar as configurações do usuário, as respostas podem ser adaptadas às necessidades individuais, otimizando a experiência do usuário.
- Processamento de entrada do usuário
O módulo de processamento de entrada do usuário desempenha um papel fundamental para garantir que o sistema possa lidar com as consultas de forma eficiente:
- Autenticação do usuário: A segurança dos sistemas corporativos é muito importante e os mecanismos de autenticação garantem que somente usuários autorizados possam usar o sistema RAG.
- Otimizador de consultas: A estrutura da consulta do usuário pode não ser adequada para recuperação e o otimizador otimiza a consulta para melhorar a relevância e a precisão da recuperação.
- Mecanismos de proteção de entrada: Os mecanismos de proteção protegem o sistema contra entradas estranhas ou maliciosas, garantindo a confiabilidade do processo de recuperação.
- Utilização do histórico de bate-papo: Ao se referir a diálogos anteriores, o sistema é mais capaz de entender e responder à consulta atual, gerando respostas mais precisas e contextualizadas.
- sistema de recuperação de informações
O sistema de recuperação de informações está no centro da arquitetura do RAG e é responsável por recuperar as informações mais relevantes de um índice de dados pré-processado:
- Indexação de dados: A tecnologia de indexação eficiente garante a recuperação rápida e precisa das informações, e os métodos avançados de indexação suportam o processamento de grandes quantidades de dados corporativos.
- Ajuste de hiperparâmetros: Os parâmetros do modelo de recuperação são ajustados para otimizar seu desempenho e garantir que os resultados mais relevantes sejam recuperados.
- Reordenação de resultados: Após a recuperação, o sistema reordena os resultados para garantir que as informações mais relevantes sejam exibidas primeiro, melhorando a qualidade da resposta.
- Otimização incorporada: Ao ajustar os vetores de incorporação, o sistema é capaz de combinar melhor a consulta com os dados relevantes, melhorando assim a precisão da recuperação.
- Problemas hipotéticos com a tecnologia HyDE: A geração de pares de perguntas e respostas hipotéticas usando a tecnologia HyDE (Hypothetical Document Embedding) pode lidar melhor com a recuperação de informações quando a consulta e o documento são assimétricos.
- Geração e processamento de informações
Quando informações relevantes são recuperadas, o sistema precisa gerar uma resposta coerente e contextualmente relevante:
- Geração de respostas: Usando modelos avançados de linguagem ampla (LLMs), o módulo sintetiza as informações recuperadas em uma resposta abrangente e precisa.
- Proteção e auditoria de saída: Para garantir que as respostas geradas atendam às especificações, o sistema usa várias regras para analisá-las.
- Cache de dados: Os dados ou respostas acessados com frequência são armazenados em cache, reduzindo assim o tempo de recuperação e melhorando a eficiência do sistema.
- Geração de personalização: O sistema personaliza o conteúdo gerado de acordo com as necessidades e a configuração do usuário para garantir a relevância e a precisão da resposta.
- Feedback e otimização do sistema
Os sistemas RAG avançados devem ter capacidade de autoaprendizagem e aprimoramento, e os mecanismos de feedback são essenciais para a otimização contínua:
- Feedback do usuário: Ao coletar e analisar o feedback do usuário, o sistema pode identificar áreas de melhoria e evoluir para atender melhor às necessidades do usuário.
- Otimização de dados: Com base no feedback dos usuários e em novas descobertas, os dados do sistema são continuamente otimizados para garantir a qualidade e a relevância das informações.
- Gerar avaliações de qualidade: O sistema avalia regularmente a qualidade do conteúdo gerado para otimização contínua.
- Monitoramento do sistema: Monitore continuamente o desempenho do sistema para garantir que ele esteja funcionando de forma eficiente e possa responder às mudanças na demanda ou nos padrões de dados.
Integração com sistemas corporativos
Para que um sistema RAG avançado funcione melhor em um ambiente organizacional, é essencial que haja uma integração perfeita com os sistemas existentes:
- Integração de sistemas CRM e ERP: A interface dos sistemas RAG avançados com os sistemas de CRM (Customer Relationship Management) e ERP (Enterprise Resource Planning) permite o acesso e a utilização eficientes dos principais dados comerciais, melhorando a capacidade de gerar respostas precisas e contextualmente relevantes.
- APIs e arquitetura de microsserviços: O uso de APIs flexíveis e de uma arquitetura de microsserviços permite que o sistema RAG seja facilmente integrado ao software corporativo existente, possibilitando atualizações e extensões modulares.
Segurança e conformidade
A segurança e a conformidade são especialmente importantes devido à sensibilidade dos dados corporativos:
- Protocolos de segurança de dados: Medidas robustas de criptografia de dados e processamento seguro de dados são usadas para proteger informações confidenciais e garantir a conformidade com as normas de proteção de dados, como o GDPR.
- Controle de acesso e autenticação: Implemente mecanismos seguros de autenticação de usuários e controle de acesso baseado em funções para garantir que somente o pessoal autorizado possa acessar ou modificar o sistema.
Escalabilidade e otimização do desempenho
Os sistemas RAG de classe empresarial precisam ser dimensionáveis e capazes de manter um bom desempenho sob altas cargas:
- Arquitetura nativa da nuvem: O uso da arquitetura nativa da nuvem oferece a flexibilidade de dimensionar recursos sob demanda, garantindo alta disponibilidade do sistema e otimização do desempenho.
- Balanceamento de carga e gerenciamento de recursos: Estratégias eficientes de balanceamento de carga e gerenciamento de recursos ajudam o sistema a lidar com grandes volumes de solicitações e dados de usuários, mantendo o desempenho ideal.
Análise e relatórios
Os sistemas RAG avançados também devem ter recursos robustos de análise e geração de relatórios:
- Monitoramento de desempenho: O monitoramento em tempo real do desempenho do sistema, das interações do usuário e da integridade do sistema por meio da integração de ferramentas avançadas de análise é essencial para manter a eficiência do sistema.
- Integração de Business Intelligence: A integração com as ferramentas de Business Intelligence pode fornecer insights valiosos para ajudar na tomada de decisões e impulsionar a estratégia de negócios.
Os sistemas RAG avançados em nível empresarial representam uma combinação de tecnologia de IA de ponta, mecanismos robustos de processamento de dados, infraestrutura segura e dimensionável e recursos de integração perfeita. Ao combinar esses elementos, as organizações conseguem criar sistemas RAG que podem recuperar e gerar informações com eficiência e, ao mesmo tempo, ser uma parte essencial do sistema de tecnologia empresarial. Esses sistemas não apenas proporcionam um valor comercial significativo, mas também aprimoram os processos de tomada de decisão e melhoram a eficiência operacional geral.
Tecnologia RAG avançada
O Advanced Retrieval Augmented Generation (RAG) abrange uma série de ferramentas tecnológicas projetadas para melhorar a eficiência e a precisão em todos os estágios do processamento. Esses sistemas avançados de RAG são capazes de gerenciar melhor os dados e fornecer respostas mais precisas e contextualizadas, aplicando tecnologias avançadas em diferentes estágios do processo, desde a indexação e a transformação de consultas até a recuperação e a geração. Veja abaixo algumas das técnicas avançadas usadas para otimizar cada estágio do processo de RAG:
1. índice
A indexação é um processo fundamental que melhora a precisão e a eficiência dos sistemas de Modelos de Linguagem Grande (LLMs). A indexação é mais do que apenas armazenar dados; ela envolve a organização e a otimização sistemáticas dos dados para garantir que as informações sejam fáceis de acessar e entender, mantendo o contexto importante. A indexação eficaz ajuda a recuperar dados com precisão e eficiência, permitindo que os LLMs forneçam respostas relevantes e precisas. Algumas das técnicas usadas no processo de indexação incluem:
Técnica 1: Otimização de blocos de texto por meio da otimização de blocos
O objetivo da otimização de blocos é ajustar o tamanho e a estrutura dos blocos de texto para que eles não sejam muito grandes ou muito pequenos e, ao mesmo tempo, mantenham o contexto, melhorando assim a recuperação.
Técnica 2: conversão de texto em vetores usando modelos avançados de incorporação
Depois de criar blocos de texto, a próxima etapa é converter esses blocos em representações vetoriais. Esse processo transforma o texto em vetores numéricos que capturam seu significado semântico. Modelos como o BGE-large ou a família de incorporação E5 são eficazes para representar as nuances do texto. Essas representações vetoriais são essenciais para a recuperação subsequente e a correspondência semântica.
Técnica 3: Aprimoramento da correspondência semântica por meio da incorporação do ajuste fino
O objetivo do ajuste fino da incorporação é aprimorar a compreensão semântica dos dados indexados pelo modelo de incorporação, melhorando assim a precisão da correspondência entre as informações recuperadas e a consulta do usuário.
Técnica 4: Aumento da eficiência da pesquisa por meio de várias representações
As técnicas de representação múltipla convertem documentos em unidades de recuperação leves, como resumos, para acelerar o processo de recuperação e melhorar a precisão ao trabalhar com documentos grandes.
Técnica 5: Uso de índices hierárquicos para organizar dados
A indexação hierárquica aprimora a recuperação ao estruturar os dados em vários níveis, do detalhado ao geral, por meio de modelos como o RAPTOR, que fornecem informações contextuais amplas e precisas.
Técnica 6: Recuperação aprimorada de dados por meio do anexo de metadados
As técnicas de inclusão de metadados acrescentam informações adicionais a cada bloco de dados para aprimorar os recursos de análise e classificação, tornando a recuperação de dados mais sistemática e contextual.
2) Conversão de consultas
A transformação de consultas visa otimizar a entrada do usuário e melhorar a qualidade da recuperação de informações. Utilizando LLMs, o processo de transformação é capaz de tornar consultas complexas ou ambíguas mais claras e específicas, melhorando assim a eficiência e a precisão geral da pesquisa.
Técnica 1: uso do HyDE (Hypothetical Document Embedding) para melhorar a clareza da consulta
O HyDE aprimora a relevância e a precisão da recuperação de informações gerando dados de hipóteses para melhorar a semelhança semântica entre as perguntas e o conteúdo de referência.
