Os modelos da série PP da Flying Paddles são novos! A nova "abelha" para a compreensão de imagens de documentos PP-DocBee!
A tecnologia de compreensão de imagens de documentos tem como objetivo permitir que os computadores compreendam o conteúdo das imagens de documentos tão bem quanto os seres humanos. Ela envolve principalmente a análise, o processamento e a compreensão de imagens de documentos (por exemplo, contratos em papel, páginas de livros, faturas etc.) obtidas por digitalização ou fotografia, extraindo informações valiosas, como textos, tabelas, gráficos etc., e estruturando essas informações. Na atual onda de transformação digital, a tecnologia de compreensão de imagens de documentos é amplamente utilizada nos negócios, no meio acadêmico e na vida cotidiana para aumentar a eficiência e a precisão do processamento de documentos.
Anteriormente, em combinação com o Wenxin Big Model, a FeiPaddle lançou a solução de fusão de modelos de tamanho PP-ChatOCRv3, que primeiro usa a tecnologia OCR para extrair o texto da imagem e, em seguida, insere-o no Wenxin Big Model para analisar o questionário, o que acaba melhorando significativamente o efeito de análise de layout de texto-imagem e extração de informações. O esquema é altamente preciso em textos e tabelas, mas a capacidade de entender imagens e gráficos em documentos precisa ser aprimorada. Portanto, para atender melhor às necessidades dos usuários em relação a tarefas complexas e diversas de compreensão de imagens de documentos, propomos um novo esquema, o PP-DocBee, que se baseia em um modelo multimodal de grande porte para obter uma compreensão completa da imagem do documento. Ele pode ser aplicado com eficiência em