Técnica 2: Simplificando consultas complexas com consultas em várias etapas
As consultas em várias etapas dividem perguntas complexas em subperguntas mais simples, recuperam as respostas para cada subpergunta separadamente e agregam os resultados para fornecer uma resposta mais precisa e abrangente.
Técnica 3: Aprimoramento do contexto com dicas de retrocesso
A técnica de backtracking hinting gera uma consulta geral mais ampla a partir da consulta original complexa, de modo que o contexto ajuda a fornecer uma base para a consulta específica, melhorando a resposta final ao combinar os resultados da consulta original e da consulta mais ampla.
Técnica 4: aprimoramento da recuperação por meio da reescrita de consultas
A técnica de reescrita de consulta usa o LLM para reformular a consulta inicial a fim de melhorar a recuperação. Tanto o LangChain quanto o LlamaIndex usam essa técnica, sendo que o LlamaIndex oferece uma implementação particularmente poderosa que melhora drasticamente a recuperação.
3. roteamento de consultas
A função do roteamento de consultas é otimizar o processo de recuperação enviando a consulta para a fonte de dados mais adequada com base nas características da consulta, garantindo que cada consulta seja tratada pelo componente do sistema mais adequado.
Técnica 1: roteamento lógico
O roteamento lógico otimiza a recuperação, analisando a estrutura da consulta para selecionar a fonte de dados ou o índice mais adequado. Essa abordagem garante que a consulta seja processada pela fonte de dados mais adequada para fornecer uma resposta precisa.
Tecnologia 2: roteamento semântico
O roteamento semântico direciona a consulta para a fonte de dados ou o índice correto, analisando o significado semântico da consulta. Ele aprimora a precisão da recuperação ao compreender o contexto e o significado da consulta, especialmente para questões complexas ou com nuances.
4. técnicas de pré-pesquisa e indexação de dados
A otimização pré-resgate melhora a qualidade e a capacidade de recuperação das informações em um índice de dados ou base de conhecimento. Os métodos específicos de otimização variam de acordo com a natureza, a fonte e o tamanho dos dados. Por exemplo, o aumento da densidade das informações pode gerar respostas mais precisas com menos tokens, o que melhora a experiência do usuário e reduz os custos. Entretanto, os métodos de otimização que funcionam para um sistema podem não funcionar para outros. Os modelos de linguagem ampla (LLMs) fornecem as ferramentas para testar e ajustar essas otimizações, permitindo abordagens personalizadas para melhorar a recuperação em diferentes domínios e aplicativos.
Técnica 1: uso de LLMs para aumentar a densidade de informações
Uma etapa fundamental para otimizar um sistema RAG é melhorar a qualidade dos dados antes que eles sejam indexados. Ao utilizar LLMs para limpeza, marcação e resumo de dados, a densidade de informações pode ser aumentada, levando a resultados de processamento de dados mais precisos e eficientes.
Técnica 2: Pesquisa de índice hierárquico
As pesquisas de indexação hierárquica simplificam o processo de pesquisa criando resumos de documentos como a primeira camada de filtros. Essa abordagem em várias camadas garante que somente os dados mais relevantes sejam considerados no estágio de pesquisa, melhorando assim a eficiência e a precisão da pesquisa.
Técnica 3: Melhorar a simetria da pesquisa por meio de pares hipotéticos de perguntas e respostas
Para lidar com a assimetria entre consultas e documentos, essa técnica usa LLMs para gerar pares hipotéticos de perguntas e respostas a partir de documentos. Ao incorporar esses pares de perguntas e respostas na recuperação, o sistema pode corresponder melhor à consulta do usuário, melhorando assim a similaridade semântica e reduzindo os erros de recuperação.
Técnica 4: eliminação de duplicação com LLMs
Informações duplicadas podem ser tanto benéficas quanto prejudiciais para um sistema RAG. O uso de LLMs para eliminar a duplicação de blocos de dados otimiza a indexação de dados, reduz o ruído e aumenta a probabilidade de gerar respostas precisas.
Técnica 5: Testar e otimizar estratégias de fragmentação
Uma estratégia de fragmentação eficaz é essencial para a recuperação. Ao realizar testes A/B com diferentes tamanhos de blocos e proporções de sobreposição, é possível encontrar o equilíbrio ideal para um caso de uso específico. Isso ajuda a reter contexto suficiente sem espalhar ou diluir demais as informações relevantes.
Técnica 6: Uso de um índice de janela deslizante
A indexação por janela deslizante garante que informações contextuais importantes não sejam perdidas entre os segmentos por meio da sobreposição de blocos de dados durante o processo de indexação. Essa abordagem mantém a continuidade dos dados e melhora a relevância e a precisão das informações recuperadas.
Técnica 7: Aumentar a granularidade dos dados
O aprimoramento da granularidade dos dados é feito principalmente por meio da aplicação de técnicas de limpeza de dados que removem informações irrelevantes e retêm apenas o conteúdo mais preciso e atualizado no índice. Isso melhora a qualidade da recuperação e garante que somente as informações relevantes sejam consideradas.
Técnica 8: adição de metadados
A adição de metadados, como data, finalidade ou seção, pode aumentar a precisão da pesquisa, permitindo que o sistema se concentre com mais eficiência nos dados mais relevantes e melhore a pesquisa geral.
Técnica 9: Otimização da estrutura do índice
A otimização da estrutura de indexação envolve o redimensionamento de blocos e o emprego de várias estratégias de indexação, como a recuperação de janelas de frases, para aprimorar a maneira como os dados são armazenados e recuperados. Ao incorporar frases individuais e, ao mesmo tempo, manter uma janela contextual, essa abordagem permite uma recuperação mais rica e contextualmente mais precisa durante a inferência.
5. técnicas de recuperação
Na fase de recuperação, o sistema coleta as informações necessárias para responder à consulta do usuário. A tecnologia de pesquisa avançada garante que o conteúdo recuperado seja abrangente e contextualmente completo, estabelecendo uma base sólida para as etapas de processamento subsequentes.
Técnica 1: otimização de consultas de pesquisa com LLMs
Os LLMs otimizam a consulta de pesquisa do usuário para atender melhor aos requisitos do sistema de pesquisa, seja uma pesquisa simples ou uma consulta de diálogo complexa. Essa otimização garante que o processo de pesquisa seja mais direcionado e eficiente.
Técnica 2: correção da assimetria entre consulta e documento com o HyDE
Ao gerar documentos com respostas hipotéticas, a técnica HyDE melhora a similaridade semântica na recuperação e resolve a assimetria entre consultas curtas e documentos longos.
TÉCNICA 3: implementação de roteamento de consultas ou modelos de decisão RAG
Em sistemas que usam várias fontes de dados, o roteamento de consultas otimiza a eficiência da recuperação, direcionando as pesquisas para o banco de dados apropriado. O modelo de decisão RAG otimiza ainda mais esse processo, determinando quando uma recuperação é necessária para economizar recursos quando o modelo de linguagem grande pode responder de forma independente.
Técnica 4: Exploração profunda com pesquisadores recursivos
Um pesquisador recursivo realiza outras consultas com base no resultado anterior e é adequado para explorar dados relevantes em profundidade para obter informações detalhadas ou abrangentes.
Técnica 5: otimização da seleção da fonte de dados com recuperadores de rota
O Routing Retriever usa o LLM para selecionar dinamicamente a fonte de dados ou a ferramenta de consulta mais adequada para melhorar a eficácia do processo de recuperação com base no contexto da consulta.
Técnica 6: geração automatizada de consultas com recuperadores automáticos
O recuperador automático usa o LLM para gerar automaticamente filtros de metadados ou instruções de consulta, simplificando assim o processo de consulta ao banco de dados e otimizando a recuperação de informações.
Técnica 7: Combinação de resultados usando um pesquisador de fusão
O Fusion Retriever combina resultados de várias consultas e índices para fornecer uma visão abrangente e não duplicada das informações, garantindo uma pesquisa abrangente.
Técnica 8: agregação de contextos de dados com pesquisadores de mesclagem automática
O Auto Merge Retriever combina vários segmentos de dados em um único contexto unificado, melhorando a relevância e a integridade das informações por meio da integração de contextos menores.
Técnica 9: ajuste fino do modelo de incorporação
O ajuste fino do modelo de incorporação para torná-lo mais específico do domínio melhora a capacidade de lidar com a terminologia especializada. Essa abordagem aumenta a relevância e a precisão das informações recuperadas, alinhando melhor o conteúdo específico do domínio.
Técnica 10: Implementação da incorporação dinâmica
Os embeddings dinâmicos vão além das representações estáticas, adaptando os vetores de palavras ao contexto, o que proporciona uma compreensão mais sutil do idioma. Essa abordagem, como o modelo embeddings-ada-02 da OpenAI, captura os significados contextuais com mais precisão e, portanto, fornece resultados de recuperação mais precisos.
Técnica 11: Utilização da pesquisa híbrida
A pesquisa híbrida combina a pesquisa vetorial com a correspondência tradicional de palavras-chave, permitindo a similaridade semântica e o reconhecimento preciso de termos. Essa abordagem é particularmente eficaz em cenários em que o reconhecimento preciso de termos é necessário, garantindo uma recuperação abrangente e precisa.
6. técnicas pós-recuperação
Depois que o conteúdo relevante é adquirido, a fase pós-recuperação se concentra em como reunir esse conteúdo de forma eficaz. Essa etapa envolve o fornecimento de informações contextuais precisas e concisas ao Modelo de Linguagem Ampla (LLM), garantindo que o sistema tenha todos os detalhes necessários para gerar respostas coerentes e precisas. A qualidade dessa integração determina diretamente a relevância e a clareza do resultado final.
Técnica 1: otimização dos resultados de pesquisa por meio de reordenação
Após a recuperação, o modelo de reordenação reorganiza os resultados da pesquisa para colocar os documentos mais relevantes mais próximos da consulta, melhorando assim a qualidade das informações fornecidas ao LLM e, consequentemente, a geração da resposta final. A reordenação não apenas reduz o número de documentos que precisam ser fornecidos ao LLM, mas também atua como um filtro para melhorar a precisão do processamento de linguagem.
Técnica 2: Otimização dos resultados de pesquisa por compressão com dicas contextuais
O LLM pode filtrar e compactar as informações recuperadas antes de gerar o prompt final. A compactação ajuda o LLM a se concentrar mais nas informações críticas, reduzindo as informações de fundo redundantes e removendo ruídos estranhos. Essa otimização melhora a qualidade da resposta, concentrando-a nos detalhes importantes. Estruturas como o LLMLingua aprimoram ainda mais esse processo, removendo tokens estranhos, tornando os avisos mais concisos e eficazes.
Técnica 3: Pontuação e filtragem de documentos recuperados por meio da correção de RAGs
Antes de o conteúdo ser inserido no LLM, os documentos precisam ser selecionados e filtrados para remover documentos irrelevantes ou menos precisos. Essa técnica garante que somente informações relevantes e de alta qualidade sejam usadas, melhorando assim a precisão e a confiabilidade da resposta. O RAG corretivo utiliza um modelo como o T5-Large para avaliar a relevância dos documentos recuperados e filtra aqueles que estão abaixo de um limite predefinido, garantindo que somente informações valiosas sejam envolvidas na geração da resposta final.
7. tecnologias generativas
Durante a fase de geração, as informações recuperadas são avaliadas e reordenadas para identificar o conteúdo mais importante. A tecnologia avançada nesse estágio envolve a seleção dos principais detalhes que aumentam a relevância e a confiabilidade da resposta. Esse processo garante que o conteúdo gerado não apenas responda à consulta, mas também seja bem suportado pelos dados recuperados de forma significativa.
Técnica 1: Reduzindo o ruído com dicas de cadeia de pensamento
Os prompts de cadeia de pensamento ajudam o LLM a lidar com informações de fundo ruidosas ou irrelevantes, aumentando a probabilidade de gerar uma resposta precisa, mesmo que haja interferências nos dados.
TÉCNICA 2: Autorreflexão do sistema por meio do auto-RAG
O Self-RAG envolve o treinamento do modelo para usar tokens reflexivos durante a geração, de modo que ele possa avaliar e melhorar seu próprio resultado em tempo real, escolhendo a melhor resposta com base na facticidade e na qualidade.
Técnica 3: Ignorar planos de fundo estranhos por meio de ajuste fino
O sistema RAG foi especificamente ajustado para aprimorar a capacidade do LLM de ignorar informações externas, garantindo que apenas as informações relevantes influenciem a resposta final.
Técnica 4: Aprimorando a robustez do LLM em relação a antecedentes irrelevantes com raciocínio de linguagem natural
A integração de modelos de inferência de linguagem natural (NLI) ajuda a filtrar informações contextuais irrelevantes, comparando o contexto recuperado com a resposta gerada, garantindo que somente as informações relevantes influenciem o resultado final.
Técnica 5: controle da recuperação de dados com o FLARE
O FLARE (Flexible Language Modelling Adaptation for Retrieval Enhancement) é uma abordagem baseada em engenharia de dicas que garante que o LLM recupere dados somente quando necessário. Ele adapta continuamente a consulta e verifica se há palavras-chave de baixa probabilidade que acionam a recuperação de documentos relevantes para aumentar a precisão da resposta.
Técnica 6: Melhorando a qualidade da resposta com o ITER-RETGEN
O ITER-RETGEN (Iterative Retrieval-Generation) melhora a qualidade da resposta executando iterativamente o processo de geração. Cada iteração usa o resultado anterior como um contexto para recuperar informações mais relevantes, melhorando assim continuamente a qualidade e a relevância da resposta final.
Técnica 7: Esclarecimento de questões usando a ToC (Árvore de Esclarecimento)
O ToC gera recursivamente perguntas específicas para esclarecer ambiguidades na consulta inicial. Essa abordagem refina o processo de perguntas e respostas, avaliando e refinando continuamente a pergunta original, o que resulta em uma resposta final mais detalhada e precisa.
8. avaliação
Nas tecnologias avançadas de Geração Aumentada de Recuperação (RAG), o processo de avaliação é fundamental para garantir que as informações recuperadas e sintetizadas sejam precisas e relevantes para a consulta do usuário. O processo de avaliação consiste em dois componentes principais: escores de qualidade e recursos necessários.
A pontuação de qualidade se concentra em medir a precisão e a relevância do conteúdo:
- Relevância do histórico. Avaliar a aplicabilidade das informações recuperadas ou geradas no contexto específico da consulta. Garantir que a resposta seja precisa e adaptada às necessidades do usuário.
- Fidelidade das respostas. Verifique se as respostas geradas refletem com precisão os dados recuperados e não introduzem erros ou informações enganosas. Isso é essencial para manter a confiabilidade do resultado do sistema.
- Relevância da resposta. Avalie se a resposta gerada responde direta e efetivamente à consulta do usuário, garantindo que a resposta seja útil e consistente com a essência da pergunta.
Os recursos necessários são aqueles que o sistema deve ter para fornecer resultados de alta qualidade:
- Robustez a ruídos. Meça a capacidade do sistema de filtrar dados estranhos ou ruidosos para garantir que esses distúrbios não afetem a qualidade da resposta final.
- Rejeição negativa. Teste a eficácia do sistema para reconhecer e excluir informações errôneas ou irrelevantes da contaminação do resultado gerado.
- Integração de informações. Avalie a capacidade do sistema de integrar várias informações relevantes em uma resposta coerente e abrangente que forneça ao usuário uma resposta completa.
- Robustez contrafatual. Verifique o desempenho do sistema ao lidar com cenários hipotéticos ou contrafactuais para garantir que as respostas permaneçam precisas e confiáveis, mesmo ao lidar com perguntas especulativas.
Juntos, esses componentes de avaliação garantem que o sistema Advanced RAG forneça uma resposta que seja precisa e relevante, robusta, confiável e personalizada para as necessidades específicas do usuário.
Tecnologias adicionais
Mecanismo de bate-papo: aprimorando o diálogo no sistema RAG
A integração de um mecanismo de bate-papo em um sistema avançado de Geração Aumentada de Recuperação (RAG) aumenta a capacidade do sistema de lidar com perguntas de acompanhamento e manter o contexto do diálogo, semelhante à tecnologia tradicional de chatbot. Diferentes implementações oferecem diferentes níveis de complexidade:
- Mecanismo de bate-papo com contexto: Essa abordagem subjacente orienta a resposta do Modelo de Linguagem Grande (LLM) recuperando o contexto relevante para a consulta do usuário, incluindo bate-papos anteriores. Isso garante que o diálogo seja coerente e contextualmente apropriado.
- Concentração mais modos contextuais: Essa é uma abordagem mais avançada que condensa os registros de bate-papo e as mensagens mais recentes de cada interação em uma consulta otimizada. Essa consulta refinada pega o contexto relevante e o combina com a mensagem original do usuário para fornecer ao LLM e gerar uma resposta mais precisa e contextualizada.
Essas implementações ajudam a melhorar a coerência e a relevância do diálogo no sistema RAG e oferecem diferentes níveis de complexidade, dependendo das necessidades.
Citações de referência: garantir que as fontes sejam precisas
É importante garantir a precisão das referências, especialmente quando várias fontes contribuem para as respostas geradas. Isso pode ser feito de várias maneiras:
- Rotulagem direta da fonte: A configuração de uma tarefa em um prompt do Modelo de Linguagem (LLM) exige que a fonte seja rotulada diretamente na resposta gerada. Essa abordagem permite que a fonte original seja claramente identificada.
- Técnica de correspondência difusa: Técnicas de correspondência difusa, como as usadas pelo LlamaIndex, são empregadas para alinhar partes do conteúdo gerado com blocos de texto no índice de origem. A correspondência difusa melhora a precisão do conteúdo e garante que ele reflita as informações de origem.
Ao aplicar essas estratégias, a precisão e a confiabilidade das citações de referência podem ser significativamente aprimoradas, garantindo que as respostas geradas sejam confiáveis e bem fundamentadas.
Agentes em Geração Aumentada de Recuperação (RAG)
Os agentes desempenham um papel importante no aprimoramento do desempenho dos sistemas RAG (Retrieval Augmented Generation), fornecendo ferramentas e funcionalidades adicionais ao LLM (Large Language Model) para ampliar seu alcance. Originalmente introduzidos por meio da API do LLM, esses agentes permitem que os LLMs aproveitem as funções de código externo, APIs e até mesmo outros LLMs para aprimorar sua funcionalidade.
Uma aplicação importante dos agentes é a recuperação de vários documentos. Por exemplo, os assistentes recentes da OpenAI demonstram avanços nesse conceito. Esses assistentes aumentam os LLMs tradicionais integrando recursos como registros de bate-papo, armazenamentos de conhecimento, interfaces de upload de documentos e APIs de chamada de função que convertem a linguagem natural em comandos acionáveis.
O uso de agentes também se estende ao gerenciamento de vários documentos, em que cada documento é tratado por um agente dedicado, como resumos e questionários. Um agente central de alto nível supervisiona esses agentes específicos de documentos, encaminhando consultas e consolidando respostas. Essa configuração oferece suporte a comparações e análises complexas em vários documentos, demonstrando técnicas avançadas de RAG.
Resposta ao Synthesizer: elaborando a resposta final
A etapa final do processo RAG é sintetizar o contexto recuperado e a consulta inicial do usuário em uma resposta. Além de combinar diretamente o contexto com a consulta e processá-la por meio do LLM, abordagens mais refinadas incluem:
- Otimização iterativa: A divisão do contexto recuperado em partes menores otimiza a resposta por meio de várias interações com o LLM.
- Resumo contextual: A compressão de uma grande quantidade de contexto para caber nos prompts do LLM garante que as respostas permaneçam focadas e relevantes.
- Geração de várias respostas: Gere várias respostas de diferentes segmentos do contexto e, em seguida, integre essas respostas em uma resposta unificada.
Essas técnicas aprimoram a qualidade e a precisão das respostas do sistema RAG, demonstrando o potencial de métodos avançados na síntese de respostas.
A adoção dessas tecnologias RAG avançadas pode melhorar significativamente o desempenho e a confiabilidade do sistema. Ao otimizar o processo em cada estágio, desde o pré-processamento de dados até a geração de respostas, as empresas podem criar aplicativos de IA mais precisos, eficientes e poderosos.