todos os tipos de cenários, como compreensão de documentos, perguntas e respostas de documentos etc. Especialmente nos cenários de compreensão de documentos chineses, como relatórios financeiros, leis e regulamentos, teses, manuais, contratos, relatórios de pesquisa etc., o desempenho é excelente.
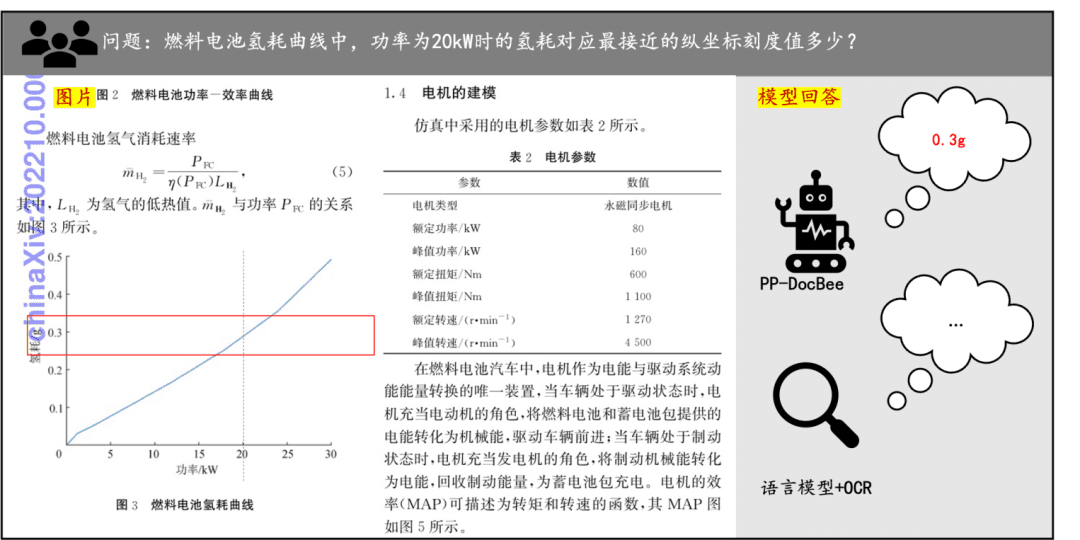
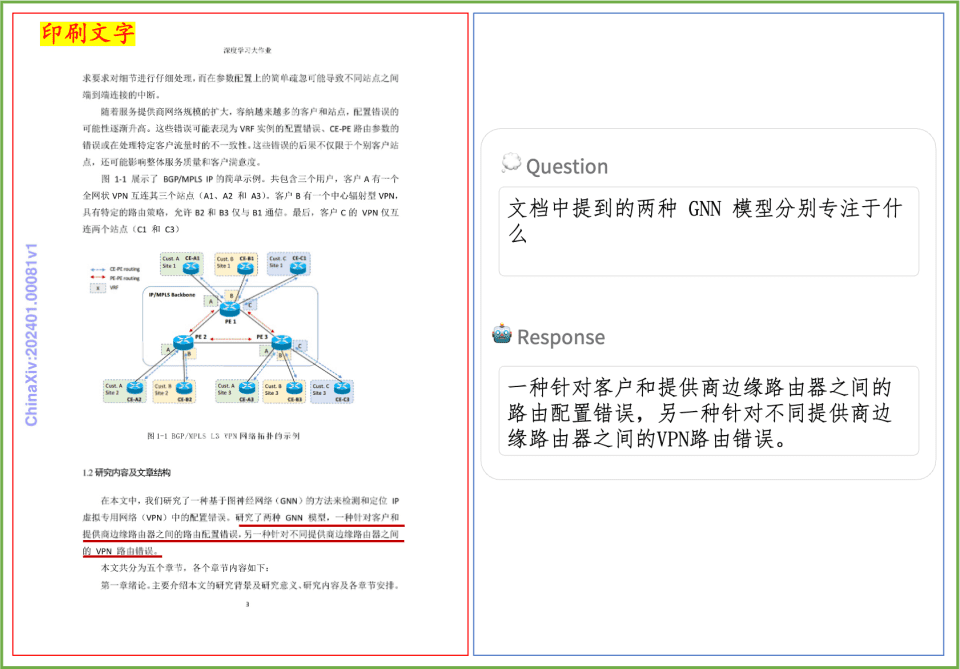
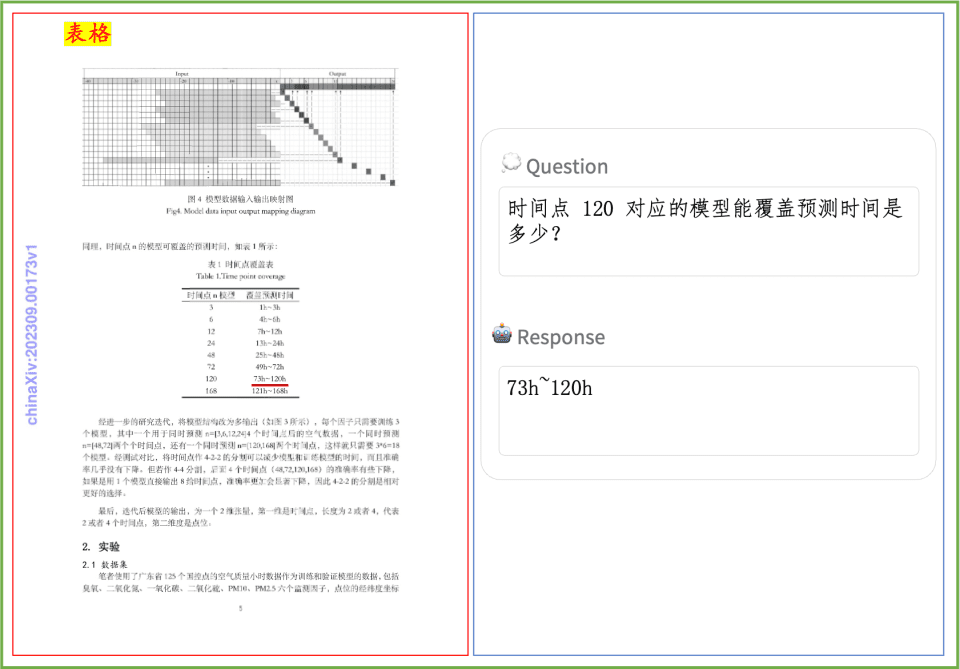
Exemplo de compreensão de documentos Uma rápida olhada no efeito do PP-DocBee na compreensão de textos impressos, tabelas, gráficos e outros documentos:

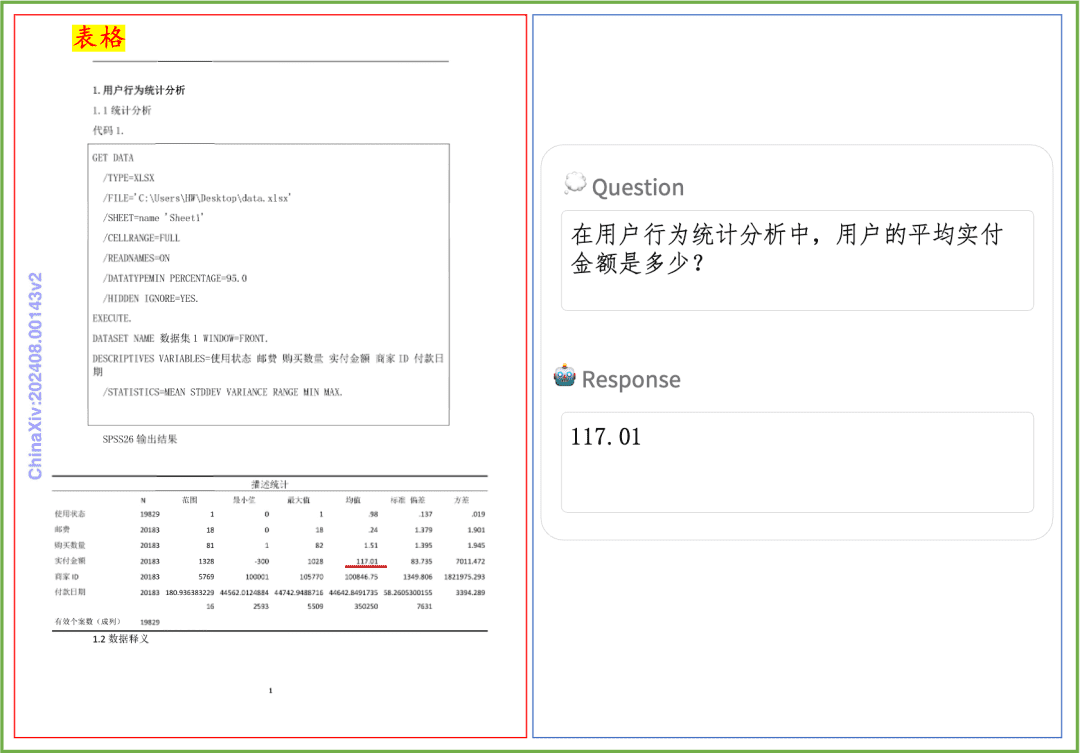

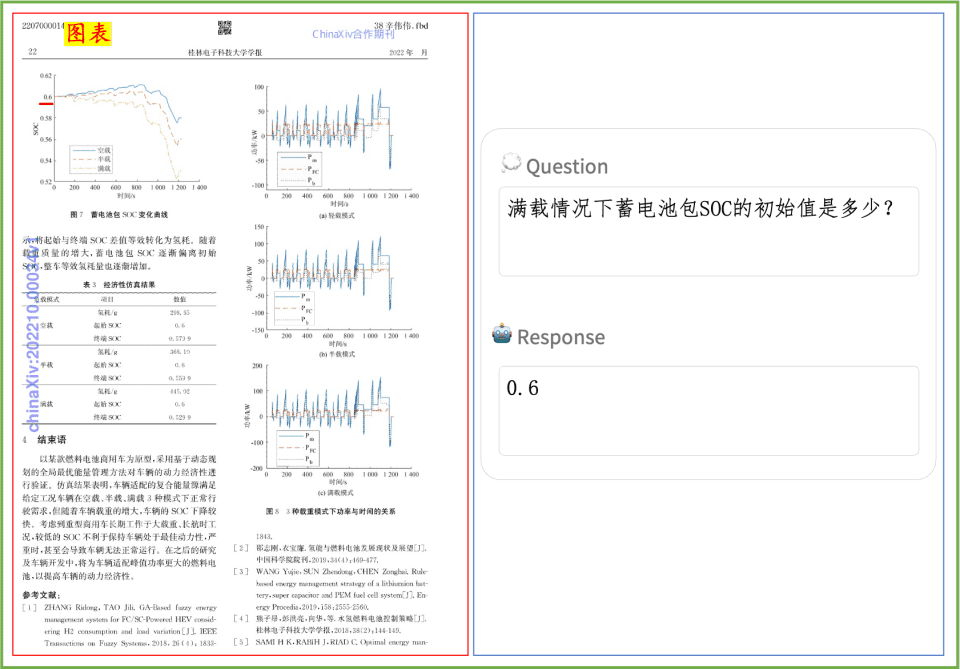
O PP-DocBee alcançou basicamente o SOTA para modelos com o mesmo nível de volume de parâmetros em várias listas de revisão de compreensão de documentos em inglês com autoridade no meio acadêmico.