Aplicativos e casos avançados de RAG
Os sistemas Advanced Retrieval Augmented Generation (RAG) são usados em uma ampla gama de campos para aprimorar a análise de dados, a tomada de decisões e a interação com o usuário por meio de seus poderosos recursos de processamento e geração de dados. Da pesquisa de mercado ao suporte ao cliente e à criação de conteúdo, os sistemas RAG avançados demonstraram benefícios significativos em diversas áreas. As aplicações específicas desses sistemas em diferentes áreas são descritas a seguir:
1. Pesquisa de mercado e análise competitiva
- integração de dadosO sistema RAG é capaz de integrar e analisar dados de diversas fontes, como mídia social, artigos de notícias e relatórios do setor.
- Identificação de tendênciasO sistema RAG é capaz de identificar tendências emergentes no mercado e mudanças no comportamento do consumidor por meio do processamento de grandes quantidades de dados.
- Informações sobre os concorrentesO sistema fornece estratégias detalhadas dos concorrentes e análises de desempenho para ajudar as empresas com a autoavaliação e o benchmarking.
- insight acionávelAs empresas podem usar esses relatórios para planejamento estratégico e tomada de decisões.
2. Suporte e interação com o cliente
- Respostas com reconhecimento de contextoO sistema RAG recupera informações relevantes da base de conhecimento para fornecer respostas precisas e contextualizadas aos clientes.
- Reduzir a carga de trabalhoAutomatização: A automatização de problemas comuns alivia a pressão sobre a equipe de suporte manual, permitindo que ela lide com problemas mais complexos.
- Serviço personalizadoO sistema personaliza as respostas e interações para atender às necessidades individuais, analisando o histórico e as preferências do cliente.
- Aprimoramento da experiência interativaServiços de suporte de alta qualidade aumentam a satisfação e fortalecem o relacionamento com o cliente.
3. Conformidade regulatória e gerenciamento de riscos
- Análise regulatóriaO sistema RAG faz a varredura e interpreta documentos legais e orientações regulatórias para garantir a conformidade.
- identificação de riscosO sistema identifica rapidamente os possíveis riscos de conformidade, comparando as políticas internas com as normas externas.
- Recomendações de conformidadeFornecer conselhos práticos para ajudar as empresas a preencher as lacunas de conformidade e reduzir os riscos legais.
- Relatórios eficientesGeração de relatórios e resumos de conformidade que são fáceis de auditar e inspecionar.
4. Desenvolvimento e inovação de produtos
- Análise do feedback do clienteO sistema RAG analisa o feedback do cliente para identificar problemas comuns e pontos problemáticos.
- Informações sobre o mercadoAcompanhar as tendências emergentes e as necessidades dos clientes para orientar o desenvolvimento de produtos.
- Propostas inovadorasFornecimento de recursos potenciais do produto e recomendações de melhorias com base na análise de dados.
- posicionamento competitivoAjudar as empresas a desenvolver produtos que atendam às necessidades do mercado e se destaquem da concorrência.
5. Análise e previsão financeira
- integração de dadosO sistema RAG integra dados financeiros, condições de mercado e indicadores econômicos para uma análise abrangente.
- Análise de tendênciasIdentificação de padrões e tendências nos mercados financeiros para auxiliar na previsão e nas decisões de investimento.
- consultoria de investimentoOrientação prática sobre oportunidades de investimento e fatores de risco: Fornecer orientação prática sobre oportunidades de investimento e fatores de risco.
- planejamento estratégicoApoio à tomada de decisões financeiras estratégicas por meio de previsões precisas e recomendações baseadas em dados.
6. Pesquisa semântica e recuperação eficiente de informações
- compreensão contextualO sistema RAG realiza pesquisa semântica compreendendo o contexto e o significado das consultas do usuário.
- Resultados relevantes: melhora a eficiência da pesquisa recuperando as informações mais relevantes e precisas de grandes quantidades de dados.
- economizar tempo: otimizar o processo de recuperação de dados e reduzir o tempo gasto na busca de informações.
- Melhorar a precisãoFornece resultados de pesquisa mais precisos do que os métodos tradicionais de pesquisa por palavra-chave.
7. Aprimoramento da criação de conteúdo
- Integração de tendênciasO sistema RAG utiliza os dados mais recentes para garantir que o conteúdo gerado esteja de acordo com as tendências atuais do mercado e os interesses do público.
- Geração automática de conteúdoGeração automática de ideias e rascunhos de conteúdo com base em temas e públicos-alvo.
- Aumentar a participaçãoGerar conteúdo mais envolvente e relevante para melhorar a interação do usuário.
- atualização oportunaConteúdo: garantir que o conteúdo reflita os últimos eventos e desenvolvimentos do mercado e permaneça atualizado.
8. resumo do texto
- DestaquesO sistema RAG pode resumir com eficácia documentos longos, destilando pontos-chave e descobertas importantes.
- economizar tempoEconomize tempo de leitura com resumos concisos de relatórios para executivos e gerentes ocupados.
- foco emDestaque as mensagens principais para ajudar os tomadores de decisão a entender rapidamente os pontos principais.
- Aumento da eficiência na tomada de decisõesDescrição: Fornecer informações relevantes de maneira fácil de entender para melhorar a eficiência da tomada de decisões.
9. Sistema avançado de perguntas e respostas
- Respostas precisas:: O sistema RAG extrai dados de uma ampla gama de fontes de informação para gerar respostas precisas a perguntas complexas.
- Aprimoramento do acesso:: Melhorar o acesso às informações em várias áreas, como saúde ou finanças.
- sensível ao contexto: Forneça respostas direcionadas com base nas necessidades e perguntas específicas do usuário.
- Questões complexasLidar com questões complexas por meio da integração de várias fontes de informação.
10. Agentes de diálogo e chatbots
- informações de contextoO sistema RAG aprimora a interação entre chatbots e assistentes virtuais, fornecendo informações contextuais relevantes.
- Melhorar a precisão: garantir que as respostas dos agentes de diálogo sejam precisas e informativas.
- suporte ao usuário: Aprimore a experiência de assistência ao usuário fornecendo uma interface de diálogo inteligente e responsiva.
- Natureza interativa: recuperação em tempo real de dados relevantes para tornar as interações mais naturais e envolventes.
11. recuperação de informações
- Pesquisa avançadaAprimore a precisão do mecanismo de pesquisa por meio dos recursos de recuperação e geração do RAG.
- Geração de fragmentos de informaçõesGerar trechos eficazes de informações para aprimorar a experiência do usuário.
- Resultados de pesquisa aprimorados: enriquecer os resultados da pesquisa com respostas geradas pelo sistema RAG para melhorar a resolução da consulta.
- mecanismo de conhecimento: Use os dados da empresa para responder a perguntas internas, como políticas de recursos humanos ou questões de conformidade, para facilitar o acesso às informações.
12. Recomendações personalizadas
- Análise de dados de clientesGeração de recomendações personalizadas de produtos por meio da análise de compras e avaliações anteriores.
- Aprimorando a experiência de compra: Melhore a experiência de compra do usuário recomendando produtos com base em preferências pessoais.
- aumentar a receitaRecomendação de produtos relevantes com base no comportamento do cliente para aumentar as vendas.
- correspondência de mercadoAdaptar o conteúdo recomendado às tendências atuais do mercado para atender às necessidades dos clientes em constante mudança.
13. preenchimento de texto
- suplemento contextual:: O sistema RAG completa partes do texto de maneira contextualmente apropriada.
- aumentar a eficiênciaDescrição: fornecer conclusões precisas para simplificar tarefas como escrever e-mails ou códigos.
- Aumento da produtividadeRedução do tempo necessário para concluir tarefas de redação e codificação e aumento da produtividade.
- Manter a consistência:: Certifique-se de que os complementos textuais sejam consistentes com o conteúdo e o tom existentes.
14. análise de dados
- Integração total de dados:: O sistema RAG integra dados de bancos de dados internos, relatórios de mercado e fontes externas para fornecer uma visão abrangente e uma análise aprofundada.
- previsão precisa:: Aumente a precisão das previsões analisando os dados, as tendências e as informações históricas mais recentes.
- Insight DiscoveryDescrição: analisar conjuntos de dados abrangentes para identificar e avaliar novas oportunidades e fornecer percepções valiosas para crescimento e aprimoramento.
- Recomendações baseadas em dadosDescrição: fornecer recomendações baseadas em dados por meio da análise de conjuntos de dados abrangentes para apoiar a tomada de decisões estratégicas e melhorar a qualidade geral da tomada de decisões.
15. tarefa de tradução
- busca de uma traduçãoTradução: Recupere traduções relevantes de bancos de dados para ajudar nas tarefas de tradução.
- Geração de contextoTradução: gerar traduções consistentes com base no contexto e com referência ao corpus recuperado.
- Melhorar a precisãoObjetivo: melhorar a precisão das traduções usando dados de várias fontes.
- aumentar a eficiênciaSimplifique o processo de tradução por meio da automação e da geração com reconhecimento de contexto.
16. Análise do feedback do cliente
- análise abrangenteAnálise de feedback de diferentes fontes para obter uma compreensão abrangente dos sentimentos e problemas dos clientes.
- percepçãoForneça insights detalhados que revelem temas recorrentes e pontos problemáticos dos clientes.
- integração de dadosIntegrar o feedback de bancos de dados internos, mídias sociais e avaliações para uma análise abrangente.
- Tomada de decisão informativa: tome decisões mais rápidas e inteligentes com base no feedback do cliente para aprimorar produtos e serviços.
Esses aplicativos demonstram a ampla gama de possibilidades dos sistemas RAG avançados, demonstrando sua capacidade de melhorar a eficiência, a precisão e a percepção. Seja para melhorar o suporte ao cliente, aprimorar a pesquisa de mercado ou simplificar a análise de dados, os sistemas RAG avançados oferecem soluções valiosas que impulsionam a tomada de decisões estratégicas e a excelência operacional.
Criação de ferramentas de diálogo com RAG avançado
As ferramentas de IA de diálogo desempenham um papel fundamental nas interações modernas com os usuários, fornecendo feedback vívido e rápido em várias plataformas. Podemos levar os recursos dessas ferramentas a um nível totalmente novo, integrando um sistema avançado de Geração Aumentada de Recuperação (RAG), que combina a recuperação avançada de informações com técnicas avançadas de geração para garantir que os diálogos sejam informativos e mantenham um fluxo natural de comunicação. Quando incorporado a uma ferramenta de IA de diálogo, o sistema RAG fornece aos usuários respostas precisas e ricas em contexto, mantendo uma cadência de diálogo natural. Esta seção explora como o RAG pode ser usado para criar ferramentas de diálogo avançadas, destacando os principais elementos a serem enfocados ao criar esses sistemas e como torná-los eficazes e práticos em aplicações do mundo real.
Planejamento do processo de diálogo
No centro de qualquer ferramenta de diálogo está o seu fluxo de diálogo, ou seja, as etapas em que o sistema processa a entrada do usuário e gera respostas. Para ferramentas avançadas baseadas em RAG, o design do fluxo de diálogo precisa ser cuidadosamente planejado para aproveitar ao máximo os recursos de recuperação do sistema RAG e a geração de modelos de linguagem. Normalmente, esse fluxo consiste em vários estágios principais:
Avaliação e reformulação do problema::
- O sistema primeiro avalia a pergunta feita pelo usuário e determina se ela precisa ser reformatada para fornecer o contexto necessário para uma resposta precisa. Se a pergunta for muito vaga ou não tiver detalhes importantes, o sistema poderá reformatá-la em uma consulta autônoma, garantindo que todas as informações necessárias sejam incluídas.
Verificação de relevância e roteamento::
- Depois que a pergunta é formatada corretamente, o sistema procura dados relevantes no armazenamento de vetores (um banco de dados que contém informações indexadas). Se forem encontradas informações relevantes, a pergunta será encaminhada para o aplicativo RAG, que recupera as informações necessárias para gerar uma resposta.
- Se não houver informações relevantes no armazenamento de vetores, o sistema precisará decidir se continua com a resposta gerada apenas pelo modelo de linguagem ou se solicita que o sistema RAG declare que não é possível fornecer uma resposta satisfatória.
Geração de uma resposta::
- Dependendo das decisões tomadas na etapa anterior, o sistema usa os dados recuperados para gerar respostas detalhadas ou se baseia no conhecimento do modelo de linguagem e no histórico do diálogo para responder ao usuário. Essa abordagem garante que a ferramenta seja capaz de lidar com problemas do mundo real e, ao mesmo tempo, acomodar diálogos mais casuais e abertos.
Otimização dos processos de diálogo usando mecanismos de tomada de decisão
Um aspecto importante na criação de ferramentas avançadas de diálogo RAG é a implementação de mecanismos de tomada de decisão que controlam o fluxo do diálogo. Esses mecanismos ajudam o sistema a decidir de forma inteligente quando recuperar informações, quando confiar em recursos generativos e quando informar ao usuário que não há dados relevantes disponíveis. Por meio dessas decisões, a ferramenta pode se tornar mais flexível e se adaptar a vários cenários de diálogo.
- Ponto de decisão 1: Reinventar ou continuar?
O sistema primeiro decide se a pergunta do usuário pode ser tratada como está ou se precisa ser reformulada. Essa etapa garante que o sistema compreenda a intenção do usuário e tenha todo o contexto necessário para permitir uma recuperação ou geração eficaz antes de gerar uma resposta. - Ponto de decisão 2: Recuperar ou gerar?
Caso seja necessária uma remodelagem, o sistema determina se há informações relevantes no armazenamento de vetores. Se forem encontrados dados relevantes, o sistema usará o RAG para recuperação e geração de respostas. Caso contrário, o sistema precisará decidir se confiará apenas no modelo de linguagem para gerar a resposta. - Ponto de decisão 3: Informar ou interagir?
Se nem o armazenamento de vetores nem o modelo de linguagem puderem fornecer uma resposta satisfatória, o sistema informará ao usuário que nenhuma informação relevante está disponível, mantendo assim a transparência e a credibilidade do diálogo.
Como criar prompts eficazes para RAGs de conversação
Os prompts desempenham um papel fundamental na orientação do comportamento de conversação dos modelos de linguagem. A criação de prompts eficazes requer uma compreensão clara das informações contextuais, dos objetivos da interação e do estilo e tom desejados. Exemplo:
- Informações básicasInformações contextuais relevantes: forneça informações contextuais relevantes para garantir que o modelo de linguagem capture o contexto necessário ao gerar ou adaptar perguntas.
- Dicas voltadas para metasEsclareça a finalidade de cada solicitação, por exemplo, para adaptar a pergunta, decidir sobre um processo de recuperação ou gerar uma resposta.
- Estilo e tomEstilo: especifique o estilo desejado (por exemplo, formal, casual) e o tom (por exemplo, informativo, empático) para garantir que a saída do modelo de linguagem atenda às expectativas da experiência do usuário.
A criação de ferramentas de diálogo usando técnicas avançadas de RAG exige uma estratégia integrada que combine os pontos fortes da recuperação e da geração. Ao projetar cuidadosamente os fluxos de diálogo, implementar mecanismos inteligentes de tomada de decisão e desenvolver prompts eficazes, os desenvolvedores podem criar ferramentas de IA que forneçam respostas precisas e ricas em contexto, bem como interações naturais e significativas com os usuários.
Como criar aplicativos RAG avançados?
É ótimo começar a criar um aplicativo Retrieval Augmented Generation (RAG) básico, mas para aproveitar todo o potencial do RAG em cenários mais complexos, é preciso ir além do básico. Esta seção descreve como criar um aplicativo RAG avançado que aprimora o processo de recuperação, melhora a precisão da resposta e implementa técnicas avançadas, como reescrita de consultas e recuperação em vários estágios.
Antes de mergulhar nas técnicas avançadas, vamos analisar brevemente a funcionalidade básica de um aplicativo RAG, que combina os recursos de um modelo de linguagem (LLM) com uma base de conhecimento externa para responder às consultas do usuário. Normalmente, esse processo consiste em duas fases:
- recuperar (dados)O aplicativo procura trechos de texto em bancos de dados vetoriais ou outras bases de conhecimento que sejam relevantes para a consulta do usuário.
- lerTexto recuperado: O texto recuperado é passado ao LLM para gerar uma resposta com base nesses contextos.
Essa abordagem de "pesquisa e leitura" fornece ao LLM as informações básicas necessárias para fornecer respostas mais precisas às consultas que exigem conhecimento especializado.
As etapas para criar um aplicativo RAG avançado são as seguintes:
Etapa 1: use técnicas avançadas para aprimorar a recuperação
O estágio de recuperação é fundamental para a qualidade da resposta final. Em um aplicativo RAG básico, o processo de recuperação é relativamente simples, mas em um aplicativo RAG avançado, você pode usar os seguintes aprimoramentos:
1. pesquisa em vários estágios
As pesquisas em vários estágios ajudam a direcionar os contextos mais relevantes, refinando a pesquisa em várias etapas. Geralmente inclui:
- Pesquisa inicial amplaInício: Comece com uma pesquisa ampla de uma série de documentos potencialmente relevantes.
- Refine sua pesquisaPesquisa mais precisa com base em resultados preliminares, restringida aos segmentos mais relevantes.
Esse método melhora a precisão das informações recuperadas, o que, por sua vez, fornece respostas mais precisas.
2. reescrita de consultas
A reescrita de consultas converte a consulta de um usuário em um formato que tem maior probabilidade de gerar resultados relevantes em uma pesquisa. Isso pode ser feito de várias maneiras:
- reescrita de amostra zeroReescrever consultas sem exemplos concretos, contando com a compreensão linguística do modelo.
- Menos reescrita de amostrasExemplos são fornecidos para ajudar os modelos a reescrever consultas semelhantes para aumentar a precisão.
- Reescritores personalizadosAjuste fino do modelo dedicado à reescrita de consultas para lidar melhor com consultas específicas do domínio.
Essas consultas reescritas correspondem melhor ao idioma e à estrutura dos documentos na base de conhecimento, melhorando assim a precisão da recuperação.
3. decomposição de subconsultas
Para consultas complexas que envolvem várias perguntas ou aspectos, a decomposição da consulta em várias subconsultas pode melhorar a recuperação. Cada subconsulta se concentra em um aspecto específico da pergunta original para que o sistema possa recuperar o contexto relevante de cada parte e integrar as respostas.
Etapa 2: Melhorar a geração de respostas
Depois de aprimorar o processo de recuperação, a próxima etapa é otimizar a forma como o Big Language Model gera respostas:
1. dicas de retrocesso
Ao se deparar com perguntas complexas ou com várias camadas, pode ser útil gerar consultas adicionais e mais amplas. Essas dicas de "fallback" podem ajudar a recuperar uma gama maior de informações contextuais, permitindo que o Big Language Model gere respostas mais abrangentes.
2) Incorporação hipotética de documentos (HyDE)
A HyDE é uma técnica de última geração que captura a intenção de uma consulta gerando documentos hipotéticos com base na consulta do usuário e, em seguida, usando esses documentos para encontrar documentos reais correspondentes em uma base de conhecimento. Essa abordagem é especialmente adequada para uso quando a consulta não é semanticamente semelhante ao contexto relevante.
Etapa 3: Integrar loops de feedback
Para melhorar continuamente o desempenho dos aplicativos RAG, é importante integrar loops de feedback ao sistema:
1. feedback do usuário
Incorporar um mecanismo que permita aos usuários avaliar a relevância e a precisão das respostas. Esse feedback pode ser usado para ajustar o processo de recuperação e geração.
2. aprendizado aprimorado
Usando técnicas de aprendizagem por reforço, os modelos são treinados com base no feedback do usuário e em outras métricas de desempenho. Isso permite que o sistema aprenda com seus erros e melhore a precisão e a relevância ao longo do tempo.
Etapa 4: Extensão e otimização
À medida que os aplicativos RAG continuam a progredir, o dimensionamento e a otimização do desempenho tornam-se cada vez mais importantes:
1. pesquisa distribuída
Para lidar com bases de conhecimento em grande escala, são implementados sistemas de recuperação distribuídos que podem processar tarefas de recuperação em paralelo em vários nós, reduzindo assim a latência e aumentando a velocidade de processamento.