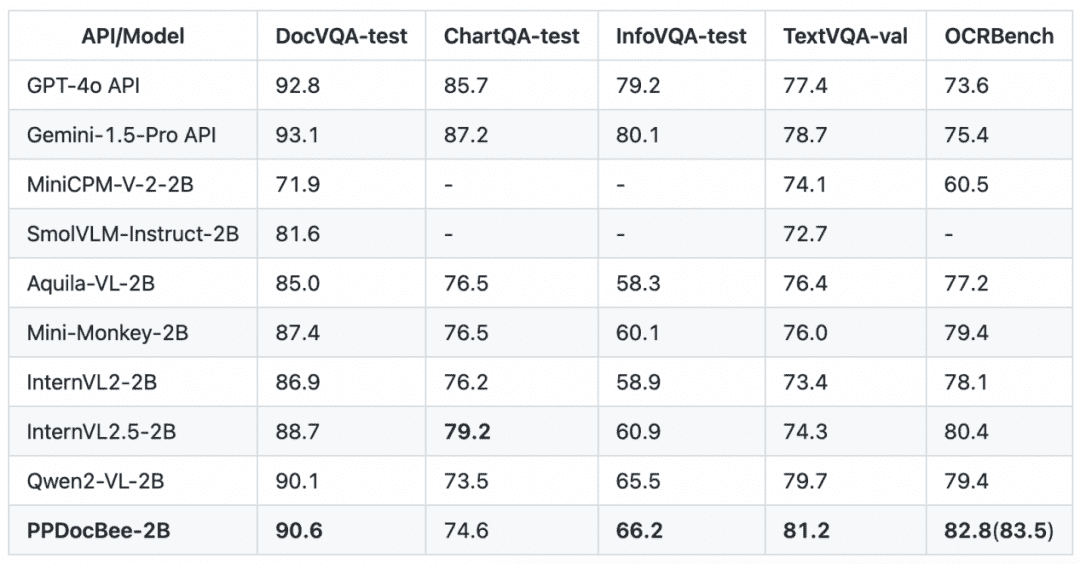
Lista de análise de compreensão de documentos em inglês Comparação de concorrentes
Observação: as métricas do OCRBench são normalizadas em uma escala de 100 pontos, e as métricas do OCRBench do PPDocBee-2B têm uma pontuação de 82,8 para avaliação completa e 83,5 para avaliação assistida por pós-processamento de OCR. O PP-DocBee também é superior aos atuais modelos populares de código aberto e fechado na categoria de métricas do cenário chinês de negócios internos.
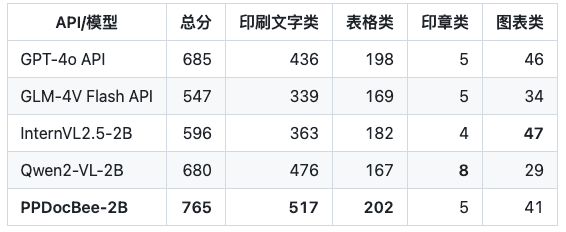
Cenário chinês de negócios Comparação de concorrentes
Observação: O conjunto de avaliação de cenários chineses para negócios internos inclui cenários de relatórios financeiros, leis e regulamentos, documentos científicos e técnicos, manuais, documentos de artes liberais, contratos, documentos de pesquisa etc., que são divididos em quatro categorias principais: texto impresso, formulários, selos e gráficos.
Para melhorar ainda mais o desempenho da inferência do PP-DocBee, conseguimos uma redução do tempo decorrido da inferência de 51,51 TP3T e uma redução total do tempo decorrido de ponta a ponta de 41,91 TP3T por meio da otimização da fusão do operador, conforme mostrado na tabela a seguir.
| PP-DocBee | Tempo médio de ponta a ponta (s) | Tempo médio de pré-processamento (s) | Tempo médio gasto com o raciocínio (s) |
| versão padrão | 1.60 | 0.29 | 1.30 |
| Edição de alto desempenho | 0.93 | 0.29 | 0.63 |
Observação: a versão de alto desempenho tem basicamente a mesma quantidade de tokens de saída que a versão padrão com a mesma quantidade de tokens de entrada. Graças à otimização de alto desempenho do flying paddle, o PP-DocBee responde mais rapidamente, mantendo a qualidade das respostas. Essa versão de raciocínio de alto desempenho, para obter detalhes, pode ser encontrada em: https://github.com/PaddlePaddle/PaddleMIX/tree/develop/deploy/ppdocbee
Também fornecemos um ambiente de experiência on-line para a Flying Paddle Star River Community, onde você pode experimentar rapidamente os recursos do PP-DocBee por meio do Flying Paddle Star River Community Application Centre (https://aistudio.baidu.com/application/detail/60135).
Além disso, também fornecemos a implantação local do gradio, a implantação do serviço OpenAI, bem como instruções detalhadas. Os usuários e entusiastas podem visitar a página inicial do projeto: https://github.com/PaddlePaddle/PaddleMIX/tree/develop/paddlemix/ examples/ppdocbee
Introdução ao programa PP-DocBee
A estrutura do modelo PP-DocBee é mostrada na figura a seguir, usando a arquitetura de ViT+MLP+LLM. As ideias de otimização para cenários de compreensão de documentos incluemEstratégias de síntese de dados, pré-processamento de dados, métodos de treinamento e assistência no pós-processamento de OCRNo final, o modelo é capaz tanto de compreender documentos genéricos quanto de analisar com precisão os documentos em cenários chineses.

Estrutura do modelo PP-DocBee
Especificamente, o PP-DocBee inclui os seguintes aprimoramentos principais:
1. estratégia de síntese de dados