2. estratégia de cache
A implementação de uma estratégia de cache para armazenar blocos de contexto acessados com frequência reduz a necessidade de recuperação repetitiva e acelera os tempos de resposta.
3. otimização do modelo
Otimização de grandes modelos de linguagem e outros modelos usados no aplicativo para reduzir a carga computacional e, ao mesmo tempo, manter a precisão. Técnicas como a destilação e a quantificação de modelos são muito úteis nesse caso.
A criação de um aplicativo RAG avançado requer um conhecimento profundo dos mecanismos de recuperação e dos modelos de geração, além da capacidade de implementar e otimizar tecnologias complexas. Seguindo as etapas descritas acima, é possível criar um sistema RAG avançado que exceda as expectativas do usuário e forneça respostas de alta qualidade e contextualmente precisas para uma variedade de cenários de aplicativos.
A ascensão dos gráficos de conhecimento em RAGs avançados
A função dos gráficos de conhecimento em sistemas avançados de geração de aumento de recuperação (RAG) tornou-se particularmente importante à medida que as organizações dependem cada vez mais da IA para tarefas complexas orientadas por dados.De acordo com a Gartner. O Knowledge Graph é uma das tecnologias de ponta que promete revolucionar vários mercados no futuro.Tecnologias emergentes que afetam o radar observou que os gráficos de conhecimento são ferramentas de suporte essenciais para aplicativos avançados de IA e fornecem a base para o gerenciamento de dados, os recursos de raciocínio e a confiabilidade do resultado da IA. Isso levou ao uso generalizado de gráficos de conhecimento em vários setores, como saúde, finanças e varejo.
O que é o Knowledge Graph?
Um gráfico de conhecimento é uma representação estruturada de informações em que as entidades (nós) e os relacionamentos entre elas (bordas) são explicitamente definidos. Essas entidades podem ser objetos concretos (como pessoas e lugares) ou conceitos abstratos. Os relacionamentos entre as entidades ajudam a criar uma rede de conhecimento que torna a recuperação de dados, o raciocínio e a inferência mais cognitivos para o ser humano. Mais do que apenas armazenar dados, o Knowledge Graph captura os relacionamentos ricos e diferenciados em um domínio, o que o torna uma ferramenta poderosa em aplicativos de IA.
Aprimoramento e planejamento de consultas com gráficos de conhecimento
O aprimoramento de consultas é uma solução para o problema de perguntas pouco claras no sistema RAG. O objetivo é adicionar o contexto necessário a uma consulta para garantir que até mesmo perguntas vagas possam ser interpretadas com precisão. Por exemplo, no domínio financeiro, perguntas como "Quais são os desafios atuais na implementação da regulamentação financeira?" Perguntas como "Quais são os desafios atuais na implementação da regulamentação financeira?" podem ser aprimoradas para incluir entidades específicas, como "conformidade com AML" ou "processo KYC", para concentrar o processo de pesquisa nas informações mais relevantes.
No domínio jurídico, perguntas como "Quais são os riscos associados aos contratos?" podem ser ampliadas com a inclusão de tipos específicos de contrato, como "contrato de trabalho" ou "contrato de serviço", com base no contexto fornecido pelo gráfico de conhecimento.
O planejamento de consultas, por outro lado, divide consultas complexas em partes gerenciáveis, gerando subperguntas. Isso garante que o sistema RAG possa recuperar e integrar as informações mais relevantes para fornecer uma resposta abrangente. Por exemplo, para responder à pergunta: "Qual é o impacto dos novos padrões de relatórios financeiros na empresa?" o sistema pode primeiro recuperar dados sobre os padrões individuais de relatórios, o cronograma de implementação e o impacto histórico em diferentes áreas.
Na área médica, uma pergunta como "Quais são os últimos avanços em dispositivos médicos?" pode ser dividida em subperguntas que exploram os avanços em áreas específicas, como "dispositivos implantáveis", "dispositivos de diagnóstico" ou "ferramentas cirúrgicas", garantindo que o sistema obtenha informações detalhadas e relevantes de cada subcategoria. informações detalhadas e relevantes de cada subcategoria.
Por meio do aprimoramento e do planejamento de consultas, o Knowledge Graph ajuda a otimizar e estruturar consultas para melhorar a precisão e a relevância da recuperação de informações, fornecendo respostas mais precisas e úteis em áreas complexas, como finanças, direito e saúde.
O papel dos gráficos de conhecimento no RAG
Nos sistemas de geração aprimorada por recuperação (RAG), os gráficos de conhecimento aprimoram o processo de recuperação e geração, fornecendo dados estruturados e ricos em contexto. Os sistemas RAG tradicionais dependem de texto não estruturado e bancos de dados vetoriais, o que pode levar à recuperação de informações imprecisas ou incompletas. Ao integrar gráficos de conhecimento, os sistemas RAG são capazes de:
- Melhor compreensão da consulta: Os gráficos de conhecimento ajudam o sistema a entender melhor o contexto e as relações de uma consulta e, portanto, a recuperar dados relevantes com mais precisão.
- Geração aprimorada de respostas: Os dados estruturados fornecidos pelo Knowledge Graph podem gerar respostas mais coerentes e contextualmente relevantes, reduzindo o risco de erros de IA.
- Implementação de raciocínio complexo: Os gráficos de conhecimento oferecem suporte ao raciocínio multihop, em que o sistema pode inferir novos conhecimentos ou conectar informações díspares percorrendo vários relacionamentos.
Principais componentes do gráfico de conhecimento
O gráfico de conhecimento consiste nos seguintes componentes principais:
- Nós: Representa várias entidades ou conceitos no campo do conhecimento, como pessoas, lugares ou coisas.
- Lateral: Descreva as relações entre os nós, mostrando como essas entidades estão interconectadas.
- Atributos: Informações adicionais ou metadados associados a nós e bordas que fornecem mais contexto ou detalhes.
- Tríade: Os blocos de construção básicos de um gráfico de conhecimento, contendo um tópico, um predicado e um objeto (por exemplo, "Einstein" [tópico] "descoberta" [predicado] "relatividade" [objeto ]), essas triplas criam a estrutura básica para descrever relacionamentos entre entidades.
Metodologia Knowledge Graph-RAG
A metodologia KG-RAG consiste em três etapas principais:
- Construção KG: Essa etapa consiste em transformar dados textuais não estruturados em um gráfico de conhecimento estruturado, garantindo que os dados sejam organizados e relevantes.
- Recuperado: Usando um novo algoritmo de recuperação chamado Chain of Exploration (CoE), o sistema executa a recuperação de dados por meio do gráfico de conhecimento.
- Geração de respostas: Por fim, as informações recuperadas são usadas para gerar respostas coerentes e contextualizadas, combinando os dados estruturados do Knowledge Graph com os recursos de um grande modelo de linguagem.
Essa metodologia destaca o papel importante do conhecimento estruturado no aprimoramento do processo de recuperação e geração de sistemas RAG.
Benefícios dos gráficos de conhecimento no RAG
A incorporação do Knowledge Graph ao sistema RAG traz várias vantagens significativas:
- Representação de conhecimento estruturado: Os gráficos de conhecimento organizam as informações de forma a refletir os relacionamentos complexos entre as entidades, tornando a recuperação e o uso dos dados mais eficientes.
- Compreensão contextual: Os gráficos de conhecimento fornecem informações contextuais mais ricas, capturando relacionamentos entre entidades, permitindo que o sistema RAG gere respostas mais relevantes e coerentes.
- Habilidades de raciocínio: O mapeamento do conhecimento ajuda o sistema a inferir novos conhecimentos, analisando as relações entre as entidades para gerar respostas mais abrangentes e precisas.
- Integração do conhecimento: Os gráficos de conhecimento podem integrar informações de diferentes fontes para fornecer uma visão mais abrangente dos dados e ajudar a tomar melhores decisões.
- Interpretabilidade e transparência: A natureza estruturada do gráfico de conhecimento torna o caminho do raciocínio claro e compreensível, facilita a explicação do processo de formação da conclusão e melhora a credibilidade do sistema.
Integração do KG com o LLM-RAG
O uso de gráficos de conhecimento em combinação com a modelagem de linguagem ampla (LLM) em sistemas RAG aprimora a representação geral do conhecimento e os recursos de raciocínio. Essa combinação permite a fusão dinâmica do conhecimento, garantindo que as informações permaneçam atualizadas e relevantes no momento da inferência, gerando, assim, respostas mais precisas e perspicazes. Os LLMs podem utilizar dados estruturados e não estruturados para fornecer resultados de melhor qualidade.
Uso de gráficos de conhecimento em testes de cadeia de raciocínio
O mapeamento do conhecimento está ganhando força nos questionários de cadeia de raciocínio, especialmente quando usado em conjunto com o Large Language Modelling (LLM). Essa abordagem funciona dividindo perguntas complexas em subperguntas, recuperando informações relevantes e sintetizando-as para formar uma resposta final. Os gráficos de conhecimento fornecem informações estruturadas nesse processo, aprimorando o poder de raciocínio do LLM.
Por exemplo, um agente de LLM pode primeiro usar o gráfico de conhecimento para identificar entidades relevantes em uma consulta, depois obter mais informações de diferentes fontes e, por fim, gerar uma resposta abrangente que reflita o conhecimento interconectado no gráfico.
Aplicações práticas de gráficos de conhecimento
No passado, os gráficos de conhecimento eram usados principalmente em domínios com uso intensivo de dados, como análise de Big Data e sistemas de pesquisa empresarial, em que sua função era manter a consistência e a uniformidade entre diferentes silos de dados. Entretanto, com o desenvolvimento de grandes sistemas RAG orientados por modelos de linguagem, os gráficos de conhecimento encontraram novos cenários de aplicação. Eles agora servem como um complemento estruturado para modelos probabilísticos de linguagem grande, ajudando a reduzir informações falsas, fornecer mais contexto e atuar como um mecanismo de memória e personalização em sistemas de IA.
Apresentando o GraphRAG
O GraphRAG é uma metodologia de recuperação de última geração que combina gráficos de conhecimento e bancos de dados vetoriais em uma arquitetura RAG (Retrieval Augmented Generation). Esse modelo híbrido aproveita os pontos fortes de ambos os sistemas para oferecer soluções de IA mais precisas, contextualmente informadas e fáceis de entender.A Gartner declarou A crescente importância dos gráficos de conhecimento no aprimoramento da estratégia de produtos e na criação de novos cenários de aplicativos de IA.