Para resolver os problemas de capacidade insuficiente do idioma chinês e falta de dados de cena, criamos uma solução de produção inteligente para dados de tipo de documento, projetamos diferentes links de geração de dados para cada um dos três principais tipos de conjuntos de dados, como documento, tabela, gráfico etc., e adotamos várias estratégias: combinação de modelo pequeno de OCR e modelo grande de LLM, produção de dados de imagem com base no mecanismo de renderização e produção de dados personalizados para cada tipo de documento modelos prontos, etc., resultando em maior qualidade de Q&A e custos de geração controláveis. Os detalhes são mostrados na figura abaixo:
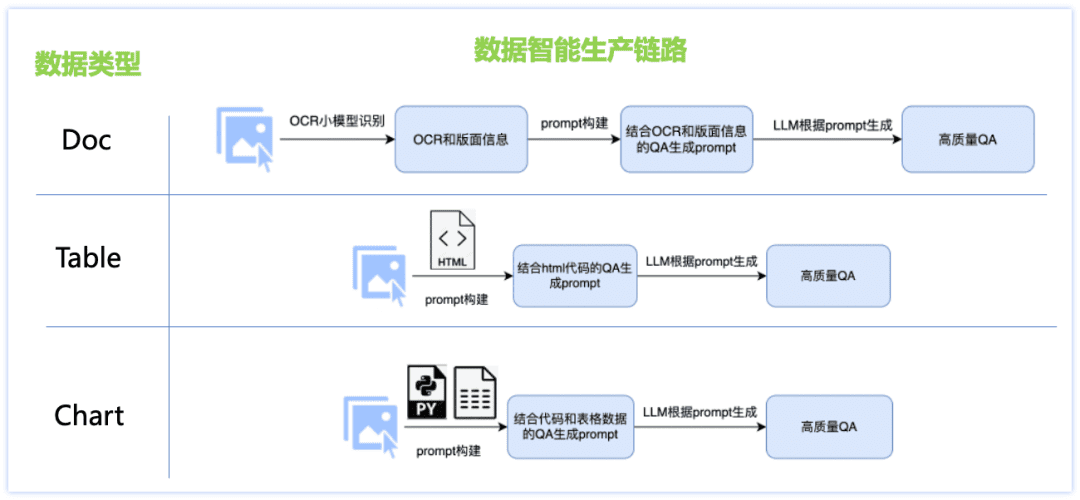
Dados da classe Doc:
Imagem: colete e organize documentos, relatórios financeiros, documentos de pesquisa e outros arquivos PDF, combinados com ferramentas de análise de PDF para produzir dados massivos de imagens de documentos de uma única página;
Perguntas e respostas: o modelo ocr small extrai informações detalhadas sobre o layout da imagem, compensando assim as deficiências na percepção visual do modelo grande e, ao mesmo tempo, usando a poderosa capacidade de compreensão de texto do modelo de linguagem grande para corrigir a imprecisão do reconhecimento de caracteres individuais do modelo ocr small, a combinação dos dois pode produzir perguntas e respostas de maior qualidade e controláveis por tipo.
Dados de classe da tabela:
Imagem: com base na imagem da tabela que contém informações de texto html, altere o valor, o assunto e outras informações no texto por meio do modelo de linguagem grande e obtenha a imagem da tabela de alta qualidade e rica em conteúdo por meio da ferramenta de renderização de tabela.
Perguntas e respostas: o texto em formato html correspondente à imagem da tabela é usado como informação auxiliar do GT para garantir a precisão das respostas, e o design de prompts ajustados para produzir perguntas e respostas de alta qualidade por meio de um grande modelo de linguagem.
Dados da classe do gráfico:
Imagem: Com base nos dados de origem do gráfico de alta qualidade testados por multidões (dados de tabela de código de imagem), altere aleatoriamente os valores, eixos, legendas, temas e outras informações refinadas do gráfico no código por meio do modelo de linguagem grande, obtenha o código-fonte com diversos conteúdos e, em seguida, renderize-o por meio da ferramenta de renderização de gráficos (Matplotlib, Seaborn, Vega-Liteetc.) para obter dados de imagem de gráficos de alta qualidade;
Perguntas e respostas: o código correspondente à imagem do gráfico e os dados da tabela são usados como informações auxiliares do GT para garantir a precisão da resposta, e os tipos de perguntas correspondentes são projetados para diferentes tipos de gráficos, e o prompt ajustado é projetado para produzir perguntas e respostas de alta qualidade por meio do modelo de linguagem grande. Por meio do esquema de produção inteligente de dados de documentos acima, obtemos uma enorme quantidade de dados sintéticos e filtramos alguns deles como um dos dados de treinamento do PP-DocBee (a distribuição de dados é mostrada na figura abaixo), o que melhora efetivamente a capacidade do modelo.