Os recursos do GraphRAG incluem:
- Maior precisão: Ao combinar dados estruturados e não estruturados, o GraphRAG é capaz de fornecer respostas mais precisas e abrangentes.
- Escalabilidade: Essa abordagem simplifica o desenvolvimento e a manutenção dos aplicativos RAG e permite melhor escalabilidade.
- Interpretabilidade: O GraphRAG fornece caminhos de inferência claros que aumentam a transparência do sistema, tornando os resultados da IA mais fáceis de entender e confiar.
Vantagens do GraphRAG
O GraphRAG tem várias vantagens significativas em relação aos métodos RAG tradicionais:
- Respostas de maior qualidade: A integração do Knowledge Graph melhorou a precisão e a relevância das respostas geradas por IA, com benchmarks recentes mostrando um aumento de três vezes na precisão.
- Custo-benefício: O GraphRAG é mais econômico, requer menos recursos de computação e dados de treinamento, e é uma opção atraente para organizações que buscam otimizar seus investimentos em IA.
- Melhor escalabilidade: Essa abordagem oferece suporte a aplicativos de IA em larga escala, permitindo que as organizações lidem facilmente com consultas mais complexas e conjuntos de dados maiores.
- Interpretabilidade aprimorada: A abordagem estruturada do GraphRAG oferece caminhos de inferência mais claros, tornando o processo de tomada de decisão da IA mais transparente e mais fácil de depurar.
- Revelando conexões ocultas: Os gráficos de conhecimento podem revelar relacionamentos que passam despercebidos em grandes conjuntos de dados, fornecendo percepções mais profundas e aprimorando a qualidade do processo de tomada de decisões.
Arquiteturas comuns do GraphRAG
Várias arquiteturas GraphRAG estão surgindo como formas de integrar efetivamente os gráficos de conhecimento aos sistemas RAG:
- Gráficos de conhecimento com agrupamento semântico: Essa arquitetura melhora a relevância e a precisão da recuperação de dados, agrupando informações relevantes antes de gerar respostas.
- Integração de gráficos de conhecimento com bancos de dados vetoriais: Essa arquitetura combina os dois sistemas para fornecer um contexto mais rico para o modelo de linguagem maior, resultando na geração de respostas mais abrangentes e contextualmente apropriadas.
- Sistema de perguntas e respostas aprimorado por gráficos de conhecimento: Nessa arquitetura, o gráfico de conhecimento acrescenta informações factuais às respostas geradas pelo modelo de linguagem grande após a recuperação do vetor para garantir a precisão e a integridade das respostas.
- Recuperação híbrida aprimorada por gráficos: Essa abordagem combina pesquisas de vetores, pesquisas de palavras-chave e consultas específicas de gráficos para fornecer um sistema de recuperação avançado e flexível que aprimora a capacidade dos modelos de linguagem grandes de gerar respostas relevantes.
Modelos emergentes para o GraphRAG
Como o GraphRAG continua a evoluir, vários padrões emergentes estão começando a surgir:
- Aprimoramento de consultas: Otimize e aprimore as consultas usando gráficos de conhecimento para garantir que as informações mais relevantes sejam recuperadas.
- Aprimoramento de respostas: Melhore a precisão e a integridade das respostas geradas pelo Big Language Model adicionando fatos relevantes.
- Controle de respostas: Use gráficos de conhecimento para verificar a precisão do conteúdo gerado por IA e reduzir o risco de informações incorretas ou falsas.
Esses padrões demonstram como o GraphRAG está mudando a forma como os sistemas de IA processam consultas complexas e geram respostas.
Aplicativos do GraphRAG
- Pesquisa jurídica: A capacidade do GraphRAG de navegar por uma complexa rede de leis, jurisprudência e estudos de caso oferece aos profissionais da área jurídica uma ferramenta poderosa para ajudar a descobrir informações jurídicas relevantes e possíveis conexões.
- Assistência médica: Na área da saúde, o GraphRAG ajuda a entender as relações complexas entre o conhecimento médico, o histórico do paciente e as opções de tratamento para melhorar a precisão do diagnóstico e o planejamento personalizado do tratamento.
- Análise financeira: O GraphRAG ajuda a analisar redes e dependências financeiras complexas, fornecendo percepções sobre tendências de mercado, gerenciamento de riscos e estratégias de investimento usando dados interconectados do gráfico de conhecimento.
- Análise de redes sociais: O GraphRAG possibilita a exploração de estruturas e interações sociais complexas, ajudando pesquisadores e analistas a entender os padrões de relacionamento e influência nas redes sociais.
- Gestão do conhecimento: O GraphRAG aprimora a base de conhecimento corporativo, capturando e aproveitando relacionamentos e hierarquias dentro das organizações, melhorando os processos de tomada de decisão e promovendo a inovação nos negócios.
Com o avanço da IA, está se tornando cada vez mais importante incorporar gráficos de conhecimento aos sistemas de geração de aumento de recuperação. O surgimento do GraphRAG demonstra as vantagens da combinação de gráficos de conhecimento com métodos vetoriais tradicionais, proporcionando uma abordagem mais abrangente e eficiente para a recuperação de informações e a geração de respostas.
RAG avançado: expandindo os horizontes por meio da geração aprimorada com recuperação multimodal
Os avanços na inteligência artificial foram acompanhados por descobertas que continuam a expandir os limites da compreensão e da geração de máquinas. Embora os sistemas tradicionais de Geração Aumentada de Recuperação (RAG) tenham se concentrado principalmente em dados textuais, o surgimento da RAG multimodal marca um importante salto tecnológico. Essa tecnologia inovadora permite que a IA processe e integre várias formas de dados, como texto, imagens, áudio e vídeo, para gerar resultados contextualizados e ricos em conteúdo. Ao aproveitar os dados multimodais, esses sistemas avançados de IA se tornam mais flexíveis, sensíveis ao contexto e capazes de fornecer percepções mais profundas e respostas mais precisas. Esta seção explora os principais conceitos, mecanismos operacionais e possíveis aplicações do RAG multimodal, destacando sua importância para a próxima geração de interações de IA.
Entendendo o RAG multimodal
O RAG multimodal é uma extensão avançada da estrutura clássica do RAG que combina mecanismos de recuperação com IA generativa para vários tipos de dados. Embora os sistemas RAG tradicionais obtenham informações por meio de consultas a bancos de dados textuais, o RAG multimodal amplia esse recurso integrando texto, imagens, áudio e vídeo ao processo de recuperação e geração. Essa extensão permite que os modelos de IA aproveitem uma variedade maior de entradas para gerar resultados mais abrangentes e diferenciados.
Como funciona o RAG multimodal?
O fluxo de trabalho de um RAG multimodal consiste em codificar diferentes tipos de dados em um formato estruturado, geralmente vetores, para que o modelo de IA possa processá-los. Esses vetores são armazenados em um espaço de incorporação compartilhado que contém dados de diferentes modalidades. Quando uma consulta é feita, o modelo recupera informações relevantes dessas modalidades, garantindo assim uma resposta mais rica e precisa. Por exemplo, para uma consulta sobre um evento histórico, o sistema pode recuperar descrições textuais, imagens relevantes, clipes de áudio de comentários de especialistas e filmagens de vídeo, que juntos formam uma resposta mais detalhada e informativa.
Métodos para implementar RAGs multimodais
Há várias abordagens que podem ser adotadas para realizar um RAG multimodal, cada uma com seus próprios benefícios e desafios:
- Um único modelo multimodal:
Essa abordagem usa um modelo unificado que é treinado para codificar vários tipos de dados - por exemplo, texto, imagens, áudio - em um espaço vetorial comum. O modelo pode, então, recuperar e gerar perfeitamente esses tipos de dados. Embora essa abordagem simplifique o processo com o uso de um único modelo, ela exige um treinamento complexo para garantir a codificação e a recuperação precisas de dados multimodais. - Modal básico baseado em texto:
Nessa abordagem, os dados não textuais são convertidos em descrições textuais antes da codificação e do armazenamento. Essa abordagem aproveita os modelos de texto atuais de última geração. Entretanto, pode haver perda de informações durante o processo de conversão, pois as nuances da imagem ou do áudio podem não ser totalmente representadas no texto. - Vários codificadores:
Essa abordagem usa modelos diferentes para codificar tipos de dados diferentes, cada um tratado por seu próprio modelo especializado. O processo de recuperação integrará esses resultados. Embora essa abordagem permita uma codificação mais especializada e uma recuperação de dados mais precisa, ela aumenta a complexidade do sistema e exige um gerenciamento cuidadoso de vários modelos e suas interações.
Arquitetura de um RAG multimodal
A arquitetura do RAG multimodal se baseia nos fundamentos dos RAGs tradicionais e incorpora a complexidade de lidar com vários tipos de dados. A arquitetura central inclui os seguintes componentes principais:
- Codificadores específicos do modo:
Cada modalidade de dados, como texto, imagem ou áudio, é processada por um codificador especializado. Esses codificadores convertem os dados brutos em um espaço de incorporação uniforme, permitindo que todas as modalidades sejam comparadas e recuperadas de forma padronizada. - Espaço incorporado compartilhado:
Um componente fundamental do RAG multimodal é o espaço de incorporação compartilhado, que armazena vetores codificados de diferentes modalidades. Esse espaço permite comparações e recuperação entre modalidades, possibilitando que o modelo reconheça informações relevantes em diferentes tipos de dados. - Retriever:
O componente Retriever é responsável por consultar o espaço de incorporação compartilhado para encontrar os pontos de dados mais relevantes entre as modalidades. Ele pode recuperar informações com base em vários critérios, como relevância para a consulta de entrada ou similaridade com outros pontos de dados no espaço. - Gerador:
Depois que as informações relevantes são recuperadas, o componente gerador integra esses dados à resposta do modelo de IA. Em geral, o gerador é um modelo de linguagem complexo que pode combinar percepções de várias modalidades em um resultado coerente e contextualmente preciso. - Mecanismos de integração:
O mecanismo de fusão é responsável por combinar os dados multimodais recuperados em uma representação unificada para uso pelo gerador. Esse processo pode envolver a seleção das modalidades mais relevantes ou a síntese de informações de diferentes fontes para criar uma resposta abrangente.