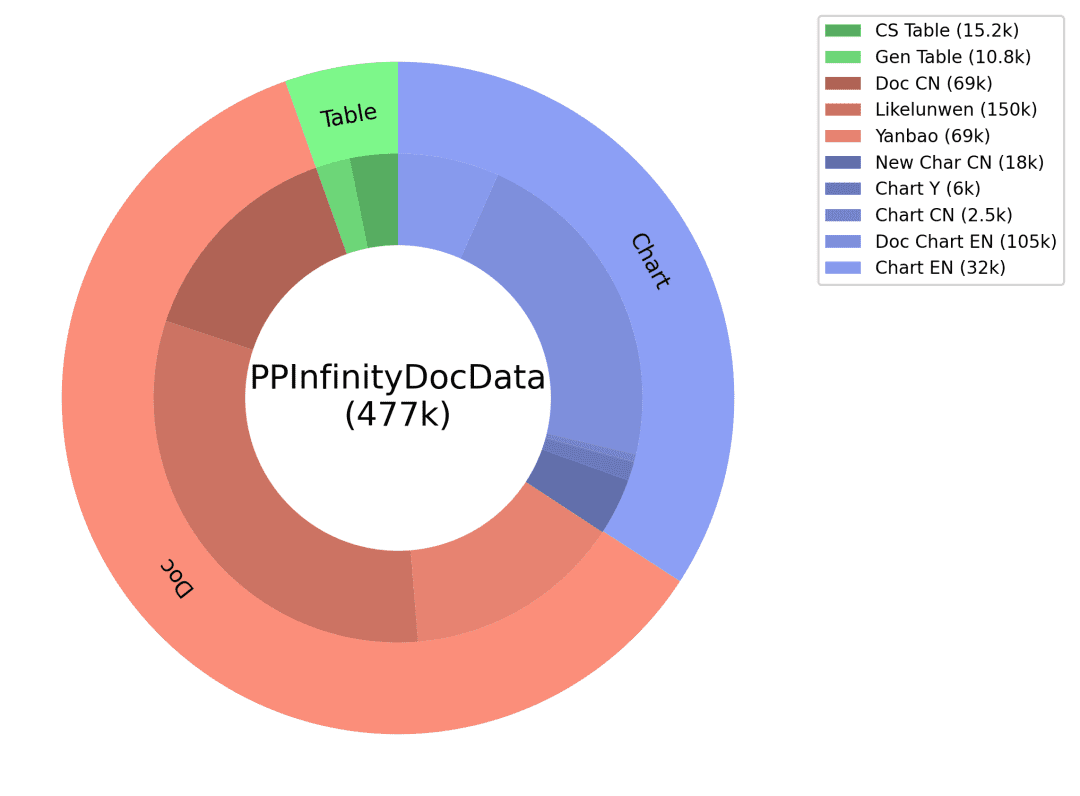
Distribuição de dados sintéticos
2. pré-processamento de dados
Duas estratégias estão incluídas: uma é definir um limite de redimensionamento maior durante o treinamento para aumentar a distribuição geral da resolução do conjunto de dados e a outra é definir uma ampliação igual de 1,1 a 1,3 vezes para a maioria das imagens regulares durante a inferência, mantendo a estratégia original de pré-processamento de dados inalterada para imagens de resolução pequena. Essas duas estratégias produziram recursos visuais mais adequados e abrangentes, o que melhorou a compreensão final.
3. métodos de treinamento
É principalmente uma mistura de várias classes de dados de compreensão de documentos, bem como um mecanismo de correspondência de dados é configurado. Os vários conjuntos de dados incluem classe VQA genérica, classe OCR, classe de diagrama, classe de documento rico em texto, classe de raciocínio matemático e complexo, classe de dados sintéticos, dados de texto simples etc. O mecanismo de correspondência de dados consiste em definir a proporção de amostragem para diferentes classes e diferentes fontes de dados entre as classes, a fim de aumentar os pesos de amostragem de várias classes de dados com maiores ganhos, bem como equilibrar as diferenças quantitativas entre os vários conjuntos de dados.
4. assistência no pós-processamento de OCR
Principalmente por meio da ferramenta ou do modelo de OCR para obter o reconhecimento de OCR dos resultados do texto e, em seguida, como uma informação auxiliar a priori fornecida nas perguntas do questionário de imagem e, em seguida, fornecer o raciocínio do modelo PP-DocBee, pode ser que o texto não seja muito claro e a imagem tenha algum efeito sobre a melhoria.
© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Artigos relacionados



Nenhum comentário...