Há várias estratégias importantes que precisam ser empregadas para gerenciar as informações de diferentes modalidades em um sistema RAG:
- Uniformemente incorporado no espaço:
A codificação de todos os tipos de dados em um espaço de incorporação comum permite que o sistema realize operações de recuperação multimodal de forma eficiente. Ao mesmo tempo, esse espaço de incorporação fornece uma base para integrar e alinhar dados de diferentes fontes. - Mecanismos de atenção transmodal:
O uso de um mecanismo de atenção multimodal garante que o modelo seja capaz de se concentrar nas informações mais relevantes dos dados recuperados, independentemente da modalidade de onde provêm. Isso ajuda a equilibrar a importância de cada tipo de dado na resposta final. - Pós-processamento específico da modalidade:
Após a conclusão da recuperação, pode ser necessário um pós-processamento específico dos dados para cada modalidade, como redimensionamento de imagens ou normalização de áudio, para garantir que os dados sejam otimizados para integração e geração.
RAG multimodal em chatbots
Os RAGs multimodais aprimoram muito os recursos dos chatbots, permitindo que eles ofereçam experiências interativas mais ricas e contextualizadas. Os chatbots tradicionais dependem principalmente de texto, o que limita sua capacidade de responder a informações que envolvem visão ou som. O RAG multimodal permite que os chatbots capturem e integrem informações de imagens, vídeos e clipes de áudio para proporcionar uma experiência de usuário mais abrangente e interessante.
Por exemplo, usando os RAGs multimodais Chatbot de suporte ao cliente Vídeos instrutivos, imagens de produtos ou guias de áudio podem ser exibidos em resposta à consulta de um usuário, permitindo uma ajuda mais interativa e prática. Isso é particularmente importante em áreas como varejo, saúde e educação, onde a comunicação geralmente precisa ser apoiada por várias formas de informação.
Expansão dos aplicativos RAG multimodais
A introdução da funcionalidade multimodal está abrindo novas oportunidades em uma variedade de setores:
- Assistência médica:
Os RAGs multimodais podem combinar registros médicos textuais, imagens radiológicas, resultados laboratoriais e descrições de áudio de pacientes para melhorar a precisão e a abrangência dos sistemas de diagnóstico. - Finanças:
Nos serviços financeiros, o RAG multimodal é capaz de processar e analisar documentos complexos que contêm tabelas, gráficos e textos explicativos para aprimorar o processo de tomada de decisões. - Educação:
As plataformas educacionais podem usar RAGs multimodais para combinar texto, palestras em vídeo, ilustrações e simulações interativas em uma história de ensino completa, proporcionando uma experiência de aprendizado mais rica.
O RAG multimodal é um importante avanço tecnológico que tem o potencial de mudar a forma como os sistemas de IA interagem e respondem aos usuários. Ao incorporar vários tipos de dados no processo de recuperação e geração, os sistemas RAG multimodais são capazes de fornecer resultados mais ricos, precisos e contextualizados, abrindo novas possibilidades em todos os setores. Com a evolução da tecnologia, espera-se que seus aplicativos se expandam para aprimorar ainda mais a capacidade da IA de processar informações multimodais complexas.
Como a plataforma de coordenação GenAI da LeewayHertz, ZBrain, se destaca entre os sistemas RAG avançados.
Curioso sobre RAG avançado, RAG multimodal e gráficos de conhecimento? Imagine combinar esses recursos avançados em uma única plataforma que lhe permite criar facilmente aplicativos avançados de IA. Esse é o ZBrain.
ZBrainDesenvolvido pela LeewayHertz, o ZBrain é uma plataforma de orquestração abrangente projetada para simplificar e acelerar o desenvolvimento e o dimensionamento de soluções de IA de classe empresarial. Por meio de seu ambiente de baixo código e fácil de usar, o ZBrain permite que as organizações criem, implementem e dimensionem rapidamente aplicativos de IA generativa (GenAI) personalizados com esforço de codificação reduzido. A plataforma revoluciona o processo de desenvolvimento de IA empresarial, permitindo que as organizações aproveitem seus próprios dados para criar aplicativos de IA altamente personalizados e precisos. Como um centro de controle central, o ZBrain se integra perfeitamente às pilhas de tecnologia existentes para melhorar a eficiência do desenvolvimento de aplicativos GenAI. Os aplicativos desenvolvidos no ZBrain são excelentes em tarefas de processamento de linguagem natural (NLP), como geração de relatórios, tradução, análise de dados, classificação e resumo de textos. Ao aproveitar os dados privados e contextuais, o ZBrain garante que as respostas sejam altamente relevantes e personalizadas para atender às necessidades comerciais específicas.
Como fazer interface com sistemas avançados de geração de aumento de recuperação (RAG)
- Integração de diversas fontes de dados: O ZBrain integra uma variedade de fontes de dados, incluindo fluxos privados, públicos e em tempo real em todos os formatos de dados (estruturados, semiestruturados e não estruturados) para melhorar a precisão e a relevância das respostas de IA.
- Otimização em nível de bloco: A plataforma garante que sejam gerados resultados precisos e personalizados, dividindo as informações em partes gerenciáveis e aplicando as estratégias de pesquisa mais eficazes.
- Descoberta automática de estratégias de pesquisa: Os algoritmos avançados do ZBrain identificam e aplicam automaticamente estratégias de pesquisa ideais, reduzindo as ações manuais com base nos dados e no contexto e melhorando a precisão da recuperação de dados.
- Medidas de proteção e controle de alucinações: O ZBrain é equipado com salvaguardas e controles fantasmas para evitar a geração de informações imprecisas ou enganosas, garantindo alta precisão e confiabilidade.
capacidade multimodal
- Lida com vários formatos de dados. O ZBrain é excelente no tratamento de vários formatos de dados, como texto, imagens, vídeo e áudio, fornecendo uma resposta abrangente e detalhada.
- Integração e análise entre tipos de dados. A plataforma é capaz de integrar e analisar vários tipos de dados para fornecer insights mais ricos e respostas relevantes.
- Processamento de consultas aprimorado. O ZBrain gerencia e recupera com eficiência informações de várias modalidades de dados, melhorando a precisão e a percepção de problemas complexos.
mapa de conhecimento
- Estrutura de dados estruturados. O ZBrain organiza os dados em uma rede estruturada que melhora a precisão da recuperação e fornece percepções mais profundas ao conectar conceitos relacionados.
- Insights de dados mais profundos. A natureza interconectada do Knowledge Graph permite que o ZBrain forneça respostas com nuances e sensíveis ao contexto que levam a insights mais ricos e significativos.
- Recursos de dados estendidos. O ZBrain suporta a extensão de dados em nível de bloco ou arquivo, a atualização de meta-informações e a geração de ontologias para melhorar a representação, a organização e a recuperação de dados.
Benefícios de usar o ZBrain no desenvolvimento de soluções empresariais de IA
O ZBrain oferece muitas vantagens para o desenvolvimento de soluções empresariais de IA, incluindo:
- escalabilidade
O ZBrain facilita o dimensionamento de soluções de IA para lidar com volumes crescentes de dados e cenários de uso sem comprometer o desempenho. - Integração eficiente
A plataforma se integra facilmente às pilhas de tecnologia existentes, reduzindo o tempo e os custos de implementação e acelerando a adoção da IA. - personalização
A ZBrain oferece suporte ao desenvolvimento de aplicativos de IA altamente personalizados que atendem a necessidades comerciais específicas e se alinham às metas organizacionais. - Eficiência de recursos
Sua natureza de baixo código reduz a necessidade de um grande número de desenvolvedores e é adequada para organizações com equipes técnicas menores. - Soluções abrangentes
Do desenvolvimento à implantação, o ZBrain abrange todo o ciclo de vida de um aplicativo de IA, o que o torna uma solução abrangente. - Implementação neutra na nuvem
O ZBrain é neutro em relação à nuvem, permitindo que os aplicativos sejam implantados em uma variedade de plataformas de nuvem, proporcionando flexibilidade para se adaptar a diferentes necessidades organizacionais e preferências de infraestrutura.
O sistema RAG avançado, o suporte multimodal e a integração robusta do gráfico de conhecimento do ZBrain fazem dele uma plataforma avançada que oferece maior precisão, eficiência e insight em uma ampla variedade de aplicativos.
nota de rodapé
Os avanços no Retrieval-Augmented Generation (RAG) aumentaram drasticamente seus recursos, permitindo que ele superasse as limitações anteriores e abrisse um novo potencial na recuperação e geração de informações orientadas por IA. Com o uso de mecanismos de recuperação sofisticados, o RAG avançado pode acessar grandes quantidades de dados para garantir que as respostas geradas sejam precisas e contextualmente relevantes. Esse avanço abre caminho para aplicativos de IA mais dinâmicos e interativos, tornando o RAG uma ferramenta importante em áreas como atendimento ao cliente, pesquisa, gerenciamento de conhecimento e criação de conteúdo. A aplicação dessas tecnologias avançadas de RAG oferece às organizações a oportunidade de aprimorar a experiência do usuário, simplificar processos e resolver problemas complexos com maior precisão e eficiência.
A introdução do RAG multimodal e do RAG de gráfico de conhecimento aprimora ainda mais os recursos dessa estrutura, impulsionando a adoção generalizada em todos os setores. O RAG multimodal combina dados textuais, visuais e outras formas de dados, permitindo que o Modelo de Linguagem Ampla (LLM) gere respostas mais abrangentes e sensíveis ao contexto, que melhoram a experiência do usuário e fornecem informações mais ricas e com mais nuances. E o Knowledge Graph RAG utiliza estruturas de dados interconectadas para recuperar e gerar conteúdo semanticamente rico, melhorando consideravelmente a precisão e a profundidade das informações. Esses avanços na tecnologia RAG anunciam uma nova onda de inovação em IA, fornecendo soluções mais inteligentes e flexíveis para desafios complexos de recuperação de informações.
© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Artigos relacionados



Nenhum comentário...